[druid]大数据挑战——如何使用Druid实现数据聚合
-- 知道你为什么惧组件很多的一些开源软件? 因为缺乏阅读能力.
最近我接手了druid+kafka+elk一套等日志系统. 但是我对druid很陌生, 周旋了几天, 官网文档快速开始照着做了下. 看了这个文章才大概明白套路.
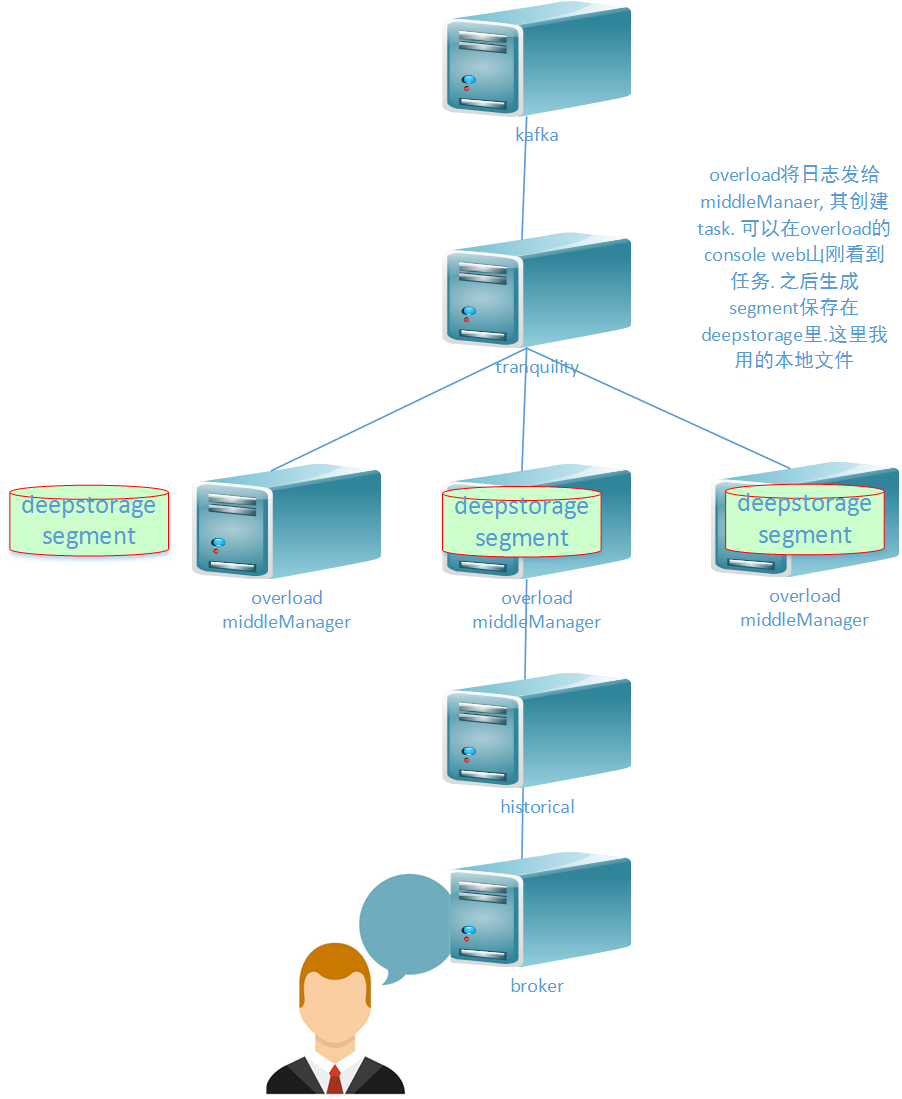
入库: kafka-->tranquility-->overload-->middleManager
查询: broker-->historical-->deepdrive
coordinator是管理segment的(下载删除等)
需要注意的是config/_common里的配置
metadata
zk
deepstorage的配置
deepstorage数据保存多久的配置在 history配置里.
