Linux 驱动开发
linux驱动开发总结(一)
基础性总结
1, linux驱动一般分为3大类:
* 字符设备
* 块设备
* 网络设备
2, 开发环境构建:
* 交叉工具链构建
* NFS和tftp服务器安装
3, 驱动开发中设计到的硬件:
* 数字电路知识
* ARM硬件知识
* 熟练使用万用表和示波器
* 看懂芯片手册和原理图
4, linux内核源代码目录结构:
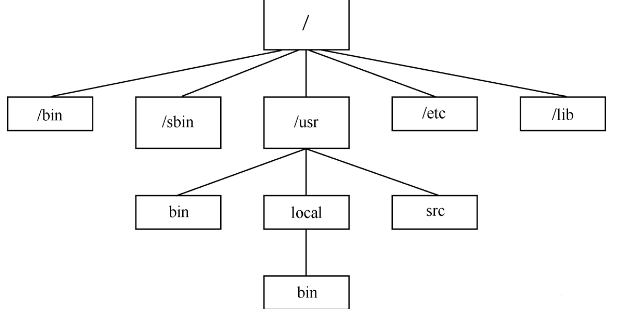
* arch/: arch子目录包括了所有和体系结构相关的核心代码。它的每一个子目录都代表一种支持的体系结构,例如i386就是关于intel cpu及与之相兼容体系结构的子目录。
* block/: 部分块设备驱动程序;
* crypto: 常用加密和散列算法(如AES、SHA等),还有一些压缩和CRC校验算法;
* documentation/: 文档目录,没有内核代码,只是一套有用的文档;
* drivers/: 放置系统所有的设备驱动程序;每种驱动程序又各占用一个子目录:如,/block
下为块设备驱动程序,比如ide(ide.c)。如果你希望查看所有可能包含文件系统的设备是如何初始化的,你可以看
drivers/block/genhd.c中的device_setup()。
* fs/: 所有的文件系统代码和各种类型的文件操作代码,它的每一个子目录支持一个文件系统, 例如fat和ext2;
* include/: include子目录包括编译核心所需要的大部分头文件。与平台无关的头文件在 include/linux子目录下,与
intel cpu相关的头文件在include/asm-i386子目录下,而include/scsi目录则是有关scsi设备的头文件目录;
* init/: 这个目录包含核心的初始化代码(注:不是系统的引导代码),包含两个文件main.c和Version.c,这是研究核心如何工作的好的起点之一;
* ipc/: 这个目录包含核心的进程间通讯的代码;
* kernel/: 主要的核心代码,此目录下的文件实现了大多数linux系统的内核函数,其中最重要的文件当属sched.c;同样,和体系结构相关的代码在arch/i386/kernel下;
* lib/: 放置核心的库代码;
* mm/:这个目录包括所有独立于 cpu 体系结构的内存管理代码,如页式存储管理内存的分配和释放等;而和体系结构相关的内存管理代码则位于arch/i386/mm/下;
* net/: 核心与网络相关的代码;
* scripts/: 描述文件,脚本,用于对核心的配置;
* security: 主要是一个SELinux的模块;
* sound: 常用音频设备的驱动程序等;
* usr: 实现了用于打包和压缩的cpio;
5, 内核的五个子系统:
* 进程调试(SCHED)
* 内存管理(MM)
* 虚拟文件系统(VFS)
* 网络接口(NET)
* 进程间通信(IPC)
6, linux内核的编译:
* 配置内核:make menuconfig,使用后会生成一个.confiig配置文件,记录哪些部分被编译入内核,哪些部分被编译成内核模块。
* 编译内核和模块的方法:make zImage
Make modules
* 执行完上述命令后,在arch/arm/boot/目录下得到压缩的内核映像zImage,在内核各对应目录得到选中的内核模块。
7, 在linux内核中增加程序
(直接编译进内核)要完成以下3项工作:
* 将编写的源代码拷入linux内核源代码相应目录
* 在目录的Kconifg文件中增加关于新源代码对应项目的编译配置选项
* 在目录的Makefile文件中增加对新源代码的编译条目
8, linux下C编程的特点:
内核下的Documentation/CodingStyle描述了linux内核对编码风格的要求。具体要求不一一列举,以下是要注意的:
* 代码中空格的应用
* 当前函数名:
GNU C预定义了两个标志符保存当前函数的名字,__FUNCTION__保存函数在源码中的名字,__PRETTY_FUNCTION__保存带语言特色的名字。
由于C99已经支持__func__宏,在linux编程中应该不要使用__FUNCTION__,应该使用__func__。
*内建函数:不属于库函数的其他内建函数的命名通常以__builtin开始。
9,内核模块
内核模块主要由如下几部分组成:
(1) 模块加载函数
(2) 模块卸载函数
(3) 模块许可证声明(常用的有Dual BSD/GPL,GPL,等)
(4) 模块参数(可选)它指的是模块被加载的时候可以传递给它的值,它本身对应模块内部的全局变量。例如P88页中讲到的一个带模块参数的例子:
insmod book.ko book_name=”GOOD BOOK” num=5000
(5) 模块导出符号(可选)导出的符号可以被其他模块使用,在使用之前只需声明一下。
(6) 模块作者等声明信息(可选)
以下是一个典型的内核模块:
/*
* A kernel module: book
* This example is to introduce module params
*
* The initial developer of the original code is Baohua Song
* <author@linuxdriver.cn>. All Rights Reserved.
*/
#include <linux/init.h>
#include <linux/module.h>
static char *book_name = “dissecting Linux Device Driver”;
static int num = 4000;
static int book_init(void)
{
printk(KERN_INFO “ book name:%s\n”,book_name);
printk(KERN_INFO “ book num:%d\n”,num);
return 0;
}
static void book_exit(void)
{
printk(KERN_INFO “ Book module exit\n “);
}
module_init(book_init);
module_exit(book_exit);
module_param(num, int, S_IRUGO);
module_param(book_name, charp, S_IRUGO);
MODULE_AUTHOR(“Song Baohua, author@linuxdriver.cn”);
MODULE_LICENSE(“Dual BSD/GPL”);
MODULE_DESCRIPTION(“A simple Module for testing module params”);
MODULE_VERSION(“V1.0”);注意:标有__init的函数在链接的时候都放在.init.text段,在.initcall.init中还保存了一份函数指针,初始化的时候内核会通过这些函数指针调用__init函数,在初始化完成后释放init区段。
模块编译常用模版:
KVERS = $(shell uname -r)
# Kernel modules
obj-m += book.o
# Specify flags for the module compilation.
#EXTRA_CFLAGS=-g -O0
build: kernel_modules
kernel_modules:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) modules
clean:
make -C /lib/modules/$(KVERS)/build M=$(CURDIR) clean注意要指明内核版本,并且内核版本要匹配——编译模块使用的内核版本要和模块欲加载到的那个内核版本要一致。
模块中经常使用的命令:
insmod,lsmod,rmmod
系统调用:
int open(const char *pathname,int flags,mode_t mode);
flag表示文件打开标志,如:O_RDONLY
mode表示文件访问权限,如:S_IRUSR(用户可读),S_IRWXG(组可以读、写、执行)
10,linux文件系统与设备驱动的关系
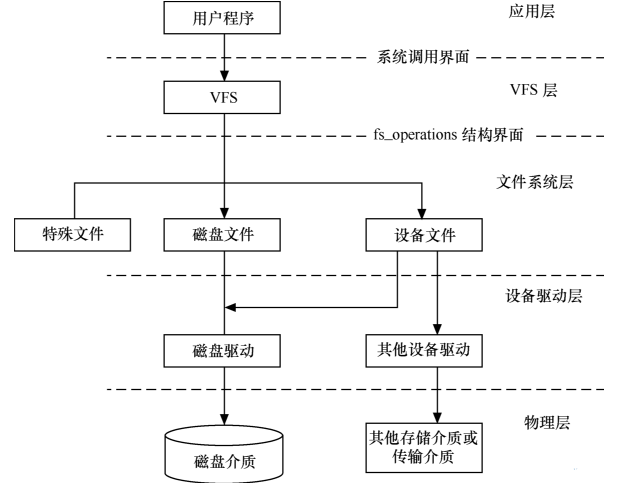
应用程序和VFS之间的接口是系统调用,而VFS与磁盘文件系统以及普通设备之间的接口是file_operation结构体成员函数。
两个重要的函数:
(1)struct file结构体定义在/linux/include/linux/fs.h(Linux
2.6.11内核)中定义。文件结构体代表一个打开的文件,系统中每个打开的文件在内核空间都有一个关联的struct
file。它由内核在打开文件时创建,并传递给在文件上进行操作的任何函数。在文件的所有实例都关闭后,内核释放这个数据结构。在内核创建和驱动源码中,struct
file的指针通常被命名为file或filp。
在驱动开发中,文件读/写模式mode、标志f_flags都是设备驱动关心的内容,而私有数据指针private_data在驱动中被广泛使用,大多被指向设备驱动自定义的用于描述设备的结构体。驱动程序中常用如下类似的代码来检测用户打开文件的读写方式:
if (file->f_mode & FMODE_WRITE) //用户要求可写
{
}
if (file->f_mode & FMODE_READ) //用户要求可读
{
}下面的代码可用于判断以阻塞还是非阻塞方式打开设备文件:
if (file->f_flags & O_NONBLOCK) //非阻塞
pr_debug("open:non-blocking\n");
else //阻塞
pr_debug("open:blocking\n");(2)struct inode结构体定义在linux/fs.h中
11,devfs、sysfs、udev三者的关系:
(1)devfs
linux下有专门的文件系统用来对设备进行管理,devfs和sysfs就是其中两种。在2.4内核4一直使用的是devfs,devfs挂载于/dev目录下,提供了一种类似于文件的方法来管理位于/dev目录下的所有设备,我们知道/dev目录下的每一个文件都对应的是一个设备,至于当前该设备存在与否先且不论,而且这些特殊文件是位于根文件系统上的,在制作文件系统的时候我们就已经建立了这些设备文件,因此通过操作这些特殊文件,可以实现与内核进行交互。但是devfs文件系统有一些缺点,例如:不确定的设备映射,有时一个设备映射的设备文件可能不同,例如我的U盘可能对应sda有可能对应sdb;没有足够的主/次设备号,当设备过多的时候,显然这会成为一个问题;/dev目录下文件太多而且不能表示当前系统上的实际设备;命名不够灵活,不能任意指定等等。
(2)sysfs
正因为上述这些问题的存在,在linux2.6内核以后,引入了一个新的文件系统sysfs,它挂载于/sys目录下,跟devfs一样它也是一个虚拟文件系统,也是用来对系统的设备进行管理的,它把实际连接到系统上的设备和总线组织成一个分级的文件,用户空间的程序同样可以利用这些信息以实现和内核的交互,该文件系统是当前系统上实际设备树的一个直观反应,它是通过kobject子系统来建立这个信息的,当一个kobject被创建的时候,对应的文件和目录也就被创建了,位于/sys下的相关目录下,既然每个设备在sysfs中都有唯一对应的目录,那么也就可以被用户空间读写了。用户空间的工具udev就是利用了sysfs提供的信息来实现所有devfs的功能的,但不同的是udev运行在用户空间中,而devfs却运行在内核空间,而且udev不存在devfs那些先天的缺陷。
(3)udev
udev是一种工具,它能够根据系统中的硬件设备的状况动态更新设备文件,包括设备文件的创建,删除等。设备文件通常放在/dev目录下,使用udev后,在/dev下面只包含系统中真实存在的设备。它于硬件平台无关的,位于用户空间,需要内核sysfs和tmpfs的支持,sysfs为udev提供设备入口和uevent通道,tmpfs为udev设备文件提供存放空间。
12,linux设备模型:
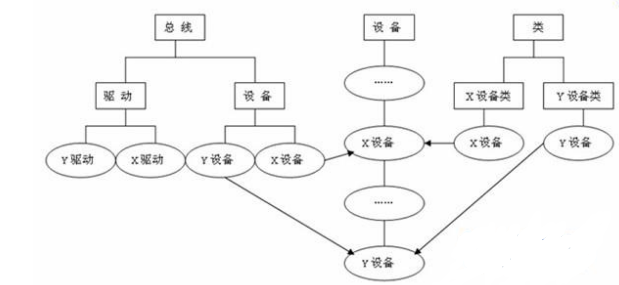
在linux内核中,分别使用bus_type,device_driver,device来描述总线、驱动和设备,这3个结构体定义于include/linux/device.h头文件中。驱动和设备正是通过bus_type中的match()函数来配对的。
13, 重要结构体解析
(1)cdev结构体
在linux2.6内核中,使用cdev结构体描述一个字符设备,定义如下:
struct cdev{
struct kobject kobj;//内嵌的kobject对象
struct module *owner;//所属模块
struct file_operations *ops;//文件操作结构体
struct list_head list;
dev_t dev;//设备号,长度为32位,其中高12为主设备号,低20位为此设备号
unsigned int count;
};(2)file_operations结构体
结构体file_operations在头文件linux/fs.h中定义,用来存储驱动内核模块提供的对设备进行各种操作的函数的指针。这些函数实际会在应用程序进行linux的open(),write(),read(),close()等系统调用时最终被调用。该结构体的每个域都对应着驱动内核模块用来处理某个被请求的事务的函数地址。源代码(2.6.28.7)如下:
struct file_operations{
struct module*owner;
loff_t (*llseek)(struct file*,loff_t,int);
ssize_t (*read)(struct file*,char__user*,size_t,loff_t*);
ssize_t (*write)(struct file*,constchar__user*,size_t,loff_t*);
ssize_t (*aio_read)(struct kiocb*,cons tstruct iovec*,unsigned long,loff_t);
ssize_t (*aio_write)(struct kiocb*,const struct iovec*,unsigned long,loff_t);
int (*readdir)(struct file*,void*,filldir_t);
unsigned int (*poll)(struct file*,struct poll_table_struct*);
int (*ioctl)(struc inode*,struct file*,unsigned int,unsigned long);
long (*unlocked_ioctl)(struct file*,unsigned int,unsigned long);
long (*compat_ioctl)(struct file*,unsigned int,unsigned long);
int (*mmap)(struct file*,struct vm_area_struct*);
int (*open)(struct inode*,struct file*);
int (*flush)(struct file*,fl_owner_t id);
int (*release)(struct inode*,struct file*);
int (*fsync)(struct file*,struct dentry*,int datasync);
int (*aio_fsync)(struct kiocb*,int datasync);
in (*fasync)(int,struct file*,int);
int (*lock)(struct file*,int,struct file_lock*);
ssize_t (*sendpage)(struct file*,struct page*,int,size_t,loff_t*,int);
unsigned long (*get_unmapped_area)(struct file*,unsigned long,unsigned long,unsigned long,unsigned long);
in t(*check_flags)(int);
int (*dir_notify)(structfile*filp,unsignedlongarg);
int (*flock)(structfile*,int,structfile_lock*);
ssize_t (*splice_write)(struct pipe_inode_info*,struct file*,loff_t*,size_t,unsig ned int);
ssize_t (*splice_read)(struct file*,loff_t*,struct pipe_inode_info*,size_t,unsigned int);
int(*setlease)(struct file*,long,struct file_lock**);
}; 解析:
struct module*owner;
/*第一个file_operations成员根本不是一个操作;它是一个指向拥有这个结构的模块的指针.
这个成员用来在它的操作还在被使用时阻止模块被卸载.几乎所有时间中,它被简单初始化为
THIS_MODULE,一个在中定义的宏.这个宏比较复杂,在进行简单学习操作的时候,一般初始化为THIS_MODULE。*/
loff_t (*llseek)(struct file*filp,loff_tp,int orig);
/*(指针参数filp为进行读取信息的目标文件结构体指针;参数p为文件定位的目标偏移量;参数orig为对文件定位
的起始地址,这个值可以为文件开头(SEEK_SET,0,当前位置(SEEK_CUR,1),文件末尾(SEEK_END,2))
llseek方法用作改变文件中的当前读/写位置,并且新位置作为(正的)返回值.
loff_t参数是一个"longoffset",并且就算在32位平台上也至少64位宽.错误由一个负返回值指示.
如果这个函数指针是NULL,seek调用会以潜在地无法预知的方式修改file结构中的位置计数器(在"file结构"一节中描述).*/
ssize_t (*read)(struct file *filp,char__user *buffer,size_t size,loff_t *p);
/*(指针参数filp为进行读取信息的目标文件,指针参数buffer为对应放置信息的缓冲区(即用户空间内存地址),
参数size为要读取的信息长度,参数p为读的位置相对于文件开头的偏移,在读取信息后,这个指针一般都会移动,移动的值为要读取信息的长度值)
这个函数用来从设备中获取数据.在这个位置的一个空指针导致read系统调用以-EINVAL("Invalidargument")失败.
一个非负返回值代表了成功读取的字节数(返回值是一个"signedsize"类型,常常是目标平台本地的整数类型).*/
ssize_t (*aio_read)(struct kiocb*,char__user *buffer,size_t size,loff_t p);
/*可以看出,这个函数的第一、三个参数和本结构体中的read()函数的第一、三个参数是不同的,
异步读写的第三个参数直接传递值,而同步读写的第三个参数传递的是指针,因为AIO从来不需要改变文件的位置。
异步读写的第一个参数为指向kiocb结构体的指针,而同步读写的第一参数为指向file结构体的指针,每一个I/O请求都对应一个kiocb结构体);
初始化一个异步读--可能在函数返回前不结束的读操作.如果这个方法是NULL,所有的操作会由read代替进行(同步地).
(有关linux异步I/O,可以参考有关的资料,《linux设备驱动开发详解》中给出了详细的解答)*/
ssize_t (*write)(struct file*filp,const char__user *buffer,size_t count,loff_t *ppos);
/*(参数filp为目标文件结构体指针,buffer为要写入文件的信息缓冲区,count为要写入信息的长度,
ppos为当前的偏移位置,这个值通常是用来判断写文件是否越界)
发送数据给设备.如果NULL,-EINVAL返回给调用write系统调用的程序.如果非负,返回值代表成功写的字节数.
(注:这个操作和上面的对文件进行读的操作均为阻塞操作)*/
ssize_t (*aio_write)(struct kiocb*,const char__user *buffer,size_t count,loff_t *ppos);
/*初始化设备上的一个异步写.参数类型同aio_read()函数;*/
int (*readdir)(struct file*filp,void*,filldir_t);
/*对于设备文件这个成员应当为NULL;它用来读取目录,并且仅对文件系统有用.*/
unsigned int(*poll)(struct file*,struct poll_table_struct*);
/*(这是一个设备驱动中的轮询函数,第一个参数为file结构指针,第二个为轮询表指针)
这个函数返回设备资源的可获取状态,即POLLIN,POLLOUT,POLLPRI,POLLERR,POLLNVAL等宏的位“或”结果。
每个宏都表明设备的一种状态,如:POLLIN(定义为0x0001)意味着设备可以无阻塞的读,POLLOUT(定义为0x0004)意味着设备可以无阻塞的写。
(poll方法是3个系统调用的后端:poll,epoll,和select,都用作查询对一个或多个文件描述符的读或写是否会阻塞.
poll方法应当返回一个位掩码指示是否非阻塞的读或写是可能的,并且,可能地,提供给内核信息用来使调用进程睡眠直到I/O变为可能.
如果一个驱动的poll方法为NULL,设备假定为不阻塞地可读可写.
(这里通常将设备看作一个文件进行相关的操作,而轮询操作的取值直接关系到设备的响应情况,可以是阻塞操作结果,同时也可以是非阻塞操作结果)*/
int (*ioctl)(struct inode*inode,struct file*filp,unsigned int cmd,unsigned long arg);
/*(inode和filp指针是对应应用程序传递的文件描述符fd的值,和传递给open方法的相同参数.
cmd参数从用户那里不改变地传下来,并且可选的参数arg参数以一个unsignedlong的形式传递,不管它是否由用户给定为一个整数或一个指针.
如果调用程序不传递第3个参数,被驱动操作收到的arg值是无定义的.
因为类型检查在这个额外参数上被关闭,编译器不能警告你如果一个无效的参数被传递给ioctl,并且任何关联的错误将难以查找.)
ioctl系统调用提供了发出设备特定命令的方法(例如格式化软盘的一个磁道,这不是读也不是写).另外,几个ioctl命令被内核识别而不必引用fops表.
如果设备不提供ioctl方法,对于任何未事先定义的请求(-ENOTTY,"设备无这样的ioctl"),系统调用返回一个错误.*/
int(*mmap)(struct file*,struct vm_area_struct*);
/*mmap用来请求将设备内存映射到进程的地址空间.如果这个方法是NULL,mmap系统调用返回-ENODEV.
(如果想对这个函数有个彻底的了解,那么请看有关“进程地址空间”介绍的书籍)*/
int(*open)(struct inode *inode,struct file *filp);
/*(inode为文件节点,这个节点只有一个,无论用户打开多少个文件,都只是对应着一个inode结构;
但是filp就不同,只要打开一个文件,就对应着一个file结构体,file结构体通常用来追踪文件在运行时的状态信息)
尽管这常常是对设备文件进行的第一个操作,不要求驱动声明一个对应的方法.如果这个项是NULL,设备打开一直成功,但是你的驱动不会得到通知.
与open()函数对应的是release()函数。*/
int(*flush)(struct file*);
/*flush操作在进程关闭它的设备文件描述符的拷贝时调用;它应当执行(并且等待)设备的任何未完成的操作.
这个必须不要和用户查询请求的fsync操作混淆了.当前,flush在很少驱动中使用;
SCSI磁带驱动使用它,例如,为确保所有写的数据在设备关闭前写到磁带上.如果flush为NULL,内核简单地忽略用户应用程序的请求.*/
int(*release)(struct inode*,struct file*);
/*release()函数当最后一个打开设备的用户进程执行close()系统调用的时候,内核将调用驱动程序release()函数:
void release(struct inode inode,struct file *file),release函数的主要任务是清理未结束的输入输出操作,释放资源,用户自定义排他标志的复位等。
在文件结构被释放时引用这个操作.如同open,release可以为NULL.*/
int (*synch)(struct file*,struct dentry*,intdatasync);
//刷新待处理的数据,允许进程把所有的脏缓冲区刷新到磁盘。
int(*aio_fsync)(struct kiocb*,int);
/*这是fsync方法的异步版本.所谓的fsync方法是一个系统调用函数。系统调用fsync
把文件所指定的文件的所有脏缓冲区写到磁盘中(如果需要,还包括存有索引节点的缓冲区)。
相应的服务例程获得文件对象的地址,并随后调用fsync方法。通常这个方法以调用函数__writeback_single_inode()结束,
这个函数把与被选中的索引节点相关的脏页和索引节点本身都写回磁盘。*/
int(*fasync)(int,struct file*,int);
//这个函数是系统支持异步通知的设备驱动,下面是这个函数的模板:
static int***_fasync(intfd,structfile*filp,intmode)
{
struct***_dev*dev=filp->private_data;
returnfasync_helper(fd,filp,mode,&dev->async_queue);//第四个参数为fasync_struct结构体指针的指针。
//这个函数是用来处理FASYNC标志的函数。(FASYNC:表示兼容BSD的fcntl同步操作)当这个标志改变时,驱动程序中的fasync()函数将得到执行。
}
/*此操作用来通知设备它的FASYNC标志的改变.异步通知是一个高级的主题,在第6章中描述.
这个成员可以是NULL如果驱动不支持异步通知.*/
int (*lock)(struct file*,int,struct file_lock*);
//lock方法用来实现文件加锁;加锁对常规文件是必不可少的特性,但是设备驱动几乎从不实现它.
ssize_t (*readv)(structfile*,const struct iovec*,unsigned long,loff_t*);
ssize_t (*writev)(struct file*,const struct iovec*,unsigned long,loff_t*);
/*这些方法实现发散/汇聚读和写操作.应用程序偶尔需要做一个包含多个内存区的单个读或写操作;
这些系统调用允许它们这样做而不必对数据进行额外拷贝.如果这些函数指针为NULL,read和write方法被调用(可能多于一次).*/
ssize_t (*sendfile)(struct file*,loff_t*,size_t,read_actor_t,void*);
/*这个方法实现sendfile系统调用的读,使用最少的拷贝从一个文件描述符搬移数据到另一个.
例如,它被一个需要发送文件内容到一个网络连接的web服务器使用.设备驱动常常使sendfile为NULL.*/
ssize_t (*sendpage)(structfile*,structpage*,int,size_t,loff_t*,int);
/*sendpage是sendfile的另一半;它由内核调用来发送数据,一次一页,到对应的文件.设备驱动实际上不实现sendpage.*/
unsigned long(*get_unmapped_area)(struct file*,unsigned long,unsignedlong,unsigned long,unsigned long);
/*这个方法的目的是在进程的地址空间找一个合适的位置来映射在底层设备上的内存段中.
这个任务通常由内存管理代码进行;这个方法存在为了使驱动能强制特殊设备可能有的任何的对齐请求.大部分驱动可以置这个方法为NULL.[10]*/
int (*check_flags)(int)
//这个方法允许模块检查传递给fnctl(F_SETFL...)调用的标志.
int (*dir_notify)(struct file*,unsigned long);
//这个方法在应用程序使用fcntl来请求目录改变通知时调用.只对文件系统有用;驱动不需要实现dir_notify.14, 字符设备驱动程序设计基础
主设备号和次设备号(二者一起为设备号):
一个字符设备或块设备都有一个主设备号和一个次设备号。主设备号用来标识与设备文件相连的驱动程序,用来反映设备类型。次设备号被驱动程序用来辨别操作的是哪个设备,用来区分同类型的设备。
linux内核中,设备号用dev_t来描述,2.6.28中定义如下:
typedef u_long dev_t;在32位机中是4个字节,高12位表示主设备号,低12位表示次设备号。
可以使用下列宏从dev_t中获得主次设备号:也可以使用下列宏通过主次设备号生成dev_t:
MAJOR(dev_tdev);
MKDEV(intmajor,intminor);
MINOR(dev_tdev);分配设备号(两种方法):
(1)静态申请:
int register_chrdev_region(dev_t from,unsigned count,const char *name);
(2)动态分配:
int alloc_chrdev_region(dev_t *dev,unsigned baseminor,unsigned count,const char *name);
注销设备号:
void unregister_chrdev_region(dev_t from,unsigned count);
创建设备文件:
利用cat/proc/devices查看申请到的设备名,设备号。
(1)使用mknod手工创建:mknod filename type major minor
(2)自动创建;
利用udev(mdev)来实现设备文件的自动创建,首先应保证支持udev(mdev),由busybox配置。在驱动初始化代码里调用class_create为该设备创建一个class,再为每个设备调用device_create创建对应的设备。
15, 字符设备驱动程序设计
设备注册:
字符设备的注册分为三个步骤:
(1)分配
cdev:struct cdev *cdev_alloc(void);
(2)初始化
cdev:void cdev_init(struct cdev *cdev,const struct file_operations *fops);
(3)添加
cdev:int cdev_add(struct cdev *p,dev_t dev,unsigned count)
设备操作的实现:
file_operations函数集的实现。
struct file_operations xxx_ops={
.owner=THIS_MODULE,
.llseek=xxx_llseek,
.read=xxx_read,
.write=xxx_write,
.ioctl=xxx_ioctl,
.open=xxx_open,
.release=xxx_release,
…
};特别注意:驱动程序应用程序的数据交换:
驱动程序和应用程序的数据交换是非常重要的。file_operations中的read()和write()函数,就是用来在驱动程序和应用程序间交换数据的。通过数据交换,驱动程序和应用程序可以彼此了解对方的情况。但是驱动程序和应用程序属于不同的地址空间。驱动程序不能直接访问应用程序的地址空间;同样应用程序也不能直接访问驱动程序的地址空间,否则会破坏彼此空间中的数据,从而造成系统崩溃,或者数据损坏。安全的方法是使用内核提供的专用函数,完成数据在应用程序空间和驱动程序空间的交换。这些函数对用户程序传过来的指针进行了严格的检查和必要的转换,从而保证用户程序与驱动程序交换数据的安全性。这些函数有:
unsigned long copy_to_user(void__user *to,const void *from,unsigned long n);
unsigned long copy_from_user(void *to,constvoid __user *from,unsigned long n);
put_user(local,user);
get_user(local,user);设备注销:
void cdev_del(struct cdev *p);
16,ioctl函数说明
ioctl是设备驱动程序中对设备的I/O通道进行管理的函数。所谓对I/O通道进行管理,就是对设备的一些特性进行控制,例如串口的传输波特率、马达的转速等等。它的调用个数如下:
int ioctl(int fd,ind cmd,…);
其中fd就是用户程序打开设备时使用open函数返回的文件标示符,cmd就是用户程序对设备的控制命令,后面的省略号是一些补充参数,有或没有是和cmd的意义相关的。
ioctl函数是文件结构中的一个属性分量,就是说如果你的驱动程序提供了对ioctl的支持,用户就可以在用户程序中使用ioctl函数控制设备的I/O通道。
命令的组织是有一些讲究的,因为我们一定要做到命令和设备是一一对应的,这样才不会将正确的命令发给错误的设备,或者是把错误的命令发给正确的设备,或者是把错误的命令发给错误的设备。
所以在Linux核心中是这样定义一个命令码的:
| 设备类型 | 序列号 | 方向 | 数据尺寸 |
|---|---|---|---|
| 8bit | 8bit | 2bit | 13~14bit |
这样一来,一个命令就变成了一个整数形式的命令码。但是命令码非常的不直观,所以LinuxKernel中提供了一些宏,这些宏可根据便于理解的字符串生成命令码,或者是从命令码得到一些用户可以理解的字符串以标明这个命令对应的设备类型、设备序列号、数据传送方向和数据传输尺寸。
点击(此处)折叠或打开
/*used to create numbers*/
#define _IO(type,nr) _IOC(_IOC_NONE,(type),(nr),0)
#define _IOR(type,nr,size) _IOC(_IOC_READ,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOW(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#define _IOWR(type,nr,size) _IOC(_IOC_READ|_IOC_WRITE,(type),(nr),(_IOC_TYPECHECK(size)))
#defin e_IOR_BAD(type,nr,size) _IOC(_IOC_READ,(type),(nr),sizeof(size))
#define _IOW_BAD(type,nr,size) _IOC(_IOC_WRITE,(type),(nr),sizeof(size))
#define _IOWR_BAD(type,nr,size)_IOC(_IOC_READ|_IOC_WRITE,(type),(nr),sizeof(size))
#define _IOC(dir,type,nr,size)\
(((dir)<<_IOC_DIRSHIFT)|\
((type)<<_IOC_TYPESHIFT)|\
((nr)<<_IOC_NRSHIFT)|\
((size)<<_IOC_SIZESHIFT))17,文件私有数据
大多数linux的驱动工程师都将文件私有数据private_data指向设备结构体,read等个函数通过调用private_data来访问设备结构体。这样做的目的是为了区分子设备,如果一个驱动有两个子设备(次设备号分别为0和1),那么使用private_data就很方便。
这里有一个函数要提出来:
container_of(ptr,type,member)//通过结构体成员的指针找到对应结构体的的指针
其定义如下:
/**
*container_of-castamemberofastructureouttothecontainingstructure
*@ptr: thepointertothemember.
*@type: thetypeofthecontainerstructthisisembeddedin.
*@member: thenameofthememberwithinthestruct.
*
*/
#define container_of(ptr,type,member)({ \
const typeof(((type*)0)->member)*__mptr=(ptr); \
(type*)((char*)__mptr-offsetof(type,member));})18,字符设备驱动的结构
可以概括如下图:
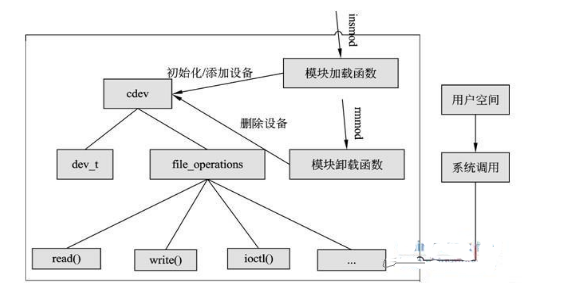
字符设备是3大类设备(字符设备、块设备、网络设备)中较简单的一类设备,其驱动程序中完成的主要工作是初始化、添加和删除cdev结构体,申请和释放设备号,以及填充file_operation结构体中操作函数,并实现file_operations结构体中的read()、write()、ioctl()等重要函数。如图所示为cdev结构体、file_operations和用户空间调用驱动的关系。
19, 自旋锁与信号量
为了避免并发,防止竞争。内核提供了一组同步方法来提供对共享数据的保护。我们的重点不是介绍这些方法的详细用法,而是强调为什么使用这些方法和它们之间的差别。
Linux使用的同步机制可以说从2.0到2.6以来不断发展完善。从最初的原子操作,到后来的信号量,从大内核锁到今天的自旋锁。这些同步机制的发展伴随Linux从单处理器到对称多处理器的过度;伴随着从非抢占内核到抢占内核的过度。锁机制越来越有效,也越来越复杂。目前来说内核中原子操作多用来做计数使用,其它情况最常用的是两种锁以及它们的变种:一个是自旋锁,另一个是信号量。
自旋锁
自旋锁是专为防止多处理器并发而引入的一种锁,它在内核中大量应用于中断处理等部分(对于单处理器来说,防止中断处理中的并发可简单采用关闭中断的方式,不需要自旋锁)。
自旋锁最多只能被一个内核任务持有,如果一个内核任务试图请求一个已被争用(已经被持有)的自旋锁,那么这个任务就会一直进行忙循环——旋转——等待锁重新可用。要是锁未被争用,请求它的内核任务便能立刻得到它并且继续进行。自旋锁可以在任何时刻防止多于一个的内核任务同时进入临界区,因此这种锁可有效地避免多处理器上并发运行的内核任务竞争共享资源。
自旋锁的基本形式如下:
spin_lock(&mr_lock);
//临界区
spin_unlock(&mr_lock);信号量
Linux中的信号量是一种睡眠锁。如果有一个任务试图获得一个已被持有的信号量时,信号量会将其推入等待队列,然后让其睡眠。这时处理器获得自由去执行其它代码。当持有信号量的进程将信号量释放后,在等待队列中的一个任务将被唤醒,从而便可以获得这个信号量。
信号量的睡眠特性,使得信号量适用于锁会被长时间持有的情况;只能在进程上下文中使用,因为中断上下文中是不能被调度的;另外当代码持有信号量时,不可以再持有自旋锁。
信号量基本使用形式为:
static DECLARE_MUTEX(mr_sem);//声明互斥信号量
if(down_interruptible(&mr_sem))
//可被中断的睡眠,当信号来到,睡眠的任务被唤醒
//临界区
up(&mr_sem);信号量和自旋锁区别
从严格意义上说,信号量和自旋锁属于不同层次的互斥手段,前者的实现有赖于后者,在信号量本身的实现上,为了保证信号量结构存取的原子性,在多CPU中需要自旋锁来互斥。
信号量是进程级的。用于多个进程之间对资源的互斥,虽然也是在内核中,但是该内核执行路径是以进程的身份,代表进程来争夺进程。鉴于进程上下文切换的开销也很大,因此,只有当进程占用资源时间比较长时,用信号量才是较好的选择。
当所要保护的临界区访问时间比较短时,用自旋锁是非常方便的,因为它节省上下文切换的时间,但是CPU得不到自旋锁会在那里空转直到执行单元锁为止,所以要求锁不能在临界区里长时间停留,否则会降低系统的效率
由此,可以总结出自旋锁和信号量选用的3个原则:
1:当锁不能获取到时,使用信号量的开销就是进程上线文切换的时间Tc,使用自旋锁的开销就是等待自旋锁(由临界区执行的时间决定)Ts,如果Ts比较小时,应使用自旋锁比较好,如果Ts比较大,应使用信号量。
2:信号量所保护的临界区可包含可能引起阻塞的代码,而自旋锁绝对要避免用来保护包含这样的代码的临界区,因为阻塞意味着要进行进程间的切换,如果进程被切换出去后,另一个进程企图获取本自旋锁,死锁就会发生。
3:信号量存在于进程上下文,因此,如果被保护的共享资源需要在中断或软中断情况下使用,则在信号量和自旋锁之间只能选择自旋锁,当然,如果一定要是要那个信号量,则只能通过down_trylock()方式进行,不能获得就立即返回以避免阻塞
自旋锁VS信号量
需求建议的加锁方法
低开销加锁优先使用自旋锁
短期锁定优先使用自旋锁
长期加锁优先使用信号量
中断上下文中加锁使用自旋锁
持有锁是需要睡眠、调度使用信号量
20, 阻塞与非阻塞I/O
一个驱动当它无法立刻满足请求应当如何响应?一个对 read
的调用可能当没有数据时到来,而以后会期待更多的数据;或者一个进程可能试图写,但是你的设备没有准备好接受数据,因为你的输出缓冲满了。调用进程往往不关心这种问题,程序员只希望调用
read 或 write 并且使调用返回,在必要的工作已完成后,你的驱动应当(缺省地)阻塞进程,使它进入睡眠直到请求可继续。
阻塞操作是指在执行设备操作时若不能获得资源则挂起进程,直到满足可操作的条件后再进行操作。
一个典型的能同时处理阻塞与非阻塞的globalfifo读函数如下:
/*globalfifo读函数*/
static ssize_t globalfifo_read(struct file *filp, char __user *buf, size_t count,
loff_t *ppos)
{
int ret;
struct globalfifo_dev *dev = filp->private_data;
DECLARE_WAITQUEUE(wait, current);
down(&dev->sem); /* 获得信号量 */
add_wait_queue(&dev->r_wait, &wait); /* 进入读等待队列头 */
/* 等待FIFO非空 */
if (dev->current_len == 0) {
if (filp->f_flags &O_NONBLOCK) {
ret = - EAGAIN;
goto out;
}
__set_current_state(TASK_INTERRUPTIBLE); /* 改变进程状态为睡眠 */
up(&dev->sem);
schedule(); /* 调度其他进程执行 */
if (signal_pending(current)) {
/* 如果是因为信号唤醒 */
ret = - ERESTARTSYS;
goto out2;
}
down(&dev->sem);
}
/* 拷贝到用户空间 */
if (count > dev->current_len)
count = dev->current_len;
if (copy_to_user(buf, dev->mem, count)) {
ret = - EFAULT;
goto out;
} else {
memcpy(dev->mem, dev->mem + count, dev->current_len - count); /* fifo数据前移 */
dev->current_len -= count; /* 有效数据长度减少 */
printk(KERN_INFO "read %d bytes(s),current_len:%d\n", count, dev->current_len);
wake_up_interruptible(&dev->w_wait); /* 唤醒写等待队列 */
ret = count;
}
out:
up(&dev->sem); /* 释放信号量 */
out2:
remove_wait_queue(&dev->w_wait, &wait); /* 从附属的等待队列头移除 */
set_current_state(TASK_RUNNING);
return ret;
}
21, poll方法
使用非阻塞I/O的应用程序通常会使用select()和poll()系统调用查询是否可对设备进行无阻塞的访问。select()和poll()系统调用最终会引发设备驱动中的poll()函数被执行。
这个方法由下列的原型:
unsigned int (*poll) (struct file *filp, poll_table *wait);
这个驱动方法被调用, 无论何时用户空间程序进行一个 poll, select, 或者 epoll 系统调用, 涉及一个和驱动相关的文件描述符. 这个设备方法负责这 2 步:
- 对可能引起设备文件状态变化的等待队列,调用
poll_wait()函数,将对应的等待队列头添加到poll_table. - 返回一个位掩码, 描述可能不必阻塞就立刻进行的操作.
poll_table结构, 给 poll 方法的第 2 个参数, 在内核中用来实现 poll, select, 和 epoll 调用; 它在 中声明, 这个文件必须被驱动源码包含. 驱动编写者不必要知道所有它内容并且必须作为一个不透明的对象使用它; 它被传递给驱动方法以便驱动可用每个能唤醒进程的等待队列来加载它, 并且可改变 poll 操作状态. 驱动增加一个等待队列到poll_table结构通过调用函数 poll_wait:
void poll_wait (struct file *, wait_queue_head_t *, poll_table *);
poll 方法的第 2 个任务是返回位掩码, 它描述哪个操作可马上被实现; 这也是直接的. 例如, 如果设备有数据可用, 一个读可能不必睡眠而完成; poll 方法应当指示这个时间状态. 几个标志(通过 定义)用来指示可能的操作:
POLLIN:如果设备可被不阻塞地读, 这个位必须设置.
POLLRDNORM:这个位必须设置, 如果”正常”数据可用来读. 一个可读的设备返回( POLLIN|POLLRDNORM ).
POLLOUT:这个位在返回值中设置, 如果设备可被写入而不阻塞.
……
poll的一个典型模板如下:
static unsigned int globalfifo_poll(struct file *filp, poll_table *wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data; /*获得设备结构体指针*/
down(&dev->sem);
poll_wait(filp, &dev->r_wait, wait);
poll_wait(filp, &dev->w_wait, wait);
/*fifo非空*/
if (dev->current_len != 0) {
mask |= POLLIN | POLLRDNORM; /*标示数据可获得*/
}
/*fifo非满*/
if (dev->current_len != GLOBALFIFO_SIZE) {
mask |= POLLOUT | POLLWRNORM; /*标示数据可写入*/
}
up(&dev->sem);
return mask;
}应用程序如何去使用这个poll呢?一般用select()来实现,其原型为:
int select(int numfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
其中,readfds, writefds, exceptfds,分别是被select()监视的读、写和异常处理的文件描述符集合。numfds是需要检查的号码最高的文件描述符加1。
以下是一个具体的例子:
/*======================================================================
A test program in userspace
This example is to introduce the ways to use "select"
and driver poll
The initial developer of the original code is Baohua Song
<author@linuxdriver.cn>. All Rights Reserved.
======================================================================*/
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/time.h>
#define FIFO_CLEAR 0x1
#define BUFFER_LEN 20
main()
{
int fd, num;
char rd_ch[BUFFER_LEN];
fd_set rfds,wfds;
/*以非阻塞方式打开/dev/globalmem设备文件*/
fd = open("/dev/globalfifo", O_RDONLY | O_NONBLOCK);
if (fd != - 1)
{
/*FIFO清0*/
if (ioctl(fd, FIFO_CLEAR, 0) < 0)
{
printf("ioctl command failed\n");
}
while (1)
{
FD_ZERO(&rfds);// 清除一个文件描述符集rfds
FD_ZERO(&wfds);
FD_SET(fd, &rfds);// 将一个文件描述符fd,加入到文件描述符集rfds中
FD_SET(fd, &wfds);
select(fd + 1, &rfds, &wfds, NULL, NULL);
/*数据可获得*/
if (FD_ISSET(fd, &rfds)) //判断文件描述符fd是否被置位
{
printf("Poll monitor:can be read\n");
}
/*数据可写入*/
if (FD_ISSET(fd, &wfds))
{
printf("Poll monitor:can be written\n");
}
}
}
else
{
printf("Device open failure\n");
}
}其中:
FD_ZERO(fd_set *set); //清除一个文件描述符集set
FD_SET(int fd, fd_set *set); //将一个文件描述符fd,加入到文件描述符集set中
FD_CLEAR(int fd, fd_set *set); //将一个文件描述符fd,从文件描述符集set中清除
FD_ISSET(int fd, fd_set *set); //判断文件描述符fd是否被置位。
22,并发与竞态介绍
Linux设备驱动中必须解决一个问题是多个进程对共享资源的并发访问,并发的访问会导致竞态,在当今的Linux内核中,支持SMP与内核抢占的环境下,更是充满了并发与竞态。幸运的是,Linux
提供了多钟解决竞态问题的方式,这些方式适合不同的应用场景。例如:中断屏蔽、原子操作、自旋锁、信号量等等并发控制机制。
并发与竞态的概念
并发是指多个执行单元同时、并发被执行,而并发的执行单元对共享资源(硬件资源和软件上的全局变量、静态变量等)的访问则很容易导致竞态。
临界区概念是为解决竞态条件问题而产生的,一个临界区是一个不允许多路访问的受保护的代码,这段代码可以操纵共享数据或共享服务。临界区操纵坚持互斥锁原则(当一个线程处于临界区中,其他所有线程都不能进入临界区)。然而,临界区中需要解决的一个问题是死锁。
23, 中断屏蔽
在单CPU 范围内避免竞态的一种简单而省事的方法是进入临界区之前屏蔽系统的中断。CPU
一般都具有屏蔽中断和打开中断的功能,这个功能可以保证正在执行的内核执行路径不被中断处理程序所抢占,有效的防止了某些竞态条件的发送,总之,中断屏蔽将使得中断与进程之间的并发不再发生。
中断屏蔽的使用方法:
local_irq_disable() /屏蔽本地CPU 中断/
…..
critical section /临界区受保护的数据/
…..
local_irq_enable() /打开本地CPU 中断/ 由于Linux 的异步I/O、进程调度等很多重要操作都依赖于中断,中断对内核的运行非常重要,在屏蔽中断期间的所有中断都无法得到处理,因此长时间屏蔽中断是非常危险的,有可能造成数据的丢失,甚至系统崩溃的后果。这就要求在屏蔽了中断后,当前的内核执行路径要尽快地执行完临界区代码。
与local_irq_disable()不同的是,local_irq_save(flags)除了进行禁止中断的操作外,还保存当前CPU 的中断状态位信息;与local_irq_enable()不同的是,local_irq_restore(flags) 除了打开中断的操作外,还恢复了CPU 被打断前的中断状态位信息。
24, 原子操作
原子操作指的是在执行过程中不会被别的代码路径所中断的操作,Linux
内核提供了两类原子操作——位原子操作和整型原子操作。它们的共同点是在任何情况下都是原子的,内核代码可以安全地调用它们而不被打断。然而,位和整型变量原子操作都依赖于底层CPU
的原子操作来实现,因此这些函数的实现都与 CPU 架构密切相关。
1 整型原子操作
1)、设置原子变量的值
void atomic_set(atomic v,int i); /设置原子变量的值为 i */
atomic_t v = ATOMIC_INIT(0); /定义原子变量 v 并初始化为 0 / 2)、获取原子变量的值
int atomic_read(atomic_t v) /返回原子变量 v 的当前值*/
3)、原子变量加/减
void atomic_add(int i,atomic_t v) /原子变量增加 i */
void atomic_sub(int i,atomic_t v) /原子变量减少 i */
4)、原子变量自增/自减
void atomic_inc(atomic_t v) /原子变量增加 1 */
void atomic_dec(atomic_t v) /原子变量减少 1 */
5)、操作并测试
int atomic_inc_and_test(atomic_t *v);
int atomic_dec_and_test(atomic_t *v);
int atomic_sub_and_test(int i, atomic_t *v);
上述操作对原子变量执行自增、自减和减操作后测试其是否为 0 ,若为 0 返回true,否则返回false。注意:没有atomic_add_and_test(int i, atomic_t *v)。
6)、操作并返回
int atomic_add_return(int i, atomic_t *v);
int atomic_sub_return(int i, atomic_t *v);
int atomic_inc_return(atomic_t *v);
int atomic_dec_return(atomic_t *v);
上述操作对原子变量进行加/减和自增/自减操作,并返回新的值。
2 位原子操作
1)、设置位
void set_bit(nr,void addr);/设置addr 指向的数据项的第 nr 位为1 */
2)、清除位
void clear_bit(nr,void addr)/设置addr 指向的数据项的第 nr 位为0 */
3)、取反位
void change_bit(nr,void addr); /对addr 指向的数据项的第 nr 位取反操作*/
4)、测试位
test_bit(nr,void addr);/返回addr 指向的数据项的第 nr位*/
5)、测试并操作位
int test_and_set_bit(nr, void *addr);
int test_and_clear_bit(nr,void *addr);
int test_amd_change_bit(nr,void *addr);
25, 自旋锁
自旋锁(spin lock)是一种典型的对临界资源进行互斥访问的手段。为了获得一个自旋锁,在某CPU 上运行的代码需先执行一个原子操作,该操作测试并设置某个内存变量,由于它是原子操作,所以在该操作完成之前其他执行单元不能访问这个内存变量。如果测试结果表明锁已经空闲,则程序获得这个自旋锁并继续执行;如果测试结果表明锁仍被占用,则程序将在一个小的循环里面重复这个“测试并设置” 操作,即进行所谓的“自旋”。
理解自旋锁最简单的方法是把它当做一个变量看待,该变量把一个临界区标记为“我在这运行了,你们都稍等一会”,或者标记为“我当前不在运行,可以被使用”。
Linux中与自旋锁相关操作有:
1)、定义自旋锁
spinlock_t my_lock;
2)、初始化自旋锁
spinlock_t my_lock = SPIN_LOCK_UNLOCKED; /静态初始化自旋锁/
void spin_lock_init(spinlock_t lock); /动态初始化自旋锁*/
3)、获取自旋锁
/若获得锁立刻返回真,否则自旋在那里直到该锁保持者释放/
void spin_lock(spinlock_t *lock);
/若获得锁立刻返回真,否则立刻返回假,并不会自旋等待/
void spin_trylock(spinlock_t *lock)
4)、释放自旋锁
void spin_unlock(spinlock_t *lock)
自旋锁的一般用法:
spinlock_t lock; /定义一个自旋锁/
spin_lock_init(&lock); /动态初始化一个自旋锁/
……
spin_lock(&lock); /获取自旋锁,保护临界区/
……./临界区/
spin_unlock(&lock); /解锁/ 自旋锁主要针对SMP 或单CPU 但内核可抢占的情况,对于单CPU 且内核不支持抢占的系统,自旋锁退化为空操作。尽管用了自旋锁可以保证临界区不受别的CPU和本地CPU内的抢占进程打扰,但是得到锁的代码路径在执行临界区的时候,还可能受到中断和底半部(BH)的影响,为了防止这种影响,就需要用到自旋锁的衍生。
获取自旋锁的衍生函数:
void spin_lock_irq(spinlock_t lock); /获取自旋锁之前禁止中断*/
void spin_lock_irqsave(spinlock_t lock, unsigned long flags);/获取自旋锁之前禁止中断,并且将先前的中断状态保存在flags 中*/
void spin_lock_bh(spinlock_t lock); /在获取锁之前禁止软中断,但不禁止硬件中断*/ 释放自旋锁的衍生函数:
void spin_unlock_irq(spinlock_t *lock)
void spin_unlock_irqrestore(spinlock_t *lock,unsigned long flags);
void spin_unlock_bh(spinlock_t *lock); 解锁的时候注意要一一对应去解锁。
自旋锁注意点:
(1)自旋锁实际上是忙等待,因此,只有占用锁的时间极短的情况下,使用自旋锁才是合理的。
(2)自旋锁可能导致系统死锁。
(3)自旋锁锁定期间不能调用可能引起调度的函数。如:copy_from_user()、copy_to_user()、kmalloc()、msleep()等函数。
(4)拥有自旋锁的代码是不能休眠的。
26, 读写自旋锁
它允许多个读进程并发执行,但是只允许一个写进程执行临界区代码,而且读写也是不能同时进行的。
1)、定义和初始化读写自旋锁
rwlock_t my_rwlock = RW_LOCK_UNLOCKED; /* 静态初始化 */
rwlock_t my_rwlock;
rwlock_init(&my_rwlock); /* 动态初始化 */
2)、读锁定
void read_lock(rwlock_t *lock);
void read_lock_irqsave(rwlock_t *lock, unsigned long flags);
void read_lock_irq(rwlock_t *lock);
void read_lock_bh(rwlock_t *lock); 3)、读解锁
void read_unlock(rwlock_t *lock);
void read_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void read_unlock_irq(rwlock_t *lock);
void read_unlock_bh(rwlock_t *lock); 在对共享资源进行读取之前,应该先调用读锁定函数,完成之后调用读解锁函数。
4)、写锁定
void write_lock(rwlock_t *lock);
void write_lock_irqsave(rwlock_t *lock, unsigned long flags);
void write_lock_irq(rwlock_t *lock);
void write_lock_bh(rwlock_t *lock);
void write_trylock(rwlock_t *lock); 5)、写解锁
void write_unlock(rwlock_t *lock);
void write_unlock_irqrestore(rwlock_t *lock, unsigned long flags);
void write_unlock_irq(rwlock_t *lock);
void write_unlock_bh(rwlock_t *lock); 在对共享资源进行写之前,应该先调用写锁定函数,完成之后应调用写解锁函数。
读写自旋锁的一般用法:
rwlock_t lock; /定义一个读写自旋锁 rwlock/
rwlock_init(&lock); /初始化/
read_lock(&lock); /读取前先获取锁/
…../临界区资源/
read_unlock(&lock); /读完后解锁/
write_lock_irqsave(&lock, flags); /写前先获取锁/
…../临界区资源/
write_unlock_irqrestore(&lock,flags); /写完后解锁/ 27, 顺序锁(sequence lock)
顺序锁是对读写锁的一种优化,读执行单元在写执行单元对被顺序锁保护的资源进行写操作时仍然可以继续读,而不必等地写执行单元完成写操作,写执行单元也不必等待所有读执行单元完成读操作才进去写操作。但是,写执行单元与写执行单元依然是互斥的。并且,在读执行单元读操作期间,写执行单元已经发生了写操作,那么读执行单元必须进行重读操作,以便确保读取的数据是完整的,这种锁对于读写同时进行概率比较小的情况,性能是非常好的。
顺序锁有个限制,它必须要求被保护的共享资源不包含有指针,因为写执行单元可能使得指针失效,但读执行单元如果正要访问该指针,就会导致oops。
1)、初始化顺序锁
seqlock_t lock1 = SEQLOCK_UNLOCKED; /静态初始化/
seqlock lock2; /动态初始化/
seqlock_init(&lock2) 2)、获取顺序锁
void write_seqlock(seqlock_t *s1);
void write_seqlock_irqsave(seqlock_t *lock, unsigned long flags)
void write_seqlock_irq(seqlock_t *lock);
void write_seqlock_bh(seqlock_t *lock);
int write_tryseqlock(seqlock_t *s1); 3)、释放顺序锁
void write_sequnlock(seqlock_t *s1);
void write_sequnlock_irqsave(seqlock_t *lock, unsigned long flags)
void write_sequnlock_irq(seqlock_t *lock);
void write_sequnlock_bh(seqlock_t *lock); 写执行单元使用顺序锁的模式如下:
write_seqlock(&seqlock_a);
/写操作代码/
……..
write_sequnlock(&seqlock_a); 4)、读开始
unsigned read_seqbegin(const seqlock_t *s1);
unsigned read_seqbegin_irqsave(seqlock_t *lock, unsigned long flags); 5)、重读
int read_seqretry(const seqlock_t *s1, unsigned iv);
int read_seqretry_irqrestore(seqlock_t *lock,unsigned int seq,unsigned long flags); 读执行单元使用顺序锁的模式如下:
unsigned int seq;
do{
seq = read_seqbegin(&seqlock_a);
/读操作代码/
…….
}while (read_seqretry(&seqlock_a, seq)); 28, 信号量
信号量的使用
信号量(semaphore)是用于保护临界区的一种最常用的办法,它的使用方法与自旋锁是类似的,但是,与自旋锁不同的是,当获取不到信号量的时候,进程不会自旋而是进入睡眠的等待状态。
1)、定义信号量
struct semaphore sem;
2)、初始化信号量
void sema_init(struct semaphore sem, int val); /初始化信号量的值为 val */
更常用的是下面这二个宏:
#define init_MUTEX(sem) sema_init(sem, 1)
#define init_MUTEX_LOCKED(sem) sem_init(sem, 0) 然而,下面这两个宏是定义并初始化信号量的“快捷方式”
DECLARE_MUTEX(name) /一个称为name信号量变量被初始化为 1 /
DECLARE_MUTEX_LOCKED(name) /一个称为name信号量变量被初始化为 0 / 3)、获得信号量
/该函数用于获取信号量,若获取不成功则进入不可中断的睡眠状态/
void down(struct semaphore *sem);
/该函数用于获取信号量,若获取不成功则进入可中断的睡眠状态/
void down_interruptible(struct semaphore *sem);
/该函数用于获取信号量,若获取不成功立刻返回 -EBUSY/
int down_trylock(struct sempahore *sem); 4)、释放信号量
void up(struct semaphore sem); /释放信号量 sem ,并唤醒等待者*/
信号量的一般用法:
DECLARE_MUTEX(mount_sem); /定义一个信号量mount_sem,并初始化为 1 /
down(&mount_sem); /* 获取信号量,保护临界区*/
…..
critical section /临界区/
…..
up(&mount_sem); /释放信号量/ 29, 读写信号量
读写信号量可能引起进程阻塞,但是它允许多个读执行单元同时访问共享资源,但最多只能有一个写执行单元。
1)、定义和初始化读写信号量
struct rw_semaphore my_rws; /定义读写信号量/
void init_rwsem(struct rw_semaphore sem); /初始化读写信号量*/
2)、读信号量获取
void down_read(struct rw_semaphore *sem);
int down_read_trylock(struct rw_semaphore *sem);
3)、读信号量释放
void up_read(struct rw_semaphore *sem);
4)、写信号量获取
void down_write(struct rw_semaphore *sem);
int down_write_trylock(struct rw_semaphore *sem);
5)、写信号量释放
void up_write(struct rw_semaphore *sem);
30, completion
完成量(completion)用于一个执行单元等待另外一个执行单元执行完某事。
1)、定义完成量
struct completion my_completion;
2)、初始化完成量
init_completion(&my_completion);
3)、定义并初始化的“快捷方式”
DECLARE_COMPLETION(my_completion)
4)、等待完成量
void wait_for_completion(struct completion c); /等待一个 completion 被唤醒*/
5)、唤醒完成量
void complete(struct completion c); /只唤醒一个等待执行单元*/
void complete(struct completion c); /唤醒全部等待执行单元*/
31, 自旋锁VS信号量
信号量是进程级的,用于多个进程之间对资源的互斥,虽然也是在内核中,但是该内核执行路径是以进程的身份,代表进程来争夺资源的。如果竞争失败,会发送进程上下文切换,当前进程进入睡眠状态,CPU 将运行其他进程。鉴于开销比较大,只有当进程资源时间较长时,选用信号量才是比较合适的选择。然而,当所要保护的临界区访问时间比较短时,用自旋锁是比较方便的。
总结:
解决并发与竞态的方法有(按本文顺序):
(1)中断屏蔽
(2)原子操作(包括位和整型原子)
(3)自旋锁
(4)读写自旋锁
(5)顺序锁(读写自旋锁的进化)
(6)信号量
(7)读写信号量
(8)完成量
其中,中断屏蔽很少单独被使用,原子操作只能针对整数进行,因此自旋锁和信号量应用最为广泛。自旋锁会导致死循环,锁定期间内不允许阻塞,因此要求锁定的临界区小;信号量允许临界区阻塞,可以适用于临界区大的情况。读写自旋锁和读写信号量分别是放宽了条件的自旋锁
信号量,它们允许多个执行单元对共享资源的并发读。
Linux驱动开发必看-Linux启动过程
在开始步入Linux设备驱动程序的神秘世界之前,让我们从驱动程序开发人员的角度看几个内核构成要素,熟悉一些基本的内核概念。我们将学习内核定时器、同步机制以及内存分配方法。不过,我们还是得从头开始这次探索之旅。因此,本章要先浏览一下内核发出的启动信息,然后再逐个讲解一些有意思的点。
2.1 启动过程
图2-1显示了基于x86计算机Linux系统的启动顺序。第一步是BIOS从启动设备中导入主引导记录(MBR),接下来MBR中的代码查看分区表并 从活动分区读取GRUB、LILO或SYSLINUX等引导装入程序,之后引导装入程序会加载压缩后的内核映像并将控制权传递给它。内核取得控制权后,会 将自身解压缩并投入运转。
基于x86的处理器有两种操作模式:实模式和保护模式。在实模式下,用户仅可以使用1 MB内存,并且没有任何保护。保护模式要复杂得多,用户可以使用更多的高级功能(如分页)。CPU必须中途将实模式切换为保护模式。但是,这种切换是单向的,即不能从保护模式再切换回实模式。
内核初始化的第一步是执行实模式下的汇编代码,之后执行保护模式下init/main.c文件(上一章修改的源文件)中的start_kernel() 函数。start_kernel()函数首先会初始化CPU子系统,之后让内存和进程管理系统就位,接下来启动外部总线和I/O设备,最后一步是激活初始 化(init)程序,它是所有Linux进程的父进程。初始化进程执行启动必要的内核服务的用户空间脚本,并且最终派生控制台终端程序以及显示登录 (login)提示。

