C++primer笔记之关联容器
在这一章中,有以下的几点收获:
1、pair类型的使用相当频繁,如果需要定义多个相同的pair类型对象,可考虑利用typedef简化其声明:
typedef pair<string, string> A;这样,在后面的使用中就可以直接用A来代替前面繁琐的书写。
2、三种方法创建pair对象:
(1)第一种方法:使用函数make_pair()
pair<string, string> spair;
string first, last;
while(cin >> first >> last) {
spair = make_pair(first, last);
}
(2)第二种方法:可以调用vector的构造函数
spair = pair<string, string> (first, last);
(3)第三种方法:由于pair的数据成员是公有的,所以可以直接输入
while(cin >> spair.first >> spair.last) { //}
三种方法个人用起来的话是第一种好用些,看个人喜好。
3、map定义的类型
map对应的元素是键-值对,在学习map接口时,警记value_type是pair类型,键是key_type类型,为const,不可修改,而值是mapped_type类型,可以修改。如下:
map<K,V>::key_type 键的类型
map<k,V>::mapped_type 值得类型
map<k,V>::value_type pair类型,first元素为const map<K,V>::key_type类型,second元素为map<K,V>::mapped_type类型
4、使用下标访问map对象
使用下标访问map与使用下标访问数组或vector的行为截然不同,用下标访问不存在的元素将导致在map容器中添加一个新的元素,它的键即为该下标值。
5、可以用insert代替下标运算,既简洁又紧凑
word.insert(map<string, int>::value_type("anna", 1));
其中红色部分代码可以用以下的两种方法代替:
word.insert(make_pair("anna",1));
typedef map<string, int>::value_type valType;
word.insert(valType("anna",1));
6、单词统计程序的两个版本:
第一版本:采用下标
string word;
map<string, int> wordCount; //第一版本
while(cin >> word) {
++ wordCount[word];
}
第二版本:采用insert,利用返回值的第二个bool值来判断元素是否插入
string word;
map<string, int> wordCount; //第二版本
while(cin >> word) {
pair< map<string, int>::iterator, bool > ret =\
wordCount.insert(make_pair(word,)); //!!!注意此句的表达
if (ret.second == false) //表明没有插入数据,map中已经存在着相应的单词
++wordCount[word];
}
7、与map容器不一样,set容器的每个键对应的元素是唯一的,不可重复。
8、在multimap和multiset中查找元素
可以用三种策略来解决查找问题:
第一种策略:使用find和count操作:
count函数求出某键出现的次数,而find操作则返回一个迭代器,指向第一个拥有正在查找的键的实例:
multimap<string, string> smmap; //创建作者和书名对应的multimap对象
string searchName("Wang"); //搜索的作者名 //第一种方法:采用find和count操作
typedef multimap<string, string>::size_type sz_type;
sz_type nCount = smmap.count(searchName); //得到searchName键对应的项的个数
multimap<string, string>::iterator it = smmap.find(searchName); for (sz_type si = ; si != nCount; ++ si, ++ it)
cout << it->second << endl;
第二种策略:采用面向迭代器的解决方案:
采用有关关联迭代器的操作:lower_bound和upper_bound
//第二种方法:采用面向迭代器的解决方案
typedef multimap<string, string>::iterator iter;
iter beg = smmap.lower_bound(searchName);
iter end = smmap.upper_bound(searchName);
while(beg != end) {
cout << beg->second << endl;
++ beg;
}
第三种策略:采用equal_range函数
调用equal_range来代替upper_bound和lower_bound函数的效果是一样的
//第三种方法:采用equal_range函数
typedef multimap<string, string>::iterator iter;
pair<iter, iter> pos = smmap.equal_range(searchName);
while (pos.first != pos.second) {
//pos是一对迭代器,pos.first是第一个迭代器所关联的实例,而pos.first->second是该实例所对应的值
cout << pos.first->first << "\t\t" << pos.first->second << endl;
++ pos.first;
}
9、容器的综合应用:文本查询程序
要求:给定一个文本文件,允许用户从该文件中查找单词,查询的结果是该单词出现的次数,并列出每次出现所在的行,如果某单词在同一行中多次出现,程序将只显示该行一次,行号按升序显示:
下面是程序的代码实现,详细实现细节可参考书本,首先看.h文件:
#ifndef _TEXTQUERY_H
#define _TEXTQUERY_H /************************************************************************/
/* 单词查找程序
/* 指定任意文本,并在其中查找单词
/* 结果为该单词出现的次数,并列出每次出现的行
/* 如果该单词在同一行中出现多次,将只显示该行一次,行号按升序显示
/************************************************************************/
class TextQuery {
public:
typedef vector<string>::size_type line_no; //行号