参考: https://cnodejs.org/topic/57918503f0d4b46026ba53db
这个文档写的很棒. 介绍druid
应用性能管理的本质就是通过对业务数据和IT系统性能数据的准确抓取和深度分析,为企业业务和IT的可持续发展提供平台支撑。而云智慧透视宝产品在得到越来越多客户认可的同时,业务数据也在急剧增加,无论是数据存储还是数据查询,都会给原有透视宝架构带来较大压力。
经过反复挑选,云智慧透视宝选择了用于大数据实时查询和分析的高容错、高性能开源分布式系统Druid,接下来就由透视宝开发工程师lucky为我们详细解读,云智慧是如何利用Druid实现数据聚合的。
大数据的挑战—
由于数据量的激增,云智慧透视宝后端数据处理系统主要面临两方面问题:
首先,在数据存储方面,因为系统需要保存所有原始数据,每天十几TB,甚至几十TB的数据量,直接导致了资源需求和运营成本的增加;
其次,在数据查询方面,如果查询是建立在所有原始数据集的基础上,那么对机器的cpu和内存要求就会非常高。
那么Druid会帮我们解决这些问题吗?!答案是肯定的,使用Druid对原始数据进行聚合,会显著的减少数据的存储,同时借鉴搜索架构的思想,Druid创建不变的数据快照,为分析查询提供极优的数据结构来存储,这样会明显提高查询效率。
Druid基本概念—
Druid是一个为大型冷数据集上实时探索查询而设计的开源数据分析和存储系统,提供低延时(实时)的数据接入,灵活的数据探索以及高速的数据聚合(存储和查询)。
保存到Druid的数据由三部分组成:
♦ Timestamp列:数据的时间戳列,所有的查询都是以时间为中心。
♦ Dimension列:数据的维度列,用于过滤数据。
♦ Metric列:数据的聚合列,用于聚合数据,支持包括sum,count,min和max等计算。
接下来为大家介绍Druid的几个基本概念:
♦ 聚合:数据按照时间戳列、维度列、聚合列和聚合粒度进行归并的过程,称之为聚合。
♦ 聚合粒度:接收到多长时间的数据归并为一条,称之为聚合粒度。
♦ Datasource:数据源,相当于关系型数据库里面表的概念。
♦ Segment:Druid用Segment文件保存数据,Segment包含着某个Datasource一段时间内的数据。
♦ Datasource和Segment之间的关系:Segment=Datasource_interval_version_partitionNumber。
从这个关系中不难发现segment也可以分区(partitonNumber),就像kafka的topic一样。其实segment不仅可以分区,并且与kafka的topic一样,也有副本的概念。
下面结合透视宝的业务场景举个例子,消化一下上面的概念:我们在Druid上创建了一个叫做cpu的datasource,他的维度列是account_id(用户唯一标识)和host_id(主机唯一标识),聚合列是cpuUser,cpuSys,cpuIdle和cpuWait,聚合计算包括sum和count,聚合粒度是30分钟。
按照如上的方式对cpu数据进行聚合后,每30分钟一组account_id和host_id只会对应一条数据,这条数据记录了我们每个聚合列的sum值和count值。这样,当我们在查询主机数-最近1天(7天)的cpu数据时,可以在这个聚合结果的基础上再次进行聚合查询。元数据数据量大大减小了,查询效率是不是就提高了!