图2-1 基于x86硬件上的Linux的启动过程
本节内的3级标题都是图2-2中的一条打印信息,这些信息来源于基于x86的笔记本电脑的Linux启动过程。如果在其他体系架构上启动内核,消息以及语义可能会有所不同。
2.1.1 BIOS-provided physical RAM map
内核会解析从BIOS中读取到的系统内存映射,并率先将以下信息打印出来:
BIOS-provided physical RAM map:
BIOS-e820: 0000000000000000 - 000000000009f000 (usable)
...
BIOS-e820: 00000000ff800000 - 0000000100000000 (reserved)
实模式下的初始化代码通过使用BIOS的int
0x15服务并执行0xe820号函数(即上面的BIOS-e820字符串)来获得系统的内存映射信息。内存映射信息中包含了预留的和可用的内存,内核将
随后使用这些信息创建其可用的内存池。在附录B的B.1节,我们会对BIOS提供的内存映射问题进行更深入的讲解。
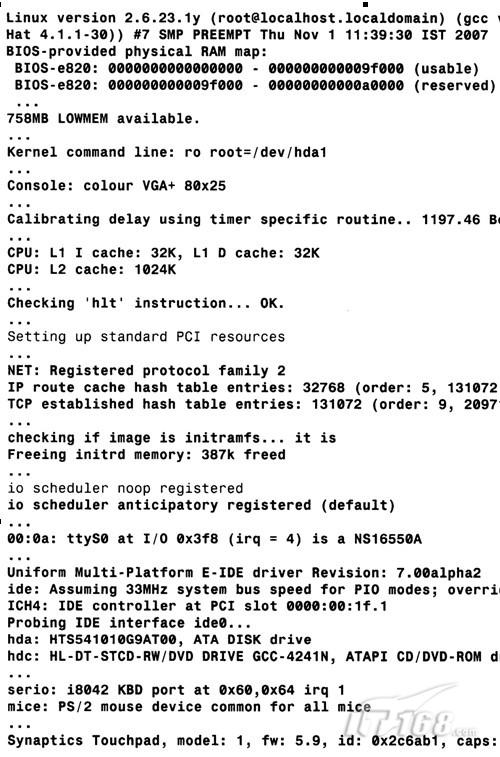
图2-2 内核启动信息
2.1.2 758MB LOWMEM available
896 MB以内的常规的可被寻址的内存区域被称作低端内存。内存分配函数kmalloc()就是从该区域分配内存的。高于896 MB的内存区域被称为高端内存,只有在采用特殊的方式进行映射后才能被访问。
在启动过程中,内核会计算并显示这些内存区内总的页数。
2.1.3 Kernel command line: ro root=/dev/hda1
Linux的引导装入程序通常会给内核传递一个命令行。命令行中的参数类似于传递给C程序中main()函数的argv[]列表,唯一的不同在于它们是
传递给内核的。可以在引导装入程序的配置文件中增加命令行参数,当然,也可以在运行过程中修改引导装入程序的提示行[1]。如果使用的是GRUB这个引导
装入程序,由于发行版本的不同,其配置文件可能是/boot/grub/grub.conf或者是/boot/grub/menu.lst。如果使用的是
LILO,配置文件为/etc/lilo.conf。下面给出了一个grub.conf文件的例子(增加了一些注释),看了紧接着title
kernel 2.6.23的那行代码之后,你会明白前述打印信息的由来。
default 0 #Boot the 2.6.23 kernel by default
timeout 5 #5 second to alter boot order or parameters
title kernel 2.6.23 #Boot Option 1
#The boot image resides in the first partition of the first disk
#under the /boot/ directory and is named vmlinuz-2.6.23. 'ro'
#indicates that the root partition should be mounted read-only.
kernel (hd0,0)/boot/vmlinuz-2.6.23 ro root=/dev/hda1
#Look under section "Freeing initrd memory:387k freed"
initrd (hd0,0)/boot/initrd
#...
命令行参数将影响启动过程中的代码执行路径。举一个例子,假设某命令行参数为bootmode,如果该参数被设置为1,意味着你希望在启动过程中打印一
些调试信息并在启动结束时切换到runlevel的第3级(初始化进程的启动信息打印后就会了解runlevel的含义);如果bootmode参数被设
置为0,意味着你希望启动过程相对简洁,并且设置runlevel为2。既然已经熟悉了init/main.c文件,下面就在该文件中增加如下修改:
int bootmode
= 1;
static
int __init
is_bootmode_setup(char
*str)
{
get_option(&str,
&bootmode);
return
1;
}
/* Handle parameter "bootmode="
*/
__setup("bootmode=", is_bootmode_setup);
if (bootmode) {
/* Print verbose output
*/
/* ...
*/
}
/* ... */
/* If bootmode is 1, choose an init runlevel of 3, else
switch to a run level of 2 */
if (bootmode) {
argv_init[++args]
= "3";
} else {
argv_init[++args]
= "2";
}
/* ... */
请重新编译内核并尝试运行新的修改。
2.1.4 Calibrating delay...1197.46 BogoMIPS (lpj=2394935)
在启动过程中,内核会计算处理器在一个jiffy时间内运行一个内部的延迟循环的次数。jiffy的含义是系统定时器2个连续的节拍之间的间隔。正如所料,该计算必须被校准到所用CPU的处理速度。校准的结果被存储在称为loops_per_jiffy的内核变量中。使用loops_per_jiffy的一种情况是某设备驱动程序希望进行小的微秒级别的延迟的时候。
为了理解延迟—循环校准代码,让我们看一下定义于init/calibrate.c文件中的calibrate_
delay()函数。该函数灵活地使用整型运算得到了浮点的精度。如下的代码片段(有一些注释)显示了该函数的开始部分,这部分用于得到一个
loops_per_jiffy的粗略值:
<< 12);
/* Initial approximation = 4096
*/
printk(KERN_DEBUG “Calibrating delay loop...“);
while ((loops_per_jiffy
<<=
1) !=
0) {
ticks = jiffies; /* As you will find out in the section, “Kernel
Timers," the jiffies variable contains the
number of timer ticks since the kernel
started, and is incremented in the timer
interrupt handler */
while (ticks
== jiffies);
/* Wait until the start of the next jiffy
*/
ticks = jiffies;
/* Delay
*/
__delay(loops_per_jiffy);
/* Did the wait outlast the current jiffy? Continue if it didn't
*/
ticks = jiffies
- ticks;
if (ticks)
break;
}
loops_per_jiffy >>=
1; /* This fixes the most significant bit and is
the lower-bound of loops_per_jiffy */
上述代码首先假定loops_per_jiffy大于4096,这可以转化为处理器速度大约为每秒100万条指令,即1
MIPS。接下来,它等待jiffy被刷新(1个新的节拍的开始),并开始运行延迟循环__delay(loops_per_jiffy)。如果这个延迟
循环持续了1个jiffy以上,将使用以前的loops_per_jiffy值(将当前值右移1位)修复当前loops_per_jiffy的最高位;否
则,该函数继续通过左移loops_per_jiffy值来探测出其最高位。在内核计算出最高位后,它开始计算低位并微调其精度:
/* Gradually work on the lower-order bits
*/
while (lps_precision--
&& (loopbit
>>=
1)) {
loops_per_jiffy |= loopbit;
ticks = jiffies;
while (ticks
== jiffies);
/* Wait until the start of the next jiffy
*/
ticks = jiffies;
/* Delay
*/
__delay(loops_per_jiffy);
if (jiffies
!= ticks) /* longer than 1 tick
*/
loops_per_jiffy &=
~loopbit;
}
上述代码计算出了延迟循环跨越jiffy边界时loops_per_jiffy的低位值。这个被校准的值可被用于获取BogoMIPS(其实它是一个并
非科学的处理器速度指标)。可以使用BogoMIPS作为衡量处理器运行速度的相对尺度。在1.6G Hz 基于Pentium M的笔记本电脑上,根据前述启动过程的打印信息,循环校准的结果是:loops_per_jiffy的值为2394935。获得BogoMIPS的方式如下:
* 1秒内的jiffy数*延迟循环消耗的指令数(以百万为单位)
= (2394935
* HZ
* 2)
/ (1000000)
= (2394935
* 250
* 2)
/ (1000000)
= 1197.46(与启动过程打印信息中的值一致)
在2.4节将更深入阐述jiffy、HZ和loops_per_jiffy。
2.1.5 Checking HLT instruction
由于Linux内核支持多种硬件平台,启动代码会检查体系架构相关的bug。其中一项工作就是验证停机(HLT)指令。
x86处理器的HLT指令会将CPU置入一种低功耗睡眠模式,直到下一次硬件中断发生之前维持不变。当内核想让CPU进入空闲状态时(查看
arch/x86/kernel/process_32.c文件中定义的cpu_idle()函数),它会使用HLT指令。对于有问题的CPU而言,命令
行参数no-hlt可以禁止HLT指令。如果no-hlt被设置,在空闲的时候,内核会进行忙等待而不是通过HLT给CPU降温。
当init/main.c中的启动代码调用include/asm-your-arch/bugs.h中定义的check_bugs()时,会打印上述信息。
2.1.6 NET: Registered protocol family 2
Linux套接字(socket)层是用户空间应用程序访问各种网络协议的统一接口。每个协议通过include/linux/socket.h文件中定义的分配给它的独一无二的系列号注册。上述打印信息中的Family 2代表af_inet(互联网协议)。
启动过程中另一个常见的注册协议系列是AF_NETLINK(Family 16)。网络链接套接字提供了用户进程和内核通信的
方法。通过网络链接套接字可完成的功能还包括存取路由表和地址解析协议(ARP)表(include/linux/netlink.h文件给出了完整的用
法列表)。对于此类任务而言,网络链接套接字比系统调用更合适,因为前者具有采用异步机制、更易于实现和可动态链接的优点。
内核中经常使能的另一个协议系列是AF_Unix或Unix-domain套接字。X Windows等程序使用它们在同一个系统上进行进程间通信。
2.1.7 Freeing initrd memory: 387k freed
initrd是一种由引导装入程序加载的常驻内存的虚拟磁盘映像。在内核启动后,会将其挂载为初始根文件系统,这个初始根文件系统中存放着挂载实际根文
件系统磁盘分区时所依赖的可动态连接的模块。由于内核可运行于各种各样的存储控制器硬件平台上,把所有可能的磁盘驱动程序都直接放进基本的内核映像中并不
可行。你所使用的系统的存储设备的驱动程序被打包放入了initrd中,在内核启动后、实际的根文件系统被挂载之前,这些驱动程序才被加载。使用
mkinitrd命令可以创建一个initrd映像。
2.6内核提供了一种称为initramfs的新功能,它在几个方面较
initrd更为优秀。后者模拟了一个磁盘(因而被称为initramdisk或initrd),会带来Linux块I/O子系统的开销(如缓冲);前者
基本上如同一个被挂载的文件系统一样,由自身获取缓冲(因此被称作initramfs)。
不同于initrd,基于页缓冲建立的
initramfs如同页缓冲一样会动态地变大或缩小,从而减少了其内存消耗。另外,initrd要求你的内核映像包含initrd所使用的文件系统(例
如,如果initrd为EXT2文件系统,内核必须包含EXT2驱动程序),然而initramfs不需要文件系统支持。再者,由于initramfs只
是页缓冲之上的一小层,因此它的代码量很小。
用户可以将初始根文件系统打包为一个cpio压缩包[1],并通过initrd=命令行参
数传递给内核。当然,也可以在内核配置过程中通过INITRAMFS_SOURCE选项直接编译进内核。对于后一种方式而言,用户可以提供cpio压缩包
的文件名或者包含initramfs的目录树。在启动过程中,内核会将文件解压缩为一个initramfs根文件系统,如果它找到了/init,它就会执
行该顶层的程序。这种获取初始根文件系统的方法对于嵌入式系统而言特别有用,因为在嵌入式系统中系统资源非常宝贵。使用mkinitramfs可以创建一
个initramfs映像,查看文档Documentation/filesystems/ramfs-
rootfs-initramfs.txt可获得更多信息。
在本例中,我们使用的是通过initrd=命令行参数向内核传递初始根文件
系统cpio压缩包的方式。在将压缩包中的内容解压为根文件系统后,内核将释放该压缩包所占据的内存(本例中为387
KB)并打印上述信息。释放后的页面会被分发给内核中的其他部分以便被申请。
在嵌入式系统开发过程中,initrd和initramfs有时候也可被用作嵌入式设备上实际的根文件系统。
2.1.8 io scheduler anticipatory registered (default)
I/O调度器的主要目标是通过减少磁盘的定位次数来增加系统的吞吐率。在磁盘定位过程中,磁头需要从当前的位置移动到感兴趣的目标位置,这会带来一定的
延迟。2.6内核提供了4种不同的I/O调度器:Deadline、Anticipatory、Complete Fair
Queuing以及NOOP。从上述内核打印信息可以看出,本例将Anticipatory 设置为了默认的I/O调度器。
2.1.9 Setting up standard PCI resources
启动过程的下一阶段会初始化I/O总线和外围控制器。内核会通过遍历PCI总线来探测PCI硬件,接下来再初始化其他的I/O子系统。从图2-3中我们会看到SCSI子系统、USB控制器、视频芯片(855北桥芯片组信息中的一部分)、串行端口(本例中为8250 UART)、PS/2键盘和鼠标、软驱、ramdisk、loopback设备、IDE控制器(本例中为ICH4南桥芯片组中的一部分)、触控板、以太网控制器(本例中为e1000)以及PCMCIA控制器初始化的启动信息。图2-3中
符号指向的为I/O设备的标识(ID)。
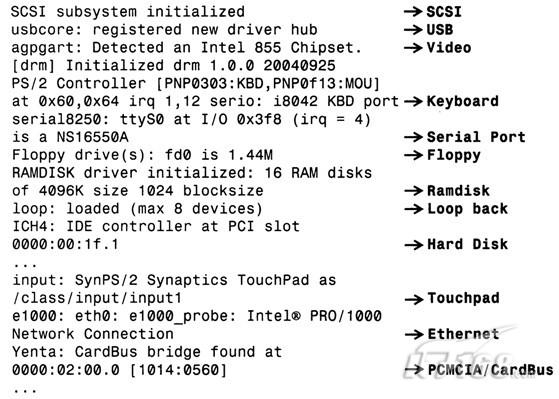
图2-3 在启动过程中初始化总线和外围控制器
本书会以单独的章节讨论大部分上述驱动程序子系统,请注意如果驱动程序以模块的形式被动态链接到内核,其中的一些消息也许只有在内核启动后才会被显示。
2.1.10 EXT3-fs: mounted filesystem
EXT3文件系统已经成为Linux事实上的文件系统。EXT3在退役的EXT2文件系统基础上增添了日志层,该层可用于崩溃后文件系统的快速恢复。它
的目标是不经由耗时的文件系统检查(fsck)操作即可获得一个一致的文件系统。EXT2仍然是新文件系统的工作引擎,但是EXT3层会在进行实际的磁盘
改变之前记录文件交互的日志。EXT3向后兼容于EXT2,因此,你可以在你现存的EXT2文件系统上加上EXT3或者由EXT3返回到EXT2文件系
统。
EXT3会启动一个称为kjournald的内核辅助线程(在接下来的一章中将深入讨论内核线程)来完成日志功能。在EXT3投入运转以后,内核挂载根文件系统并做好“业务”上的准备:
EXT3-fs: mounted filesystem with ordered data mode
kjournald starting. Commit interval 5 seconds
VFS: Mounted root (ext3 filesystem).
2.1.11 INIT: version 2.85 booting
所有Linux进程的父进程init是内核完成启动序列后运行的第1个程序。在init/main.c的最后几行,内核会搜索一个不同的位置以定位到init:
/* Look for /init in initramfs
*/
run_init_process(ramdisk_execute_command);
}
if (execute_command) {
/* You may override init and ask the kernel
to execute a custom program using the
"init=" kernel command-line argument. If
you do that, execute_command points to the
specified program */
run_init_process(execute_command);
}
/* Else search for init or sh in the usual places ..
*/
run_init_process("/sbin/init");
run_init_process("/etc/init");
run_init_process("/bin/init");
run_init_process("/bin/sh");
panic("No init found. Try passing init= option to kernel.");
init会接受/etc/inittab的指引。它首先执行/etc/rc.sysinit中的系统初始化脚本,该脚本的一项最重要的职责就是激活对换(swap)分区,这会导致如下启动信息被打印:
Adding 1552384k swap on /dev/hda6
让我们来仔细看看上述这段话的意思。Linux用户进程拥有3
GB的虚拟地址空间(见2.7节),构成“工作集”的页被保存在RAM中。但是,如果有太多程序需要内存资源,内核会释放一些被使用了的RAM页面并将其
存储到称为对换空间(swap
space)的磁盘分区中。根据经验法则,对换分区的大小应该是RAM的2倍。在本例中,对换空间位于/dev/hda6这个磁盘分区,其大小为1
552 384 KB。
接下来,init开始运行/etc/rc.d/rcX.d/目录中的脚本,其中X是inittab中定义的运行
级别。runlevel是根据预期的工作模式所进入的执行状态。例如,多用户文本模式意味着runlevel为3,X
Windows则意味着runlevel为5。因此,当你看到INIT: Entering runlevel
3这条信息的时候,init就已经开始执行/etc/rc.d/rc3.d/目录中的脚本了。这些脚本会启动动态设备命名子系统(第4章中将讨论
udev),并加载网络、音频、存储设备等驱动程序所对应的内核模块:
Starting udev: [ OK ]
Initializing hardware... network audio storage [Done]
...
最后,init发起虚拟控制台终端,你现在就可以登录了。
2.2 内核模式和用户模式
MS-DOS等操作系统在单一的CPU模式下运行,但是一些类Unix的操作系统则使用了双模式,可以有效地实现时间共享。在Linux机器上,CPU要么处于受信任的内核模式,要么处于受限制的用户模式。除了内核本身处于内核模式以外,所有的用户进程都运行在用户模式之中。
内核模式的代码可以无限制地访问所有处理器指令集以及全部内存和I/O空间。如果用户模式的进程要享有此特权,它必须通过系统调用向设备驱动程序或其他内核模式的代码发出请求。另外,用户模式的代码允许发生缺页,而内核模式的代码则不允许。
在2.4和更早的内核中,仅仅用户模式的进程可以被上下文切换出局,由其他进程抢占。除非发生以下两种情况,否则内核模式代码可以一直独占CPU:
(1) 它自愿放弃CPU;
(2) 发生中断或异常。
2.6内核引入了内核抢占,大多数内核模式的代码也可以被抢占。
2.3 进程上下文和中断上下文
内核可以处于两种上下文:进程上下文和中断上下文。在系统调用之后,用户应用程序进入内核空间,此后内核空间针对用户空间相应进程的代表就运行于进程上
下文。异步发生的中断会引发中断处理程序被调用,中断处理程序就运行于中断上下文。中断上下文和进程上下文不可能同时发生。
运行于进程上下文的内核代码是可抢占的,但进程上下文则会一直运行至结束,不会被抢占。因此,内核会限制中断上下文的工作,不允许其执行如下操作:
(1) 进入睡眠状态或主动放弃CPU;
(2) 占用互斥体;
(3) 执行耗时的任务;
(4) 访问用户空间虚拟内存。
本书4.2节会对中断上下文进行更深入的讨论。
2.4 内核定时器
内核中许多部分的工作都高度依赖于时间信息。Linux内核利用硬件提供的不同的定时器以支持忙等待或睡眠等待等时间相关的服务。忙等待时,CPU会不
断运转。但是睡眠等待时,进程将放弃CPU。因此,只有在后者不可行的情况下,才考虑使用前者。内核也提供了某些便利,可以在特定的时间之后调度某函数运
行。
我们首先来讨论一些重要的内核定时器变量(jiffies、HZ和xtime)的含义。接下来,我们会使用Pentium时间戳计数器(TSC)测量基于Pentium的系统的运行次数。之后,我们也分析一下Linux怎么使用实时钟(RTC)。
2.4.1 HZ和Jiffies
系统定时器能以可编程的频率中断处理器。此频率即为每秒的定时器节拍数,对应着内核变量HZ。选择合适的HZ值需要权衡。HZ值大,定时器间隔时间就小,因此进程调度的准确性会更高。但是,HZ值越大也会导致开销和电源消耗更多,因为更多的处理器周期将被耗费在定时器中断上下文中。
2.6.21内核支持无节拍的内核(CONFIG_NO_HZ),它会根据系统的负载动态触发定时器中断。无节拍系统的实现超出了本章的讨论范围,不再详述。
jiffies变量记录了系统启动以来,系统定时器已经触发的次数。内核每秒钟将jiffies变量增加HZ次。因此,对于HZ值为100的系统,1个jiffy等于10ms,而对于HZ为1000的系统,1个jiffy仅为1ms。
为了更好地理解HZ和jiffies变量,请看下面的取自IDE驱动程序(drivers/ide/ide.c)的代码片段。该段代码会一直轮询磁盘驱动器的忙状态:
= jiffies
+ (3*HZ);
while (hwgroup->busy) {
/* ...
*/
if (time_after(jiffies, timeout)) {
return
-EBUSY;
}
/* ...
*/
}
return SUCCESS;
如果忙条件在3s内被清除,上述代码将返回SUCCESS,否则,返回-EBUSY。3*HZ是3s内的jiffies数量。计算出来的超时
jiffies +
3*HZ将是3s超时发生后新的jiffies值。time_after()的功能是将目前的jiffies值与请求的超时时间对比,检测溢出。类似函数
还包括time_before()、time_before_eq()和time_after_eq()。
jiffies被定义为volatile类型,它会告诉编译器不要优化该变量的存取代码。这样就确保了每个节拍发生的定时器中断处理程序都能更新jiffies值,并且循环中的每一步都会重新读取jiffies值。
对于jiffies向秒转换,可以查看USB主机控制器驱动程序drivers/usb/host/ehci-sched.c中的如下代码片段:
ehci_info(ehci, "ep%ds-iso rescheduled
" "%lu times in %lu
seconds\n", stream->bEndpointAddress, is_in?
"in":
"out", stream->rescheduled,
((jiffies – stream->start)/HZ));
}
上述调试语句计算出USB端点流(见第11章)被重新调度stream->rescheduled次所耗费的秒数。jiffies-stream->start是从开始到现在消耗的jiffies数量,将其除以HZ就得到了秒数值。
假定jiffies值为1000,32位的jiffies会在大约50天的时间内溢出。由于系统的运行时间可以比该时间长许多倍,因此,内核提供了另一
个变量jiffies_64以存放64位(u64)的jiffies。链接器将jiffies_64的低32位与32位的jiffies指向同一个地址。
在32位的机器上,为了将一个u64变量赋值给另一个,编译器需要2条指令,因此,读jiffies_64的操作不具备原子性。可以将
drivers/cpufreq/cpufreq_stats.c文件中定义的cpufreq_stats_update()作为实例来学习。
2.4.2 长延时
在内核中,以jiffies为单位进行的延迟通常被认为是长延时。一种可能但非最佳的实现长延时的方法是忙等待。实现忙等待的函数有“占着茅坑不拉屎”之嫌,它本身不利用CPU进行有用的工作,同时还不让其他程序使用CPU。如下代码将占用CPU 1秒:
unsigned long timeout = jiffies + HZ;
while (time_before(jiffies, timeout)) continue;
实现长延时的更好方法是睡眠等待而不是忙等待,在这种方式中,本进程会在等待时将处理器出让给其他进程。schedule_timeout()完成此功能:
unsigned long timeout = HZ;
schedule_timeout(timeout); /* Allow other parts of the kernel to run */
这种延时仅仅确保超时较低时的精度。由于只有在时钟节拍引发的内核调度才会更新jiffies,所以无论是在内核空间还是在用户空间,都很难使超时的精
度比HZ更大了。另外,即使你的进程已经超时并可被调度,但是调度器仍然可能基于优先级策略选择运行队列的其他进程[1]。
用于睡眠等
待的另2个函数是wait_event_timeout()和msleep(),它们的实现都基于schedule_timeout()。
wait_event_timeout()的使用场合是:在一个特定的条件满足或者超时发生后,希望代码继续运行。msleep()表示睡眠指定的时间
(以毫秒为单位)。
这种长延时技术仅仅适用于进程上下文。睡眠等待不能用于中断上下文,因为中断上下文不允许执行schedule()
或睡眠(4.2节给出了中断上下文可以做和不能做的事情)。在中断中进行短时间的忙等待是可行的,但是进行长时间的忙等则被认为不可赦免的罪行。在中断禁
止时,进行长时间的忙等待也被看作禁忌。
为了支持在将来的某时刻进行某项工作,内核也提供了定时器API。可以通过
init_timer()动态定义一个定时器,也可以通过DEFINE_TIMER()静态创建定时器。然后,将处理函数的地址和参数绑定给一个
timer_list,并使用add_timer()注册它即可:
struct timer_list my_timer;
init_timer(&my_timer); /* Also see setup_timer()
*/
my_timer.expire = jiffies
+ n*HZ;
/* n is the timeout in number of seconds
*/
my_timer.function = timer_func;
/* Function to execute after n seconds
*/
my_timer.data = func_parameter;
/* Parameter to be passed to timer_func
*/
add_timer(&my_timer);
/* Start the timer
*/
上述代码只会让定时器运行一次。如果想让timer_func()函数周期性地执行,需要在timer_func()加上相关代码,指定其在下次超时后调度自身:
long func_parameter)
{
/* Do work to be done periodically
*/
/* ...
*/
init_timer(&my_timer);
my_timer.expire = jiffies
+ n*HZ;
my_timer.data = func_parameter;
my_timer.function = timer_func;
add_timer(&my_timer);
}
你可以使用mod_timer()修改my_timer的到期时间,使用del_timer()取消定时器,或使用timer_pending()以查
看my_timer当前是否处于等待状态。查看kernel/timer.c源代码,会发现schedule_timeout()内部就使用了这些
API。
clock_settime()和clock_gettime()等用户空间函数可用于获得内核定时器服务。用户应用程序可以使用setitimer()和getitimer()来控制一个报警信号在特定的超时后发生。
2.4.3 短延时
在内核中,小于jiffy的延时被认为是短延时。这种延时在进程或中断上下文都可能发生。由于不可能使用基于jiffy的方法实现短延时,之前讨论的睡眠等待将不再能用于短的超时。这种情况下,唯一的解决途径就是忙等待。
实现短延时的内核API包括mdelay()、udelay()和ndelay(),分别支持毫秒、微秒和纳秒级的延时。这些函数的实际实现取决于体系架构,而且也并非在所有平台上都被完整实现。
忙等待的实现方法是测量处理器执行一条指令的时间,为了延时,执行一定数量的指令。从前文可知,内核会在启动过程中进行测量并将该值存储在
loops_per_jiffy变量中。短延时API就使用了loops_per_jiffy值来决定它们需要进行循环的数量。为了实现握手进程中1微秒
的延时,USB主机控制器驱动程序(drivers/usb/host/ehci-hcd.c)会调用udelay(),而udelay()会内部调用
loops_per_jiffy:
result = ehci_readl(ehci, ptr);
/* ...
*/
if (result
== done) return
0;
udelay(1);
/* Internally uses loops_per_jiffy
*/
usec--;
} while (usec
> 0);
2.4.4 Pentium时间戳计数器
时间戳计数器(TSC)是Pentium兼容处理器中的一个计数器,它记录自启动以来处理器消耗的时钟周期数。由于TSC随着处理器周期速率的比例的变
化而变化,因此提供了非常高的精确度。TSC通常被用于剖析和监测代码。使用rdtsc指令可测量某段代码的执行时间,其精度达到微秒级。TSC的节拍可
以被转化为秒,方法是将其除以CPU时钟速率(可从内核变量cpu_khz读取)。
在如下代码片段中,low_tsc_ticks和high_tsc_ticks分别包含了TSC的低32位和高32位。低32位可能在数秒内溢出(具体时间取决于处理器速度),但是这已经用于许多代码的剖析了:
unsigned long low_tsc_ticks1, high_tsc_ticks1;
unsigned long exec_time;
rdtsc(low_tsc_ticks0, high_tsc_ticks0); /* Timestamp before
*/
printk("Hello World\n"); /* Code to
be profiled */
rdtsc(low_tsc_ticks1, high_tsc_ticks1); /* Timestamp after
*/
exec_time = low_tsc_ticks1
- low_tsc_ticks0;
在1.8 GHz Pentium 处理器上,exec_time的结果为871(或半微秒)。
2.4.5 实时钟
RTC在非易失性存储器上记录绝对时间。在x86
PC上,RTC位于由电池供电[1]的互补金属氧化物半导体(CMOS)存储器的顶部。从第5章的图5-1可以看出传统PC体系架构中CMOS的位置。在
嵌入式系统中,RTC可能被集成到处理器中,也可能通过I2C或SPI总线在外部连接,见第8章。
使用RTC可以完成如下工作:
(1) 读取、设置绝对时间,在时钟更新时产生中断;
(2) 产生频率为2~8192 Hz之间的周期性中断;
(3) 设置报警信号。
许多应用程序需要使用绝对时间[或称墙上时间(wall
time)]。jiffies是相对于系统启动后的时间,它不包含墙上时间。内核将墙上时间记录在xtime变量中,在启动过程中,会根据从RTC读取到
的目前的墙上时间初始化xtime,在系统停机后,墙上时间会被写回RTC。你可以使用do_gettimeofday()读取墙上时间,其最高精度由硬
件决定:
static struct timeval curr_time;
do_gettimeofday(&curr_time);
my_timestamp = cpu_to_le32(curr_time.tv_sec);
/* Record timestamp
*/
用户空间也包含一系列可以访问墙上时间的函数,包括:
(1) time(),该函数返回日历时间,或从新纪元(1970年1月1日00:00:00)以来经历的秒数;
(2) localtime(),以分散的形式返回日历时间;
(3) mktime(),进行localtime()函数的反向工作;
(4) gettimeofday(),如果你的平台支持,该函数将以微秒精度返回日历时间。
用户空间使用RTC的另一种途径是通过字符设备/dev/rtc来进行,同一时刻只有一个进程允许返回该字符设备。
在第5章和第8章,本书将更深入讨论RTC驱动程序。另外,在第19章给出了一个使用/dev/rtc以微秒级精度执行周期性工作的应用程序示例。
2.5 内核中的并发
随着多核笔记本电脑时代的到来,对称多处理器(SMP)的使用不再被限于高科技用户。SMP和内核抢占是多线程执行的两种场景。多个线程能够同时操作共享的内核数据结构,因此,对这些数据结构的访问必须被串行化。
接下来,我们会讨论并发访问情况下保护共享内核资源的基本概念。我们以一个简单的例子开始,并逐步引入中断、内核抢占和SMP等复杂概念。
2.5.1 自旋锁和互斥体
访问共享资源的代码区域称作临界区。自旋锁(spinlock)和互斥体(mutex,mutual exclusion的缩写)是保护内核临界区的两种基本机制。我们逐个分析。
自旋锁可以确保在同时只有一个线程进入临界区。其他想进入临界区的线程必须不停地原地打转,直到第1个线程释放自旋锁。注意:这里所说的线程不是内核线程,而是执行的线程。
下面的例子演示了自旋锁的基本用法:
spinlock_t mylock = SPIN_LOCK_UNLOCKED;
/* Initialize
*/
/* Acquire the spinlock. This is inexpensive if there
* is no one inside the critical section. In the face of
* contention, spinlock() has to busy-wait.
*/
spin_lock(&mylock);
/* ... Critical Section code ...
*/
spin_unlock(&mylock);
/* Release the lock
*/
与自旋锁不同的是,互斥体在进入一个被占用的临界区之前不会原地打转,而是使当前线程进入睡眠状态。如果要等待的时间较长,互斥体比自旋锁更合适,因为
自旋锁会消耗CPU资源。在使用互斥体的场合,多于2次进程切换时间都可被认为是长时间,因此一个互斥体会引起本线程睡眠,而当其被唤醒时,它需要被切换
回来。
因此,在很多情况下,决定使用自旋锁还是互斥体相对来说很容易:
(1) 如果临界区需要睡眠,只能使用互斥体,因为在获得自旋锁后进行调度、抢占以及在等待队列上睡眠都是非法的;
(2) 由于互斥体会在面临竞争的情况下将当前线程置于睡眠状态,因此,在中断处理函数中,只能使用自旋锁。(第4章将介绍更多的关于中断上下文的限制。)
下面的例子演示了互斥体使用的基本方法:
/* Statically declare a mutex. To dynamically
create a mutex, use mutex_init() */
static DEFINE_MUTEX(mymutex);
/* Acquire the mutex. This is inexpensive if there
* is no one inside the critical section. In the face of
* contention, mutex_lock() puts the calling thread to sleep.
*/
mutex_lock(&mymutex);
/* ... Critical Section code ...
*/
mutex_unlock(&mymutex); /* Release the mutex
*/
为了论证并发保护的用法,我们首先从一个仅存在于进程上下文的临界区开始,并以下面的顺序逐步增加复杂性:
(1) 非抢占内核,单CPU情况下存在于进程上下文的临界区;
(2) 非抢占内核,单CPU情况下存在于进程和中断上下文的临界区;
(3) 可抢占内核,单CPU情况下存在于进程和中断上下文的临界区;
(4) 可抢占内核,SMP情况下存在于进程和中断上下文的临界区。
旧的信号量接口
互斥体接口代替了旧的信号量接口(semaphore)。互斥体接口是从-rt树演化而来的,在2.6.16内核中被融入主线内核。
尽管如此,但是旧的信号量仍然在内核和驱动程序中广泛使用。信号量接口的基本用法如下:
Architecture dependent header */
/* Statically declare a semaphore. To dynamically
create a semaphore, use init_MUTEX() */
static DECLARE_MUTEX(mysem);
down(&mysem); /* Acquire the semaphore
*/
/* ... Critical Section code ...
*/
up(&mysem); /* Release the semaphore
*/
1. 案例1:进程上下文,单CPU,非抢占内核
这种情况最为简单,不需要加锁,因此不再赘述。
2. 案例2:进程和中断上下文,单CPU,非抢占内核
在这种情况下,为了保护临界区,仅仅需要禁止中断。如图2-4所示,假定进程上下文的执行单元A、B以及中断上下文的执行单元C都企图进入相同的临界区。

图2-4 进程和中断上下文进入临界区
由于执行单元C总是在中断上下文执行,它会优先于执行单元A和B,因此,它不用担心保护的问题。执行单元A和B也不必关心彼此会被互相打断,因为内核是
非抢占的。因此,执行单元A和B仅仅需要担心C会在它们进入临界区的时候强行进入。为了实现此目的,它们会在进入临界区之前禁止中断:
local_irq_disable(); /* Disable Interrupts in local CPU
*/
/* ... Critical Section ... */
local_irq_enable(); /* Enable Interrupts in local CPU
*/
但是,如果当执行到Point A的时候已经被禁止,local_irq_enable()将产生副作用,它会重新使能中断,而不是恢复之前的中断状态。可以这样修复它:
Point A:
local_irq_save(flags); /* Disable Interrupts
*/
/* ... Critical Section ...
*/
local_irq_restore(flags); /* Restore state to what it was at Point A
*/
不论Point A的中断处于什么状态,上述代码都将正确执行。
3. 案例3:进程和中断上下文,单CPU,抢占内核
如果内核使能了抢占,仅仅禁止中断将无法确保对临界区的保护,因为另一个处于进程上下文的执行单元可能会进入临界区。重新回到图2-4,现在,除了C以
外,执行单元A和B必须提防彼此。显而易见,解决该问题的方法是在进入临界区之前禁止内核抢占、中断,并在退出临界区的时候恢复内核抢占和中断。因此,执
行单元A和B使用了自旋锁API的irq变体:
Point A:
/* Save interrupt state.
* Disable interrupts - this implicitly disables preemption */
spin_lock_irqsave(&mylock, flags);
/* ... Critical Section ...
*/
/* Restore interrupt state to what it was at Point A
*/
spin_unlock_irqrestore(&mylock, flags);
我们不需要在最后显示地恢复Point
A的抢占状态,因为内核自身会通过一个名叫抢占计数器的变量维护它。在抢占被禁止时(通过调用preempt_disable()),计数器值会增加;在
抢占被使能时(通过调用preempt_enable()),计数器值会减少。只有在计数器值为0的时候,抢占才发挥作用。
4. 案例4:进程和中断上下文,SMP机器,抢占内核
现在假设临界区执行于SMP机器上,而且你的内核配置了CONFIG_SMP和CONFIG_PREEMPT。
到目前为止讨论的场景中,自旋锁原语发挥的作用仅限于使能和禁止抢占和中断,时间的锁功能并未被完全编译进来。在SMP机器内,锁逻辑被编译进来,而且自旋锁原语确保了SMP安全性。SMP使能的含义如下:
Point A:
/*
- Save interrupt state on the local CPU
- Disable interrupts on the local CPU. This implicitly disables preemption.
- Lock the section to regulate access by other CPUs
*/
spin_lock_irqsave(&mylock, flags);
/* ... Critical Section ...
*/
/*
- Restore interrupt state and preemption to what it
was at Point A for the local CPU
- Release the lock
*/
spin_unlock_irqrestore(&mylock, flags);
在SMP系统上,获取自旋锁时,仅仅本CPU上的中断被禁止。因此,一个进程上下文的执行单元(图2-4中的执行单元A)在一个CPU上运行的同时,一
个中断处理函数(图2-4中的执行单元C)可能运行在另一个CPU上。非本CPU上的中断处理函数必须自旋等待本CPU上的进程上下文代码退出临界区。中
断上下文需要调用spin_lock()/spin_unlock():
/* ... Critical Section ...
*/
spin_unlock(&mylock);
除了有irq变体以外,自旋锁也有底半部(BH)变体。在锁被获取的时候,spin_lock_bh()会禁止底半部,而spin_unlock_bh()则会在锁被释放时重新使能底半部。我们将在第4章讨论底半部。
-rt树
实时(-rt)树,也被称作CONFIG_PREEMPT_RT补丁集,实现了内核中一些针对低延时的修改。该补丁集可以从
www.kernel.org/pub/linux/kernel/projects/rt下载,它允许内核的大部分位置可被抢占,但是用自旋锁代替了一
些互斥体。它也合并了一些高精度的定时器。数个-rt功能已经被融入了主线内核。详细的文档见http://rt.wiki.kernel.org/。
为了提高性能,内核也定义了一些针对特定环境的特定的锁原语。使能适用于代码执行场景的互斥机制将使代码更高效。下面来看一下这些特定的互斥机制。
2.5.2 原子操作
原子操作用于执行轻量级的、仅执行一次的操作,例如修改计数器、有条件的增加值、设置位等。原子操作可以确保操作的串行化,不再需要锁进行并发访问保护。原子操作的具体实现取决于体系架构。
为了在释放内核网络缓冲区(称为skbuff)之前检查是否还有余留的数据引用,定义于net/core/skbuff.c文件中的skb_release_data()函数将进行如下操作:
||
2 /* Atomically decrement and check if the returned value is zero
*/
3 !atomic_sub_return(skb->nohdr
? (1
<< SKB_DATAREF_SHIFT)
+ 1 :
4
1,&skb_shinfo(skb)->dataref)) {
5 /* ...
*/
6 kfree(skb->head);
7 }
当skb_release_data()执行的时候,另一个调用skbuff_clone()(也在net/core/skbuff.c文件中定义)的执行单元也许在同步地增加数据引用计数值:
/* Atomically bump up the data reference count
*/
atomic_inc(&(skb_shinfo(skb)->dataref));
/* ... */
原子操作的使用将确保数据引用计数不会被这两个执行单元“蹂躏”。它也消除了使用锁去保护单一整型变量的争论。
内核也支持set_bit()、clear_bit()和test_and_set_bit()操作,它们可用于原子地位修改。查看include/asm-your-arch/atomic.h文件可以看出你所在体系架构所支持的原子操作。
2.5.3 读—写锁
另一个特定的并发保护机制是自旋锁的读—写锁变体。如果每个执行单元在访问临界区的时候要么是读要么是写共享的数据结构,但是它们都不会同时进行读和写操作,那么这种锁是最好的选择。允许多个读线程同时进入临界区。读自旋锁可以这样定义:
read_lock(&myrwlock);
/* Acquire reader lock
*/
/* ... Critical Region ...
*/
read_unlock(&myrwlock);
/* Release lock
*/
但是,如果一个写线程进入了临界区,那么其他的读和写都不允许进入。写锁的用法如下:
write_lock(&myrwlock); /* Acquire writer lock
*/
/* ... Critical Region ...
*/
write_unlock(&myrwlock); /* Release lock
*/
net/ipx/ipx_route.c中的IPX路由代码是使用读—写锁的真实示例。一个称作ipx_routes_lock的读—写锁将保护IPX
路由表的并发访问。要通过查找路由表实现包转发的执行单元需要请求读锁。需要添加和删除路由表中入口的执行单元必须获取写锁。由于通过读路由表的情况比更
新路由表的情况多得多,使用读—写锁提高了性能。
和传统的自旋锁一样,读—写锁也有相应的irq变 体:read_lock_irqsave()、read_unlock_
irqrestore()、write_lock_irqsave()和write_unlock_irqrestore()。这些函数的含义与传统自旋
锁相应的变体相似。
2.6内核引入的顺序锁(seqlock)是一种支持写多于读的读—写锁。在一个变量的写操作比读操作多得多的情况
下,这种锁非常有用。前文讨论的jiffies_64变量就是使用顺序锁的一个例子。写线程不必等待一个已经进入临界区的读,因此,读线程也许会发现它们
进入临界区的操作失败,因此需要重试:
/* Defined in kernel/time.c
*/
{
unsigned long seq;
u64 ret;
do {
seq = read_seqbegin(&xtime_lock);
ret = jiffies_64;
} while (read_seqretry(&xtime_lock, seq));
return ret;
}
写者会使用write_seqlock()和write_sequnlock()保护临界区。
2.6内核还引入了另一种称为读—复制—更新(RCU)的机制。该机制用于提高读操作远多于写操作时的性能。其基本理念是读线程不需要加锁,但是写线程
会变得更加复杂,它们会在数据结构的一份副本上执行更新操作,并代替读者看到的指针。为了确保所有正在进行的读操作的完成,原子副本会一直被保持到所有
CPU上的下一次上下文切换。使用RCU的情况很复杂,因此,只有在确保你确实需要使用它而不是前文的其他原语的时候,才适宜选择它。
include/linux/
rcupdate.h文件中定义了RCU的数据结构和接口函数,Documentation/RCU/*提供了丰富的文档。
fs/dcache.c文件中包含一个RCU的使用示例。在Linux中,每个文件都与一个目录入口信息(dentry结构体)、元数据信息(存放在
inode中)和实际的数据(存放在数据块中)关联。每次操作一个文件的时候,文件路径中的组件会被解析,相应的dentry会被获取。为了加速未来的操
作,dentry结构体被缓存在称为dcache的数据结构中。任何时候,对dcache进行查找的数量都远多于dcache的更新操作,因此,对
dcache的访问适宜用RCU原语进行保护。
2.5.4 调试
由于难于重现,并发相关的问
题通常非常难调试。在编译和测试代码的时候使能SMP(CONFIG_SMP)和抢占(CONFIG_PREEMPT)是一种很好的理念,即便你的产品将
运行在单CPU、禁止抢占的情况下。在Kernel hacking下有一个称为Spinlock and rw-lock
debugging的配置选项(CONFIG_DEBUG_SPINLOCK),它能帮助你找到一些常见的自旋锁错误。
Lockmeter(http://oss.sgi. com/projects/lockmeter/)等工具可用于收集锁相关的统计信息。
在访问共享资源之前忘记加锁就会出现常见的并发问题。这会导致一些不同的执行单元杂乱地“竞争”。这种问题(被称作“竞态”)可能会导致一些其他的行为。
在某些代码路径里忘记了释放锁也会出现并发问题,这会导致死锁。为了理解这个问题,让我们分析如下代码:
/* Acquire lock
*/
/* ... Critical Section ...
*/
if (error) { /* This error condition occurs rarely
*/
return
-EIO; /* Forgot to release the lock!
*/
}
spin_unlock(&mylock);
/* Release lock
*/
if (error)语句成立的话,任何要获取mylock的线程都会死锁,内核也可能因此而冻结。
如果在写完代码的数月或数年以后首次出现了问题,回过头来调试它将变得更为棘手。(在21.3.3节有一个相关的调试例子。)因此,为了避免遭遇这种不快,在设计软件架构的时候,就应该考虑并发逻辑。
2.6 proc文件系统
proc文件系统(procfs)是一种虚拟的文件系统,它创建内核内部的视窗。浏览procfs时看到的数据是在内核运行过程中产生的。procfs中的文件可被用于配置内核参数、查看内核结构体、从设备驱动程序中收集统计信息或者获取通用的系统信息。
procfs是一种虚拟的文件系统,这意味着驻留于procfs中的文件并不与物理存储设备如硬盘等关联。相反,这些文件中的数据由内核中相应的入口点按需动态创建。因此,procfs中的文件大小都显示为0。procfs通常在启动过程中挂载在/proc目录,通过运行mount命令可以看出这一点。
为了了解procfs的能力,请查看/proc/cpuinfo、/proc/meminfo、/proc/interrupts、/proc/tty
/driver
/serial、/proc/bus/usb/devices和/proc/stat的内容。通过写/proc/sys/目录中的文件可以在运行时修改某
些内核参数。例如,通过向/proc/sys/kernel/printk文件回送一个新的值,可以改变内核printk日志的级别。许多实用程序(如
ps)和系统性能监视工具(如sysstat)就是通过驻留于/proc中的文件来获取信息的。
2.6内核引入的seq文件简化了大的procfs操作。附录C对此进行了描述。
2.7 内存分配
一些设备驱动程序必须意识到内存区的存在,另外,许多驱动程序需要内存分配函数的服务。本节我们将简要地讨论这两点。
内核会以分页形式组织物理内存,而页大小则取决于具体的体系架构。在基于x86的机器上,其大小为4096B。物理内存中的每一页都有一个与之对应的struct page(定义在include/linux/ mm_types.h文件中):
在32位x86系统上,默认的内核配置会将4 GB的地址空间分成给用户空间的3 GB的虚拟内存空间和给内核空间的1
GB的空间(如图2-5所示)。这导致内核能处理的处理内存有1 GB的限制。现实情况是,限制为896 MB,因为地址空间的128
MB已经被内核数据结构占据。通过改变3 GB/1
GB的分割线,可以放宽这个限制,但是由于减少了用户进程虚拟地址空间的大小,在内存密集型的应用程序中可能会出现一些问题。
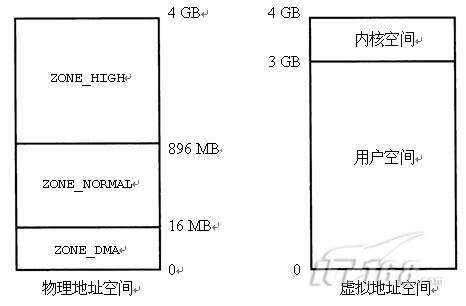
图2-5 32位PC系统上默认的地址空间分布
内核中用于映射低于896
MB物理内存的地址与物理地址之间存在线性偏移;这种内核地址被称作逻辑地址。在支持“高端内存”的情况下,在通过特定的方式映射这些区域产生对应的虚拟
地址后,内核将能访问超过896 MB的内存。所有的逻辑地址都是内核虚拟地址,而所有的虚拟地址并非一定是逻辑地址。
因此,存在如下的内存区。
(1) ZONE_DMA(小于16 MB),该区用于直接内存访问(DMA)。由于传统的ISA设备有24条地址线,只能访问开始的16 MB,因此,内核将该区献给了这些设备。
(2) ZONE_NORMAL(16~896 MB),常规地址区域,也被称作低端内存。用于低端内存页的struct page结构中的“虚拟”字段包含了对应的逻辑地址。
(3) ZONE_HIGH(大于896
MB),仅仅在通过kmap()映射页为虚拟地址后才能访问。(通过kunmap()可去除映射。)相应的内核地址为虚拟地址而非逻辑地址。如果相应的页
未被映射,用于高端内存页的struct page结构体的“虚拟”字段将指向NULL。
kmalloc()是一个用于从ZONE_NORMAL区域返回连续内存的内存分配函数,其原型如下:
void *kmalloc(int count, int flags);
count是要分配的字节数,flags是一个模式说明符。支持的所有标志列在include/linux./gfp.h文件中(gfp是get free page的缩写),如下为常用标志。
(1) GFP_KERNEL,被进程上下文用来分配内存。如果指定了该标志,kmalloc()将被允许睡眠,以等待其他页被释放。
(2) GFP_ATOMIC,被中断上下文用来获取内存。在这种模式下,kmalloc()不允许进行睡眠等待,以获得空闲页,因此GFP_ATOMIC分配成功的可能性比用GFP_KERNEL低。
由于kmalloc()返回的内存保留了以前的内容,将它暴露给用户空间可到会导致安全问题,因此我们可以使用kzalloc()获得被填充为0的内存。
如果需要分配大的内存缓冲区,而且也不要求内存在物理上有联系,可以用vmalloc()代替kmalloc():
void *vmalloc(unsigned long count);
count是要请求分配的内存大小。该函数返回内核虚拟地址。
vmalloc()需要比kmalloc()更大的分配空间,但是它更慢,而且不能从中断上下文调用。另外,不能用vmalloc()返回的物理上不连
续的内存执行DMA。在设备打开时,高性能的网络驱动程序通常会使用vmalloc()来分配较大的描述符环行缓冲区。
内核还提供了一些更复杂的内存分配技术,包括后备缓冲区(look aside buffer)、slab和mempool;这些概念超出了本章的讨论范围,不再细述。
2.8 查看源代码
内存启动始于执行arch/x86/boot/目录中的实模式汇编代码。查看arch/x86/kernel/setup_32.c文件可以看出保护模式的内核怎样获取实模式内核收集的信息。
第一条信息来自于init/main.c中的代码,深入挖掘init/calibrate.c可以对BogoMIPS校准理解得更清楚,而include/asm-your-arch/bugs.h则包含体系架构相关的检查。
内核中的时间服务由驻留于arch/your-arch/kernel/中的体系架构相关的部分和实现于kernel/timer.c中的通用部分组成。从include/linux/time*.h头文件中可以获取相关的定义。
jiffies定义于linux/jiffies.h文件中。HZ的值与处理器相关,可以从include/asm-your-arch/ param.h找到。
内存管理源代码存放在顶层mm/目录中。
表2-1给出了本章中主要的数据结构以及其在源代码树中定义的位置。表2-2则列出了本章中主要内核编程接口及其定义的位置。
表2-1 数据结构小结

表2-2 内核编程接口小结



Linux 驱动之模块参数--Linux设备驱动程序
模块参数
很多情况下,我们期望通过参数来控制我们的驱动的行为,比如由于系统的不同,而为了保证我们驱动有较好的移植性,我们有时候期望通过传递参数来控制我们驱动的行为,这样不同的系统中,驱动可能有不同的行为控制。
为了满足这种需求,内核允许对驱动程序指定参数,而这些参数可在加载驱动的过程中动态的改变
参数的来源主要有两个
使用
insmod/modprobe ./xxx.ko时候在命令行后直接给出参数;modprobe命令装载模块时可以从它的配置文件
/etc/modprobe.conf文件中读取参数值
这个宏必须放在任何函数之外,通常实在源文件的头部
模块参数传递的方式
对于如何向模块传递参数,Linux kernel 提供了一个简单的框架。其允许驱动程序声明参数,并且用户在系统启动或模块装载时为参数指定相应值,在驱动程序里,参数的用法如同全局变量。
使用下面的宏时需要包含头文件<linux/moduleparam.h>
宏
module_param(name, type, perm);
module_param_array(name, type, num_point, perm);
module_param_named(name_out, name_in, type, perm);
module_param_string(name, string, len, perm);
MODULE_PARM_DESC(name, describe);- 1
- 2
- 3
- 4
- 5
参数类型
内核支持的模块参数类型如下
| 参数 | 描述 |
|---|---|
| bool | 布尔类型(true/false),关联的变量类型应该死int |
| intvbool | bool的反值,例如赋值位true,但是实际值位false |
| int | 整型 |
| long | 长整型 |
| short | 短整型 |
| uint | 无符号整型 |
| ulong | 无符号长整形型 |
| ushort | 无符号短整型 |
| charp | 字符指针类型,内核会为用户提供的字符串分配内存,并设置相应指针 |
关于数组类型怎么传递,我们后面会谈到
注意
如果我们需要的类型不在上面的清单中,模块代码中的钩子可让我们来指定这些类型。
具体的细节请参阅moduleparam.h文件。所有的模块参数都应该给定一个默认值;
insmod只会在用户明确设定了参数值的情况下才会改变参数的值,模块可以根据默认值来判断是否一个显示给定的值
访问权限
perm访问权限与linux文件爱你访问权限相同的方式管理,
如0644,或使用stat.h中的宏如S_IRUGO表示。
我们鼓励使用stat.h中存在的定义。这个值用来控制谁能够访问sysfs中对模块参数的表述。
如果制定0表示完全关闭在sysfs中相对应的项,否则的话,模块参数会在/sys/module中出现,并设置为给定的访问许可。
如果指定S_IRUGO,则任何人均可读取该参数,但不能修改
如果指定S_IRUGO | S_IWUSR 则允许root修改该值
注意
如果一个参数通过sysfs而被修改,则如果模块修改了这个参数的值一样,但是内核不会以任何方式通知模块,大多数情况下,我们不应该让模块参数是可写的,除非我们打算检测这种修改并做出相应的动作。
如果你只有ko文件却没有源码,想知道模块中到底有哪些模块参数,不着急,只需要用
modinfo -p ${modulename}
就可以看到个究竟啦。
对于已经加载到内核里的模块,如果想改变这些模块的模块参数该咋办呢?简单,只需要输入
echo -n ${value} > /sys/module/${modulename}/parameters/${param}- 1
来修改即可。
示例
传递全局参数
在模块里面, 声明一个变量(全局变量),用来接收用户加载模块时传递的参数
module_param(name, type, perm);
- 1
- 2
| 参数 | 描述 |
|---|---|
| name | 用来接收参数的变量名 |
| type | 参数的数据类型 |
| perm | 用于sysfs入口项系的访问可见性掩码 |
示例–传递int
这些宏不会声明变量,因此在使用宏之前,必须声明变量,典型地用法如下:
static int value = 0;
module_param(value, int, 0644);
MODULE_PARM_DESC(value_int, "Get an value from user...\n");- 1
- 2
- 3
使用
sudo insmod param.ko value=100 - 1
来进行加载
示例–传递charp
static char *string = "gatieme";
module_param(string, charp, 0644);
MODULE_PARM_DESC(string, "Get an string(char *) value from user...\n");- 1
- 2
- 3
使用
sudo insmod param.ko string="hello" - 1
在模块内部变量的名字和加载模块时传递的参数名字不同
前面那种情况下,外部参数的名字和模块内部的名字必须一致,那么有没有其他的绑定方法,可以是我们的参数传递更加灵活呢?
使模块源文件内部的变 量名与外部的参数名有不同的名字,通过module_param_named()定义。
module_param_named(name_out, name_in, type, perm);- 1
| 参数 | 描述 |
|---|---|
| name_out | 加载模块时,参数的名字 |
| name_in | 模块内部变量的名字 |
| type | 参数类型 |
| perm | 访问权限 |
使用
static int value_in = 0;
module_param_named(value_out, value_in, int, 0644);
MODULE_PARM_DESC(value_in, "value_in named var_out...\n");- 1
- 2
- 3
加载
sudo insmod param.ko value_out=200- 1
传递字符串
加载模块的时候, 传递字符串到模块的一个全局字符数组里面
module_param_string(name, string, len, perm);- 1
| 参数 | 描述 |
|---|---|
| name | 在加载模块时,参数的名字 |
| string | 模块内部的字符数组的名字 |
| len | 模块内部的字符数组的大小 |
| perm | 访问权限 |
static char buffer[20] = "gatieme";
module_param_string(buffer, buffer, sizeof(buffer), 0644);
MODULE_PARM_DESC(value_charp, "Get an string buffer from user...\n");- 1
- 2
- 3
传递数组
加载模块的时候, 传递参数到模块的数组中
module_param_array(name, type, num_point, perm);- 1
| 参数 | 描述 |
|---|---|
| name | 模块的数组名,也是外部制定的数组名 |
| type | 模块数组的数据类型 |
| num_point | 用来获取用户在加载模块时传递的参数个数,为NULL时,表示不关心用户传递的参数个数 |
| perm | 访问权限 |
使用
static int array[3];
int num;
module_param_array(array, int, &num, 0644);
MODULE_PARM_DESC(array, "Get an array from user...\n");- 1
- 2
- 3
- 4
指定描述信息
MODULE_PARM_DESC(name, describe);- 1
| 参数 | 描述 |
|---|---|
| name | 参数变量名 |
| describe | 描述信息的字符串 |
使用modinfo查看参数
modinfo -p param.ko- 1
param驱动源码
驱动源码param.c
#include <linux/init.h>
#include <linux/module.h>
#include <linux/moduleparam.h>
/*
* 在模块里面, 声明一个变量(全局变量),
* 用来接收用户加载模块哦时传递的参数
*
* module_param(name, type, perm)
**/
static int value = 0;
module_param(value, int, 0644);
MODULE_PARM_DESC(value_int, "Get an value from user...\n");
/*
* 在模块内部变量的名字和加载模块时传递的参数名字不同
*
* module_param_named(name_out, name_in, type, perm)
*
* @name_out 加载模块时,参数的名字
* @name_in 模块内部变量的名字
* @type 参数类型
* @perm 访问权限
* */
static int value_in = 0;
module_param_named(value_out, value_in, int, 0644);
MODULE_PARM_DESC(value_in, "value_in named var_out...\n");
/*
* 加载模块的时候, 传递字符串到模块的一个全局字符数组里面
*
* module_param_string(name, string, len, perm)
*
* @name 在加载模块时,参数的名字
* @string 模块内部的字符数组的名字
* @len 模块内部的字符数组的大小
* #perm 访问权限
*
* */
static char *string = NULL;
module_param(string, charp, 0644);
MODULE_PARM_DESC(string, "Get an string(char *) value from user...\n");
static char buffer[20] = "gatieme";
module_param_string(buffer, buffer, sizeof(buffer), 0644);
MODULE_PARM_DESC(value_charp, "Get an string buffer from user...\n");
/*
* 加载模块的时候, 传递参数到模块的数组中
*
* module_param_array(name, type, num_point, perm)
*
* @name 模块的数组名,也是外部制定的数组名
* @type 模块数组的数据类型
* @num_point 用来获取用户在加载模块时传递的参数个数,
* 为NULL时,表示不关心用户传递的参数个数
* @perm 访问权限
*
* */
static int array[3];
int num;
module_param_array(array, int, &num, 0644);
MODULE_PARM_DESC(array, "Get an array from user...\n");
int __init param_module_init(void)
{
int index = 0;
printk("\n---------------------\n");
printk("value : %d\n", value);
printk("value_in : %d\n", value_in);
printk("string : %s\n", string);
printk("buffer : %s\n", buffer);
for(index = 0; index < num; index++)
{
printk("array[%2d] : %d\n", index, array[index]);
}
printk("---------------------\n");
return 0;
}
void __exit param_module_exit(void)
{
printk("\n---------------------\n");
printk("exit param dobule\n");
printk("---------------------\n");
}
module_init(param_module_init);
module_exit(param_module_exit);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
Makefile
obj-m := param.o
KERNELDIR ?= /lib/modules/$(shell uname -r)/build
PWD := $(shell pwd)
all:
make -C $(KERNELDIR) M=$(PWD) modules
clean:
make -C $(KERNELDIR) M=$(PWD) clean- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
参数传递过程
sudo insmod param.ko value=100 value_out=200 string="gatieme" buffer="Hello-World" array=100,200,300- 1