void read_file(ifstream &is) { //从文件读入一行,并创建每个单词对应行号的map容器
store_file(is);
build_map();
}
set<line_no> run_query(const string &) const; //返回包含string对象的所有行的行号
string text_line(line_no) const; //返回某行号所对应的文本行
private: void store_file(ifstream &); //读入文件的每一行并存入vector中
void build_map(); //将每一行分解成各单词,同时记录该单词出现的行号
private:
vector<string> lines_of_text;
map < string, set<line_no> > word_map;
}; // void TextQuery::read_file(ifstream &is)
// {
// store_file(is);
// build_map();
// } set<TextQuery::line_no> TextQuery::run_query(const string &str) const
{
map< string, set<line_no> >::const_iterator loc = word_map.find(str);
if (loc == word_map.end())
return set<line_no>(); //没有找到,则返回空的set集
else
return loc->second;
} string TextQuery::text_line(line_no line) const
{
if (line < lines_of_text.size())
return lines_of_text[line];
throw out_of_range("line number out of range");
} void TextQuery::store_file(ifstream &infile)
{
string line;
while(getline(infile, line))
lines_of_text.push_back(line);
} void TextQuery::build_map()
{
for(line_no linenum = ; linenum != lines_of_text.size(); ++ linenum) {
istringstream issrem(lines_of_text[linenum]);
string word;
while (issrem >> word) {
word_map[word].insert(linenum); //下标插入法
}
}
} #endif//_TEXTQUERY_H
下面是.cpp文件
#include "stdafx.h"
#include <iostream>
#include <map>
#include <set>
#include <vector>
#include <sstream>
#include <fstream>
#include <string> using namespace std;
#include "TextQuery.h"
#include "fileio.h" /************************************************************************/
/* 文本查询程序(TextQuery.h)
/* Author:bakari Date:2013.9.20
/************************************************************************/ void print_result(const set<TextQuery::line_no> &locs,\
const string &s, const TextQuery &file);//打印结果
string make_plural(size_t size, const string &str, const string &endstr);//根据size的值打印单数还是复数 int main(int argc, char **argv)
{
ifstream infile; if (argc < || !open_file(infile,argv[])) {
cerr << "no input file" << endl;
return EXIT_FAILURE;
}
TextQuery tq;
tq.read_file(infile); while(true) {
cout << "enter word to look for or q to quit!" << endl;
string s;
cin >> s;
if (!cin || s == "q")
break;
set<TextQuery::line_no> locs = tq.run_query(s);
print_result(locs, s, tq);
}
return ;
} void print_result(const set<TextQuery::line_no> &locs,\
const string &s, const TextQuery &file)
{
typedef set<TextQuery::line_no> line_num;
line_num::size_type size = locs.size(); //记录locs中每个单词出现的总次数 !!!注意表达
if (!size) { //没有该单词出现
cout << "no this word!" << endl;
exit(EXIT_FAILURE);
} cout << s << " occurs " << size << make_plural(size, " time", "s") << endl;
for (line_num::const_iterator iter = locs.begin(); iter != locs.end(); ++iter) {
cout << "\t(line " << *iter + << ") ";
cout << file.text_line(*iter) << endl;
} } string make_plural(size_t size, const string &str, const string &endstr)
{
return (size == )?str : str + endstr;
}
程序运行结果: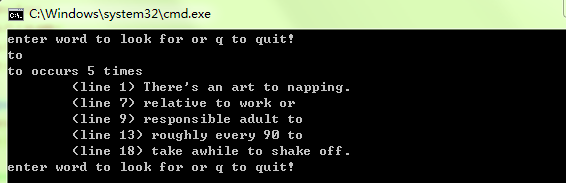
C++primer笔记之关联容器的更多相关文章
- 高放的c++学习笔记之关联容器
标准库提供8个关联容器 按关键字有序保存有(红黑树实现) set map multset 关键字可重复出现的set multimap 关键字可重复出现的map 无序保存 哈希实现 unorderre ...
