Java并发编程(十四)Java内存模型
1.共享内存和消息传递
线程之间的通信机制有两种:共享内存和消息传递;在共享内存的并发模型里,线程之间共享程序的公共状态,线程之间通过写-读内存中的公共状态来隐式进行通信。在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过明确的发送消息来显式进行通信。
同步是指程序用于控制不同线程之间操作发生相对顺序的机制。在共享内存并发模型里,同步是显式进行的。工程师必须显式指定某个方法或某段代码需要在线程之间互斥执行。在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
Java的并发采用的是共享内存模型,Java线程之间的通信总是隐式进行,整个通信过程对工程师完全透明。
2.Java内存模型的抽象
在java中,所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”这个术语代指实例域,静态域和数组元素)。局部变量,方法定义参数和异常处理器参数不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存中,每个线程都有一个私有的本地内存,本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java内存模型的抽象示意图如下:
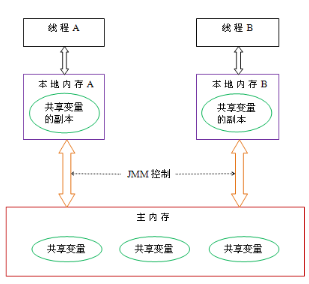
从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
- 线程A把本地内存A中更新过的共享变量刷新到主内存中去。
- 线程B到主内存中去读取线程A之前已更新过的共享变量。
3.从源代码到指令序列的重排序
在执行程序时为了提高性能,编译器和处理器常常会对指令做重排序。重排序分三种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从java源代码到最终实际执行的指令序列,会分别经历下面三种重排序:

上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序都可能会导致多线程程序出现内存可见性问题。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序(不是所有的处理器重排序都要禁止)。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
4.happens-before简介
happens-before是JMM最核心的概念,对于Java工程师来说,理解happens-before是理解JMM的关键。
JMM的设计意图
在设计JMM需要考虑两个关键因素:
- 工程师对内存模型的使用,希望内存模型易于理解和编程,工程师希望基于一个强内存模型来编写代码。
- 编译器和处理器对内存的实现,希望内存模型对他们的束缚越少越好,编译器和处理器希望实现一个弱内存模型。
这两个因素是互相矛盾的,所以JSR-133专家组设计时需要考虑到一个好的平衡点:一方面为工程师提供足够强的内存可见性,另一方面要对编译器和处理器的限制要尽量松些。
我们来举了例子:
int a=; //A
int b=; //B
int c=a*b; //C 上面是一个简单的乘法运算,并存在3个happens-before关系:
. A happens-before B
. B happens-before C
. A happens-before C 这三个happens-before关系中,2和3是必须的,但1是不必要的。因此,JMM把happens-before要求禁止的重排序分为两类:
.会改变程序执行结果的重排序。
.不会改变程序执行结果的重排序。 JMM对这两种不同性质的重排序,采取了不同的策略:
.对于会改变程序执行结果的重排序,JMM要求编译器和处理器必须禁止这种重排序。
.对于不会改变程序执行结果的重排序,JMM要求编译器和处理器不做要求,可以允许这种重排序。
happens-before的定义与规则