dmesg查看
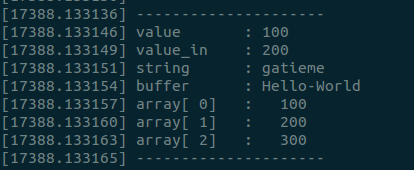
sudo rmmod param- 1

使用modinfo查看参数
modinfo -p param.ko
- 1
- 2
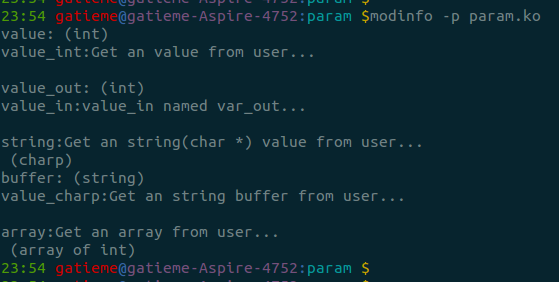
动态修改模块参数
首先查看一下sysfs目录下的本模块参数信息
ls /sys/module/param/parameters- 1
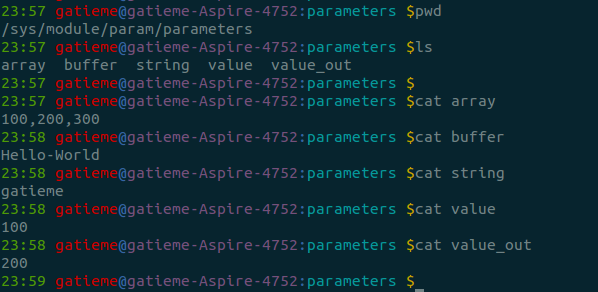
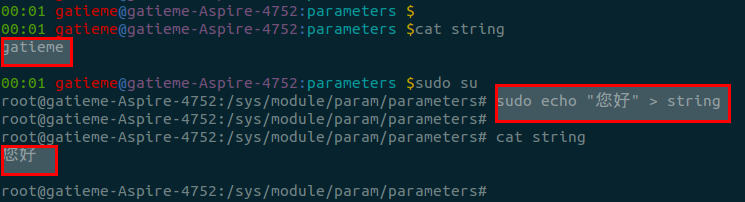
动态修改
Linux 驱动开发之内核模块开发 (一)—— 内核模块机制基础
一、内核模块的概念
1、什么是模块?
内核模块是一些可以让操作系统内核在需要时载入和执行的代码,同时在不需要的时候可以卸载。这是一个好的功能,扩展了操作系统的内核功能,却不需要重新启动系统,是一种动态加载的技术。
特点:动态加载,随时载入,随时卸载,扩展功能
2、内核模块的加载作用
内核模块只是向linux内核预先注册自己,以便于将来的请求使用;由目标代码组成,没有形成完整的可执行程序。只是告诉内核,它有了新增的功能,而并不马上使用(执行),只是等待应用程序的调用;而应用程序在加载后就开始执行。
3、内核模块所用函数
内核模块代码编写没有外部的函数库可以用,只能使用内核导出的函数。而应用程序习惯于使用外部的库函数,在编译时将程序与库函数链接在一起。例如对比printf( ) and printk( )。
所以驱动所用头文件均来自内核源代码,应用程序所用头文件来自库函数。
4、内核模块代码运行空间
内核代码运行在内核空间,而应用程序在用户空间。应用程序的运行会形成新的进程,而内核模块一般不会。每当应用程序执行系统调用时,linux执行模式从用户空间切换到内核空间。
二、linux内核模块的框架
最少两个入口点
*模块加载函数 module_init()
*模块卸载函数 module_exit()
module_init() and module_exit()两个宏定义声明模块的加载函数和卸载函数,这个定义在linux3.14/include/linux/init.h中。内容为:
#define module_init(x) __initcall(x)
//在内核启动或模块加载时执行
#define module_exit(x) __exitcall(x)
//在模块卸载时执行
每一个模块只能有一个module_init 和一个module_exit。
下面我们对比一下应用程序,看看应用程序与内核模块的区别:
|
#include <stdio.h>
int main()
{
printf("Hello World!\n");
return 0;
}
|
#include <linux/module.h> //所有内核模块都必须包含这个头文件
#include<linux/kernel.h> //使用内核信息优先级时要包含这个
#include<linux/init.h> //一些初始化的函数如module_init() static int hello_init(void)
{
printk("hello_init");
}
static void hello_exit(void)
{
printk("hello_exit \n");
}
MODULE_LICENSE("GPL"); //模块许可声明
module_init(hello_init); 加载时候调用该函数insmod
module_exit(hello_exit);卸载时候 rmmod
|
| 应用程序 | 模块 | |
| 入口函数 | main | 加载时候调用hello_init |
| 函数的调用 | /lib | 所有函数可以直接调用 |
| 运行空间 | 用户空间 | 内核空间 |
| 资源的释放 |
系统自动释放
kill -9 pid 手动释放
|
手动释放 |
最顶层的Makefile
s/ Makefile.* 一些Makefile的通用规则
kbuild Makefile 各级目录下的大概约500个文件,编译时根据上层Makefile传下来的宏定义和其他编译规则,将源代码编译成模块或者编入内核
Makefile则提供补充体系结构相关的信息。 s目录下的Makefile文件包含了所有用来根据kbuild Makefile
构建内核所需的定义和规则。(其中.config的内容是在make menuconfig的时候,通过Kconfig文件配置的结果,上面已经说过)
表示要由foo.c或者foo.s文件编译得到foo.o并链接进内核,而obj-m则表示该文件要作为模块编译。除了y,m以外的obj-x形式的目标都不会被编译。
由于既可以编译成模块,也可以编译进内核,更常见的做法是根据.config文件的CONFIG_ 变量来决定文件的编译方式,如:
obj-$(CONFIG_HELLO_MODULE) += hello.o
除了obj-形式的目标以外,还有lib-y library库,hostprogs-y 主机程序等目标,但是基本都应用在特定的目录和场合下
一个内核模块由多个源文件编译而成,这是Makefile有所不同。
采用模块名加 –objs后缀或者 –y后缀的形式来定义模块的组成文件。
如以下例子:
ext2-y := balloc.o bitmap.o
ext2-$(CONFIG_EXT2_FS_XATTR) += xattr.o
直至ext2.ko文件,是否包括xattr.o取决于内核配置文件的配置情况。如果CONFIG_EXT2_FS的值是y也没有关系,在此过程中生成的
ext2.o将被链接进built-in.o最终链接进内核。这里需要注意的一点是,该kbuild
Makefile所在的目录中不应该再包含和模块名相同的源文件如ext2.c/ext2.s
obj-$(CONFIG_EXT2_FS) += ext2/
make -C path/to/kernel/src M=$PWD modules
当你需要将模块安装到非默认位置的时候,你可以用INSTALL_MOD_PATH 指定一个前缀,如:
Linux 驱动开发之内核模块开发 (二)—— 内核模块编译 Makefile 入门
一、模块的编译
我们在前面内核编译中驱动移植那块,讲到驱动编译分为静态编译和动态编译;静态编译即为将驱动直接编译进内核,动态编译即为将驱动编译成模块。
而动态编译又分为两种:
a -- 内部编译
在内核源码目录内编译
b -- 外部编译
在内核源码的目录外编译
二、具体编译过程分析
注:本次编译是外部编译,使用的内核源码是Ubuntu 的源代码,而非开发板所用linux 3.14内核源码,运行平台为X86。
对于一个普通的linux设备驱动模块,以下是一个经典的makefile代码,使用下面这个makefile可以完成大部分驱动的编译,使用时只需要修改一下要编译生成的驱动名称即可。只需修改obj-m的值。
|
ifneq ($(KERNELRELEASE),)
obj-m:=hello.o
else
KDIR := /lib/modules/$(shell uname -r)/build
PWD:=$(shell pwd)
all:
make -C $(KDIR) M=$(PWD) modules
clean:
rm -f *.ko *.o *.symvers *.cmd *.cmd.o
endif
|
1、makefile 中的变量
先说明以下makefile中一些变量意义:
(1)KERNELRELEASE 在linux内核源代码中的顶层makefile中有定义
(2)shell pwd 取得当前工作路径
(3)shell uname -r 取得当前内核的版本号
(4)KDIR 当前内核的源代码目录。
关于linux源码的目录有两个,分别为
"/lib/modules/$(shell uname -r)/build"
"/usr/src/linux-header-$(shell uname -r)/"
但如果编译过内核就会知道,usr目录下那个源代码一般是我们自己下载后解压的,而lib目录下的则是在编译时自动copy过去的,两者的文件结构完全一样,因此有时也将内核源码目录设置成/usr/src/linux-header-$(shell uname -r)/。关于内核源码目录可以根据自己的存放位置进行修改。
(5)make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
这就是编译模块了:
a -- 首先改变目录到-C选项指定的位置(即内核源代码目录),其中保存有内核的顶层makefile;
b -- M=选项让该makefile在构造modules目标之前返回到模块源代码目录;然后,modueles目标指向obj-m变量中设定的模块;在上面的例子中,我们将该变量设置成了hello.o。
2、make 的的执行步骤
a -- 第一次进来的时候,宏“KERNELRELEASE”未定义,因此进入 else;
b -- 记录内核路径,记录当前路径;
由于make 后面没有目标,所以make会在Makefile中的第一个不是以.开头的目标作为默认的目标执行。默认执行all这个规则
c -- make -C $(KDIR) M=$(PWD) modules
-C 进入到内核的目录执行Makefile ,在执行的时候KERNELRELEASE就会被赋值,M=$(PWD)表示返回当前目录,再次执行makefile,modules
编译成模块的意思
所以这里实际运行的是
make -C /lib/modules/2.6.13-study/build M=/home/fs/code/1/module/hello/ modules
d -- 再次执行该makefile,KERNELRELEASE就有值了,就会执行obj-m:=hello.o
obj-m:表示把hello.o 和其他的目标文件链接成hello.ko模块文件,编译的时候还要先把hello.c编译成hello.o文件
可以看出make在这里一共调用了3次
1)-- make
2)-- linux内核源码树的顶层makedile调用,产生。o文件
3)-- linux内核源码树makefile调用,把.o文件链接成ko文件
3、编译多文件
若有多个源文件,则采用如下方法:
obj-m := hello.o
hello-objs := file1.o file2.o file3.o
三、内部编译简单说明
如果把hello模块移动到内核源代码中。例如放到/usr/src/linux/driver/中, KERNELRELEASE就有定义了。
在/usr/src/linux/Makefile中有KERNELRELEASE=$(VERSION).$(PATCHLEVEL).$(SUBLEVEL)$(EXTRAVERSION)$(LOCALVERSION)。
这时候,hello模块也不再是单独用make编译,而是在内核中用make modules进行编译,此时驱动模块便和内核编译在一起。
Linux 驱动开发之内核模块开发 (三)—— 模块传参
一、module_param() 定义
通常在用户态下编程,即应用程序,可以通过main()的来传递命令行参数,而编写一个内核模块,则通过module_param() 来传参。
module_param()宏是Linux 2.6内核中新增的,该宏被定义在include/linux/moduleparam.h文件中,具体定义如下:
#define module_param(name, type, perm) module_param_named(name, name, type, perm)
所以我们通过宏module_param()定义一个模块参数:
module_param(name, type, perm);
参数的意义:
name 既是用户看到的参数名,又是模块内接受参数的变量;
type 表示参数的数据类型,是下列之一:byte, short, ushort, int, uint, long, ulong, charp, bool, invbool;
perm 指定了在sysfs中相应文件的访问权限。访问权限与linux文件访问权限相同的方式管理,如0644,或使用stat.h中的宏如S_IRUGO表示。
0表示完全关闭在sysfs中相对应的项。
二、module_param() 使用方法
module_param()宏不会声明变量,因此在使用宏之前,必须声明变量,典型地用法如下:
static unsigned int int_var = 0;
module_param(int_var, uint, S_IRUGO);
这些必须写在模块源文件的开头部分。即int_var是全局的。也可以使模块源文件内部的变量名与外部的参数名有不同的名字,通过module_param_named()定义。
a -- module_param_named()
module_param_named(name, variable, type, perm);
name 外部(用户空间)可见的参数名;
variable 源文件内部的全局变量名;
type 类型
perm 权限
而module_param通过module_param_named实现,只不过name与variable相同。
例如:
static unsigned int max_test = 9;
module_param_name(maximum_line_test, max_test, int, 0);
b -- 字符串参数
如果模块参数是一个字符串时,通常使用charp类型定义这个模块参数。内核复制用户提供的字符串到内存,并且相对应的变量指向这个字符串。
例如:
static char *name;
module_param(name, charp, 0);
另一种方法是通过宏module_param_string()让内核把字符串直接复制到程序中的字符数组内。
module_param_string(name, string, len, perm);
这里,name是外部的参数名,string是内部的变量名,len是以string命名的buffer大小(可以小于buffer的大小,但是没有意义),perm表示sysfs的访问权限(或者perm是零,表示完全关闭相对应的sysfs项)。
例如:
static char species[BUF_LEN];
module_param_string(specifies, species, BUF_LEN, 0);
c -- 数组参数
数组参数, 用逗号间隔的列表提供的值, 模块加载者也支持. 声明一个数组参数, 使用:
module_param_array(name, type, num, perm);
name 数组的名子(也是参数名),
type
数组元素的类型,
num 一个整型变量,
perm
通常的权限值.
如果数组参数在加载时设置, num被设置成提供的数的个数. 模块加载者拒绝比数组能放下的多的值。
三、使用实例
- #include <linux/init.h>
- #include <linux/module.h>
- #include <linux/moduleparam.h>
- MODULE_LICENSE ("GPL");
- static char *who = "world";
- static int times = 1;
- module_param (times, int, S_IRUSR);
- module_param (who, charp, S_IRUSR);
- static int hello_init (void)
- {
- int i;
- for (i = 0; i < times; i++)
- printk (KERN_ALERT "(%d) hello, %s!\n", i, who);
- return 0;
- }
- static void hello_exit (void)
- {
- printk (KERN_ALERT "Goodbye, %s!\n", who);
- }
- module_init (hello_init);
- module_exit (hello_exit);
编译生成可执行文件hello
# insmod hello.ko who="world" times=5
- #(1) hello, world!
- #(2) hello, world!
- #(3) hello, world!
- #(4) hello, world!
- #(5) hello, world!
- # rmmod hello
- # Goodbye,world!
注:
a -- 如果加载模块hello时,没有输入任何参数,那么who的初始值为"world",times的初始值为1
b -- 同时向指针传递字符串的时候,不能传递这样的字符串 who="hello world!".即字符串中间不能有空格
c --/sys/module/hello/parameters 该目录下生成变量对应的文件节点
Linux 驱动开发之内核模块开发(四)—— 符号表的导出
Linux内核头文件提供了一个方便的方法用来管理符号的对模块外部的可见性,因此减少了命名空间的污染(命名空间的名称可能会与内核其他地方定义的名称冲突),并且适当信息隐藏。 如果你的模块需要输出符号给其他模块使用,应当使用下面的宏定义:
EXPORT_SYMBOL(name);
EXPORT_SYMBOL_GPL(name); //只适用于包含GPL许可权的模块;
这两个宏均用于将给定的符号导出到模块外. _GPL版本的宏定义只能使符号对GPL许可的模块可用。 符号必须在模块文件的全局部分导出,不能在函数中导出,这是因为上述这两个宏将被扩展成一个特殊用途的声明,而该变量必须是全局的。这个变量存储于模块的一个特殊的可执行部分(一个"ELF段" ),在装载时,内核通过这个段来寻找模块导出的变量(感兴趣的读者可以看<linux/module.h>获知更详细的信息)。
一、宏定义EXPORT_SYMBOL分析
1、源码
- <include/linux/moudule.h>
- …….
- #ifndef MODULE_SYMBOL_PREFIX
- #define MODULE_SYMBOL_PREFIX ""
- #endif
- …….
- struct kernel_symbol //内核符号结构
- {
- unsignedlong value; //该符号在内存地址中的地址
- constchar *name; //该符号的名称
- };
- ……
- #define __EXPORT_SYMBOL(sym,sec) \
- externtypeof(sym) sym; \
- __CRC_SYMBOL(sym,sec) \
- staticconst char __kstrtab_##sym[] \
- __attribute__((section(“__ksymtab_strings”),aligned(1))) \
- =MODULE_SYMBOL_PREFIX#sym; \
- staticconst struct kernel_symbol __ksymtab_##sym \
- __used \
- __attribute__((section(“__ksymatab”sec),unused)) \
- ={(unsignedlong)&sym,_kstrab_#sym}
- #define EXPORT_SYMBOL(sym) \
- __EXPOTR_SYMBOL(sym,””)
- #define EXPORT_SYMBOL_GPL(sym) \
- __EXPOTR_SYMBOL(sym,”_gpl”)
- #define EXPORT_SYMBOL(sym) \
- __EXPOTR_SYMBOL(sym,”_gpl_future”)
在分析前,先了解如下相关知识:
1)#运算符,##运算符
通常在宏定义中使用#来创建字符串 #abc就表示字符串”abc”等。
##运算符称为预处理器的粘合剂,用来替换粘合两个不同的符号,
如:#define xName (n) x##n
则xName(4) 则变为x4
2)gcc的 __attribute__ 属性:
__attribute__((section(“section_name”)))的作用是将指定的函数或变量放入到名为”section_name”的段中。
__attribute__属性添加可以在函数或变量定义的时候直接加入在定义语句中。
如:
int myvar__attribute__((section("mydata"))) = 0;
表示定义了整形变量myvar=0;并且将该变量存放到名为”mydata”的section中
关于gcc_attribute详解可以参考:http://blog.sina.com.cn/s/blog_661314940100qujt.html
2、EXPORT_SYMBOL的作用是什么?
EXPORT_SYMBOL标签内定义的函数或者符号对全部内核代码公开,不用修改内核代码就可以在您的内核模块中直接调用,即使用EXPORT_SYMBOL可以将一个函数以符号的方式导出给其他模块使用。
这里要和System.map做一下对比:System.map 中的是连接时的函数地址。连接完成以后,在2.6内核运行过程中,是不知道哪个符号在哪个地址的。
EXPORT_SYMBOL的符号,是把这些符号和对应的地址保存起来,在内核运行的过程中,可以找到这些符号对应的地址。而模块在加载过程中,其本质就是能动态连接到内核,如果在模块中引用了内核或其它模块的符号,就要EXPORT_SYMBOL这些符号,这样才能找到对应的地址连接。
二、 EXPORT_SYMBOL使用方法
第一、在模块函数定义之后使用EXPORT_SYMBOL(函数名)
第二、在调用该函数的模块中使用extern对之声明
第三、首先加载定义该函数的模块,再加载调用该函数的模块
要调用别的模块实现的函数接口和全局变量,就要导出符号 /usr/src/linux-headers-2.6.32-33-generic/Module.symvers
| A | B |
|
static int num =10;
static void show(void)
{
printk("%d \n",num);
}
EXPORT_SYMBOL(show);
|
extern void show(void);
|
函数A先将show() 函数导出,函数B 使用extern 对其声明,要注意:
a -- 编译a模块后,要将 Module.symvers 拷贝到b模块下
b -- 然后才能编译b模块
c -- 加载:先加载a模块,再加载b模块
d -- 卸载:先卸载b模块,再卸载a模块
- #include <linux/module.h>
- static int num =10;
- static void show(void)
- {
- printk("show(),num = %d\n",num);
- }
- static int hello_init(void)
- {
- printk("hello_init");
- return 0;
- }
- static void hello_exit(void)
- {
- printk("hello_exit \n");
- }
- EXPORT_SYMBOL(show);
- MODULE_LICENSE("GPL");
- module_init(hello_init);
- module_exit(hello_exit);
代码b show.c
- #include <linux/module.h>
- extern void show(void);
- static int show_init(void)
- {
- printk("show_init");
- show();
- return 0;
- }
- static void show_exit(void)
- {
- printk("show_exit \n");
- }
- MODULE_LICENSE("GPL");
- module_init(show_init);
- module_exit(show_exit);<strong>
- </strong>
编译后加载模块,卸载模块,可以用 dmesg
查看内核打印信息。
Linux 设备驱动开发 —— Tasklets 机制浅析
一 、Tasklets 机制基础知识点
1、Taklets 机制概念
Tasklets 机制是linux中断处理机制中的软中断延迟机制。通常用于减少中断处理的时间,将本应该是在中断服务程序中完成的任务转化成软中断完成。
为了最大程度的避免中断处理时间过长而导致中断丢失,有时候我们需要把一些在中断处理中不是非常紧急的任务放在后面执行,而让中断处理程序尽快返回。在老版本的 linux 中通常将中断处理分为 top half handler 、 bottom half handler 。利用 top half handler 处理中断必须处理的任务,而 bottom half handler 处理不是太紧急的任务。
但是 linux2.6 以后的 linux 采取了另外一种机制,就是软中断来代替 bottom half handler 的处理。而 tasklet 机制正是利用软中断来完成对驱动 bottom half 的处理。 Linux2.6 中软中断通常只有固定的几种: HI_SOFTIRQ( 高优先级的 tasklet ,一种特殊的 tasklet) 、 TIMER_SOFTIRQ (定时器)、 NET_TX_SOFTIRQ (网口发送)、 NET_RX_SOFTIRQ (网口接收) 、 BLOCK_SOFTIRQ (块设备)、 TASKLET_SOFTIRQ (普通 tasklet )。当然也可以通过直接修改内核自己加入自己的软中断,但是一般来说这是不合理的,软中断的优先级比较高,如果不是在内核处理频繁的任务不建议使用。通常驱动用户使用 tasklet 足够了。
机制流程:当linux接收到硬件中断之后,通过 tasklet 函数来设定软中断被执行的优先程度从而导致软中断处理函数被优先执行的差异性。
特点:tasklet的优先级别较低,而且中断处理过程中可以被打断。但被打断之后,还能进行自我恢复,断点续运行。
2、Tasklets 解决什么问题?
a -- tasklet是I/O驱动程序中实现可延迟函数的首选方法;
b -- tasklet和工作队列是延期执行工作的机制,其实现基于软中断,但他们更易于使用,因而更适合与设备驱动程序...tasklet是“小进程”,执行一些迷你任务,对这些人物使用全功能进程可能比较浪费。
c -- tasklet是并行可执行(但是是锁密集型的)软件中断和旧下半区的一种混合体,这里既谈不上并行性,也谈不上性能。引入tasklet是为了替代原来的下半区。
软中断是将操作推迟到未来时刻执行的最有效的方法。但该延期机制处理起来非常复杂。因为多个处理器可以同时且独立的处理软中断,同一个软中断的处理程序可以在几个CPU上同时运行。对软中断的效率来说,这是一个关键,多处理器系统上的网络实现显然受惠于此。但处理程序的设计必须是完全可重入且线程安全的。另外,临界区必须用自旋锁保护(或其他IPC机制),而这需要大量审慎的考虑。
我自己的理解,由于软中断以ksoftirqd的形式与用户进程共同调度,这将关系到OS整体的性能,因此软中断在Linux内核中也仅仅就几个(网络、时钟、调度以及Tasklet等),在内核编译时确定。软中断这种方法显然不是面向硬件驱动的,而是驱动更上一层:不关心如何从具体的网卡接收数据包,但是从所有的网卡接收的数据包都要经过内核协议栈的处理。而且软中断比较“硬”——数量固定、编译时确定、操作函数必须可重入、需要慎重考虑锁的问题,不适合驱动直接调用,因此Linux内核为驱动直接提供了一种使用软中断的方法,就是tasklet。
软中断和 tasklet 的关系如下图:
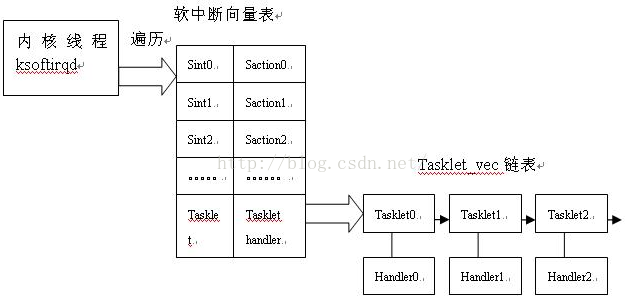
上图可以看出, ksoftirqd
是一个后台运行的内核线程,它会周期的遍历软中断的向量列表,如果发现哪个软中断向量被挂起了( pend ),就执行对应的处理函数,对于
tasklet 来说,此处理函数就是 tasklet_action
,这个处理函数在系统启动时初始化软中断的就挂接了。Tasklet_action 函数,遍历一个全局的 tasklet_vec 链表(此链表对于
SMP 系统是每个 CPU 都有一个),此链表中的元素为 tasklet_struct 。下面将介绍各个函数
二、tasklet数据结构
tasklet通过软中断实现,软中断中有两种类型属于tasklet,分别是级别最高的HI_SOFTIRQ和TASKLET_SOFTIRQ。
Linux内核采用两个PER_CPU的数组tasklet_vec[]和tasklet_hi_vec[]维护系统种的所有tasklet(kernel/softirq.c),分别维护TASKLET_SOFTIRQ级别和HI_SOFTIRQ级别的tasklet:
- struct tasklet_head
- {
- struct tasklet_struct *head;
- struct tasklet_struct *tail;
- };
- static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);
- static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);
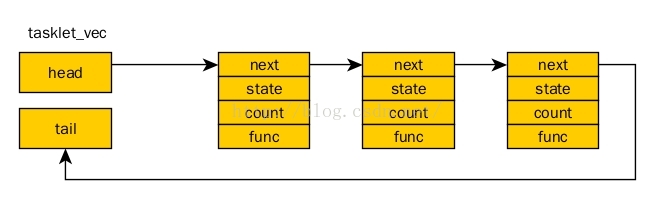
tasklet的核心结构体如下(include/linux/interrupt.h):
- struct tasklet_struct
- {
- struct tasklet_struct *next;
- unsigned long state;
- atomic_t count;
- void (*func)(unsigned long);
- unsigned long data;
- };
各成员的含义如下:
a -- next指针:指向下一个tasklet的指针。
b -- state:定义了这个tasklet的当前状态。这一个32位的无符号长整数,当前只使用了bit[1]和bit[0]两个状态位。其中,bit[1]=1表示这个tasklet当前正在某个CPU上被执行,它仅对SMP系统才有意义,其作用就是为了防止多个CPU同时执行一个tasklet的情形出现;bit[0]=1表示这个tasklet已经被调度去等待执行了。对这两个状态位的宏定义如下所示(interrupt.h)
- enum
- {
- TASKLET_STATE_SCHED,
- TASKLET_STATE_RUN
- };
TASKLET_STATE_SCHED置位表示已经被调度(挂起),也意味着tasklet描述符被插入到了tasklet_vec和tasklet_hi_vec数组的其中一个链表中,可以被执行。TASKLET_STATE_RUN置位表示该tasklet正在某个CPU上执行,单个处理器系统上并不校验该标志,因为没必要检查特定的tasklet是否正在运行。
c -- 原子计数count:对这个tasklet的引用计数值。NOTE!只有当count等于0时,tasklet代码段才能执行,也即此时tasklet是被使能的;如果count非零,则这个tasklet是被禁止的。任何想要执行一个tasklet代码段的人都首先必须先检查其count成员是否为0。
d -- 函数指针func:指向以函数形式表现的可执行tasklet代码段。
e -- data:函数func的参数。这是一个32位的无符号整数,其具体含义可供func函数自行解释,比如将其解释成一个指向某个用户自定义数据结构的地址值。
三、tasklet操作接口
tasklet对驱动开放的常用操作包括:
a -- 初始化,tasklet_init(),初始化一个tasklet描述符。
b -- 调度,tasklet_schedule()和tasklet_hi_schedule(),将taslet置位TASKLET_STATE_SCHED,并尝试激活所在的软中断。
c -- 禁用/启动,tasklet_disable_nosync()、tasklet_disable()、task_enable(),通过count计数器实现。
d -- 执行,tasklet_action()和tasklet_hi_action(),具体的执行软中断。
e -- 杀死,tasklet_kill()
即驱动程序在初始化时,通过函数task_init建立一个tasklet,然后调用函数tasklet_schedule将这个tasklet放在
tasklet_vec链表的头部,并唤醒后台线程ksoftirqd。当后台线程ksoftirqd运行调用__do_softirq时,会执行在中断向量表softirq_vec里中断号TASKLET_SOFTIRQ对应的tasklet_action函数,然后tasklet_action遍历
tasklet_vec链表,调用每个tasklet的函数完成软中断操作。
1、tasklet_int()函数实现如下(kernel/softirq.c)
用来初始化一个指定的tasklet描述符
- void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
- {
- t->next = NULL;
- t->state = 0;
- atomic_set(&t->count, 0);
- t->func = func;
- t->data = data;
- }
2、tasklet_schedule()函数
与tasklet_hi_schedule()函数的实现很类似,这里只列tasklet_schedule()函数的实现(kernel/softirq.c),都挺明白就不描述了:
- static inline void tasklet_schedule(struct tasklet_struct *t)
- {
- if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
- __tasklet_schedule(t);
- }
- void __tasklet_schedule(struct tasklet_struct *t)
- {
- unsigned long flags;
- local_irq_save(flags);
- t->next = NULL;
- *__this_cpu_read(tasklet_vec.tail) = t;
- __this_cpu_write(tasklet_vec.tail, &(t->next));
- raise_softirq_irqoff(TASKLET_SOFTIRQ);
- local_irq_restore(flags);
- }
该函数的参数t指向要在当前CPU上被执行的tasklet。对该函数的NOTE如下:
a --
调用test_and_set_bit()函数将待调度的tasklet的state成员变量的bit[0]位(也即TASKLET_STATE_SCHED位)设置为1,该函数同时还返回TASKLET_STATE_SCHED位的原有值。因此如果bit[0]为的原有值已经为1,那就说明这个tasklet已经被调度到另一个CPU上去等待执行了。由于一个tasklet在某一个时刻只能由一个CPU来执行,因此tasklet_schedule()函数什么也不做就直接返回了。否则,就继续下面的调度操作。
b -- 首先,调用local_irq_save()函数来关闭当前CPU的中断,以保证下面的步骤在当前CPU上原子地被执行。
c -- 然后,将待调度的tasklet添加到当前CPU对应的tasklet队列的首部。
d -- 接着,调用__cpu_raise_softirq()函数在当前CPU上触发软中断请求TASKLET_SOFTIRQ。
e -- 最后,调用local_irq_restore()函数来开当前CPU的中断。
3、tasklet_disable()函数、task_enable()函数以及tasklet_disable_nosync()函数(include/linux/interrupt.h)
使能与禁止操作往往总是成对地被调用的
- static inline void tasklet_disable_nosync(struct tasklet_struct *t)
- {
- atomic_inc(&t->count);
- smp_mb__after_atomic_inc();
- }
- static inline void tasklet_disable(struct tasklet_struct *t)
- {
- tasklet_disable_nosync(t);
- tasklet_unlock_wait(t);
- smp_mb();
- }
- static inline void tasklet_enable(struct tasklet_struct *t)
- {
- smp_mb__before_atomic_dec();
- atomic_dec(&t->count);
- }
4、tasklet_action()函数在softirq_init()函数中被调用:
- void __init softirq_init(void)
- {
- ...
- open_softirq(TASKLET_SOFTIRQ, tasklet_action);
- open_softirq(HI_SOFTIRQ, tasklet_hi_action);
- }
tasklet_action()函数
- static void tasklet_action(struct softirq_action *a)
- {
- struct tasklet_struct *list;
- local_irq_disable();
- list = __this_cpu_read(tasklet_vec.head);
- __this_cpu_write(tasklet_vec.head, NULL);
- __this_cpu_write(tasklet_vec.tail, &__get_cpu_var(tasklet_vec).head);
- local_irq_enable();
- while (list)
- {
- struct tasklet_struct *t = list;
- list = list->next;
- if (tasklet_trylock(t))
- {
- if (!atomic_read(&t->count))
- {
- if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
- BUG();
- t->func(t->data);
- tasklet_unlock(t);
- continue;
- }
- tasklet_unlock(t);
- }
- local_irq_disable();
- t->next = NULL;
- *__this_cpu_read(tasklet_vec.tail) = t;
- __this_cpu_write(tasklet_vec.tail, &(t->next));
- __raise_softirq_irqoff(TASKLET_SOFTIRQ);
- local_irq_enable();
- }
- }
注释如下:
①首先,在当前CPU关中断的情况下,“原子”地读取当前CPU的tasklet队列头部指针,将其保存到局部变量list指针中,然后将当前CPU的tasklet队列头部指针设置为NULL,以表示理论上当前CPU将不再有tasklet需要执行(但最后的实际结果却并不一定如此,下面将会看到)。
②然后,用一个while{}循环来遍历由list所指向的tasklet队列,队列中的各个元素就是将在当前CPU上执行的tasklet。循环体的执行步骤如下:
a -- 用指针t来表示当前队列元素,即当前需要执行的tasklet。
b -- 更新list指针为list->next,使它指向下一个要执行的tasklet。
c -- 用tasklet_trylock()宏试图对当前要执行的tasklet(由指针t所指向)进行加锁
如果加锁成功(当前没有任何其他CPU正在执行这个tasklet),则用原子读函atomic_read()进一步判断count成员的值。如果count为0,说明这个tasklet是允许执行的,于是:
(1)先清除TASKLET_STATE_SCHED位;
(2)然后,调用这个tasklet的可执行函数func;
(3)执行barrier()操作;
(4)调用宏tasklet_unlock()来清除TASKLET_STATE_RUN位。
(5)最后,执行continue语句跳过下面的步骤,回到while循环继续遍历队列中的下一个元素。如果count不为0,说明这个tasklet是禁止运行的,于是调用tasklet_unlock()清除前面用tasklet_trylock()设置的TASKLET_STATE_RUN位。
如果tasklet_trylock()加锁不成功,或者因为当前tasklet的count值非0而不允许执行时,我们必须将这个tasklet重新放回到当前CPU的tasklet队列中,以留待这个CPU下次服务软中断向量TASKLET_SOFTIRQ时再执行。为此进行这样几步操作:
(1)先关CPU中断,以保证下面操作的原子性。
(2)把这个tasklet重新放回到当前CPU的tasklet队列的首部;
(3)调用__cpu_raise_softirq()函数在当前CPU上再触发一次软中断请求TASKLET_SOFTIRQ;
(4)开中断。
c -- 最后,回到while循环继续遍历队列。
5、tasklet_kill()实现
- void tasklet_kill(struct tasklet_struct *t)
- {
- if (in_interrupt())
- printk("Attempt to kill tasklet from interruptn");
- while (test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
- {
- do {
- yield();
- } while (test_bit(TASKLET_STATE_SCHED, &t->state));
- }
- tasklet_unlock_wait(t);
- clear_bit(TASKLET_STATE_SCHED, &t->state);
- }
四、一个tasklet调用例子
找了一个tasklet的例子看一下(drivers/usb/atm,usb摄像头),在其自举函数usbatm_usb_probe()中调用了tasklet_init()初始化了两个tasklet描述符用于接收和发送的“可延迟操作处理”,但此是并没有将其加入到tasklet_vec[]或tasklet_hi_vec[]中:
- tasklet_init(&instance->rx_channel.tasklet,
- usbatm_rx_process, (unsigned long)instance);
- tasklet_init(&instance->tx_channel.tasklet,
- usbatm_tx_process, (unsigned long)instance);
在其发送接口usbatm_atm_send()函数调用tasklet_schedule()函数将所初始化的tasklet加入到当前cpu的tasklet_vec链表尾部,并尝试调用do_softirq_irqoff()执行软中断TASKLET_SOFTIRQ:
- static int usbatm_atm_send(struct atm_vcc *vcc, struct sk_buff *skb)
- {
- ...
- tasklet_schedule(&instance->tx_channel.tasklet);
- ...
- }
在其断开设备的接口usbatm_usb_disconnect()中调用tasklet_disable()函数和tasklet_enable()函数重新启动其收发tasklet(具体原因不详,这个地方可能就是由这个需要,暂时重启收发tasklet):
- void usbatm_usb_disconnect(struct usb_interface *intf)
- {
- ...
- tasklet_disable(&instance->rx_channel.tasklet);
- tasklet_disable(&instance->tx_channel.tasklet);
- ...
- tasklet_enable(&instance->rx_channel.tasklet);
- tasklet_enable(&instance->tx_channel.tasklet);
- ...
- }
在其销毁接口usbatm_destroy_instance()中调用tasklet_kill()函数,强行将该tasklet踢出调度队列。
从上述过程以及tasklet的设计可以看出,tasklet整体是这么运行的:驱动应该在其硬中断处理函数的末尾调用tasklet_schedule()接口激活该tasklet;内核经常调用do_softirq()执行软中断,通过softirq执行tasket,如下图所示。图中灰色部分为禁止硬中断部分,为保护软中断pending位图和tasklet_vec链表数组,count的改变均为原子操作,count确保SMP架构下同时只有一个CPU在执行该tasklet:
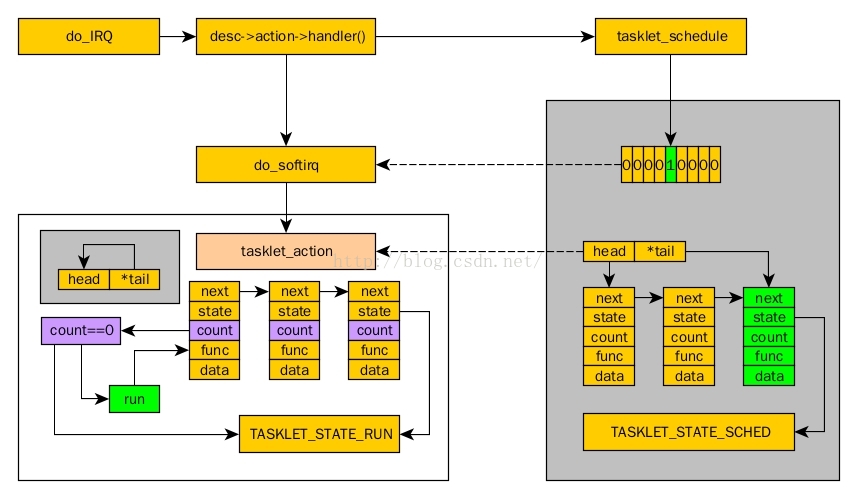
进程上下文、中断上下文及原子上下文
谈论进程上下文 、中断上下文 、 原子上下文之前,有必要讨论下两个概念:
a -- 上下文
上下文是从英文context翻译过来,指的是一种环境。相对于进程而言,就是进程执行时的环境;
具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
b -- 原子
原子(atom)本意是“不能被进一步分割的最小粒子”,而原子操作(atomic operation)意为"不可被中断的一个或一系列操作" ;
一、为什么会有上下文这种概念
内核空间和用户空间是现代操作系统的两种工作模式,内核模块运行在内核空间,而用户态应用程序运行在用户空间。它们代表不同的级别,而对系统资源具有不同的访问权限。内核模块运行在最高级别(内核态),这个级下所有的操作都受系统信任,而应用程序运行在较低级别(用户态)。在这个级别,处理器控制着对硬件的直接访问以及对内存的非授权访问。内核态和用户态有自己的内存映射,即自己的地址空间。
其中处理器总处于以下状态中的一种:
内核态,运行于进程上下文,内核代表进程运行于内核空间;
内核态,运行于中断上下文,内核代表硬件运行于内核空间;
用户态,运行于用户空间。
系统的两种不同运行状态,才有了上下文的概念。用户空间的应用程序,如果想请求系统服务,比如操作某个物理设备,映射设备的地址到用户空间,必须通过系统调用来实现。(系统调用是操作系统提供给用户空间的接口函数)。
通过系统调用,用户空间的应用程序就会进入内核空间,由内核代表该进程运行于内核空间,这就涉及到上下文的切换,用户空间和内核空间具有不同的 地址映射,通用或专用的寄存器组,而用户空间的进程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回到用户 空间继续执行,
二、进程上下文
所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈上的内容,当内核需要切换到另一个进程时,它
需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
用户级上下文: 正文、数据、用户堆栈以及共享存储区;
寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
当发生进程调度时,进行进程切换就是上下文切换(context switch)。
操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。而系统调用进行的是模式切换(mode switch)。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
进程上下文主要是异常处理程序和内核线程。内核之所以进入进程上下文是因为进程自身的一些工作需要在内核中做。例如,系统调用是为当前进程服务的,异常通常是处理进程导致的错误状态等。所以在进程上下文中引用current是有意义的。
三、中断上下文
硬件通过触发信号,向CPU发送中断信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核, 内核通过这些参数进行中断处理。
所以,“中断上下文”就可以理解为硬件传递过来的这些参数和内核需要保存的一些环境,主要是被中断的进程的环境。
内核进入中断上下文是因为中断信号而导致的中断处理或软中断。而中断信号的发生是随机的,中断处理程序及软中断并不能事先预测发生中断时当前运行的是哪个进程,所以在中断上下文中引用current是可以的,但没有意义。
事实上,对于A进程希望等待的中断信号,可能在B进程执行期间发生。例如,A进程启动写磁盘操作,A进程睡眠后B进程在运行,当磁盘写完后磁盘中断信号打断的是B进程,在中断处理时会唤醒A进程。
四、进程上下文 VS 中断上下文
内核可以处于两种上下文:进程上下文和中断上下文。
在系统调用之后,用户应用程序进入内核空间,此后内核空间针对用户空间相应进程的代表就运行于进程上下文。
异步发生的中断会引发中断处理程序被调用,中断处理程序就运行于中断上下文。
中断上下文和进程上下文不可能同时发生。
运行于进程上下文的内核代码是可抢占的,但中断上下文则会一直运行至结束,不会被抢占。因此,内核会限制中断上下文的工作,不允许其执行如下操作:
a -- 进入睡眠状态或主动放弃CPU
由于中断上下文不属于任何进程,它与current没有任何关系(尽管此时current指向被中断的进程),所以中断上下文一旦睡眠或者放弃CPU,将无法被唤醒。所以也叫原子上下文(atomic context)。
b -- 占用互斥体
为了保护中断句柄临界区资源,不能使用mutexes。如果获得不到信号量,代码就会睡眠,会产生和上面相同的情况,如果必须使用锁,则使用spinlock。
c -- 执行耗时的任务
中断处理应该尽可能快,因为内核要响应大量服务和请求,中断上下文占用CPU时间太长会严重影响系统功能。在中断处理例程中执行耗时任务时,应该交由中断处理例程底半部来处理。
d -- 访问用户空间虚拟内存
因为中断上下文是和特定进程无关的,它是内核代表硬件运行在内核空间,所以在中断上下文无法访问用户空间的虚拟地址
e -- 中断处理例程不应该设置成reentrant(可被并行或递归调用的例程)
因为中断发生时,preempt和irq都被disable,直到中断返回。所以中断上下文和进程上下文不一样,中断处理例程的不同实例,是不允许在SMP上并发运行的。
f -- 中断处理例程可以被更高级别的IRQ中断
如果想禁止这种中断,可以将中断处理例程定义成快速处理例程,相当于告诉CPU,该例程运行时,禁止本地CPU上所有中断请求。这直接导致的结果是,由于其他中断被延迟响应,系统性能下降。
五、原子上下文
内核的一个基本原则就是:在中断或者说原子上下文中,内核不能访问用户空间,而且内核是不能睡眠的。也就是说在这种情况下,内核是不能调用有可能引起睡眠的任何函数。一般来讲原子上下文指的是在中断或软中断中,以及在持有自旋锁的时候。内核提供 了四个宏来判断是否处于这几种情况里:
- #define in_irq() (hardirq_count()) //在处理硬中断中
- #define in_softirq() (softirq_count()) //在处理软中断中
- #define in_interrupt() (irq_count()) //在处理硬中断或软中断中
- #define in_atomic() ((preempt_count() & ~PREEMPT_ACTIVE) != 0) //包含以上所有情况
这四个宏所访问的count都是thread_info->preempt_count。这个变量其实是一个位掩码。最低8位表示抢占计数,通常由spin_lock/spin_unlock修改,或程序员强制修改,同时表明内核容许的最大抢占深度是256。
8-15位是软中断计数,通常由local_bh_disable/local_bh_enable修改,同时表明内核容许的最大软中断深度是256。
16-27位是硬中断计数,通常由enter_irq/exit_irq修改,同时表明内核容许的最大硬中断深度是4096。
第28位是PREEMPT_ACTIVE标志。用代码表示就是:
PREEMPT_MASK: 0x000000ff
SOFTIRQ_MASK: 0x0000ff00
HARDIRQ_MASK: 0x0fff0000
凡是上面4个宏返回1得到地方都是原子上下文,是不容许内核访问用户空间,不容许内核睡眠的,不容许调用任何可能引起睡眠的函数。而且代表thread_info->preempt_count不是0,这就告诉内核,在这里面抢占被禁用。
但
是,对于in_atomic()来说,在启用抢占的情况下,它工作的很好,可以告诉内核目前是否持有自旋锁,是否禁用抢占等。但是,在没有启用抢占的情况
下,spin_lock根本不修改preempt_count,所以即使内核调用了spin_lock,持有了自旋锁,in_atomic()仍然会返回
0,错误的告诉内核目前在非原子上下文中。所以凡是依赖in_atomic()来判断是否在原子上下文的代码,在禁抢占的情况下都是有问题的。
Linux的mmap内存映射机制解析
在讲述文件映射的概念时,不可避免的要牵涉到虚存(SVR 4的VM).实际上,文件映射是虚存的中心概念, 文件映射一方面给用户提供了一组措施,好似用户将文件映射到自己地址空间的某个部分,使用简单的内存访问指令读写文件;另一方面,它也可以用于内核的基本组织模式,在这种模式种,内核将整个地址空间视为诸如文件之类的一组不同对象的映射.中的传统文件访问方式是,首先用open系统调用打开文件,然后使用read, write以及lseek等调用进行顺序或者随即的I/O.这种方式是非常低效的,每一次I/O操作都需要一次系统调用.另外,如果若干个进程访问同一个文件,每个进程都要在自己的地址空间维护一个副本,浪费了内存空间.而如果能够通过一定的机制将页面映射到进程的地址空间中,也就是说首先通过简单的产生某些内存管理数据结构完成映射的创建.当进程访问页面时产生一个缺页中断,内核将页面读入内存并且更新页表指向该页面.而且这种方式非常方便于同一副本的共享.
VM是面向对象的方法设计的,这里的对象是指内存对象:内存对象是一个软件抽象的概念,它描述内存区与后备存储之间的映射.系统可以使用多种类型的后备存储,比如交换空间,本地或者远程文件以及帧缓存等等. VM系统对它们统一处理,采用同一操作集操作,比如读取页面或者回写页面等.每种不同的后备存储都可以用不同的方法实现这些操作.这样,系统定义了一套统一的接口,每种后备存储给出自己的实现方法.这样,进程的地址空间就被视为一组映射到不同数据对象上的的映射组成.所有的有效地址就是那些映射到数据对象上的地址.这些对象为映射它的页面提供了持久性的后备存储.映射使得用户可以直接寻址这些对象.
值得提出的是, VM体系结构独立于Unix系统,所有的Unix系统语义,如正文,数据及堆栈区都可以建构在基本VM系统之上.同时, VM体系结构也是独立于存储管理的,存储管理是由操作系统实施的,如:究竟采取什么样的对换和请求调页算法,究竟是采取分段还是分页机制进行存储管理,究竟是如何将虚拟地址转换成为物理地址等等(Linux中是一种叫Three Level Page Table的机制),这些都与内存对象的概念无关.
一、Linux中VM的实现.
一个进程应该包括一个mm_struct(memory manage struct), 该结构是进程虚拟地址空间的抽象描述,里面包括了进程虚拟空间的一些管理信息: start_code, end_code, start_data, end_data, start_brk, end_brk等等信息.另外,也有一个指向进程虚存区表(vm_area_struct: virtual memory area)的指针,该链是按照虚拟地址的增长顺序排列的.在Linux进程的地址空间被分作许多区(vma),每个区(vma)都对应虚拟地址空间上一段连续的区域, vma是可以被共享和保护的独立实体,这里的vma就是前面提到的内存对象.
下面是vm_area_struct的结构,其中,前半部分是公共的,与类型无关的一些数据成员,如:指向mm_struct的指针,地址范围等等,后半部分则是与类型相关的成员,其中最重要的是一个指向vm_operation_struct向量表的指针vm_ops, vm_pos向量表是一组虚函数,定义了与vma类型无关的接口.每一个特定的子类,即每种vma类型都必须在向量表中实现这些操作.这里包括了: open, close, unmap, protect, sync, nopage, wppage, swapout这些操作.
- struct vm_area_struct {
- /*公共的, 与vma类型无关的 */
- struct mm_struct * vm_mm;
- unsigned long vm_start;
- unsigned long vm_end;
- struct vm_area_struct *vm_next;
- pgprot_t vm_page_prot;
- unsigned long vm_flags;
- short vm_avl_height;
- struct vm_area_struct * vm_avl_left;
- struct vm_area_struct * vm_avl_right;
- struct vm_area_struct *vm_next_share;
- struct vm_area_struct **vm_pprev_share;
- /* 与类型相关的 */
- struct vm_operations_struct * vm_ops;
- unsigned long vm_pgoff;
- struct file * vm_file;
- unsigned long vm_raend;
- void * vm_private_data;
- };
vm_ops: open, close, no_page, swapin, swapout……
二、驱动中的mmap()函数解析
设备驱动的mmap实现主要是将一个物理设备的可操作区域(设备空间)映射到一个进程的虚拟地址空间。这样就可以直接采用指针的方式像访问内存的方式访问设备。在驱动中的mmap实现主要是完成一件事,就是实际物理设备的操作区域到进程虚拟空间地址的映射过程。同时也需要保证这段映射的虚拟存储器区域不会被进程当做一般的空间使用,因此需要添加一系列的保护方式。
- /*主要是建立虚拟地址到物理地址的页表关系,其他的过程又内核自己完成*/
- static int mem_mmap(struct file* filp,struct vm_area_struct *vma)
- {
- /*间接的控制设备*/
- struct mem_dev *dev = filp->private_data;
- /*标记这段虚拟内存映射为IO区域,并阻止系统将该区域包含在进程的存放转存中*/
- vma->vm_flags |= VM_IO;
- /*标记这段区域不能被换出*/
- vma->vm_flags |= VM_RESERVED;
- /**/
- if(remap_pfn_range(vma,/*虚拟内存区域*/
- vma->vm_start, /*虚拟地址的起始地址*/
- virt_to_phys(dev->data)>>PAGE_SHIFT, /*物理存储区的物理页号*/
- dev->size, /*映射区域大小*/
- vma->vm_page_prot /*虚拟区域保护属性*/
- ))
- return -EAGAIN;
- return 0;
- }
具体的实现分析如下:
vma->vm_flags |= VM_IO;
vma->vm_flags |= VM_RESERVED;
上面的两个保护机制就说明了被映射的这段区域具有映射IO的相似性,同时保证这段区域不能随便的换出。就是建立一个物理页与虚拟页之间的关联性。具体原理是虚拟页和物理页之间是以页表的方式关联起来,虚拟内存通常大于物理内存,在使用过程中虚拟页通过页表关联一切对应的物理页,当物理页不够时,会选择性的牺牲一些页,也就是将物理页与虚拟页之间切断,重现关联其他的虚拟页,保证物理内存够用。在设备驱动中应该具体的虚拟页和物理页之间的关系应该是长期的,应该保护起来,不能随便被别的虚拟页所替换。具体也可参看关于虚拟存储器的文章。
接下来就是建立物理页与虚拟页之间的关系,即采用函数remap_pfn_range(),具体的参数如下:
int remap_pfn_range(structvm_area_struct *vma, unsigned long addr,unsigned long pfn, unsigned long size, pgprot_t prot)
1、struct vm_area_struct是一个虚拟内存区域结构体,表示虚拟存储器中的一个内存区域。其中的元素vm_start是指虚拟存储器中的起始地址。
2、addr也就是虚拟存储器中的起始地址,通常可以选择addr = vma->vm_start。
3、pfn是指物理存储器的具体页号,通常通过物理地址得到对应的物理页号,具体采用virt_to_phys(dev->data)>>PAGE_SHIFT.首先将虚拟内存转换到物理内存,然后得到页号。>>PAGE_SHIFT通常为12,这是因为每一页的大小刚好是4K,这样右移12相当于除以4096,得到页号。
4、size区域大小
5、区域保护机制。
返回值,如果成功返回0,否则正数。
三、系统调用mmap函数解析
介绍完VM的基本概念后,我们可以讲述mmap和munmap系统调用了.mmap调用实际上就是一个内存对象vma的创建过程,
1、mmap函数
Linux提供了内存映射函数mmap,它把文件内容映射到一段内存上(准确说是虚拟内存上),通过对这段内存的读取和修改,实现对文件的读取和修改 。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问,不必再调用read(),write()等操作。
先来看一下mmap的函数声明:
- 头文件:
- <unistd.h>
- <sys/mman.h>
- 原型: void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offsize);
- /*
- 返回值: 成功则返回映射区起始地址, 失败则返回MAP_FAILED(-1).
- 参数:
- addr: 指定映射的起始地址, 通常设为NULL, 由系统指定.
- length: 将文件的多大长度映射到内存.
- prot: 映射区的保护方式, 可以是:
- PROT_EXEC: 映射区可被执行.
- PROT_READ: 映射区可被读取.
- PROT_WRITE: 映射区可被写入.
- PROT_NONE: 映射区不能存取.
- flags: 映射区的特性, 可以是:
- MAP_SHARED: 对映射区域的写入数据会复制回文件, 且允许其他映射该文件的进程共享.
- MAP_PRIVATE: 对映射区域的写入操作会产生一个映射的复制(copy-on-write), 对此区域所做的修改不会写回原文件.
- 此外还有其他几个flags不很常用, 具体查看linux C函数说明.
- fd: 由open返回的文件描述符, 代表要映射的文件.
- offset: 以文件开始处的偏移量, 必须是分页大小的整数倍, 通常为0, 表示从文件头开始映射.
- */
mmap的作用是映射文件描述符fd指定文件的 [off,off + len]区域至调用进程的[addr, addr + len]的内存区域, 如下图所示:
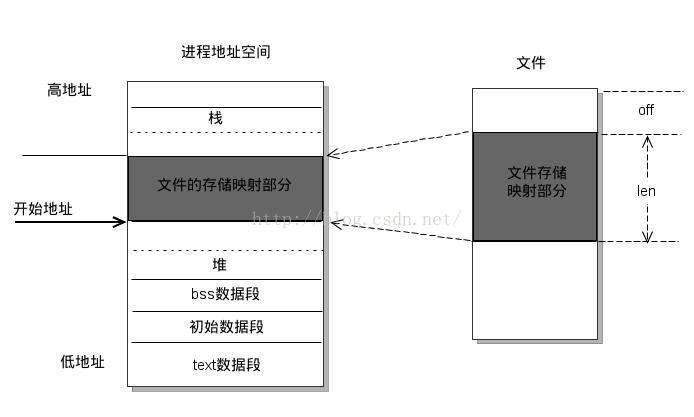
mmap系统调用的实现过程是
1.先通过文件系统定位要映射的文件;
2.权限检查,映射的权限不会超过文件打开的方式,也就是说如果文件是以只读方式打开,那么则不允许建立一个可写映射;
3.创建一个vma对象,并对之进行初始化;
4.调用映射文件的mmap函数,其主要工作是给vm_ops向量表赋值;
5.把该vma链入该进程的vma链表中,如果可以和前后的vma合并则合并;
6.如果是要求VM_LOCKED(映射区不被换出)方式映射,则发出缺页请求,把映射页面读入内存中.
2、munmap函数
munmap(void * start, size_t length):
该调用可以看作是mmap的一个逆过程.它将进程中从start开始length长度的一段区域的映射关闭,如果该区域不是恰好对应一个vma,则有可能会分割几个或几个vma.
msync(void * start, size_t length, int flags):
把映射区域的修改回写到后备存储中.因为munmap时并不保证页面回写,如果不调用msync,那么有可能在munmap后丢失对映射区的修改.其中flags可以是MS_SYNC,
MS_ASYNC, MS_INVALIDATE, MS_SYNC要求回写完成后才返回, MS_ASYNC发出回写请求后立即返回, MS_INVALIDATE使用回写的内容更新该文件的其它映射.该系统调用是通过调用映射文件的sync函数来完成工作的.
brk(void * end_data_segement):
将进程的数据段扩展到end_data_segement指定的地址,该系统调用和mmap的实现方式十分相似,同样是产生一个vma,然后指定其属性.不过在此之前需要做一些合法性检查,比如该地址是否大于mm->end_code,
end_data_segement和mm->brk之间是否还存在其它vma等等.通过brk产生的vma映射的文件为空,这和匿名映射产生的vma相似,关于匿名映射不做进一步介绍.库函数malloc就是通过brk实现的.
四、实例解析
下面这个例子显示了把文件映射到内存的方法,源代码是:
- /************关于本文 档********************************************
- *filename: mmap.c
- *purpose: 说明调用mmap把文件映射到内存的方法
- *wrote by: zhoulifa(zhoulifa@163.com) 周立发(http://zhoulifa.bokee.com)
- Linux爱好者 Linux知识传播者 SOHO族 开发者 最擅长C语言
- *date time:2008-01-27 18:59 上海大雪天,据说是多年不遇
- *Note: 任何人可以任意复制代码并运用这些文档,当然包括你的商业用途
- * 但请遵循GPL
- *Thanks to:
- * Ubuntu 本程序在Ubuntu 7.10系统上测试完全正常
- * Google.com 我通常通过google搜索发现许多有用的资料
- *Hope:希望越来越多的人贡献自己的力量,为科学技术发展出力
- * 科技站在巨人的肩膀上进步更快!感谢有开源前辈的贡献!
- *********************************************************************/
- #include <sys/mman.h> /* for mmap and munmap */
- #include <sys/types.h> /* for open */
- #include <sys/stat.h> /* for open */
- #include <fcntl.h> /* for open */
- #include <unistd.h> /* for lseek and write */
- #include <stdio.h>
- int main(int argc, char **argv)
- {
- int fd;
- char *mapped_mem, * p;
- int flength = 1024;
- void * start_addr = 0;
- fd = open(argv[1], O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
- flength = lseek(fd, 1, SEEK_END);
- write(fd, "\0", 1); /* 在文件最后添加一个空字符,以便下面printf正常工作 */
- lseek(fd, 0, SEEK_SET);
- mapped_mem = mmap(start_addr, flength, PROT_READ, //允许读
- MAP_PRIVATE, //不允许其它进程访问此内存区域
- fd, 0);
- /* 使用映射区域. */
- printf("%s\n", mapped_mem); /* 为了保证这里工作正常,参数传递的文件名最好是一个文本文件 */
- close(fd);
- munmap(mapped_mem, flength);
- return 0;
- }
编译运行此程序:
gcc -Wall mmap.c
./a.out text_filename
上面的方法因为用了PROT_READ,所以只能读取文件里的内容,不能修改,如果换成PROT_WRITE就可以修改文件的内容了。又由于 用了MAAP_PRIVATE所以只能此进程使用此内存区域,如果换成MAP_SHARED,则可以被其它进程访问,比如下面的
- #include <sys/mman.h> /* for mmap and munmap */
- #include <sys/types.h> /* for open */
- #include <sys/stat.h> /* for open */
- #include <fcntl.h> /* for open */
- #include <unistd.h> /* for lseek and write */
- #include <stdio.h>
- #include <string.h> /* for memcpy */
- int main(int argc, char **argv)
- {
- int fd;
- char *mapped_mem, * p;
- int flength = 1024;
- void * start_addr = 0;
- fd = open(argv[1], O_RDWR | O_CREAT, S_IRUSR | S_IWUSR);
- flength = lseek(fd, 1, SEEK_END);
- write(fd, "\0", 1); /* 在文件最后添加一个空字符,以便下面printf正常工作 */
- lseek(fd, 0, SEEK_SET);
- start_addr = 0x80000;
- mapped_mem = mmap(start_addr, flength, PROT_READ|PROT_WRITE, //允许写入
- MAP_SHARED, //允许其它进程访问此内存区域
- fd, 0);
- * 使用映射区域. */
- printf("%s\n", mapped_mem); /* 为了保证这里工作正常,参数传递的文件名最好是一个文本文 */
- while((p = strstr(mapped_mem, "Hello"))) { /* 此处来修改文件 内容 */
- memcpy(p, "Linux", 5);
- p += 5;
- }
- close(fd);
- munmap(mapped_mem, flength);
- return 0;
- }
五、mmap和共享内存对比
共享内存允许两个或多个进程共享一给定的存储区,因为数据不需要来回复制,所以是最快的一种进程间通信机制。共享内存可以通过mmap()映射普通文件(特殊情况下还可以采用匿名映射)机制实现,也可以通过系统V共享内存机制实现。应用接口和原理很简单,内部机制复杂。为了实现更安全通信,往往还与信号灯等同步机制共同使用。
对比如下:
mmap机制:就是在磁盘上建立一个文件,每个进程存储器里面,单独开辟一个空间来进行映射。如果多进程的话,那么不会对实际的物理存储器(主存)消耗太大。
shm机制:每个进程的共享内存都直接映射到实际物理存储器里面。
1、mmap保存到实际硬盘,实际存储并没有反映到主存上。优点:储存量可以很大(多于主存);缺点:进程间读取和写入速度要比主存的要慢。
2、shm保存到物理存储器(主存),实际的储存量直接反映到主存上。优点,进程间访问速度(读写)比磁盘要快;缺点,储存量不能非常大(多于主存)
使用上看:如果分配的存储量不大,那么使用shm;如果存储量大,那么使用mmap。
Linux 下的DMA浅析
DMA是一种无需CPU的参与就可以让外设和系统内存之间进行双向数据传输的硬件机制。使用DMA可以使系统CPU从实际的I/O数据传输过程中摆脱出来,从而大大提高系统的吞吐率。DMA经常与硬件体系结构特别是外设的总线技术密切相关。
一、DMA控制器硬件结构
DMA允许外围设备和主内存之间直接传输 I/O 数据, DMA 依赖于系统。每一种体系结构DMA传输不同,编程接口也不同。
数据传输可以以两种方式触发:一种软件请求数据,另一种由硬件异步传输。
a -- 软件请求数据
调用的步骤可以概括如下(以read为例):
(1)在进程调用 read 时,驱动程序的方法分配一个 DMA 缓冲区,随后指示硬件传送它的数据。进程进入睡眠。
(2)硬件将数据写入 DMA 缓冲区并在完成时产生一个中断。
(3)中断处理程序获得输入数据,应答中断,最后唤醒进程,该进程现在可以读取数据了。
b -- 由硬件异步传输
在 DMA 被异步使用时发生的。以数据采集设备为例:
(1)硬件发出中断来通知新的数据已经到达。
(2)中断处理程序分配一个DMA缓冲区。
(3)外围设备将数据写入缓冲区,然后在完成时发出另一个中断。
(4)处理程序利用DMA分发新的数据,唤醒任何相关进程。
网卡传输也是如此,网卡有一个循环缓冲区(通常叫做 DMA 环形缓冲区)建立在与处理器共享的内存中。每一个输入数据包被放置在环形缓冲区中下一个可用缓冲区,并且发出中断。然后驱动程序将网络数据包传给内核的其它部分处理,并在环形缓冲区中放置一个新的 DMA 缓冲区。
驱动程序在初始化时分配DMA缓冲区,并使用它们直到停止运行。
二、DMA通道使用的地址
DMA通道用dma_chan结构数组表示,这个结构在kernel/dma.c中,列出如下:
- struct dma_chan {
- int lock;
- const char *device_id;
- };
- static struct dma_chan dma_chan_busy[MAX_DMA_CHANNELS] = {
- [4] = { 1, "cascade" },
- };
如果dma_chan_busy[n].lock != 0表示忙,DMA0保留为DRAM更新用,DMA4用作级联。DMA 缓冲区的主要问题是,当它大于一页时,它必须占据物理内存中的连续页。
由于DMA需要连续的内存,因而在引导时分配内存或者为缓冲区保留物理 RAM 的顶部。在引导时给内核传递一个"mem="参数可以保留 RAM
的顶部。例如,如果系统有 32MB 内存,参数"mem=31M"阻止内核使用最顶部的一兆字节。稍后,模块可以使用下面的代码来访问这些保留的内存:
dmabuf = ioremap( 0x1F00000 /* 31M */, 0x100000 /* 1M */);
分配 DMA 空间的方法,代码调用 kmalloc(GFP_ATOMIC) 直到失败为止,然后它等待内核释放若干页面,接下来再一次进行分配。最终会发现由连续页面组成的DMA 缓冲区的出现。
一个使用 DMA 的设备驱动程序通常会与连接到接口总线上的硬件通讯,这些硬件使用物理地址,而程序代码使用虚拟地址。基于 DMA
的硬件使用总线地址而不是物理地址,有时,接口总线是通过将 I/O
地址映射到不同物理地址的桥接电路连接的。甚至某些系统有一个页面映射方案,能够使任意页面在外围总线上表现为连续的。
当驱动程序需要向一个 I/O 设备(例如扩展板或者DMA控制器)发送地址信息时,必须使用 virt_to_bus 转换,在接受到来自连接到总线上硬件的地址信息时,必须使用 bus_to_virt 了。
三、DMA操作函数
写一个DMA驱动的主要工作包括:DMA通道申请、DMA中断申请、控制寄存器设置、挂入DMA等待队列、清除DMA中断、释放DMA通道
因为 DMA 控制器是一个系统级的资源,所以内核协助处理这一资源。内核使用 DMA 注册表为 DMA 通道提供了请求/释放机制,并且提供了一组函数在 DMA 控制器中配置通道信息。
以下具体分析关键函数(linux/arch/arm/mach-s3c2410/dma.c)
- int s3c2410_request_dma(const char *device_id, dmach_t channel,
- dma_callback_t write_cb, dma_callback_t read_cb) (s3c2410_dma_queue_buffer);
- /*
- 函数描述:申请某通道的DMA资源,填充s3c2410_dma_t 数据结构的内容,申请DMA中断。
- 输入参数:device_id DMA 设备名;channel 通道号;
- write_cb DMA写操作完成的回调函数;read_cb DMA读操作完成的回调函数
- 输出参数:若channel通道已使用,出错返回;否则,返回0
- */
- int s3c2410_dma_queue_buffer(dmach_t channel, void *buf_id,
- dma_addr_t data, int size, int write) (s3c2410_dma_stop);
- /*
- 函数描述:这是DMA操作最关键的函数,它完成了一系列动作:分配并初始化一个DMA内核缓冲区控制结构,并将它插入DMA等待队列,设置DMA控制寄存器内容,等待DMA操作触发
- 输入参数: channel 通道号;buf_id,缓冲区标识
- dma_addr_t data DMA数据缓冲区起始物理地址;size DMA数据缓冲区大小;write 是写还是读操作
- 输出参数:操作成功,返回0;否则,返回错误号
- */
- int s3c2410_dma_stop(dmach_t channel)
- //函数描述:停止DMA操作。
- int s3c2410_dma_flush_all(dmach_t channel)
- //函数描述:释放DMA通道所申请的所有内存资源
- void s3c2410_free_dma(dmach_t channel)
- //函数描述:释放DMA通道
四、DMA映射
一个DMA映射就是分配一个 DMA 缓冲区并为该缓冲区生成一个能够被设备访问的地址的组合操作。一般情况下,简单地调用函数virt_to_bus
就设备总线上的地址,但有些硬件映射寄存器也被设置在总线硬件中。映射寄存器(mapping
register)是一个类似于外围设备的虚拟内存等价物。在使用这些寄存器的系统上,外围设备有一个相对较小的、专用的地址区段,可以在此区段执行
DMA。通过映射寄存器,这些地址被重映射到系统
RAM。映射寄存器具有一些好的特性,包括使分散的页面在设备地址空间看起来是连续的。但不是所有的体系结构都有映射寄存器,特别地,PC
平台没有映射寄存器。
在某些情况下,为设备设置有用的地址也意味着需要构造一个反弹(bounce)缓冲区。例如,当驱动程序试图在一个不能被外围设备访问的地址(一个高端内存地址)上执行
DMA 时,反弹缓冲区被创建。然后,按照需要,数据被复制到反弹缓冲区,或者从反弹缓冲区复制。
根据 DMA 缓冲区期望保留的时间长短,PCI 代码区分两种类型的 DMA 映射:
a -- 一致 DMA 映射
它们存在于驱动程序的生命周期内。一个被一致映射的缓冲区必须同时可被 CPU 和外围设备访问,这个缓冲区被处理器写时,可立即被设备读取而没有cache效应,反之亦然,使用函数pci_alloc_consistent建立一致映射。
b -- 流式 DMA映射
流式DMA映射是为单个操作进行的设置。它映射处理器虚拟空间的一块地址,以致它能被设备访问。应尽可能使用流式映射,而不是一致映射。这是因为在支持一致映射的系统上,每个
DMA
映射会使用总线上一个或多个映射寄存器。具有较长生命周期的一致映射,会独占这些寄存器很长时间――即使它们没有被使用。使用函数dma_map_single建立流式映射。
1、建立一致 DMA 映射
函数pci_alloc_consistent处理缓冲区的分配和映射,函数分析如下(在include/asm-generic/pci-dma-compat.h中):
- static inline void *pci_alloc_consistent(struct pci_dev *hwdev,
- size_t size, dma_addr_t *dma_handle)
- {
- return dma_alloc_coherent(hwdev == NULL ? NULL : &hwdev->dev,
- size, dma_handle, GFP_ATOMIC);
- }
结构dma_coherent_mem定义了DMA一致性映射的内存的地址、大小和标识等。结构dma_coherent_mem列出如下(在arch/i386/kernel/pci-dma.c中):
- struct dma_coherent_mem {
- void *virt_base;
- u32 device_base;
- int size;
- int flags;
- unsigned long *bitmap;
- };
函数dma_alloc_coherent分配size字节的区域的一致内存,得到的dma_handle是指向分配的区域的地址指针,这个地址作为区域的物理基地址。dma_handle是与总线一样的位宽的无符号整数。
函数dma_alloc_coherent分析如下(在arch/i386/kernel/pci-dma.c中):
- void *dma_alloc_coherent(struct device *dev, size_t size,
- dma_addr_t *dma_handle, int gfp)
- {
- void *ret;
- //若是设备,得到设备的dma内存区域,即mem= dev->dma_mem
- struct dma_coherent_mem *mem = dev ? dev->dma_mem : NULL;
- int order = get_order(size);//将size转换成order,即
- //忽略特定的区域,因而忽略这两个标识
- gfp &= ~(__GFP_DMA | __GFP_HIGHMEM);
- if (mem) {//设备的DMA映射,mem= dev->dma_mem
- //找到mem对应的页
- int page = bitmap_find_free_region(mem->bitmap, mem->size,
- order);
- if (page >= 0) {
- *dma_handle = mem->device_base + (page << PAGE_SHIFT);
- ret = mem->virt_base + (page << PAGE_SHIFT);
- memset(ret, 0, size);
- return ret;
- }
- if (mem->flags & DMA_MEMORY_EXCLUSIVE)
- return NULL;
- }
- //不是设备的DMA映射
- if (dev == NULL || (dev->coherent_dma_mask < 0xffffffff))
- gfp |= GFP_DMA;
- //分配空闲页
- ret = (void *)__get_free_pages(gfp, order);
- if (ret != NULL) {
- memset(ret, 0, size);//清0
- *dma_handle = virt_to_phys(ret);//得到物理地址
- }
- return ret;
- }
当不再需要缓冲区时(通常在模块卸载时),应该调用函数 pci_free_consitent 将它返还给系统。
2、建立流式 DMA 映射
在流式 DMA 映射的操作中,缓冲区传送方向应匹配于映射时给定的方向值。缓冲区被映射后,它就属于设备而不再属于处理器了。在缓冲区调用函数pci_unmap_single撤销映射之前,驱动程序不应该触及其内容。
在缓冲区为 DMA 映射时,内核必须确保缓冲区中所有的数据已经被实际写到内存。可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新。在刷新之后,由处理器写入缓冲区的数据对设备来说也许是不可见的。
如果欲映射的缓冲区位于设备不能访问的内存区段时,某些体系结构仅仅会操作失败,而其它的体系结构会创建一个反弹缓冲区。反弹缓冲区是被设备访问的独立内存区域,反弹缓冲区复制原始缓冲区的内容。
函数pci_map_single映射单个用于传送的缓冲区,返回值是可以传递给设备的总线地址,如果出错的话就为 NULL。一旦传送完成,应该使用函数pci_unmap_single 删除映射。其中,参数direction为传输的方向,取值如下:
PCI_DMA_TODEVICE 数据被发送到设备。
PCI_DMA_FROMDEVICE如果数据将发送到 CPU。
PCI_DMA_BIDIRECTIONAL数据进行两个方向的移动。
PCI_DMA_NONE 这个符号只是为帮助调试而提供。
函数pci_map_single分析如下(在arch/i386/kernel/pci-dma.c中)
- static inline dma_addr_t pci_map_single(struct pci_dev *hwdev,
- void *ptr, size_t size, int direction)
- {
- return dma_map_single(hwdev == NULL ? NULL : &hwdev->dev, ptr, size,
- (enum ma_data_direction)direction);
- }
函数dma_map_single映射一块处理器虚拟内存,这块虚拟内存能被设备访问,返回内存的物理地址,函数dma_map_single分析如下(在include/asm-i386/dma-mapping.h中):
- static inline dma_addr_t dma_map_single(struct device *dev, void *ptr,
- size_t size, enum dma_data_direction direction)
- {
- BUG_ON(direction == DMA_NONE);
- //可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新
- flush_write_buffers();
- return virt_to_phys(ptr); //虚拟地址转化为物理地址
- }
3、分散/集中映射
分散/集中映射是流式 DMA 映射的一个特例。它将几个缓冲区集中到一起进行一次映射,并在一个 DMA 操作中传送所有数据。这些分散的缓冲区由分散表结构scatterlist来描述,多个分散的缓冲区的分散表结构组成缓冲区的struct scatterlist数组。
分散表结构列出如下(在include/asm-i386/scatterlist.h):
- struct scatterlist {
- struct page *page;
- unsigned int offset;
- dma_addr_t dma_address; //用在分散/集中操作中的缓冲区地址
- unsigned int length;//该缓冲区的长度
- };
每一个缓冲区的地址和长度会被存储在 struct scatterlist 项中,但在不同的体系结构中它们在结构中的位置是不同的。下面的两个宏定义来解决平台移植性问题,这些宏定义应该在一个pci_map_sg 被调用后使用:
- //从该分散表项中返回总线地址
- #define sg_dma_address(sg) �sg)->dma_address)
- //返回该缓冲区的长度
- #define sg_dma_len(sg) �sg)->length)
函数pci_map_sg完成分散/集中映射,其返回值是要传送的 DMA 缓冲区数;它可能会小于 nents(也就是传入的分散表项的数量),因为可能有的缓冲区地址上是相邻的。一旦传输完成,分散/集中映射通过调用函数pci_unmap_sg
来撤销映射。 函数pci_map_sg分析如下(在include/asm-generic/pci-dma-compat.h中):
- static inline int pci_map_sg(struct pci_dev *hwdev, struct scatterlist *sg,
- int nents, int direction)
- {
- return dma_map_sg(hwdev == NULL ? NULL : &hwdev->dev, sg, nents,
- (enum dma_data_direction)direction);
- }
- include/asm-i386/dma-mapping.h
- static inline int dma_map_sg(struct device *dev, struct scatterlist *sg,
- int nents, enum dma_data_direction direction)
- {
- int i;
- BUG_ON(direction == DMA_NONE);
- for (i = 0; i < nents; i++ ) {
- BUG_ON(!sg[i].page);
- //将页及页偏移地址转化为物理地址
- sg[i].dma_address = page_to_phys(sg[i].page) + sg[i].offset;
- }
- //可能有些数据还会保留在处理器的高速缓冲存储器中,因此必须显式刷新
- flush_write_buffers();
- return nents;
- }
五、DMA池
许多驱动程序需要又多又小的一致映射内存区域给DMA描述子或I/O缓存buffer,这使用DMA池比用dma_alloc_coherent分配的一页或多页内存区域好,DMA池用函数dma_pool_create创建,用函数dma_pool_alloc从DMA池中分配一块一致内存,用函数dmp_pool_free放内存回到DMA池中,使用函数dma_pool_destory释放DMA池的资源。
结构dma_pool是DMA池描述结构,列出如下:
- struct dma_pool { /* the pool */
- struct list_head page_list;//页链表
- spinlock_t lock;
- size_t blocks_per_page; //每页的块数
- size_t size; //DMA池里的一致内存块的大小
- struct device *dev; //将做DMA的设备
- size_t allocation; //分配的没有跨越边界的块数,是size的整数倍
- char name [32]; //池的名字
- wait_queue_head_t waitq; //等待队列
- struct list_head pools;
- };
函数dma_pool_create给DMA创建一个一致内存块池,其参数name是DMA池的名字,用于诊断用,参数dev是将做DMA的设备,参数size是DMA池里的块的大小,参数align是块的对齐要求,是2的幂,参数allocation返回没有跨越边界的块数(或0)。
函数dma_pool_create返回创建的带有要求字符串的DMA池,若创建失败返回null。对被给的DMA池,函数dma_pool_alloc被用来分配内存,这些内存都是一致DMA映射,可被设备访问,且没有使用缓存刷新机制,因为对齐原因,分配的块的实际尺寸比请求的大。如果分配非0的内存,从函数dma_pool_alloc返回的对象将不跨越size边界(如不跨越4K字节边界)。这对在个体的DMA传输上有地址限制的设备来说是有利的。
函数dma_pool_create分析如下(在drivers/base/dmapool.c中):
- struct dma_pool *dma_pool_create (const char *name, struct device *dev,
- size_t size, size_t align, size_t allocation)
- {
- struct dma_pool *retval;
- if (align == 0)
- align = 1;
- if (size == 0)
- return NULL;
- else if (size < align)
- size = align;
- else if ((size % align) != 0) {//对齐处理
- size += align + 1;
- size &= ~(align - 1);
- }
- //如果一致内存块比页大,是分配为一致内存块大小,否则,分配为页大小
- if (allocation == 0) {
- if (PAGE_SIZE < size)//页比一致内存块小
- allocation = size;
- else
- allocation = PAGE_SIZE;//页大小
- // FIXME: round up for less fragmentation
- } else if (allocation < size)
- return NULL;
- //分配dma_pool结构对象空间
- if (!(retval = kmalloc (sizeof *retval, SLAB_KERNEL)))
- return retval;
- strlcpy (retval->name, name, sizeof retval->name);
- retval->dev = dev;
- //初始化dma_pool结构对象retval
- INIT_LIST_HEAD (&retval->page_list);//初始化页链表
- spin_lock_init (&retval->lock);
- retval->size = size;
- retval->allocation = allocation;
- retval->blocks_per_page = allocation / size;
- init_waitqueue_head (&retval->waitq);//初始化等待队列
- if (dev) {//设备存在时
- down (&pools_lock);
- if (list_empty (&dev->dma_pools))
- //给设备创建sysfs文件系统属性文件
- device_create_file (dev, &dev_attr_pools);
- /* note: not currently insisting "name" be unique */
- list_add (&retval->pools, &dev->dma_pools); //将DMA池加到dev中
- up (&pools_lock);
- } else
- INIT_LIST_HEAD (&retval->pools);
- return retval;
- }
函数dma_pool_alloc从DMA池中分配一块一致内存,其参数pool是将产生块的DMA池,参数mem_flags是GFP_*位掩码,参数handle是指向块的DMA地址,函数dma_pool_alloc返回当前没用的块的内核虚拟地址,并通过handle给出它的DMA地址,如果内存块不能被分配,返回null。
函数dma_pool_alloc包裹了dma_alloc_coherent页分配器,这样小块更容易被总线的主控制器使用。这可能共享slab分配器的内容。
函数dma_pool_alloc分析如下(在drivers/base/dmapool.c中):
- void *dma_pool_alloc (struct dma_pool *pool, int mem_flags, dma_addr_t *handle)
- {
- unsigned long flags;
- struct dma_page *page;
- int map, block;
- size_t offset;
- void *retval;
- restart:
- spin_lock_irqsave (&pool->lock, flags);
- list_for_each_entry(page, &pool->page_list, page_list) {
- int i;
- /* only cachable accesses here ... */
- //遍历一页的每块,而每块又以32字节递增
- for (map = 0, i = 0;
- i < pool->blocks_per_page; //每页的块数
- i += BITS_PER_LONG, map++) { // BITS_PER_LONG定义为32
- if (page->bitmap [map] == 0)
- continue;
- block = ffz (~ page->bitmap [map]);//找出第一个0
- if ((i + block) < pool->blocks_per_page) {
- clear_bit (block, &page->bitmap [map]);
- //得到相对于页边界的偏移
- offset = (BITS_PER_LONG * map) + block;
- offset *= pool->size;
- goto ready;
- }
- }
- }
- //给DMA池分配dma_page结构空间,加入到pool->page_list链表,
- //并作DMA一致映射,它包括分配给DMA池一页。
- // SLAB_ATOMIC表示调用 kmalloc(GFP_ATOMIC) 直到失败为止,
- //然后它等待内核释放若干页面,接下来再一次进行分配。
- if (!(page = pool_alloc_page (pool, SLAB_ATOMIC))) {
- if (mem_flags & __GFP_WAIT) {
- DECLARE_WAITQUEUE (wait, current);
- current->state = TASK_INTERRUPTIBLE;
- add_wait_queue (&pool->waitq, &wait);
- spin_unlock_irqrestore (&pool->lock, flags);
- schedule_timeout (POOL_TIMEOUT_JIFFIES);
- remove_wait_queue (&pool->waitq, &wait);
- goto restart;
- }
- retval = NULL;
- goto done;
- }
- clear_bit (0, &page->bitmap [0]);
- offset = 0;
- ready:
- page->in_use++;
- retval = offset + page->vaddr; //返回虚拟地址
- *handle = offset + page->dma; //相对DMA地址
- #ifdef CONFIG_DEBUG_SLAB
- memset (retval, POOL_POISON_ALLOCATED, pool->size);
- #endif
- done:
- spin_unlock_irqrestore (&pool->lock, flags);
- return retval;
- }
六、一个简单的使用DMA 例子
示例:下面是一个简单的使用DMA进行传输的驱动程序,它是一个假想的设备,只列出DMA相关的部分来说明驱动程序中如何使用DMA的。
函数dad_transfer是设置DMA对内存buffer的传输操作函数,它使用流式映射将buffer的虚拟地址转换到物理地址,设置好DMA控制器,然后开始传输数据。
- int dad_transfer(struct dad_dev *dev, int write, void *buffer,
- size_t count)
- {
- dma_addr_t bus_addr;
- unsigned long flags;
- /* Map the buffer for DMA */
- dev->dma_dir = (write ? PCI_DMA_TODEVICE : PCI_DMA_FROMDEVICE);
- dev->dma_size = count;
- //流式映射,将buffer的虚拟地址转化成物理地址
- bus_addr = pci_map_single(dev->pci_dev, buffer, count,
- dev->dma_dir);
- dev->dma_addr = bus_addr; //DMA传送的buffer物理地址
- //将操作控制写入到DMA控制器寄存器,从而建立起设备
- writeb(dev->registers.command, DAD_CMD_DISABLEDMA);
- //设置传输方向--读还是写
- writeb(dev->registers.command, write ? DAD_CMD_WR : DAD_CMD_RD);
- writel(dev->registers.addr, cpu_to_le32(bus_addr));//buffer物理地址
- writel(dev->registers.len, cpu_to_le32(count)); //传输的字节数
- //开始激活DMA进行数据传输操作
- writeb(dev->registers.command, DAD_CMD_ENABLEDMA);
- return 0;
- }
函数dad_interrupt是中断处理函数,当DMA传输完时,调用这个中断函数来取消buffer上的DMA映射,从而让内核程序可以访问这个buffer。
- void dad_interrupt(int irq, void *dev_id, struct pt_regs *regs)
- {
- struct dad_dev *dev = (struct dad_dev *) dev_id;
- /* Make sure it's really our device interrupting */
- /* Unmap the DMA buffer */
- pci_unmap_single(dev->pci_dev, dev->dma_addr, dev->dma_size,
- dev->dma_dir);
- /* Only now is it safe to access the buffer, copy to user, etc. */
- ...
- }
函数dad_open打开设备,此时应申请中断号及DMA通道
- int dad_open (struct inode *inode, struct file *filp)
- {
- struct dad_device *my_device;
- // SA_INTERRUPT表示快速中断处理且不支持共享 IRQ 信号线
- if ( (error = request_irq(my_device.irq, dad_interrupt,
- SA_INTERRUPT, "dad", NULL)) )
- return error; /* or implement blocking open */
- if ( (error = request_dma(my_device.dma, "dad")) ) {
- free_irq(my_device.irq, NULL);
- return error; /* or implement blocking open */
- }
- return 0;
- }
在与open 相对应的 close 函数中应该释放DMA及中断号。
- void dad_close (struct inode *inode, struct file *filp)
- {
- struct dad_device *my_device;
- free_dma(my_device.dma);
- free_irq(my_device.irq, NULL);
- ……
- }
函数dad_dma_prepare初始化DMA控制器,设置DMA控制器的寄存器的值,为 DMA 传输作准备。
- int dad_dma_prepare(int channel, int mode, unsigned int buf,
- unsigned int count)
- {
- unsigned long flags;
- flags = claim_dma_lock();
- disable_dma(channel);
- clear_dma_ff(channel);
- set_dma_mode(channel, mode);
- set_dma_addr(channel, virt_to_bus(buf));
- set_dma_count(channel, count);
- enable_dma(channel);
- release_dma_lock(flags);
- return 0;
- }
函数dad_dma_isdone用来检查 DMA 传输是否成功结束。
- int dad_dma_isdone(int channel)
- {
- int residue;
- unsigned long flags = claim_dma_lock ();
- residue = get_dma_residue(channel);
- release_dma_lock(flags);
- return (residue == 0);
- }
Linux 设备驱动的固件加载
作为一个驱动作者, 你可能发现你面对一个设备必须在它能支持工作前下载固件到它里面. 硬件市场的许多地方的竞争是如此得强烈, 以至于甚至一点用作设备控制固件的 EEPROM 的成本制造商都不愿意花费. 因此固件发布在随硬件一起的一张 CD 上, 并且操作系统负责传送固件到设备自身.
硬件越来越复杂,硬件的许多功能使用了程序实现,与直接硬件实现相比,固件拥有处理复杂事物的灵活性和便于升级、维护等优点。固件(firmware)就是这样的一段在设备硬件自身中执行的程序,通过固件标准驱动程序才能实现特定机器的操作,如:光驱、刻录机等都有内部的固件。
固件一般存放在设备上的flash存储器中,但出于成本和灵活性考虑,许多设备都将固件的映像(image)以文件的形式存放在硬盘中,设备驱动程序初始化时再装载到设备内部的存储器中。这样,方便了固件的升级,并省略了设备的flash存储器。
一、驱动和固件的区别
从计算机领域来说,驱动和固件从来没有过明确的定义,就好像今天我们说内存,大部分人用来表示SDRAM,但也有人把Android里的“固化的Flash/Storage"称为“内存”,你不能说这样说就错了,因为这确实是一种“内部存储”。
但在Linux Kernel中,Driver和Firmware是有明确含义的,
1、驱动
Driver是控制被操作系统管理的外部设备(Device)的代码段。很多时候Driver会被实现为LKM,但这不是必要条件。driver通过driver_register()注册到总线(bus_type)上,代表系统具备了驱动某种设备(device)的能力。当某个device被注册到同样的总线的时候(通常是总线枚举的时候发现了这个设备),总线驱动会对driver和device会通过一定的策略进行binding(即进行匹配),如果Binding成功,总线驱动会调用driver的probe()函数,把设备的信息(例如端口,中断号等)传递给驱动,驱动就可以对真实的物理部件进行初始化,并把对该设备的控制接口注册到Linux的其他子系统上(例如字符设备,v4l2子系统等)。这样操作系统的其他部分就可以通过这些通用的接口来访问设备了。
2、固件
Firmware,是表示运行在非“控制处理器”(指不直接运行操作系统的处理器,例如外设中的处理器,或者被用于bare metal的主处理器的其中一些核)中的程序。这些程序很多时候使用和操作系统所运行的处理器完全不同的指令集。这些程序以二进制形式存在于Linux内核的源代码树中,生成目标系统的时候,通常拷贝在/lib/firmware目录下。当driver对device进行初始化的时候,通过request_firmware()等接口,在一个用户态helper程序的帮助下,可以把指定的firmware加载到内存中,由驱动传输到指定的设备上。
所以,总的来说,其实driver和firmware没有什么直接的关系,但firmware通常由驱动去加载。我们讨论的那个OS,一般不需要理解firmware是什么,只是把它当做数据。firmware是什么,只有使用这些数据的那个设备才知道。好比你用一个电话,电话中有一个软件,这个软件你完全不关心如何工作的,你换这个软件的时候,就可以叫这个软件是“固件”,但如果你用了一个智能手机,你要细细关系什么是上面的应用程序,Android平台,插件之类的细节内容,你可能就不叫这个东西叫“固件”了。
如何解决固件问题呢?你可能想解决固件问题使用这样的一个声明:
static char my_firmware[] = { 0x34, 0x78, 0xa4, ... };
但是, 这个方法几乎肯定是一个错误. 将固件编码到一个驱动扩大了驱动的代码, 使固件升级困难, 并且非常可能产生许可问题. 供应商不可能已经发布固件映象在 GPL 之下, 因此和 GPL-许可的代码混合常常是一个错误. 为此, 包含内嵌固件的驱动不可能被接受到主流内核或者被 Linux 发布者包含.
二、内核固件接口
正确的方法是当你需要它时从用户空间获取它. 但是, 请抵制试图从内核空间直接打开包含固件的文件的诱惑; 那是一个易出错的操作, 并且它安放了策略(以一个文件名的形式)到内核. 相反, 正确的方法时使用固件接口, 它就是为此而创建的:
- #include <linux/firmware.h>
- int request_firmware(const struct firmware **fw, char *name, struct device *device);
函数request_firmware向用户空间请求提供一个名为name固件映像文件并等待完成。参数device为固件装载的设备。文件内容存入request_firmware 返回,如果固件请求成功,返回0。该函数从用户空间得到的数据未做任何检查,用户在编写驱动程序时,应对固件映像做数据安全检查,检查方向由设备固件提供商确定,通常有检查标识符、校验和等方法。
调用 request_firmware 要求用户空间定位并提供一个固件映象给内核; 我们一会儿看它如何工作的细节. name 应当标识需要的固件; 正常的用法是供应者提供的固件文件名. 某些象 my_firmware.bin 的名子是典型的. 如果固件被成功加载, 返回值是 0(负责常用的错误码被返回), 并且 fw 参数指向一个这些结构:
- struct firmware {
- size_t size;
- u8 *data;
- };
那个结构包含实际的固件, 它现在可被下载到设备中. 小心这个固件是来自用户空间的未被检查的数据; 你应当在发送它到硬件之前运用任何并且所有的你能够想到的检查来说服你自己它是正确的固件映象. 设备固件常常包含标识串, 校验和, 等等; 在信任数据前全部检查它们.
在你已经发送固件到设备前, 你应当释放 in-kernel 结构, 使用:
- void release_firmware(struct firmware *fw);
因为 request_firmware 请求用户空间来帮忙, 它保证在返回前睡眠. 如果你的驱动当它必须请求固件时不在睡眠的位置, 异步的替代方法可能要使用:
- int request_firmware_nowait(struct module *module,
- char *name, struct device *device, void *context,
- void (*cont)(const struct firmware *fw, void *context));
这里额外的参数是 moudle( 它将一直是 THIS_MODULE), context (一个固件子系统不使用的私有数据指针), 和 cont. 如果都进行顺利, request_firmware_nowait 开始固件加载过程并且返回 0. 在将来某个时间, cont 将用加载的结果被调用. 如果由于某些原因固件加载失败, fw 是 NULL.
三、固件如何工作
固件子系统使用 sysfs 和热插拔机制. 当调用 request_firmware, 一个新目录在 /sys/class/firmware 下使用你的驱动的名子被创建. 那个目录包含 3 个属性:
loading
这个属性应当被加载固件的用户空间进程设置为 1. 当加载进程完成, 它应当设为 0. 写一个值 -1 到 loading 会中止固件加载进程.
data
data 是一个二进制的接收固件数据自身的属性. 在设置 loading 后, 用户空间进程应当写固件到这个属性.
device
这个属性是一个符号连接到 /sys/devices 下面的被关联入口项.
一旦创建了 sysfs 入口项, 内核为你的设备产生一个热插拔事件. 传递给热插拔处理者的环境包括一个变量 FIRMWARE, 它被设置为提供给 request_firmware 的名子. 这个处理者应当定位固件文件, 并且拷贝它到内核使用提供的属性. 如果这个文件无法找到, 处理者应当设置 loading 属性为 -1.
如果一个固件请求在 10 秒内没有被服务, 内核就放弃并返回一个失败状态给驱动. 超时周期可通过 sysfs 属性 /sys/class/firmware/timeout 属性改变.
使用 request_firmware 接口允许你随你的驱动发布设备固件. 当正确地集成到热插拔机制, 固件加载子系统允许设备简化工作"在盒子之外" 显然这是处理问题的最好方法.
但是, 请允许我们提出多一条警告: 设备固件没有制造商的许可不应当发布. 许多制造商会同意在合理的条款下许可它们的固件, 如果客气地请求; 一些其他的可能不何在. 无论如何, 在没有许可时拷贝和发布它们的固件是对版权法的破坏并且招致麻烦.
四、固件接口函数的使用方法
当驱动程序需要使用固件驱动时,在驱动程序的初始化化过程中需要加下如下的代码:
- if(request_firmware(&fw_entry, $FIRMWARE, device) == 0) /*从用户空间请求映像数据*/
- /*将固件映像拷贝到硬件的存储器,拷贝函数由用户编写*/
- copy_fw_to_device(fw_entry->data, fw_entry->size);
- release(fw_entry);
用户还需要在用户空间提供脚本通过文件系统sysfs中的文件data将固件映像文件读入到内核的缓冲区中。脚本样例列出如下:
- #变量$DEVPATH(固件设备的路径)和$FIRMWARE(固件映像名)应已在环境变量中提供
- HOTPLUG_FW_DIR=/usr/lib/hotplug/firmware/ #固件映像文件所在目录
- echo 1 > /sys/$DEVPATH/loading
- cat $HOTPLUG_FW_DIR/$FIRMWARE > /sysfs/$DEVPATH/data
- echo 0 > /sys/$DEVPATH/loading
五、固件请求函数request_firmware
函数request_firmware请求从用户空间拷贝固件映像文件到内核缓冲区。该函数的工作流程列出如下:
a -- 在文件系统sysfs中创建文件/sys/class/firmware/xxx/loading和data,"xxx"表示固件的名字,给文件loading和data附加读写函数,设置文件属性,文件loading表示开/关固件映像文件装载功能;文件data的写操作将映像文件的数据写入内核缓冲区,读操作从内核缓冲区读取数据。
b -- 将添加固件的uevent事件(即"add")通过内核对象模型发送到用户空间。
c -- 用户空间管理uevent事件的后台进程udevd接收到事件后,查找udev规则文件,运行规则所定义的动作,与固件相关的规则列出如下:
- $ /etc/udev/rules.d/50-udev-default.rules
- ……
- # firmware class requests
- SUBSYSTEM=="firmware", ACTION=="add", RUN+="firmware.sh"
- ……
从上述规则可以看出,固件添加事件将引起运行脚本firmware.sh。
d -- 脚本firmware.sh打开"装载"功能,同命令"cat 映像文件 > /sys/class/firmware/xxx/data"将映像文件数据写入到内核的缓冲区。
e -- 映像数据拷贝完成后,函数request_firmware从文件系统/sysfs注销固件设备对应的目录"xxx"。如果请求成功,函数返回0。
f -- 用户就将内核缓冲区的固件映像数据拷贝到固件的内存中。然后,调用函数release_firmware(fw_entry)释放给固件映像分配的缓冲区。
函数request_firmware列出如下(在drivers/base/firmware_class.c中):
- int request_firmware(const struct firmware **firmware_p, const char *name,
- struct device *device)
- {
- int uevent = 1;
- return _request_firmware(firmware_p, name, device, uevent);
- }
- static int _request_firmware(const struct firmware **firmware_p, const char *name,
- struct device *device, int uevent)
- {
- struct device *f_dev;
- struct firmware_priv *fw_priv;
- struct firmware *firmware;
- struct builtin_fw *builtin;
- int retval;
- if (!firmware_p)
- return -EINVAL;
- *firmware_p = firmware = kzalloc(sizeof(*firmware), GFP_KERNEL);
- …… //省略出错保护
- /*如果固件映像在内部__start_builtin_fw指向的地址,拷贝数据到缓冲区*/
- for (builtin = __start_builtin_fw; builtin != __end_builtin_fw;
- builtin++) {
- if (strcmp(name, builtin->name))
- continue;
- dev_info(device, "firmware: using built-in firmware %s\n", name); /*打印信息*/
- firmware->size = builtin->size;
- firmware->data = builtin->data;
- return 0;
- }
- ……//省略打印信息
- /*在文件系统sysfs建立xxx目录及文件*/
- retval = fw_setup_device(firmware, &f_dev, name, device, uevent);
- if (retval)
- goto error_kfree_fw;
- fw_priv = dev_get_drvdata(f_dev);
- if (uevent) {
- if (loading_timeout > 0) { /*加载定时器*/
- fw_priv->timeout.expires = jiffies + loading_timeout * HZ;
- add_timer(&fw_priv->timeout);
- }
- kobject_uevent(&f_dev->kobj, KOBJ_ADD); /*发送事件KOBJ_ADD*/
- wait_for_completion(&fw_priv->completion);
- set_bit(FW_STATUS_DONE, &fw_priv->status);
- del_timer_sync(&fw_priv->timeout);
- } else
- wait_for_completion(&fw_priv->completion); /*等待完成固件映像数据的装载*/
- mutex_lock(&fw_lock);
- /*如果装载出错,释放缓冲区*/
- if (!fw_priv->fw->size || test_bit(FW_STATUS_ABORT, &fw_priv->status)) {
- retval = -ENOENT;
- release_firmware(fw_priv->fw);
- *firmware_p = NULL;
- }
- fw_priv->fw = NULL;
- mutex_unlock(&fw_lock);
- device_unregister(f_dev); /*在文件系统sysfs注销xxx目录*/
- goto out;
- error_kfree_fw:
- kfree(firmware);
- *firmware_p = NULL;
- out:
- return retval;
- }
函数fw_setup_device在文件系统sysfs中创建固件设备的目录和文件,其列出如下:
- static int fw_setup_device(struct firmware *fw, struct device **dev_p,
- const char *fw_name, struct device *device,
- int uevent)
- {
- struct device *f_dev;
- struct firmware_priv *fw_priv;
- int retval;
- *dev_p = NULL;
- retval = fw_register_device(&f_dev, fw_name, device);
- if (retval)
- goto out;
- ……
- fw_priv = dev_get_drvdata(f_dev); /*从设备结构中得到私有数据结构*/
- fw_priv->fw = fw;
- retval = sysfs_create_bin_file(&f_dev->kobj, &fw_priv->attr_data); /*在sysfs中创建可执行文件*/
- …… //省略出错保护
- retval = device_create_file(f_dev, &dev_attr_loading); /*在sysfs中创建一般文件*/
- …… //省略出错保护
- if (uevent)
- f_dev->uevent_suppress = 0;
- *dev_p = f_dev;
- goto out;
- error_unreg:
- device_unregister(f_dev);
- out:
- return retval;
- }
函数fw_register_device注册设备,在文件系统sysfs中创建固件设备对应的设备类,存放固件驱动程序私有数据。其列出如下:
- static int fw_register_device(struct device **dev_p, const char *fw_name,
- struct device *device)
- {
- int retval;
- struct firmware_priv *fw_priv = kzalloc(sizeof(*fw_priv),
- GFP_KERNEL);
- struct device *f_dev = kzalloc(sizeof(*f_dev), GFP_KERNEL);
- *dev_p = NULL;
- …… //省略出错保护
- init_completion(&fw_priv->completion); /*初始化completion机制的等待队列*/
- fw_priv->attr_data = firmware_attr_data_tmpl; /*设置文件的属性结构*/
- strlcpy(fw_priv->fw_id, fw_name, FIRMWARE_NAME_MAX);
- fw_priv->timeout.function = firmware_class_timeout; /*超时装载退出函数*/
- fw_priv->timeout.data = (u_long) fw_priv;
- init_timer(&fw_priv->timeout); /*初始化定时器*/
- fw_setup_device_id(f_dev, device); /*拷贝device ->bus_id到f_dev中*/
- f_dev->parent = device;
- f_dev->class = &firmware_class; /*设备类实例*/
- dev_set_drvdata(f_dev, fw_priv); /*存放设备驱动的私有数据:f_dev ->driver_data = fw_priv*/
- f_dev->uevent_suppress = 1;
- retval = device_register(f_dev);
- if (retval) {
- dev_err(device, "%s: device_register failed\n", __func__);
- goto error_kfree;
- }
- *dev_p = f_dev;
- return 0;
- …… //省略了出错保护
- }
- /*文件属性结构实例,设置文件系统sysfs中data文件的模式和读/写函数*/
- static struct bin_attribute firmware_attr_data_tmpl = {
- .attr = {.name = "data", .mode = 0644},
- .size = 0,
- .read = firmware_data_read, /*从内核缓冲区读出数据*/
- .write = firmware_data_write, /*用于将固件映像文件的数据写入到内核缓冲区*/
- };
- /*设备类结构实例,含有发送uevent事件函数和释放设备的函数*/
- static struct class firmware_class = {
- .name = "firmware", /*设备类的名字*/
- .dev_uevent = firmware_uevent, /*设备发送uevent事件的函数*/
- .dev_release = fw_dev_release, /*释放设备的函数*/
- };
linux驱动之--fops的关联
1.各种驱动形式不过是表象,本质还是把fops注册到inode中。
2.一直没有找到确实的“证据”不过还是有点线索的:device_create->device_create_vargs->
dev_set_drvdata(dev, drvdata)把fops设置到了dev->p->driver_data中 device_register->device_add->devtmpfs_create_node->vfs_mknod这里应该就是终点了
注:前半部分把fops函数数组放到了dev->device_private->driver_data中,后半部分vfs_mknod(nd.path.dentry->d_inode,dentry, mode, dev->devt);建立了设备号与inode名称的映射关系,这样通过文件名可以找到设备号,通过设备号就能找到dev结构,通过dev->device_private->driver_data就能解析出fops,从而给系统调用open时建立file operation
linux平台驱动其实不是真正的“驱动”它只不过做点初始化硬件的事情(在probe函数里)真正操作设备的函数在device结构里。
这里体现了C++类的影子
3.简单点说系统调用open会建立一个file结构体,并且通过文件名和路径找到inode结构,并提取i_fop给fops