Druid工作流程—
一个Druid集群有各种类型的节点(Node)组成,每种节点都被设计来做某组事情,这样的设计可以隔离关注并简化整个系统的复杂度。Druid包含如下节点:overlord节点,middlemanager节点,broker节点,historical节点和coordinator节点,在设计时充分考虑到了高可用性,各种节点挂掉都不会使Druid停止工作。
下面简单介绍下Druid不同节点的作用:
overlord节点:接收和分发任务。上面说到了在Druid上创建了一个叫做cpu的datasource,其实暂时可以理解为创建了一个任务,目的是告诉overlord节点这个datasource/任务处理的数据描述(模板)是什么,描述包括数据的维度列,聚合列,聚合粒度,segment生成时间等等参数,任务会按照这个描述对接收到的数据进行聚合。overlord节点接到任务后并不会直接处理任务,而是分发给middlemaanger节点。
middlemanager节点:管理任务。middlemanager接收到overlord分发给他的任务,会继续分发任务,分发给谁呢?分发给peon,这才是真正做聚合任务的同志。
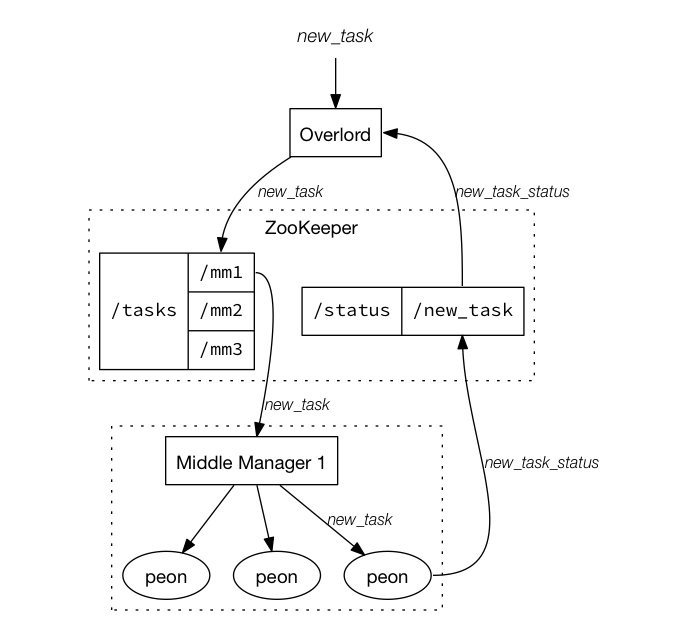
从这张图可以看出overlord是如何分发任务给middlemanager的,通过zookeeper(下面会提到,druid的依赖,一些分布式服务都会依赖它,kafka,hbase等等)。peon完成数据聚合任务后,会生成一个segment文件,并且会将segment文件永久保存到deepstorage,deepstroage也是Druid的一个依赖,Druid依赖deepstorage对segment做永久存储,常用的deepstorage有s3和hdfs。
broker节点:响应外部的查询请求。broker节点会根据请求参数(时间段参数等),决定从哪里获取数据。