JSR-133使用happens-before的概念来指定两个操作之间的执行顺序,由于这两个操作可以在一个线程内,也可以在不同的线程之间。因此,JMM可以通过happens-before关系向工程师提供跨线程的内存可见性保证。
happens-before规则如下:
1. 程序顺序规则:一个线程中的每个操作,happens- before 于该线程中的任意后续操作。
2. 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
3. volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
4. 传递性:如果A happens- before B,且B happens- before C,那么A happens- before C。
5.顺序一致性
顺序一致性内存模型是一个理论参考模型,在设计的时候,处理器的内存模型和编程语言的内存模型都会以顺序一致性内存模型为参考。
数据竞争与顺序一致性
当程序未正确同步时,就会存在数据竞争。数据竞争指的是:在一个线程中写一个变量,在另一个线程读同一个变量,而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。
JMM对正确同步的多线程程序的内存一致性做了如下保证:
如果程序是正确同步的,程序的执行将具有顺序一致性(sequentially consistent),即程序的执行结果与该程序在顺序一致性内存模型中的执行结果相同。这里的同步是指广义上的同步,包括对常用同步原语(synchronized,volatile和final)的正确使用。
顺序一致性模型
顺序一致性内存模型是一个被计算机科学家理想化了的理论参考模型,它为程序员提供了极强的内存可见性保证。顺序一致性内存模型有两大特性:
- 一个线程中的所有操作必须按照程序的顺序来执行。
- (不管程序是否同步)所有线程都只能看到一个单一的操作执行顺序。在顺序一致性内存模型中,每个操作都必须原子执行且立刻对所有线程可见。
顺序一致性内存模型为程序员提供的视图如下:
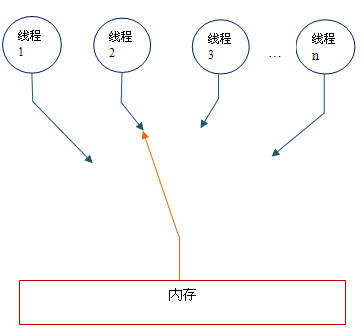
在概念上,顺序一致性模型有一个单一的全局内存,这个内存通过一个左右摆动的开关可以连接到任意一个线程。同时,每一个线程必须按程序的顺序来执行内存读/写操作。从上图我们可以看出,在任意时间点最多只能有一个线程可以连接到内存。当多个线程并发执行时,图中的开关装置能把所有线程的所有内存读/写操作串行化。
顺序一致性内存模型中的每个操作必须立即对任意线程可见,但是在JMM中就没有这个保证。未同步程序在JMM中不但整体的执行顺序是无序的,而且所有线程看到的操作执行顺序也可能不一致。比如,在当前线程把写过的数据缓存在本地内存中,且还没有刷新到主内存之前,这个写操作仅对当前线程可见;从其他线程的角度来观察,会认为这个写操作根本还没有被当前线程执行。只有当前线程把本地内存中写过的数据刷新到主内存之后,这个写操作才能对其他线程可见。在这种情况下,当前线程和其它线程看到的操作执行顺序将不一致。
同步程序的顺序一致性
我们接下来看看正确同步的程序如何具有顺序一致性。
class SynchronizedExample {
int a = ;
boolean flag = false;
public synchronized void writer() {
a = ;
flag = true;
}
public synchronized void reader() {
if (flag) {
int i = a;
……
}
}
}
上面示例代码中,假设A线程执行writer()方法后,B线程执行reader()方法。这是一个正确同步的多线程程序。根据JMM规范,该程序的执行结果将与该程序在顺序一致性模型中的执行结果相同。下面是该程序在两个内存模型中的执行时序对比图:
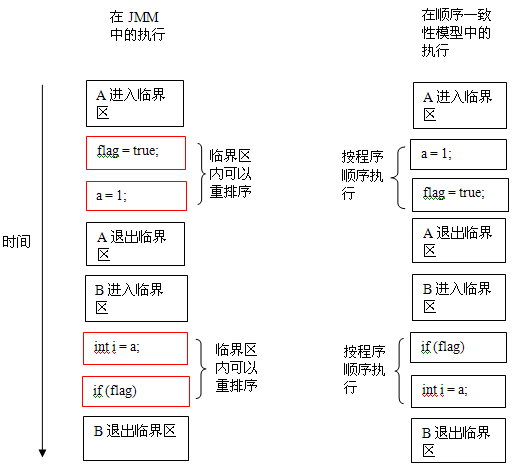