4.至于提取的过程
static int chrdev_open(struct inode *inode, struct file *filp)
{
struct cdev *p;
struct cdev *new = NULL;
int ret = 0;
spin_lock(&cdev_lock);
p = inode->i_cdev;
if (!p) {
struct kobject *kobj;
int idx;
spin_unlock(&cdev_lock);
kobj = kobj_lookup(cdev_map, inode->i_rdev, &idx);
if (!kobj)
return -ENXIO;
new = container_of(kobj, struct cdev, kobj);
spin_lock(&cdev_lock);
/* Check i_cdev again in case somebody beat us to it while
we dropped the lock. */
p = inode->i_cdev;
if (!p) {
inode->i_cdev = p = new;
list_add(&inode->i_devices, &p->list);
new = NULL;
} else if (!cdev_get(p))
ret = -ENXIO;
} else if (!cdev_get(p))
ret = -ENXIO;
spin_unlock(&cdev_lock);
cdev_put(new);
if (ret)
return ret;
ret = -ENXIO;
filp->f_op = fops_get(p->ops);
if (!filp->f_op)
goto out_cdev_put;
if (filp->f_op->open) {
ret = filp->f_op->open(inode,filp);
if (ret)
goto out_cdev_put;
}
return 0;
out_cdev_put:
cdev_put(p);
return ret;
}
注:貌似只有 open(!/dev/testchar!, O_RDWR) 打开才是这样的,因为/dev目录下都是字符的驱动,是不是使用cdev的都不在sysfs内呢?
在linux设备模型浅析之设备篇中有段描述:device_add定义在drivers/base/core.c中
int device_add(struct device *dev)
{
................
if (MAJOR(dev->devt)) {
error = device_create_file(dev, &devt_attr); //如果存在设备号则添加dev_t属性,这样udev就能读取设备号属性从而在/dev/目录下创建设备节点,这样kobj和cdev也关联了
if (error)
goto ueventattrError;
注:所以我一直追求的目标貌似在这里,是udev把device里包含的fops关联到cedv里,然后chrdev_open就顺理成章了!!
补充点内容:device结构有个device_private用来放一些不想对外开放的东西,其中还有个driver_data。所以是这样的device->p->driver_data
一般情况下这里放的是file_operations但是也未必,对于platform来说有2个函数void *dev_get_drvdata(const struct device *dev)
和void dev_set_drvdata(struct device *dev, void *data)
注册的时候set,至于以后怎么用就不一定了,比如LED的驱动,使用get函数又取出数据,放在了attr里导出到用户空间使用
Linux驱动开发之主设备号找驱动,次设备号找设备
一、引言
很久前接触linux驱动就知道主设备号找驱动,次设备号找设备。这句到底怎么理解呢,如何在驱动中实现呢,在介绍该实现之前先看下内核中主次设备号的管理:
二、Linux内核主次设备号的管理
Linux的设备管理是和文件系统紧密结合的,各种设备都以文件的形式存放在/dev目录下,称为设备文件。应用程序可以打开、关闭和读写这些设备文件,完成对设备的操作,就像操作普通的数据文件一样。为了管理这些设备,系统为设备编了号,每个设备号又分为主设备号和次设备号。主设备号用来区分不同种类的设备,而次设备号用来区分同一类型的多个设备。对于常用设备,Linux有约定俗成的编号,如终端类设备的主设备号是4。
设备号的内部表示
在内核中,dev_t 类型( 在 <linux/types.h>头文件有定义 ) 用来表示设备号,包括主设备号和次设备号两部分。对于 2.6.x内核,dev_t是个32位量,其中高12位用来表示主设备号,低20位用来表示次设备号。
在 linux/types.h 头文件里定义有
typedef __kernel_dev_t dev_t;
typedef __u32 __kernel_dev_t;
主设备号和次设备号的获取
为了写出可移植的驱动程序,不能假定主设备号和次设备号的位数。不同的机型中,主设备号和次设备号的位数可能是不同的。应该使用MAJOR宏得到主设备号,使用MINOR宏来得到次设备号。下面是两个宏的定义:(linux/kdev_t.h)
#define MINORBITS 20 /*次设备号*/
#define MINORMASK ((1U << MINORBITS) - 1) /*次设备号掩码*/
#define MAJOR(dev) ((unsigned int) ((dev) >> MINORBITS)) /*dev右移20位得到主设备号*/
#define MINOR(dev) ((unsigned int) ((dev) & MINORMASK)) /*与次设备掩码与,得到次设备号*/
MAJOR宏将dev_t向右移动20位,得到主设备号;MINOR宏将dev_t的高12位清零,得到次设备号。相反,可以将主设备号和次设备号转换为设备号类型(dev_t),使用宏MKDEV可以完成这个功能。
#define MKDEV(ma,mi) (((ma) << MINORBITS) | (mi))
MKDEV宏将主设备号(ma)左移20位,然后与次设备号(mi)相或,得到设备号
三、主设备号找驱动、次设备号找设备的内核实现
Linux内核允许多个驱动共享一个主设备号,但更多的设备都遵循一个驱动对一个主设备号的原则。
内核维护着一个以主设备号为key的全局哈希表,而哈希表中数据部分则为与该主设备号设备对应的驱动程序(只有一个次设备)的指针或者多个同类设备驱动程序组成的数组的指针(设备共享主设备号)。根据所编写的驱动程序,可以从内核那里得到一个直接指向设备驱动的指针,或者使用次设备号作为索引的数组来找到设备驱动程序。但无论哪种方式,内核自身几乎不知道次设备号的什么事情。如下图所示:
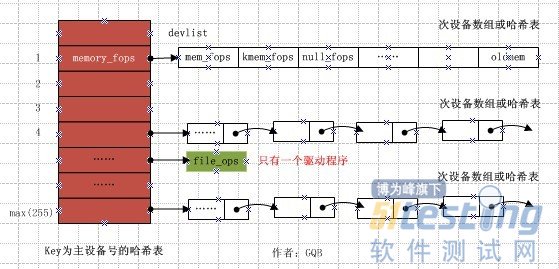
图1:应用程序调用open时通过主次设备号找到相应驱动
来看内核中一个简单的字符设备驱动的例子,其主设备号为1,根据LANANA标准,该设备有10个不同的次设备号。每个都提供了一个不同的功能,这些都与内存访问操作有关。下面列出一些次设备号,以及相关的文件名和含义。
表1 用于主设备号1的各个从设备号
| 从设备号 | 文件 | 含义 |
| 1 | /dev/mem | 物理内存 |
| 2 | /dev/kmem | 内核虚拟地址空间 |
| 3 | /dev/null | 比特位桶 |
| 4 | /dev/port | 访问I/O端口 |
| 5 | /dev/zero | WULL字符源 |
| 8 | /dev/random | 非确定性随机数发生器 |
一些设备是我们熟悉的,特别是/dev/null。根据设备描述我们可以很清楚地知道尽管这些从设备都涉及到内存访问,但所实现功能有很大差别。然后来看下图1中主设备号为1的memory_fops中定义了哪些函数指针。代码如下:
driver/char/mem.c
| static const struct file_operations memory_fops = { .open = memory_open, .llseek = noop_llseek, }; |
其中函数memory_open最为关键,其作用是根据次设备号找到次设备的驱动程序。
|
static int memory_open(struct inode *inode, struct file *filp) minor = iminor(inode); /* get the minor device number commented by guoqingbo */ dev = &devlist[minor];/* select the specific file_operations */ filp->f_op = dev->fops; /* Is /dev/mem or /dev/kmem ? */ if (dev->fops->open) //open the device return 0; |
该函数用到的图1中的devlist数组定义如下:
| static const struct memdev { const char *name; mode_t mode; const struct file_operations *fops; struct backing_dev_info *dev_info; } devlist[] = { [1] = { "mem", 0, &mem_fops, &directly_mappable_cdev_bdi }, #ifdef CONFIG_DEVKMEM [2] = { "kmem", 0, &kmem_fops, &directly_mappable_cdev_bdi }, #endif [3] = { "null", 0666, &null_fops, NULL }, #ifdef CONFIG_DEVPORT [4] = { "port", 0, &port_fops, NULL }, #endif [5] = { "zero", 0666, &zero_fops, &zero_bdi }, [7] = { "full", 0666, &full_fops, NULL }, [8] = { "random", 0666, &random_fops, NULL }, [9] = { "urandom", 0666, &urandom_fops, NULL }, [11] = { "kmsg", 0, &kmsg_fops, NULL }, #ifdef CONFIG_CRASH_DUMP [12] = { "oldmem", 0, &oldmem_fops, NULL }, #endif }; |
通过上面代码及图1可看出,memory_open实际上实现了一个分配器(根据次设备号区分各个设备,并且选择适当的file_operations),图2说明了打开内存设备时,文件操作是如何改变的。所涉及的函数逐渐反映了设备的具体特性。最初只知道用于打开设备的一般函数,然后由打开与内存相关设备文件的具体函数所替代。接下来根据选择的次设备号,进一步细化函数指针
,为不同的次设备号最终选定函数指针。
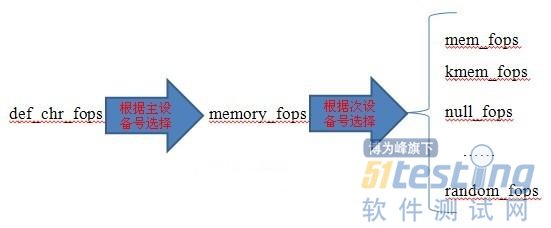
图2:设备驱动程序函数指针的选择过程
Linux 用户空间与内核空间数据交换方式
引言
一般地,在使用虚拟内存技术的多任务系统上,内核和应用有不同的地址空间,因此,在内核和应用之间以及在应用与应用之间进行数据交换需要专门的机制来实现,众所周知,进程间通信(IPC)机制就是为实现应用与应用之间的数据交换而专门实现的,大部分读者可能对进程间通信比较了解,但对应用与内核之间的数据交换机制可能了解甚少
本文将详细介绍 Linux 系统下内核与应用进行数据交换的各种方式,包括内核启动参数、模块参数与 sysfs、sysctl、系统调用、netlink、procfs、seq_file、debugfs 和 relayfs。
系统调用
Linux内核提供了多个函数和宏用于内核空间和用户空间传递数据。
主要有:access_ok(),copy_to_user(),copy_from_user,put_user,get_user。
1.access_ok()
函数原型:int access_ok(int type,unsigned long addr,unsigned long size)
函数access_ok()用于检查指定地址是否可以访问。参数type为访问方式,可以为VERIFY_READ(可读),VERIFY_WRITE(可写)。addr为要操作的地址,size为要操作的空间大小(以字节计算)。函数返回1,表示可以访问,0表示不可以访问。
2.copy_to_user()和copy_from_user()
函数原型:unsigned long copy_to_user(void *to,const void *from,unsigned long len)
unsigned long copy_from_user(void *to,const void *from,unsigned long len)
这两个函数用于内核空间与用户空间的数据交换。copy_to_user()用于把数据从内核空间拷贝至用户空间,copy_from_user()用于把数据从用户空间拷贝至内核空间。第一个参数to为目标地址,第二个参数from为源地址,第三个参数len为要拷贝的数据个数,以字节计算。这两个函数在内部调用access_ok()进行地址检查。返回值为未能拷贝的字节数。
3.get_user()和put_user()
函数原型:int get_user(x,p)
int put_user(x,p)
这是两个宏,用于一个基本数据(1,2,4字节)的拷贝。get_user()用于把数据从用户空间拷贝至内核空间,put_user()用于把数据从内核空间拷贝至用户空间。x为内核空间的数据,p为用户空间的指针。这两个宏会调用access_ok()进行地址检查。拷贝成功,返回0,否则返回-EFAULT。
4.还有两个函数__copy_to_user()和__copy_from_user(),功能与copy_to_user()和copy_from_user()相同,只是不进行地址检查。还有两个宏__get_user()和__put_user(),功能与get_user()和put_user()相同,也不进行地址检查。
(通常情况下,应用程序通过内核接口访问驱动程序,因此,驱动程序需要和应用程序交换数据。Linux将存储器分为“内核空间”和“用户空间”。操作系统和驱动程序在内核空间运行,应用程序在用户空间运行,两者不能简单地使用指针传递数据。因为Linux系统使用了虚拟内存机制,用户空间的内存可能被换出,当内核空间使用用户空间指针时,对应的数据可能不在内存中。Linux内核提供了多个函数和宏用于内核空间和用户空间传递数据。)
内核开发者经常需要向用户空间应用输出一些调试信息,在稳定的系统中可能根本不需要这些调试信息,但是在开发过程中,为了搞清楚内核的行为,调试信息非常必要,printk可能是用的最多的,但它并不是最好的,调试信息只是在开发中用于调试,而printk将一直输出,因此开发完毕后需要清除不必要 的printk语句,另外如果开发者希望用户空间应用能够改变内核行为时,printk就无法实现。因此,需要一种新的机制,那只有在需要的时候使用,它在需要时通过在一个虚拟文件系统中创建一个或多个文件来向用户空间应用提供调试信息。
有几种方式可以实现上述要求:
(1)使用procfs,在/proc创建文件输出调试信息,但是procfs对于大于一个内存页(对于x86是4K)的输出比较麻烦,而且速度慢,有时回出现一些意想不到的问题。
(2)使用sysfs(2.6内核引入的新的虚拟文件系统),在很多情况下,调试信息可以存放在那里,但是sysfs主要用于系统管理,它希望每一个文件对应内核的一个变量,如果使用它输出复杂的数据结构或调试信息是非常困难的。
(3)使用libfs创建一个新的文件系统,该方法极其灵活,开发者可以为新文件系统设置一些规则,使用libfs使得创建新文件系统更加简单,但是仍然超出了一个开发者的想象。
(4)为了使得开发者更加容易使用这样的机制,Greg
Kroah-Hartman开发了debugfs(在2.6.11中第一次引入),它是一个虚拟文件系统,专门用于输出调试信息,该文件系统非常小,很容易使用,可以在配置内核时选择是否构件到内核中,在不选择它的情况下,使用它提供的API的内核部分不需要做任何改动。
使用debugfs的开发者首先需要在文件系统中创建一个目录,下面函数用于在debugfs文件系统下创建一个目录:
struct dentry *debugfs_create_dir(const char *name, struct dentry *parent);
参数name是要创建的目录名,参数parent指定创建目录的父目录的dentry,如果为NULL,目录将创建在debugfs文件系统的根目录下。如果返回为-ENODEV,表示内核没有把debugfs编译到其中,如果返回为NULL,表示其他类型的创建失败,如果创建目录成功,返回指向该 目录对应的dentry条目的指针。
下面函数用于在debugfs文件系统中创建一个文件:
参数name指定要创建的文件名,参数mode指定该文件的访问许可,参数parent指向该文件所在目录,参数data为该文件特定的一些数据, 参数fops为实现在该文件上进行文件操作的fiel_operations结构指针,在很多情况下,由seq_file提供的文件操作实现就足够了,因此使用debugfs很容易,当然,在一些情况下,开发者可能仅需要使用用户应用可以控制的变量来调试,debugfs也提供了4个这样的API方便开发者使用:

struct dentry *debugfs_create_u16(const char *name, mode_t mode, struct dentry *parent, u16 *value);
struct dentry *debugfs_create_u32(const char *name, mode_t mode, struct dentry *parent, u32 *value);
struct dentry *debugfs_create_bool(const char *name, mode_t mode, struct dentry *parent, u32 *value);
参数name和mode指定文件名和访问许可,参数value为需要让用户应用控制的内核变量指针。
当内核模块卸载时,Debugfs并不会自动清除该模块创建的目录或文件,因此对于创建的每一个文件或目录,开发者必须调用下面函数清除:
void debugfs_remove(struct dentry *dentry);
参数dentry为上面创建文件和目录的函数返回的dentry指针。
在下面给出了一个使用debufs的示例模块debugfs_exam.c,为了保证该模块正确运行,必须让内核支持debugfs,
debugfs是一个调试功能,因此它位于主菜单Kernel hacking,并且必须选择Kernel
debugging选项才能选择,它的选项名称为Debug
Filesystem。为了在用户态使用debugfs,用户必须mount它,下面是在作者系统上的使用输出:
$ mkdir -p /debugfs
$ mount -t debugfs debugfs /debugfs
$ insmod ./debugfs_exam.ko
$ ls /debugfs
debugfs-exam
$ ls /debugfs/debugfs-exam
u8_var u16_var u32_var bool_var
$ cd /debugfs/debugfs-exam
$ cat u8_var
0
$ echo 200 > u8_var
$ cat u8_var
200
$ cat bool_var
N
$ echo 1 > bool_var
$ cat bool_var
Y
#include <linux/config.h>
#include <linux/module.h>
#include <linux/debugfs.h>
#include <linux/types.h>
/*dentry:目录项,是Linux文件系统中某个索引节点(inode)的链接。这个索引节点可以是文件,也可以是目录。
Linux用数据结构dentry来描述fs中和某个文件索引节点相链接的一个目录项(能是文件,也能是目录)。
(1)未使用(unused)状态:该dentry对象的引用计数d_count的值为0,但其d_inode指针仍然指向相关
(2)正在使用(inuse)状态:处于该状态下的dentry对象的引用计数d_count大于0,且其d_inode指向相关
(3)负(negative)状态:和目录项相关的inode对象不复存在(相应的磁盘索引节点可能已被删除),dentry
*/
static struct dentry *root_entry, *u8_entry, *u16_entry, *u32_entry, *bool_entry;
static u8 var8;
static u16 var16;
static u32 var32;
static u32 varbool;
static int __init exam_debugfs_init(void)
{
root_entry = debugfs_create_dir("debugfs-exam", NULL);
if (!root_entry) {
printk("Fail to create proc dir: debugfs-exam\n");
return 1;
}
u8_entry = debugfs_create_u8("u8-var", 0644, root_entry, &var8);
u16_entry = debugfs_create_u16("u16-var", 0644, root_entry, &var16);
u32_entry = debugfs_create_u32("u32-var", 0644, root_entry, &var32);
bool_entry = debugfs_create_bool("bool-var", 0644, root_entry, &varbool);
return 0;
}
static void __exit exam_debugfs_exit(void)
{
debugfs_remove(u8_entry);
debugfs_remove(u16_entry);
debugfs_remove(u32_entry);
debugfs_remove(bool_entry);
debugfs_remove(root_entry);
}
module_init(exam_debugfs_init);
module_exit(exam_debugfs_exit);
MODULE_LICENSE("GPL");
procfs是比较老的一种用户态与内核态的数据交换方式,内核的很多数据都是通过这种方式出口给用户的,内核的很多参数也是通过这种方式来让用户方便设置的。除了sysctl出口到/proc下的参数,procfs提供的大部分内核参数是只读的。实际上,很多应用严重地依赖于procfs,因此它几乎是必不可少的组件。本节将讲解如何使用procfs。
Procfs提供了如下API:
该函数用于创建一个正常的proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参数 parent指定建立的proc条目所在的目录。如果要在/proc下建立proc条目,parent应当为NULL。否则它应当为proc_mkdir 返回的struct proc_dir_entry结构的指针。
externvoid remove_proc_entry(constchar*name, struct proc_dir_entry *parent)
该函数用于删除上面函数创建的proc条目,参数name给出要删除的proc条目的名称,参数parent指定建立的proc条目所在的目录。
struct proc_dir_entry *proc_mkdir(constchar* name, struct proc_dir_entry *parent)
该函数用于创建一个proc目录,参数name指定要创建的proc目录的名称,参数parent为该proc目录所在的目录。
该函数用于建立一个proc条目的符号链接,参数name给出要建立的符号链接proc条目的名称,参数parent指定符号连接所在的目录,参数dest指定链接到的proc条目名称。
read_proc_t *read_proc, void* data);
该函数用于建立一个规则的只读proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参 数base指定建立的proc条目所在的目录,参数read_proc给出读去该proc条目的操作函数,参数data为该proc条目的专用数据,它将 保存在该proc条目对应的struct file结构的private_data字段中。
get_info_t *get_info);
该函数用于创建一个info型的proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限, 参数base指定建立的proc条目所在的目录,参数get_info指定该proc条目的get_info操作函数。实际上get_info等同于 read_proc,如果proc条目没有定义个read_proc,对该proc条目的read操作将使用get_info取代,因此它在功能上非常类似于函数create_proc_read_entry。
该函数用于在/proc/net目录下创建一个proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参数get_info指定该proc条目的get_info操作函数。
该函数也用于在/proc/net下创建proc条目,但是它也同时指定了对该proc条目的文件操作函数。
void proc_net_remove(constchar*name)
该函数用于删除前面两个函数在/proc/net目录下创建的proc条目。参数name指定要删除的proc名称。
除了这些函数,值得一提的是结构struct
proc_dir_entry,为了创建一了可写的proc条目并指定该proc条目的写操作函数,必须设置上面的这些创建proc条目的函数返回的指针
指向的struct proc_dir_entry结构的write_proc字段,并指定该proc条目的访问权限有写权限。
为了使用这些接口函数以及结构struct proc_dir_entry,用户必须在模块中包含头文件linux/proc_fs.h。
在源代码包中给出了procfs示例程序procfs_exam.c,它定义了三个proc文件条目和一个proc目录条目,读者在插入该模块后应当看到如下结构:
$ ls /proc/myproctest
aint astring bigprocfile
$
读者可以通过cat和echo等文件操作函数来查看和设置这些proc文件。特别需要指出,bigprocfile是一个大文件(超过一个内存
页),对于这种大文件,procfs有一些限制,因为它提供的缓存,只有一个页,因此必须特别小心,并对超过页的部分做特别的考虑,处理起来比较复杂并且
很容易出错,所有procfs并不适合于大数据量的输入输出,后面一节seq_file就是因为这一缺陷而设计的,当然seq_file依赖于 procfs的一些基础功能。
#include <linux/config.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/sched.h>
#include <linux/types.h>
#include <asm/uaccess.h>
#define STR_MAX_SIZE 255
staticint int_var;
staticchar string_var[];
staticchar big_buffer[];
staticint big_buffer_len =;
staticstruct proc_dir_entry * myprocroot;
staticint first_write_flag =;
int int_read_proc(char*page, char**start, off_t off, int count, int*eof, void*data)
{
count = sprintf(page, "%d", *(int*)data);
return count;
}
int int_write_proc(struct file *file, constchar __user *buffer,unsigned long count, void*data)
{
unsigned int c =, len =, val, sum =;
int* temp = (int*)data;
while (count) {
if (get_user(c, buffer)) //从用户空间中得到数据
return-EFAULT;
len++;
buffer++;
count--;
if (c ==|| c ==)
break;
val = c -'';
if (val >)
return-EINVAL;
sum *=;
sum += val;
}
* temp = sum;
return len;
}
int string_read_proc(char*page, char**start, off_t off,int count, int*eof, void*data)
{
count = sprintf(page, "%s", (char*)data);
return count;
}
int string_write_proc(struct file *file, constchar __user *buffer, unsigned long count, void*data)
{
if (count > STR_MAX_SIZE) {
count =;
}
copy_from_user(data, buffer, count);
return count;
}
int bigfile_read_proc(char*page, char**start, off_t off, int count, int*eof, void*data)
{
if (off > big_buffer_len) {
* eof =;
return;
}
if (count > PAGE_SIZE) {
count = PAGE_SIZE;
}
if (big_buffer_len - off < count) {
count = big_buffer_len - off;
}
memcpy(page, data, count);
*start = page;
return count;
}
int bigfile_write_proc(struct file *file, constchar __user *buffer, unsigned long count, void*data)
{
char* p = (char*)data;
if (first_write_flag) {
big_buffer_len =;
first_write_flag =;
}
if (- big_buffer_len < count) {
count =- big_buffer_len;
first_write_flag =;
}
copy_from_user(p + big_buffer_len, buffer, count);
big_buffer_len += count;
return count;
}
staticint __init procfs_exam_init(void)
{
#ifdef CONFIG_PROC_FS
struct proc_dir_entry * entry;
myprocroot = proc_mkdir("myproctest", NULL);
entry = create_proc_entry("aint", , myprocroot);
if (entry) {
entry->data =&int_var;
entry->read_proc =&int_read_proc;
entry->write_proc =&int_write_proc;
}
entry = create_proc_entry("astring", , myprocroot);
if (entry) {
entry->data =&string_var;
entry->read_proc =&string_read_proc;
entry->write_proc =&string_write_proc;
}
entry = create_proc_entry("bigprocfile", , myprocroot);
if (entry) {
entry->data =&big_buffer;
entry->read_proc =&bigfile_read_proc;
entry->write_proc =&bigfile_write_proc;
}
#else
printk("This module requires the kernel to support procfs,\n");
#endif
return;
}
staticvoid __exit procfs_exam_exit(void)
{
#ifdef CONFIG_PROC_FS
remove_proc_entry("aint", myprocroot);
remove_proc_entry("astring", myprocroot);
remove_proc_entry("bigprocfile", myprocroot);
remove_proc_entry("myproctest", NULL);
#endif
} module_init(procfs_exam_init);
module_exit(procfs_exam_exit);
MODULE_LICENSE("GPL");
一般地,内核通过在procfs文件系统下建立文件来向用户空间提供输出信息,用户空间可以通过任何文本阅读应用查看该文件信息,但是procfs 有一个缺陷,如果输出内容大于1个内存页,需要多次读,因此处理起来很难,另外,如果输出太大,速度比较慢,有时会出现一些意想不到的情况, Alexander Viro实现了一套新的功能,使得内核输出大文件信息更容易,该功能出现在2.4.15(包括2.4.15)以后的所有2.4内核以及2.6内核中,尤其 是在2.6内核中,已经大量地使用了该功能。
要想使用seq_file功能,开发者需要包含头文件linux/seq_file.h,并定义与设置一个seq_operations结构(类似于file_operations结构):
struct seq_operations {
void* (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void*v);
void* (*next) (struct seq_file *m, void*v, loff_t *pos);
int (*show) (struct seq_file *m, void*v);
};
start函数用于指定seq_file文件的读开始位置,返回实际读开始位置,如果指定的位置超过文件末尾,应当返回NULL,start函数可以有一个特殊的返回SEQ_START_TOKEN,它用于让show函数输出文件头,但这只能在pos为0时使用,next函数用于把seq_file文件的当前读位置移动到下一个读位置,返回实际的下一个读位置,如果已经到达文件末尾,返回NULL,stop函数用于在读完seq_file文件后调用,它类似于文件操作close,用于做一些必要的清理,如释放内存等,show函数用于格式化输出,如果成功返回0,否则返回出错码。
Seq_file也定义了一些辅助函数用于格式化输出:
/*函数seq_putc用于把一个字符输出到seq_file文件*/
int seq_putc(struct seq_file *m, char c); /*函数seq_puts则用于把一个字符串输出到seq_file文件*/
int seq_puts(struct seq_file *m, constchar*s); /*函数seq_escape类似于seq_puts,只是,它将把第一个字符串参数中出现的包含在第二个字符串参数
中的字符按照八进制形式输出,也即对这些字符进行转义处理*/
int seq_escape(struct seq_file *, constchar*, constchar*); /*函数seq_printf是最常用的输出函数,它用于把给定参数按照给定的格式输出到seq_file文件*/
int seq_printf(struct seq_file *, constchar*, ...)__attribute__ ((format(printf,,))); /*函数seq_path则用于输出文件名,字符串参数提供需要转义的文件名字符,它主要供文件系统使用*/
int seq_path(struct seq_file *, struct vfsmount *, struct dentry *, char*);
在定义了结构struct seq_operations之后,用户还需要把打开seq_file文件的open函数,以便该结构与对应于seq_file文件的struct file结构关联起来,例如,struct seq_operations定义为:
struct seq_operations exam_seq_ops = {
.start = exam_seq_start,
.stop = exam_seq_stop,
.next = exam_seq_next,
.show = exam_seq_show
};
那么,open函数应该如下定义:
staticint exam_seq_open(struct inode *inode, struct file *file)
{
return seq_open(file, &exam_seq_ops);
};
注意,函数seq_open是seq_file提供的函数,它用于把struct seq_operations结构与seq_file文件关联起来。
最后,用户需要如下设置struct file_operations结构:
struct file_operations exam_seq_file_ops = {
.owner = THIS_MODULE,
.open = exm_seq_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release
};
注意,用户仅需要设置open函数,其它的都是seq_file提供的函数。
然后,用户创建一个/proc文件并把它的文件操作设置为exam_seq_file_ops即可:
struct proc_dir_entry *entry;
entry = create_proc_entry("exam_seq_file", , NULL);
if (entry)
entry->proc_fops =&exam_seq_file_ops;
对于简单的输出,seq_file用户并不需要定义和设置这么多函数与结构,它仅需定义一个show函数,然后使用single_open来定义open函数就可以,以下是使用这种简单形式的一般步骤:
1.定义一个show函数
int exam_show(struct seq_file *p, void*v)
{
…
}
2. 定义open函数
int exam_single_open(struct inode *inode, struct file *file)
{
return(single_open(file, exam_show, NULL));
}
注意要使用single_open而不是seq_open。
3. 定义struct file_operations结构
struct file_operations exam_single_seq_file_operations = {
.open = exam_single_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
注意,如果open函数使用了single_open,release函数必须为single_release,而不是seq_release。
下面给出了一个使用seq_file的具体例子seqfile_exam.c,它使用seq_file提供了一个查看当前系统运行的所有进程的/proc接口,在编译并插入该模块后,用户通过命令"cat
/proc/exam_esq_file"可以查看系统的所有进程。
#include <linux/config.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/percpu.h>
#include <linux/sched.h>
staticstruct proc_dir_entry *entry;
staticvoid*l_start(struct seq_file *m, loff_t * pos)
{
loff_t index =*pos;
if (index ==) {
seq_printf(m, "Current all the processes in system:\n"
"%-24s%-5s\n", "name", "pid");
return&init_task;
}
else {
return NULL;
}
}
staticvoid*l_next(struct seq_file *m, void*p, loff_t * pos)
{
task_t * task = (task_t *)p;
task = next_task(task);
if ((*pos !=) && (task ==&init_task)) {
return NULL;
}
++*pos;
return task;
}
staticvoid l_stop(struct seq_file *m, void*p)
{
}
staticint l_show(struct seq_file *m, void*p)
{
task_t * task = (task_t *)p;
seq_printf(m, "%-24s%-5d\n", task->comm, task->pid);
return;
}
staticstruct seq_operations exam_seq_op = {
.start = l_start,
.next = l_next,
.stop = l_stop,
.show = l_show
};
staticint exam_seq_open(struct inode *inode, struct file *file)
{
return seq_open(file, &exam_seq_op);
}
staticstruct file_operations exam_seq_fops = {
.open = exam_seq_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release,
};
staticint __init exam_seq_init(void)
{
entry = create_proc_entry("exam_esq_file", , NULL);
if (entry)
entry->proc_fops =&exam_seq_fops;
return;
}
staticvoid __exit exam_seq_exit(void)
{
remove_proc_entry("exam_esq_file", NULL);
}
module_init(exam_seq_init);
module_exit(exam_seq_exit);
MODULE_LICENSE("GPL");
relayfs是一个快速的转发(relay)数据的文件系统,它以其功能而得名。它为那些需要从内核空间转发大量数据到用户空间的工具和应用提供了快速有效的转发机制。
Channel是relayfs文件系统定义的一个主要概念,每一个channel由一组内核缓存组成,每一个CPU有一个对应于该channel 的内核缓存,每一个内核缓存用一个在relayfs文件系统中的文件文件表示,内核使用relayfs提供的写函数把需要转发给用户空间的数据快速地写入当前CPU上的channel内核缓存,用户空间应用通过标准的文件I/O函数在对应的channel文件中可以快速地取得这些被转发出的数据mmap 来。写入到channel中的数据的格式完全取决于内核中创建channel的模块或子系统。
relayfs的用户空间API:
relayfs实现了四个标准的文件I/O函数,open、mmap、poll和close.
open(),打开一个channel在某一个CPU上的缓存对应的文件。
mmap(),把打开的channel缓存映射到调用者进程的内存空间。
read
(),读取channel缓存,随后的读操作将看不到被该函数消耗的字节,如果channel的操作模式为非覆盖写,那么用户空间应用在有内核模块写时仍
可以读取,但是如果channel的操作模式为覆盖式,那么在读操作期间如果有内核模块进行写,结果将无法预知,因此对于覆盖式写的channel,用户
应当在确认在channel的写完全结束后再进行读。
poll(),用于通知用户空间应用转发数据跨越了子缓存的边界,支持的轮询标志有POLLIN、POLLRDNORM和POLLERR。
close(),关闭open函数返回的文件描述符,如果没有进程或内核模块打开该channel缓存,close函数将释放该channel缓存。
注意:用户态应用在使用上述API时必须保证已经挂载了relayfs文件系统,但内核在创建和使用channel时不需要relayfs已经挂载。下面命令将把relayfs文件系统挂载到/mnt/relay。
mount -t relayfs relayfs /mnt/relay
relayfs内核API:
relayfs提供给内核的API包括四类:channel管理、写函数、回调函数和辅助函数。
Channel管理函数包括:
relay_open(base_filename, parent, subbuf_size, n_subbufs, overwrite, callbacks)
relay_close(chan)
relay_flush(chan)
relay_reset(chan)
relayfs_create_dir(name, parent)
relayfs_remove_dir(dentry)
relay_commit(buf, reserved, count)
relay_subbufs_consumed(chan, cpu, subbufs_consumed)
写函数包括:
relay_write(chan, data, length)
__relay_write(chan, data, length)
relay_reserve(chan, length)
回调函数包括:
subbuf_start(buf, subbuf, prev_subbuf_idx, prev_subbuf)
buf_mapped(buf, filp)
buf_unmapped(buf, filp)
辅助函数包括:
relay_buf_full(buf)
subbuf_start_reserve(buf, length)
前面已经讲过,每一个channel由一组channel缓存组成,每个CPU对应一个该channel的缓存,每一个缓存又由一个或多个子缓存组成,每一个缓存是子缓存组成的一个环型缓存。
函数relay_open用于创建一个channel并分配对应于每一个CPU的缓存,用户空间应用通过在relayfs文件系统中对应的文件可以
访问channel缓存,参数base_filename用于指定channel的文件名,relay_open函数将在relayfs文件系统中创建
base_filename0..base_filenameN-1,即每一个CPU对应一个channel文件,其中N为CPU数,缺省情况下,这些文件将建立在relayfs文件系统的根目录下,但如果参数parent非空,该函数将把channel文件创建于parent目录下,parent目录使
用函数relay_create_dir创建,函数relay_remove_dir用于删除由函数relay_create_dir创建的目录,谁创建的目录,谁就负责在不用时负责删除。参数subbuf_size用于指定channel缓存中每一个子缓存的大小,参数n_subbufs用于指定
channel缓存包含的子缓存数,因此实际的channel缓存大小为(subbuf_size x
n_subbufs),参数overwrite用于指定该channel的操作模式,relayfs提供了两种写模式,一种是覆盖式写,另一种是非覆盖式
写。使用哪一种模式完全取决于函数subbuf_start的实现,覆盖写将在缓存已满的情况下无条件地继续从缓存的开始写数据,而不管这些数据是否已经
被用户应用读取,因此写操作决不失败。在非覆盖写模式下,如果缓存满了,写将失败,但内核将在用户空间应用读取缓存数据时通过函数
relay_subbufs_consumed()通知relayfs。如果用户空间应用没来得及消耗缓存中的数据或缓存已满,两种模式都将导致数据丢失,唯一的区别是,前者丢失数据在缓存开头,而后者丢失数据在缓存末尾。一旦内核再次调用函数relay_subbufs_consumed(),已满的缓存将不再满,因而可以继续写该缓存。当缓存满了以后,relayfs将调用回调函数buf_full()来通知内核模块或子系统。当新的数据太大无法写
入当前子缓存剩余的空间时,relayfs将调用回调函数subbuf_start()来通知内核模块或子系统将需要使用新的子缓存。内核模块需要在该回调函数中实现下述功能:
初始化新的子缓存;
如果1正确,完成当前子缓存;
如果2正确,返回是否正确完成子缓存切换;
在非覆盖写模式下,回调函数subbuf_start()应该如下实现:
if (prev_subbuf)
*((unsigned *)prev_subbuf) = prev_padding;
if (relay_buf_full(buf))
return;
subbuf_start_reserve(buf, sizeof(unsigned int));
return;
}
如果当前缓存满,即所有的子缓存都没读取,该函数返回0,指示子缓存切换没有成功。当子缓存通过函数relay_subbufs_consumed ()被读取后,读取者将负责通知relayfs,函数relay_buf_full()在已经有读者读取子缓存数据后返回0,在这种情况下,子缓存切换成 功进行。
在覆盖写模式下, subbuf_start()的实现与非覆盖模式类似:
{
if (prev_subbuf)
*((unsigned *)prev_subbuf) = prev_padding;
subbuf_start_reserve(buf, sizeof(unsigned int));
return;
}
只是不做relay_buf_full()检查,因为此模式下,缓存是环行的,可以无条件地写。因此在此模式下,子缓存切换必定成功,函数 relay_subbufs_consumed() 也无须调用。如果channel写者没有定义subbuf_start(),缺省的实现将被使用。 可以通过在回调函数subbuf_start()中调用辅助函数subbuf_start_reserve()在子缓存中预留头空间,预留空间可以保存任 何需要的信息,如上面例子中,预留空间用于保存子缓存填充字节数,在subbuf_start()实现中,前一个子缓存的填充值被设置。前一个子缓存的填 充值和指向前一个子缓存的指针一道作为subbuf_start()的参数传递给subbuf_start(),只有在子缓存完成后,才能知道填充值。 subbuf_start()也被在channel创建时分配每一个channel缓存的第一个子缓存时调用,以便预留头空间,但在这种情况下,前一个子 缓存指针为NULL。
内核模块使用函数relay_write()或__relay_write()往channel缓存中写需要转发的数据,它们的区别是前者失效了本 地中断,而后者只抢占失效,因此前者可以在任何内核上下文安全使用,而后者应当在没有任何中断上下文将写channel缓存的情况下使用。这两个函数没有 返回值,因此用户不能直接确定写操作是否失败,在缓存满且写模式为非覆盖模式时,relayfs将通过回调函数buf_full来通知内核模块。
函数relay_reserve()用于在channel缓存中预留一段空间以便以后写入,在那些没有临时缓存而直接写入channel缓存的内核 模块可能需要该函数,使用该函数的内核模块在实际写这段预留的空间时可以通过调用relay_commit()来通知relayfs。当所有预留的空间全 部写完并通过relay_commit通知relayfs后,relayfs将调用回调函数deliver()通知内核模块一个完整的子缓存已经填满。由于预留空间的操作并不在写channel的内核模块完全控制之下,因此relay_reserve()不能很好地保护缓存,因此当内核模块调用 relay_reserve()时必须采取恰当的同步机制。
当内核模块结束对channel的使用后需要调用relay_close() 来关闭channel,如果没有任何用户在引用该channel,它将和对应的缓存全部被释放。
函数relay_flush()强制在所有的channel缓存上做一个子缓存切换,它在channel被关闭前使用来终止和处理最后的子缓存。
函数relay_reset()用于将一个channel恢复到初始状态,因而不必释放现存的内存映射并重新分配新的channel缓存就可以使用channel,但是该调用只有在该channel没有任何用户在写的情况下才可以安全使用。
回调函数buf_mapped() 在channel缓存被映射到用户空间时被调用。
回调函数buf_unmapped()在释放该映射时被调用。内核模块可以通过它们触发一些内核操作,如开始或结束channel写操作。
在源代码包中给出了一个使用relayfs的示例程序relayfs_exam.c,它只包含一个内核模块,对于复杂的使用,需要应用程序配合。该模块实现了类似于文章中seq_file示例实现的功能。
当然为了使用relayfs,用户必须让内核支持relayfs,并且要mount它,下面是作者系统上的使用该模块的输出信息:
$ mkdir -p /relayfs
$ insmod ./relayfs-exam.ko
$ mount -t relayfs relayfs /relayfs
$ cat /relayfs/example0
…
$
relayfs是一种比较复杂的内核态与用户态的数据交换方式,本例子程序只提供了一个较简单的使用方式,对于复杂的使用,请参考relayfs用例页面http://relayfs.sourceforge.net/examples.html。
#include <linux/module.h>
#include <linux/relayfs_fs.h>
#include <linux/string.h>
#include <linux/sched.h>
#define WRITE_PERIOD (HZ * 60)
staticstruct rchan * chan;
static size_t subbuf_size =;
static size_t n_subbufs =;
staticchar buffer[];
void relayfs_exam_write(unsigned long data);
static DEFINE_TIMER(relayfs_exam_timer, relayfs_exam_write, , );
void relayfs_exam_write(unsigned long data)
{
int len;
task_t * p = NULL;
len = sprintf(buffer, "Current all the processes:\n");
len += sprintf(buffer + len, "process name\t\tpid\n");
relay_write(chan, buffer, len);
for_each_process(p) {
len = sprintf(buffer, "%s\t\t%d\n", p->comm, p->pid);
relay_write(chan, buffer, len);
}
len = sprintf(buffer, "\n\n");
relay_write(chan, buffer, len);
relayfs_exam_timer.expires = jiffies + WRITE_PERIOD;
add_timer(&relayfs_exam_timer);
}
/*
* subbuf_start() relayfs callback.
*
* Defined so that we can 1) reserve padding counts in the sub-buffers, and
* 2) keep a count of events dropped due to the buffer-full condition.
*/
staticint subbuf_start(struct rchan_buf *buf,
void*subbuf,
void*prev_subbuf,
unsigned int prev_padding)
{
if (prev_subbuf)
*((unsigned *)prev_subbuf) = prev_padding;
if (relay_buf_full(buf))
return;
subbuf_start_reserve(buf, sizeof(unsigned int));
return;
}
/*
* relayfs callbacks
*/
staticstruct rchan_callbacks relayfs_callbacks =
{
.subbuf_start = subbuf_start,
};
/**
* module init - creates channel management control files
*
* Returns 0 on success, negative otherwise.
*/
staticint init(void)
{
chan = relay_open("example", NULL, subbuf_size,
n_subbufs, &relayfs_callbacks);
if (!chan) {
printk("relay channel creation failed.\n");
return;
}
relayfs_exam_timer.expires = jiffies + WRITE_PERIOD;
add_timer(&relayfs_exam_timer);
return;
}
staticvoid cleanup(void)
{
del_timer_sync(&relayfs_exam_timer);
if (chan) {
relay_close(chan);
chan = NULL;
}
}
module_init(init);
module_exit(cleanup);
MODULE_LICENSE("GPL");
Linux 提供了一种通过 bootloader 向其传输启动参数的功能,内核开发者可以通过这种方式来向内核传输数据,从而控制内核启动行为。
通常的使用方式是,定义一个分析参数的函数,而后使用内核提供的宏 __setup把它注册到内核中,该宏定义在 linux/init.h 中,因此要使用它必须包含该头文件:
__setup("para_name=", parse_func)
para_name 为参数名,parse_func 为分析参数值的函数,它负责把该参数的值转换成相应的内核变量的值并设置那个内核变量。内核为整数参数值的分析提供了函数 get_option 和 get_options,前者用于分析参数值为一个整数的情况,而后者用于分析参数值为逗号分割的一系列整数的情况,对于参数值为字符串的情况,需要开发者自定义相应的分析函数。在源代码包中的内核程序kern-boot-params.c 说明了三种情况的使用。该程序列举了参数为一个整数、逗号分割的整数串以及字符串三种情况,读者要想测试该程序,需要把该程序拷贝到要使用的内核的源码目录树的一个目录下,为了避免与内核其他部分混淆,作者建议在内核源码树的根目录下创建一个新目录,如 examples,然后把该程序拷贝到 examples 目录下并重新命名为 setup_example.c,并且为该目录创建一个 Makefile 文件:
obj-y = setup_example.o
Makefile 仅许这一行就足够了,然后需要修改源码树的根目录下的 Makefile文件的一行,把下面行
core-y := usr/
修改为
core-y := usr/ examples/
注意:如果读者创建的新目录和重新命名的文件名与上面不同,需要修改上面所说
Makefile 文件相应的位置。
做完以上工作就可以按照内核构建步骤去构建新的内核,在构建好内核并设置好lilo或grub为该内核的启动条目后,就可以启动该内核,然后使用lilo或grub的编辑功能为该内核的启动参数行增加如下参数串:
setup_example_int=1234 setup_example_int_array=100,200,300,400 setup_example_string=Thisisatest
当然,该参数串也可以直接写入到lilo或grub的配置文件中对应于该新内核的内核命令行参数串中。读者可以使用其它参数值来测试该功能。
下面是作者系统上使用上面参数行的输出:
setup_example_int=1234
setup_example_int_array=100,200,300,400
setup_example_int_array includes 4 intergers
setup_example_string=Thisisatest
读者可以使用$dmesg | grep setup 来查看该程序的输出。
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/string.h>
#define MAX_SIZE 5
staticint setup_example_int;
staticint setup_example_int_array[MAX_SIZE];
staticchar setup_example_string[];
staticint __init parse_int(char* s)
{
int ret;
ret = get_option(&s, &setup_example_int);
if (ret ==) {
printk("setup_example_int=%d\n", setup_example_int);
}
return;
}
staticint __init parse_int_string(char*s)
{
char* ret_str;
int i;
ret_str = get_options(s, MAX_SIZE, setup_example_int_array);
if (*ret_str !='\0') {
printk("incorrect setup_example_int_array paramters: %s\n", ret_str);
}
else {
printk("setup_example_int_array=");
for (i=; i<MAX_SIZE; i++) {
printk("%d", setup_example_int_array[i]);
if (i < (MAX_SIZE -)) {
printk(",");
}
}
printk("\n");
printk("setup_example_int_array includes %d intergers\n", setup_example_int_array[]);
}
return;
}
staticint __init parse_string(char*s)
{
if (strlen(s) >) {
printk("Too long setup_example_string parameter, \n");
printk("maximum length is less than or equal to 15\n");
}
else {
memcpy(setup_example_string, s, strlen(s) +);
printk("setup_example_string=%s\n", setup_example_string);
}
return;
}
/*宏__setup()将分析参数的函数注册到内核中*/
__setup("setup_example_int=", parse_int);
__setup("setup_example_int_array=", parse_int_string);
__setup("setup_example_string=", parse_string);
内核子系统或设备驱动可以直接编译到内核,也可以编译成模块,如果编译到内核,可以使用前一节介绍的方法通过内核启动参数来向它们传递参数,如果编译成模块,则可以通过命令行在插入模块时传递参数,或者在运行时,通过sysfs来设置或读取模块数据。
Sysfs是一个基于内存的文件系统,实际上它基于ramfs,sysfs提供了一种把内核数据结构、它们的属性以及属性与数据结构的联系开放给用户态的方式,它与kobject子系统紧密地结合在一起,因此内核开发者不需要直接使用它,而是内核的各个子系统使用它。用户要想使用 sysfs 读取和设置内核参数,仅需装载 sysfs 就可以通过文件操作应用来读取和设置内核通过 sysfs 开放给用户的各个参数:
# mkdir -p /sysfs
$ mount -t sysfs sysfs /sysfs
注意,不要把 sysfs 和 sysctl 混淆,sysctl 是内核的一些控制参数,其目的是方便用户对内核的行为进行控制,而 sysfs
仅仅是把内核的 kobject 对象的层次关系与属性开放给用户查看,因此 sysfs 的绝大部分是只读的,模块作为一个 kobject
也被出口到 sysfs,模块参数则是作为模块属性出口的,内核实现者为模块的使用提供了更灵活的方式,允许用户设置模块参数在 sysfs
的可见性并允许用户在编写模块时设置这些参数在 sysfs 下的访问权限,然后用户就可以通过sysfs
来查看和设置模块参数,从而使得用户能在模块运行时控制模块行为。
对于模块而言,声明为 static 的变量都可以通过命令行来设置,但要想在 sysfs下可见,必须通过宏 module_param
来显式声明,该宏有三个参数,第一个为参数名,即已经定义的变量名,第二个参数则为变量类型,可用的类型有 byte, short, ushort,
int, uint, long, ulong, charp 和 bool 或 invbool,分别对应于 c 类型 char, short,
unsigned short, int, unsigned int, long, unsigned long, char * 和
int,用户也可以自定义类型 XXX(如果用户自己定义了 param_get_XXX,param_set_XXX 和
param_check_XXX)。该宏的第三个参数用于指定访问权限,如果为 0,该参数将不出现在 sysfs 文件系统中,允许的访问权限为
S_IRUSR, S_IWUSR,S_IRGRP,S_IWGRP,S_IROTH 和 S_IWOTH
的组合,它们分别对应于用户读,用户写,用户组读,用户组写,其他用户读和其他用户写,因此用文件的访问权限设置是一致的。
在源代码中的内核模块 module-param-exam.c 是一个利用模块参数和sysfs来进行用户态与内核态数据交互的例子。该模块有三个参数可以通过命令行设置,下面是作者系统上的运行结果示例:
# insmod ./module-param-exam.ko my_invisible_int= my_visible_int= mystring="Hello,World"
my_invisible_int =
my_visible_int =
mystring ='Hello,World'
# ls /sys/module/module_param_exam/parameters/
mystring my_visible_int
# cat /sys/module/module_param_exam/parameters/mystring
Hello,World
# cat /sys/module/module_param_exam/parameters/my_visible_int # echo >/sys/module/module_param_exam/parameters/my_visible_int
# cat /sys/module/module_param_exam/parameters/my_visible_int # echo "abc">/sys/module/module_param_exam/parameters/mystring
# cat /sys/module/module_param_exam/parameters/mystring
abc
# rmmod module_param_exam
my_invisible_int =
my_visible_int =
mystring ='abc'
以下为示例源码:
#include <linux/config.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/stat.h>
staticint my_invisible_int =;
staticint my_visible_int =;
staticchar* mystring ="Hello, World";
module_param(my_invisible_int, int, );
MODULE_PARM_DESC(my_invisible_int, "An invisible int under sysfs");
module_param(my_visible_int, int, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
MODULE_PARM_DESC(my_visible_int, "An visible int under sysfs");
module_param(mystring, charp, S_IRUSR | S_IWUSR | S_IRGRP | S_IROTH);
MODULE_PARM_DESC(mystring, "An visible string under sysfs");
staticint __init exam_module_init(void)
{
printk("my_invisible_int = %d\n", my_invisible_int);
printk("my_visible_int = %d\n", my_visible_int);
printk("mystring = '%s'\n", mystring);
return;
}
staticvoid __exit exam_module_exit(void)
{
printk("my_invisible_int = %d\n", my_invisible_int);
printk("my_visible_int = %d\n", my_visible_int);
printk("mystring = '%s'\n", mystring);
}
module_init(exam_module_init);
module_exit(exam_module_exit);
MODULE_AUTHOR("Yang Yi");
MODULE_DESCRIPTION("A module_param example module");
MODULE_LICENSE("GPL");
sysctl是一种用户应用来设置和获得运行时内核的配置参数的一种有效方式,通过这种方式,用户应用可以在内核运行的任何时刻来改变内核的配置参数,也可以在任何时候获得内核的配置参数,通常,内核的这些配置参数也出现在proc文件系统的/proc/sys目录下,用户应用可以直接通过这个目录下的文件来实现内核配置的读写操作,例如,用户可以通过
cat /proc/sys/net/ipv4/ip_forward
来得知内核IP层是否允许转发IP包,用户可以通过
echo 1 > /proc/sys/net/ipv4/ip_forward
把内核 IP 层设置为允许转发 IP 包,即把该机器配置成一个路由器或网关。 一般地,所有的 Linux 发布也提供了一个系统工具
sysctl,它可以设置和读取内核的配置参数,但是该工具依赖于 proc 文件系统,为了使用该工具,内核必须支持 proc 文件系统。下面是使用
sysctl 工具来获取和设置内核配置参数的例子:
# sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
# sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
# sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
注意,参数 net.ipv4.ip_forward 实际被转换到对应的 proc
文件/proc/sys/net/ipv4/ip_forward,选项 -w 表示设置该内核配置参数,没有选项表示读内核配置参数,用户可以使用
sysctl -a 来读取所有的内核配置参数,对应更多的 sysctl 工具的信息,请参考手册页 sysctl(8)。
但是 proc 文件系统对 sysctl 不是必须的,在没有 proc 文件系统的情况下,仍然可以,这时需要使用内核提供的系统调用 sysctl 来实现对内核配置参数的设置和读取。
在源代码中给出了一个实际例子程序,它说明了如何在内核和用户态使用sysctl。头文件 sysctl-exam.h 定义了 sysctl
条目 ID,用户态应用和内核模块需要这些 ID 来操作和注册 sysctl 条目。内核模块在文件 sysctl-exam-kern.c
中实现,在该内核模块中,每一个 sysctl 条目对应一个 struct ctl_table 结构,该结构定义了要注册的 sysctl 条目的
ID(字段 ctl_name),在 proc
下的名称(字段procname),对应的内核变量(字段data,注意该该字段的赋值必须是指针),条目允许的最大长度(字段maxlen,它主要用于字符串内核变量,以便在对该条目设置时,对超过该最大长度的字符串截掉后面超长的部分),条目在proc文件系统下的访问权限(字段mode),在通过
proc设置时的处理函数(字段proc_handler,对于整型内核变量,应当设置为&proc_dointvec,而对于字符串内核变量,则设置为
&proc_dostring),字符串处理策略(字段strategy,一般这是为&sysctl_string)。
sysctl 条目可以是目录,此时 mode 字段应当设置为 0555,否则通过 sysctl 系统调用将无法访问它下面的 sysctl
条目,child 则指向该目录条目下面的所有条目,对于在同一目录下的多个条目,不必一一注册,用户可以把它们组织成一个 struct
ctl_table 类型的数组,然后一次注册就可以,但此时必须把数组的最后一个结构设置为NULL,即
{
.ctl_name = 0
}
注册sysctl条目使用函数register_sysctl_table(struct ctl_table *,
int),第一个参数为定义的struct
ctl_table结构的sysctl条目或条目数组指针,第二个参数为插入到sysctl条目表中的位置,如果插入到末尾,应当为0,如果插入到开头,则为非0。内核把所有的sysctl条目都组织成sysctl表。
当模块卸载时,需要使用函数unregister_sysctl_table(struct ctl_table_header
*)解注册通过函数register_sysctl_table注册的sysctl条目,函数register_sysctl_table在调用成功时返
回结构struct ctl_table_header,它就是sysctl表的表头,解注册函数使用它来卸载相应的sysctl条目。
用户态应用sysctl-exam-user.c通过sysctl系统调用来查看和设置前面内核模块注册的sysctl条目(当然如果用户的系统内核已经支持proc文件系统,可以直接使用文件操作应用如cat,
echo等直接查看和设置这些sysctl条目)。
下面是作者运行该模块与应用的输出结果示例:
# insmod ./sysctl-exam-kern.ko
# cat /proc/sys/mysysctl/myint # cat /proc/sys/mysysctl/mystring
# ./sysctl-exam-user
mysysctl.myint =
mysysctl.mystring =""
# ./sysctl-exam-user "Hello, World"
old value: mysysctl.myint =
new value: mysysctl.myint =
old vale: mysysctl.mystring =""
new value: mysysctl.mystring ="Hello, World"
# cat /proc/sys/mysysctl/myint # cat /proc/sys/mysysctl/mystring
Hello, World
#
示例:
头文件:sysctl-exam.h:
//header: sysctl-exam.h
#ifndef _SYSCTL_EXAM_H
#define _SYSCTL_EXAM_H
#include <linux/sysctl.h> #define MY_ROOT (CTL_CPU + 10)
#define MY_MAX_SIZE 256 enum {
MY_INT_EXAM =,
MY_STRING_EXAM =,
};
#endif
内核模块代码 sysctl-exam-kern.c:
//kernel module: sysctl-exam-kern.c
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sysctl.h>
#include "sysctl-exam.h" staticchar mystring[];
staticint myint; staticstruct ctl_table my_sysctl_exam[] = {
{
.ctl_name = MY_INT_EXAM,
.procname ="myint",
.data =&myint,
.maxlen =sizeof(int),
.mode =,
.proc_handler =&proc_dointvec,
},
{
.ctl_name = MY_STRING_EXAM,
.procname ="mystring",
.data = mystring,
.maxlen = MY_MAX_SIZE,
.mode =,
.proc_handler =&proc_dostring,
.strategy =&sysctl_string,
},
{
.ctl_name =
}
}; staticstruct ctl_table my_root = {
.ctl_name = MY_ROOT,
.procname ="mysysctl",
.mode =,
.child = my_sysctl_exam,
}; staticstruct ctl_table_header * my_ctl_header; staticint __init sysctl_exam_init(void)
{
my_ctl_header = register_sysctl_table(&my_root, ); return;
} staticvoid __exit sysctl_exam_exit(void)
{
unregister_sysctl_table(my_ctl_header);
} module_init(sysctl_exam_init);
module_exit(sysctl_exam_exit);
MODULE_LICENSE("GPL");
用户程序 sysctl-exam-user.c:
#include <linux/unistd.h>
#include <linux/types.h>
#include <linux/sysctl.h>
#include "sysctl-exam.h"
#include <stdio.h>
#include <errno.h>
_syscall1(int, _sysctl, struct __sysctl_args *, args);
int sysctl(int*name, int nlen, void*oldval, size_t *oldlenp, void*newval, size_t newlen)
{
struct __sysctl_args args={name,nlen,oldval,oldlenp,newval,newlen};
return _sysctl(&args);
}
#define SIZE(x) sizeof(x)/sizeof(x[0])
#define OSNAMESZ 100
int oldmyint;
int oldmyintlen;
int newmyint;
int newmyintlen;
char oldmystring[MY_MAX_SIZE];
int oldmystringlen;
char newmystring[MY_MAX_SIZE];
int newmystringlen;
int myintctl[] = {MY_ROOT, MY_INT_EXAM};
int mystringctl[] = {MY_ROOT, MY_STRING_EXAM};
int main(int argc, char** argv)
{
if (argc <)
{
oldmyintlen =sizeof(int);
if (sysctl(myintctl, SIZE(myintctl), &oldmyint, &oldmyintlen, , )) {
perror("sysctl");
exit(-);
}
else {
printf("mysysctl.myint = %d\n", oldmyint);
}
oldmystringlen = MY_MAX_SIZE;
if (sysctl(mystringctl, SIZE(mystringctl), oldmystring, &oldmystringlen, , )) {
perror("sysctl");
exit(-);
}
else {
printf("mysysctl.mystring = \"%s\"\n", oldmystring);
}
}
elseif (argc !=)
{
printf("Usage:\n");
printf("\tsysctl-exam-user\n");
printf("Or\n");
printf("\tsysctl-exam-user aint astring\n");
}
else
{
newmyint = atoi(argv[]);
newmyintlen =sizeof(int);
oldmyintlen =sizeof(int);
strcpy(newmystring, argv[]);
newmystringlen = strlen(newmystring);
oldmystringlen = MY_MAX_SIZE;
if (sysctl(myintctl, SIZE(myintctl), &oldmyint, &oldmyintlen, &newmyint, newmyintlen)) {
perror("sysctl");
exit(-);
}
else {
printf("old value: mysysctl.myint = %d\n", oldmyint);
printf("new value: mysysctl.myint = %d\n", newmyint);
}
if (sysctl(mystringctl, SIZE(mystringctl), oldmystring, &oldmystringlen, newmystring, newmystringlen))
perror("sysctl");
exit(-);
}
else {
printf("old vale: mysysctl.mystring = \"%s\"\n", oldmystring);
printf("new value: mysysctl.mystring = \"%s\"\n", newmystring);
}
}
exit();
}
系统调用是内核提供给应用程序的接口,应用对底层硬件的操作大部分都是通过调用系统调用来完成的,例如得到和设置系统时间,就需要分别调用 gettimeofday 和 settimeofday 来实现。事实上,所有的系统调用都涉及到内核与应用之间的数据交换,如文件系统操作函数 read 和 write,设置和读取网络协议栈的 setsockopt 和 getsockopt。本节并不是讲解如何增加新的系统调用,而是讲解如何利用现有系统调用来实现用户的数据传输需求。
一般地,用户可以建立一个伪设备来作为应用与内核之间进行数据交换的渠道,最通常的做法是使用伪字符设备,具体实现方法是:
1.定义对字符设备进行操作的必要函数并设置结构 struct file_operations
结构 struct file_operations 非常大,对于一般的数据交换需求,只定义 open, read, write, ioctl, mmap 和 release 函数就足够了,它们实际上对应于用户态的文件系统操作函数 open, read, write, ioctl, mmap 和 close。这些函数的原型示例如下:
ssize_t exam_read (struct file * file, char __user * buf, size_t count, loff_t * ppos)
{
…
} ssize_t exam_write(struct file * file, constchar __user * buf, size_t count, loff_t * ppos)
{
…
} int exam_ioctl(struct inode * inode, struct file * file, unsigned int cmd, unsigned long argv)
{
…
} int exam_mmap(struct file *, struct vm_area_struct *)
{
…
} int exam_open(struct inode * inode, struct file * file)
{
…
} int exam_release(struct inode * inode, struct file * file)
{
…
}
在定义了这些操作函数后需要定义并设置结构struct file_operations
struct file_operations exam_file_ops = {
.owner = THIS_MODULE,
.read = exam_read,
.write = exam_write,
.ioctl = exam_ioctl,
.mmap = exam_mmap,
.open = exam_open,
.release = exam_release,
};
2. 注册定义的伪字符设备并把它和上面的 struct file_operations 关联起来:
int exam_char_dev_major;
exam_char_dev_major = register_chrdev(0, "exam_char_dev", &exam_file_ops);
注意,函数 register_chrdev 的第一个参数如果为
0,表示由内核来确定该注册伪字符设备的主设备号,这是该函数的返回为实际分配的主设备号,如果返回小于
0,表示注册失败。因此,用户在使用该函数时必须判断返回值以便处理失败情况。为了使用该函数必须包含头文件 linux/fs.h。
在源代码包中给出了一个使用这种方式实现用户态与内核态数据交换的典型例子,它包含了三个文件:头文件 syscall-exam.h 定义了
ioctl 命令,.c 文件 syscall-exam-user.c为用户态应用,它通过文件系统操作函数 mmap 和 ioctl
来与内核态模块交换数据,.c 文件 syscall-exam-kern.c
为内核模块,它实现了一个伪字符设备,以便与用户态应用进行数据交换。为了正确运行应用程序 syscall-exam-user,需要在插入模块
syscall-exam-kern 后创建该实现的伪字符设备,用户可以使用下面命令来正确创建设备:
$ mknod /dev/mychrdev c `dmesg | grep "char device mychrdev" | sed 's/.*major is //g'` 0
然后用户可以通过 cat 来读写 /dev/mychrdev,应用程序 syscall-exam-user则使用 mmap 来读数据并使用 ioctl 来得到该字符设备的信息以及裁减数据内容,它只是示例如何使用现有的系统调用来实现用户需要的数据交互操作。
下面是作者运行该模块的结果示例:
$ insmod ./syscall-exam-kern.ko
char device mychrdev is registered, major is
$ mknod /dev/mychrdev c `dmesg | grep "char device mychrdev"| sed 's/.*major is //g'`
$ cat /dev/mychrdev
$ echo "abcdefghijklmnopqrstuvwxyz">/dev/mychrdev
$ cat /dev/mychrdev
abcdefghijklmnopqrstuvwxyz
$ ./syscall-exam-user
User process: syscall-exam-us()
Available space: bytes
Data len: bytes
Offset in physical: cc0 bytes
mychrdev content by mmap:
abcdefghijklmnopqrstuvwxyz
$ cat /dev/mychrdev
abcde
$
示例:
头文件 syscall-exam.h:
//header: syscall-exam.h
#ifndef _SYSCALL_EXAM_H
#define _SYSCALL_EXAM_H #include <linux/ioctl.h> #undef TASK_COMM_LEN
#define TASK_COMM_LEN 16 typedef struct mychrdev_info {
pid_t user_pid;
char user_name[TASK_COMM_LEN];
unsigned int available_len;
unsigned int len;
unsigned long offset_in_ppage;
} mydev_info_t; struct mychrdev_window {
unsigned int head;
unsigned int tail;
}; #define MYCHRDEV_IOCTL_BASE 'm'
#define MYCHRDEV_IOR(nr, size) _IOR(MYCHRDEV_IOCTL_BASE, nr, size)
#define MYCHRDEV_IOW(nr, size) _IOW(MYCHRDEV_IOCTL_BASE, nr, size) #define MYCHRDEV_IOCTL_GET_INFO MYCHRDEV_IOR(0x01,mydev_info_t)
#define MYCHRDEV_IOCTL_SET_TRUNCATE MYCHRDEV_IOW(0x02,int)
#endif
内核模块源码 syscall-exam-kern.c:
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/fs.h>
#include <linux/string.h>
#include <asm/uaccess.h>
#include <linux/mm.h>
#include "syscall-exam.h"
#define MYCHRDEV_MAX_MINOR 4
#define MYCHRDEV_CAPACITY 65536
struct mychrdev_data {
char buf[MYCHRDEV_CAPACITY];
unsigned int headptr;
unsigned int tailptr;
};
struct mychrdev_data * mydata[MYCHRDEV_MAX_MINOR];
static atomic_t mychrdev_use_stats[MYCHRDEV_MAX_MINOR];
staticint mychrdev_major;
struct mychrdev_private {
pid_t user_pid;
char user_name[TASK_COMM_LEN];
int minor;
struct mychrdev_data * data;
#define headptr data->headptr
#define tailptr data->tailptr
#define buffer data->buf
};
ssize_t mychrdev_read(struct file * file, char __user * buf, size_t count, loff_t * ppos)
{
int len;
struct mychrdev_private * myprivate = (struct mychrdev_private *)file->private_data;
len = (int)(myprivate->tailptr - myprivate->headptr);
if (*ppos >= len) {
return;
}
if (*ppos + count > len) {
count = len -*ppos;
}
if (copy_to_user(buf, myprivate->buffer + myprivate->headptr +*ppos, count)) {
return-EFAULT;
}
*ppos += count;
return count;
}
ssize_t mychrdev_write(struct file * file, constchar __user * buf, size_t count, loff_t * ppos)
{
int leftlen;
struct mychrdev_private * myprivate = (struct mychrdev_private *)file->private_data;
leftlen = (MYCHRDEV_CAPACITY - myprivate->tailptr);
if (* ppos >= MYCHRDEV_CAPACITY) {
return-ENOBUFS;
}
if (*ppos + count > leftlen) {
count = leftlen -*ppos;
}
if (copy_from_user(myprivate->buffer + myprivate->headptr +*ppos, buf, count)) {
return-EFAULT;
}
*ppos += count;
myprivate->tailptr += count;
return count;;
}
int mychrdev_ioctl(struct inode * inode, struct file * file, unsigned int cmd, unsigned long argp)
{
struct mychrdev_private * myprivate = (struct mychrdev_private *)file->private_data;
mydev_info_t a;
struct mychrdev_window window;
switch(cmd) {
case MYCHRDEV_IOCTL_GET_INFO:
a.user_pid = myprivate->user_pid;
memcpy(a.user_name, myprivate->user_name, strlen(myprivate->user_name));
a.available_len = MYCHRDEV_CAPACITY - myprivate->tailptr;
a.len = myprivate->tailptr - myprivate->headptr;
a.offset_in_ppage = __pa(myprivate) &0x00000fff;
if (copy_to_user((void*)argp, (void*)&a, sizeof(a))) {
return-EFAULT;
}
break;
case MYCHRDEV_IOCTL_SET_TRUNCATE:
if (copy_from_user(&window, (void*)argp, sizeof(window))) {
return-EFAULT;
}
if (window.head < myprivate->headptr) {
return-EINVAL;
}
if (window.tail > myprivate->tailptr) {
return-EINVAL;
}
myprivate->headptr = window.head;
myprivate->tailptr = window.tail;
break;
default:
return-EINVAL;
}
return;
}
int mychrdev_open(struct inode * inode, struct file * file)
{
struct mychrdev_private * myprivate = NULL;
int minor;
if (current->euid !=) {
return-EPERM;
}
minor = MINOR(inode->i_rdev);
if (atomic_read(&mychrdev_use_stats[minor])) {
return-EBUSY;
}
else {
atomic_inc(&mychrdev_use_stats[minor]);
}
myprivate = (struct mychrdev_private *)kmalloc(sizeof(struct mychrdev_private), GFP_KERNEL);
if (myprivate == NULL) {
return-ENOMEM;
}
myprivate->user_pid = current->pid;
sprintf(myprivate->user_name, "%s", current->comm);
myprivate->minor = minor;
myprivate->data = mydata[minor];
file->private_data = (void*)myprivate;
return;
}
int mychrdev_mmap(struct file * file, struct vm_area_struct * vma)
{
unsigned long pfn;
struct mychrdev_private * myprivate = (struct mychrdev_private *)file->private_data;
/* Turn a kernel-virtual address into a physical page frame */
pfn = __pa(&(mydata[myprivate->minor]->buf)) >> PAGE_SHIFT;
if (!pfn_valid(pfn))
return-EIO;
vma->vm_flags |= VM_RESERVED;
vma->vm_page_prot = pgprot_noncached(vma->vm_page_prot);
/* Remap-pfn-range will mark the range VM_IO and VM_RESERVED */
if (remap_pfn_range(vma,
vma->vm_start,
pfn,
vma->vm_end - vma->vm_start,
vma->vm_page_prot))
return-EAGAIN;
return;
}
int mychrdev_release(struct inode * inode, struct file * file)
{
atomic_dec(&mychrdev_use_stats[MINOR(inode->i_rdev)]);
kfree(((struct mychrdev_private *)(file->private_data))->data);
kfree(file->private_data);
return;
}
loff_t mychrdev_llseek(struct file * file, loff_t offset, int seek_flags)
{
struct mychrdev_private * myprivate = (struct mychrdev_private *)file->private_data;
int len = myprivate->tailptr - myprivate->headptr;
switch (seek_flags) {
case:
if ((offset > len)
|| (offset <)) {
return-EINVAL;
}
case:
if ((offset + file->f_pos <)
|| (offset + file->f_pos > len)) {
return-EINVAL;
}
offset += file->f_pos;
case:
if ((offset >)
|| (-offset > len)) {
return-EINVAL;
}
offset += len;
break;
default:
return-EINVAL;
}
if ((offset >=) && (offset <= len)) {
file->f_pos = offset;
file->f_version =;
return offset;
}
else {
return-EINVAL;
}
}
struct file_operations mychrdev_fops = {
.owner = THIS_MODULE,
.read = mychrdev_read,
.write = mychrdev_write,
.ioctl = mychrdev_ioctl,
.open = mychrdev_open,
.llseek = mychrdev_llseek,
.release = mychrdev_release,
.mmap = mychrdev_mmap,
};
staticint __init mychardev_init(void)
{
int i;
for (i=;i<MYCHRDEV_MAX_MINOR;i++) {
atomic_set(&mychrdev_use_stats[i], );
mydata[i] = NULL;
mydata[i] =
(struct mychrdev_data *)kmalloc(sizeof(struct mychrdev_data), GFP_KERNEL);
if (mydata[i] == NULL) {
return-ENOMEM;
}
memset(mydata[i], , sizeof(struct mychrdev_data));
}
mychrdev_major = register_chrdev(, "mychrdev", &mychrdev_fops);
if (mychrdev_major <=) {
printk("Fail to register char device mychrdev.\n");
return-;
}
printk("char device mychrdev is registered, major is %d\n", mychrdev_major);
return;
}
staticvoid __exit mychardev_remove(void)
{
unregister_chrdev(mychrdev_major, NULL);
}
module_init(mychardev_init);
module_exit(mychardev_remove);
MODULE_LICENSE("GPL");
用户程序 syscall-exam-user.c:
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#include <sys/mman.h>
#include "syscall-exam.h"
int main(void)
{
int fd;
mydev_info_t mydev_info;
struct mychrdev_window truncate_window;
char* mmap_ptr = NULL;
int i;
fd = open("/dev/mychrdev", O_RDWR);
if (fd <) {
perror("open:");
exit(-);
}
ioctl(fd, MYCHRDEV_IOCTL_GET_INFO, &mydev_info);
printf("User process: %s(%d)\n", mydev_info.user_name, mydev_info.user_pid);
printf("Available space: %d bytes\n", mydev_info.available_len);
printf("Data len: %d bytes\n", mydev_info.len);
printf("Offset in physical: %lx bytes\n", mydev_info.offset_in_ppage);
mmap_ptr = mmap(NULL, , PROT_READ, MAP_PRIVATE, fd, );
if ((int) mmap_ptr ==-) {
perror("mmap:");
close(fd);
exit(-);
}
printf("mychrdev content by mmap:\n");
printf("%s\n", mmap_ptr);
munmap(mmap_ptr, );
truncate_window.head =;
truncate_window.tail =;
ioctl(fd, MYCHRDEV_IOCTL_SET_TRUNCATE, &truncate_window);
close(fd);
}
Netlink 是一种特殊的 socket,它是 Linux 所特有的,类似于 BSD 中的AF_ROUTE 但又远比它的功能强大,目前在最新的 Linux 内核(2.6.14)中使用netlink 进行应用与内核通信的应用很多,包括:
路由 daemon(NETLINK_ROUTE),
1-wire 子系统(NETLINK_W1),
用户态 socket 协议(NETLINK_USERSOCK),
防火墙(NETLINK_FIREWALL),
socket 监视(NETLINK_INET_DIAG),
netfilter 日志(NETLINK_NFLOG),
ipsec 安全策略(NETLINK_XFRM),
SELinux 事件通知(NETLINK_SELINUX),
iSCSI 子系统(NETLINK_ISCSI),
进程审计(NETLINK_AUDIT),
转发信息表查询(NETLINK_FIB_LOOKUP),
netlink connector(NETLINK_CONNECTOR),
netfilter 子系统(NETLINK_NETFILTER),
IPv6 防火墙(NETLINK_IP6_FW),
DECnet 路由信息(NETLINK_DNRTMSG),
内核事件向用户态通知(NETLINK_KOBJECT_UEVENT),
通用 netlink(NETLINK_GENERIC)。
Netlink 是一种在内核与用户应用间进行双向数据传输的非常好的方式,用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能,内核态需要使用专门的内核 API 来使用 netlink。
Netlink 相对于系统调用,ioctl 以及 /proc 文件系统而言具有以下优点:
1,为了使用 netlink,用户仅需要在 include/linux/netlink.h 中增加一个新类型的 netlink
协议定义即可,如 #define NETLINK_MYTEST 17 然后,内核和用户态应用就可以立即通过 socket API 使用该
netlink 协议类型进行数据交换。但系统调用需要增加新的系统调用,ioctl 则需要增加设备或文件, 那需要不少代码,proc
文件系统则需要在 /proc 下添加新的文件或目录,那将使本来就混乱的 /proc 更加混乱。
2.
netlink是一种异步通信机制,在内核与用户态应用之间传递的消息保存在socket缓存队列中,发送消息只是把消息保存在接收者的socket的接
收队列,而不需要等待接收者收到消息,但系统调用与 ioctl 则是同步通信机制,如果传递的数据太长,将影响调度粒度。
3.使用 netlink 的内核部分可以采用模块的方式实现,使用 netlink 的应用部分和内核部分没有编译时依赖,但系统调用就有依赖,而且新的系统调用的实现必须静态地连接到内核中,它无法在模块中实现,使用新系统调用的应用在编译时需要依赖内核。
4.netlink 支持多播,内核模块或应用可以把消息多播给一个netlink组,属于该neilink
组的任何内核模块或应用都能接收到该消息,内核事件向用户态的通知机制就使用了这一特性,任何对内核事件感兴趣的应用都能收到该子系统发送的内核事件,在后面的文章中将介绍这一机制的使用。
5.内核可以使用 netlink 首先发起会话,但系统调用和 ioctl 只能由用户应用发起调用。
6.netlink 使用标准的 socket API,因此很容易使用,但系统调用和 ioctl则需要专门的培训才能使用。
用户态使用 netlink
用户态应用使用标准的socket APIs, socket(), bind(), sendmsg(), recvmsg() 和
close() 就能很容易地使用 netlink socket,查询手册页可以了解这些函数的使用细节,本文只是讲解使用 netlink
的用户应该如何使用这些函数。注意,使用 netlink 的应用必须包含头文件 linux/netlink.h。当然 socket
需要的头文件也必不可少,sys/socket.h。
为了创建一个 netlink socket,用户需要使用如下参数调用 socket():
socket(AF_NETLINK, SOCK_RAW, netlink_type)
第一个参数必须是 AF_NETLINK 或 PF_NETLINK,在 Linux
中,它们俩实际为一个东西,它表示要使用netlink,第二个参数必须是SOCK_RAW或SOCK_DGRAM,
第三个参数指定netlink协议类型,如前面讲的用户自定义协议类型NETLINK_MYTEST,
NETLINK_GENERIC是一个通用的协议类型,它是专门为用户使用的,因此,用户可以直接使用它,而不必再添加新的协议类型。内核预定义的协议类型有:
#define NETLINK_ROUTE 0 /* Routing/device hook */
#define NETLINK_W1 1 /* 1-wire subsystem */
#define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols */
#define NETLINK_FIREWALL 3 /* Firewalling hook */
#define NETLINK_INET_DIAG 4 /* INET socket monitoring */
#define NETLINK_NFLOG 5 /* netfilter/iptables ULOG */
#define NETLINK_XFRM 6 /* ipsec */
#define NETLINK_SELINUX 7 /* SELinux event notifications */
#define NETLINK_ISCSI 8 /* Open-iSCSI */
#define NETLINK_AUDIT 9 /* auditing */
#define NETLINK_FIB_LOOKUP 10
#define NETLINK_CONNECTOR 11
#define NETLINK_NETFILTER 12 /* netfilter subsystem */
#define NETLINK_IP6_FW 13
#define NETLINK_DNRTMSG 14 /* DECnet routing messages */
#define NETLINK_KOBJECT_UEVENT 15 /* Kernel messages to userspace */
#define NETLINK_GENERIC 16
对于每一个netlink协议类型,可以有多达 32多播组,每一个多播组用一个位表示,netlink 的多播特性使得发送消息给同一个组仅需要一次系统调用,因而对于需要多拨消息的应用而言,大大地降低了系统调用的次数。
函数 bind() 用于把一个打开的 netlink socket 与 netlink 源 socket 地址绑定在一起。netlink socket 的地址结构如下:
struct sockaddr_nl
{
sa_family_t nl_family;
unsigned short nl_pad;
__u32 nl_pid;
__u32 nl_groups;
};
字段 nl_family 必须设置为 AF_NETLINK 或着 PF_NETLINK,字段 nl_pad 当前没有使用,因此要总是设置为 0,字段 nl_pid 为接收或发送消息的进程的 ID,如果希望内核处理消息或多播消息,就把该字段设置为 0,否则设置为处理消息的进程 ID。字段 nl_groups 用于指定多播组,bind 函数用于把调用进程加入到该字段指定的多播组,如果设置为 0,表示调用者不加入任何多播组。
传递给 bind 函数的地址的 nl_pid 字段应当设置为本进程的进程 ID,这相当于 netlink socket 的本地地址。但是,对于一个进程的多个线程使用 netlink socket 的情况,字段 nl_pid 则可以设置为其它的值,如:
pthread_self() << 16 | getpid();
因此字段 nl_pid 实际上未必是进程 ID,它只是用于区分不同的接收者或发送者的一个标识,用户可以根据自己需要设置该字段。函数 bind 的调用方式如下:
bind(fd, (struct sockaddr*)&nladdr, sizeof(struct sockaddr_nl));
fd为前面的 socket 调用返回的文件描述符,参数 nladdr 为 struct sockaddr_nl 类型的地址。 为了发送一个 netlink 消息给内核或其他用户态应用,需要填充目标 netlink socket 地址 ,此时,字段 nl_pid 和 nl_groups 分别表示接收消息者的进程 ID 与多播组。如果字段 nl_pid 设置为 0,表示消息接收者为内核或多播组,如果 nl_groups为 0,表示该消息为单播消息,否则表示多播消息。 使用函数 sendmsg 发送 netlink 消息时还需要引用结构 struct msghdr、struct nlmsghdr 和 struct iovec,结构 struct msghdr 需如下设置:
struct msghdr msg;
memset(&msg, , sizeof(msg));
msg.msg_name = (void*)&(nladdr);
msg.msg_namelen =sizeof(nladdr);
其中 nladdr 为消息接收者的 netlink 地址。
struct nlmsghdr 为 netlink socket 自己的消息头,这用于多路复用和多路分解 netlink
定义的所有协议类型以及其它一些控制,netlink
的内核实现将利用这个消息头来多路复用和多路分解已经其它的一些控制,因此它也被称为netlink 控制块。因此,应用在发送 netlink
消息时必须提供该消息头。
struct nlmsghdr
{
__u32 nlmsg_len; /* Length of message */
__u16 nlmsg_type; /* Message type*/
__u16 nlmsg_flags; /* Additional flags */
__u32 nlmsg_seq; /* Sequence number */
__u32 nlmsg_pid; /* Sending process PID */
};
字段 nlmsg_len 指定消息的总长度,包括紧跟该结构的数据部分长度以及该结构的大小,字段 nlmsg_type
用于应用内部定义消息的类型,它对 netlink 内核实现是透明的,因此大部分情况下设置为 0,字段 nlmsg_flags
用于设置消息标志,可用的标志包括:
/* Flags values */
#define NLM_F_REQUEST 1 /* It is request message. */
#define NLM_F_MULTI 2 /* Multipart message, terminated by NLMSG_DONE */
#define NLM_F_ACK 4 /* Reply with ack, with zero or error code */
#define NLM_F_ECHO 8 /* Echo this request */ /* Modifiers to GET request */
#define NLM_F_ROOT 0x100 /* specify tree root */
#define NLM_F_MATCH 0x200 /* return all matching */
#define NLM_F_ATOMIC 0x400 /* atomic GET */
#define NLM_F_DUMP (NLM_F_ROOT|NLM_F_MATCH) /* Modifiers to NEW request */
#define NLM_F_REPLACE 0x100 /* Override existing */
#define NLM_F_EXCL 0x200 /* Do not touch, if it exists */
#define NLM_F_CREATE 0x400 /* Create, if it does not exist */
#define NLM_F_APPEND 0x800 /* Add to end of list */
标志NLM_F_REQUEST用于表示消息是一个请求,所有应用首先发起的消息都应设置该标志。
标志NLM_F_MULTI 用于指示该消息是一个多部分消息的一部分,后续的消息可以通过宏NLMSG_NEXT来获得。
宏NLM_F_ACK表示该消息是前一个请求消息的响应,顺序号与进程ID可以把请求与响应关联起来。
标志NLM_F_ECHO表示该消息是相关的一个包的回传。
标志NLM_F_ROOT 被许多 netlink
协议的各种数据获取操作使用,该标志指示被请求的数据表应当整体返回用户应用,而不是一个条目一个条目地返回。有该标志的请求通常导致响应消息设置
NLM_F_MULTI标志。注意,当设置了该标志时,请求是协议特定的,因此,需要在字段 nlmsg_type 中指定协议类型。
标志 NLM_F_MATCH 表示该协议特定的请求只需要一个数据子集,数据子集由指定的协议特定的过滤器来匹配。
标志 NLM_F_ATOMIC 指示请求返回的数据应当原子地收集,这预防数据在获取期间被修改。
标志 NLM_F_DUMP 未实现。
标志 NLM_F_REPLACE 用于取代在数据表中的现有条目。
标志 NLM_F_EXCL_ 用于和 CREATE 和 APPEND 配合使用,如果条目已经存在,将失败。
标志 NLM_F_CREATE 指示应当在指定的表中创建一个条目。
标志 NLM_F_APPEND 指示在表末尾添加新的条目。
内核需要读取和修改这些标志,对于一般的使用,用户把它设置为 0 就可以,只是一些高级应用(如 netfilter 和路由 daemon
需要它进行一些复杂的操作),字段 nlmsg_seq 和 nlmsg_pid 用于应用追踪消息,前者表示顺序号,后者为消息来源进程
ID。下面是一个示例:
#define MAX_MSGSIZE 1024 char buffer[] ="An example message";
struct nlmsghdr nlhdr;
nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(MAX_MSGSIZE));
strcpy(NLMSG_DATA(nlhdr),buffer);
nlhdr->nlmsg_len = NLMSG_LENGTH(strlen(buffer));
nlhdr->nlmsg_pid = getpid(); /* self pid */
nlhdr->nlmsg_flags =;
结构 struct iovec 用于把多个消息通过一次系统调用来发送,下面是该结构使用示例:
struct iovec iov;
iov.iov_base = (void*)nlhdr;
iov.iov_len = nlh->nlmsg_len;
msg.msg_iov =&iov;
msg.msg_iovlen =;
在完成以上步骤后,消息就可以通过下面语句直接发送:
sendmsg(fd, &msg, 0);
应用接收消息时需要首先分配一个足够大的缓存来保存消息头以及消息的数据部分,然后填充消息头,添完后就可以直接调用函数 recvmsg() 来接收。
#define MAX_NL_MSG_LEN 1024 struct sockaddr_nl nladdr;
struct msghdr msg;
struct iovec iov;
struct nlmsghdr * nlhdr;
nlhdr = (struct nlmsghdr *)malloc(MAX_NL_MSG_LEN);
iov.iov_base = (void*)nlhdr;
iov.iov_len = MAX_NL_MSG_LEN;
msg.msg_name = (void*)&(nladdr);
msg.msg_namelen =sizeof(nladdr);
msg.msg_iov =&iov;
msg.msg_iovlen =;
recvmsg(fd, &msg, );
注意:fd为socket调用打开的netlink socket描述符。
在消息接收后,nlhdr指向接收到的消息的消息头,nladdr保存了接收到的消息的目标地址,宏NLMSG_DATA(nlhdr)返回指向消息的数据部分的指针。
在linux/netlink.h中定义了一些方便对消息进行处理的宏,这些宏包括:
#define NLMSG_ALIGNTO 4
/*宏NLMSG_ALIGN(len)用于得到不小于len且字节对齐的最小数值*/
#define NLMSG_ALIGN(len) ( ((len)+NLMSG_ALIGNTO-1) & ~(NLMSG_ALIGNTO-1) ) /*宏NLMSG_LENGTH(len)用于计算数据部分长度为len时实际的消息长度。它一般用于分配消息缓存*/
#define NLMSG_LENGTH(len) ((len)+NLMSG_ALIGN(sizeof(struct nlmsghdr))) /*宏NLMSG_SPACE(len)返回不小于NLMSG_LENGTH(len)且字节对齐的最小数值,它也用于分配消息缓存*/
#define NLMSG_SPACE(len) NLMSG_ALIGN(NLMSG_LENGTH(len)) /*宏NLMSG_DATA(nlh)用于取得消息的数据部分的首地址,设置和读取消息数据部分时需要使用该宏*/
#define NLMSG_DATA(nlh) ((void*)(((char*)nlh) + NLMSG_LENGTH(0))) /*宏NLMSG_NEXT(nlh,len)用于得到下一个消息的首地址,同时len也减少为剩余消息的总长度,该宏一般
在一个消息被分成几个部分发送或接收时使用*/
#define NLMSG_NEXT(nlh,len) ((len) -= NLMSG_ALIGN((nlh)->nlmsg_len), \ (struct nlmsghdr*)(((char*)(nlh)) + NLMSG_ALIGN((nlh)->nlmsg_len))) /*宏NLMSG_OK(nlh,len)用于判断消息是否有len这么长*/
#define NLMSG_OK(nlh,len) ((len) >= (int)sizeof(struct nlmsghdr) && \ (nlh)->nlmsg_len >=sizeof(struct nlmsghdr) && \ (nlh)->nlmsg_len <= (len)) /*宏NLMSG_PAYLOAD(nlh,len)用于返回payload的长度*/
#define NLMSG_PAYLOAD(nlh,len) ((nlh)->nlmsg_len - NLMSG_SPACE((len)))
函数close用于关闭打开的netlink socket。
netlink内核API
netlink的内核实现在.c文件net/core/af_netlink.c中,内核模块要想使用netlink,也必须包含头文件 linux/netlink.h。内核使用netlink需要专门的API,这完全不同于用户态应用对netlink的使用。如果用户需要增加新的 netlink协议类型,必须通过修改linux/netlink.h来实现,当然,目前的netlink实现已经包含了一个通用的协议类型 NETLINK_GENERIC以方便用户使用,用户可以直接使用它而不必增加新的协议类型。前面讲到,为了增加新的netlink协议类型,用户仅需增 加如下定义到linux/netlink.h就可以:
#define NETLINK_MYTEST 17
只要增加这个定义之后,用户就可以在内核的任何地方引用该协议。
在内核中,为了创建一个netlink socket用户需要调用如下函数:
struct sock *
netlink_kernel_create(int unit, void (*input)(struct sock *sk, int len));
参数unit表示netlink协议类型,如NETLINK_MYTEST,参数input则为内核模块定义的netlink消息处理函数,当有消
息到达这个netlink
socket时,该input函数指针就会被引用。函数指针input的参数sk实际上就是函数netlink_kernel_create返回的
struct sock指针,sock实际是socket的一个内核表示数据结构,用户态应用创建的socket在内核中也会有一个struct
sock结构来表示。下面是一个input函数的示例:
void input (struct sock *sk, int len)
{
struct sk_buff *skb;
struct nlmsghdr *nlh = NULL;
u8 *data = NULL;
while ((skb = skb_dequeue(&sk->receive_queue)) != NULL)
{
/* process netlink message pointed by skb->data */
nlh = (struct nlmsghdr *)skb->data;
data = NLMSG_DATA(nlh);
/* process netlink message with header pointed by
* nlh and data pointed by data
*/
}
}
函数input()会在发送进程执行sendmsg()时被调用,这样处理消息比较及时,但是,如果消息特别长时,这样处理将增加系统调用 sendmsg()的执行时间,对于这种情况,可以定义一个内核线程专门负责消息接收,而函数input的工作只是唤醒该内核线程,这样sendmsg将 很快返回。
函数skb = skb_dequeue(&sk->receive_queue)用于取得socket sk的接收队列上的消息,返回为一个struct sk_buff的结构,skb->data指向实际的netlink消息。
函数skb_recv_datagram(nl_sk)也用于在netlink socket nl_sk上接收消息,与skb_dequeue的不同指出是,如果socket的接收队列上没有消息,它将导致调用进程睡眠在等待队列nl_sk- >sk_sleep,因此它必须在进程上下文使用,刚才讲的内核线程就可以采用这种方式来接收消息。
下面的函数input就是这种使用的示例:
void input (struct sock *sk, int len)
{
wake_up_interruptible(sk->sk_sleep);
}
当内核中发送netlink消息时,也需要设置目标地址与源地址,而且内核中消息是通过struct sk_buff来管理的, linux/netlink.h中定义了一个宏:
#define NETLINK_CB(skb) (*(struct netlink_skb_parms*)&((skb)->cb))
来方便消息的地址设置。下面是一个消息地址设置的例子:
NETLINK_CB(skb).pid =; NETLINK_CB(skb).dst_pid =; NETLINK_CB(skb).dst_group =;
字段pid表示消息发送者进程ID,也即源地址,对于内核,它为 0, dst_pid 表示消息接收者进程
ID,也即目标地址,如果目标为组或内核,它设置为 0,否则 dst_group 表示目标组地址,如果它目标为某一进程或内核,dst_group
应当设置为 0。
在内核中,模块调用函数 netlink_unicast 来发送单播消息:
int netlink_unicast(struct sock *sk, struct sk_buff *skb, u32 pid, int nonblock);
参数sk为函数netlink_kernel_create()返回的socket,参数skb存放消息,它的data字段指向要发送的
netlink消息结构,而skb的控制块保存了消息的地址信息,前面的宏NETLINK_CB(skb)就用于方便设置该控制块,
参数pid为接收消息进程的pid,参数nonblock表示该函数是否为非阻塞,如果为1,该函数将在没有接收缓存可利用时立即返回,而如果为0,该函
数在没有接收缓存可利用时睡眠。
内核模块或子系统也可以使用函数netlink_broadcast来发送广播消息:
void netlink_broadcast(struct sock *sk, struct sk_buff *skb, u32 pid, u32 group, int allocation);
前面的三个参数与netlink_unicast相同,参数group为接收消息的多播组,该参数的每一个代表一个多播组,因此如果发送给多个多播组,就把该参数设置为多个多播组组ID的位或。参数allocation为内核内存分配类型,一般地为GFP_ATOMIC或GFP_KERNEL,
GFP_ATOMIC用于原子的上下文(即不可以睡眠),而GFP_KERNEL用于非原子上下文。
在内核中使用函数sock_release来释放函数netlink_kernel_create()创建的netlink socket:
void sock_release(struct socket * sock);
注意函数netlink_kernel_create()返回的类型为struct sock,因此函数sock_release应该这种调用:
sock_release(sk->sk_socket);
sk为函数netlink_kernel_create()的返回值。
在源代码包中 给出了一个使用 netlink 的示例,它包括一个内核模块 netlink-exam-kern.c 和两个应用程序
netlink-exam-user-recv.c,
netlink-exam-user-send.c。内核模块必须先插入到内核,然后在一个终端上运行用户态接收程序,在另一个终端上运行用户态发送程序,发送程序读取参数指定的文本文件并把它作为
netlink 消息的内容发送给内核模块,内核模块接受该消息保存到内核缓存中,它也通过proc接口出口到 procfs,因此用户也能够通过
/proc/netlink_exam_buffer
看到全部的内容,同时内核也把该消息发送给用户态接收程序,用户态接收程序将把接收到的内容输出到屏幕上。
示例:
内核模块 netlink-exam-kern.c:
#include <linux/config.h>
#include <linux/module.h>
#include <linux/netlink.h>
#include <linux/sched.h>
#include <net/sock.h>
#include <linux/proc_fs.h>
#define BUF_SIZE 16384
staticstruct sock *netlink_exam_sock;
static unsigned char buffer[BUF_SIZE];
static unsigned int buffer_tail =;
staticint exit_flag =;
static DECLARE_COMPLETION(exit_completion);
staticvoid recv_handler(struct sock * sk, int length)
{
wake_up(sk->sk_sleep);
}
staticint process_message_thread(void* data)
{
struct sk_buff * skb = NULL;
struct nlmsghdr * nlhdr = NULL;
int len;
DEFINE_WAIT(wait);
daemonize("mynetlink");
while (exit_flag ==) {
prepare_to_wait(netlink_exam_sock->sk_sleep, &wait, TASK_INTERRUPTIBLE);
schedule();
finish_wait(netlink_exam_sock->sk_sleep, &wait);
while ((skb = skb_dequeue(&netlink_exam_sock->sk_receive_queue))
!= NULL) {
nlhdr = (struct nlmsghdr *)skb->data;
if (nlhdr->nlmsg_len <sizeof(struct nlmsghdr)) {
printk("Corrupt netlink message.\n");
continue;
}
len = nlhdr->nlmsg_len - NLMSG_LENGTH();
if (len + buffer_tail > BUF_SIZE) {
printk("netlink buffer is full.\n");
}
else {
memcpy(buffer + buffer_tail, NLMSG_DATA(nlhdr), len);
buffer_tail += len;
}
nlhdr->nlmsg_pid =;
nlhdr->nlmsg_flags =;
NETLINK_CB(skb).pid =;
NETLINK_CB(skb).dst_pid =;
NETLINK_CB(skb).dst_group =;
netlink_broadcast(netlink_exam_sock, skb, , , GFP_KERNEL);
}
}
complete(&exit_completion);
return;
}
staticint netlink_exam_readproc(char*page, char**start, off_t off,
int count, int*eof, void*data)
{
int len;
if (off >= buffer_tail) {
* eof =;
return;
}
else {
len = count;
if (count > PAGE_SIZE) {
len = PAGE_SIZE;
}
if (len > buffer_tail - off) {
len = buffer_tail - off;
}
memcpy(page, buffer + off, len);
*start = page;
return len;
}
}
staticint __init netlink_exam_init(void)
{
netlink_exam_sock = netlink_kernel_create(NETLINK_GENERIC, , recv_handler, THIS_MODULE);
if (!netlink_exam_sock) {
printk("Fail to create netlink socket.\n");
return;
}
kernel_thread(process_message_thread, NULL, CLONE_KERNEL);
create_proc_read_entry("netlink_exam_buffer", , NULL, netlink_exam_readproc, );
return;
}
staticvoid __exit netlink_exam_exit(void)
{
exit_flag =;
wake_up(netlink_exam_sock->sk_sleep);
wait_for_completion(&exit_completion);
sock_release(netlink_exam_sock->sk_socket);
}
module_init(netlink_exam_init);
module_exit(netlink_exam_exit);
MODULE_LICENSE("GPL");
netlink-exam-user-send.c:
//application sender: netlink-exam-user-send.c
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <linux/netlink.h> #define MAX_MSGSIZE 1024 int main(int argc, char* argv[])
{
FILE * fp;
struct sockaddr_nl saddr, daddr;
struct nlmsghdr *nlhdr = NULL;
struct msghdr msg;
struct iovec iov;
int sd;
char text_line[MAX_MSGSIZE];
int ret =-; if (argc <) {
printf("Usage: %s atextfilename\n", argv[]);
exit();
} if ((fp = fopen(argv[], "r")) == NULL) {
printf("File %s dosen't exist.\n");
exit();
} sd = socket(AF_NETLINK, SOCK_RAW,NETLINK_GENERIC);
memset(&saddr, , sizeof(saddr));
memset(&daddr, , sizeof(daddr)); saddr.nl_family = AF_NETLINK;
saddr.nl_pid = getpid();
saddr.nl_groups =;
bind(sd, (struct sockaddr*)&saddr, sizeof(saddr)); daddr.nl_family = AF_NETLINK;
daddr.nl_pid =;
daddr.nl_groups =; nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(MAX_MSGSIZE)); while (fgets(text_line, MAX_MSGSIZE, fp)) {
memcpy(NLMSG_DATA(nlhdr), text_line, strlen(text_line));
memset(&msg, ,sizeof(struct msghdr)); nlhdr->nlmsg_len = NLMSG_LENGTH(strlen(text_line));
nlhdr->nlmsg_pid = getpid(); /* self pid */
nlhdr->nlmsg_flags =; iov.iov_base = (void*)nlhdr;
iov.iov_len = nlhdr->nlmsg_len;
msg.msg_name = (void*)&daddr;
msg.msg_namelen =sizeof(daddr);
msg.msg_iov =&iov;
msg.msg_iovlen =;
ret = sendmsg(sd, &msg, );
if (ret ==-) {
perror("sendmsg error:");
}
} close(sd);
}
netlink-exam-user-recv.c:
#include <stdio.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <linux/netlink.h>
#define MAX_MSGSIZE 1024
int main(void)
{
struct sockaddr_nl saddr, daddr;
struct nlmsghdr *nlhdr = NULL;
struct msghdr msg;
struct iovec iov;
int sd;
int ret =;
sd = socket(AF_NETLINK, SOCK_RAW,NETLINK_GENERIC);
memset(&saddr, , sizeof(saddr));
memset(&daddr, , sizeof(daddr));
saddr.nl_family = AF_NETLINK;
saddr.nl_pid = getpid();
saddr.nl_groups =;
bind(sd, (struct sockaddr*)&saddr, sizeof(saddr));
nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(MAX_MSGSIZE));
while () {
memset(nlhdr, , NLMSG_SPACE(MAX_MSGSIZE));
iov.iov_base = (void*)nlhdr;
iov.iov_len = NLMSG_SPACE(MAX_MSGSIZE);
msg.msg_name = (void*)&daddr;
msg.msg_namelen =sizeof(daddr);
msg.msg_iov =&iov;
msg.msg_iovlen =;
ret = recvmsg(sd, &msg, );
if (ret ==) {
printf("Exit.\n");
exit();
}
elseif (ret ==-) {
perror("recvmsg:");
exit();
}
printf("%s", NLMSG_DATA(nlhdr));
}
close(sd);
}
本系列文章包括两篇,他们文周详地地介绍了Linux系统下用户空间和内核空间数据交换的九种方式,包括内核启动参数、模块参数和sysfs、
sysctl、系统调用、netlink、procfs、seq_file、debugfs和relayfs,并给出具体的例子帮助读者掌控这些技术的使
用。
本文是该系列文章的第二篇,他介绍了procfs、seq_file、debugfs和relayfs,并结合给出的例子程式周详地说明了他们怎么使用。
1、内核启动参数
Linux 提供了一种通过 bootloader 向其传输启动参数的功能,内核研发者能通过这种方式来向内核传输数据,从而控制内核启动行为。
通常的使用方式是,定义一个分析参数的函数,而后使用内核提供的宏 __setup把他注册到内核中,该宏定义在 linux/init.h 中,因此要使用他必须包含该头文件:
__setup("para_name=", parse_func)
para_name 为参数名,parse_func
为分析参数值的函数,他负责把该参数的值转换成相应的内核变量的值并设置那个内核变量。内核为整数参数值的分析提供了函数 get_option 和
get_options,前者用于分析参数值为一个整数的情况,而后者用于分析参数值为逗号分割的一系列整数的情况,对于参数值为字符串的情况,需要研发
者自定义相应的分析函数。在原始码包中的内核程式kern-boot-params.c
说明了三种情况的使用。该程式列举了参数为一个整数、逗号分割的整数串及字符串三种情况,读者要想测试该程式,需要把该程式拷贝到要使用的内核的源码目
录树的一个目录下,为了避免和内核其他部分混淆,作者建议在内核源码树的根目录下创建一个新目录,如 examples,然后把该程式拷贝到
examples 目录下并重新命名为 setup_example.c,并且为该目录创建一个 Makefile 文件:
obj-y = setup_example.o
Makefile 仅许这一行就足够了,然后需要修改源码树的根目录下的 Makefile文件的一行,把下面行
core-y := usr/
修改为
core-y := usr/ examples/
注意:如果读者创建的新目录和重新命名的文件名和上面不同,需要修改上面所说 Makefile 文件相应的位置。
做完以上工作就能按照内核构建步骤去构建新的内核,在构建好内核并设置好lilo或grub为该内核的启动条目后,就能启动该内核,然后使用lilo或grub的编辑功能为该内核的启动参数行增加如下参数串:
setup_example_int=1234 setup_example_int_array=100,200,300,400 setup_example_string=Thisisatest
当然,该参数串也能直接写入到lilo或grub的设置文件中对应于该新内核的内核命令行参数串中。读者能使用其他参数值来测试该功能。
下面是作者系统上使用上面参数行的输出:
setup_example_int=1234
setup_example_int_array=100,200,300,400
setup_example_int_array includes 4 intergers
setup_example_string=Thisisatest
读者能使用
dmesg | grep setup
来查看该程式的输出。
2、模块参数和sysfs
内核子系统或设备驱动能直接编译到内核,也能编译成模块,如果编译到内核,能使用前一节介绍的方法通过内核启动参数来向他们传递参数,如果编译成模块,则能通过命令行在插入模块时传递参数,或在运行时,通过sysfs来设置或读取模块数据。
Sysfs是个基于内存的文件系统,实际上他基于ramfs,sysfs提供了一种把内核数据结构,他们的属性及属性和数据结构的联系开放给用
户态的方式,他和kobject子系统紧密地结合在一起,因此内核研发者不必直接使用他,而是内核的各个子系统使用他。用户要想使用 sysfs
读取和设置内核参数,仅需装载 sysfs 就能通过文件操作应用来读取和设置内核通过 sysfs 开放给用户的各个参数:
$ mkdir -p /sysfs
$ mount -t sysfs sysfs /sysfs
注意,不要把 sysfs 和 sysctl 混淆,sysctl 是内核的一些控制参数,其目的是方便用户对内核的行为进行控制,而
sysfs 仅仅是把内核的 kobject 对象的层次关系和属性开放给用户查看,因此 sysfs 的绝大部分是只读的,模块作为一个
kobject 也被出口到 sysfs,模块参数则是作为模块属性出口的,内核实现者为模块的使用提供了更灵活的方式,允许用户设置模块参数在
sysfs 的可见性并允许用户在编写模块时设置这些参数在 sysfs 下的访问权限,然后用户就能通过sysfs
来查看和设置模块参数,从而使得用户能在模块运行时控制模块行为。
对于模块而言,声明为 static 的变量都能通过命令行来设置,但要想在 sysfs下可见,必须通过宏 module_param
来显式声明,该宏有三个参数,第一个为参数名,即已定义的变量名,第二个参数则为变量类型,可用的类型有 byte, short, ushort,
int, uint, long, ulong, charp 和 bool 或 invbool,分别对应于 c 类型 char, short,
unsigned short, int, unsigned int, long, unsigned long, char * 和
int,用户也能自定义类型 XXX(如果用户自己定义了 param_get_XXX,param_set_XXX 和
param_check_XXX)。该宏的第三个参数用于指定访问权限,如果为 0,该参数将不出目前 sysfs 文件系统中,允许的访问权限为
S_IRUSR, S_IWUSR,S_IRGRP,S_IWGRP,S_IROTH 和 S_IWOTH
的组合,他们分别对应于用户读,用户写,用户组读,用户组写,其他用户读和其他用户写,因此用文件的访问权限设置是一致的。
在
原始码包
中的内核模块 module-param-exam.c 是个利用模块参数和sysfs来进行用户态和内核态数据交互的例子。该模块有三个参数能通过命令行设置,下面是作者系统上的运行结果示例:
$ insmod ./module-param-exam.ko my_invisible_int=10 my_visible_int=20 mystring="Hello,World"
my_invisible_int = 10
my_visible_int = 20
mystring = ’Hello,World’
$ ls /sys/module/module_param_exam/parameters/
mystring my_visible_int
$ cat /sys/module/module_param_exam/parameters/mystring
Hello,World
$ cat /sys/module/module_param_exam/parameters/my_visible_int
20
$ echo 2000 > /sys/module/module_param_exam/parameters/my_visible_int
$ cat /sys/module/module_param_exam/parameters/my_visible_int
2000
$ echo "abc" > /sys/module/module_param_exam/parameters/mystring
$ cat /sys/module/module_param_exam/parameters/mystring
abc
$ rmmod module_param_exam
my_invisible_int = 10
my_visible_int = 2000
mystring = ’abc’
3、sysctl
Sysctl是一种用户应用来设置和获得运行时内核的设置参数的一种有效方式,通过这种方式,用户应用能在内核运行的所有时刻来改动内核的设置参
数,也能在所有时候获得内核的设置参数,通常,内核的这些设置参数也出目前proc文件系统的/proc/sys目录下,用户应用能直接通过这个目录
下的文件来实现内核设置的读写操作,例如,用户能通过
Cat /proc/sys/net/ipv4/ip_forward
来得知内核IP层是否允许转发IP包,用户能通过
echo 1 > /proc/sys/net/ipv4/ip_forward
把内核 IP 层设置为允许转发 IP 包,即把该机器设置成一个路由器或网关。
一般地,所有的 Linux 发布也提供了一个系统工具 sysctl,他能设置和读取内核的设置参数,不过该工具依赖于 proc 文件系统,为了使用该工具,内核必须支持 proc 文件系统。下面是使用 sysctl 工具来获取和设置内核设置参数的例子:
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
$ sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 1
注意,参数 net.ipv4.ip_forward 实际被转换到对应的 proc
文件/proc/sys/net/ipv4/ip_forward,选项 -w 表示设置该内核设置参数,没有选项表示读内核设置参数,用户能使用
sysctl -a 来读取所有的内核设置参数,对应更多的 sysctl 工具的信息,请参考手册页 sysctl(8)。
不过 proc 文件系统对 sysctl 不是必须的,在没有 proc 文件系统的情况下,仍然能,这时需要使用内核提供的系统调用 sysctl 来实现对内核设置参数的设置和读取。
在
原始码包
中
给出了一个实际例子程式,他说明了怎么在内核和用户态使用sysctl。头文件 sysctl-exam.h 定义了 sysctl 条目
ID,用户态应用和内核模块需要这些 ID 来操作和注册 sysctl 条目。内核模块在文件 sysctl-exam-kern.c
中实现,在该内核模块中,每一个 sysctl 条目对应一个 struct ctl_table 结构,该结构定义了要注册的 sysctl 条目的
ID(字段 ctl_name),在 proc
下的名称(字段procname),对应的内核变量(字段data,注意该该字段的赋值必须是指针),条目允许的最大长度(字段maxlen,他主要用于
字符串内核变量,以便在对该条目设置时,对超过该最大长度的字符串截掉后面超长的部分),条目在proc文件系统下的访问权限(字段mode),在通过
proc设置时的处理函数(字段proc_handler,对于整型内核变量,应当设置为&proc_dointvec,而对于字符串内核变量,
则设置为 &proc_dostring),字符串处理策略(字段strategy,一般这是为&sysctl_string)。
Sysctl 条目能是目录,此时 mode 字段应当设置为 0555,否则通过 sysctl 系统调用将无法访问他下面的 sysctl
条目,child 则指向该目录条目下面的所有条目,对于在同一目录下的多个条目,不必一一注册,用户能把他们组织成一个 struct
ctl_table 类型的数组,然后一次注册就能,但此时必须把数组的最后一个结构设置为NULL,即
{
.ctl_name = 0
}
注册sysctl条目使用函数register_sysctl_table(struct ctl_table *,
int),第一个参数为定义的struct
ctl_table结构的sysctl条目或条目数组指针,第二个参数为插入到sysctl条目表中的位置,如果插入到末尾,应当为0,如果插入到开头,
则为非0。内核把所有的sysctl条目都组织成sysctl表。
当模块卸载时,需要使用函数unregister_sysctl_table(struct ctl_table_header
*)解注册通过函数register_sysctl_table注册的sysctl条目,函数register_sysctl_table在调用成功时返
回结构struct ctl_table_header,他就是sysctl表的表头,解注册函数使用他来卸载相应的sysctl条目。
用户态应用sysctl-exam-user.c通过sysctl系统调用来查看和设置前面内核模块注册的sysctl条目(当然如果用户的系统内核已
支持proc文件系统,能直接使用文件操作应用如cat, echo等直接查看和设置这些sysctl条目)。
下面是作者运行该模块和应用的输出结果示例:
$ insmod ./sysctl-exam-kern.ko
$ cat /proc/sys/mysysctl/myint
0
$ cat /proc/sys/mysysctl/mystring
$ ./sysctl-exam-user
mysysctl.myint = 0
mysysctl.mystring = ""
$ ./sysctl-exam-user 100 "Hello, World"
old value: mysysctl.myint = 0
new value: mysysctl.myint = 100
old vale: mysysctl.mystring = ""
new value: mysysctl.mystring = "Hello, World"
$ cat /proc/sys/mysysctl/myint
100
$ cat /proc/sys/mysysctl/mystring
Hello, World
$
4、系统调用
系统调用是内核提供给应用程式的接口,应用对底层硬件的操作大部分都是通过调用系统调用来完成的,例如得到和设置系统时间,就需要分别调用
gettimeofday 和 settimeofday 来实现。事实上,所有的系统调用都涉及到内核和应用之间的数据交换,如文件系统操作函数
read 和 write,设置和读取网络协议栈的 setsockopt 和
getsockopt。本节并不是讲解怎么增加新的系统调用,而是讲解怎么利用现有系统调用来实现用户的数据传输需求。
一般地,用户能建立一个伪设备来作为应用和内核之间进行数据交换的渠道,最通常的做法是使用伪字符设备,具体实现方法是:
1.定义对字符设备进行操作的必要函数并设置结构 struct file_operations
结构 struct file_operations 非常大,对于一般的数据交换需求,只定义 open, read, write,
ioctl, mmap 和 release 函数就足够了,他们实际上对应于用户态的文件系统操作函数 open, read, write,
ioctl, mmap 和 close。这些函数的原型示例如下:
ssize_t exam_read (struct file * file, char __user * buf, size_t count, loff_t * ppos)
{
…
}
ssize_t exam_write(struct file * file, const char __user * buf, size_t count, loff_t * ppos)
{
…
}
int exam_ioctl(struct inode * inode, struct file * file, unsigned int cmd, unsigned long argv)
{
…
}
int exam_mmap(struct file *, struct vm_area_struct *)
{
…
}
int exam_open(struct inode * inode, struct file * file)
{
…
}
int exam_release(struct inode * inode, struct file * file)
{
…
}
在定义了这些操作函数后需要定义并设置结构struct file_operations
struct file_operations exam_file_ops = {
.owner = THIS_MODULE,
.read = exam_read,
.write = exam_write,
.ioctl = exam_ioctl,
.mmap = exam_mmap,
.open = exam_open,
.release = exam_release,
};
2. 注册定义的伪字符设备并把他和上面的 struct file_operations 关联起来:
int exam_char_dev_major;
exam_char_dev_major = register_chrdev(0, "exam_char_dev", &exam_file_ops);
注意,函数 register_chrdev 的第一个参数如果为
0,表示由内核来确定该注册伪字符设备的主设备号,这是该函数的返回为实际分配的主设备号,如果返回小于
0,表示注册失败。因此,用户在使用该函数时必须判断返回值以便处理失败情况。为了使用该函数必须包含头文件 linux/fs.h。
在原始码包中给出了一个使用这种方式实现用户态和内核态数据交换的典型例子,他包含了三个文件:
头文件 syscall-exam.h 定义了 ioctl 命令,.c 文件
syscall-exam-user.c为用户态应用,他通过文件系统操作函数 mmap 和 ioctl 来和内核态模块交换数据,.c 文件
syscall-exam-kern.c 为内核模块,他实现了一个伪字符设备,以便和用户态应用进行数据交换。为了正确运行应用程式
syscall-exam-user,需要在插入模块 syscall-exam-kern
后创建该实现的伪字符设备,用户能使用下面命令来正确创建设备:
$ mknod /dev/mychrdev c `dmesg | grep "char device mychrdev" | sed ’s/.*major is //g’` 0
然后用户能通过 cat 来读写 /dev/mychrdev,应用程式 syscall-exam-user则使用 mmap 来读数据并使用 ioctl 来得到该字符设备的信息及裁减数据内容,他只是示例怎么使用现有的系统调用来实现用户需要的数据交互操作。
下面是作者运行该模块的结果示例:
$ insmod ./syscall-exam-kern.ko
char device mychrdev is registered, major is 254
$ mknod /dev/mychrdev c `dmesg | grep "char device mychrdev" | sed ’s/.*major is //g’` 0
$ cat /dev/mychrdev
$ echo "abcdefghijklmnopqrstuvwxyz" > /dev/mychrdev
$ cat /dev/mychrdev
abcdefghijklmnopqrstuvwxyz
$ ./syscall-exam-user
User process: syscall-exam-us(1433)
Available space: 65509 bytes
Data len: 27 bytes
Offset in physical: cc0 bytes
mychrdev content by mmap:
abcdefghijklmnopqrstuvwxyz
$ cat /dev/mychrdev
abcde
$
5、netlink
Netlink 是一种特别的 socket,他是 Linux 所特有的,类似于 BSD 中的AF_ROUTE
但又远比他的功能强大,目前在最新的 Linux 内核(2.6.14)中使用netlink 进行应用和内核通信的应用非常多,包括:路由
daemon(NETLINK_ROUTE),1-wire 子系统(NETLINK_W1),用户态 socket
协议(NETLINK_USERSOCK),防火墙(NETLINK_FIREWALL),socket
监视(NETLINK_INET_DIAG),netfilter 日志(NETLINK_NFLOG),ipsec
安全策略(NETLINK_XFRM),SELinux 事件通知(NETLINK_SELINUX),iSCSI
子系统(NETLINK_ISCSI),进程审计(NETLINK_AUDIT),转发信息表查询(NETLINK_FIB_LOOKUP),
netlink connector(NETLINK_CONNECTOR),netfilter
子系统(NETLINK_NETFILTER),IPv6 防火墙(NETLINK_IP6_FW),DECnet
路由信息(NETLINK_DNRTMSG),内核事件向用户态通知(NETLINK_KOBJECT_UEVENT),通用
netlink(NETLINK_GENERIC)。
Netlink 是一种在内核和用户应用间进行双向数据传输的非常好的方式,用户态应用使用标准的 socket API 就能使用 netlink 提供的强大功能,内核态需要使用专门的内核 API 来使用 netlink。
Netlink 相对于系统调用,ioctl 及 /proc 文件系统而言具有以下好处:
1,为了使用 netlink,用户仅需要在 include/linux/netlink.h 中增加一个新类型的 netlink
协议定义即可, 如
#define NETLINK_MYTEST 17
然后,内核和用户态应用就能即时通过 socket API 使用该 netlink
协议类型进行数据交换。但系统调用需要增加新的系统调用,ioctl 则需要增加设备或文件, 那需要不少代码,proc 文件系统则需要在
/proc 下添加新的文件或目录,那将使本来就混乱的 /proc 更加混乱。
2.
netlink是一种异步通信机制,在内核和用户态应用之间传递的消息保存在socket缓存队列中,发送消息只是把消息保存在接收者的socket的接
收队列,而不必等待接收者收到消息,但系统调用和 ioctl 则是同步通信机制,如果传递的数据太长,将影响调度粒度。
3.使用 netlink 的内核部分能采用模块的方式实现,使用 netlink 的应用部分和内核部分没有编译时依赖,但系统调用就有依赖,而且新的系统调用的实现必须静态地连接到内核中,他无法在模块中实现,使用新系统调用的应用在编译时需要依赖内核。
4.netlink 支持多播,内核模块或应用能把消息多播给一个netlink组,属于该neilink
组的所有内核模块或应用都能接收到该消息,内核事件向用户态的通知机制就使用了这一特性,所有对内核事件感兴趣的应用都能收到该子系统发送的内核事件,在
后面的文章中将介绍这一机制的使用。
5.内核能使用 netlink 首先发起会话,但系统调用和 ioctl 只能由用户应用发起调用。
6.netlink 使用标准的 socket API,因此非常容易使用,但系统调用和 ioctl则需要专门的培训才能使用。
用户态使用 netlink
用户态应用使用标准的socket APIs, socket(), bind(), sendmsg(), recvmsg() 和
close() 就能非常容易地使用 netlink socket,查询手册页能了解这些函数的使用细节,本文只是讲解使用 netlink
的用户应该怎么使用这些函数。注意,使用 netlink 的应用必须包含头文件 linux/netlink.h。当然 socket
需要的头文件也必不可少,sys/socket.h。
为了创建一个 netlink socket,用户需要使用如下参数调用 socket():
socket(AF_NETLINK, SOCK_RAW, netlink_type)
第一个参数必须是 AF_NETLINK 或 PF_NETLINK,在 Linux
中,他们俩实际为一个东西,他表示要使用netlink,第二个参数必须是SOCK_RAW或SOCK_DGRAM,
第三个参数指定netlink协议类型,如前面讲的用户自定义协议类型NETLINK_MYTEST,
NETLINK_GENERIC是个通用的协议类型,他是专门为用户使用的,因此,用户能直接使用他,而不必再添加新的协议类型。内核预定义的协议类
型有:
#define NETLINK_ROUTE 0 /* Routing/device hook */
#define NETLINK_W1 1 /* 1-wire subsystem */
#define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols */
#define NETLINK_FIREWALL 3 /* Firewalling hook */
#define NETLINK_INET_DIAG 4 /* INET socket monitoring */
#define NETLINK_NFLOG 5 /* netfilter/iptables ULOG */
#define NETLINK_XFRM 6 /* ipsec */
#define NETLINK_SELINUX 7 /* SELinux event notifications */
#define NETLINK_ISCSI 8 /* Open-iSCSI */
#define NETLINK_AUDIT 9 /* auditing */
#define NETLINK_FIB_LOOKUP 10
#define NETLINK_CONNECTOR 11
#define NETLINK_NETFILTER 12 /* netfilter subsystem */
#define NETLINK_IP6_FW 13
#define NETLINK_DNRTMSG 14 /* DECnet routing messages */
#define NETLINK_KOBJECT_UEVENT 15 /* Kernel messages to userspace */
#define NETLINK_GENERIC 16
对于每一个netlink协议类型,能有多达 32多播组,每一个多播组用一个位表示,netlink 的多播特性使得发送消息给同一个组仅需要一次系统调用,因而对于需要多拨消息的应用而言,大大地降低了系统调用的次数。
函数 bind() 用于把一个打开的 netlink socket 和 netlink 源 socket 地址绑定在一起。netlink socket 的地址结构如下:
struct sockaddr_nl
{
sa_family_t nl_family;
unsigned short nl_pad;
__u32 nl_pid;
__u32 nl_groups;
};
字段 nl_family 必须设置为 AF_NETLINK 或着 PF_NETLINK,字段 nl_pad
当前没有使用,因此要总是设置为 0,字段 nl_pid 为接收或发送消息的进程的 ID,如果希望内核处理消息或多播消息,就把该字段设置为
0,否则设置为处理消息的进程 ID。字段 nl_groups 用于指定多播组,bind 函数用于把调用进程加入到该字段指定的多播组,如果设置为
0,表示调用者不加入所有多播组。
传递给 bind 函数的地址的 nl_pid 字段应当设置为本进程的进程 ID,这相当于 netlink socket 的本地地址。不过,对于一个进程的多个线程使用 netlink socket 的情况,字段 nl_pid 则能设置为其他的值,如:
pthread_self()
因此字段 nl_pid 实际上未必是进程 ID,他只是用于区分不同的接收者或发送者的一个标识,用户能根据自己需要设置该字段。函数 bind 的调用方式如下:
bind(fd, (struct sockaddr*)&nladdr, sizeof(struct sockaddr_nl));
fd为前面的 socket 调用返回的文件描述符,参数 nladdr 为 struct sockaddr_nl 类型的地址。
为了发送一个 netlink 消息给内核或其他用户态应用,需要填充目标 netlink socket 地址
,此时,字段 nl_pid 和 nl_groups 分别表示接收消息者的进程 ID 和多播组。如果字段 nl_pid 设置为 0,表示消息接收者为内核或多播组,如果 nl_groups为 0,表示该消息为单播消息,否则表示多播消息。
使用函数 sendmsg 发送 netlink 消息时还需要引用结构 struct msghdr、struct nlmsghdr 和 struct iovec,结构 struct msghdr 需如下设置:
struct msghdr msg;
memset(&msg, 0, sizeof(msg));
msg.msg_name = (void *)&(nladdr);
msg.msg_namelen = sizeof(nladdr);
其中 nladdr 为消息接收者的 netlink 地址。
struct nlmsghdr 为 netlink socket 自己的消息头,这用于多路复用和多路分解 netlink
定义的所有协议类型及其他一些控制,netlink
的内核实现将利用这个消息头来多路复用和多路分解已其他的一些控制,因此他也被称为netlink 控制块。因此,应用在发送 netlink
消息时必须提供该消息头。
struct nlmsghdr
{
__u32 nlmsg_len; /* Length of message */
__u16 nlmsg_type; /* Message type*/
__u16 nlmsg_flags; /* Additional flags */
__u32 nlmsg_seq; /* Sequence number */
__u32 nlmsg_pid; /* Sending process PID */
};
字段 nlmsg_len 指定消息的总长度,包括紧跟该结构的数据部分长度及该结构的大小,字段 nlmsg_type
用于应用内部定义消息的类型,他对 netlink 内核实现是透明的,因此大部分情况下设置为 0,字段 nlmsg_flags
用于设置消息标志,可用的标志包括:
/* Flags values */
#define NLM_F_REQUEST 1 /* It is request message. */
#define NLM_F_MULTI 2 /* Multipart message, terminated by NLMSG_DONE */
#define NLM_F_ACK 4 /* Reply with ack, with zero or error code */
#define NLM_F_ECHO 8 /* Echo this request */
/* Modifiers to GET request */
#define NLM_F_ROOT 0x100 /* specify tree root */
#define NLM_F_MATCH 0x200 /* return all matching */
#define NLM_F_ATOMIC 0x400 /* atomic GET */
#define NLM_F_DUMP (NLM_F_ROOT|NLM_F_MATCH)
/* Modifiers to NEW request */
#define NLM_F_REPLACE 0x100 /* Override existing */
#define NLM_F_EXCL 0x200 /* Do not touch, if it exists */
#define NLM_F_CREATE 0x400 /* Create, if it does not exist */
#define NLM_F_APPEND 0x800 /* Add to end of list */
标志NLM_F_REQUEST用于表示消息是个请求,所有应用首先发起的消息都应设置该标志。
标志NLM_F_MULTI 用于指示该消息是个多部分消息的一部分,后续的消息能通过宏NLMSG_NEXT来获得。
宏NLM_F_ACK表示该消息是前一个请求消息的响应,顺序号和进程ID能把请求和响应关联起来。
标志NLM_F_ECHO表示该消息是相关的一个包的回传。
标志NLM_F_ROOT 被许多 netlink
协议的各种数据获取操作使用,该标志指示被请求的数据表应当整体返回用户应用,而不是个条目一个条目地返回。有该标志的请求通常导致响应消息设置
NLM_F_MULTI标志。注意,当设置了该标志时,请求是协议特定的,因此,需要在字段 nlmsg_type 中指定协议类型。
标志 NLM_F_MATCH 表示该协议特定的请求只需要一个数据子集,数据子集由指定的协议特定的过滤器来匹配。
标志 NLM_F_ATOMIC 指示请求返回的数据应当原子地收集,这预防数据在获取期间被修改。
标志 NLM_F_DUMP 未实现。
标志 NLM_F_REPLACE 用于取代在数据表中的现有条目。
标志 NLM_F_EXCL_ 用于和 CREATE 和 APPEND 配合使用,如果条目已存在,将失败。
标志 NLM_F_CREATE 指示应当在指定的表中创建一个条目。
标志 NLM_F_APPEND 指示在表末尾添加新的条目。
内核需要读取和修改这些标志,对于一般的使用,用户把他设置为 0 就能,只是一些高级应用(如 netfilter 和路由 daemon
需要他进行一些复杂的操作),字段 nlmsg_seq 和 nlmsg_pid 用于应用追踪消息,前者表示顺序号,后者为消息来源进程
ID。下面是个示例:
#define MAX_MSGSIZE 1024
char buffer[] = "An example message";
struct nlmsghdr nlhdr;
nlhdr = (struct nlmsghdr *)malloc(NLMSG_SPACE(MAX_MSGSIZE));
strcpy(NLMSG_DATA(nlhdr),buffer);
nlhdr->nlmsg_len = NLMSG_LENGTH(strlen(buffer));
nlhdr->nlmsg_pid = getpid(); /* self pid */
nlhdr->nlmsg_flags = 0;
结构 struct iovec 用于把多个消息通过一次系统调用来发送,下面是该结构使用示例:
struct iovec iov;
iov.iov_base = (void *)nlhdr;
iov.iov_len = nlh->nlmsg_len;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
在完成以上步骤后,消息就能通过下面语句直接发送:
sendmsg(fd, &msg, 0);
应用接收消息时需要首先分配一个足够大的缓存来保存消息头及消息的数据部分,然后填充消息头,添完后就能直接调用函数 recvmsg() 来接收。
#define MAX_NL_MSG_LEN 1024
struct sockaddr_nl nladdr;
struct msghdr msg;
struct iovec iov;
struct nlmsghdr * nlhdr;
nlhdr = (struct nlmsghdr *)malloc(MAX_NL_MSG_LEN);
iov.iov_base = (void *)nlhdr;
iov.iov_len = MAX_NL_MSG_LEN;
msg.msg_name = (void *)&(nladdr);
msg.msg_namelen = sizeof(nladdr);
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
recvmsg(fd, &msg, 0);
注意:fd为socket调用打开的netlink socket描述符。
在消息接收后,nlhdr指向接收到的消息的消息头,nladdr保存了接收到的消息的目标地址,宏NLMSG_DATA(nlhdr)返回指向消息的数据部分的指针。
在linux/netlink.h中定义了一些方便对消息进行处理的宏,这些宏包括:
#define NLMSG_ALIGNTO 4
#define NLMSG_ALIGN(len) ( ((len)+NLMSG_ALIGNTO-1) & ~(NLMSG_ALIGNTO-1) )
宏NLMSG_ALIGN(len)用于得到不小于len且字节对齐的最小数值。
#define NLMSG_LENGTH(len) ((len)+NLMSG_ALIGN(sizeof(struct nlmsghdr)))
宏NLMSG_LENGTH(len)用于计算数据部分长度为len时实际的消息长度。他一般用于分配消息缓存。
#define NLMSG_SPACE(len) NLMSG_ALIGN(NLMSG_LENGTH(len))
宏NLMSG_SPACE(len)返回不小于NLMSG_LENGTH(len)且字节对齐的最小数值,他也用于分配消息缓存。
#define NLMSG_DATA(nlh) ((void*)(((char*)nlh) + NLMSG_LENGTH(0)))
宏NLMSG_DATA(nlh)用于取得消息的数据部分的首地址,设置和读取消息数据部分时需要使用该宏。
#define NLMSG_NEXT(nlh,len) ((len) -= NLMSG_ALIGN((nlh)->nlmsg_len), \
(struct nlmsghdr*)(((char*)(nlh)) + NLMSG_ALIGN((nlh)->nlmsg_len)))
宏NLMSG_NEXT(nlh,len)用于得到下一个消息的首地址,同时len也减少为剩余消息的总长度,该宏一般在一个消息被分成几个部分发送或接收时使用。
#define NLMSG_OK(nlh,len) ((len) >= (int)sizeof(struct nlmsghdr) && \
(nlh)->nlmsg_len >= sizeof(struct nlmsghdr) && \
(nlh)->nlmsg_len
宏NLMSG_OK(nlh,len)用于判断消息是否有len这么长。
#define NLMSG_PAYLOAD(nlh,len) ((nlh)->nlmsg_len - NLMSG_SPACE((len)))
宏NLMSG_PAYLOAD(nlh,len)用于返回payload的长度。
函数close用于关闭打开的netlink socket。
netlink内核API
netlink的内核实目前.c文件net/core/af_netlink.c中,内核模块要想使用netlink,也必须包含头文件
linux/netlink.h。内核使用netlink需要专门的API,这完全不同于用户态应用对netlink的使用。如果用户需要增加新的
netlink协议类型,必须通过修改linux/netlink.h来实现,当然,目前的netlink实现已包含了一个通用的协议类型
NETLINK_GENERIC以方便用户使用,用户能直接使用他而不必增加新的协议类型。前面讲到,为了增加新的netlink协议类型,用户仅需增
加如下定义到linux/netlink.h就能:
#define NETLINK_MYTEST 17
只要增加这个定义之后,用户就能在内核的所有地方引用该协议。
在内核中,为了创建一个netlink socket用户需要调用如下函数:
struct sock *
netlink_kernel_create(int unit, void (*input)(struct sock *sk, int len));
参数unit表示netlink协议类型,如NETLINK_MYTEST,参数input则为内核模块定义的netlink消息处理函数,当有消
息到达这个netlink
socket时,该input函数指针就会被引用。函数指针input的参数sk实际上就是函数netlink_kernel_create返回的
struct sock指针,sock实际是socket的一个内核表示数据结构,用户态应用创建的socket在内核中也会有一个struct
sock结构来表示。下面是个input函数的示例:
void input (struct sock *sk, int len)
{
struct sk_buff *skb;
struct nlmsghdr *nlh = NULL;
u8 *data = NULL;
while ((skb = skb_dequeue(&sk->receive_queue))
!= NULL) {
/* process netlink message pointed by skb->data */
nlh = (struct nlmsghdr *)skb->data;
data = NLMSG_DATA(nlh);
/* process netlink message with header pointed by
* nlh and data pointed by data
*/
}
}
函数input()会在发送进程执行sendmsg()时被调用,这样处理消息比较及时,不过,如果消息特别长时,这样处理将增加系统调用
sendmsg()的执行时间,对于这种情况,能定义一个内核线程专门负责消息接收,而函数input的工作只是唤醒该内核线程,这样sendmsg将
非常快返回。
函数skb = skb_dequeue(&sk->receive_queue)用于取得socket sk的接收队列上的消息,返回为一个struct sk_buff的结构,skb->data指向实际的netlink消息。
函数skb_recv_datagram(nl_sk)也用于在netlink socket
nl_sk上接收消息,和skb_dequeue的不同指出是,如果socket的接收队列上没有消息,他将导致调用进程睡眠在等待队列nl_sk-
>sk_sleep,因此他必须在进程上下文使用,刚才讲的内核线程就能采用这种方式来接收消息。
下面的函数input就是这种使用的示例:
void input (struct sock *sk, int len)
{
wake_up_interruptible(sk->sk_sleep);
}
当内核中发送netlink消息时,也需要设置目标地址和源地址,而且内核中消息是通过struct sk_buff来管理的,
linux/netlink.h中定义了一个宏:
#define NETLINK_CB(skb) (*(struct netlink_skb_parms*)&((skb)->cb))
来方便消息的地址设置。下面是个消息地址设置的例子:
NETLINK_CB(skb).pid = 0;
NETLINK_CB(skb).dst_pid = 0;
NETLINK_CB(skb).dst_group = 1;
字段pid表示消息发送者进程ID,也即源地址,对于内核,他为 0, dst_pid 表示消息接收者进程
ID,也即目标地址,如果目标为组或内核,他设置为 0,否则 dst_group 表示目标组地址,如果他目标为某一进程或内核,dst_group
应当设置为 0。
在内核中,模块调用函数 netlink_unicast 来发送单播消息:
int netlink_unicast(struct sock *sk, struct sk_buff *skb, u32 pid, int nonblock);
参数sk为函数netlink_kernel_create()返回的socket,参数skb存放消息,他的data字段指向要发送的
netlink消息结构,而skb的控制块保存了消息的地址信息,前面的宏NETLINK_CB(skb)就用于方便设置该控制块,
参数pid为接收消息进程的pid,参数nonblock表示该函数是否为非阻塞,如果为1,该函数将在没有接收缓存可利用时即时返回,而如果为0,该函
数在没有接收缓存可利用时睡眠。
内核模块或子系统也能使用函数netlink_broadcast来发送广播消息:
void netlink_broadcast(struct sock *sk, struct sk_buff *skb, u32 pid, u32 group, int allocation);
前面的三个参数和netlink_unicast相同,参数group为接收消息的多播组,该参数的每一个代表一个多播组,因此如果发送给多个多播
组,就把该参数设置为多个多播组组ID的位或。参数allocation为内核内存分配类型,一般地为GFP_ATOMIC或GFP_KERNEL,
GFP_ATOMIC用于原子的上下文(即不能睡眠),而GFP_KERNEL用于非原子上下文。
在内核中使用函数sock_release来释放函数netlink_kernel_create()创建的netlink socket:
void sock_release(struct socket * sock);
注意函数netlink_kernel_create()返回的类型为struct sock,因此函数sock_release应该这种调用:
sock_release(sk->sk_socket);
sk为函数netlink_kernel_create()的返回值。
在
原始码包
中
给出了一个使用 netlink 的示例,他包括一个内核模块 netlink-exam-kern.c 和两个应用程式
netlink-exam-user-recv.c,
netlink-exam-user-send.c。内核模块必须先插入到内核,然后在一个终端上运行用户态接收程式,在另一个终端上运行用户态发送程
序,发送程式读取参数指定的文本文件并把他作为 netlink
消息的内容发送给内核模块,内核模块接受该消息保存到内核缓存中,他也通过proc接口出口到 procfs,因此用户也能够通过
/proc/netlink_exam_buffer
看到全部的内容,同时内核也把该消息发送给用户态接收程式,用户态接收程式将把接收到的内容输出到屏幕上。
6、procfs
procfs是比较老的一种用户态和内核态的数据交换方式,内核的非常多数据都是通过这种方式出口给用户的,内核的非常多参数也是通过这种方式来让用户
方便设置的。除了sysctl出口到/proc下的参数,procfs提供的大部分内核参数是只读的。实际上,非常多应用严重地依赖于procfs,因此他
几乎是必不可少的组件。前面部分的几个例子实际上已使用他来出口内核数据,不过并没有讲解怎么使用,本节将讲解怎么使用procfs。
Procfs提供了如下API:
struct proc_dir_entry *create_proc_entry(const char *name, mode_t mode,
struct proc_dir_entry *parent)
该函数用于创建一个正常的proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参数
parent指定建立的proc条目所在的目录。如果要在/proc下建立proc条目,parent应当为NULL。否则他应当为proc_mkdir
返回的struct proc_dir_entry结构的指针。
extern void remove_proc_entry(const char *name, struct proc_dir_entry *parent)
该函数用于删除上面函数创建的proc条目,参数name给出要删除的proc条目的名称,参数parent指定建立的proc条目所在的目录。
struct proc_dir_entry *proc_mkdir(const char * name, struct proc_dir_entry *parent)
该函数用于创建一个proc目录,参数name指定要创建的proc目录的名称,参数parent为该proc目录所在的目录。
extern struct proc_dir_entry *proc_mkdir_mode(const char *name, mode_t mode,
struct proc_dir_entry *parent);
struct proc_dir_entry *proc_symlink(const char * name,
struct proc_dir_entry * parent, const char * dest)
该函数用于建立一个proc条目的符号链接,参数name给出要建立的符号链接proc条目的名称,参数parent指定符号连接所在的目录,参数dest指定链接到的proc条目名称。
struct proc_dir_entry *create_proc_read_entry(const char *name,
mode_t mode, struct proc_dir_entry *base,
read_proc_t *read_proc, void * data)
该函数用于建立一个规则的只读proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参
数base指定建立的proc条目所在的目录,参数read_proc给出读去该proc条目的操作函数,参数data为该proc条目的专用数据,他将
保存在该proc条目对应的struct file结构的private_data字段中。
struct proc_dir_entry *create_proc_info_entry(const char *name,
mode_t mode, struct proc_dir_entry *base, get_info_t *get_info)
该函数用于创建一个info型的proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,
参数base指定建立的proc条目所在的目录,参数get_info指定该proc条目的get_info操作函数。实际上get_info等同于
read_proc,如果proc条目没有定义个read_proc,对该proc条目的read操作将使用get_info取代,因此他在功能上非常类
似于函数create_proc_read_entry。
struct proc_dir_entry *proc_net_create(const char *name,
mode_t mode, get_info_t *get_info)
该函数用于在/proc/net目录下创建一个proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参数get_info指定该proc条目的get_info操作函数。
struct proc_dir_entry *proc_net_fops_create(const char *name,
mode_t mode, struct file_operations *fops)
该函数也用于在/proc/net下创建proc条目,不过他也同时指定了对该proc条目的文件操作函数。
void proc_net_remove(const char *name)
该函数用于删除前面两个函数在/proc/net目录下创建的proc条目。参数name指定要删除的proc名称。
除了这些函数,值得一提的是结构struct
proc_dir_entry,为了创建一了可写的proc条目并指定该proc条目的写操作函数,必须设置上面的这些创建proc条目的函数返回的指针
指向的struct proc_dir_entry结构的write_proc字段,并指定该proc条目的访问权限有写权限。
为了使用这些接口函数及结构struct proc_dir_entry,用户必须在模块中包含头文件linux/proc_fs.h。
在原始码包中给出了procfs示例程式procfs_exam.c,他定义了三个proc文件条目和一个proc目录条目,读者在插入该模块后应当看到如下结构:
$ ls /proc/myproctest
aint astring bigprocfile
$
读者能通过cat和echo等文件操作函数来查看和设置这些proc文件。特别需要指出,bigprocfile是个大文件(超过一个内存
页),对于这种大文件,procfs有一些限制,因为他提供的缓存,只有一个页,因此必须特别小心,并对超过页的部分做特别的考虑,处理起来比较复杂并且
非常容易出错,所有procfs并不适合于大数据量的输入输出,后面一节seq_file就是因为这一缺陷而设计的,当然seq_file依赖于
procfs的一些基础功能。
7、seq_file
一般地,内核通过在procfs文件系统下建立文件来向用户空间提供输出信息,用户空间能通过所有文本阅读应用查看该文件信息,不过procfs
有一个缺陷,如果输出内容大于1个内存页,需要多次读,因此处理起来非常难,另外,如果输出太大,速度比较慢,有时会出现一些意想不到的情况,
Alexander
Viro实现了一套新的功能,使得内核输出大文件信息更容易,该功能出目前2.4.15(包括2.4.15)以后的所有2.4内核及2.6内核中,尤其
是在2.6内核中,已大量地使用了该功能。
要想使用seq_file功能,研发者需要包含头文件linux/seq_file.h,并定义和设置一个seq_operations结构(类似于file_operations结构):
struct seq_operations {
void * (*start) (struct seq_file *m, loff_t *pos);
void (*stop) (struct seq_file *m, void *v);
void * (*next) (struct seq_file *m, void *v, loff_t *pos);
int (*show) (struct seq_file *m, void *v);
};
start函数用于指定seq_file文件的读开始位置,返回实际读开始位置,如果指定的位置超过文件末尾,应当返回NULL,start函数可
以有一个特别的返回SEQ_START_TOKEN,他用于让show函数输出文件头,但这只能在pos为0时使用,next函数用于把seq_file
文件的当前读位置移动到下一个读位置,返回实际的下一个读位置,如果已到达文件末尾,返回NULL,stop函数用于在读完seq_file文件后调
用,他类似于文件操作close,用于做一些必要的清理,如释放内存等,show函数用于格式化输出,如果成功返回0,否则返回出错码。
Seq_file也定义了一些辅助函数用于格式化输出:
int seq_putc(struct seq_file *m, char c);
函数seq_putc用于把一个字符输出到seq_file文件。
int seq_puts(struct seq_file *m, const char *s);
函数seq_puts则用于把一个字符串输出到seq_file文件。
int seq_escape(struct seq_file *, const char *, const char *);
函数seq_escape类似于seq_puts,只是,他将把第一个字符串参数中出现的包含在第二个字符串参数中的字符按照八进制形式输出,也即对这些字符进行转义处理。
int seq_printf(struct seq_file *, const char *, ...)
__attribute__ ((format (printf,2,3)));
函数seq_printf是最常用的输出函数,他用于把给定参数按照给定的格式输出到seq_file文件。
int seq_path(struct seq_file *, struct vfsmount *, struct dentry *, char *);
函数seq_path则用于输出文件名,字符串参数提供需要转义的文件名字符,他主要供文件系统使用。
在定义了结构struct seq_operations之后,用户还需要把打开seq_file文件的open函数,以便该结构和对应于seq_file文件的struct file结构关联起来,例如,struct seq_operations定义为:
struct seq_operations exam_seq_ops = {
.start = exam_seq_start,
.stop = exam_seq_stop,
.next = exam_seq_next,
.show = exam_seq_show
};
那么,open函数应该如下定义:
static int exam_seq_open(struct inode *inode, struct file *file)
{
return seq_open(file, &exam_seq_ops);
};
注意,函数seq_open是seq_file提供的函数,他用于把struct seq_operations结构和seq_file文件关联起来。
最后,用户需要如下设置struct file_operations结构:
struct file_operations exam_seq_file_ops = {
.owner = THIS_MODULE,
.open = exm_seq_open,
.read = seq_read,
.llseek = seq_lseek,
.release = seq_release
};
注意,用户仅需要设置open函数,其他的都是seq_file提供的函数。
然后,用户创建一个/proc文件并把他的文件操作设置为exam_seq_file_ops即可:
struct proc_dir_entry *entry;
entry = create_proc_entry("exam_seq_file", 0, NULL);
if (entry)
entry->proc_fops = &exam_seq_file_ops;
对于简单的输出,seq_file用户并不必定义和设置这么多函数和结构,他仅需定义一个show函数,然后使用single_open来定义open函数就能,以下是使用这种简单形式的一般步骤:
1.定义一个show函数
int exam_show(struct seq_file *p, void *v)
{
…
}
2. 定义open函数
int exam_single_open(struct inode *inode, struct file *file)
{
return(single_open(file, exam_show, NULL));
}
注意要使用single_open而不是seq_open。
3. 定义struct file_operations结构
struct file_operations exam_single_seq_file_operations = {
.open = exam_single_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
注意,如果open函数使用了single_open,release函数必须为single_release,而不是seq_release。
在原始码包中给出了一个使用seq_file的具体例子seqfile_exam.c,他使用seq_file提供了一个查看当前系统运行的所有进程的
/proc接口,在编译并插入该模块后,用户通过命令"cat /proc/ exam_esq_file"能查看系统的所有进程。
回页首
三、debugfs
内核研发者经常需要向用户空间应用输出一些调试信息,在稳定的系统中可能根本不必这些调试信息,不过在研发过程中,为了搞清晰内核的行为,调试信
息非常必要,printk可能是用的最多的,但他并不是最佳的,调试信息只是在研发中用于调试,而printk将一直输出,因此研发完毕后需要清除不必要
的printk语句,另外如果研发者希望用户空间应用能够改动内核行为时,printk就无法实现。因此,需要一种新的机制,那只有在需要的时候使用,他
在需要时通过在一个虚拟文件系统中创建一个或多个文件来向用户空间应用提供调试信息。
有几种方式能实现上述需求:
使用procfs,在/proc创建文件输出调试信息,不过procfs对于大于一个内存页(对于x86是4K)的输出比较麻烦,而且速度慢,有时回出现一些意想不到的问题。
使用sysfs(2.6内核引入的新的虚拟文件系统),在非常多情况下,调试信息能存放在那里,不过sysfs主要用于系统管理,他希望每一个文件对应内核的一个变量,如果使用他输出复杂的数据结构或调试信息是非常困难的。
使用libfs创建一个新的文件系统,该方法极其灵活,研发者能为新文件系统设置一些规则,使用libfs使得创建新文件系统更加简单,不过仍然超出了一个研发者的想象。
为了使得研发者更加容易使用这样的机制,Greg
Kroah-Hartman研发了debugfs(在2.6.11中第一次引入),他是个虚拟文件系统,专门用于输出调试信息,该文件系统非常小,非常容
易使用,能在设置内核时选择是否构件到内核中,在不选择他的情况下,使用他提供的API的内核部分不必做所有改动。
使用debugfs的研发者首先需要在文件系统中创建一个目录,下面函数用于在debugfs文件系统下创建一个目录:
struct dentry *debugfs_create_dir(const char *name, struct dentry *parent);
参数name是要创建的目录名,参数parent指定创建目录的父目录的dentry,如果为NULL,目录将创建在debugfs文件系统的根目
录下。如果返回为-ENODEV,表示内核没有把debugfs编译到其中,如果返回为NULL,表示其他类型的创建失败,如果创建目录成功,返回指向该
目录对应的dentry条目的指针。
下面函数用于在debugfs文件系统中创建一个文件:
struct dentry *debugfs_create_file(const char *name, mode_t mode,
struct dentry *parent, void *data,
struct file_operations *fops);
参数name指定要创建的文件名,参数mode指定该文件的访问许可,参数parent指向该文件所在目录,参数data为该文件特定的一些数据,
参数fops为实目前该文件上进行文件操作的fiel_operations结构指针,在非常多情况下,由seq_file(前面章节已讲过)提供的文件
操作实现就足够了,因此使用debugfs非常容易,当然,在一些情况下,研发者可能仅需要使用用户应用能控制的变量来调试,debugfs也提供了4个
这样的API方便研发者使用:
struct dentry *debugfs_create_u8(const char *name, mode_t mode,
struct dentry *parent, u8 *value);
struct dentry *debugfs_create_u16(const char *name, mode_t mode,
struct dentry *parent, u16 *value);
struct dentry *debugfs_create_u32(const char *name, mode_t mode,
struct dentry *parent, u32 *value);
struct dentry *debugfs_create_bool(const char *name, mode_t mode,
struct dentry *parent, u32 *value);
参数name和mode指定文件名和访问许可,参数value为需要让用户应用控制的内核变量指针。
当内核模块卸载时,Debugfs并不会自动清除该模块创建的目录或文件,因此对于创建的每一个文件或目录,研发者必须调用下面函数清除:
void debugfs_remove(struct dentry *dentry);
参数dentry为上面创建文件和目录的函数返回的dentry指针。
在原始码包中给出了一个使用debufs的示例模块debugfs_exam.c,为了确保该模块正确运行,必须让内核支持debugfs,
debugfs是个调试功能,因此他位于主菜单Kernel hacking,并且必须选择Kernel
debugging选项才能选择,他的选项名称为Debug
Filesystem。为了在用户态使用debugfs,用户必须mount他,下面是在作者系统上的使用输出:
$ mkdir -p /debugfs
$ mount -t debugfs debugfs /debugfs
$ insmod ./debugfs_exam.ko
$ ls /debugfs
debugfs-exam
$ ls /debugfs/debugfs-exam
u8_var u16_var u32_var bool_var
$ cd /debugfs/debugfs-exam
$ cat u8_var
0
$ echo 200 > u8_var
$ cat u8_var
200
$ cat bool_var
N
$ echo 1 > bool_var
$ cat bool_var
Y
8、relayfs
relayfs是个快速的转发(relay)数据的文件系统,他以其功能而得名。他为那些需要从内核空间转发大量数据到用户空间的工具和应用提供了快速有效的转发机制。
Channel是relayfs文件系统定义的一个主要概念,每一个channel由一组内核缓存组成,每一个CPU有一个对应于该channel
的内核缓存,每一个内核缓存用一个在relayfs文件系统中的文件文件表示,内核使用relayfs提供的写函数把需要转发给用户空间的数据快速地写入
当前CPU上的channel内核缓存,用户空间应用通过标准的文件I/O函数在对应的channel文件中能快速地取得这些被转发出的数据mmap
来。写入到channel中的数据的格式完全取决于内核中创建channel的模块或子系统。
relayfs的用户空间API:
relayfs实现了四个标准的文件I/O函数,open、mmap、poll和close
o open(),o 打开一个channel在某一个CPU上的缓存对应的文件。
o mmap(),o 把打开的channel缓存映射到调用者进程的内存空间。
o read
(),o 读取channel缓存,o 随后的读操作将看不o 到被该函数消耗的字节,o 如果channel的操作模式为非覆盖写,o 那么用户空间应用在有内核模块写时仍
能读取,o 不o 过如果channel的操作模式为覆盖式,o 那么在读操作期间如果有内核模块进行写,o 结果将无法预知,o 因此对于覆盖式写的channel,o 用户
应当在确认在channel的写完全结束后再进行读。
o poll(),o 用于通知用户空间应用转发数据跨越了子缓存的边界,o 支持的轮询标o 志有POLLIN、POLLRDNORM和POLLERR。
o close(),o 关闭open函数返回的文件描述符,o 如果没有进程或内核模块打开该channel缓存,o close函数将释放该channel缓存。
注意:用户态应用在使用上述API时必须确保已挂载了relayfs文件系统,但内核在创建和使用channel时不必relayfs已挂载。下面命令将把relayfs文件系统挂载到/mnt/relay。
mount -t relayfs relayfs /mnt/relay
relayfs内核API:
relayfs提供给内核的API包括四类:channel管理、写函数、回调函数和辅助函数。
Channel管理函数包括:
o relay_open(base_filename, parent, subbuf_size, n_subbufs, overwrite, callbacks)
o relay_close(chan)
o relay_flush(chan)
o relay_reset(chan)
o relayfs_create_dir(name, parent)
o relayfs_remove_dir(dentry)
o relay_commit(buf, reserved, count)
o relay_subbufs_consumed(chan, cpu, subbufs_consumed)
写函数包括:
o relay_write(chan, data, length)
o __relay_write(chan, data, length)
o relay_reserve(chan, length)
回调函数包括:
o subbuf_start(buf, subbuf, prev_subbuf_idx, prev_subbuf)
o buf_mapped(buf, filp)
o buf_unmapped(buf, filp)
辅助函数包括:
o relay_buf_full(buf)
o subbuf_start_reserve(buf, length)
前面已讲过,每一个channel由一组channel缓存组成,每个CPU对应一个该channel的缓存,每一个缓存又由一个或多个子缓存组成,每一个缓存是子缓存组成的一个环型缓存。
函数relay_open用于创建一个channel并分配对应于每一个CPU的缓存,用户空间应用通过在relayfs文件系统中对应的文件能
访问channel缓存,参数base_filename用于指定channel的文件名,relay_open函数将在relayfs文件系统中创建
base_filename0..base_filenameN-1,即每一个CPU对应一个channel文件,其中N为CPU数,缺省情况下,这些文
件将建立在relayfs文件系统的根目录下,但如果参数parent非空,该函数将把channel文件创建于parent目录下,parent目录使
用函数relay_create_dir创建,函数relay_remove_dir用于删除由函数relay_create_dir创建的目录,谁创建
的目录,谁就负责在不用时负责删除。参数subbuf_size用于指定channel缓存中每一个子缓存的大小,参数n_subbufs用于指定
channel缓存包含的子缓存数,因此实际的channel缓存大小为(subbuf_size x
n_subbufs),参数overwrite用于指定该channel的操作模式,relayfs提供了两种写模式,一种是覆盖式写,另一种是非覆盖式
写。使用哪一种模式完全取决于函数subbuf_start的实现,覆盖写将在缓存已满的情况下无条件地继续从缓存的开始写数据,而不管这些数据是否已
被用户应用读取,因此写操作决不失败。在非覆盖写模式下,如果缓存满了,写将失败,但内核将在用户空间应用读取缓存数据时通过函数
relay_subbufs_consumed()通知relayfs。如果用户空间应用没来得及消耗缓存中的数据或缓存已满,两种模式都将导致数据丢
失,唯一的差别是,前者丢失数据在缓存开头,而后者丢失数据在缓存末尾。一旦内核再次调用函数relay_subbufs_consumed(),已满的
缓存将不再满,因而能继续写该缓存。当缓存满了以后,relayfs将调用回调函数buf_full()来通知内核模块或子系统。当新的数据太大无法写
入当前子缓存剩余的空间时,relayfs将调用回调函数subbuf_start()来通知内核模块或子系统将需要使用新的子缓存。内核模块需要在该回
调函数中实现下述功能:
初始化新的子缓存;
如果1正确,完成当前子缓存;
如果2正确,返回是否正确完成子缓存转换;
在非覆盖写模式下,回调函数subbuf_start()应该如下实现:
static int subbuf_start(struct rchan_buf *buf,
void *subbuf,
void *prev_subbuf,
unsigned int prev_padding)
{
if (prev_subbuf)
*((unsigned *)prev_subbuf) = prev_padding;
if (relay_buf_full(buf))
return 0;
subbuf_start_reserve(buf, sizeof(unsigned int));
return 1;
}
如果当前缓存满,即所有的子缓存都没读取,该函数返回0,指示子缓存转换没有成功。当子缓存通过函数relay_subbufs_consumed
()被读取后,读取者将负责通知relayfs,函数relay_buf_full()在已有读者读取子缓存数据后返回0,在这种情况下,子缓存转换成
功进行。
在覆盖写模式下, subbuf_start()的实现和非覆盖模式类似:
static int subbuf_start(struct rchan_buf *buf,
void *subbuf,
void *prev_subbuf,
unsigned int prev_padding)
{
if (prev_subbuf)
*((unsigned *)prev_subbuf) = prev_padding;
subbuf_start_reserve(buf, sizeof(unsigned int));
return 1;
}
只是不做relay_buf_full()检查,因为此模式下,缓存是环行的,能无条件地写。因此在此模式下,子缓存转换必定成功,函数
relay_subbufs_consumed() 也无须调用。如果channel写者没有定义subbuf_start(),缺省的实现将被使用。
能通过在回调函数subbuf_start()中调用辅助函数subbuf_start_reserve()在子缓存中预留头空间,预留空间能保存任
何需要的信息,如上面例子中,预留空间用于保存子缓存填充字节数,在subbuf_start()实现中,前一个子缓存的填充值被设置。前一个子缓存的填
充值和指向前一个子缓存的指针一道作为subbuf_start()的参数传递给subbuf_start(),只有在子缓存完成后,才能知道填充值。
subbuf_start()也被在channel创建时分配每一个channel缓存的第一个子缓存时调用,以便预留头空间,但在这种情况下,前一个子
缓存指针为NULL。
内核模块使用函数relay_write()或__relay_write()往channel缓存中写需要转发的数据,他们的差别是前者失效了本
地中断,而后者只抢占失效,因此前者能在所有内核上下文安全使用,而后者应当在没有所有中断上下文将写channel缓存的情况下使用。这两个函数没有
返回值,因此用户不能直接确定写操作是否失败,在缓存满且写模式为非覆盖模式时,relayfs将通过回调函数buf_full来通知内核模块。
函数relay_reserve()用于在channel缓存中预留一段空间以便以后写入,在那些没有临时缓存而直接写入channel缓存的内核
模块可能需要该函数,使用该函数的内核模块在实际写这段预留的空间时能通过调用relay_commit()来通知relayfs。当所有预留的空间全
部写完并通过relay_commit通知relayfs后,relayfs将调用回调函数deliver()通知内核模块一个完整的子缓存已填满。由
于预留空间的操作并不在写channel的内核模块完全控制之下,因此relay_reserve()不能非常好地保护缓存,因此当内核模块调用
relay_reserve()时必须采取恰当的同步机制。
当内核模块结束对channel的使用后需要调用relay_close() 来关闭channel,如果没有所有用户在引用该channel,他将和对应的缓存全部被释放。
函数relay_flush()强制在所有的channel缓存上做一个子缓存转换,他在channel被关闭前使用来终止和处理最后的子缓存。
函数relay_reset()用于将一个channel恢复到初始状态,因而不必释放现存的内存映射并重新分配新的channel缓存就能使用channel,不过该调用只有在该channel没有所有用户在写的情况下才能安全使用。
回调函数buf_mapped() 在channel缓存被映射到用户空间时被调用。
回调函数buf_unmapped()在释放该映射时被调用。内核模块能通过他们触发一些内核操作,如开始或结束channel写操作。
在原始码包中给出了一个使用relayfs的示例程式relayfs_exam.c,他只包含一个内核模块,对于复杂的使用,需要应用程式配合。该模块实现了类似于文章中seq_file示例实现的功能。
当然为了使用relayfs,用户必须让内核支持relayfs,并且要mount他,下面是作者系统上的使用该模块的输出信息:
$ mkdir -p /relayfs
$ insmod ./relayfs-exam.ko
$ mount -t relayfs relayfs /relayfs
$ cat /relayfs/example0
…
$
relayfs是一种比较复杂的内核态和用户态的数据交换方式,本例子程式只提供了一个较简单的使用方式,对于复杂的使用,请参考relayfs用例页面
http://relayfs.sourceforge.net/examples.html
。
小结
本文是该系列文章最后一篇,他周详地讲解了其余四种用户空间和内核空间的数据交换方式,并通过实际例子程式向读者讲解了怎么在内核研发中使用这些技
术,其中seq_file是单向的,即只能向内核传递,而不能从内核获取,而另外三种方式均能进行双向数据交换,即既能从用户应用传递给内核,又能
从内核传递给应用态应用。procfs一般用于向用户出口少量的数据信息,或用户通过他设置内核变量从而控制内核行为。seq_file实际上依赖于
procfs,因此为了使用seq_file,必须使内核支持procfs。debugfs用于内核研发者调试使用,他比其他集中方式都方便,不过仅用于
简单类型的变量处理。relayfs是一种非常复杂的数据交换方式,要想准确使用并不容易,不过如果使用得当,他远比procfs和seq_file功能
强大。
linux用户空间和内核空间交换数据
在研究dahdi驱动的时候,见到了一些get_user,put_user的函数,不知道其来由,故而搜索了这篇文章,前面对linux内存的框架描述不是很清晰,描述的有一点乱,如果没有刚性需求,建议不用怎么关注,倒不如直接看那几个图片。对我非常有用的地方就是几个函数的介绍,介绍的比较详细,对应用有需求的可以着重看一个这几个函数。
Linux 内存
在 Linux
中,用户内存和内核内存是独立的,在各自的地址空间实现。地址空间是虚拟的,就是说地址是从物理内存中抽象出来的(通过一个简短描述的过程)。由于地址空间是虚拟的,所以可以存在很多。事实上,内核本身驻留在一个地址空间中,每个进程驻留在自己的地址空间。这些地址空间由虚拟内存地址组成,允许一些带有独立地址空间的进程指向一个相对较小的物理地址空间(在机器的物理内存中)。不仅仅是方便,而且更安全。因为每个地址空间是独立且隔离的,因此很安全。
但是与安全性相关联的成本很高。因为每个进程(和内核)会有相同地址指向不同的物理内存区域,不可能立即共享内存。幸运的是,有一些解决方案。用户进程可以通过
Portable Operating System Interface for UNIX? (POSIX)
共享的内存机制(shmem)共享内存,但有一点要说明,每个进程可能有一个指向相同物理内存区域的不同虚拟地址。
虚拟内存到物理内存的映射通过页表完成,这是在底层软件中实现的(见图
1)。硬件本身提供映射,但是内核管理表及其配置。注意这里的显示,进程可能有一个大的地址空间,但是很少见,就是说小的地址空间的区域(页面)通过页表指向物理内存。这允许进程仅为随时需要的网页指定大的地址空间。
图 1. 页表提供从虚拟地址到物理地址的映射 
由于缺乏为进程定义内存的能力,底层物理内存被过度使用。通过一个称为 paging(然而,在 Linux 中通常称为
swap)的进程,很少使用的页面将自动移到一个速度较慢的存储设备(比如磁盘),来容纳需要被访问的其它页面(见图 2
)。这一行为允许,在将很少使用的页面迁移到磁盘来提高物理内存使用的同时,计算机中的物理内存为应用程序更容易需要的页面提供服务。注意,一些页面可以指向文件,在这种情况下,如果页面是脏(dirty)的,数据将被冲洗,如果页面是干净的(clean),直接丢掉。
图 2. 通过将很少使用的页面迁移到速度慢且便宜的存储器,交换使物理内存空间得到了更好的利用 
MMU-less 架构
不是所有的处理器都有 MMU。因此,uClinux 发行版(微控制器 Linux)支持操作的一个地址空间。该架构缺乏 MMU 提供的保护,但是允许 Linux 运行另一类处理器。
选择一个页面来交换存储的过程被称为一个页面置换算法,可以通过使用许多算法(至少是最近使用的)来实现。该进程在请求存储位置时发生,存储位置的页面不在存储器中(在存储器管理单元
[MMU] 中无映射)。这个事件被称为一个页面错误 并被硬件(MMU)删除,出现页面错误中断后该事件由防火墙管理。该栈的详细说明见 图 3。
Linux 提供一个有趣的交换实现,该实现提供许多有用的特性。Linux
交换系统允许创建和使用多个交换分区和优先权,这支持存储设备上的交换层次结构,这些存储设备提供不同的性能参数(例如,固态磁盘 [SSD]
上的一级交换和速度较慢的存储设备上的较大的二级交换)。为 SSD
交换附加一个更高的优先级使其可以使用直至耗尽;直到那时,页面才能被写入优先级较低的交换分区。
图 3. 地址空间和虚拟 - 物理地址映射的元素 
并不是所有的页面都适合交换。考虑到响应中断的内核代码或者管理页表和交换逻辑的代码,显然,这些页面决不能被换出,因此它们是固定的,或者是永久地驻留在内存中。尽管内核页面不需要进行交换,然而用户页面需要,但是它们可以被固定,通过
mlock(或
mlockall)函数来锁定页面。这就是用户空间内存访问函数的目的。如果内核假设一个用户传递的地址是有效的且是可访问的,最终可能会出现内核严重错误(kernel
panic)(例如,因为用户页面被换出,而导致内核中的页面错误)。该应用程序编程接口(API)确保这些边界情况被妥善处理。
内核 API
现在,让我们来研究一下用户操作用户内存的内核 API。请注意,这涉及内核和用户空间接口,而下一部分将研究其他的一些内存 API。用户空间内存访问函数在表 1 中列出。
表 1. 用户空间内存访问 API
| 函数 | 描述 |
| access_ok | 检查用户空间内存指针的有效性 |
| get_user | 从用户空间获取一个简单变量 |
| put_user | 输入一个简单变量到用户空间 |
| clear_user | 清除用户空间中的一个块,或者将其归零。 |
| copy_to_user | 将一个数据块从内核复制到用户空间 |
| copy_from_user | 将一个数据块从用户空间复制到内核 |
| strnlen_user | 获取内存空间中字符串缓冲区的大小 |
| strncpy_from_user | 从用户空间复制一个字符串到内核 |
正如您所期望的,这些函数的实现架构是独立的。例如在 x86 架构中,您可以使用
./linux/arch/x86/lib/usercopy_32.c 和 usercopy_64.c 中的源代码找到这些函数以及在
./linux/arch/x86/include/asm/uaccess.h 中定义的字符串。
当数据移动函数的规则涉及到复制调用的类型时(简单 VS. 聚集),这些函数的作用如图 4 所示。
图 4. 使用 User Space Memory Access API 进行数据移动 
access_ok 函数
您可以使用 access_ok 函数在您想要访问的用户空间检查指针的有效性。调用函数提供指向数据块的开始的指针、块大小和访问类型(无论这个区域是用来读还是写的)。函数原型定义如下:
access_ok( type, addr, size );
type 参数可以被指定为 VERIFY_READ 或 VERIFY_WRITE。VERIFY_WRITE 也可以识别内存区域是否可读以及可写(尽管访问仍然会生成 -EFAULT)。该函数简单检查地址可能是在用户空间,而不是内核。
get_user 函数
要从用户空间读取一个简单变量,可以使用 get_user 函数,该函数适用于简单数据类型,比如,char 和
int,但是像结构体这类较大的数据类型,必须使用 copy_from_user 函数。该原型接受一个变量(存储数据)和一个用户空间地址来进行
Read 操作:
get_user( x, ptr );
get_user 函数将映射到两个内部函数其中的一个。在系统内部,这个函数决定被访问变量的大小(根据提供的变量存储结果)并通过
__get_user_x 形成一个内部调用。成功时该函数返回 0,一般情况下,get_user 和 put_user
函数比它们的块复制副本要快一些,如果是小类型被移动的话,应该用它们。
put_user 函数
您可以使用 put_user 函数来将一个简单变量从内核写入用户空间。和 get_user 一样,它接受一个变量(包含要写的值)和一个用户空间地址作为写目标:
put_user( x, ptr );
和 get_user 一样,put_user 函数被内部映射到 put_user_x 函数,成功时,返回 0,出现错误时,返回 -EFAULT。
clear_user 函数
clear_user 函数被用于将用户空间的内存块清零。该函数采用一个指针(用户空间中)和一个型号进行清零,这是以字节定义的:
clear_user( ptr, n );
在内部,clear_user 函数首先检查用户空间指针是否可写(通过 access_ok),然后调用内部函数(通过内联组装方式编码)来执行
Clear 操作。使用带有 repeat 前缀的字符串指令将该函数优化成一个非常紧密的循环。它将返回不可清除的字节数,如果操作成功,则返回 0。
copy_to_user 函数
copy_to_user 函数将数据块从内核复制到用户空间。该函数接受一个指向用户空间缓冲区的指针、一个指向内存缓冲区的指针、以及一个以字节定义的长度。该函数在成功时,返回 0,否则返回一个非零数,指出不能发送的字节数。
copy_to_user( to, from, n );
检查了向用户缓冲区写入的功能之后(通过 access_ok),内部函数 __copy_to_user 被调用,它反过来调用
__copy_from_user_inatomic(在 ./linux/arch/x86/include/asm/uaccess_XX.h
中。其中 XX 是 32 或者 64 ,具体取决于架构。)在确定了是否执行 1、2 或 4 字节复制之后,该函数调用
__copy_to_user_ll,这就是实际工作进行的地方。在损坏的硬件中(在 i486 之前,WP
位在管理模式下不可用),页表可以随时替换,需要将想要的页面固定到内存,使它们在处理时不被换出。i486
之后,该过程只不过是一个优化的副本。
copy_from_user 函数
copy_from_user
函数将数据块从用户空间复制到内核缓冲区。它接受一个目的缓冲区(在内核空间)、一个源缓冲区(从用户空间)和一个以字节定义的长度。和
copy_to_user 一样,该函数在成功时,返回 0 ,否则返回一个非零数,指出不能复制的字节数。
copy_from_user( to, from, n );
该函数首先检查从用户空间源缓冲区读取的能力(通过 access_ok),然后调用 __copy_from_user,最后调用
__copy_from_user_ll。从此开始,根据构架,为执行从用户缓冲区到内核缓冲区的零拷贝(不可用字节)而进行一个调用。优化组装函数包含管理功能。
strnlen_user 函数
strnlen_user 函数也能像 strnlen 那样使用,但前提是缓冲区在用户空间可用。strnlen_user 函数带有两个参数:用户空间缓冲区地址和要检查的最大长度。
strnlen_user( src, n );
strnlen_user 函数首先通过调用 access_ok 检查用户缓冲区是否可读。如果是 strlen 函数被调用,max length 参数则被忽略。
strncpy_from_user 函数
strncpy_from_user 函数将一个字符串从用户空间复制到一个内核缓冲区,给定一个用户空间源地址和最大长度。
strncpy_from_user( dest, src, n );
由于从用户空间复制,该函数首先使用 access_ok 检查缓冲区是否可读。和 copy_from_user 一样,该函数作为一个优化组装函数(在 ./linux/arch/x86/lib/usercopy_XX.c 中)实现。
内存映射的其他模式
上面部分探讨了在内核和用户空间之间移动数据的方法(使用内核初始化操作)。Linux 还提供一些其他的方法,用于在内核和用户空间中移动数据。尽管这些方法未必能够提供与用户空间内存访问函数相同的功能,但是它们在地址空间之间映射内存的功能是相似的。
在用户空间,注意,由于用户进程出现在单独的地址空间,在它们之间移动数据必须经过某种进程间通信机制。Linux
提供各种模式(比如,消息队列),但是最着名的是 POSIX
共享内存(shmem)。该机制允许进程创建一个内存区域,然后同一个或多个进程共享该区域。注意,每个进程可能在其各自的地址空间中映射共享内存区域到不同地址。因此需要相对的寻址偏移(offset
addressing)。
mmap
函数允许一个用户空间应用程序在虚拟地址空间中创建一个映射,该功能在某个设备驱动程序类中是常见的,允许将物理设备内存映射到进程的虚拟地址空间。在一个驱动程序中,mmap
函数通过 remap_pfn_range 内核函数实现,它提供设备内存到用户地址空间的线性映射。
结束语
本文讨论了 Linux 中的内存管理主题,然后讨论了使用这些概念的用户空间内存访问函数。在用户空间和内核空间之间移动数据并没有表面上看起来那么简单,但是 Linux 包含一个简单的 API 集合,跨平台为您管理这个复杂的任务。
内核空间与用户空间的通信方式
下面总结了7种方式,主要对以前不是很熟悉的方式做了编程实现,以便加深印象。
1.使用API:这是最常使用的一种方式了
A.get_user(x,ptr):在内核中被调用,获取用户空间指定地址的数值并保存到内核变量x中。
B.put_user(x,ptr):在内核中被调用,将内核空间的变量x的数值保存到到用户空间指定地址处。
C.Copy_from_user()/copy_to_user():主要应用于设备驱动读写函数中,通过系统调用触发。
2.使用proc文件系统:和sysfs文件系统类似,也可以作为内核空间和用户空间交互的手段。
/proc 文件系统是一种虚拟文件系统,通过他可以作为一种linux内核空间和用户空间的。与普通文件不同,这里的虚拟文件的内容都是动态创建的。
使用/proc文件系统的方式很简单。调用create_proc_entry,返回一个proc_dir_entry指针,然后去填充这个指针指向的结构就好了,我下面的这个测试用例只是填充了其中的read_proc属性。
下面是一个简单的测试用例,通过读虚拟出的文件可以得到内核空间传递过来的“proc ! test by qiankun!”字符串。
3.使用sysfs文件系统+kobject:其实这个以前是编程实现过得,但是那天太紧张忘记了,T_T。每个在内核中注册的kobject都对应着sysfs系统中的一个目录。可以通过读取根目录下的sys目录中的文件来获得相应的信息。除了sysfs文件系统和proc文件系统之外,一些其他的虚拟文件系统也能同样达到这个效果。
4.netlink:netlink socket提供了一组类似于BSD风格的API,用于用户态和内核态的IPC。相比于其他的用户态和内核态IPC机制,netlink有几个好处:1.使用自定义一种协议完成数据交换,不需要添加一个文件等。2.可以支持多点传送。3.支持内核先发起会话。4.异步通信,支持缓存机制。
对于用户空间,使用netlink比较简单,因为和使用socket非常的类似,下面说一下内核空间对netlink的使用,主要说一下最重要的create函数,函数原型如下:
extern struct sock *netlink_kernel_create(struct net *net,
int unit,unsigned int groups,
void (*input)(struct sk_buff *skb),
struct mutex *cb_mutex,
struct module *module);
第一个参数一般传入&init_net。
第二个参数指的是netlink的类型,系统定义了16个,我们如果使用的话最好自己定义。这个需和用户空间所使用的创建socket的第三个参数一致,才可以完成通信。
第四个参数指的是一个回调函数,当接受到一个消息的时候会调用这个函数。回调函数的参数为struct sk_buff类型的结构体。通过分析其结构成员可以得到传递过来的数据
第六个参数一般传入的是THIS_MODULE。指当前模块。
下面是对netlink的一个简单测试,将字符串“netlink test by qiankun”通过netlink输出到内核,内核再把字符串返回。Netlink类型使用的是22.