historical节点:存储历史数据。broker节点响应外部的查询请求,会从某个或者某些historical节点查询数据(如果没有,从deepstorage加载)。
coordinator节点:管理集群中的Segment操作(下载,删除等)。
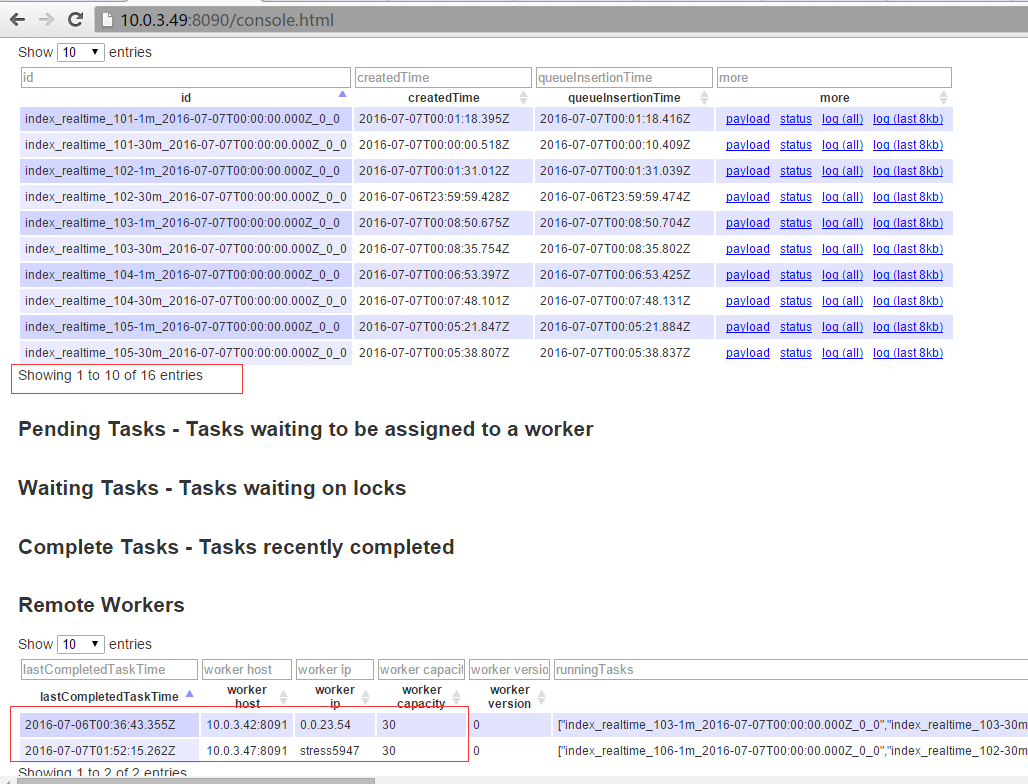
每个节点都提供了很多api,可以通过api查看各个节点的状态信息等,例如查看overlord节点的状态信息,如下图:

另外,还可以通过overlord节点提供的web页面查看任务的状态,以及middlemanager的数量,
和每个middlemanager可以容纳的peon数量等等。
** 下面是官方提供的Druid工作流程图:**
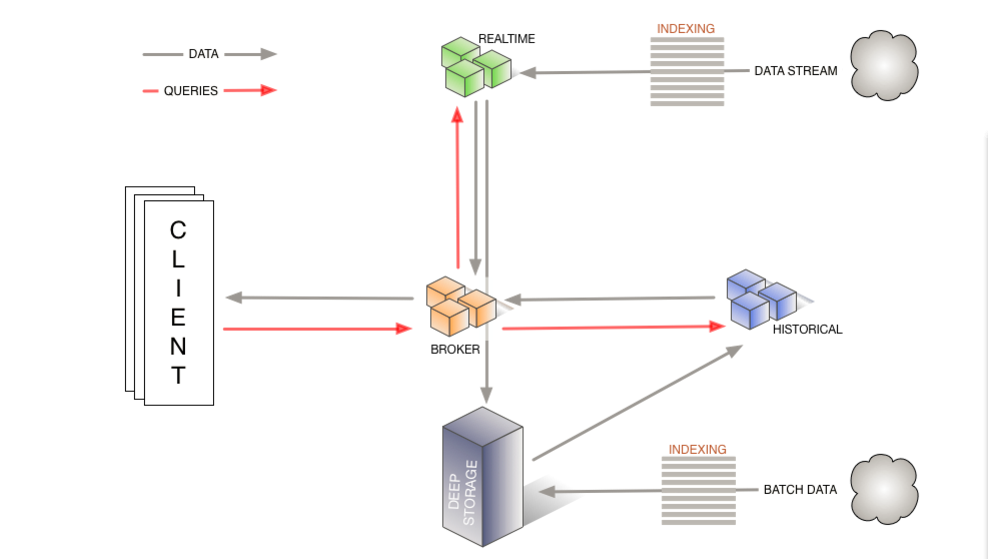
这个流程图中没有画出overlord和middlemaanger节点,图中的realtime节点我们暂时没有用到,云智慧用的是tranquility(a high level data producer library for Druid)。通过我们自己的程序,对数据进行清洗后,借助tranquility发送数据给overlord,看图:
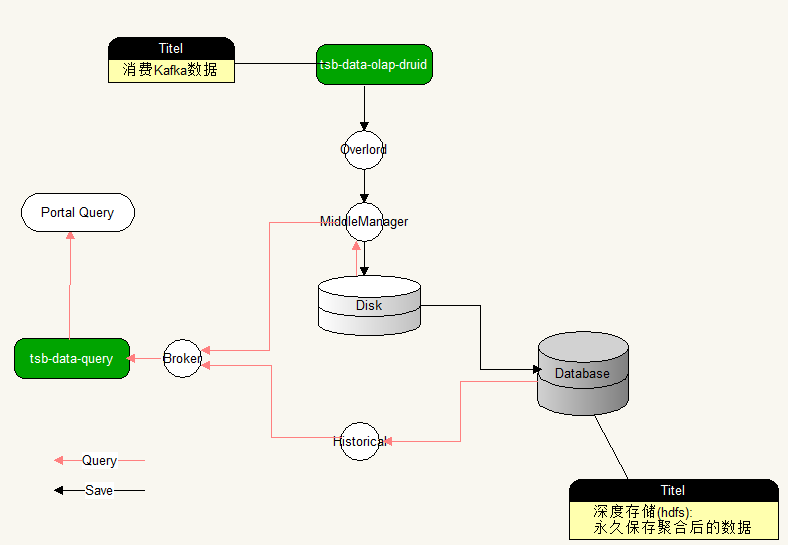
上面对Druid节点做了一下大概的介绍,要想让Druid正常工作,除了运行Druid自身的这些节点外,还需要借助三个依赖。
♦ deepstorage:用来永久存储segment数据,一般是s3和hdfs。
♦ zookeeper:用来管理集群状态,保证集群内的数据统一。
♦ metadata storage:用来保存一些元数据,规则数据,配置数据等。
deepstorage功能很单一不用多说,那么zookeeper和metadata storage在Druid工作流程中,起着什么样的作用呢?以聚合数据和查询数据简单介绍一下zookeeper和metadata storage在Druid中的工作。