在顺序一致性模型中,所有操作完全按程序的顺序串行执行。而在JMM中,临界区内的代码可以重排序(但JMM不允许临界区内的代码“逸出”到临界区之外,那样会破坏监视器的语义)。JMM会在退出监视器和进入监视器这两个关键时间点做一些特别处理,使得线程在这两个时间点具有与顺序一致性模型相同的内存视图。虽然线程A在临界区内做了重排序,但由于监视器的互斥执行的特性,这里的线程B根本无法“观察”到线程A在临界区内的重排序。这种重排序既提高了执行效率,又没有改变程序的执行结果。
从这里我们可以看到JMM在具体实现上的基本方针:在不改变(正确同步的)程序执行结果的前提下,尽可能的为编译器和处理器的优化打开方便之门。
未同步程序的顺序一致性
JMM不保证未同步程序的执行结果与该程序在顺序一致性模型中的执行结果一致。因为未同步程序在顺序一致性模型中执行时,整体上是无序的,其执行结果无法预知。保证未同步程序在两个模型中的执行结果一致毫无意义。
和顺序一致性模型一样,未同步程序在JMM中的执行时,整体上也是无序的,其执行结果也无法预知。
同时,未同步程序在这两个模型中的执行特性有下面几个差异:
- 顺序一致性模型保证单线程内的操作会按程序的顺序执行,而JMM不保证单线程内的操作会按程序的顺序执行(比如上面正确同步的多线程程序在临界区内的重排序)。
- 顺序一致性模型保证所有线程只能看到一致的操作执行顺序,而JMM不保证所有线程能看到一致的操作执行顺序。
- JMM不保证对64位的long型和double型变量的读/写操作具有原子性,而顺序一致性模型保证对所有的内存读/写操作都具有原子性。
对于第三个差异:在一些32位的处理器上,如果要求对64位数据的读/写操作具有原子性,会有比较大的开销。为了照顾这种处理器,java语言规范鼓励但不强求JVM对64位的long型变量和double型变量的读/写具有原子性。当JVM在这种处理器上运行时,会把一个64位long/ double型变量的读/写操作拆分为两个32位的读/写操作来执行。这两个32位的读/写操作可能会被分配到不同的总线事务中执行,此时对这个64位变量的读/写将不具有原子性。
当单个内存操作不具有原子性,将可能会产生意想不到后果。请看下面示意图:
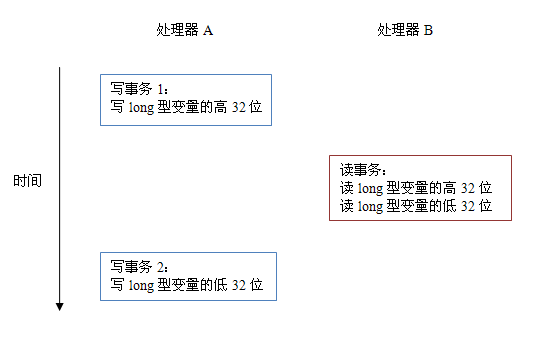
如上图所示,假设处理器A写一个long型变量,同时处理器B要读这个long型变量。处理器A中64位的写操作被拆分为两个32位的写操作,且这两个32位的写操作被分配到不同的写事务中执行。同时处理器B中64位的读操作被拆分为两个32位的读操作,且这两个32位的读操作被分配到同一个的读事务中执行。当处理器A和B按上图的时序来执行时,处理器B将看到仅仅被处理器A“写了一半“的无效值。
Java并发编程(十四)Java内存模型的更多相关文章
- JAVA并发编程的艺术 JMM内存模型
锁的升级和对比 java1.6为了减少获得锁和释放锁带来的性能消耗,引入了"偏向锁"和"轻量级锁". 偏向锁 偏向锁为了解决大部分情况下只有一个线程持有锁的情况 ...
- java并发编程(9)内存模型
JAVA内存模型 在多线程这一系列中,不去探究内存模型的底层 一.什么是内存模型,为什么需要它 在现代多核处理器中,每个处理器都有自己的缓存,定期的与主内存进行协调: 想要确保每个处理器在任意时刻知道 ...
- [Java并发编程(四)] Java volatile 的理论实践
[Java并发编程(四)] Java volatile 的理论实践 摘要 Java 语言中的 volatile 变量可以被看作是一种 "程度较轻的 synchronized":与 ...
- Java并发编程系列-(7) Java线程安全
7. 线程安全 7.1 线程安全的定义 如果多线程下使用这个类,不过多线程如何使用和调度这个类,这个类总是表示出正确的行为,这个类就是线程安全的. 类的线程安全表现为: 操作的原子性 内存的可见性 不 ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
- Java并发编程系列-(6) Java线程池
6. 线程池 6.1 基本概念 在web开发中,服务器需要接受并处理请求,所以会为一个请求来分配一个线程来进行处理.如果每次请求都新创建一个线程的话实现起来非常简便,但是存在一个问题:如果并发的请求数 ...