- STL学习笔记(三) 关联容器
条款19:理解相等(equality)和等价(equivalence)的区别 相等的概念是基于 operator== 的,如果 operator== 的实现不正确,会导致并不实际相等等价关系是以&qu ...
- C++primer笔记之顺序容器
最近又重新拾起C++primer,发现每一次看都会有不同的体验,但每一次看后因为不常用,忘记得很快,所以记笔记是很关键的一环,咋一看是浪费时间,实际上是节省了很多时间.下面就把这一节的内容做一个简单的 ...
- C++ primer 11章关联容器
map set multimap (关键字可重复出现) multiset 无序 unordered_map (用哈希函数组织的map) unordered_set unordered_multima ...
- 【C++ Primer | 11】关联容器(一)
在multimap或multiset中查找元素 第二种方法解释: #include <iostream> #include <utility> #include <ite ...
- C++ Primer 读书笔记:第10章 关联容器
第10章 关联容器 引: map set multimap multiset 1.pair类型 pair<string, int> anon anon.first, anon.second ...
- C++ Primer笔记7_STL之关联容器
关联容器 与顺序容器不同,关联容器的元素是按keyword来訪问和保存的.而顺序容器中的元素是按他们在容器中的位置来顺序保存的. 关联容器最常见的是map.set.multimap.multiset ...
- C++ Primer 笔记——关联容器
1.关联容器支持高效的关键字查找和访问,标准库提供8个关联容器. 2.如果一个类型定义了“行为正常”的 < 运算符,则它可以用作关键字类型. 3.为了使用自己定义的类型,在定义multiset时 ...
- C++ Primer 学习笔记_34_STL实践与分析(8) --引言、pair类型、关联容器
STL实践与分析 --引言.pair类型.关联容器 引言: 关联容器与顺序容器的本质差别在于:关联容器通过键[key]来存储和读取元素,而顺序容器则通过元素在容器中的位置顺序的存取元素. ma ...
随机推荐
- Ubuntu 装nexus
装nexus前提是装好JDK和maven 先下载 wget http://download.sonatype.com/nexus/oss/nexus-2.12.0-01-bundle.tar.gz 再 ...
- Handler实现消息的定时发送
话不多说,直接上代码 private Handler mHandler = new Handler() { @Override public void handleMessage(Message ms ...
- RDD认知
1.RDD又叫弹性分布式数据集 2.抽象 3.带泛型,支持多种数据类型 4.集合是可以进行分区 例如(1,2,3,4,5,6,7,8,9)这个数组是可以进行分区的(1,2,3) (4,5,6) ( ...
- DBHelper类
import java.sql.Connection;import java.sql.DriverManager;import java.sql.PreparedStatement;import ja ...
- 【c++】内存检查工具Valgrind介绍,安装及使用以及内存泄漏的常见原因
转自:https://www.cnblogs.com/LyndonYoung/articles/5320277.html Valgrind是运行在Linux上一套基于仿真技术的程序调试和分析工具,它包 ...
- java基础 ----- 选择结构
--------- 流程控制 ------ 流程图 ------ 基本的 if 选择结构 import java.util.Scanner; public class GetPr ...
- java ssh执行shell脚本
1.添加依赖 com.jcraft:jsch ch.ethz.ganymed:ganymed-ssh2:262 2.获取连接 conn = new Connection(ip, port); conn ...
- 探索未知种族之osg类生物---呼吸分解之更新循环三
补充 当然细心的你会发现,_scene->updateSceneGraph(*_updateVisitor)中还有一个imagePager::UpdateSceneGraph()还没有进行讲解, ...
- tab选项卡实例
之前也见了不少的tab选项卡,但是下面这个选项卡是一个页面中有多个时互不影响的. <head> <meta charset="utf-8"> <met ...
- Unity 游戏运行越久加载越慢
原因是某个GameObject 被调用多次DontDestroyOnLoad,表面上是调用多次没问题,实际上调用次数越多,加载速度越慢.