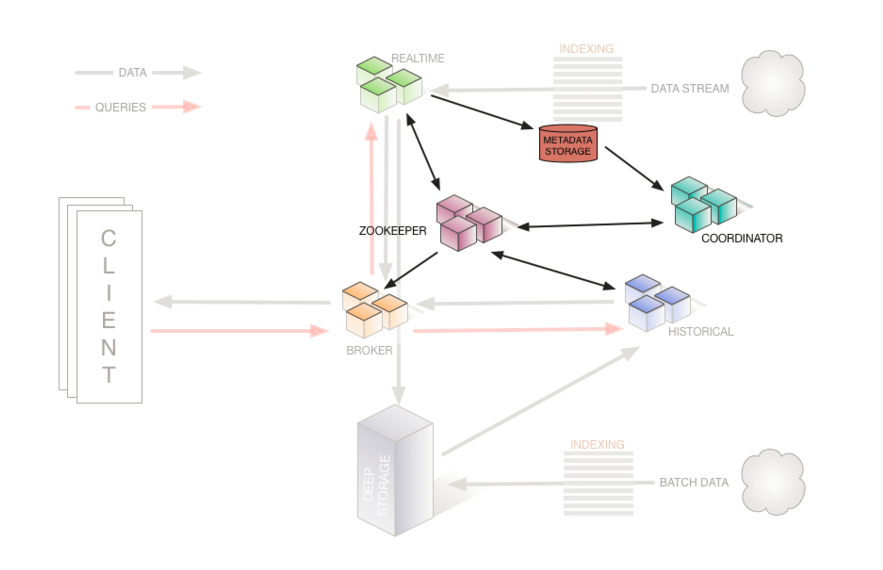
聚合数据: peon在做聚合任务的时候会周期性的告诉zookeeper,正在为哪个datasource,生成哪个时间段的数据,即生成哪个segment,当聚合任务执行完成后,peon会将segment生成到deepstroage,同时会将生成的segment的描述信息保存到metadata storage中,并同时通知zookeeper。
查询数据:broker接收数据的查询请求后,会根据请求参数,通过zookeeper分析请求的segment在哪里:是在peon上(middlemaanger中还没有完全生成一个segment,即热数据/实时数据),还是在某个或者某些历史节点中,分析出结果后分别向对应节点发出请求,获取数据。broker获取各个节点返回过来的数据,再次进行数据归并并最终返回给请求者。
metadata database的作用又是什么呢?peon完成数据聚合后,首先将其保存到deepstorage中,同时会将聚合的产物segment描述信息(在hdfs中的保存路径)保存到metadata database中,并通知zookeeper。注意:Coordinator和historical节点一直和zookeeper保持着连接,Coordinator还和metadata database保持着连接。当Coordinator发现zookeeper上有一个新的segment生成后,会通知historical节点去加载这个数据,通知方式依然是借助zookeeper。
前文说到Coordinator节点管理segment的下载和删除,是发生在聚合数据的过程中,peon完成数据聚合后会通知zookeeper,而Coordinator一直监控着zookeeper,当发现有一个新的segment生成后,会通过zookeeerp通知某个historical节点去下载segment。而删除是因为Historical节点容量是一定的(可配置的),如果超过了容量,他会删除过期数据或旧数据。