- Java并发编程:JMM(Java内存模型)和volatile
1. 并发编程的3个概念 并发编程时,要想并发程序正确地执行,必须要保证原子性.可见性和有序性.只要有一个没有被保证,就有可能会导致程序运行不正确. 1.1. 原子性 原子性:即一个或多个操作要么全部 ...
- Java并发编程:JMM (Java内存模型) 以及与volatile关键字详解
目录 计算机系统的一致性 Java内存模型 内存模型的3个重要特征 原子性 可见性 有序性 指令重排序 volatile关键字 保证可见性和防止指令重排 不能保证原子性 计算机系统的一致性 在现代计算 ...
- 【Java并发编程】从CPU缓存模型到JMM来理解volatile关键字
目录 并发编程三大特性 原子性 可见性 有序性 CPU缓存模型是什么 高速缓存为何出现? 缓存一致性问题 如何解决缓存不一致 JMM内存模型是什么 JMM的规定 Java对三大特性的保证 原子性 可见 ...
- JAVA并发编程的艺术 Java并发容器和框架
ConcurrentHashMap ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成. 一个ConcurrentHashMap里包含一个Segment数组, ...
随机推荐
- [WINForm]C#应用程序图标设置问题
在屏幕分辨率大小不一的情况下,应用程序的图标有些电脑显示合适,有些电脑显示在图标中间出现过多空白边距: 处理方式: 1.在vs中打开ico图片 2.在图标空白处右键添加新图像类型 3.选择自己需要的尺 ...
- MySQL 字符集utf8和utf-8的关系
目录 什么是字符集(character set) 校对规则(collation) ASCII码 Unicode国际化支持 UTF-8 utf8 utf8与utf8mb4的关系 超集 字符集设置 什么是 ...
- Mac下命令行批量重命名
日常中碰到需要批量修改文件名怎么办?嗯,来终端先 案例:将Users/case目录下所有html文件修改为php文件 步骤: 1.进入目标文件夹 $ cd Users/case 2.执行以下命令 $ ...
- 【WebAPI No.2】如何WebAPI发布
介绍: Asp.Net Core在Windows上可以采用两种运行方式.一种是自托管运行,另一种是发布到IIS托管运行. 自托管 首先有一个完好的.Net Core WebAPI测试项目,然后进入根目 ...
- 源码安装redis环境
linux下安装redis 1.下载源码,解压包后编译源码: wget http://download.redis.io/releases/redis-2.8.3.tar.gz tar xzf red ...
- Intellij新安装初始化配置
自动编译开关 忽略大小写开关 IDEA默认是匹配大小写,此开关如果未关.你输入字符一定要符合大小写.比如你敲string是不会出现代码提示或智能补充.但是,如果你开了这个开关,你无论输入String或 ...
- Linux_CentOS-服务器搭建 <四>
既然tomcat,弄好了,数据库安装好了.我们考虑考虑下.今天带给大家是, 数据库的还原备份: 备份开始: 登录开始: mysql -u root -p 创建一个测试用的数据库test并创 ...
- 本地k8s环境minikube搭建过程
首先要安装docker这个环境是需要自己安装的.相关步骤如下: 1 2 3 4 5 6 7 8 9 10 11 yum install -y yum-utils device-mapper-persi ...
- Deep learning with Python 学习笔记(10)
生成式深度学习 机器学习模型能够对图像.音乐和故事的统计潜在空间(latent space)进行学习,然后从这个空间中采样(sample),创造出与模型在训练数据中所见到的艺术作品具有相似特征的新作品 ...
- Jenkins持续集成学习-Windows环境进行.Net开发4
目录 Jenkins持续集成学习-Windows环境进行.Net开发4 目录 前言 目标 Github持续集成 提交代码到Github 从Github更新代码 git上显示构建状态 自动触发构建 Gi ...