Druid官方提供的流程图如下:
Druid在透视宝的作用—
Druid是如何从透视宝接入数据的呢?如下图所示:
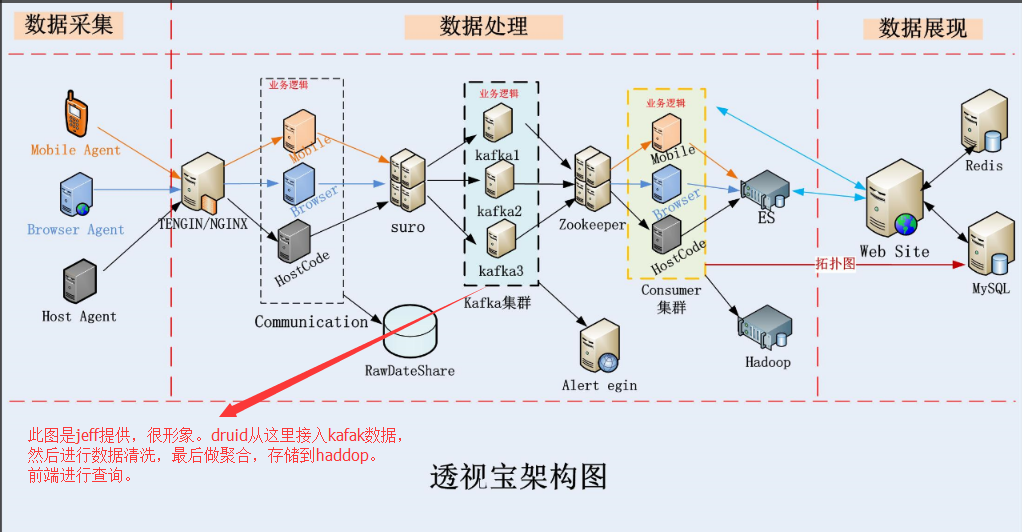
目前,我们有两个服务,一个服务是连接kafka和Druid,即从kafka消费数据发送给Druid。一个是连接broker,并对外提供api,供前端查询数据做报表展示。通过使用Druid,大大节省了透视宝的数据存储的空间,提升了数据查询的效率,更好的满足客户大数据分析的需求。今天的分享也到此结束,希望能给你的工作带来一点帮助。
[druid]大数据挑战——如何使用Druid实现数据聚合的更多相关文章
- Spring+SpringMVC+MyBatis+easyUI整合优化篇(十)数据层优化-整合druid
druid介绍 这是druid对自己的介绍: Druid是阿里开源的一个数据库连接池技术,号称自己是目前最好的数据库连接池,在功能.性能.扩展性方面,都超过其他数据库连接池,包括DBCP.C3P0.B ...
- 【转载】DRuid 大数据分析之查询
转载自http://yangyangmyself.iteye.com/blog/2321759 1.Druid 查询概述 上一节完成数据导入后,接下来讲讲Druid如何查询及统计分析导入的数据 ...
- 转 开启“大数据”时代--大数据挑战与NoSQL数据库技术 iteye
一直觉得“大数据”这个名词离我很近,却又很遥远.最近不管是微博上,还是各种技术博客.论坛,碎碎念大数据概念的不胜枚举. 在我的理解里,从概念理解上来讲,大数据的目的在于更好的数据分析,否则如此大数据的 ...
- NLP数据集大放送,再也不愁数据了!【上百个哦】
奉上100多个按字母顺序排列的开源自然语言处理文本数据集列表(原始未结构化的文本数据),快去按图索骥下载数据自己研究吧! 数据集 Apache软件基金会公开邮件档案:截止到2011年7月11日全部公开 ...
- 【大数据技巧】日均2TB日志数据在线快速处理之法
[大数据技巧]日均2TB日志数据在线快速处理之法 http://click.aliyun.com/m/8958/
- spring+hibernate+jpa+Druid的配置文件,spring整合Druid
spring+hibernate+jpa+Druid的配置文件 spring+hibernate+jpa+Druid的完整配置 spring+hibernate+jpa+Druid的数据源配置 spr ...
- 使用std::map和std::list存放数据,消耗内存比实际数据大得多
使用std::map和std::list存放数据,消耗内存比实际数据大得多 场景:项目中需要存储一个结构,如下程序段中TEST_DATA_STRU,结构占24B.但是使用代码中的std::list&l ...
- 2 python大数据挖掘系列之淘宝商城数据预处理实战
preface 在上一章节我们聊了python大数据分析的基本模块,下面就说说2个项目吧,第一个是进行淘宝商品数据的挖掘,第二个是进行文本相似度匹配.好了,废话不多说,赶紧上车. 淘宝商品数据挖掘 数 ...
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
http://edu.51cto.com/roadmap/view/id-29.html http://my.oschina.net/infiniteSpace/blog/308401 大数据实时计算 ...
随机推荐
- BZOJ-5-4300: 绝世好题-位-DP
思路 :题意描述我也很绝望 .先说一下题意 : 给定长度为n数组a [ ],求a[ ] 的一个最大子序列(可以不连续),使得b [ i ]& b [ i - 1 ] ! = 0.求最大的 b数 ...
- linux命令基础三
使用cat命令进行文件的纵向合并使用cat命令实现文件的纵向合并: 例如:使用cat命令将baby.age.baby.kg和baby.sex这三个文件纵向合并为baby文件的方法:cat baby.a ...
- 橡皮筋进度条ElasticProgressBar
橡皮筋进度条ElasticProgressBar 橡皮筋进度条是一个极具动画效果的进度条.该进度条不仅具有皮筋效果,还带有进度数据显示,让用户可以很清晰的看到当前的进度,可用于下载.加载进度等场景.E ...
- 前缀和的应用 CodeForces - 932B Recursive Queries
题目链接: https://vjudge.net/problem/1377985/origin 题目大意就是要你把一个数字拆开,然后相乘. 要求得数要小于9,否则递归下去. 这里用到一个递归函数: i ...
- BZOJ.4826.[AHOI/HNOI2017]影魔(树状数组/莫队 单调栈)
BZOJ LOJ 洛谷 之前看\(mjt\)用莫队写了,以为是一种正解,码了3h结果在LOJ T了没A= = 心态爆炸(upd:发现是用C++11(NOI)交的,用C++11交就快一倍了...) 深刻 ...
- BZOJ.3784.树上的路径(点分治 贪心 堆)
BZOJ \(Description\) 给定一棵\(n\)个点的带权树,求树上\(\frac{n\times(n-1)}{2}\)条路径中,长度最大的\(m\)条路径的长度. \(n\leq5000 ...
- 嵌入式单片机STM32应用技术(课本)
目录SAIU R20 1 6 第1页第1 章. 初识STM32..................................................................... ...
- 通过Quartz 配置定时调度任务:使用cron表达式配置时间点
Cron官网入口 在后台经常需要一些定时处理的任务,比如微信相关应用所需的access_token,就要定时刷新,官方返回的有效性是7200s,也就是2小时,但是为了保险起见,除了在发现access_ ...
- JDBC连接
jdbc是java中的数据库连接技术,功能非常强大. 数据库访问过程 1.加载数据库驱动 要通过jdbc去访问某数据库必须有相应的JDBC driver 它往往由数据库厂商提供,是链接jdbc API ...
- [Codeforces113C]Double Happiness(数论)
题意 给定闭区间[l,r] [l,r] [l,r],找出区间内满足t=a2+b2 t=a^{2}+b^{2} t=a2+b2的所有素数t t t的个数( a,b a,b a,b为任意正整数). 思路 ...