5.文件:应该说这是一种比较笨拙的做法,不过确实可以这样用。当处于内核空间的时候,直接操作文件,将想要传递的信息写入文件,然后用户空间可以读取这个文件便可以得到想要的数据了。下面是一个简单的测试程序,在内核态中,程序会向“/home/melody/str_from_kernel”文件中写入一条字符串,然后我们在用户态读取这个文件,就可以得到内核态传输过来的数据了。

6.使用mmap系统调用:可以将内核空间的地址映射到用户空间。在以前做嵌入式的时候用到几次。一方面可以在driver中修改Struct file_operations结构中的mmap函数指针来重新实现一个文件对应的映射操作。另一方面,也可以直接打开/dev/mem文件,把物理内存中的某一页映射到进程空间中的地址上。
其实,除了重写Struct file_operations中mmap函数,我们还可以重写其他的方法如ioctl等,来达到驱动内核空间和用户空间通信的方式。
7.信号:从内核空间向进程发送信号。这个倒是经常遇到,用户程序出现重大错误,内核发送信号杀死相应进程。
socket阻塞与非阻塞模式
阻塞模式
Windows套接字在阻塞和非阻塞两种模式下执行I/O操作。在阻塞模式下,在I/O操作完成前,执行的操作函数一直等候而不会立即返回,该函数所在的线程会阻塞在这里。相反,在非阻塞模式下,套接字函数会立即返回,而不管I/O是否完成,该函数所在的线程会继续运行。
在阻塞模式的套接字上,调用任何一个Windows Sockets API都会耗费不确定的等待时间。图所示,在调用recv()函数时,发生在内核中等待数据和复制数据的过程。
当调用recv()函数时,系统首先查是否有准备好的数据。如果数据没有准备好,那么系统就处于等待状态。当数据准备好后,将数据从系统缓冲区复制到用户空间,然后该函数返回。在套接应用程序中,当调用recv()函数时,未必用户空间就已经存在数据,那么此时recv()函数就会处于等待状态。
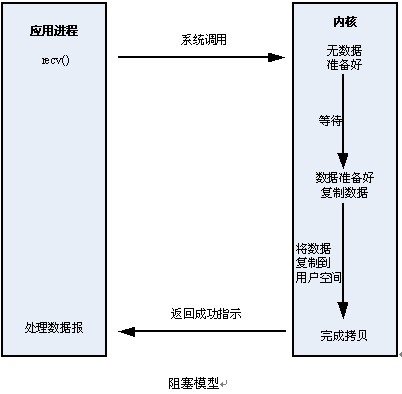
当使用socket()函数创建套接字时,默认的套接字都是阻塞的。这意味着当调用Windows Sockets API不能立即完成时,线程处于等待状态,直到操作完成。
并不是所有Windows Sockets API以阻塞套接字为参数调用都会发生阻塞。例如,以阻塞模式的套接字为参数调用bind()、listen()函数时,函数会立即返回。将可能阻塞套接字的Windows Sockets API调用分为以下四种:
1.输入操作
recv()、recvfrom()、WSARecv()和WSARecvfrom()函数。以阻塞套接字为参数调用该函数接收数据。如果此时套接字缓冲区内没有数据可读,则调用线程在数据到来前一直睡眠。
2.输出操作
send()、sendto()、WSASend()和WSASendto()函数。以阻塞套接字为参数调用该函数发送数据。如果套接字缓冲区没有可用空间,线程会一直睡眠,直到有空间。
3.接受连接
accept()和WSAAcept()函数。以阻塞套接字为参数调用该函数,等待接受对方的连接请求。如果此时没有连接请求,线程就会进入睡眠状态。
4.外出连接
connect()和WSAConnect()函数。对于TCP连接,客户端以阻塞套接字为参数,调用该函数向服务器发起连接。该函数在收到服务器的应答前,不会返回。这意味着TCP连接总会等待至少到服务器的一次往返时间。
使用阻塞模式的套接字,开发网络程序比较简单,容易实现。当希望能够立即发送和接收数据,且处理的套接字数量比较少的情况下,使用阻塞模式来开发网络程序比较合适。
阻塞模式套接字的不足表现为,在大量建立好的套接字线程之间进行通信时比较困难。当使用“生产者-消费者”模型开发网络程序时,为每个套接字都分别分配一个读线程、一个处理数据线程和一个用于同步的事件,那么这样无疑加大系统的开销。其最大的缺点是当希望同时处理大量套接字时,将无从下手,其扩展性很差。
非阻塞模式
把套接字设置为非阻塞模式,即通知系统内核:在调用Windows
Sockets
API时,不要让线程睡眠,而应该让函数立即返回。在返回时,该函数返回一个错误代码。图所示,一个非阻塞模式套接字多次调用recv()函数的过程。前三次调用recv()函数时,内核数据还没有准备好。因此,该函数立即返回WSAEWOULDBLOCK错误代码。第四次调用recv()函数时,数据已经准备好,被复制到应用程序的缓冲区中,recv()函数返回成功指示,应用程序开始处理数据。
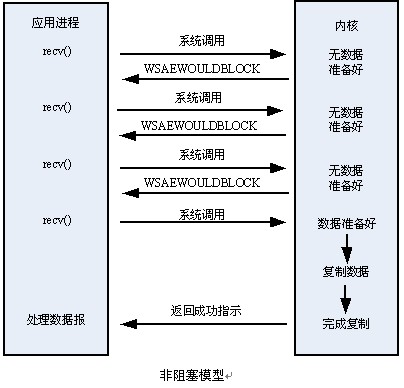
当使用socket()函数和WSASocket()函数创建套接字时,默认都是阻塞的。在创建套接字之后,通过调用ioctlsocket()函数,将该套接字设置为非阻塞模式。Linux下的函数是:fcntl().
套接字设置为非阻塞模式后,在调用Windows Sockets
API函数时,调用函数会立即返回。大多数情况下,这些函数调用都会调用“失败”,并返回WSAEWOULDBLOCK错误代码。说明请求的操作在调用期间内没有时间完成。通常,应用程序需要重复调用该函数,直到获得成功返回代码。
需要说明的是并非所有的Windows Sockets
API在非阻塞模式下调用,都会返回WSAEWOULDBLOCK错误。例如,以非阻塞模式的套接字为参数调用bind()函数时,就不会返回该错误代码。当然,在调用WSAStartup()函数时更不会返回该错误代码,因为该函数是应用程序第一调用的函数,当然不会返回这样的错误代码。
要将套接字设置为非阻塞模式,除了使用ioctlsocket()函数之外,还可以使用WSAAsyncselect()和WSAEventselect()函数。当调用该函数时,套接字会自动地设置为非阻塞方式。
由于使用非阻塞套接字在调用函数时,会经常返回WSAEWOULDBLOCK错误。所以在任何时候,都应仔细检查返回代码并作好对“失败”的准备。应用程序连续不断地调用这个函数,直到它返回成功指示为止。上面的程序清单中,在While循环体内不断地调用recv()函数,以读入1024个字节的数据。这种做法很浪费系统资源。
要完成这样的操作,有人使用MSG_PEEK标志调用recv()函数查看缓冲区中是否有数据可读。同样,这种方法也不好。因为该做法对系统造成的开销是很大的,并且应用程序至少要调用recv()函数两次,才能实际地读入数据。较好的做法是,使用套接字的“I/O模型”来判断非阻塞套接字是否可读可写。
非阻塞模式套接字与阻塞模式套接字相比,不容易使用。使用非阻塞模式套接字,需要编写更多的代码,以便在每个Windows Sockets API函数调用中,对收到的WSAEWOULDBLOCK错误进行处理。因此,非阻塞套接字便显得有些难于使用。
非阻塞套接字在控制建立的多个连接,在数据的收发量不均,时间不定时,明显具有优势。
这种套接字在使用上存在一定难度,但只要排除了这些困难,它在功能上还是非常强大的。通常情况下,可考虑使用套接字的“I/O模型”,它有助于应用程序通过异步方式,同时对一个或多个套接字的通信加以管理。
Linux设备的阻塞式和非阻塞式访问
休眠的概念:
休眠的进程会被搁置在一边,等待将来的某个事件发生。
当进程休眠时,它期待某个条件未来为真,当一个休眠的进程被唤醒
是,它必须再次检查它所等待的条件的确为真。
休眠有简单休眠、高级休眠、手工休眠等。
1.1简单休眠
Linux内核中最简单的休眠方式称为是wait_event的宏,它在休眠的同时
也要检查进程等待的条件。
以下是几种简单的休眠宏:
1)、wait_event(wq, condition)
* wait_event - sleep until a condition gets true
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
* @condition:任意一个布尔表达式
2)、wait_event_timeout(wq, condition, ret)
* wait_event_timeout - sleep until a condition gets true or a timeout elapses
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
* @timeout: timeout, in jiffies
3)、wait_event_interruptible(wq, condition)
* wait_event_interruptible - sleep until a condition gets true or a signal is received
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
4)、wait_event_interruptible_timeout(wq, condition, timeout)
* wait_event_interruptible_timeout - sleep until a condition gets true or a timeout elapses
* @wq: the waitqueue to wait on
* @condition: a C expression for the event to wait for
* @timeout: timeout, in jiffies
唤醒休眠函数
wake_up()
wake_up_interruptible()
wake_up()会唤醒等待在queue上的所有进程,wake_up_interruptible()
只会唤醒那些执行可中断休眠的进程
如果要确保只有一个进程能看到非零值,则必须以原子的方式进行检查。
if (condition)\
break;
\
__wait_event(wq, condition);\
} while (0)
1.2高级休眠
1.3手工休眠
在早期的Linux版本中出现,如果愿意仍可以沿用这种休眠方式,但容易出错。
在源码中进行了如下解释:
DEFINE_WAIT(name) //建立并初始化一个等待队列入口
void prepare_to_wait(wait_queue_head_t *q, wait_queue_t *wait, int state);
void finish_wait(wait_queue_head_t *q, wait_queue_t *wait);
2、Linux设备的阻塞式和非阻塞式访问
linux驱动为上层用户空间访问设备提供了阻塞和非阻塞两种不同
的访问模式。
阻塞操作的概念:
在执行设备操作时若不能获得资源则挂起进程,知道满足可操作的
条件后再进行操作,被挂起的进程进入休眠状态。
非阻塞操作的概念:
在不能进行设备操作时并不挂起,它或者放弃,或者不停的查询,
直到可以操作为止。只有read、write和open文件操作受非阻塞标志的影响。
阻塞的进程会进入休眠状态,因此必须确保有一个地方能够唤醒休
眠的进程,为确保唤醒发生,需整体理解自己的代码,唤醒休眠进程的
地方最可能发生在中断,因为硬件资源状态变化往往伴随一个中断。
使用非阻塞I/O的应用程序通常会使用select()和poll()系统调用查询是否对
设备进行无阻塞的访问。select()和poll()的系统调用最终会引发设备驱动中的poll
函数执行。select()和poll()系统调用的本质是一样的。
深入浅出:Linux设备驱动中的阻塞和非阻塞I/O
今天写的是Linux设备驱动中的阻塞和非阻塞I/0,何谓阻塞与非阻塞I/O?简单来说就是对I/O操作的两种不同的方式,驱动程序可以灵活的支持用户空间对设备的这两种访问方式。
一、基本概念:
阻塞操作 : 是指在执行设备操作时,若不能获得资源,则挂起进程直到满足操作条件后再进行操作。被挂起的进程进入休眠, 被从调度器移走,直到条件满足。
非阻塞操作 :在不能进行设备操作时,并不挂起,它或者放弃,或者不停地查询,直到可以进行操作。非阻塞应用程序通常使用select系统调用查询是否可以对设备进行无阻塞的访问最终会引发设备驱动中 poll函数执行。
二、轮询操作
阻塞的读取一个字符:
char buf;
fd = open("/dev/ttyS1",O_RDWR);
.....
res = read(fd,&buf,1); //当串口上有输入时才返回,没有输入则进程挂起睡眠
if(res == 1)
{
printf("%c/n",buf);
}char buf;
fd = open("/dev/ttyS1",O_RDWR);
.....
res = read(fd,&buf,1); //当串口上有输入时才返回,没有输入则进程挂起睡眠
if(res == 1)
{
printf("%c/n",buf);
}非阻塞的读一个字符:
char buf;
fd = open("/dev/ttyS1",O_RDWR|O_NONBLOCK);//O_NONBLOCK 非阻塞标识
.....
while(read(fd,&buf,1)!=1);//串口上没有输入则返回,所以循环读取
printf("%c/n",buf);char buf;
fd = open("/dev/ttyS1",O_RDWR|O_NONBLOCK);//O_NONBLOCK 非阻塞标识
.....
while(read(fd,&buf,1)!=1);//串口上没有输入则返回,所以循环读取
printf("%c/n",buf);阻塞操作常常用等待队列来实现,而非阻塞操作用轮询的方式来实现。非阻塞I/O的操作在应用层通常会用到select()和poll()系统调用查询是否可对设备进行无阻塞访问。select()和poll()系统调用最终会引发设备驱动中的poll()函数被调用。这里对队列就不多介绍了,大家可以看看数据结构里面的知识点。
应用层的select()原型为:
int select(int numfds,fd_set *readfds,fd_set *writefds,fd_set *exceptionfds,struct timeval *timeout);numfds 的值为需要检查的号码最高的文件描述符加1,若select()在等待timeout时间后,若没有文件描述符准备好则返回。
int select(int numfds,fd_set *readfds,fd_set *writefds,fd_set *exceptionfds,
struct timeval *timeout); numfds 的值为需要检查的号码最高的文件描述符加1,若select()在等待timeout时间后,若没有文件描述符准备好则返回。
应用程序为:
#inlcude------
main()
{
int fd,num;
char rd_ch[BUFFER_LEN];
fd_set rfds,wfds; //读写文件描述符集
//以非阻塞方式打开/dev/globalfifo设备文件
fd=open("/dev/globalfifo",O_RDWR|O_NONBLOCK);
if(fd != -1)
{
//FIFO 清零
if(ioctl(fd,FIFO_CLEAR,0) < 0)
{
printf("ioctl cmd failed /n");
}
while(1)
{
FD_ZERO(&rfds);
FD_ZERO(&wfds);
FD_SET(fd,&rfds);
FD_SET(fd,&wfds);
select(fd+1,&rfds,&wfds,null,null);
}
}
}
#inlcude------
main()
{
int fd,num;
char rd_ch[BUFFER_LEN];
fd_set rfds,wfds; //读写文件描述符集
//以非阻塞方式打开/dev/globalfifo设备文件
fd=open("/dev/globalfifo",O_RDWR|O_NONBLOCK);
if(fd != -1)
{
//FIFO 清零
if(ioctl(fd,FIFO_CLEAR,0) < 0)
{
printf("ioctl cmd failed /n");
}
while(1)
{
FD_ZERO(&rfds);
FD_ZERO(&wfds);
FD_SET(fd,&rfds);
FD_SET(fd,&wfds);
select(fd+1,&rfds,&wfds,null,null);
}
}
}下面说说设备驱动中的poll()函数,函数原型如下:
static unsigned int poll(struct file *file, struct socket *sock,poll_table *wait) //第一个参数是file结构体指针,第三个参数是轮询表指针,这个函数应该进行两项工作
static unsigned int poll(struct file *file, struct socket *sock,poll_table *wait) //第一个参数是file结构体指针,第三个参数是轮询表指针,这个函数应该进行两项工作
对可能引起设备文件状态变化的等待队列调用poll_wait()函数,将对应的等待队列头添加到poll_table
返回表示是否能对设备进行无阻塞读,写访问的掩码
这里还要提到poll_wait()函数,很多人会以为是和wait_event()一样的函数,会阻塞的等待某件事情的发生,其实这个函数并不会引起阻塞,它的工作是把当前的进程增添到wait参数指定的等待列表poll_table中去,poll_wait()函数原型如下:
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)从中可以看出是将等待队列头wait_address添加到p所指向的结构体中(poll_table)
static inline void poll_wait(struct file * filp, wait_queue_head_t * wait_address, poll_table *p)
从中可以看出是将等待队列头wait_address添加到p所指向的结构体中(poll_table)
驱动函数中的poll()函数典型模板如下:
static unsigned int xxx_poll(struct file *filp,struct socket *sock,
poll_table *wait)
{
unsigned int mask = 0;
struct xxx_dev *dev = filp->private_data;//获得设备结构体指针
...
poll_wait(filp,&dev->r_wait,wait);//加读等待队列头到poll_table
poll_wait(filp,&dev->w_wait,wait);//加写等待队列头到poll_table
...
if(...)//可读
mask |= POLLIN | POLLRDNORM;
if(...)//可写
mask |= POLLOUT | POLLRDNORM;
...
return mask;
}
static unsigned int xxx_poll(struct file *filp,struct socket *sock,
poll_table *wait)
{
unsigned int mask = 0;
struct xxx_dev *dev = filp->private_data;//获得设备结构体指针
...
poll_wait(filp,&dev->r_wait,wait);//加读等待队列头到poll_table
poll_wait(filp,&dev->w_wait,wait);//加写等待队列头到poll_table
...
if(...)//可读
mask |= POLLIN | POLLRDNORM;
if(...)//可写
mask |= POLLOUT | POLLRDNORM;
...
return mask;
}三、支持轮询操作的globalfifo驱动
在globalfifo的poll()函数中,首先将设备结构体重的r_wait和w_wait等待队列头加到等待队列表,globalfifo设备驱动的poll()函数如下:
static unsigned int gloablfif0_poll(struct file *filp,poll_table *wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data;
down(&dev->sem);
poll_wait(filp,&dev->r_wait , wait) ;
poll_wait(filp,&dev->r_wait , wait) ;
if(dev->current_len != 0)
{
mask |= POLLIN | POLLRDNORM;
}
if(dev->current_len != GLOBALFIFO_SIZE)
{
mask |= POLLOUT | POLLWRNORM;
}
up(&dev->sem);
return mask;
}static unsigned int gloablfif0_poll(struct file *filp,poll_table *wait)
{
unsigned int mask = 0;
struct globalfifo_dev *dev = filp->private_data;
down(&dev->sem);
poll_wait(filp,&dev->r_wait , wait) ;
poll_wait(filp,&dev->r_wait , wait) ;
if(dev->current_len != 0)
{
mask |= POLLIN | POLLRDNORM;
}
if(dev->current_len != GLOBALFIFO_SIZE)
{
mask |= POLLOUT | POLLWRNORM;
}
up(&dev->sem);
return mask;
}四、总结
阻塞与非阻塞操作:
定义并初始化等待对列头;
定义并初始化等待队列;
把等待队列添加到等待队列头
设置进程状态(TASK_INTERRUPTIBLE(可以被信号打断)和TASK_UNINTERRUPTIBLE(不能被信号打断))
调用其它进程
poll机制:
把等待队列头加到poll_table
返回表示是否能对设备进行无阻塞读,写访问的掩码linux设备驱动中的阻塞与非阻塞
首先说说什么是阻塞和非阻塞的概念:阻塞操作就是指进程在操作设备时,由于不能获取资源或者暂时不能操作设备时,系统就会把进程挂起,被挂起的进程会进入休眠状态并且会从调度器的运行队列移走,放到等待队列中,然后一直休眠,直到该进程满足可操作的条件,再被唤醒,继续执行之前的操作。非阻塞操作的进程在不能进行设备操作时,并不会挂起,要么放弃,要么不停地执行,直到可以进行操作为止。
我们都知道,在应用中,打开一个设备文件时,指定了是以阻塞还是非阻塞打开(缺省是阻塞方式),然后后面的读写一切都是交由驱动来实现,那么驱动是如何实现read()和write()的阻塞呢!下面以读写一个内存块为例子,当该内存写满了,不能写的时候,调用write()函数该怎么处理,当该内存已经读取完了,空了的时候,调用read()函数,又改如何处理(该代码简化了,只为说明问题,不能正常编译使用):
wait_queue_head_t read_queue; //定义读等待队列头部
wait_queue_head_t write_queue; //定义写等待队列头部
struct semaphore sem; //定义信号量,用于互斥访问公共资源
static ssize_t mem_read(struct file *filp, char __user *buf, size_t size, loff_t *ppos)
{
if(down_interruptible(&sem))
return -ERESTARTSYS; //使用 down_interruptible,给公共资源上锁,以防出现并发引起的竞态问题
while (!have_data)
//have_data用来判断缓冲区中是否有数据,如果有数据,直接跳过该while语句,执行下面的
// copy_to_user
{
up(&sem); //由于没有数据,不能进行读取数据操作,要释放锁,解锁,这里的解锁很重要,要是没有解锁,很容 //易进入死锁,具体怎样,下面再分析
if(filp->f_flags & O_NONBLOCK) //判断该文件时以阻塞方式还是非阻塞方式打开
return -EAGAIN; //由于是非阻塞打开,直接返回
wait_event_interruptible(read_queue,have_date);//阻塞方式代开,该语句会让进程进入休眠状态,然后等待其他进程
//的唤醒并且have_data=true时,才会被完全唤醒,执行下面的语句
if(down_interruptible(&sem)) //由于可以进行读取了,所以在此给公共资源上锁
return -ERESTARTSYS;
if (copy_to_user(buf, (void*)(dev->data + p), count)) { //实现数据从内核空间读取到用户空间,完成读取操作
..................
}
have_data = false; //标记该数据已经读取完毕
up(&sem); //释放锁
wake_up(&write_queue); //读取完毕,缓冲区有空间可以写入了,就唤醒写进程,让写进程把数据写入
return ;
}
下面分析write函数,其原理和实现也是和read函数一样,都是先给公共资源上锁,再判断是阻塞访问还是非阻塞访问,如果是非阻塞访问,且资源不能获取时,直接返回,若果时阻塞且不能获取资源时,就进入休眠,等待其他进程的唤醒。
static ssize_t mem_write(struct file *filp, char __user *buf, size_t size, loff_t *ppos)
{
if(down_interruptible(&sem))
return -ERESTARTSYS; //使用 down_interruptible,给公共资源上锁,以防出现并发引起的竞态问题
while (have_data) //have_data用来判断缓冲区中是否有数据,如果有数据,表示缓冲区已经满了,不能写入,
//如果have_data是false,即没有数据,缓冲区是空的,可以写入数据,就执行下面的copy_from_user
{
up(&sem); //由于有数据,不能进行写入数据操作,要释放锁,解锁 if(filp->f_flags & O_NONBLOCK) //判断该文件时以阻塞方式还是非阻塞方式打开
return -EAGAIN; //由于是非阻塞打开,直接返回
wait_event_interruptible(write_queue,!have_date);//阻塞方式代开,该语句会让进程进入休眠状态,然后等待其他进程
//的唤醒并且have_data=false时,才会被完全唤醒,执行下面的语句
if(down_interruptible(&sem)) //由于可以进行写入操作了,所以在此给公共资源上锁
return -ERESTARTSYS;
if (copy_from_user((dev->data + p), buf,count)) { //实现数据从内核空间读取到用户空间,完成读取操作
..................
}
have_data = true; //标记该数据已经读取完毕
up(&sem); //释放锁
wake_up(&read_queue); //写入数据完毕,缓冲区有数据可以读取了,就唤醒读进程,让读进程开始读取数据
return ;
}
以上是驱动中的读取和写入操作,当写进程发现数据已满,不能写入时,且上层应用是以阻塞的方式打开设备文件时,所以必须要写入数据才能返回,否则不能返回,那么就有两种实现机制,要不就是不停地忙等待,等待设备可以写入时,便写入,然后返回,可是这样做的话,非常影响CPU的执行效率,大大降低了CPU的性能,所以linux内核中采取了等待队列的实现方式,就是当一个阻塞进程写入数据时,发现不能写入时,会把这个进程挂起,放到等待队列中休眠,然后一直在休眠,直到有个读进程,把缓冲区的数据读取完毕后,然后读进程会把写进程唤醒,告诉写进程缓冲区可以写入数据了,于是写进程继续写入操作,并且返回。举个例子,小明饿了,要吃饭,于是跑去妈妈那里,说要吃饭,妈妈说放没有做好,你说小明是继续在这里一直等着妈妈把饭做好,还是先去睡一觉好呢,如果我是小明,我就先去睡一觉,然后妈妈把饭做好了,就把小明叫醒,小明,可以吃饭了,于是小明起来,跑去吃饭。当读进程阻塞时,也是这样,就不分析了。
现在说说为什么每次进去阻塞前都要把锁释放掉,然后唤醒时再次上锁,我们试想一下,假如读进程发现缓冲区为空,不能读取时,准备进入休眠了,没有把锁释放,效果会怎样,就相当于读进程带着锁睡着了,一旦读进程带着锁睡着了,写进程来了,可是写进程因为不能获取锁,就不能访问临界区的资源,更不能往缓冲区里面写入数据,所以缓冲区会一直为空,且写进程也会不停地在那里休眠,等到读进程释放锁,可是读进程睡着了,不能释放锁,写进程也休眠了,不能唤醒读进程,于是就发生了死锁了。这就好比小明他爸爸藏了一个还魂丹在保险箱里,有一天,他爸爸晕倒了,可是没有告诉小明锁放在那里,于是小明只能在保险箱外面,看着他爸爸晕过去,却无能为力了.....
阻塞和非阻塞
阻塞函数在完成其指定的任务以前不允许程序调用另一个函数。例如,程序执行一个读数据的函数调用时,在此函数完成读操作以前将不会执行下一程序语句。当服务器运行到accept语句时,而没有客户连接服务请求到来,服务器就会停止在accept语句上等待连接服务请求的到来。这种情况称为阻塞(blocking)。而非阻塞操作则可以立即完成。比如,如果你希望服务器仅仅注意检查是否有客户在等待连接,有就接受连接,否则就继续做其他事情,则可以通过将Socket设置为非阻塞方式来实现。非阻塞socket在没有客户在等待时就使accept调用立即返回。
#include
#include
……
sockfd = socket(AF_INET,SOCK_STREAM,0);
fcntl(sockfd,F_SETFL,O_NONBLOCK);
……
通过设置socket为非阻塞方式,可以实现"轮询"若干Socket。当企图从一个没有数据等待处理的非阻塞Socket读入数据时,函数将立即返回,返回值为-1,并置errno值为EWOULDBLOCK。但是这种"轮询"会使CPU处于忙等待方式,从而降低性能,浪费系统资源。而调用select()会有效地解决这个问题,它允许你把进程本身挂起来,而同时使系统内核监听所要求的一组文件描述符的任何活动,只要确认在任何被监控的文件描述符上出现活动,select()调用将返回指示该文件描述符已准备好的信息,从而实现了为进程选出随机的变化,而不必由进程本身对输入进行测试而浪费CPU开销。Select函数原型为:
int select(int numfds,fd_set *readfds,fd_set *writefds,
fd_set *exceptfds,struct timeval *timeout);
其中readfds、writefds、exceptfds分别是被select()监视的读、写和异常处理的文件描述符集合。如果你希望确定是否可以从标准输入和某个socket描述符读取数据,你只需要将标准输入的文件描述符0和相应的sockdtfd加入到readfds集合中;numfds的值是需要检查的号码最高的文件描述符加1,这个例子中numfds的值应为sockfd+1;当select返回时,readfds将被修改,指示某个文件描述符已经准备被读取,你可以通过FD_ISSSET()来测试。为了实现fd_set中对应的文件描述符的设置、复位和测试,它提供了一组宏:
FD_ZERO(fd_set *set)----清除一个文件描述符集;
FD_SET(int fd,fd_set *set)----将一个文件描述符加入文件描述符集中;
FD_CLR(int fd,fd_set *set)----将一个文件描述符从文件描述符集中清除;
FD_ISSET(int fd,fd_set *set)----试判断是否文件描述符被置位。
Timeout参数是一个指向struct timeval类型的指针,它可以使select()在等待timeout长时间后没有文件描述符准备好即返回。struct timeval数据结构为:
struct timeval {
int tv_sec; /* seconds */
int tv_usec; /* microseconds */
};
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
怎样能使accept函数立即返回?
可以使用ioctlsocket。
用 selece,如果返回侦听套接字可读,说明有连接请求要处理
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
关于socket的阻塞与非阻塞模式以及它们之间的优缺点,这已经没什么可言的;我打个很简单的比方,如果你调用socket send函数时;
如果是阻塞模式下:
send先比较待发送数据的长度len和套接字s的发送缓冲的长度,如果len大于s的发送缓冲区的长度,该函数返回SOCKET_ERROR;如果len小于或者等于s的发送缓冲区的长度,那么send先检查协议是否正在发送s的发送缓冲中的数据,如果是就等待协议把数据发送完,如果协议还没有开始发送s的发送缓冲中的数据或者s的发送缓冲中没有数据,那么
send就比较s的发送缓冲区的剩余空间和len,如果len大于剩余空间大小,send就一直等待协议把s的发送缓冲中的数据发送完,如果len小于剩余空间大小send就仅仅把buf中的数据copy到剩余空间里
如果是非阻塞模式下:
在调用socket
send函数时,如果能写到socket缓冲区时,就写数据并返回实际写的字节数目,当然这个返回的实际值可能比你所要写的数据长度要小些(On
nonblocking stream oriented sockets, the number of bytes written can be
between 1 and the requested length, depending on buffer availability on
both the client and server
computers),如果不可写的话,就直接返回SOCKET_ERROR了,所以没有等待的过程。。
经过上面的介绍后,下面介绍如何设置socket的非阻塞模式:
http://www.cnblogs.com/dawen/archive/2011/05/18/2050330.html
////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////////
非阻塞recvfrom的设置
int iMode = 1; //0:阻塞
ioctlsocket(socketc,FIONBIO, (u_long FAR*) &iMode);//非阻塞设置
rs=recvfrom(socketc,rbuf,sizeof(rbuf),0,(SOCKADDR*)&addr,&len);
int ioctlsocket (
SOCKET s,
long cmd,
u_long FAR* argp
);
- s
- [in] A descriptor identifying a socket.
- cmd
- [in] The command to perform on the socket s.
- argp
- [in/out] A pointer to a parameter for cmd.
不知道大家有没有遇到过这种情况,当socket进行TCP连接的时候(也就是调用connect时),一旦网络不通,或者是ip地址无效,就可能使整个线程阻塞。一般为30秒(我测的是20秒)。如果设置为非阻塞模式,能很好的解决这个问题,我们可以这样来设置非阻塞模式:调用ioctlsocket函数:
unsigned long flag=1;
if (ioctlsocket(sock,FIONBIO,&flag)!=0)
{
closesocket(sock);
return false;
}
以下是对ioctlsocket函数的相关解释:
int PASCAL FAR ioctlsocket( SOCKET s, long cmd, u_long FAR* argp);
s:一个标识套接口的描述字。
cmd:对套接口s的操作命令。
argp:指向cmd命令所带参数的指针。
注释:
本函数可用于任一状态的任一套接口。它用于获取与套接口相关的操作参数,而与具体协议或通讯子系统无关。支持下列命令:
FIONBIO:允许或禁止套接口s的非阻塞模式。argp指向一个无符号长整型。如允许非阻塞模式则非零,如禁止非阻塞模式则为零。当创建一个套接口时,它就处于阻塞模式(也就是说非阻塞模式被禁止)。这与BSD套接口是一致的。WSAAsynSelect()函数将套接口自动设置为非阻塞模式。如果已对一个套接口进行了WSAAsynSelect()
操作,则任何用ioctlsocket()来把套接口重新设置成阻塞模式的试图将以WSAEINVAL失败。为了把套接口重新设置成阻塞模式,应用程序必须首先用WSAAsynSelect()调用(IEvent参数置为0)来禁至WSAAsynSelect()。
FIONREAD:确定套接口s自动读入的数据量。argp指向一个无符号长整型,其中存有ioctlsocket()的返回值。如果s是SOCKET_STREAM类型,则FIONREAD返回在一次recv()中所接收的所有数据量。这通常与套接口中排队的数据总量相同。如果S是SOCK_DGRAM
型,则FIONREAD返回套接口上排队的第一个数据报大小。
SIOCATMARK:确实是否所有的带外数据都已被读入。这个命令仅适用于SOCK_STREAM类型的套接口,且该套接口已被设置为可以在线接收带外数据(SO_OOBINLINE)。如无带外数据等待读入,则该操作返回TRUE真。否则的话返回FALSE假,下一个recv()或recvfrom()操作将检索“标记”前一些或所有数据。应用程序可用SIOCATMARK操作来确定是否有数据剩下。如果在“紧急”(带外)数据前有常规数据,则按序接收这些数据(请注意,recv()和recvfrom()操作不会在一次调用中混淆常规数据与带外数据)。argp指向一个BOOL型数,ioctlsocket()在其中存入返回值。
此时已经设置非阻塞模式,但是并没有设置connect的连接时间,我们可以通过调用select语句来实现这个功能。以下代码设定了是连接时间为5秒,如果还未能连上,则直接返回。
struct timeval timeout ;
fd_set r;
int ret;
connect( sock, (LPSOCKADDR)sockAddr, sockAddr.Size());
FD_ZERO(&r);
FD_SET(sock,&r);
timeout.tv_sec = 5;
timeout.tv_usec =0;
ret = select(0,0,&r,0,&timeout);
if ( ret <= 0 )
{
closesocket(sock);
return false;
}
以下是对select函数的解释:
int select (
int nfds,
fd_set FAR * readfds,
fd_set FAR * writefds,
fd_set FAR * exceptfds,
const struct timeval FAR * timeout
);
第一个参数nfds沒有用,仅仅为与伯克利Socket兼容而提供。
readfds指定一個Socket数组(应该是一个,但这里主要是表现为一个Socket数组),select检查该数组中的所有Socket。如果成功返回,则readfds中存放的是符合‘可读性’条件的数组成员(如缓冲区中有可读的数据)。
writefds指定一个Socket数组,select检查该数组中的所有Socket。如果成功返回,则writefds中存放的是符合‘可写性’条件的数组成员(如连接成功)。
exceptfds指定一个Socket数组,select检查该数组中的所有Socket。如果成功返回,则cxceptfds中存放的是符合‘有异常’条件的数组成员(如连接接失败)。
timeout指定select执行的最长时间,如果在timeout限定的时间内,readfds、writefds、exceptfds中指定的Socket沒有一个符合要求,就返回0。
如果对 Connect
进行非阻塞调用,则可读意味着已经成功连接,连接不成功则不可读。所以通过这样的设定,我们就能够实现对connect连接时间的修改。但是,应该注意,这样的设置并不能保证在限定时间内连接不上就说明网络不通。比如我们设的时间是5秒,但是由于种种原因,可能第6秒就能连接上,但是函数在5秒后就返回了。
- 本节目标:
- 学习原子操作和互斥信号量,实现互斥机制,同一时刻只能一个应用程序使用驱动程序
- 学习阻塞和非阻塞操作
当设备被一个程序打开时,存在被另一个程序打开的可能,如果两个或多个程序同时对设备文件进行写操作,这就是说我们的设备资源同时被多个进程使用,对共享资源(硬件资源、和软件上的全局变量、静态变量等)的访问则很容易导致竞态。
显然这不是我们想要的,所以本节引入互斥的概念:实现同一时刻,只能一个应用程序使用驱动程序
互斥其实现很简单,就是采用一些标志,当文件被一个进程打开后,就会设置该标志,使其他进程无法打开设备文件。
1.其中的标志需要使用函数来操作,不能直接通过判断变量来操作标志
比如:
if (-- canopen != ) //当canopen==0,表示没有进程访问驱动,当canopen<0:表示有进程访问
编译汇编来看,分了3段: 读值、减1、判断
如果刚好在读值的时候发生了中断,有另一个进程访问时,那么也会访问成功,也会容易导致访问竞态。
1.1所以采用某种函数来实现,保证执行过程不被其他行为打断,有两种类型函数可以实现:
原子操作(像原子一样不可再细分不可被中途打断)
当多个进程同时访问同一个驱动时,只能有一个进程访问成功,其它进程会退出
互斥信号量操作
比如:A、B进程同时访问同一个驱动时,只有A进程访问成功了,B进程进入休眠等待状态,当A进程执行完毕释放后,等待状态的B进程又来访问,保证一个一个进程都能访问
2. 原子操作详解
原子操作指的是在执行过程中不会被别的代码路径所中断的操作。
原子操作函数如下:
)atomic_t v = ATOMIC_INIT(); //定义原子变量v并初始化为0 )atomic_read(atomic_t *v); //返回原子变量的值 )void atomic_inc(atomic_t *v); //原子变量增加1 )void atomic_dec(atomic_t *v); //原子变量减少1 )int atomic_dec_and_test(atomic_t *v); //自减操作后测试其是否为0,为0则返回true,否则返回false。
2.1修改驱动程序
定义原子变量:
/*定义原子变量canopen并初始化为1 */
atomic_t canopen = ATOMIC_INIT();
在.open成员函数里添加:
/*自减操作后测试其是否为0,为0则返回true,否则返回false */
if(!atomic_dec_and_test(&canopen))
{
atomic_inc(&canopen); //++,复位
return -;
}
在. release成员函数里添加:
atomic_inc(&canopen); //++,复位
2.2修改测试程序:
int main(int argc,char **argv)
{
int oflag;
unsigned int val=;
fd=open("/dev/buttons",O_RDWR);
if(fd<)
{printf("can't open, fd=%d\n",fd);
return -;}
while()
{
read( fd, &ret, ); //读取驱动层数据
printf("key_vale=0X%x\r\n",ret);
} return ; }
2.3 测试效果
如下图,可以看到第一个进程访问驱动成功,后面的就再也不能访问成功了

3.互斥信号量详解
互斥信号量(semaphore)是用于保护临界区的一种常用方法,只有得到信号量的进程才能执行临界区代码。
当获取不到信号量时,进程进入休眠等待状态。
信号量函数如下:
/*注意: 在2.6.36版本后这个函数DECLARE_MUTEX修改成DEFINE_SEMAPHORE了*/
)static DECLARE_MUTEX(button_lock); //定义互斥锁button_lock,被用来后面的down和up用
)void down(struct semaphore * sem); // 获取不到就进入不被中断的休眠状态(down函数中睡眠)
)int down_interruptible(struct semaphore * sem); //获取不到就进入可被中断的休眠状态(down函数中睡眠)
)int down_trylock(struct semaphore * sem); //试图获取信号量,获取不到则立刻返回正数
)void up(struct semaphore * sem); //释放信号量
3.1修改驱动程序(以down函数获取为例)
(1)定义互斥锁变量:
/*定义互斥锁button_lock,被用来后面的down()和up()使用 */
static DECLARE_MUTEX(button_lock);
(2)在.open成员函数里添加:
/* 获取不到就进入不被中断的休眠状态(down函数中睡眠) */
down(&button_lock);
(3)在. release成员函数里添加:
/* 释放信号量 */
up(&button_lock);
3.2修改测试程序:
int main(int argc,char **argv)
{
int oflag;
unsigned int val=;
fd=open("/dev/buttons",O_RDWR);
if(fd<)
{printf("can't open, fd=%d\n",fd);
return -;}
else
{
printf("can open,PID=%d\n",getpid()); //打开成功,打印pid进程号
}
while()
{
read( fd, &ret, ); //读取驱动层数据
printf("key_vale=0X%x\r\n",ret);
}
return ;
}
3.3 测试效果
如下图所示,3个进程同时访问时,只有一个进程访问成功,其它2个进程进入休眠等待状态

如下图所示,多个信号量访问时, 会一个一个进程来排序访问

4.阻塞与非阻塞
4.1阻塞操作
进程进行设备操作时,使用down()函数,若获取不到资源则挂起进程,将被挂起的进程进入休眠状态,被从调度器的运行队列移走,直到等待的条件被满足。
在read读取按键时, 一直等待按键按下才返回数据
4.2非阻塞操作
进程进行设备操作时,使用down_trylock()函数,若获取不到资源并不挂起,直接放弃。
在read读取按键时, 不管有没有数据都要返回
4.3 怎么来判断阻塞与非阻塞操作?
在用户层open时,默认为阻塞操作,如果添加了” O_NONBLOCK”,表示使open()、read()、write()不被阻塞
实例:
fd=open("/dev/buttons",O_RDWR); //使用阻塞操作
fd = open("/dev/buttons ", O_RDWR | O_NONBLOCK); //使用非阻塞操作
然后在驱动设备中,通过file_operations成员函数.open、.read、.write带的参数file->f_flags 来查看用户层访问时带的参数
实例:
if( file->f_flags & O_NONBLOCK ) //非阻塞操作,获取不到则退出
{
... ...
}
else //阻塞操作,获取不到则进入休眠
{
... ...
}
4.4修改应用程序,通过判断file->f_flags来使用阻塞操作还是非阻塞操作
(1)定义互斥锁变量:
/*定义互斥锁button_lock,被用来后面的down()和up()使用 */
static DECLARE_MUTEX(button_lock);
(2)在.open成员函数里添加:
if( file->f_flags & O_NONBLOCK ) //非阻塞操作
{
if(down_trylock(&button_lock) ) //尝试获取信号量,获取不到则退出
return -;
}
else //阻塞操作
{
down(&button_lock); //获取信号量,获取不到则进入休眠
}
(3)在. release成员函数里添加:
/*释放信号量*/
up(&button_lock);
4.5 写阻塞测试程序 fifth_blocktext.c
代码如下:
int main(int argc,char **argv)
{
int oflag;
unsigned int val=;
fd=open("/dev/buttons",O_RDWR); //使用阻塞操作
if(fd<)
{printf("can't open, fd=%d\n",fd);
return -;}
else
{
printf("can open,PID=%d\n",getpid()); //打开成功,打印pid进程号
} while()
{
val=read( fd, &ret, ); //读取驱动层数据
printf("key_vale=0X%x,retrun=%d\r\n",ret,val);
}
return ; }
4.6 非阻塞测试效果
如下图所示:

4.7写阻塞测试程序 fifth_nonblock.c
代码如下:
int main(int argc,char **argv)
{
int oflag;
unsigned int val=;
fd=open("/dev/buttons",O_RDWR | O_NONBLOCK); //使用非阻塞操作
if(fd<)
{printf("can't open, fd=%d\n",fd);
return -;}
else
{
printf("can open,PID=%d\n",getpid()); //打开成功,打印pid进程号
}
while()
{
val=read( fd, &ret, ); //读取驱动层数据
printf("key_vale=0X%x,retrun=%d\r\n",ret,val);
sleep(); //延时3S
}
return ;
}
4.8 阻塞测试效果
如下图所示:

本节目标:
分析在linux中的中断是如何运行的,以及中断3大结构体:irq_desc、irq_chip、irqaction
在裸板程序中(参考stmdb和ldmia详解):
1.按键按下,
2.cpu发生中断,
3.强制跳到异常向量入口执行(0x18中断地址处)
3.1使用stmdb将寄存器值保存在栈顶(保护现场)
stmdb sp!, { r0-r12,lr }
3.2执行中断服务函数
3.3 使用ldmia将栈顶处数据读出到寄存器中,并使pc=lr(恢复现场)
ldmia sp!, { r0-r12,pc }^
//^表示将spsr的值复制到cpsr,因为异常返回后需要恢复异常发生前的工作状态
在linux中:
需要先设置异常向量地址(参考linux应用手册P412):
在ARM裸板中异常向量基地址是0x00000000,如下图:
而linux内核中异常向量基地址是0xffff0000(虚拟地址),
位于代码arch/cam/kernel/traps.c,代码如下:
void __init trap_init(void)
{
/* CONFIG_VECTORS_BASE :内核配置项,在.config文件中,设置的是0Xffff0000*/
/* vectors =0xffff0000*/
unsigned long vectors = CONFIG_VECTORS_BASE;
... ...
/*将异常向量地址复制到0xffff0000处*/
memcpy((void *)vectors, __vectors_start, __vectors_end - __vectors_start);
memcpy((void *)vectors + 0x200, __stubs_start, __stubs_end - __stubs_start);
memcpy((void *)vectors + 0x1000 - kuser_sz, __kuser_helper_start, kuser_sz); ... ...
}
上面代码中主要是将__vectors_end - __vectors_start之间的代码复制到vectors (0xffff0000)处,
__vectors_start为什么是异常向量基地址?
通过搜索,找到它在arch/arm/kernel/entry_armv.S中定义:
__vectors_start:
swi SYS_ERROR0 //复位异常,复位时会执行
b vector_und + stubs_offset //undefine未定义指令异常
ldr pc, .LCvswi + stubs_offset //swi软件中断异常
b vector_pabt + stubs_offset //指令预取中止abort
b vector_dabt + stubs_offset //数据访问中止abort
b vector_addrexcptn + stubs_offset //没有用到
b vector_irq + stubs_offset //irq异常
b vector_fiq + stubs_offset //fig异常
其中stubs_offset是链接地址的偏移地址, vector_und、vector_pabt等表示要跳转去执行的代码
1.以vector_irq中断为例, vector_irq是个宏,它在哪里定义呢?
它还是在arch/arm/kernel/entry_armv.S中定义,如下所示:
vector_stub irq, IRQ_MODE, //irq:名字 IRQ_MODE:0X12 4:偏移量
上面的vector_stub 根据参数irq, IRQ_MODE, 4来定义” vector_ irq”这个宏(其它宏也是这样定义的)
2.vector_stub又是怎么实现出来的定义不同的宏呢?
我们找到vector_stub这个定义:
.macro vector_stub, name, mode, correction= //定义vector_stub有3个参数
.align
vector_\name: //定义不同的宏,比如vector_ irq
.if \correction //判断correction参数是否为0
sub lr, lr, #\correction //计算返回地址
.endif
@
@ Save r0, lr_<exception> (parent PC) and spsr_<exception>
@ (parent CPSR)
@
stmia sp, {r0, lr} @ save r0, lr
mrs lr, spsr //读出spsr
str lr, [sp, #] @ save spsr @
@ Prepare for SVC32 mode. IRQs remain disabled.
@ 进入管理模式
mrs r0, cpsr //读出cpsr
eor r0, r0, #(\mode ^ SVC_MODE)
msr spsr_cxsf, r0 @
@ the branch table must immediately follow this code
@
and lr, lr, #0x0f //lr等于进入模式之前的spsr,&0X0F就等于模式位
mov r0, sp
ldr lr, [pc, lr, lsl #]
movs pc, lr @ branch to handler in SVC mode
3.因此我们将上面__vectors_start里的b vector_irq + stubs_offset 中断展开如下:
.macro vector_stub, name, mode, correction= //定义vector_stub有3个参数
.align
vector_stub irq, IRQ_MODE, //这三个参数值代入 vector_stub中 vector_ irq: //定义 vector_ irq
/*计算返回地址(在arm流水线中,lr=pc+8,但是pc+4只译码没有执行,所以lr=lr-4) */
sub lr, lr, # @
@ Save r0, lr_<exception> (parent PC) and spsr_<exception>
@ (parent CPSR)
@保存r0和lr和spsr
stmia sp, {r0, lr} //存入sp栈里
mrs lr, spsr //读出spsr
str lr, [sp, #] @ save spsr @
@ Prepare for SVC32 mode. IRQs remain disabled.
@ 进入管理模式
mrs r0, cpsr //读出cpsr
eor r0, r0, #(\mode ^ SVC_MODE)
msr spsr_cxsf, r0 @
@ the branch table must immediately follow this code
@
and lr, lr, #0x0f //lr等于进入模式之前的spsr,&0X0F就等于模式位
mov r0, sp
ldr lr, [pc, lr, lsl #] //如果进入中断前是usr,则取出PC+4*0的内容,即__irq_usr @如果进入中断前是svc,则取出PC+4*3的内容,即__irq_svc movs pc, lr //跳转到下面某处,且目标寄存器是pc,指令S结尾,最后会恢复cpsr. .long __irq_usr @ (USR_26 / USR_32)
.long __irq_invalid @ (FIQ_26 / FIQ_32)
.long __irq_invalid @ (IRQ_26 / IRQ_32)
.long __irq_svc @ (SVC_26 / SVC_32)
.long __irq_invalid @
.long __irq_invalid @
.long __irq_invalid @
.long __irq_invalid @
.long __irq_invalid @
.long __irq_invalid @
.long __irq_invalid @ a
.long __irq_invalid @ b
.long __irq_invalid @ c
.long __irq_invalid @ d
.long __irq_invalid @ e
.long __irq_invalid @ f
从上面代码中的注释可以看出:
- 1).将发生异常前的各个寄存器值保存在SP栈里,若是中断异常,则PC=PC-4,也就是CPU下个要运行的位置处
- 2).然后根据进入中断前的工作模式不同,程序下一步将跳转到_irq_usr 、或__irq_svc等位置。
4.我们先选择__irq_usr作为下一步跟踪的目标:
4.1其中__irq_usr的实现如下(arch\arm\kernel\entry-armv.S):
__irq_usr:
usr_entry //保存数据到栈里
get_thread_info tsk
irq_handler //调用irq_handler
b ret_to_user
4.2.irq_handler的实现过程,arch\arm\kernel\entry-armv.S
.macro irq_handler
get_irqnr_preamble r5, lr
get_irqnr_and_base r0, r6, r5, lr // get_irqnr_and_base:获取中断号,r0=中断号
movne r1, sp //r1等于sp (发生中断之前的各个寄存器的基地址)
adrne lr, 1b
bne asm_do_IRQ //调用asm_do_IRQ, irq=r0 regs=r1
irq_handler最终调用asm_do_IRQ
4.3 asm_do_IRQ实现过程,arch/arm/kernel/irq.c
该函数和裸板中断处理一样的,完成3件事情:
1).分辨是哪个中断;
2).通过desc_handle_irq(irq, desc)调用对应的中断处理函数;
3).清中断
asmlinkage void __exception asm_do_IRQ(unsigned int irq, struct pt_regs *regs) //irq:中断号 *regs:发生中断前的各个寄存器基地址
{
struct pt_regs *old_regs = set_irq_regs(regs);
/*根据irq中断号,找到哪个中断, *desc =irq_desc[irq]*/
struct irq_desc *desc = irq_desc + irq; // irq_desc是个数组(位于kernel/irq/handle.c) if (irq >= NR_IRQS)
desc = &bad_irq_desc; irq_enter();
desc_handle_irq(irq, desc); // desc_handle_irq根据中断号和desc,调用函数指针,进入中断处理, irq_finish(irq);
irq_exit();
set_irq_regs(old_regs); }
上面主要是执行desc_handle_irq函数进入中断处理
其中desc_handle_irq代码如下:
desc->handle_irq(irq, desc);//相当于执行irq_desc[irq]-> handle_irq(irq, irq_desc[irq]);
它会执行handle_irq成员函数,这个成员handle_irq又是在哪里被赋值的?
搜索handle_irq,找到它位于kernel/irq/chip.c,__set_irq_handler函数下:
void __set_irq_handler(unsigned int irq, irq_flow_handler_t handle, int is_chained,const char *name)
{
... ...
desc = irq_desc + irq; //在irq_desc结构体数组中找到对应的中断
... ...
desc->handle_irq = handle; //使handle_irq成员指向handle参数函数
}
继续搜索__set_irq_handler函数,它被set_irq_handler函数调用:
static inline void set_irq_handler(unsigned int irq, irq_flow_handler_t handle)
{
__set_irq_handler(irq, handle, , NULL);
}
继续搜索set_irq_handler函数,如下图

发现它在s3c24xx_init_irq(void)函数中被多次使用,显然在中断初始化时,多次进入__set_irq_handler函数,并在irq_desc数组中构造了很多项 handle_irq函数
我们来看看irq_desc中断描述结构体到底有什么内容:
struct irq_desc {
irq_flow_handler_t handle_irq; //指向中断函数, 中断产生后,就会执行这个handle_irq
struct irq_chip *chip; //指向irq_chip结构体,用于底层的硬件访问,下面会介绍
struct msi_desc *msi_desc;
void *handler_data;
void *chip_data;
struct irqaction *action; /* IRQ action list */ //action链表,用于中断处理函数
unsigned int status; /* IRQ status */
unsigned int depth; /* nested irq disables */
unsigned int wake_depth; /* nested wake enables */
unsigned int irq_count; /* For detecting broken IRQs */
unsigned int irqs_unhandled;
spinlock_t lock;
... ...
const char *name; //产生中断的硬件名字
} ;
其中的成员*chip的结构体,用于底层的硬件访问, irq_chip类型如下:
struct irq_chip {
const char *name;
unsigned int (*startup)(unsigned int irq); //启动中断
void (*shutdown)(unsigned int irq); //关闭中断
void (*enable)(unsigned int irq); //使能中断
void (*disable)(unsigned int irq); //禁止中断
void (*ack)(unsigned int irq); //响应中断,就是清除当前中断使得可以再接收下个中断
void (*mask)(unsigned int irq); //屏蔽中断源
void (*mask_ack)(unsigned int irq); //屏蔽和响应中断
void (*unmask)(unsigned int irq); //开启中断源
... ...
int (*set_type)(unsigned int irq, unsigned int flow_type); //将对应的引脚设置为中断类型的引脚
... ...
#ifdef CONFIG_IRQ_RELEASE_METHOD
void (*release)(unsigned int irq, void *dev_id); //释放中断服务函数
#endif
};
其中的成员struct irqaction *action,主要是用来存用户注册的中断处理函数,
一个中断可以有多个处理函数 ,当一个中断有多个处理函数,说明这个是共享中断.
所谓共享中断就是一个中断的来源有很多,这些来源共享同一个引脚。
所以在irq_desc结构体中的action成员是个链表,以action为表头,若是一个以上的链表就是共享中断
irqaction结构定义如下:
struct irqaction {
irq_handler_t handler; //等于用户注册的中断处理函数,中断发生时就会运行这个中断处理函数
unsigned long flags; //中断标志,注册时设置,比如上升沿中断,下降沿中断等
cpumask_t mask; //中断掩码
const char *name; //中断名称,产生中断的硬件的名字
void *dev_id; //设备id
struct irqaction *next; //指向下一个成员
int irq; //中断号,
struct proc_dir_entry *dir; //指向IRQn相关的/proc/irq/
};
上面3个结构体的关系如下图所示:
我们来看看s3c24xx_init_irq()函数是怎么初始化中断的,以外部中断0为例(位于s3c24xx_init_irq函数):
s3c24xx_init_irq()函数中部分代码如下:
/*其中IRQ_EINT0=16, 所以irqno=16 */
for (irqno = IRQ_EINT0; irqno <= IRQ_EINT3; irqno++)
{
irqdbf("registering irq %d (ext int)\n", irqno);
/*在set_irq_chip函数中会执行:
desc = irq_desc + irq;
desc->chip = chip;*/
set_irq_chip(irqno, &s3c_irq_eint0t4); //所以(irq_desc+16)->chip= &s3c_irq_eint0t4 /* set_irq_handler 会调用__set_irq_handler 函数*/
set_irq_handler(irqno, handle_edge_irq); //所以(irq_desc+16)-> handle_irq = handle_edge_irq set_irq_flags(irqno, IRQF_VALID);
}
初始化了外部中断0后,当外部中断0触发,就会进入我们之前分析的asm_do_IRQ函数中,调用(irq_desc+16)-> handle_irq也就是handle_edge_irq函数。
我们来分析下handle_edge_irq函数是如何执行中断服务的:
void fastcall handle_edge_irq(unsigned int irq, struct irq_desc *desc)
{
const unsigned int cpu = smp_processor_id();
spin_lock(&desc->lock);
desc->status &= ~(IRQ_REPLAY | IRQ_WAITING); /*判断这个中断是否正在运行(INPROGRESS)或者禁止(DISABLED)*/
if (unlikely((desc->status & (IRQ_INPROGRESS | IRQ_DISABLED)) || !desc->action))
{
desc->status |= (IRQ_PENDING | IRQ_MASKED);
mask_ack_irq(desc, irq); //屏蔽中断
goto out_unlock;
} kstat_cpu(cpu).irqs[irq]++; //计数中断次数
/* Start handling the irq */
desc->chip->ack(irq); //开始处理这个中断 /* Mark the IRQ currently in progress.*/
desc->status |= IRQ_INPROGRESS; //标记当前中断正在运行 do {
struct irqaction *action = desc->action;
irqreturn_t action_ret; if (unlikely(!action)) { //判断链表是否为空
desc->chip->mask(irq);
goto out_unlock;
} if (unlikely((desc->status &
(IRQ_PENDING | IRQ_MASKED | IRQ_DISABLED)) ==
(IRQ_PENDING | IRQ_MASKED))) {
desc->chip->unmask(irq);
desc->status &= ~IRQ_MASKED;
} desc->status &= ~IRQ_PENDING;
spin_unlock(&desc->lock);
action_ret = handle_IRQ_event(irq, action); //真正的处理过程
if (!noirqdebug)
note_interrupt(irq, desc, action_ret);
spin_lock(&desc->lock); } while ((desc->status & (IRQ_PENDING | IRQ_DISABLED)) == IRQ_PENDING); desc->status &= ~IRQ_INPROGRESS; out_unlock:
spin_unlock(&desc->lock); }
上面handle_edge_irq()函数主要执行了:
1. desc->chip->ack(irq); //开始处理这个中断
在s3c24xx_init_irq()函数中chip成员指向了s3c_irq_eint0t4(),
所以desc->chip->ack(irq)就是执行handle_edge_irq(irq)函数,handle_edge_irq函数如下:
s3c_irq_ack(unsigned int irqno)
{
unsigned long bitval = 1UL << (irqno - IRQ_EINT0);
__raw_writel(bitval, S3C2410_SRCPND); //向SRCPND寄存器写入bitval ,清SRCPND中断
__raw_writel(bitval, S3C2410_INTPND); //向INTPND寄存器位写入bitval ,清INTPND中断
}
所以desc->chip->ack(irq); 主要执行清中断之类的
2.handle_IRQ_event(irq, action); //真正的处理过程
handle_IRQ_event()代码如下:
handle_IRQ_event(unsigned int irq, struct irqaction *action)
{
irqreturn_t ret, retval = IRQ_NONE;
unsigned int status = ;
handle_dynamic_tick(action);
if (!(action->flags & IRQF_DISABLED))
local_irq_enable_in_hardirq();
do {
ret = action->handler(irq, action->dev_id); //执行action->handler
if (ret == IRQ_HANDLED)
status |= action->flags;
retval |= ret;
action = action->next; //指向下个action成员
} while (action); //取出action所有成员 if (status & IRQF_SAMPLE_RANDOM)
add_interrupt_randomness(irq);
local_irq_disable();
return retval; }
所以handle_IRQ_event()函数主要是取出action链表中的成员,然后执行irq_desc->action->handler(irq, action->dev_id);
action链表是irq_desc中断描述符结构体的 成员
本节常用函数总结:
trap_init(): 初始化异常向量的虚拟基地址,一般为0XFFFF0000
s3c24xx_init_irq():初始化各个中断
set_irq_chip(irqno, &s3c_irq_eint0t4):设置irq_desc[irqno]->chip等于第二个参数
set_irq_handler(irqno, handle_edge_irq); 设置irq_desc[irqno]->handle_irq等于第二个参数
asm_do_IRQ():中断产生后,会进入这个函数,最终执行 desc->handle_irq(irq, desc);
handle_edge_irq(irq, desc):执行中断函数,主要是执行以下两步骤:
(1) desc->chip->ack(irq):相应中断,也就是清中断,使能再次接受中断
(2) handle_IRQ_event(irq, action):执行中断的服务函数,desc->action->handler
中断运行总结:
当产生一个中断异常
1.进入异常向量vector,比如中断异常: vector_irq + stubs_offset
2.比如中断异常之前是用户模式(正常工作),则进入 __irq_usr,然后最终进入asm_do_IRQ函数,
3.然后执行irq_desc [irq]->handle_irq(irq, irq_desc [irq]);
通过刚才的分析,外部中断0(irq_desc[16])的handle_irq成员等于handle_edge_irq函数,
所以就是执行handle_edge_irq(irq, irq_desc [irq]);
4.以外部中断0为例,在handle_edge_irq函数中主要执行两步:
->4.1 desc->chip->ack //使用chip成员中的ack函数来清中断
->4.2 执行action链表 irq_desc->action->handler
这4步都是系统给做好的(中断的框架),当我们想自己写个中断处理程序,去执行自己的代码,就需要写irq_desc->action->handler,然后通过request_irq()来向内核申请注册中断
中断运行分析完毕后,接下来开始分析如何通过函数来注册卸载中断
上一节讲了如何实现运行中断,这些都是系统给做好的,当我们想自己写个中断处理程序,去执行自己的代码,就需要写irq_desc->action->handler,然后通过request_irq()来向内核申请注册中断
本节目标:
分析request_irq()如何申请注册中断,free_irq()如何注销中断
1.request_irq()位于kernel/irq/ manage .c,函数原型如下:
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long irqflags, const char *devname, void *dev_id)
参数说明:
unsigned int irq:为要注册中断服务函数的中断号,比如外部中断0就是16,定义在mach/irqs.h
irq_handler_t handler:为要注册的中断服务函数,就是(irq_desc+ irq )->action->handler
unsigned long irqflags: 触发中断的参数,比如边沿触发, 定义在linux/interrupt.h。
const char *devname:中断程序的名字,使用cat /proc/interrupt 可以查看中断程序名字
void *dev_id:传入中断处理程序的参数,注册共享中断时不能为NULL,因为卸载时需要这个做参数,避免卸载其它中断服务函数
1.1request_irq代码如下:
int request_irq(unsigned int irq, irq_handler_t handler, unsigned long irqflags, const char *devname, void *dev_id)
{
struct irqaction *action;
... ...
action = kmalloc(sizeof(struct irqaction), GFP_ATOMIC); //注册irqaction结构体类型的action
if (!action)
return -ENOMEM; /* 将带进来的参数赋给action */
action->handler = handler;
action->flags = irqflags;
cpus_clear(action->mask);
action->name = devname;
action->next = NULL;
action->dev_id = dev_id; select_smp_affinity(irq);
... ...
retval = setup_irq(irq, action); // 进入setup_irq(irq, action),设置irq_ desc[irq]->action
if (retval)
kfree(action); return retval;
}
从上面分析,request_irq()函数主要注册了一个irqaction型action,然后把参数都赋给这个action,最后进入setup_irq(irq, action)设置irq_ desc[irq]->action
1.2我们来看看setup_irq(irq, action)如何设置irq_ desc[irq]->action的:
int setup_irq(unsigned int irq, struct irqaction *new)
{
struct irq_desc *desc = irq_desc + irq; //根据中断号找到irq_ desc[irq]
... ...
p = &desc->action; //指向desc->action
old = *p;
if (old) { //判断action是否为空
/*判断这个中断是否支持共享 (IRQF_SHARED)*/
if (!((old->flags & new->flags) & IRQF_SHARED) ||
((old->flags ^ new->flags) & IRQF_TRIGGER_MASK)) {
old_name = old->name;
goto mismatch; //不支持,则跳转
} #if defined(CONFIG_IRQ_PER_CPU)
/* All handlers must agree on per-cpuness */
if ((old->flags & IRQF_PERCPU) !=
(new->flags & IRQF_PERCPU))
goto mismatch;
#endif /*找到action链表尾处,后面用于添加 新的中断服务函数(*new) */
do {
p = &old->next;
old = *p;
} while (old);
shared = ; //表示该中断支持共享,添加新的action,否则直接赋值新的action
} *p = new; //指向新的action ... ... if (!shared) { //若该中断不支持共享
irq_chip_set_defaults(desc->chip); //更新desc->chip,将为空的成员设置默认值 #if defined(CONFIG_IRQ_PER_CPU)
if (new->flags & IRQF_PERCPU)
desc->status |= IRQ_PER_CPU;
#endif /* Setup the type (level, edge polarity) if configured: */
if (new->flags & IRQF_TRIGGER_MASK) {
if (desc->chip && desc->chip->set_type) // desc->chip->set_type设置为中断引脚
desc->chip->set_type(irq,new->flags & IRQF_TRIGGER_MASK);
else
printk(KERN_WARNING "No IRQF_TRIGGER set_type " "function for IRQ %d (%s)\n", irq, desc->chip ? desc->chip->name : "unknown");
} else
compat_irq_chip_set_default_handler(desc); desc->status &= ~(IRQ_AUTODETECT | IRQ_WAITING |
IRQ_INPROGRESS); if (!(desc->status & IRQ_NOAUTOEN)) {
desc->depth = ;
desc->status &= ~IRQ_DISABLED;
if (desc->chip->startup)
desc->chip->startup(irq); //开启中断
else
desc->chip->enable(irq); //使能中断 } else /* Undo nested disables: */
desc->depth = ;
}
从上面可以看出setup_irq(irq, action)主要是将action中断服务函数放在irq_ desc[irq]->action中,
然后设置中断引脚:
desc->chip->set_type(irq,new->flags & IRQF_TRIGGER_MASK);
最后[开启/使能]中断:
desc->chip->[startup(irq) /enable(irq)]; //[开启/使能]中断
我们以外部中断0的desc[16]->chip->set_type为例,来看看它是如何初始化中断引脚的:
s3c_irqext_type(unsigned int irq, unsigned int type)
{
void __iomem *extint_reg;
void __iomem *gpcon_reg;
unsigned long gpcon_offset, extint_offset;
unsigned long newvalue = , value;
if ((irq >= IRQ_EINT0) && (irq <= IRQ_EINT3)) //找到寄存器
{
gpcon_reg = S3C2410_GPFCON;
extint_reg = S3C24XX_EXTINT0; // EXTINT0对应中断0~中断7
gpcon_offset = (irq - IRQ_EINT0) * ; //找到gpcon寄存器的相应位偏移量
extint_offset = (irq - IRQ_EINT0) * ; //找到extint寄存器的相应位偏移量
}
else if(... ...) //找到其它的EINT4~23的寄存器 /*将GPIO引脚设为中断引脚*/
value = __raw_readl(gpcon_reg);
value = (value & ~( << gpcon_offset)) | (0x02 << gpcon_offset); //相应位设置0x02
switch (type) //设置EXTINT0中断模式
{
case IRQT_NOEDGE: //未指定的中断模式
printk(KERN_WARNING "No edge setting!\n");
break; case IRQT_RISING: //上升沿触发,设置EXTINT0相应位为0x04
newvalue = S3C2410_EXTINT_RISEEDGE;
break; case IRQT_FALLING: //下降沿触发,设置EXTINT0相应位为0x02
newvalue = S3C2410_EXTINT_FALLEDGE;
break; case IRQT_BOTHEDGE: //双边沿触发,设置EXTINT0相应位为0x06
newvalue = S3C2410_EXTINT_BOTHEDGE;
break; case IRQT_LOW: //低电平触发,设置EXTINT0相应位为0x00
newvalue = S3C2410_EXTINT_LOWLEV;
break; case IRQT_HIGH: //高电平触发,设置EXTINT0相应位为0x01
newvalue = S3C2410_EXTINT_HILEV;
break;
default:
} /*更新EXTINT0相应位*/
value = __raw_readl(extint_reg);
value = (value & ~( << extint_offset)) | (newvalue << extint_offset); //相应位设置
__raw_writel(value, extint_reg); //向extint_reg写入value值
return ;
}
通过上面分析,就是将action->flags带入到desc[16]->chip->set_type里面,根据不同的中断来设置寄存器模式
2.request_irq()是注册中断,同样的卸载中断的函数是free_irq()
free_irq()也位于kernel/irq/ manage .c,函数原型如下:
free_irq(unsigned int irq, void *dev_id);
参数说明:
unsigned int irq:要卸载的中断号
void *dev_id:这个是要卸载的中断action下的哪个服务函数,
2.1 free_irq()代码如下:
void free_irq(unsigned int irq, void *dev_id)
{
struct irq_desc *desc;
struct irqaction **p;
unsigned long flags;
irqreturn_t (*handler)(int, void *) = NULL; WARN_ON(in_interrupt());
if (irq >= NR_IRQS)
return; desc = irq_desc + irq; //根据中断号,找到数组
spin_lock_irqsave(&desc->lock, flags);
p = &desc->action; //p指向中断里的action链表 for (;;) {
struct irqaction *action = *p; if (action) { //在action链表中找到与参数dev_id相等的中断服务函数
struct irqaction **pp = p;
p = &action->next;
if (action->dev_id != dev_id) //直到找dev_id才执行下面,进行卸载
continue;
*pp = action->next; //指向下个action成员,将当前的action释放掉
#ifdef CONFIG_IRQ_RELEASE_METHOD
if (desc->chip->release) //执行chip->release释放中断服务函数相关的东西
desc->chip->release(irq, dev_id);
#endif
if (!desc->action) { //判断当前action成员是否为空,表示没有中断服务函数
desc->status |= IRQ_DISABLED;
if (desc->chip->shutdown) //执行chip->shutdown关闭中断
desc->chip->shutdown(irq);
else //执行chip-> disable禁止中断
desc->chip->disable(irq);
} spin_unlock_irqrestore(&desc->lock, flags);
unregister_handler_proc(irq, action);
synchronize_irq(irq);
if (action->flags & IRQF_SHARED)
handler = action->handler;
kfree(action);
return; } printk(KERN_ERR "Trying to free already-free IRQ %d\n", irq);//没有找到要卸载的action成员 spin_unlock_irqrestore(&desc->lock, flags); return; } #ifdef CONFIG_DEBUG_SHIRQ
if (handler) { /* * It's a shared IRQ -- the driver ought to be prepared for it * to happen even now it's being freed, so let's make sure.... * We do this after actually deregistering it, to make sure that * a 'real' IRQ doesn't run in parallel with our fake */
handler(irq, dev_id); }
#endif
}
从上面分析,free_irq()函数主要通过irq和dev_id来找要释放的中断action
若释放的中断action不是共享的中断(为空),则执行:
*pp = action->next; //指向下个action成员,将当前的action释放掉
desc->chip->release(irq, dev_id); //执行chip->release释放中断服务函数相关的东西 desc->status |= IRQ_DISABLED; //设置desc[irq]->status标志位
desc->chip->[shutdown(irq)/ desible(irq)]; //关闭/禁止中断
若释放的中断action是共享的中断(还有其它中断服务函数)的话就只执行:
*pp = action->next; //指向下个action成员,将当前的action释放掉
desc->chip->release(irq, dev_id); //执行chip->release释放中断服务函数相关的东西
request_irq()和free_irq()分析完毕后,接下来开始编写中断方式的按键驱动
request_irq()和free_irq()分析完毕后,接下来开始编写上升沿中断的按键驱动
如下图,需要设置4个按键的EINT0, EINT2, EINT11, EINT19的模式为双边沿,且设置按键引脚为中断引脚
这里我们只需要使用request_irq函数就行了, 在request_irq函数里会初始chip->set_type(设置引脚和中断模式)
1.首先添加头文件
#include <linux/irq.h> //要用到IRQ_EINT0和IRQT_RISING这些变量
2.在second_drv_open函数中,申请4个中断:
/* IRQ_EINT0: 中断号, 定义在 asm/arch/irqs.h,被linux/irq.h调用
buttons_irq : 中断服务函数,
IRQT_ BOTHEDGE: 双边沿中断, 定义在 asm/irq.h,被linux/irq.h调用
“S1”: 保存文件到/proc/interrupt/S1,
1: dev_id,中断函数的参数, 被用来释放中断服务函数,中断时并会传入中断服务函数
*/ request_irq(IRQ_EINT0, buttons_irq,IRQT_BOTHEDGE, “S1”, );
request_irq(IRQ_EINT2, buttons_irq,IRQT_ BOTHEDGE, “S2”, );
request_irq(IRQ_EINT11, buttons_irq,IRQT_ BOTHEDGE, “S3”, );
request_irq(IRQ_EINT19, buttons_irq,IRQT_ BOTHEDGE, “S4”, );
3.在file_oprations结构体中添加.release成员函数,用来释放中断
static struct file_operations second_drv_fops={
.owner = THIS_MODULE,
.open = second_drv_open,
.read = second_drv_read,
.release=second_drv_class, //里面添加free_irq函数,来释放中断服务函数
};
然后写.release成员函数,释放中断:
int second_drv_class(struct inode *inode, struct file *file)
{
free_irq(IRQ_EINT0,);
free_irq(IRQ_EINT2,);
free_irq(IRQ_EINT11,);
free_irq(IRQ_EINT19,); return ; }
4.写action->handler中断服务函数,在第2小节里request_irq函数的中断服务函数是buttons_irq
static irqreturn_t buttons_irq (int irq, void *dev_id) //irq:中断号, void *:表示支持所有类型
{
printk(“irq=%d\n”);
return IRQ_HANDLED;
}
5.make后,然后放在开发板里insmod,并挂载好了buttons设备节点,如下图:

6.通过exec 5</dev/buttons 将/dev/buttons 设备节点挂载到-sh进程下描述符5:
如下图,使用ps查看-sh进程为801,然后ls -l /proc/801/fd 找到描述符5指向/dev/buttons

如下图,并申请中断,当有按键按下时,就进入中断服务函数buttons_irq()打印数据:
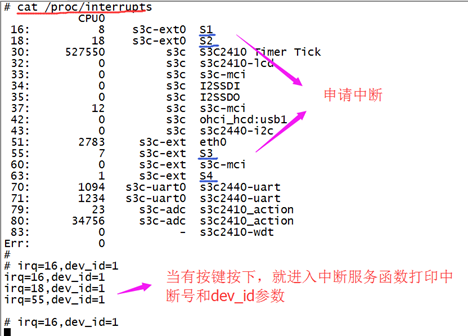
6.通过exec 5<&- 将描述符5卸载
会进入.release成员second_drv_class()函数释放中断,
然后cat /proc/interrupts会发现申请的中断已经注销掉了,在-sh进程fd文件里也没有文件描述符5
7.改进中断按键驱动程序
使用等待队列,让read函数没有中断时,进入休眠状态,降低CPU.
使用dev_id来获取不同按键的状态,是上升沿还是下降沿触发?
7.1接下来要用到以下几个函数:
s3c2410_gpio_getpin(unsigned int pin); //获取引脚高低电平
pin: 引脚名称,例如:S3C2410_GPA0,定义在<asm/arch/regs-gpio.h>
队列3个函数(声明队列,唤醒队列,等待队列):
static DECLARE_WAIT_QUEUE_HEAD(qname);
声明一个新的等待队列类型的中断
qname:就是中断名字,被用来后面的唤醒中断和等待中断
wake_up_interruptible(*qname);
唤醒一个中断,会将这个中断重新添加到runqueue队列(将中断置为TASK_RUNNING状态)
qname:指向声明的等待队列类型中断名字
wait_event_interruptible(qname, condition);
等待事件中断函数,用来将中断放回等待队列,
前提是condition要为0,然后将这个中断从runqueue队列中删除(将中断置为TASK_INTERRUPTIBLE状态),然后会在函数里一直for(; ;)判断condition为真才退出
注意:此时的中断属于僵尸进程(既不在等待队列,也不在运行队列),当需要这个进程时,需要使用wake_up_interruptible(*qname)来唤醒中断
qname: (wait queue):为声明的等待队列的中断名字
condition:状态,等于0时就是中断进入休眠, 1:退出休眠
7.2 驱动程序步骤
(1)定义引脚描述结构体数组,每个结构体都保存按键引脚和初始状态,然后在中断服务函数中通过s3c2410_gpio_getpin()来获取按键是松开还是按下(因为中断是双边沿触发),并保存在key_val里(它会在.read函数发送给用户层)
/*
*引脚描述结构体
*/
struct pin_desc{
unsigned int pin;
unsigned int pin_status;
};
/*
*key初始状态(没有按下): 0x01,0x02,0x03,0x04
*key状态(按下): 0x81,0x82,0x83,0x84
*/
struct pin_desc pins_desc[]={
{S3C2410_GPF0,0x01 },
{S3C2410_GPF2, 0x02 },
{S3C2410_GPG3, 0x03 },
{S3C2410_GPG11,0x04},} ;
(2)声明等待队列类型的中断button_wait:
static DECLARE_WAIT_QUEUE_HEAD(button_ wait); //声明等待队列类型的中断
(3)定义全局变量even _press,用于中断事件标志:
static volatile int even _press = ;
(4)在.read函数里,将even _press置0放入等待事件中断函数中,判断even _press为真,才发送数据:
even_press = ; wait_event_interruptible(button_ wait, even _press); //当even _press为真,表示有按键按下,退出等待队列 copy_to_user(buf, &key_val, ); //even _press为真,有数据了,发送给用户层
(5)在中断服务函数里,发生中断时, 就将even _press置1,并唤醒中断button_wait(.read函数里就会发送数据给用户层):
even _press = ;
wake_up_interruptible(&button_wait); //唤醒中断
7.3 更改测试程序second_interrupt_text.c
最终修改如下:
#include <sys/types.h> //调用sys目录下types.h文件
#include <sys/stat.h> //stat.h获取文件属性
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
/*secondtext while一直获取按键信息 */
int main(int argc,char **argv)
{
int fd,ret;
unsigned int val=;
fd=open("/dev/buttons",O_RDWR);
if(fd<)
{printf("can't open!!!\n");
return -;}
while()
{
ret=read(fd,&val,); //读取一个值,(当在等待队列时,本进程就会进入休眠状态)
if(ret<)
{
printf("read err!\n");
continue;
}
printf("key_val=0X%x\r\n",val);
}
return ;
}
8.运行结果
insmod second_interrupt.ko //挂载驱动设备
./second_interrupt_text & //后台运行测试程序
创建了4个中断,如下图:

当没有按键按下时,这个进程就处于静止状态staitc,如下图所示:

在等待队列(休眠状态)下,该进程占用了CPU0%资源,如下图所示:
当有按键按下时,便打印数据,如下图所示:
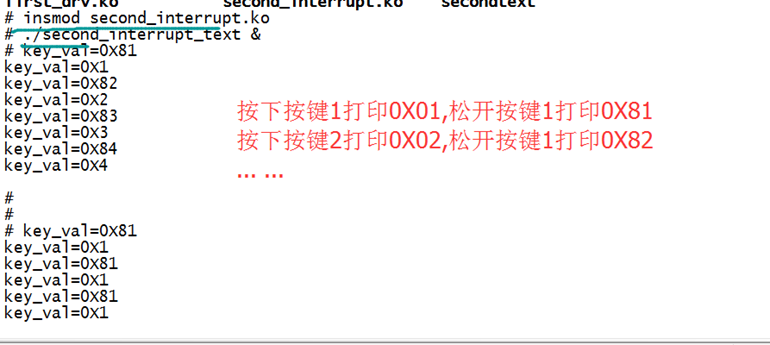
本节驱动代码如下:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <linux/irq.h>
#include <asm/irq.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <asm/uaccess.h>
#include <asm/io.h> static struct class *seconddrv_class;
static struct class_device *seconddrv_class_devs; /* 声明等待队列类型中断 button_wait */
static DECLARE_WAIT_QUEUE_HEAD(button_wait); /*
* 定义中断事件标志
* 0:进入等待队列 1:退出等待队列
*/
static int even_press=; /*
* 定义全局变量key_val,保存key状态
*/
static int key_val=; /*
*引脚描述结构体
*/
struct pin_desc{
unsigned int pin;
unsigned int pin_status;
}; /*
*key初始状态(没有按下): 0x01,0x02,0x03,0x04
*key状态(按下): 0x81,0x82,0x83,0x84
*/
struct pin_desc pins_desc[]={
{S3C2410_GPF0,0x01 },
{S3C2410_GPF2, 0x02 },
{S3C2410_GPG3, 0x03 },
{S3C2410_GPG11,0x04},} ; int second_drv_class(struct inode *inode, struct file *file) //卸载中断
{
free_irq(IRQ_EINT0,&pins_desc[]);
free_irq(IRQ_EINT2,&pins_desc[]);
free_irq(IRQ_EINT11,&pins_desc[]);
free_irq(IRQ_EINT19,&pins_desc[]);
return ;
} /* 确定是上升沿还是下降沿 */
static irqreturn_t buttons_irq (int irq, void *dev_id) //中断服务函数
{
struct pin_desc *pindesc=(struct pin_desc *)dev_id; //获取引脚描述结构体
unsigned int pin_val=;
pin_val=s3c2410_gpio_getpin(pindesc->pin); if(pin_val)
{
/*没有按下 (下降沿),清除0x80*/
key_val=pindesc->pin_status&0xef;
}
else
{
/*按下(上升沿),加上0x80*/
key_val=pindesc->pin_status|0x80;
} even_press=; //退出等待队列
wake_up_interruptible(&button_wait); //唤醒 中断 return IRQ_HANDLED;
} static int second_drv_open(struct inode *inode, struct file *file)
{
request_irq(IRQ_EINT0,buttons_irq,IRQT_BOTHEDGE,"S1",&pins_desc[]);
request_irq(IRQ_EINT2, buttons_irq,IRQT_BOTHEDGE, "S2", &pins_desc[]);
request_irq(IRQ_EINT11, buttons_irq,IRQT_BOTHEDGE, "S3", &pins_desc[]);
request_irq(IRQ_EINT19, buttons_irq,IRQT_BOTHEDGE, "S4", &pins_desc[]); return ;
} static int second_drv_read(struct file *file, const char __user *buf, size_t count, loff_t * ppos)
{/*将中断 进入等待队列(休眠状态)*/
wait_event_interruptible(button_wait, even_press); /*有按键按下,退出等待队列,上传key_val 给用户层*/
if(copy_to_user(buf,&key_val,sizeof(key_val)))
return EFAULT;
even_press=0; //数据发完后,立马设为休眠状态,避免误操作
return ;
} static struct file_operations second_drv_fops={
.owner = THIS_MODULE,
.open = second_drv_open,
.read = second_drv_read,
.release=second_drv_class, //里面添加free_irq函数,来释放中断服务函数
}; volatile int second_major;
static int second_drv_init(void)
{
second_major=register_chrdev(,"second_drv",&second_drv_fops); //创建驱动
seconddrv_class=class_create(THIS_MODULE,"second_dev"); //创建类名
seconddrv_class_devs=class_device_create(seconddrv_class, NULL, MKDEV(second_major,), NULL,"buttons");
return ;
} static int second_drv_exit(void)
{
unregister_chrdev(second_major,"second_drv"); //卸载驱动
class_device_unregister(seconddrv_class_devs); //卸载类设备
class_destroy(seconddrv_class); //卸载类
return ;
} module_init(second_drv_init);
module_exit(second_drv_exit);
MODULE_LICENSE("GPL v2");
中断按键驱动程序之poll机制(详解)
本节继续在上一节中断按键程序里改进,添加poll机制.
那么我们为什么还需要poll机制呢。之前的测试程序是这样:
while ()
{
read(fd, &key_val, );
printf("key_val = 0x%x\n", key_val);
}
在没有poll机制的情况下,大部分时间程序都处在read中休眠的那个位置。如果我们不想让程序停在这个位置,而是希望当有按键按下时,我们再去read,因此我们编写poll函数,测试程序调用poll函数根据返回值,来决定是否执行read函数。
poll机制作用:相当于定时器,设置一定时间使进程等待资源,如果时间到了中断还处于睡眠状态(等待队列),poll机制就会唤醒中断,获取一次资源
1.poll机制内核框架
如下图所示,在用户层上,使用poll或select函数时,和open、read那些函数一样,也要进入内核sys_poll函数里,接下来我们分析sys_poll函数来了解poll机制(位于/fs/select.c)

1.1 sys_poll代码如下:
asmlinkage long sys_poll(struct pollfd __user *ufds, unsigned int nfds,long timeout_msecs)
{
if (timeout_msecs > ) //参数timeout>0
{
timeout_jiffies = msecs_to_jiffies(timeout_msecs); //通过频率来计算timeout时间需要多少计数值
}
else
{
timeout_jiffies = timeout_msecs; //如果timeout时间为0,直接赋值
}
return do_sys_poll(ufds, nfds, &timeout_jiffies); //调用do_sys_poll。
}
1.2 然后进入do_sys_poll(位于fs/select.c):
int do_sys_poll(struct pollfd __user *ufds, unsigned int nfds, s64 *timeout)
{
... ...
/*初始化一个poll_wqueues变量table*/
poll_initwait(&table);
... ...
fdcount = do_poll(nfds, head, &table, timeout);
... ...
}
1.3进入poll_initwait函数,发现主要实现以下一句,后面会分析这里:
table ->pt-> qproc=__pollwait; //__pollwait将在驱动的poll函数里的poll_wait函数用到
1.4然后进入do_poll函数, (位于fs/select.c):
static int do_poll(unsigned int nfds, struct poll_list *list, struct poll_wqueues *wait, s64 *timeout)
{
……
for (;;)
{
……
set_current_state(TASK_INTERRUPTIBLE); //设置为等待队列状态
......
for (; pfd != pfd_end; pfd++) { //for循环运行多个poll机制
/*将pfd和pt参数代入我们驱动程序里注册的poll函数*/
if (do_pollfd(pfd, pt)) //若返回非0,count++,后面并退出
{ count++;
pt = NULL; } } …… /*count非0(.poll函数返回非0),timeout超时计数到0,有信号在等待*/ if (count || !*timeout || signal_pending(current))
break;
……
/*进入休眠状态,只有当timeout超时计数到0,或者被中断唤醒才退出,*/
__timeout = schedule_timeout(__timeout); …… } __set_current_state(TASK_RUNNING); //开始运行
return count; }
1.4.1上面do_pollfd函数到底是怎么将pfd和pt参数代入的?代码如下(位于fs/select.c):
static inline unsigned int do_pollfd(struct pollfd *pollfd, poll_table *pwait)
{
……
if (file->f_op && file->f_op->poll)
mask = file->f_op->poll(file, pwait);
…… return mask;
}
上面file->f_op 就是我们驱动里的file_oprations结构体,如下图所示:

所以do_pollfd(pfd, pt)就执行了我们驱动程序里的.poll(pfd, pt)函数(第2小节开始分析.poll函数)
1.4.2当poll进入休眠状态后,又是谁来唤醒它?这就要分析我们的驱动程序.poll函数(第2小节开始分析.poll函数)
2写驱动程序.poll函数,并分析.poll函数:
在上一节驱动程序里添加以下代码:
#include <linux/poll.h> //添加头文件
/* .poll驱动函数: third_poll */
static unsigned int third_poll(struct file *fp, poll_table * wait) //fp:文件 wait:
{
unsigned int mask =;
poll_wait(fp, &button_wait, wait);
if(even_press) //中断事件标志, 1:退出休眠状态 0:进入休眠状态
mask |= POLLIN | POLLRDNORM ;
return mask; //当超时,就返给应用层为0 ,被唤醒了就返回POLLIN | POLLRDNORM ; } static struct file_operations third_drv_fops={
.owner = THIS_MODULE,
.open = third_drv_open,
.read = third_drv_read,
.release=third_drv_class,
.poll = third_poll, //创建.poll函数
};
2.1 在我们1.4小节do_poll函数有一段以下代码:
if (do_pollfd(pfd, pt)) //若返回非0,count++,后面并退出
{
count++;
pt = NULL;
}
且在1.4.1分析出: do_pollfd(pfd, pt)就是指向的驱动程序third_poll()函数,
所以当我们有按键按下时, 驱动函数third_poll()就会返回mask非0值,然后在内核函数do_poll里的count就++,poll机制并退出睡眠.
2.2分析在内核中poll机制如何被驱动里的中断唤醒的
在驱动函数third_poll()里有以下一句:
poll_wait(fp, &button_wait, wait);

如上图所示,代入参数,poll_wait()就是执行了: p->qproc(filp, button_wait, p);
刚好对应了我们1.3小节的:
table ->pt-> qproc=__pollwait;
所以poll_wait()函数就是调用了: __pollwait(filp, button_wait, p);
然后我们来分析__pollwait函数,pollwait的代码如下:
static void __pollwait(struct file *filp, wait_queue_head_t *wait_address,poll_table *p)
{
... ...
//把current进程挂载到&entry->wait下
init_waitqueue_entry(&entry->wait, current); //再&entry->wait把添加到到button_wait中断下
add_wait_queue(wait_address, &entry->wait); }
它是将poll进程添加到了button_wait中断队列里,这样,一有按键按下时,在中断服务函数里就会唤醒button_wait中断,同样也会唤醒poll机制,使poll机制重新进程休眠计数
2.3 驱动程序.poll函数返回值介绍
当中断休眠状态时,返回mask为0
当运行时返回:mask |= POLLIN | POLLRDNORM
其中参数意义如下:
|
常量 |
说明 |
|
POLLIN |
普通或优先级带数据可读 |
|
POLLRDNORM |
normal普通数据可读 |
|
POLLRDBAND |
优先级带数据可读 |
|
POLLPRI |
Priority高优先级数据可读 |
|
POLLOUT |
普通数据可写 |
|
POLLWRNORM |
normal普通数据可写 |
|
POLLWRBAND |
band优先级带数据可写 |
|
POLLERR |
发生错误 |
|
POLLHUP |
发生挂起 |
|
POLLNVAL |
描述字不是一个打开的文件 |
所以POLLIN | POLLRDNORM:普通数据可读|优先级带数据可读
mask就返回到应用层poll函数,
3.改进测试程序third_poll_text.c(添加poll函数)
在linux中可以通过man poll 来查看poll函数如何使用
poll函数原型如下(#include <poll.h>):
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数介绍:
1) *fds:是一个poll描述符结构体数组(可以处理多个poll),结构体pollfd如下:
struct pollfd {
int fd; /* file descriptor 文件描述符*/
short events; /* requested events 请求的事件*/
short revents; /* returned events 返回的事件(函数返回值)*/
};
其中events和revents值参数如下:
|
常量 |
说明 |
|
POLLIN |
普通或优先级带数据可读 |
|
POLLRDNORM |
normal普通数据可读 |
|
POLLRDBAND |
优先级带数据可读 |
|
POLLPRI |
Priority高优先级数据可读 |
|
POLLOUT |
普通数据可写 |
|
POLLWRNORM |
normal普通数据可写 |
|
POLLWRBAND |
band优先级带数据可写 |
|
POLLERR |
发生错误 |
|
POLLHUP |
发生挂起 |
|
POLLNVAL |
描述字不是一个打开的文件 |
2) nfds:表示多少个poll,如果1个,就填入1
3) timeout:定时多少ms
返回值介绍:
返回值为0:表示超时或者fd文件描述符无法打开
返回值为 -1:表示错误
返回值为>0时 :就是以下几个常量
|
常量 |
说明 |
|
POLLIN |
普通或优先级带数据可读 |
|
POLLRDNORM |
normal普通数据可读 |
|
POLLRDBAND |
优先级带数据可读 |
|
POLLPRI |
Priority高优先级数据可读 |
|
POLLOUT |
普通数据可写 |
|
POLLWRNORM |
normal普通数据可写 |
|
POLLWRBAND |
band优先级带数据可写 |
|
POLLERR |
发生错误 |
|
POLLHUP |
发生挂起 |
|
POLLNVAL |
描述字不是一个打开的文件 |
最终改进的测试代码如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdio.h>
#include <string.h>
#include <poll.h> //添加poll头文件 /*useg: thirdtext */
int main(int argc,char **argv)
{
int fd,ret;
unsigned int val=;
struct pollfd fds; //定义poll文件描述结构体
fd=open("/dev/buttons",O_RDWR);
if(fd<)
{printf("can't open!!!\n");
return -;} fds.fd=fd;
fds.events= POLLIN; //请求类型是 普通或优先级带数据可读 while()
{ ret=poll(&fds,,) ; //一个poll, 定时5000ms,进入休眠状态
if(ret==) //超时
{
printf("time out \r\n");
}
else if(ret>) //poll机制被唤醒,表示有数据可读
{
read(fd,&val,); //读取一个值
printf("key_val=0X%x\r\n",val);
}
}
return ;
}
效果如下:
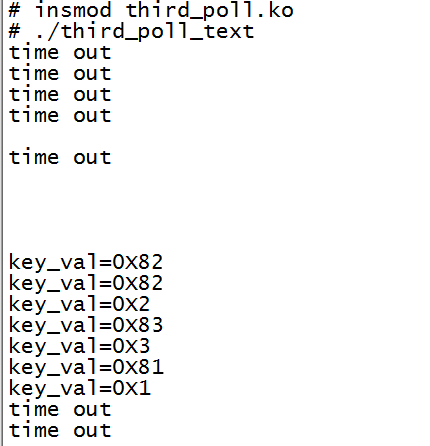
若5S没有数据,则打印time out
下节开始学习——使用异步通知来通知信号
按键之使用异步通知(详解)
之前学的应用层都是:
1)查询方式:一直读
以上3种,我们都是让应用程序主动去读,本节我们学习异步通知,它的作用就是当驱动层有数据时,主动告诉应用程序,然后应用程序再来读, 这样,应用程序就可以干其它的事情,不必一直读
比如:kill -9 pid ,其实就是通过发信号杀死进程,kill发数据9给指定id号进程
1.怎么来收信号?
通过signal函数来实现获取信号,先来看看以下例子:
头函数:
sighandler_t signal(int signum, sighandler_t handler);
函数说明:让一个信号与与一个函数对应,每当接收到这个信号就会调用相应的函数。
头文件: #include <signal.h>
参数1: 指明了所要处理的信号类型
信号有以下几种:
- SIGINT 键盘中断(如break、ctrl+c键被按下)
- SIGUSR1 用户自定义信号1,kill的USR1(10)信号
- SIGUSR2 用户自定义信号2, kill的USR2(12)信号
参数2: 信号产生后需要处理的方式,可以是个函数
代码如下:
#include <stdio.h>
#include <signal.h> void my_signal_run(int signum) //信号处理函数
{
static int run_cnt=;
printf("signal = %d, %d count\r\n",signum,++count);
} int main(int argc,char **argv)
{
signal(SIGUSR1,my_signal_run); //调用signal函数,让指定的信号SIGUSR1与处理函数my_signal_run对应。
while()
{
sleep(); //去做其它事,睡眠1s
} return ;
}
然后运行后,使用kill -10 802,可以看到产生单信号USR1(10)时就会调用my_signal_run()打印数据。
# kill -10 802
# signal = 10, 1 count
# kill -10 802
# signal = 10, 2 count
2. 来实现异步通知
要求:
- 一、应用程序要实现有:注册信号处理函数,使用signal函数
- 二、谁来发?驱动来发
- 三、发给谁?驱动发给应用程序,但应用程序必须告诉驱动PID,
- 四、怎么发?驱动程序调用kill_fasync函数
3先来写驱动程序,我们在之前的中断程序上修改
3.1定义 异步信号结构体 变量:
static struct fasync_struct * button_async;
3.2在file_operations结构体添加成员.fasync函数,并写函数
static struct file_operations third_drv_fops={
.owner = THIS_MODULE,
.open = fourth_drv_open,
.read = fourth _drv_read,
.release= fourth _drv_class,
.poll = fourth _poll,
.fasync = fourth_fasync //添加初始化异步信号函数
};
static int fourth_fasync (int fd, struct file *file, int on)
{
return fasync_helper(fd, file, on, & button_async); //初始化button_async结构体,就能使用kill_fasync()了
}
成员.fasync函数又是什么情况下使用?
是被应用程序调用,在下面第4小节会见到。
3.3在buttons_irq中断服务函数里发送信号:
kill_fasync(&button_async, SIGIO, POLL_IN); //当有中断时,就发送SIGIO信号给应用层,应用层就会触发与SIGIO信号对应的函数
3.4 驱动程序代码如下:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <linux/irq.h>
#include <asm/irq.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <asm/uaccess.h>
#include <asm/io.h>
#include <linux/poll.h> static struct class *fourthdrv_class;
static struct class_device *fourthdrv_class_devs; /* 声明等待队列类型中断 button_wait */
static DECLARE_WAIT_QUEUE_HEAD(button_wait); /* 异步信号结构体变量 */
static struct fasync_struct * button_async; /*
* 定义中断事件标志
* 0:进入等待队列 1:退出等待队列
*/
static int even_press=; /*
* 定义全局变量key_val,保存key状态
*/
static int key_val=; /*
*引脚描述结构体
*/
struct pin_desc{ unsigned int pin; unsigned int pin_status; }; /*
*key初始状态(没有按下): 0x01,0x02,0x03,0x04
*key状态(按下): 0x81,0x82,0x83,0x84
*/ struct pin_desc pins_desc[]={
{S3C2410_GPF0,0x01 },
{S3C2410_GPF2, 0x02 },
{S3C2410_GPG3, 0x03 },
{S3C2410_GPG11,0x04}, } ; int fourth_drv_class(struct inode *inode, struct file *file) //卸载中断
{
free_irq(IRQ_EINT0,&pins_desc[]);
free_irq(IRQ_EINT2,&pins_desc[]);
free_irq(IRQ_EINT11,&pins_desc[]);
free_irq(IRQ_EINT19,&pins_desc[]);
return ;
} /*
* 确定是上升沿还是下降沿
*/
static irqreturn_t buttons_irq (int irq, void *dev_id) //中断服务函数
{
struct pin_desc *pindesc=(struct pin_desc *)dev_id; //获取引脚描述结构体
unsigned int pin_val=;
pin_val=s3c2410_gpio_getpin(pindesc->pin);
if(pin_val)
{
/*没有按下 (下降沿),清除0x80*/
key_val=pindesc->pin_status&0xef;
}
else
{
/*按下(上升沿),加上0x80*/
key_val=pindesc->pin_status|0x80;
} even_press=; //退出等待队列
wake_up_interruptible(&button_wait); //唤醒 中断
kill_fasync(&button_async, SIGIO, POLL_IN); //发送SIGIO信号给应用层 return IRQ_RETVAL(IRQ_HANDLED);
} static int fourth_drv_open(struct inode *inode, struct file *file)
{
request_irq(IRQ_EINT0,buttons_irq,IRQT_BOTHEDGE,"S1",&pins_desc[]);
request_irq(IRQ_EINT2, buttons_irq,IRQT_BOTHEDGE, "S2", &pins_desc[]);
request_irq(IRQ_EINT11, buttons_irq,IRQT_BOTHEDGE, "S3", &pins_desc[]);
request_irq(IRQ_EINT19, buttons_irq,IRQT_BOTHEDGE, "S4", &pins_desc[]);
return ;
} static int fourth_drv_read(struct file *file, const char __user *buf, size_t count, loff_t * ppos)
{
/*将中断 进入等待队列(休眠状态)*/
wait_event_interruptible(button_wait, even_press); /*有按键按下,退出等待队列,上传key_val 给用户层*/
if(copy_to_user(buf,&key_val,sizeof(key_val)))
return EFAULT; even_press=;
return ;
} static unsigned fourth_poll(struct file *file, poll_table *wait)
{
unsigned int mask = ;
poll_wait(file, &button_wait, wait); // 不会立即休眠
if (even_press)
mask |= POLLIN | POLLRDNORM; return mask;
} static int fourth_fasync (int fd, struct file *file, int on)
{
return fasync_helper(fd, file, on, & button_async); //初始化button_async结构体,就能使用kill_fasync()了
} static struct file_operations fourth_drv_fops={
.owner = THIS_MODULE,
.open = fourth_drv_open,
.read = fourth_drv_read,
.release=fourth_drv_class, //里面添加free_irq函数,来释放中断服务函数
.poll = fourth_poll,
.fasync= fourth_fasync, //初始化异步信号函数
}; volatile int fourth_major;
static int fourth_drv_init(void)
{
fourth_major=register_chrdev(,"fourth_drv",&fourth_drv_fops); //创建驱动
fourthdrv_class=class_create(THIS_MODULE,"fourth_dev"); //创建类名
fourthdrv_class_devs=class_device_create(fourthdrv_class, NULL, MKDEV(fourth_major,), NULL,"buttons");
return ; } static int fourth_drv_exit(void)
{
unregister_chrdev(fourth_major,"fourth_drv"); //卸载驱动
class_device_unregister(fourthdrv_class_devs); //卸载类设备
class_destroy(fourthdrv_class); //卸载类
return ;
} module_init(fourth_drv_init);
module_exit(fourth_drv_exit);
MODULE_LICENSE("GPL v2");
4 写应用测试程序
步骤如下:
1) signal(SIGIO, my_signal_fun);
调用signal函数,当接收到SIGIO信号就进入my_signal_fun函数,读取驱动层的数据
2) fcntl(fd,F_SETOWN,getpid());
指定进程做为fd文件的”属主”,内核收到F_SETOWN命令,就会设置pid(驱动无需处理),这样fd驱动程序就知道发给哪个进程
3) oflags=fcntl(fd,F_GETFL);
获取fd的文件状态标志
4) fcntl(fd,F_SETFL, oflags| FASYNC );
添加FASYNC状态标志,会调用驱动中成员.fasync函数,执行fasync_helper()来初始化异步信号结构体
这4个步骤执行后,一旦有驱动层有SIGIO信号时,进程就会收到
应用层代码如下:
#include <sys/types.h>
#include <sys/stat.h>
#include <stdio.h>
#include <string.h>
#include <poll.h>
#include <signal.h>
#include <unistd.h>
#include <fcntl.h> int fd,ret;
void my_signal_fun(int signame) //有信号来了
{
read( fd, &ret, ); //读取驱动层数据
printf("key_vale=0X%x\r\n",ret); } /*useg: fourthtext */
int main(int argc,char **argv)
{
int oflag;
unsigned int val=;
fd=open("/dev/buttons",O_RDWR);
if(fd<)
{printf("can't open!!!\n");
return -;} signal(SIGIO,my_signal_fun); //指定的信号SIGIO与处理函数my_signal_run对应
fcntl( fd, F_SETOWN, getip()); //指定进程作为fd 的属主,发送pid给驱动
oflag=fcntl( fd, F_GETFL); //获取fd的文件标志状态
fcntl( fd, F_SETFL, oflag|FASYNC); //添加FASYNC状态标志,调用驱动层.fasync成员函数 while()
{
sleep(); //做其它的事情
}
return ; }
5 运行查看结果

下节开始学习——按键之互斥、阻塞机制
按键驱动之定时器防抖(详解)
本节目标:
通过定时器来防止按键抖动,测试程序是使用上节的:阻塞操作的测试程序
1.如下图所示,在没有定时器防抖情况下,按键没有稳定之前会多次进入中断,使得输出多个相同信息出来

2.按键波形图,如下所示:

3.如何消去按键抖动
通过定时器延时10ms,然后每当按键进入中断时就更新定时器延时10ms,若延时10ms到了说明已经过了抖动范围,然后再打印按键电平信息
4.定时器结构体和函数介绍
我们先来看看两个全局变量:
jiffies: 是系统时钟,全局变量,默认每隔10ms加1
HZ:是每S的频率,通过系统时钟换算出来,比如每隔10ms加1,那么HZ就等于100
4.1定时器结构体timer_list
timer_list常用结构体成员如下所示:
)data //传递到*function超时处理函数的参数,主要在多个定时器同时使用时,区别是哪个timer超时。 )expires //定时器到期的时间,当expires小于等于jiffies时,这个定时器便到期并调用定时器超时处理函数,然后就不会再调用了,
比如要使用10ms后到期,赋值(jiffies+HZ/100)即可 )void (*function)(unsigned long) //定时器超时处理函数。
4.2 定时器常用函数
init_timer(struct timer_list*) //定时器初始化结构体函数, add_timer(struct timer_list*) //往系统添加定时器,告诉内核有个定时器结构体 mod_timer(struct timer_list *, unsigned long jiffier_timerout) //修改定时器的超时时间为jiffies_timerout,
当expires小于等于jiffies时,便调用定时器超时处理函数。 timer_pending(struct timer_list *) //定时器状态查询,如果在系统的定时器列表中则返回1,否则返回0; del_timer(struct timer_list*) //删除定时器,在本驱动程序出口函数sixth_drv_exit()里添加
5.修改驱动程序实现定时器消抖动
5.1首先定义一个定时器结构体:
static struct timer_list buttons_timer; //定义定时器结构体
5.2在init入口函数中初始化定时器结构体:
init_timer(&buttons_timer); //初始化结构体 /*本中断都是更新同一个定时器,所以成员.data无需初始,默认为0
不需要定时器到期时间,所以成员.expires无需初始化,默认为0,由于小于等于jiffies,会进入一次定时器超时函数*/
buttons_timer. function= buttons_timer_ function; add_timer(&buttons_timer); //告诉内核,有一个定时器
5.3 在exit出口函数中删除定时器:
del_timer(&buttons_timer); //删除定时器
5.4定义全局变量*irq_dev_id,然后在中断服务函数中获取dev_id
struct pin_desc *irq_dev_id ; //定义全局变量获取dev_id
并修改中断服务函数:
static irqreturn_t buttons_irq (int irq, void *dev_id) //中断服务函数
{
irq_dev_id =(struct pin_desc *)dev_id; //获取引脚描述结构体
/*每产生一次中断,则更新定时器10ms超时 */
mod_timer(&buttons_timer, jiffies+HZ/); return IRQ_RETVAL(IRQ_HANDLED);
}
5.5当10ms超时到了,进入定时器超时函数,处理*irq_dev_id来判断是哪个按键按下的
static void buttons_timer_function(unsigned long data) //定时器超时函数
{
unsigned int pin_val=;
if(!irq_dev_id) //初始化时,由于定时器.expires成员=0,会进入一次,若irq_dev_id为0则退出
{printk("expires: timer out\n");
return ; } pin_val=s3c2410_gpio_getpin(irq_dev_id->pin); //获取按键值 if(pin_val)
{
/*按下 (下降沿),清除0x80*/
key_val=irq_dev_id->pin_status&0xef;
}
else
{
/*没有按下(上升沿),加上0x80*/
key_val=irq_dev_id->pin_status|0x80;
} even_press=; //退出等待队列
wake_up_interruptible(&button_wait); //唤醒 中断
kill_fasync(&button_async, SIGIO, POLL_IN); //发送SIGIO信号给应用层
}
6.测试效果
如下图所示,当定时器expire成员<=jiffies时会进入一次定时器超时函数,我们按键驱动就不需要这个,因为按键并没有按下,所以需要进入定时器超时函数,需要先判断一次,避免误操作:

如下图所示,我们运行测试程序,来快速按下按键试试:

7.本节测试程序代码使用的是上一节: 阻塞操作的测试程序
8.本节驱动程序sixth.c代码:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <linux/irq.h>
#include <asm/irq.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <asm/uaccess.h>
#include <asm/io.h>
#include <linux/poll.h> static struct timer_list buttons_timer; //定义定时器结构体
struct pin_desc *irq_dev_id ; //定义全局变量获取dev_id static struct class *sixthdrv_class;
static struct class_device *sixthdrv_class_devs; /*定义互斥锁button_lock,被用来后面的down()和up()使用 */
static DECLARE_MUTEX(button_lock); /* 声明等待队列类型中断 button_wait */
static DECLARE_WAIT_QUEUE_HEAD(button_wait); /* 异步信号结构体变量 */
static struct fasync_struct * button_async; /*
* 定义中断事件标志
* 0:进入等待队列 1:退出等待队列
*/
static int even_press=; /*
* 定义全局变量key_val,保存key状态
*/
static int key_val=; /*
*引脚描述结构体
*/
struct pin_desc{
unsigned int pin;
unsigned int pin_status;
}; /*
*key初始状态(没有按下): 0x81,0x82,0x83,0x84
*key状态(按下): 0x01,0x02,0x03,0x04
*/
struct pin_desc pins_desc[]={
{S3C2410_GPF0,0x01 },
{S3C2410_GPF2, 0x02 },
{S3C2410_GPG3, 0x03 },
{S3C2410_GPG11,0x04},
} ; int sixth_drv_class(struct inode *inode, struct file *file) //卸载中断
{
free_irq(IRQ_EINT0,&pins_desc[]);
free_irq(IRQ_EINT2,&pins_desc[]);
free_irq(IRQ_EINT11,&pins_desc[]);
free_irq(IRQ_EINT19,&pins_desc[]); /*释放信号量*/
up(&button_lock); return ;
} /*
* 确定是上升沿还是下降沿
*/
static irqreturn_t buttons_irq (int irq, void *dev_id) //中断服务函数
{
irq_dev_id =(struct pin_desc *)dev_id; //获取引脚描述结构体 /*每产生一次中断,则更新定时器10ms超时 */
mod_timer(&buttons_timer, jiffies+HZ/); return IRQ_RETVAL(IRQ_HANDLED);
} static int sixth_drv_open(struct inode *inode, struct file *file)
{
if( file->f_flags & O_NONBLOCK ) //非阻塞操作,获取不到则退出
{
if(down_trylock(&button_lock) )
return -;
} else //阻塞操作,获取不到则进入休眠
{
down(&button_lock);
} request_irq(IRQ_EINT0,buttons_irq,IRQT_BOTHEDGE,"S1",&pins_desc[]);
request_irq(IRQ_EINT2, buttons_irq,IRQT_BOTHEDGE, "S2", &pins_desc[]);
request_irq(IRQ_EINT11, buttons_irq,IRQT_BOTHEDGE, "S3", &pins_desc[]);
request_irq(IRQ_EINT19, buttons_irq,IRQT_BOTHEDGE, "S4", &pins_desc[]); return ;
} static int sixth_drv_read(struct file *file, const char __user *buf, size_t count, loff_t * ppos)
{ if( file->f_flags & O_NONBLOCK ) //非阻塞操作,获取不到则退出
{
if(!even_press ) //没有按键按下
return -;
} /*阻塞操作,则直接进入休眠状态,直到有按键按下为止*/
/*进程 进入等待队列(休眠状态)*/
wait_event_interruptible(button_wait, even_press); /*有按键按下,退出等待队列,上传key_val 给用户层*/
if(copy_to_user(buf,&key_val,sizeof(key_val)))
return EFAULT;
even_press=;
return ;
} static unsigned sixth_poll(struct file *file, poll_table *wait)
{
unsigned int mask = ;
poll_wait(file, &button_wait, wait); // 不会立即休眠 if (even_press)
mask |= POLLIN | POLLRDNORM;
return mask;
} static int sixth_fasync (int fd, struct file *file, int on)
{
return fasync_helper(fd, file, on, & button_async); //初始化button_async结构体,就能使用kill_fasync()了
} static struct file_operations sixth_drv_fops={
.owner = THIS_MODULE,
.open = sixth_drv_open,
.read = sixth_drv_read,
.release=sixth_drv_class, //里面添加free_irq函数,来释放中断服务函数
.poll = sixth_poll,
.fasync= sixth_fasync, //初始化异步信号函数
}; static void buttons_timer_function(unsigned long data) //定时器超时函数
{
unsigned int pin_val=; if(!irq_dev_id) //定时器.expires成员=0,会进入一次,若irq_dev_id为0则退出
{printk("expires: timer out\n");
return ; } pin_val=s3c2410_gpio_getpin(irq_dev_id->pin);
if(pin_val)
{
/* 按下 (下降沿),清除0x80*/
key_val=irq_dev_id->pin_status&0xef;
}
else
{
/*没有按下(上升沿),加上0x80*/
key_val=irq_dev_id->pin_status|0x80;
} even_press=; //退出等待队列
wake_up_interruptible(&button_wait); //唤醒 中断
kill_fasync(&button_async, SIGIO, POLL_IN); //发送SIGIO信号给应用层 } volatile int sixth_major;
static int sixth_drv_init(void)
{
init_timer(&buttons_timer); //初始化定时器
buttons_timer. function= buttons_timer_function; //定时器超时函数
add_timer(&buttons_timer); //添加到内核中 sixth_major=register_chrdev(,"sixth_drv",&sixth_drv_fops); //创建驱动
sixthdrv_class=class_create(THIS_MODULE,"sixth_dev"); //创建类名
sixthdrv_class_devs=class_device_create(sixthdrv_class, NULL, MKDEV(sixth_major,), NULL,"buttons"); return ;
} static int sixth_drv_exit(void)
{
unregister_chrdev(sixth_major,"sixth_drv"); //卸载驱动
class_device_unregister(sixthdrv_class_devs); //卸载类设
class_destroy(sixthdrv_class); //卸载类
del_timer(&buttons_timer); //删除定时器
return ;
} module_init(sixth_drv_init);
module_exit(sixth_drv_exit);
MODULE_LICENSE("GPL v2");
}
Linux之输入子系统分析(详解)
在此节之前,我们学的都是简单的字符驱动,涉及的内容有字符驱动的框架、自动创建设备节点、linux中断、poll机制、异步通知、同步互斥/非阻塞、定时器去抖动。
其中驱动框架如下:
1)写file_operations结构体的成员函数: .open()、.read()、.write()
2)在入口函数里通过register_chrdev()创建驱动名,生成主设备号,赋入file_operations结构体
3)在出口函数里通过unregister_chrdev() 卸载驱动
若有多个不同的驱动程序时,应用程序就要打开多个不同的驱动设备,由于是自己写肯定会很清楚,如果给别人来使用时是不是很麻烦?
所以需要使用输入子系统, 使应用程序无需打开多个不同的驱动设备便能实现
1.输入子系统简介
同样的输入子系统也需要输入驱动的框架,好来辨认应用程序要打开的是哪个输入驱动
比如: 鼠标、键盘、游戏手柄等等这些都属于输入设备;这些输入设备的驱动都是通过输入子系统来实现的(当然,这些设备也依赖于usb子系统)
这些输入设备都各有不同,那么输入子系统也就只能实现他们的共性,差异性则由设备驱动来实现。差异性又体现在哪里?
最直观的就表现在这些设备功能上的不同了。对于我们写驱动的人来说在设备驱动中就只要使用输入子系统提供的工具(也就是函数)来完成这些“差异”就行了,其他的则是输入子系统的工作。这个思想不仅存在于输入子系统,其他子系统也是一样(比如:usb子系统、video子系统等)
所以我们先来分析下输入子系统input.c的代码,然后怎么来使用输入子系统(在内核中以input来形容输入子系统)
2.打开input.c,位于内核deivers/input
有以下这么两段:
subsys_initcall(input_init); //修饰入口函数 module_exit(input_exit); //修饰出口函数
显然输入子系统是作为一个模块存在,我们先来分析下input_int()入口函数
static int __init input_init(void)
{
int err;
err = class_register(&input_class); //(1)注册类,放在/sys/class
if (err) {
printk(KERN_ERR "input: unable to register input_dev class\n");
return err;
} err = input_proc_init(); //在/proc下面建立相关的文件
if (err)
goto fail1; err = register_chrdev(INPUT_MAJOR, "input", &input_fops); //(2)注册驱动
if (err) {
printk(KERN_ERR "input: unable to register char major %d", INPUT_MAJOR);
goto fail2;
} return ; fail2: input_proc_exit(); fail1: class_unregister(&input_class); return err; }
(1)上面第4行”err = class_register(&input_class);”是在/sys/class 里创建一个 input类, input_class变量如下图:

如下图,我们启动内核,再启动一个input子系统的驱动后,也可以看到创建了个"input"类 :
为什么这里代码只创建类,没有使用class_device_create()函数在类下面创建驱动设备?
在下面第8小结会详细讲到,这里简单描述:当注册input子系统的驱动后,才会有驱动设备,此时这里的代码是没有驱动的
(2)上面第14行通过register_chrdev创建驱动设备,其中变量INPUT_MAJOR =13,所以创建了一个主设备为13的"input"设备。
然后我们来看看它的操作结构体input_fops,如下图:

只有一个.open函数,比如当我们挂载一个新的input驱动,则内核便会调用该.open函数,接下来分析该.open函数
3 然后进入input_open_file函数(drivers/input/input.c)
static int input_open_file(struct inode *inode, struct file *file)
{
struct input_handler *handler = input_table[iminor(inode) >> ]; // (1)
const struct file_operations *old_fops, *new_fops = NULL;
int err; if (!handler || !(new_fops = fops_get(handler->fops))) //(2)
return -ENODEV; if (!new_fops->open) {
fops_put(new_fops);
return -ENODEV;
} old_fops = file->f_op;
file->f_op = new_fops; //(3) err = new_fops->open(inode, file); //(4)
if (err) {
fops_put(file->f_op);
file->f_op = fops_get(old_fops);
} fops_put(old_fops); return err;
}
(1)第3行中,其中iminor (inode)函数调用了MINOR(inode->i_rdev);读取子设备号,然后将子设备除以32,找到新挂载的input驱动的数组号,然后放在input_handler 驱动处理函数handler中
(2)第7行中,若handler有值,说明挂载有这个驱动,就将handler结构体里的成员file_operations * fops赋到新的file_operations *old_fops里面
(3)第16行中, 再将新的file_operations *old_fops赋到file-> file_operations *f_op里, 此时input子系统的file_operations就等于新挂载的input驱动的file_operations结构体,实现一个偷天换日的效果.
(4)第18行中,然后调用新挂载的input驱动的*old_fops里面的成员.open函数
4.上面代码的input_table[]数组在初始时是没有值的,
所以我们来看看input_table数组里面的数据又是在哪个函数里被赋值
在input.c函数(drivers/input/input.c)中搜索input_table,找到它在input_register_handler()函数中被赋值,代码如下:
int input_register_handler(struct input_handler *handler)
{
... ...
input_table[handler->minor >> ] = handler; //input_table[]被赋值
... ...
list_add_tail(&handler->node, &input_handler_list); //然后将这个input_handler放到input_handler_list链表中
... ...
}
就是将驱动处理程序input_handler注册到input_table[]中,然后放在input_handler_list链表中,后面会讲这个链表
5继续来搜索input_register_handler,看看这个函数被谁来调用
如下图所示,有evdev.c(事件设备),tsdev.c(触摸屏设备),joydev.c(joystick操作杆设备),keyboard.c(键盘设备),mousedev.c(鼠标设备) 这5个内核自带的设备处理函数注册到input子系统中

我们以evdev.c为例,它在evdev_ini()函数中注册:
static int __init evdev_init(void)
{
return input_register_handler(&evdev_handler); //注册
}
6我们来看看这个evdev_handler变量是什么结构体,:
static struct input_handler evdev_handler = {
.event = evdev_event,
.connect = evdev_connect, //(4)
.disconnect = evdev_disconnect,
.fops = &evdev_fops, //(1)
.minor = EVDEV_MINOR_BASE, //(2)
.name = "evdev",
.id_table = evdev_ids, //(3)
};
就是我们之前看的input_handler驱动处理结构体
(1) 第5行中.fops:文件操作结构体,其中evdev_fops函数就是自己的写的操作函数,然后赋到.fops中
(2)第6行中 .minor:用来存放次设备号
其中EVDEV_MINOR_BASE=64, 然后调用input_register_handler(&evdev_handler)后,由于EVDEV_MINOR_BASE/32=2,所以存到input_table[2]中
所以当open打开这个input设备,就会进入 input_open_file()函数,执行evdev_handler-> evdev_fops -> .open函数,如下图所示:

(3)第8行中.id_table : 表示能支持哪些输入设备,比如某个驱动设备的input_dev->的id和某个input_handler的id_table相匹配,就会调用.connect连接函数,如下图
(4)第3行中.connect:连接函数,将设备input_dev和某个input_handler建立连接,如下图
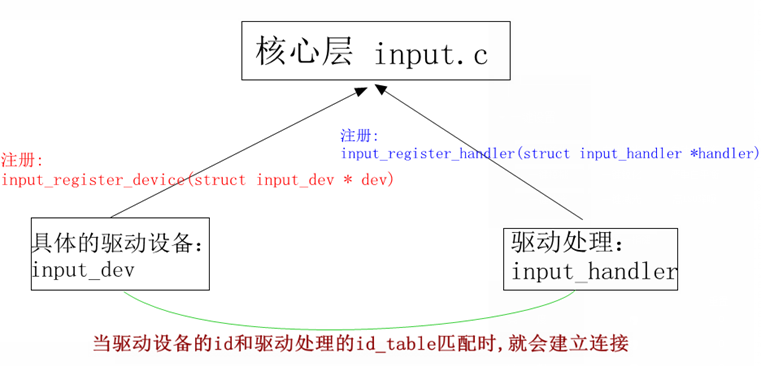
7我们先来看看上图的input_register_device()函数,如何创建驱动设备的
搜索input_register_device,发现内核自己就已经注册了很多驱动设备
7.1然后进入input_register_device()函数,代码如下:
int input_register_device(struct input_dev *dev) //*dev:要注册的驱动设备
{
... ...
list_add_tail(&dev->node, &input_dev_list); //(1)放入链表中
... ...
list_for_each_entry(handler, &input_handler_list, node) //(2)
input_attach_handler(dev, handler);
... ...
}
(1)第4行中,将要注册的input_dev驱动设备放在input_dev_list链表中
(2)第6行中,其中input_handler_list在前面讲过,就是存放每个input_handle驱动处理结构体,
然后list_for_each_entry()函数会将每个input_handle从链表中取出,放到handler中
最后会调用input_attach_handler()函数,将每个input_handle的id_table进行判断,若两者支持便进行连接。
7.2然后我们在回过头来看注册input_handler的input_register_handler()函数,如下图所示

所以,不管新添加input_dev还是input_handler,都会进入input_attach_handler()判断两者id是否有支持, 若两者支持便进行连接。
7.3我们来看看input_attach_handler()如何实现匹配两者id的:
static int input_attach_handler(struct input_dev *dev, struct input_handler *handler)
{
... ...
id = input_match_device(handler->id_table, dev); //匹配两者 if (!id) //若不匹配,return退出
return -ENODEV; error = handler->connect(handler, dev, id); //调用input_handler ->connect函数建立连接
... ... }
若两者匹配成功,就会自动进入input_handler 的connect函数建立连接
8我们还是以evdev.c(事件驱动) 的evdev_handler->connect函数
来分析是怎样建立连接的,如下图:

8.1 evdev_handler的.connect函数是evdev_connect(),代码如下:
static int evdev_connect(struct input_handler *handler, struct input_dev *dev, const struct input_device_id *id)
{
... ...
for (minor = ; minor < EVDEV_MINORS && evdev_table[minor]; minor++); //查找驱动设备的子设备号
if (minor == EVDEV_MINORS) { // EVDEV_MINORS=32,所以该事件下的驱动设备最多存32个,
printk(KERN_ERR "evdev: no more free evdev devices\n");
return -ENFILE; //没找到驱动设备
}
... ...
evdev = kzalloc(sizeof(struct evdev), GFP_KERNEL); //分配一个input_handle全局结构体(没有r)
... ...
evdev->handle.dev = dev; //指向参数input_dev驱动设备
evdev->handle.name = evdev->name;
evdev->handle.handler = handler; //指向参数 input_handler驱动处理结构体
evdev->handle.private = evdev;
sprintf(evdev->name, "event%d", minor); //(1)保存驱动设备名字, event%d
... ...
devt = MKDEV(INPUT_MAJOR, EVDEV_MINOR_BASE + minor), //(2) 将主设备号和次设备号转换成dev_t类型
cdev = class_device_create(&input_class, &dev->cdev, devt,dev->cdev.dev, evdev->name);
// (3)在input类下创建驱动设备 ... ...
error = input_register_handle(&evdev->handle); //(4)注册这个input_handle结构体 ... ...
}
(1) 第16行中,是在保存驱动设备名字,名为event%d, 比如下图(键盘驱动)event1: 因为没有设置子设备号,默认从小到大排列,其中event0是表示这个input子系统,所以这个键盘驱动名字就是event1
(2)第18行中,是在保存驱动设备的主次设备号,其中主设备号INPUT_MAJOR=13,因为EVDEV_MINOR_BASE=64,所以此设备号=64+驱动程序本事子设备号, 比如下图(键盘驱动)event1: 主次设备号就是13,65
(3)在之前在2小结里就分析了input_class类结构,所以第19行中,会在/sys/class/input类下创建驱动设备event%d,比如下图(键盘驱动)event1:

(4)最终会进入input_register_handle()函数来注册,代码在下面
8.2 input_register_handle()函数如下:
int input_register_handle(struct input_handle *handle)
{
struct input_handler *handler = handle->handler; //handler= input_handler驱动处理结构体 list_add_tail(&handle->d_node, &handle->dev->h_list); //(1)
list_add_tail(&handle->h_node, &handler->h_list); // (2) if (handler->start)
handler->start(handle);
return ;
}
(1)在第5行中, 因为handle->dev指向input_dev驱动设备,所以就是将handle->d_node放入到input_dev驱动设备的h_list链表中,
即input_dev驱动设备的h_list链表就指向handle->d_node
(2) 在第6行中, 同样, input_handler驱动处理结构体的h_list也指向了handle->h_node
最终如下图所示:

两者的.h_list都指向了同一个handle结构体,然后通过.h_list 来找到handle的成员.dev和handler,便能找到对方,便建立了连接
9建立了连接后,又如何读取evdev.c(事件驱动) 的evdev_handler->.fops->.read函数?
事件驱动的.read函数是evdev_read()函数,我们来分析下:
static ssize_t evdev_read(struct file *file, char __user * buffer, size_t count, loff_t *ppos)
{
... ...
/*判断应用层要读取的数据是否正确*/
if (count < evdev_event_size())
return -EINVAL; /*在非阻塞操作情况下,若client->head == client->tail|| evdev->exist时(没有数据),则return返回*/
if (client->head == client->tail && evdev->exist && (file->f_flags & O_NONBLOCK))
return -EAGAIN; /*若client->head == client->tail|| evdev->exist时(没有数据),等待中断进入睡眠状态 */
retval = wait_event_interruptible(evdev->wait,client->head != client->tail || !evdev->exist); ... ... //上传数据 }
10若read函数进入了休眠状态,又是谁来唤醒?
我们搜索这个evdev->wait这个等待队列变量,找到evdev_event函数里唤醒:
static void evdev_event(struct input_handle *handle, unsigned int type, unsigned int code, int value)
{
... ...
wake_up_interruptible(&evdev->wait); //有事件触发,便唤醒等待中断
}
其中evdev_event()是evdev.c(事件驱动) 的evdev_handler->.event成员,如下图所示:

当有事件发生了,比如对于按键驱动,当有按键按下时,就会进入.event函数中处理事件
11分析下,是谁调用evdev_event()这个.event事件驱动函数
应该就是之前分析的input_dev那层调用的
我们来看看内核 gpio_keys_isr()函数代码例子就知道了 (driver/input/keyboard/gpio_key.c)
static irqreturn_t gpio_keys_isr(int irq, void *dev_id)
{
/*获取按键值,赋到state里*/
... ... /*上报事件*/
input_event(input, type, button->code, !!state);
input_sync(input); //同步信号通知,表示事件发送完毕
}
显然就是通过input_event()来调用.event事件函数,我们来看看:
void input_event(struct input_dev *dev, unsigned int type, unsigned int code, int value)
{
struct input_handle *handle;
... ... /* 通过input_dev ->h_list链表找到input_handle驱动处理结构体*/
list_for_each_entry(handle, &dev->h_list, d_node)
if (handle->open) //如果input_handle之前open 过,那么这个就是我们的驱动处理结构体
handle->handler->event(handle, type, code, value); //调用evdev_event()的.event事件函数 }
若之前驱动input_dev和处理input_handler已经通过input_handler 的.connect函数建立起了连接,那么就调用evdev_event()的.event事件函数,如下图所示:
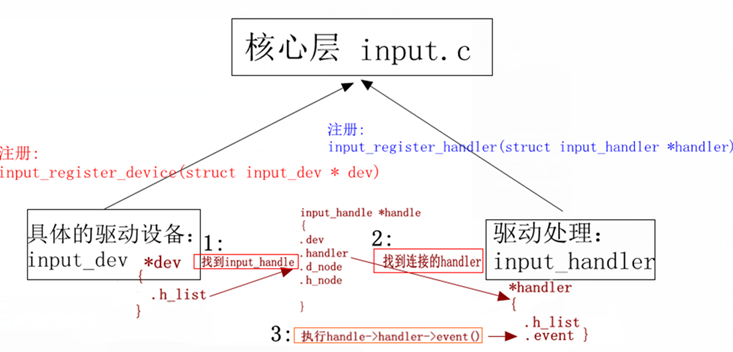
12本节总结分析:
1.注册输入子系统,进入put_init():
1)创建主设备号为13的"input"字符设备
err = register_chrdev(INPUT_MAJOR, "input", &input_fops);
2.open打开驱动,进入input_open_file():
1)更新设备的file_oprations
file->f_op=fops_get(handler->fops);
2)执行file_oprations->open函数
err = new_fops->open(inode, file);
3.注册input_handler,进入input_register_handler():
1)添加到input_table[]处理数组中
input_table[handler->minor >> ] = handler;
2)添加到input_handler_list链表中
list_add_tail(&handler->node, &input_handler_list);
3)判断input_dev的id,是否有支持这个驱动的设备
list_for_each_entry(dev, &input_dev_list, node) //遍历查找input_dev_list链表里所有input_dev input_attach_handler(dev, handler); //判断两者id,若两者支持便进行连接。
4.注册input_dev,进入input_register_device():
1)放在input_dev_list链表中
list_add_tail(&dev->node, &input_dev_list);
2)判断input_handler的id,是否有支持这个设备的驱动
list_for_each_entry(handler, &input_handler_list, node) //遍历查找input_handler_list链表里所有input_handler
input_attach_handler(dev, handler); //判断两者id,若两者支持便进行连接。
5.判断input_handler和input_dev的id,进入input_attach_handler():
1)匹配两者id,
input_match_device(handler->id_table, dev); //匹配input_handler和dev的id,不成功退出函数
2)匹配成功调用input_handler ->connect
handler->connect(handler, dev, id); //建立连接
6.建立input_handler和input_dev的连接,进入input_handler->connect():
1)创建全局结构体,通过input_handle结构体连接双方
evdev = kzalloc(sizeof(struct evdev), GFP_KERNEL); //创建两者连接的input_handle全局结构体
list_add_tail(&handle->d_node, &handle->dev->h_list); //连接input_dev->h_list
list_add_tail(&handle->h_node, &handler->h_list); // 连接input_handle->h_list
7.有事件发生时,比如按键中断,在中断函数中需要进入input_event()上报事件:
1)找到驱动处理结构体,然后执行input_handler->event()
list_for_each_entry(handle, &dev->h_list, d_node) // 通过input_dev ->h_list链表找到input_handle驱动处理结构体
if (handle->open) //如果input_handle之前open 过,那么这个就是我们的驱动处理结构体(有可能一个驱动设备在不同情况下有不同的驱动处理方式)
handle->handler->event(handle, type, code, value); //调用evdev_event()的.event事件函数
Linux键盘按键驱动 (详解)
在上一节分析输入子系统内的intput_handler软件处理部分后,接下来我们开始写input_dev驱动
本节目标:
实现键盘驱动,让开发板的4个按键代表键盘中的L、S、空格键、回车键
1.先来介绍以下几个结构体使用和函数,下面代码中会用到
1)input_dev驱动设备结构体中常用成员如下:
struct input_dev {
void *private;
const char *name; //设备名字
const char *phys; //文件路径,比如 input/buttons
const char *uniq;
struct input_id id;
unsigned long evbit[NBITS(EV_MAX)]; //表示支持哪类事件,常用有以下几种事件(可以多选)
//EV_SYN 同步事件,当使用input_event()函数后,就要使用这个上报个同步事件
//EV_KEY 键盘事件
//EV_REL (relative)相对坐标事件,比如鼠标
//EV_ABS (absolute)绝对坐标事件,比如摇杆、触摸屏感应
//EV_MSC 其他事件,功能
//EV_LED LED灯事件
//EV_SND (sound)声音事件
//EV_REP 重复键盘按键事件
//(内部会定义一个定时器,若有键盘按键事件一直按下/松开,就重复定时,时间一到就上报事件)
//EV_FF 受力事件
//EV_PWR 电源事件
//EV_FF_STATUS 受力状态事件
unsigned long keybit[NBITS(KEY_MAX)]; //存放支持的键盘按键值
//键盘变量定义在:include/linux/input.h, 比如: KEY_L(按键L)
unsigned long relbit[NBITS(REL_MAX)]; //存放支持的相对坐标值
unsigned long absbit[NBITS(ABS_MAX)]; //存放支持的绝对坐标值
unsigned long mscbit[NBITS(MSC_MAX)]; //存放支持的其它事件,也就是功能
unsigned long ledbit[NBITS(LED_MAX)]; //存放支持的各种状态LED
unsigned long sndbit[NBITS(SND_MAX)]; //存放支持的各种声音
unsigned long ffbit[NBITS(FF_MAX)]; //存放支持的受力设备
unsigned long swbit[NBITS(SW_MAX)]; //存放支持的开关功能
... ...
2)函数如下:
struct input_dev *input_allocate_device(void); //向内核中申请一个input_dev设备,然后返回这个设备 input_unregister_device(struct input_dev *dev); //卸载/sys/class/input目录下的input_dev这个类设备, 一般在驱动出口函数写 input_free_device(struct input_dev *dev); //释放input_dev这个结构体, 一般在驱动出口函数写 set_bit(nr,p); //设置某个结构体成员p里面的某位等于nr,支持这个功能
/* 比如:
set_bit(EV_KEY,buttons_dev->evbit); //设置input_dev结构体buttons_dev->evbit支持EV_KEY
set_bit(KEY_S,buttons_dev->keybit); //设置input_dev结构体buttons_dev->keybit支持按键”S”
*/ void input_event(struct input_dev *dev, unsigned int type, unsigned int code, int value); //上报事件
// input_dev *dev :要上报哪个input_dev驱动设备的事件
// type : 要上报哪类事件, 比如按键事件,则填入: EV_KEY
// code: 对应的事件里支持的哪个变量,比如按下按键L则填入: KEY_L
//value:对应的变量里的数值,比如松开按键则填入1,松开按键则填入0
input_sync(struct input_dev *dev); //同步事件通知
为什么使用了input_event()上报事件函数,就要使用这个函数?
因为input_event()函数只是个事件函数,所以需要这个input_sync()同步事件函数来通知系统,然后系统才会知道
input_sync()代码如下:
static inline void input_sync(struct input_dev *dev)
{
input_event(dev, EV_SYN, SYN_REPORT, ); //就是上报同步事件,告诉内核:input_event()事件执行完毕
}
2.然后开始写代码
1)向内核申请input_dev结构体
2)设置input_dev的成员
3)注册input_dev 驱动设备
4)初始化定时器和中断
5)写中断服务函数
6)写定时器超时函数
7)在出口函数中 释放中断函数,删除定时器,卸载释放驱动
具体代码如下(都加了注释):
#include <linux/module.h>
#include <linux/version.h>
#include <linux/init.h>
#include <linux/fs.h>
#include <linux/interrupt.h>
#include <linux/irq.h>
#include <linux/sched.h>
#include <linux/pm.h>
#include <linux/sysctl.h>
#include <linux/proc_fs.h>
#include <linux/delay.h>
#include <linux/platform_device.h>
#include <linux/input.h>
#include <linux/irq.h>
#include <linux/gpio_keys.h>
#include <asm/gpio.h> struct input_dev *buttons_dev; // 定义一个input_dev结构体
static struct ping_desc *buttons_id; //保存dev_id,在定时器中用
static struct timer_list buttons_timer; //定时器结构体 struct ping_desc{ unsigned char *name; //中断设备名称
int pin_irq; //按键的外部中断标志位
unsigned int pin; //引脚
unsigned int irq_ctl; //触发中断状态: IRQ_TYPE_EDGE_BOTH
unsigned int button; //dev_id,对应键盘的 L , S, 空格, enter
}; // KEY1 -> L
// KEY2 -> S
// KEY3 -> 空格
// KEY4 -> enter
static struct ping_desc buttons_desc[]=
{
{"s1", IRQ_EINT0, S3C2410_GPF0, IRQ_TYPE_EDGE_BOTH,KEY_L},
{"s2", IRQ_EINT2, S3C2410_GPF2, IRQ_TYPE_EDGE_BOTH,KEY_S},
{"s3", IRQ_EINT11, S3C2410_GPG3 , IRQ_TYPE_EDGE_BOTH,KEY_SPACE},
{"s4", IRQ_EINT19, S3C2410_GPG11,IRQ_TYPE_EDGE_BOTH,KEY_ENTER},
}; /*5. 写中断服务函数*/
static irqreturn_t buttons_irq (int irq, void *dev_id) //中断服务函数
{
buttons_id=(struct ping_desc *)dev_id; //保存当前的dev_id
mod_timer(&buttons_timer, jiffies+HZ/ ); //更新定时器值 10ms
return ;
} /*6.写定时器超时函数*/
void buttons_timer_function(unsigned long i)
{
int val;
val=s3c2410_gpio_getpin(buttons_id->pin); //获取是什么电平
if(val) //高电平,松开
{
/*上报事件*/
input_event(buttons_dev,EV_KEY,buttons_id->button, ); //上报EV_KEY类型,button按键,0(没按下)
input_sync(buttons_dev); // 上传同步事件,告诉系统有事件出现
} else //低电平,按下
{
/*上报事件*/
input_event(buttons_dev, EV_KEY, buttons_id->button, ); //上报EV_KEY类型,button按键,1(按下)
input_sync(buttons_dev); // 上传同步事件,告诉系统有事件出现
}
} static int buttons_init(void) //入口函数
{
int i;
buttons_dev=input_allocate_device(); //1.向内核 申请input_dev结构体
/*2.设置input_dev , */
set_bit(EV_KEY,buttons_dev->evbit); //支持键盘事件
set_bit(EV_REP,buttons_dev->evbit); //支持键盘重复按事件 set_bit(KEY_L,buttons_dev->keybit); //支持按键 L
set_bit(KEY_S,buttons_dev->keybit); //支持按键 S
set_bit(KEY_SPACE,buttons_dev->keybit); //支持按键 空格
set_bit(KEY_ENTER,buttons_dev->keybit); //支持按键 enter /*3.注册input_dev */
input_register_device(buttons_dev); /*4. 初始化硬件:初始化定时器和中断*/
// KEY1 -> L
// KEY2 -> S
// KEY3 -> 空格
// KEY4 -> enter
init_timer(&buttons_timer);
buttons_timer.function=buttons_timer_function;
add_timer(&buttons_timer); for(i=;i<;i++)
request_irq(buttons_desc[i].pin_irq, buttons_irq, buttons_desc[i].irq_ctl, buttons_desc[i].name, &buttons_desc[i]); return ;
} static int buttons_exit(void) //出口函数
{
/*7.释放中断函数,删除定时器,卸载释放驱动*/
int i;
for(i=;i<;i++)
free_irq(buttons_desc[i].pin_irq,&buttons_desc[i]); //释放中断函数 del_timer(&buttons_timer); //删除定时器 input_unregister_device(buttons_dev); //卸载类下的驱动设备
input_free_device(buttons_dev); //释放驱动结构体
return ;
} module_init(buttons_init);
module_exit(buttons_exit);
MODULE_LICENSE("GPL v2");
3.测试运行:
挂载键盘驱动后, 如下图,可以通过 ls -l /dev/event* 命令查看已挂载的设备节点:

在上一节输入子系统里分析到:输入子系统的主设备号为13,其中event驱动本身的此设备号是从64开始的,如上图,内核启动时,会加载自带触摸屏驱动,所以我们的键盘驱动的次设备号=64+1
3.1测试运行有两种,一种是直接打开/dev/tyy1,第二种是使用exec命令
(exec命令详解入口地址: http://www.cnblogs.com/lifexy/p/7553228.html)
方法1:
cat /dev/tty1 //tty1:LCD终端,就会通过tty_io.c来访问键盘驱动,然后打印在tty1终端上
方法2:
exec 0</dev/tty1 //将/dev/tty1挂载到-sh进程描述符0下,此时的键盘驱动就会直接打印在tty1终端上
3.2 调试:
若测试不成功,板子又在QT下进行的:
1)可以使用vi命令,在记事本中按按键试
2)或者删除/etc/init.d/rcS 里面有关QT自启动的命令,然后重启
若板子没在QT下进行,也无法测试成功:
1)可以使用hexdump命令来调试代码
(hexdump命令调试代码详解地址:http://www.cnblogs.com/lifexy/p/7553550.html)
linux-platform机制实现驱动层分离(详解)
本节目标:
学习platform机制,如何实现驱动层分离
1.先来看看我们之前分析输入子系统的分层概念,如下图所示:
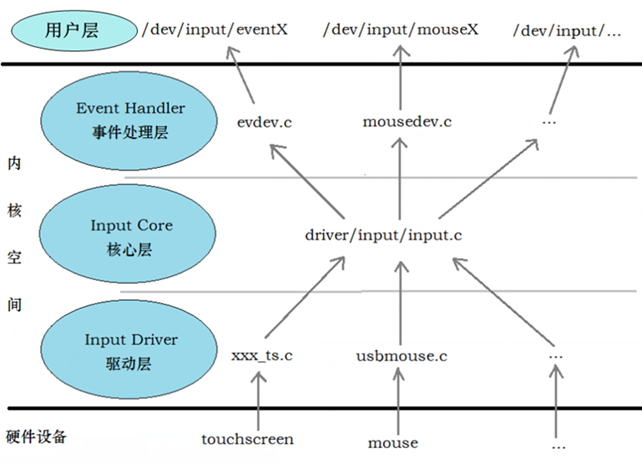
如上图所示,分层就是将一个复杂的工作分成了4层, 分而做之,降低难度,每一层专注于自己的事情, 系统只将其中的核心层和事件处理层写好了,所以我们只需要来写驱动层即可,接下来我们来分析platform机制以及分离概念
2.分离概念
优点:
- 将所有设备挂接到一个虚拟的总线上,方便sysfs节点和设备电源的管理
- 使得驱动代码,具有更好的扩展性和跨平台性,就不会因为新的平台而再次编写驱动
介绍:
分离就是在驱动层中使用platform机制把硬件相关的代码(固定的,如板子的网卡、中断地址)和驱动(会根据程序作变动,如点哪一个灯)分离开来,即要编写两个文件:dev.c和drv.c(platform设备和platform驱动)
3.platform机制
基本内容:
platform会存在/sys/bus/里面
如下图所示, platform目录下会有两个文件,分别就是platform设备和platform驱动

1) device设备
挂接在platform总线下的设备, platform_device结构体类型
2) driver驱动
挂接在platform总线下,是个与某种设备相对于的驱动, platform_driver结构体类型
3) platform总线
是个全局变量,为platform_bus_type,属于虚拟设备总线,通过这个总线将设备和驱动联系起来,属于Linux中bus的一种
该platform_bus_type的结构体定义如下所示(位于drivers/base):
struct bus_type platform_bus_type = {
.name = "platform", //设备名称
.dev_attrs = platform_dev_attrs, //设备属性、含获取sys文件名,该总线会放在/sys/bus下
.match = platform_match, //匹配设备和驱动,匹配成功就调用driver的.probe函数
.uevent = platform_uevent, //消息传递,比如热插拔操作
.suspend = platform_suspend, //电源管理的低功耗挂起
.suspend_late = platform_suspend_late, //电源管理的恢复、唤醒
.resume_early = platform_resume_early,
.resume = platform_resume,
};
驱动、设备注册匹配图如下所示:
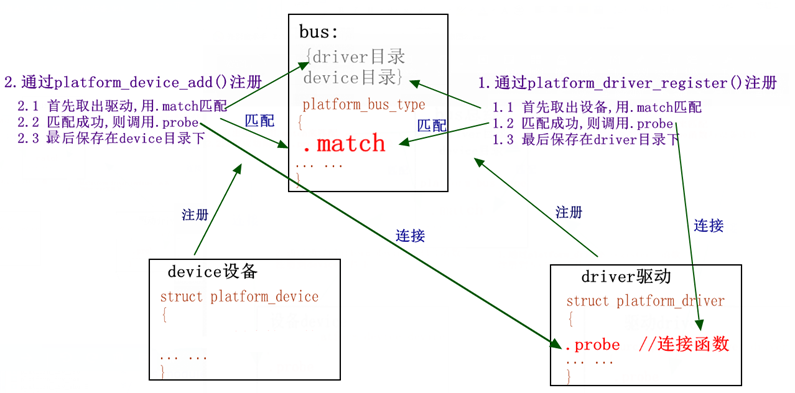
只要有一方注册,就会调用platform_bus_type的.match匹配函数,来找对方,成功就调用driver驱动结构体里的.probe函数来使总线将设备和驱动联系起来
4.实例-分析driver驱动:
我们以/drivers/input/keybard/gpio_keys.c内核自带的示例程序为例,
它的代码中只有driver驱动,因为是个示例程序,所以没有device硬件设备代码
4.1发现在gpio_keys.c中有1个全局变量driver驱动:
struct platform_driver gpio_keys_device_driver = { //定义一个platform_driver类型驱动
.probe = gpio_keys_probe, //设备的检测,当匹配成功就会调用这个函数(需要自己编写)
.remove = __devexit_p(gpio_keys_remove), //删除设备(需要自己编写)
.driver = {
.name = "gpio-keys", //驱动名称,用来与设备名称匹配用的
}
};
4.2然后来找找这个gpio_keys_device_driver被谁用到
发现在驱动层init入口函数中通过platform_driver_register()来注册diver驱动
在驱动层exit出口函数中通过platform_driver_unregister()函数来注销diver驱动
代码如下:
static int __init gpio_keys_init(void) //init出口函数
{
return platform_driver_register(&gpio_keys_device_driver); //注册driver驱动
} static void __exit gpio_keys_exit(void) //exit出口函数
{
platform_driver_unregister(&gpio_keys_device_driver); //注销driver驱动
}
3.3我们进来platform_driver_register(),看它是如何注册diver的,注册到哪里?
platform_driver_register()函数如下:
int platform_driver_register(struct platform_driver *drv)
{
drv->driver.bus = &platform_bus_type; //(1)挂接到虚拟总线platform_bus_type上
if (drv->probe)
drv->driver.probe = platform_drv_probe;
if (drv->remove)
drv->driver.remove = platform_drv_remove;
if (drv->shutdown)
drv->driver.shutdown = platform_drv_shutdown;
if (drv->suspend)
drv->driver.suspend = platform_drv_suspend;
if (drv->resume)
drv->driver.resume = platform_drv_resume; return driver_register(&drv->driver); //(2) 注册到driver目录下
}
(1) 挂接到虚拟总线platform_bus_type上,然后会调用platform_bus_type下的platform_match匹配函数,来匹配device和driver的名字,其中driver的名字如下图所示:
platform_match()匹配函数如下所示:
static int platform_match(struct device * dev, struct device_driver * drv)
{
/*找到所有的device设备*/
struct platform_device *pdev = container_of(dev, struct platform_device, dev); return (strncmp(pdev->name, drv->name, BUS_ID_SIZE) == ); //找BUS_ID_SIZE次
}
若名字匹配成功,则调用device的.probe成员函数
(2)然后放到/sys/bus/platform/driver目录下,其中driver_register()函数就是用来创建dirver目录的
5. 使用platform机制,编写LED驱动层
首先创建设备代码和驱动代码:led_dev.c 、led_drv.c
led_dev.c用来指定灯的引脚地址,当更换平台时,只需要修改这个就行
led_drv.c用来初始化灯以及如何控制灯的逻辑,当更换控制逻辑时,只需要修改这个就行
6.编写led.dev.c
6.1编写led_dev.c之前先来看看platform_device结构体和要使用的函数:
platform_device结构体如下:
struct platform_device {
const char * name; //设备名称,要与platform_driver的name一样,这样总线才能匹配成功
u32 id; //id号,插入总线下相同name的设备编号(一个驱动可以有多个设备),如果只有一个设备填-1
struct device dev; //内嵌的具体的device结构体,其中成员.release函数不可缺少
u32 num_resources; //资源数量,
struct resource * resource; //资源结构体,保存设备的信息
};
其中resource资源结构体,如下:
struct resource {
resource_size_t start; //起始资源,如果是地址的话,必须是物理地址
resource_size_t end; //结束资源,如果是地址的话,必须是物理地址
const char *name; //资源名
unsigned long flags; //资源的标志
//比如IORESOURCE_MEM,表示地址资源, IORESOURCE_IRQ表示中断引脚... ...
struct resource *parent, *sibling, *child; //资源拓扑指针父、兄、子,可以构成链表
};
要用的函数如下,在dev设备的入口出口函数中用到
int platform_device_register(struct platform_device * pdev); //注册dev设备
int platform_device_register(struct platform_device * pdev); //注销dev设备
6.2接下来开始写代码
1)先写要注册的led设备:platform_device结构体
#include <linux/module.h>
#include <linux/version.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/types.h>
#include <linux/interrupt.h>
#include <linux/list.h>
#include <linux/timer.h>
#include <linux/init.h>
#include <linux/serial_core.h>
#include <linux/platform_device.h> static struct resource led_resource[] = { //资源数组
[] = {
.start = 0x56000050, //led的寄存器GPFCON起始地址
.end = 0x56000050 + - , // led的寄存器GPFDAT结束地址
.flags = IORESOURCE_MEM, //表示地址资源
},
[] = {
.start = , //表示GPF第几个引脚开始
.end = , //结束引脚
.flags = IORESOURCE_IRQ, //表示中断资源
}
}; static void led_release(struct device * dev) //释放函数
{} static struct platform_device led_dev = {
.name = "myled", //对应的platform_driver驱动的名字
.id = -, //表示只有一个设备
.num_resources = ARRAY_SIZE(led_resource), //资源数量,ARRAY_SIZE()函数:获取数量
.resource = led_resource, //资源数组led_resource
.dev = {
.release = led_release, //释放函数,必须向内核提供一个release函数, 、
//否则卸载时,内核找不到该函数会报错
},
};
2)最后写出口入口函数:
static int led_dev_init(void) //入口函数,注册dev设备
{
platform_device_register(&led_dev);
return ;
} static void led_dev_exit(void) //出口函数,注销dev设备
{
platform_device_unregister(&led_dev);
}
module_init(led_dev_init); //修饰入口函数
module_exit(led_dev_exit); //修饰出口函数
MODULE_LICENSE("GPL"); //声明函数
7.编写led.drv.c
7.1编写led_dev.c之前先来看看platform_device结构体和要使用的函数:
struct platform_driver {
int (*probe)(struct platform_device *); //查询设备的存在
int (*remove)(struct platform_device *); //删除
void (*shutdown)(struct platform_device *); //断电
int (*suspend)(struct platform_device *, pm_message_t state); //休眠
int (*suspend_late)(struct platform_device *, pm_message_t state);
int (*resume_early)(struct platform_device *);
int (*resume)(struct platform_device *); //唤醒
struct device_driver driver; //内嵌的driver,其中的name成员要等于设备的名称才能匹配
};
int platform_driver_register(struct platform_driver *drv); //注册驱动
platform_driver_unregister(struct platform_driver *drv); //卸载驱动
struct resource * platform_get_resource(struct platform_device *dev, unsigned int type,unsigned int num);
//获取设备的某个资源,获取成功,则返回一个resource资源结构体
//参数:
// *dev :指向某个platform device设备
// type:获取的资源类型
// num: type资源下的第几个数组
7.2接下来开始写代码
1)先写要注册的led驱动:platform_driver结构体
/*函数声明*/
static int led_remove(struct platform_device *led_dev);
static int led_probe(struct platform_device *led_dev); struct platform_driver led_drv = {
.probe = led_probe, //当与设备匹配,则调用该函数
.remove = led_remove, //删除设备 .driver = {
.name = "myled", //与设备名称一样
}
};
2)写file_operations 结构体、以及成员函数(.open、.write)、.probe函数、
当驱动和设备都insmod加载后,然后bus总线会匹配成功,就进入.probe函数,
在.probe函数中便使用platform_get_resource()函数获取LED的地址和引脚,然后初始化LED,并注册字符设备和设备节点"led"
static struct class *cls; //类,用来注册,和注销
static volatile unsigned long *gpio_con; //被file_operations的.open函数用
static volatile unsigned long *gpio_dat; //被file_operations的.write函数用
static int pin; //LED位于的引脚值 static int led_open(struct inode *inode, struct file *file)
{
*GPFcon&=~(0x03<<(LED_PIN*));
*GPFcon|=(0x01<<(LED_PIN*));
return ;
} static ssize_t led_write(struct file *file, const char __user *buf, size_t count, loff_t * ppos)
{
int val=;
if(count!=)
return -EINAL;
copy_from_user(&val,buf,count); //从用户(应用层)拷贝数据 if(val) //开灯
{
*GPFdat&=~(0x1<<LED_PIN);
}
else
{
*GPFdat |= (0x1<<LED_PIN);
}
return ;
} static struct file_operations led_fops= {
.owner = THIS_MODULE, //被使用时阻止模块被卸载
.open = led_open,
.write = led_write,
}; static int led_probe(struct platform_device *pdev)
{
struct resource *res;
printk("enter probe\n"); /* 根据platform_device的资源进行ioremap */
res = platform_get_resource(pdev, IORESOURCE_MEM, ); //获取寄存器地址
gpio_con = ioremap(res->start, res->end - res->start + ); //获取虚拟地址
gpio_dat = gpio_con + ; res = platform_get_resource(pdev, IORESOURCE_IRQ, ); //获取引脚值
pin = res->start; /* 注册字符设备驱动程序 */
major = register_chrdev(, "myled", &led_fops); //赋入file_operations结构体
cls = class_create(THIS_MODULE, "myled");
class_device_create(cls, NULL, MKDEV(major, ), NULL, "led"); /* /dev/led */
return ;
}
3)写.remove函数
如果驱动与设备已联系起来,当卸载驱动时,就会调用.remove函数卸载设备
和.probe函数一样,注册了什么就卸载什么便可
static int led_remove(struct platform_device *pdev)
{
/* 卸载字符设备驱动程序 */
printk("enter remove\n");
class_device_destroy(cls, MKDEV(major, ));
class_destroy(cls);
unregister_chrdev(major, "myled"); iounmap(gpio_con); //注销虚拟地址
return ;
}
4)最后写drv的入口出口函数
static int led_drv_init(void) //入口函数,注册驱动
{
platform_driver_register(&led_drv);
return 0;
}
static void led_drv_exit(void) //出口函数,卸载驱动
{
platform_driver_unregister(&led_drv);
} module_init(led_drv_init);
module_exit(led_drv_exit);
MODULE_LICENSE("GPL");
8.测试运行
1)如下图,我们先挂载dev设备模块,和我们之前分析的一样,它在platform/devices目录下生成一个"myled"设备

2)如下图,我们再来挂载drv驱动模块,同样的在platform/drivers目录下生成一个"myled"驱动,devices目录下的"myled"设备匹配成功,进入.probe函数创建设备,接下来就可以使用应用程序来控制led灯了
3)如下图,卸载驱动时,也会进入.remove函数卸载设备

Linux-块设备驱动之框架详细分析(详解)
本节目的:
通过分析2.6内核下的块设备驱动框架,知道如何来写驱动
1.之前我们学的都是字符设备驱动,先来回忆一下
字符设备驱动:
当我们的应用层读写(read()/write())字符设备驱动时,是按字节/字符来读写数据的,期间没有任何缓存区,因为数据量小,不能随机读取数据,例如:按键、LED、鼠标、键盘等
2.接下来本节开始学习块设备驱动
块设备:
块设备是i/o设备中的一类, 当我们的应用层对该设备读写时,是按扇区大小来读写数据的,若读写的数据小于扇区的大小,就会需要缓存区, 可以随机读写设备的任意位置处的数据,例如 普通文件(*.txt,*.c等),硬盘,U盘,SD卡,
3.块设备结构:
- 段(Segments):由若干个块组成。是Linux内存管理机制中一个内存页或者内存页的一部分。
- 块 (Blocks): 由Linux制定对内核或文件系统等数据处理的基本单位。通常由1个或多个扇区组成。(对Linux操作系统而言)
- 扇区(Sectors):块设备的基本单位。通常在512字节到32768字节之间,默认512字节
4.我们以txt文件为例,来简要分析下块设备流程:
比如:当我们要写一个很小的数据到txt文件某个位置时, 由于块设备写的数据是按扇区为单位,但又不能破坏txt文件里其它位置,那么就引入了一个“缓存区”,将所有数据读到缓存区里,然后修改缓存数据,再将整个数据放入txt文件对应的某个扇区中,当我们对txt文件多次写入很小的数据的话,那么就会重复不断地对扇区读出,写入,这样会浪费很多时间在读/写硬盘上,所以内核提供了一个队列的机制,再没有关闭txt文件之前,会将读写请求进行优化,排序,合并等操作,从而提高访问硬盘的效率
(PS:内核中是通过elv_merge()函数实现将队列优化,排序,合并,后面会分析到)
5.接下来开始分析块设备框架
当我们对一个*.txt写入数据时,文件系统会转换为对块设备上扇区的访问,也就是调用ll_rw_block()函数,从这个函数开始就进入了设备层.
5.1先来分析ll_rw_block()函数(/fs/buffer.c):
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[])
//rw:读写标志位, nr:bhs[]长度, bhs[]:要读写的数据数组
{
int i;
for (i = ; i < nr; i++) {
struct buffer_head *bh = bhs[i]; //获取nr个buffer_head
... ...
if (rw == WRITE || rw == SWRITE) {
if (test_clear_buffer_dirty(bh)) {
... ...
submit_bh(WRITE, bh); //提交WRITE写标志的buffer_head
continue;
}}
else {
if (!buffer_uptodate(bh)) {
... ...
submit_bh(rw, bh); //提交其它标志的buffer_head
continue;
}}
unlock_buffer(bh); }
}
其中buffer_head结构体,就是我们的缓冲区描述符,存放缓存区的各种信息,结构体如下所示:
struct buffer_head {
unsigned long b_state; //缓冲区状态标志
struct buffer_head *b_this_page; //页面中的缓冲区
struct page *b_page; //存储缓冲区位于哪个页面
sector_t b_blocknr; //逻辑块号
size_t b_size; //块的大小
char *b_data; //页面中的缓冲区
struct block_device *b_bdev; //块设备,来表示一个独立的磁盘设备
bh_end_io_t *b_end_io; //I/O完成方法
void *b_private; //完成方法数据
struct list_head b_assoc_buffers; //相关映射链表
/* mapping this buffer is associated with */
struct address_space *b_assoc_map;
atomic_t b_count; //缓冲区使用计数
};
5.2然后进入submit_bh()中, submit_bh()函数如下:
int submit_bh(int rw, struct buffer_head * bh)
{
struct bio *bio; //定义一个bio(block input output),也就是块设备i/o
... ...
bio = bio_alloc(GFP_NOIO, ); //分配bio
/*根据buffer_head(bh)构造bio */
bio->bi_sector = bh->b_blocknr * (bh->b_size >> ); //存放逻辑块号
bio->bi_bdev = bh->b_bdev; //存放对应的块设备
bio->bi_io_vec[].bv_page = bh->b_page; //存放缓冲区所在的物理页面
bio->bi_io_vec[].bv_len = bh->b_size; //存放扇区的大小
bio->bi_io_vec[].bv_offset = bh_offset(bh); //存放扇区中以字节为单位的偏移量 bio->bi_vcnt = ; //计数值
bio->bi_idx = ; //索引值
bio->bi_size = bh->b_size; //存放扇区的大小 bio->bi_end_io = end_bio_bh_io_sync; //设置i/o回调函数
bio->bi_private = bh; //指向哪个缓冲区
... ...
submit_bio(rw, bio); //提交bio
... ...
}
submit_bh()函数就是通过bh来构造bio,然后调用submit_bio()提交bio
5.3 submit_bio()函数如下:
void submit_bio(int rw, struct bio *bio)
{
... ...
generic_make_request(bio);
}
最终调用generic_make_request(),把bio数据提交到相应块设备的请求队列中,generic_make_request()函数主要是实现对bio的提交处理
5.4 generic_make_request()函数如下所示:
void generic_make_request(struct bio *bio)
{
if (current->bio_tail) { // current->bio_tail不为空,表示有bio正在提交
*(current->bio_tail) = bio; //将当前的bio放到之前的bio->bi_next里面
bio->bi_next = NULL; //更新bio->bi_next=0;
current->bio_tail = &bio->bi_next; //然后将当前的bio->bi_next放到current->bio_tail里,使下次的bio就会放到当前bio->bi_next里面了
return; }
BUG_ON(bio->bi_next);
do {
current->bio_list = bio->bi_next;
if (bio->bi_next == NULL)
current->bio_tail = ¤t->bio_list;
else
bio->bi_next = NULL; __generic_make_request(bio); //调用__generic_make_request()提交bio
bio = current->bio_list;
} while (bio);
current->bio_tail = NULL; /* deactivate */
}
从上面的注释和代码分析到,只有当第一次进入generic_make_request()时, current->bio_tail为NULL,才能调用__generic_make_request().
__generic_make_request()首先由bio对应的block_device获取申请队列q,然后要检查对应的设备是不是分区,如果是分区的话要将扇区地址进行重新计算,最后调用q的成员函数make_request_fn完成bio的递交.
5.5 __generic_make_request()函数如下所示:
static inline void __generic_make_request(struct bio *bio)
{
request_queue_t *q;
int ret;
... ...
do {
q = bdev_get_queue(bio->bi_bdev); //通过bio->bi_bdev获取申请队列q
... ...
ret = q->make_request_fn(q, bio); //提交申请队列q和bio
} while (ret);
}
这个q->make_request_fn()又是什么函数?到底做了什么,我们搜索下它在哪里被初始化的
如下图,搜索make_request_fn,它在blk_queue_make_request()函数中被初始化mfn这个参数
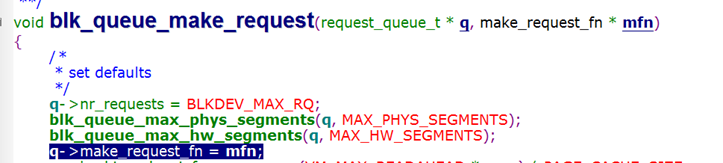
继续搜索blk_queue_make_request,找到它被谁调用,赋入的mfn参数是什么
如下图,找到它在blk_init_queue_node()函数中被调用

最终q->make_request_fn()执行的是__make_request()函数
5.6我们来看看__make_request()函数,对提交的申请队列q和bio做了什么
static int __make_request(request_queue_t *q, struct bio *bio)
{ struct request *req; //块设备本身的队列
... ...
//(1)将之前的申请队列q和传入的bio,通过排序,合并在本身的req队列中
el_ret = elv_merge(q, &req, bio);
... ... init_request_from_bio(req, bio); //合并失败,单独将bio放入req队列
add_request(q, req); //单独将之前的申请队列q放入req队列
... ...
__generic_unplug_device(q); //(2) 执行申请队列的处理函数
}
1)上面的elv_merge()函数,就是内核中的电梯算法(elevator merge),它就类似我们坐的电梯,通过一个标志,向上或向下.
比如申请队列中有以下6个申请:
4(in),2(out),5(in),3(out),6(in),1(out) //其中in:写出队列到扇区,ou:读入队列
最后执行下来,就会排序合并,先写出4,5,6,队列,再读入1,2,3队列
2) 上面的__generic_unplug_device()函数如下:
void __generic_unplug_device(request_queue_t *q)
{ if (unlikely(blk_queue_stopped(q)))
return;
if (!blk_remove_plug(q))
return;
q->request_fn(q);
}
最终执行q的成员request_fn()函数, 执行申请队列的处理函数
6.本节框架分析总结,如下图所示:

7.其中q->request_fn是一个request_fn_proc结构体,如下图所示:
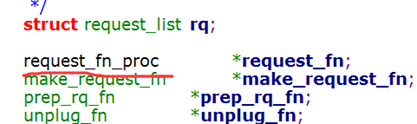
7.1那这个申请队列q->request_fn又是怎么来的?
我们参考自带的块设备驱动程序drivers\block\xd.c
在入口函数中发现有这么一句:
static struct request_queue *xd_queue; //定义一个申请队列xd_queue xd_queue = blk_init_queue(do_xd_request, &xd_lock); //分配一个申请队列
其中blk_init_queue()函数原型如下所示:
request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);
// *rfn: request_fn_proc结构体,用来执行申请队列中的处理函数
// *lock:队列访问权限的自旋锁(spinlock),该锁需要通过DEFINE_SPINLOCK()函数来定义
显然就是将do_xd_request()挂到xd_queue->request_fn里.然后返回这个request_queue队列
7.2我们再看看申请队列的处理函数 do_xd_request()是如何处理的,函数如下:
static void do_xd_request (request_queue_t * q)
{
struct request *req; if (xdc_busy)
return; while ((req = elv_next_request(q)) != NULL) //(1)while获取申请队列中的需要处理的申请
{
int res = ;
... ...
for (retry = ; (retry < XD_RETRIES) && !res; retry++)
res = xd_readwrite(rw, disk, req->buffer, block, count);
//将获取申请req的buffer成员 读写到disk扇区中,当读写失败返回0,成功返回1
end_request(req, res); //申请队列中的的申请已处理结束,当res=0,表示读写失败
}
}
(1)为什么要while一直获取?
因为这个q是个申请队列,里面会有多个申请,之前是使用电梯算法elv_merge()函数合并的,所以获取也要通过电梯算法elv_next_request()函数获取.
通过上面代码和注释,内核中的申请队列q最终都是交给驱动处理,由驱动来对扇区读写
8.接下来我们就看看drivers\block\xd.c的入口函数大概流程,是如何创建块设备驱动的
static DEFINE_SPINLOCK(xd_lock); //定义一个自旋锁,用到申请队列中
static struct request_queue *xd_queue; //定义一个申请队列xd_queue static int __init xd_init(void) //入口函数
{
if (register_blkdev(XT_DISK_MAJOR, "xd")) //1.创建一个块设备,保存在/proc/devices中
goto out1; xd_queue = blk_init_queue(do_xd_request, &xd_lock); //2.分配一个申请队列,后面会赋给gendisk结构体的queue成员
... ... for (i = ; i < xd_drives; i++) {
... ...
struct gendisk *disk = alloc_disk(); //3.分配一个gendisk结构体, 64:次设备号个数,也称为分区个数
/* 4.接下来设置gendisk结构体 */
disk->major = XT_DISK_MAJOR; //设置主设备号
disk->first_minor = i<<; //设置次设备号
disk->fops = &xd_fops; //设置块设备驱动的操作函数
disk->queue = xd_queue; //设置queue申请队列,用于管理该设备IO申请队列
... ... xd_gendisk[i] = disk;
} ... ...
for (i = ; i < xd_drives; i++)
add_disk(xd_gendisk[i]); //5.注册gendisk结构体
}
其中gendisk(通用磁盘)结构体是用来存储该设备的硬盘信息,包括请求队列、分区链表和块设备操作函数集等,结构体如下所示:
struct gendisk {
int major; /*设备主设备号*/
int first_minor; /*起始次设备号*/
int minors; /*次设备号的数量,也称为分区数量,如果改值为1,表示无法分区*/
char disk_name[]; /*设备名称*/
struct hd_struct **part; /*分区表的信息*/
int part_uevent_suppress;
struct block_device_operations *fops; /*块设备操作集合 */
struct request_queue *queue; /*申请队列,用于管理该设备IO申请队列的指针*/
void *private_data; /*私有数据*/
sector_t capacity; /*扇区数,512字节为1个扇区,描述设备容量*/
....
};
9.所以注册一个块设备驱动,需要以下步骤:
- 创建一个块设备
- 分配一个申请队列
- 分配一个gendisk结构体
- 设置gendisk结构体的成员
- 注册gendisk结构体
未完待续~ ~下节便开始写块设备驱动程序
Linux-块设备驱动(详解)
通过上节的块设备驱动分析,本节便通过内存来模拟块设备驱动 ,方便我们更加熟悉块设备驱动框架
参考内核自带的块设备驱动程序:
drivers/block /xd.c
drivers/block /z2ram.c
1.本节需要的结构体如下:
1.1 gendisk磁盘结构体:
struct gendisk {
int major; //设备主设备号,等于register_blkdev()函数里的major
int first_minor; //起始次设备号,等于0,则表示此设备号从0开始的
int minors; //分区(次设备)数量,当使用alloc_disk()时,就会自动设置该成员
char disk_name[]; //块设备名称, 等于register_blkdev()函数里的name
struct hd_struct **part; /*分区表的信息*/
int part_uevent_suppress;
struct block_device_operations *fops; //块设备操作函数
struct request_queue *queue; //请求队列,用于管理该设备IO请求队列的指针*
void *private_data; /*私有数据*/
sector_t capacity; /*扇区数,512字节为1个扇区,描述设备容量*/
....
};
1.2 request申请结构体:
struct request {
//用于挂在请求队列链表的节点,使用函数elv_next_request()访问它,而不能直接访问
struct list_head queuelist;
struct list_head donelist; /*用于挂在已完成请求链表的节点*/
struct request_queue *q; /*指向请求队列*/
unsigned int cmd_flags; /*命令标识*/
enum rq_cmd_type_bits cmd_type; //读写命令标志,为 0(READ)表示读, 为1(WRITE)表示写
sector_t sector; //要提交的下一个扇区偏移位置(offset)
... ...
unsigned int current_nr_sectors; //当前需要传送的扇区数(长度)
... ...
char *buffer; //当前请求队列链表的申请里面的数据,用来读写扇区数据(源地址)
... ...
};
2.本节需要的函数如下:
int register_blkdev(unsigned int major, const char *name);
创建一个块设备,当major==0时,表示动态创建,创建成功会返回一个主设备号
unregister_blkdev(unsigned int major, const char *name);
卸载一个块设备, 在出口函数中使用,major:主设备号, name:名称
struct gendisk *alloc_disk(int minors);
分配一个gendisk结构,minors为分区数,填1表示不分区
void del_gendisk(struct gendisk *disk);
释放gendisk结构,在出口函数中使用,也就是不需要这个磁盘了
request_queue *blk_init_queue(request_fn_proc *rfn, spinlock_t *lock);
分配一个request_queue请求队列,分配成功返回一个request_queue结构体
rfn: request_fn_proc结构体,用来执行放置在队列中的请求的处理函数
lock:队列访问权限的自旋锁(spinlock),该锁通过DEFINE_SPINLOCK()来定义
void blk_cleanup_queue(request_queue_t * q);
清除内核中的request_queue请求队列,在出口函数中使用
static DEFINE_SPINLOCK(spinlock_t lock);
定义一个自旋锁(spinlock)
static inline void set_capacity(struct gendisk *disk, sector_t size);
设置gendisk结构体的扇区数(成员copacity), size等于扇区数
该函数内容如下:
disk->capacity = size;
void add_disk(struct gendisk *gd);
向内核中注册gendisk结构体
void put_disk(struct gendisk *disk);
注销内核中的gendisk结构体,在出口函数中使用
struct request *elv_next_request(request_queue_t *q);
通过电梯算法获取申请队列中未完成的申请,获取成功返回一个request结构体,不成功返回NULL
(PS: 不使用获取到的这个申请时,应使用end_request()来结束获取申请)
void end_request(struct request *req, int uptodate);
结束获取申请, 当uptodate==0,表示使用该申请读写扇区失败, uptodate==1,表示成功
static inline void *kzalloc(size_t size, gfp_t flags);
分配一段静态缓存,这里用来当做我们的磁盘扇区用,分配成功返回缓存地址,分配失败会返回0
void kfree(const void *block);
注销一段静态缓存,与kzalloc()成对,在出口函数中使用
rq_data_dir(rq);
获取request申请结构体的命令标志(cmd_flags成员),当返回READ(0)表示读扇区命令,否则为写扇区命令
3.步骤如下:
3.1在入口函数中:
- 1)使用register_blkdev()创建一个块设备
- 2) blk_init_queue()使用分配一个申请队列,并赋申请队列处理函数
- 3)使用alloc_disk()分配一个gendisk结构体
- 4)设置gendisk结构体的成员
- ->4.1)设置成员参数(major、first_minor、disk_name、fops)
- ->4.2)设置queue成员,等于之前分配的申请队列
- ->4.3)通过set_capacity()设置capacity成员,等于扇区数
- 5)使用kzalloc()来获取缓存地址,用做扇区
- 6)使用add_disk()注册gendisk结构体
3.2在申请队列的处理函数中
- 1) while循环使用elv_next_request()获取申请队列中每个未处理的申请
- 2)使用rq_data_dir()来获取每个申请的读写命令标志,为 0(READ)表示读, 为1(WRITE)表示写
- 3)使用memcp()来读或者写扇区(缓存)
- 4)使用end_request()来结束获取的每个申请
3.3在出口函数中
- 1)使用put_disk()和del_gendisk()来注销,释放gendisk结构体
- 2)使用kfree()释放磁盘扇区缓存
- 3)使用blk_cleanup_queue()清除内存中的申请队列
- 4)使用unregister_blkdev()卸载块设备
4.代码如下:
#include <linux/module.h>
#include <linux/errno.h>
#include <linux/interrupt.h>
#include <linux/mm.h>
#include <linux/fs.h>
#include <linux/kernel.h>
#include <linux/timer.h>
#include <linux/genhd.h>
#include <linux/hdreg.h>
#include <linux/ioport.h>
#include <linux/init.h>
#include <linux/wait.h>
#include <linux/blkdev.h>
#include <linux/blkpg.h>
#include <linux/delay.h>
#include <linux/io.h> #include <asm/system.h>
#include <asm/uaccess.h>
#include <asm/dma.h> static DEFINE_SPINLOCK(memblock_lock); //定义自旋锁
static request_queue_t * memblock_request; //申请队列
static struct gendisk *memblock_disk; //磁盘结构体
static int memblock_major; #define BLOCKBUF_SIZE (1024*1024) //磁盘大小
#define SECTOR_SIZE (512) //扇区大小
static unsigned char *block_buf; //磁盘地址 static int memblock_getgeo(struct block_device *bdev, struct hd_geometry *geo)
{
geo->heads =; // 2个磁头分区
geo->cylinders = ; //一个磁头有32个柱面
geo->sectors = BLOCKBUF_SIZE/(**SECTOR_SIZE); //一个柱面有多少个扇区
return ;
} static struct block_device_operations memblock_fops = {
.owner = THIS_MODULE,
.getgeo = memblock_getgeo, //几何,保存磁盘的信息(柱头,柱面,扇区)
}; /*申请队列处理函数*/
static void do_memblock_request (request_queue_t * q)
{
struct request *req;
unsigned long offset;
unsigned long len;
static unsigned long r_cnt = ;
static unsigned long w_cnt = ; while ((req = elv_next_request(q)) != NULL) //获取每个申请
{
offset=req->sector*SECTOR_SIZE; //偏移值
len=req->current_nr_sectors*SECTOR_SIZE; //长度 if(rq_data_dir(req)==READ)
{
memcpy(req->buffer,block_buf+offset,len); //读出缓存
}
else
{
memcpy(block_buf+offset,req->buffer,len); //写入缓存
}
end_request(req, ); //结束获取的申请
}
} /*入口函数*/
static int memblock_init(void)
{
/*1)使用register_blkdev()创建一个块设备*/
memblock_major=register_blkdev(, "memblock"); /*2) blk_init_queue()使用分配一个申请队列,并赋申请队列处理函数*/
memblock_request=blk_init_queue(do_memblock_request,&memblock_lock); /*3)使用alloc_disk()分配一个gendisk结构体*/
memblock_disk=alloc_disk(); //不分区 /*4)设置gendisk结构体的成员*/
/*->4.1)设置成员参数(major、first_minor、disk_name、fops)*/
memblock_disk->major = memblock_major;
memblock_disk->first_minor = ;
sprintf(memblock_disk->disk_name, "memblock");
memblock_disk->fops = &memblock_fops; /*->4.2)设置queue成员,等于之前分配的申请队列*/
memblock_disk->queue = memblock_request; /*->4.3)通过set_capacity()设置capacity成员,等于扇区数*/
set_capacity(memblock_disk,BLOCKBUF_SIZE/SECTOR_SIZE); /*5)使用kzalloc()来获取缓存地址,用做扇区*/
block_buf=kzalloc(BLOCKBUF_SIZE, GFP_KERNEL); /*6)使用add_disk()注册gendisk结构体*/
add_disk(memblock_disk);
return ;
}
static void memblock_exit(void)
{
/*1)使用put_disk()和del_gendisk()来注销,释放gendisk结构体*/
put_disk(memblock_disk);
del_gendisk(memblock_disk);
/*2)使用kfree()释放磁盘扇区缓存 */
kfree(block_buf);
/*3)使用blk_cleanup_queue()清除内存中的申请队列 */
blk_cleanup_queue(memblock_request); /*4)使用unregister_blkdev()卸载块设备 */
unregister_blkdev(memblock_major,"memblock");
} module_init(memblock_init);
module_exit(memblock_exit);
MODULE_LICENSE("GPL");
5.测试运行
insmod ramblock.ko //挂载memblock块设备 mkdosfs /dev/memblock //将memblock块设备格式化为dos磁盘类型 mount /dev/ memblock /tmp/ //挂载块设备到/tmp目录下
接下来在/tmp目录下vi 1.txt文件,最终都会保存在/dev/ memblock块设备里面
cd /; umount /tmp/ //退出/tmp,卸载,同时之前读写的文件也会消失 cat /dev/memblock > /mnt/memblock.bin //在/mnt目录下创建.bin文件,然后将块设备里面的文件追加到.bin里面
然后进入linux的nfs挂载目录中
sudo mount -o loop ramblock.bin /mnt //挂载ramblock.bin, -loop:将文件当做磁盘来挂载
如下图,就可以找到我们之前在开发板上创建的1.txt了

说明这个块设备测试运行无误
6.使用fdisk来对磁盘分区
(fdisk命令使用详解: http://www.cnblogs.com/lifexy/p/7661239.html)
共分了两个分区,如下图所示:

如下图,接下来就可以向上小节那样,分别操作多个分区磁盘了:

Linux-Nand Flash驱动(分析MTD层并制作NAND驱动)
1.本节使用的nand flash型号为K9F2G08U0M,它的命令如下:

1.1我们以上图的read id(读ID)为例,它的时序图如下:

首先需要使能CE片选
1)使能CLE
2)发送0X90命令,并发出WE写脉冲
3)复位CLE,然后使能ALE
4)发送0X00地址,并发出WE写脉冲
5)设CLE和ALE为低电平
6)while判断nRE(读使能)是否为低电平
7)读出8个I/O的数据,并发出RE上升沿脉冲
(我们的nand flash为8个I/O口,所以型号为K9F2G08U0M)
1.2 nand flash 控制器介绍
在2440中有个nand flash 控制器,它会自动控制CLE,ALE那些控制引脚,我们只需要配置控制器,就可以直接写命令,写地址,读写数据到它的寄存器中便能完成(读写数据之前需要判断RnB脚),如下图所示:

若在nand flash 控制器下,我们读ID就只需要如下几步(非常方便):
1)将寄存器NFCONT(0x4E000004)的bit1=0,来使能片选
2)写入寄存器NFCMMD(0x4E000008)=0X90,发送命令
3)写入寄存器NFADDR(0x4E00000C)=0X00,发送地址
4)while判断nRE(读使能)是否为低电平
5)读取寄存器NFDATA(0x4E000010),来读取数据
1.3 我们在uboot中测试,通过md和mw命令来实现读id(x要小写)
如下图所示,最终读取出0XEC 0XDA 0X10 0X95

刚好对应了我们nand flash手册里的数据(其中0XEC表示厂家ID, 0XDA表示设备ID):

若我们要退出读ID命令时,只需要reset就行,同样地,要退出读数据/写数据时,也是reset
1.4 reset的命令为0xff,它的时序图如下所示:

1.5 同样地,我们再参考读地址时序图来看看:

其中column Address对应列地址,表示某页里的2k地址
row Address对应行地址,表示具体的哪一页
5个地址的周期的图,如下所示:

因为我们的nand flash=256MB=(2k*128M)b
所以row Address=128M=2^17(A27~A11)
所以column Address=2k=2^11( A10~A0)
2.接下来我们来参考自带的nand flash驱动,位于drivers/mtd/nand/s3c2410.c中
2.1 为什么nand在mtd目录下?
因为mtd(memory technology device 存储 技术设备 ) 是用于访问 memory 设备( ROM 、 flash )的Linux 的子系统。 MTD 的主要目的是为了使新的 memory 设备的驱动更加简单,为此它在硬件和上层之间提供了一个抽象的接口
2.2首先来看s3c2410.c的入口函数:
static int __init s3c2410_nand_init(void)
{
printk("S3C24XX NAND Driver, (c) 2004 Simtec Electronics\n");
platform_driver_register(&s3c2412_nand_driver);
platform_driver_register(&s3c2440_nand_driver);
return platform_driver_register(&s3c2410_nand_driver);
}
在入口函数中,注册了一个platform平台设备驱动,也是说当与nandflash设备匹配时,就会调用s3c2440_nand_driver ->probe来初始化
我们进入probe函数中,看看是如何初始化
static int s3c24xx_nand_probe(struct platform_device *pdev, enum s3c_cpu_type cpu_type)
{
... ... err = s3c2410_nand_inithw(info, pdev); //初始化硬件hardware,设置TACLS 、TWRPH0、TWRPH1通信时序等 s3c2410_nand_init_chip(info, nmtd, sets); //初始化芯片 nmtd->scan_res = nand_scan(&nmtd->mtd, (sets) ? sets->nr_chips : ); //3.扫描nandflash
... ...
s3c2410_nand_add_partition(info, nmtd, sets); //4.调用add_mtd_partitions()来添加mtd分区
... ...
}
通过上面代码和注释,得出:驱动主要调用内核的nand_scan()函数,add_mtd_partitions()函数,来完成注册nandflash
3.上面probe()里的 nand_scan()扫描函数 位于/drivers/mtd/nand/nand_base.c
它会调用nand_scan()->nand_scan_ident()->nand_get_flash_type()来获取flash存储器的类型
以及nand_scan()->nand_scan_ident()->nand_scan_tail()来构造mtd设备的成员(实现对nandflash的读,写,擦除等)
3.1其中nand_get_flash_type()函数如下所示:
static struct nand_flash_dev *nand_get_flash_type(struct mtd_info *mtd,struct nand_chip *chip,int busw, int *maf_id)
{
struct nand_flash_dev *type = NULL;
int i, dev_id, maf_idx;
chip->select_chip(mtd, ); //调用nand_chip结构体的成员select_chip使能flash片选 chip->cmdfunc(mtd, NAND_CMD_READID, 0x00, -); //3.2调用nand_chip结构体的成员cmdfunc,发送读id命令,最后数据保存在mtd结构体里 *maf_id = chip->read_byte(mtd); // 获取厂家ID, dev_id = chip->read_byte(mtd); //获取设备ID /* 3.3for循环匹配nand_flash_ids[]数组,找到对应的nandflash信息*/
for (i = ; nand_flash_ids[i].name != NULL; i++)
{
if (dev_id == nand_flash_ids[i].id) //匹配设备ID
{type = &nand_flash_ids[i];
break;}
}
... ... /* 3.4 匹配成功,便打印nandflash参数 */
printk(KERN_INFO "NAND device: Manufacturer ID:"
" 0x%02x, Chip ID: 0x%02x (%s %s)\n", *maf_id,
dev_id, nand_manuf_ids[maf_idx].name, mtd->name);
... ...
}
从上面代码和注释得出, nand_chip结构体就是保存与硬件相关的函数(后面会讲这个结构体)
3.2 其中NAND_CMD_READID定义为0x90,也就是发送0X90命令,和0x00地址来读id,最后放到mtd中
3.3 nand_flash_ids[]数组是个全局变量,这里通过匹配设备ID,来确定我们的nand flash是个多大的存储器
如下图所示,在芯片手册中,看到nand flash的设备ID=0XDA

所以就匹配到nand_flash_ids[]里的0XDA:

3.4 然后打印出nand flash参数,我们启动内核就可以看到:

4. probe()里的s3c2410_nand_add_partition()函数主要是注册mtd设备的nand flash
最终它调用了s3c2410_nand_add_partition()->add_mtd_partitions() -> add_mtd_device()
其中add_mtd_partitions()函数主要实现多个分区创建,也就是多次调用add_mtd_device()
当只设置nand_flash为一个分区时,就直接调用add_mtd_device()即可.
4.1 add_mtd_partitions()函数原型如下:
int add_mtd_partitions(struct mtd_info *master, const struct mtd_partition *parts,int nbparts); //创建多个分区mtd设备
//函 数 成 员 介 绍 :
//master:就是要创建的mtd设备
//parts:分区信息的数组,它的结构体是mtd_partition,该结构体如下所示:
/*
struct mtd_partition {
char *name; //分区名,比如bootloader、params、kernel、root
u_int32_t size; //分区大小
u_int32_t offset; //分区所在的偏移值
u_int32_t mask_flags; //掩码标志
struct nand_ecclayout *ecclayout; //OOB布局
struct mtd_info **mtdp; //MTD的指针,不常用
};
*/
//nbparts:等于分区信息的数组个数,表示要创建分区的个数
比如我们启动内核时,也能找到内核自带的nandflash的分区信息:

4.2 其中add_mtd_device()函数如下所示:
int add_mtd_device(struct mtd_info *mtd) //创建一个mtd设备
{
struct list_head *this;
... ...
list_for_each(this, &mtd_notifiers) //4.3找mtd_notifiers链表里的list_head结构体
{
struct mtd_notifier *not = list_entry(this, struct mtd_notifier, list); //通过list_head找到struct mtd_notifier *not
not->add(mtd); //最后调用mtd_notifier 的add()函数
}
... ...
}
4.3 我们搜索上面函数里的mtd_notifiers链表
看看里面的list_head结构体,在哪里放入的,就能找到执行的add()是什么了。
4.4 如下图,发现list_head在register_mtd_user()里放到mtd_notifiers链表中

4.5 继续搜索register_mtd_user(),被哪个调用

如上图,找到被drivers/mtd/mtdchar.c、drivers/mtd/mtd_blkdevs.c调用(4.6节和4.7节会分析)
是因为mtd层既提供了字符设备的操作接口(mtdchar.c), 也实现了块设备的操作接口(mtd_blkdevs.c)
我们在控制台输入ls -l /dev/mtd*,也能找到块MTD设备节点和字符MTD设备节点,如下图所示:

上图中,可以看到共创了4个分区的设备,每个分区都包含了两个字符设备(mtd%d,mtd%dro)、一个块设备(mtdblock0).
其中MTD的块设备的主设备号为31,MTD的字符设备的主设备号为90 (后面会讲到在哪被创建)
4.6 我们进入上面搜到的drivers/mtd/mtdchar.c, 找到它的入口函数是init_mtdchar():
static int __init init_mtdchar(void)
{ /*创建字符设备mtd,主设备号为90 ,cat /proc/devices 可以看到 */
if (register_chrdev(MTD_CHAR_MAJOR, "mtd", &mtd_fops)) {
printk(KERN_NOTICE "Can't allocate major number %d for Memory Technology Devices.\n",MTD_CHAR_MAJOR);
return -EAGAIN;
}
mtd_class = class_create(THIS_MODULE, "mtd"); //创建类 if (IS_ERR(mtd_class)) {
printk(KERN_ERR "Error creating mtd class.\n");
unregister_chrdev(MTD_CHAR_MAJOR, "mtd");
return PTR_ERR(mtd_class);
} register_mtd_user(¬ifier); //调用register_mtd_user(),将notifier添加到mtd_notifiers链表中 return ;
}
之所以上面没有创建设备节点,是因为此时没有nand flash驱动.
4.6.1发现上面的notifiers是 mtd_notifier结构体的:

4.6.2 如上图,我们进入notifie的mtd_notify_add ()函数看看:
static void mtd_notify_add(struct mtd_info* mtd)
{
if (!mtd)
return; /*其中MTD_CHAR_MAJOR主设备定义为90 */
class_device_create(mtd_class, NULL, MKDEV(MTD_CHAR_MAJOR, mtd->index*),NULL, "mtd%d", mtd->index);
//创建mtd%d字符设备节点 class_device_create(mtd_class, NULL,MKDEV(MTD_CHAR_MAJOR, mtd->index*+),NULL, "mtd%dro", mtd->index);
//创建mtd%dro字符设备节点 }
该函数创建了两个字符设备(mtd%d, mtd%dro ),其中ro的字符设备表示为只读
总结出:
mtdchar.c的入口函数 将notifie添加到mtd_notifiers链表中,
然后在add_mtd_device()函数中当查找到mtd字符设备的list_head时,就调用mtd_notifiers->add()来创建两个字符设备(mtd%d,mtd%dro)
4.7 同样,我们也进入mtd_blkdevs.c (MTD块设备)中,找到注册到mtd_notifiers链表的是blktrans_notifier变量:

4.7.1 然后进入blktrans_notifier变量的blktrans_notify_add ()函数:
static void blktrans_notify_add(struct mtd_info *mtd)
{
struct list_head *this; if (mtd->type == MTD_ABSENT)
return; list_for_each(this, &blktrans_majors) //找blktrans_majors链表里的list_head结构体
{
struct mtd_blktrans_ops *tr = list_entry(this, struct mtd_blktrans_ops, list);
tr->add_mtd(tr, mtd); // 执行mtd_blktrans_ops结构体的add_mtd()
}
}
从上面的代码和注释得出:块设备的add()是查找blktrans_majors链表,然后执行mtd_blktrans_ops结构体的add_mtd()
4.7.2 我们搜索blktrans_majors链表,看看mtd_blktrans_ops结构体在哪里添加进去的
找到该链表在register_mtd_blktrans()函数中:
int register_mtd_blktrans(struct mtd_blktrans_ops *tr)
{
... ...
ret = register_blkdev(tr->major, tr->name); //注册块设备
tr->blkcore_priv->rq=blk_init_queue(mtd_blktrans_request, &tr->blkcore_priv->queue_lock);
//分配一个请求队列
... ...
list_add(&tr->list, &blktrans_majors); //将tr->list 添加到blktrans_majors链表
}
继续搜索register_mtd_blktrans(),如下图,找到被drivers/mtd/Mtdblock.c、Mtdblock_ro.c调用

4.7.3 我们进入drivers/mtd/Mtdblock.c函数中,如下图所示:

找到执行mtd_blktrans_ops结构体的add_mtd()函数,就是上图的mtdblock_add_mtd()函数
在mtdblock_add_mtd()函数中最终会调用add_mtd_blktrans_dev()
4.7.4 add_mtd_blktrans_dev()函数如下所示:
int add_mtd_blktrans_dev(struct mtd_blktrans_dev *new)
{
... ...
gd = alloc_disk( << tr->part_bits); //分配一个gendisk结构体 gd->major = tr->major; //设置gendisk的主设备号 gd->first_minor = (new->devnum) << tr->part_bits; //设置gendisk的起始此设备号 gd->fops = &mtd_blktrans_ops; //设置操作函数
... ... gd->queue = tr->blkcore_priv->rq; //设置请求队列 add_disk(gd); //向内核注册gendisk结构体
}
总结出:
mtd_blkdevs()块设备的入口函数 将blktrans_notifier添加到mtd_notifiers链表中,并创建块设备,请求队列.
然后在add_mtd_device()函数中,当查找到有blktrans_notifier时,就调用blktrans_notifier->add()来分配设置注册gendisk结构体
5.显然在内核中,mtd已经帮我们做了整个框架,而我们的nand flash驱动只需要以下几步即可:
1)设置mtd_info结构体成员
2)设置nand_chip结构体成员
3)设置硬件相关(设置nand控制器时序等)
4)通过nand_scan()来扫描nandflash
5)通过add_mtd_partitions()来添加分区,创建MTD字符/块设备
5.1 mtd_info结构体介绍:
主要是实现对nandflash的read()、write()、read_oob()、write_oob()、erase()等操作,属于软件的部分,它会通过它的成员priv来找到对应的nand_chip结构体,来调用与硬件相关的操作.
5.2 nand_chip结构体介绍:
它是mtd_info结构体的priv成员,主要是对MTD设备中的nandflash硬件相关的描述.
当我们不设置nand_chip的成员时,以下的成员就会被mtd自动设为默认值,代码位于: nand_scan()->nand_scan_ident()->nand_set_defaults()
struct nand_chip {
void __iomem *IO_ADDR_R; /* 需要读出数据的nandflash地址 */
void __iomem *IO_ADDR_W; /* 需要写入数据的nandflash地址 */
/* 从芯片中读一个字节 */
uint8_t (*read_byte)(struct mtd_info *mtd);
/* 从芯片中读一个字 */
u16 (*read_word)(struct mtd_info *mtd);
/* 将缓冲区内容写入nandflash地址, len:数据长度*/
void (*write_buf)(struct mtd_info *mtd, const uint8_t *buf, int len);
/* 读nandflash地址至缓冲区, len:数据长度 */
void (*read_buf)(struct mtd_info *mtd, uint8_t *buf, int len);
/* 验证芯片和写入缓冲区中的数据 */
int (*verify_buf)(struct mtd_info *mtd, const uint8_t *buf, int len);
/* 选中芯片,当chip==0表示选中,chip==-1时表示取消选中 */
void (*select_chip)(struct mtd_info *mtd, int chip);
/* 检测是否有坏块 */
int (*block_bad)(struct mtd_info *mtd, loff_t ofs, int getchip);
/* 标记坏块 */
int (*block_markbad)(struct mtd_info *mtd, loff_t ofs);
/* 命令、地址控制函数 , dat :要传输的命令/地址 */
/*当ctrl的bit[1]==1: 表示要发送的dat是命令
bit[2]==1: 表示要发送的dat是地址
bit[0]==1:表示使能nand , ==0:表示禁止nand
具体可以参考内核的nand_command_lp()函数,它会调用这个cmd_crtl函数实现功能*/
void (*cmd_ctrl)(struct mtd_info *mtd, int dat,unsigned int ctrl);
/* 设备是否就绪,当该函数返回的RnB引脚的数据等于1,表示nandflash已就绪 */
int (*dev_ready)(struct mtd_info *mtd);
/* 实现命令发送,最终调用nand_chip -> cmd_ctrl来实现 */
void (*cmdfunc)(struct mtd_info *mtd, unsigned command, int column, int page_addr);
/*等待函数,通过nand_chip ->dev_ready来等待nandflash是否就绪 */
int (*waitfunc)(struct mtd_info *mtd, struct nand_chip *this);
/* 擦除命令的处理 */
void (*erase_cmd)(struct mtd_info *mtd, int page);
/* 扫描坏块 */
int (*scan_bbt)(struct mtd_info *mtd);
int (*errstat)(struct mtd_info *mtd, struct nand_chip *this, int state, int status, int page);
/* 写一页 */
int (*write_page)(struct mtd_info *mtd, struct nand_chip *chip,const uint8_t *buf, int page, int cached, int raw); int chip_delay; /* 由板决定的延迟时间 */
/* 与具体的NAND芯片相关的一些选项,默认为8位宽nand,
比如设置为NAND_BUSWIDTH_16,表示nand的总线宽为16 */
unsigned int options; /* 用位表示的NAND芯片的page大小,如某片NAND芯片
* 的一个page有512个字节,那么page_shift就是9
*/
int page_shift; /* 用位表示的NAND芯片的每次可擦除的大小,如某片NAND芯片每次可
* 擦除16K字节(通常就是一个block的大小),那么phys_erase_shift就是14
*/
int phys_erase_shift; /* 用位表示的bad block table的大小,通常一个bbt占用一个block,
* 所以bbt_erase_shift通常与phys_erase_shift相等
*/
int bbt_erase_shift;
/* 用位表示的NAND芯片的容量 */
int chip_shift;
/* NADN FLASH芯片的数量 */
int numchips;
/* NAND芯片的大小 */
uint64_t chipsize; int pagemask;
int pagebuf;
int subpagesize;
uint8_t cellinfo;
int badblockpos;
nand_state_t state;
uint8_t *oob_poi;
struct nand_hw_control *controller;
struct nand_ecclayout *ecclayout; /* ECC布局 */
/* ECC校验结构体,若不设置, ecc.mode默认为NAND_ECC_NONE(无ECC校验) */
/*可以为硬件ECC和软件ECC校验,比如:设置ecc.mode=NAND_ECC_SOFT(软件ECC校验)*/
struct nand_ecc_ctrl ecc;
struct nand_buffers *buffers;
struct nand_hw_control hwcontrol;
struct mtd_oob_ops ops;
uint8_t *bbt;
struct nand_bbt_descr *bbt_td;
struct nand_bbt_descr *bbt_md;
struct nand_bbt_descr *badblock_pattern;
void *priv;
};
5.3本节驱动我们需要设置nand_chip的成员如下:
IO_ADDR_R(提供读数据)
IO_ADDR_W(提供写数据)
select_chip(提供片选使能/禁止)
cmd_ctrl(提供写命令/地址)
dev_ready(提供nandflash的RnB脚,来判断是否就绪)
ecc.mode(设置ECC为硬件校验/软件校验)
其它成员会通过nand_scan()->nand_scan_ident()->nand_set_defaults()来设置为默认值.
6.接下来我们就来写nand flash块设备驱动
参考: drivers/mtd/nand/at91_nand.c
drivers/mtd/nand/s3c2410.c
6.1本节需要用到的函数如下所示:
int nand_scan(struct mtd_info *mtd, int maxchips); //扫描nandflash,扫描成功返回0 int add_mtd_partitions(struct mtd_info *master,const struct mtd_partition *parts,int nbparts);
//将nandflash分成nbparts个分区,会创建多个MTD字符/块设备,成功返回0
//master:就是要创建的mtd设备
//parts:分区信息的数组,它的结构体是mtd_partition
//nbparts:要创建分区的个数,比如上图,那么就等于4 int del_mtd_partitions(struct mtd_info *master);
//卸载分区,并会卸载MTD字符/块设备
6.2 在init入口函数中
- 1)通过kzalloc()来分配结构体: mtd_info和nand_chip
- 2)通过ioremap()来分配获取nand flash 寄存器虚拟地址
- 3)设置mtd_info结构体成员
- 4)设置nand_chip结构体成员
- 5)设置硬件相关
- ->5.1) 通过clk_get()和clk_enable()来使能nand flash 时钟
- ->5.2)设置时序
- ->5.3)关闭片选,并开启nand flash 控制器
- 6)通过nand_scan()来扫描nandflash
- 7)通过add_mtd_partitions()来添加分区,创建MTD字符/块设备
6.3 在exit入口函数中
- 1)卸载分区,卸载字符/块设备
- 2)释放mtd
- 3)释放nand flash寄存器
- 4)释放nand_chip
驱动代码如下:
#include <linux/module.h>
#include <linux/types.h>
#include <linux/init.h>
#include <linux/kernel.h>
#include <linux/string.h>
#include <linux/ioport.h>
#include <linux/platform_device.h>
#include <linux/delay.h>
#include <linux/err.h>
#include <linux/slab.h>
#include <linux/clk.h>
#include <linux/mtd/mtd.h>
#include <linux/mtd/nand.h>
#include <linux/mtd/nand_ecc.h>
#include <linux/mtd/partitions.h>
#include <asm/io.h>
#include <asm/arch/regs-nand.h>
#include <asm/arch/nand.h> struct mynand_regs {
unsigned long nfconf ; //0x4E000000
unsigned long nfcont ;
unsigned long nfcmd ;
unsigned long nfaddr ;
unsigned long nfdata ;
unsigned long nfeccd0 ;
unsigned long nfeccd1 ;
unsigned long nfeccd ;
unsigned long nfstat ;
unsigned long nfestat0;
unsigned long nfestat1;
unsigned long nfmecc0 ;
unsigned long nfmecc1 ;
unsigned long nfsecc ;
unsigned long nfsblk ;
unsigned long nfeblk ;
};
static struct mynand_regs *my_regs; //nand寄存器
static struct mtd_info *my_mtd;
static struct nand_chip *mynand_chip; static struct mtd_partition mynand_part[] = {
[] = {
.name = "bootloader",
.size = 0x00040000,
.offset = ,
},
[] = {
.name = "params",
.offset = MTDPART_OFS_APPEND,
.size = 0x00020000,
},
[] = {
.name = "kernel",
.offset = MTDPART_OFS_APPEND,
.size = 0x00200000,
},
[] = {
.name = "root",
.offset = MTDPART_OFS_APPEND,
.size = MTDPART_SIZ_FULL,
}
}; /*nand flash :CE */
static void mynand_select_chip(struct mtd_info *mtd, int chipnr)
{
if(chipnr==-) //CE Disable
{
my_regs->nfcont|=(0x01<<); //bit1置1
}
else //CE Enable
{
my_regs->nfcont&=~(0x01<<); //bit1置0
}
}
/*命令/地址控制函数 */
static void mynand__cmd_ctrl(struct mtd_info *mtd, int dat, unsigned int ctrl)
{
if (ctrl & NAND_CLE) //当前为command状态 ,
my_regs->nfcmd=dat;
else //当前为地址状态 , if (ctrl & NAND_ALE)
my_regs->nfaddr=dat;
} /* nand flash 设备就绪函数(获取RnB引脚状态 */
static int mynand__device_ready(struct mtd_info *mtd)
{
return (my_regs->nfstat&0x01); //获取RnB状态,0:busy 1:ready
}
/*init入口函数*/
static int mynand_init(void)
{
struct clk *nand_clk;
int res;
/*1.分配结构体: mtd_info和nand_chip */
my_mtd=kzalloc(sizeof(struct mtd_info), GFP_KERNEL);
mynand_chip=kzalloc(sizeof(struct nand_chip), GFP_KERNEL); /*2.获取nand flash 寄存器虚拟地址*/
my_regs=ioremap(0x4E000000, sizeof(struct mynand_regs)); /*3.设置mtd_info*/
my_mtd->owner=THIS_MODULE;
my_mtd->priv=mynand_chip; //私有数据 /*4.设置nand_chip*/
mynand_chip->IO_ADDR_R=&my_regs->nfdata; //设置读data
mynand_chip->IO_ADDR_W=&my_regs->nfdata; //设置写data
mynand_chip->select_chip=mynand_select_chip; //设置CE
mynand_chip->cmd_ctrl = mynand__cmd_ctrl; //设置写command/address
mynand_chip->dev_ready = mynand__device_ready; //设置RnB
mynand_chip->ecc.mode = NAND_ECC_SOFT; //设置软件ECC /*5.设置硬件相关*/
/*5.1使能nand flash 时钟*/
nand_clk=clk_get(NULL,"nand");
clk_enable(nand_clk);
/*5.2设置时序*/
#define TACLS 0 //0nS
#define TWRPH0 1 //15nS
#define TWRPH1 0 //5nS
my_regs->nfconf = (TACLS<<) | (TWRPH0<<) | (TWRPH1<<); /*5.3 bit1:关闭片选, bit0:开启nand flash 控制器*/
my_regs->nfcont=(<<)|(<<); /*6.扫描NAND*/
if (nand_scan(my_mtd, )) { // 1:表示只扫描一个nand flash 设备
res = -ENXIO;
goto out;
} /*7.添加分区,创建字符/块设备*/
res = add_mtd_partitions(my_mtd, mynand_part, );
if(res)
return ; out:
del_mtd_partitions(my_mtd); //卸载分区,卸载字符/块设备
kfree(my_mtd); //释放mtd
iounmap(my_regs); //释放nand flash寄存器
kfree(mynand_chip); //释放nand_chip
return ; } /*exit出口函数*/
static void mynand_exit(void)
{
del_mtd_partitions(my_mtd); //卸载分区,卸载字符/块设备
kfree(my_mtd); //释放mtd
iounmap(my_regs); //释放nand flash寄存器
kfree(mynand_chip); //释放nand_chip
} module_init(mynand_init);
module_exit(mynand_exit);
MODULE_LICENSE("GPL");
7.编译启动内核
7.1 重新设置编译内核(去掉默认的nand flash驱动)
make menuconfig ,进入menu菜单重新设置内核参数:
进入-> Device Drivers-> Memory Technology Device (MTD) support-> NAND Device Support
< > NAND Flash support for S3C2410/S3C2440 SoC //去掉默认的nandflash驱动
然后make uImage 编译内核
将新的nandflash驱动模块放入nfs文件系统目录中
7.2然后烧写内核,启动内核
如下图,发现内核启动时,卡住了,是因为我们使用的文件系统是存在nand flash上

所以设置为nfs文件系统才行.
8.挂载nand flash 驱动
8.1如下图,可以看到共添了4个分区: bootloader、params、kernel、root、
刚好对应了程序中的mynand_part数组里面的分区信息

8.2 如下图,可以看到/dev下共创建了4个MTD块设备(mtdblock%d),4个MTD字符设备(mtd%d、mtd%dro)

8.3 如下图,使用cat /proc/partitions ,可以看到分区信息

其中blocks表示分区的容量,每个blocks是1KB
9. 使用mount来挂载mtd块设备
mount /dev/mtdblock3 /mnt/ //挂载, mount会自动获取该设备的文件类型
进入mnt,可以看到里面就是我们之前存在nand flash上的文件系统

10. 使用mtd-util 工具擦除mtdblock3(使用nand之前最好擦除一次)
因为flash的特性如下:
写入,只能把数据(bit)从1改为0;擦除,只能把所有数据(bit)从0改为1。
所以,要想写入数据之前必须先擦除。因为flash只能写0,写1时其实是保持原来的状态。
10.1 使用mtd-util工具步骤如下:
tar -xjf mtd-utils-05.07..tar.bz2 //解压mtd-util工具
cd mtd-utils-05.07./util / //进入util目录
vi Makefile //修改交叉编译改为: CROSS=arm-linux-
make //编译,生成flashcp 、flash_erase、flash_eraseall等命令
cp flash_erase flash_eraseall /nfs文件系统目录 //复制命令
10.2mtd-util工具的常用命令介绍
命令:flashcp
作用: copy数据到 flash 中
实例:
./flashcp fs.yaffs2 /dev/mtd0 //将文件系统yaffs2复制到mtd0中
命令:flash_erase
常用参数:
-j 使用jffs2来格式化分区
-q 不打印过程信息
作用:擦除某个分区的指定范围 (其中指定位置必须以0x20000(128K)为倍数)
实例:
./flash_erase /dev/mtd0 0x20000 //擦除mtd0从0x20000开始的5块数据 ,128K/块
命令:flash_eraseall
常用参数:
-j 使用jffs2来格式化分区(对于norflash才加该参数)
-q 不打印过程信息
作用:擦除整个分区的内容
实例:
./flash_eraseall -q /dev/mtd0 //擦除mtd0,并不打印过程信息
10.3为什么这里的实例都是对mtd字符设备进行操作,而不是mtdblock块设备?
因为每个分区的字符设备,其实就是对应着每个分区块设备。即/dev/mtd3对应/dev/mtdblock3
flash_eraseall, flash_erase那些命令是以ioctl等基础而实现, 而块设备不支持ioctl, 只有字符设备支持
10.4 使用flash_eraseall来擦除分区3
步骤如下:
umount /mnt //擦除之前需要使用umount mnt来取消之前的挂载
./flash_eraseall /dev/mtd3 //擦除mtd3
mount -t yaffs /dev/mtdblock3 /mnt/ //使用yaffs类型来挂载mtdblock3块设备
//因为当前的mtdblock3为空,mount命令无法自动获取mtdblock3的文件类型
如下图,可以看到分区3已经为空了

Linux-Nor Flash驱动(详解)
1.nor硬件介绍:
从原理图中我们能看到NOR FLASH有地址线,有数据线,它和我们的SDRAM接口相似,能直接读取数据,但是不能像SDRAM直接写入数据,需要有命令才行
1.1其中我们2440的地址线共有27根(LADDR0~26),为什么是27根?
因为2440共有7个bank内存块,每个bank=128MB=(2^27)B,所以共有27根数据线
1.2为什么Nor Flash的地址线A0是接在2440的LADDR1上?
因为Nor Flash的数据共有16位,也就是每个地址保存了2B数据,而我们的2440每个地址是保存的1B数据,
比如:
当2440访问0X00地址时,就会读取到Nor上0地址的2B数据,然后2440的内存控制器会根据0x00来找到低8位字节,并返回给CPU,
当2440访问0x01地址时,由于2440的LADDR0线未接,所以还是访问Nor的0地址上的2B数据,然后内存控制器会根据0x01来找到高8位字节,并返回给CPU
1.3 nand和nor区别:
nor flash在价格上比nand贵,且容量很小 ,擦除和写数据都慢,好处在于接口简单,稳定,无位反转,坏块,常用于保存关键数据,而nand flash常用于保存大容量数据
在2440中是通过硬件开关来设置OM0为Nand启动还是Nor启动,如下图所示:
OM0具体参数如下所示,其中2440的OM1引脚默认接地
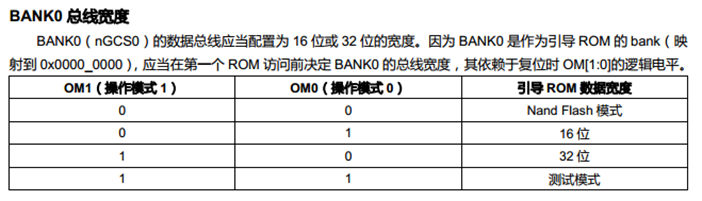
对于nand启动:OM0接地,nand flash的开始4KB会自动地被加载到2440内置的SRAM缓存器中,就可以直接读写
对于nor启动:OM0接高,2440访问的内存就是nor flash,可以直接读,但是不能直接写
2.nor flash命令如下所示(参考MX29LV160DBTI.pdf)
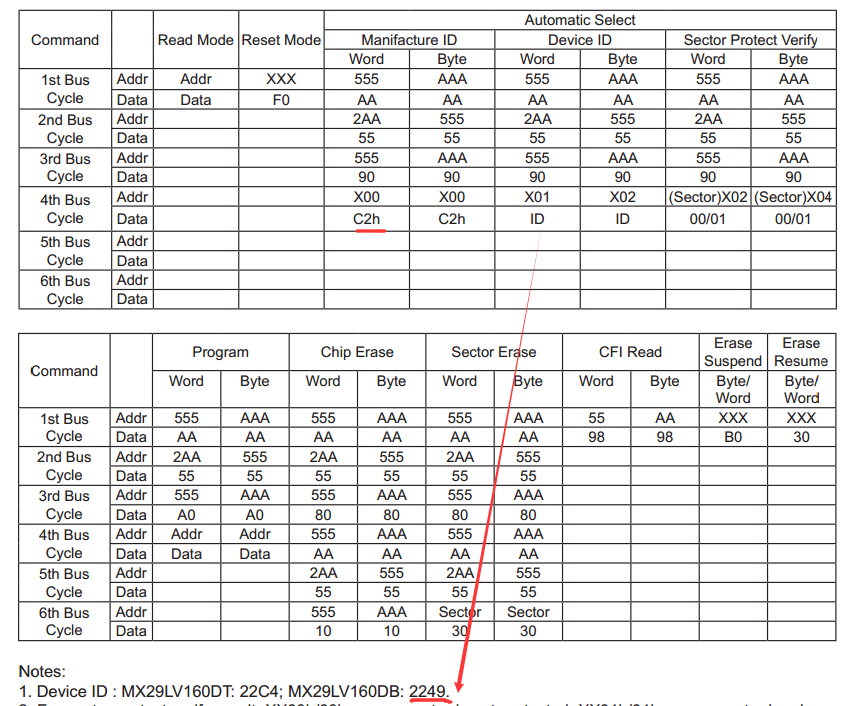
其中word是针对16位nand,byte针对8位nand.
由于我们2440的flash型号是MX29LV160DB,所以设备ID为0x2249
2.1 比如,当我们要program(往0x20地址写入0xff数据)时
需要以下3步:
1.发送解锁地址:
往nor地址0x555写入0xAA
往nor地址0x2AA写入0x55
2.发送命令:
往nor地址0x555写入0xA0 //进入program模式
3.写数据:
往nor地址0x20(PA)写入0xff(PD) //往0x20写入0xff
(接下来就会一直是program模式,执行reset模式便可以退出)
2.2该NOR有两种规范, jedec, cfi(common flash interface)
jedec
就是和nandflash的一样,通过读ID来匹配linux内核中drivers/mtd/chips/jedec_probe.c里的jedec_table[]数组,来确定norflash的各个参数(名称、容量、位宽等),如下图所示:

- [0] = MTD_UADDR_0x5555_0x2AAA
表示解锁地址为0x5555,0x2AAAM,其中数组[0],表示属于8位flash,定义如下:

- CmdSet
使用哪种命令,一般CmdSet=0xFFF0
- .NumEraseRegions= 1
只有1个不同的扇区区域
- ERASEINFO(0x10000, 64)
共有64个扇区,每个扇区都是64KB(0x10000)
cfi
就是将这些参数保存在cfi模式下指定地址中, 往nor的0x55地址写入0x98,即可进入cfi模式,
cfi模式部分命令如下图所示:
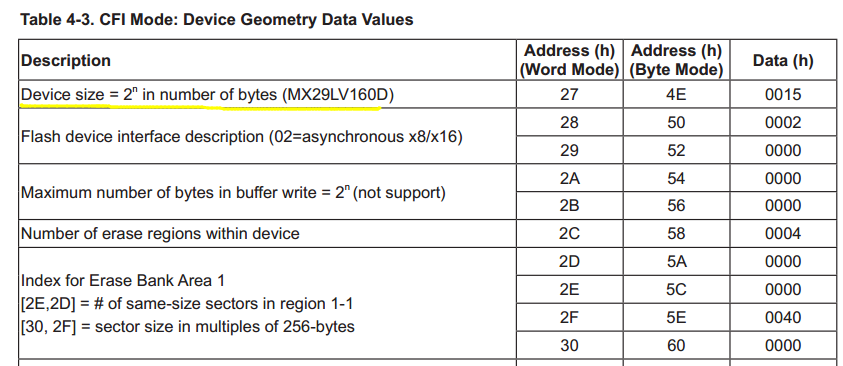
当我们在cfi模式下,比如:读取nor地址0x27处的数据,便能读到nor的容量
如下图所示,之所以地址*2,是因为nor地址线A0接在我们2440的A1上(退出cfi模式,使用复位命令即可)

读到0X15,0x15=21,如下图,刚好对应我们原理图的21根nor地址线,所以容量为2^21=2MB
2.3为什么上图的A20引脚没有接?
对于2440来讲,因为此时的A0~A19的容量刚好为2MB,与cfi模式下读取的数据一致,所以没有接A20
3.接下来便来分析如何写norflash驱动
3.1 先来回忆下之前的nandflsh驱动:
nandflsh驱动会放在内核的mtd设备中,而mtd设备知道如何通过命令/地址/数据来操作nandflash,所以我们之前的nandflash驱动只实现了硬件相关的操作(构造mtd_info,nand_chip结构体、启动nand控制器等)
同样地,norflash驱动也是放在内核的mtd设备中,mtd设备也知道对nor如何来读写擦除,只是不知道norflash的位宽(数据线个数),基地址等,所以我们的norflash驱动同样要实现硬件相关的操作,供给mtd设备调用
3.2参考内核自带的nor驱动:drivers/mtd/maps/physmap.c
进入它的init函数:

发现注册了两个platform平台设备驱动,进入physmap_flash结构体中:

发现3个未定义的变量:
CONFIG_MTD_PHYSMAP_BANKWIDTH: nandflash的字节位宽
CONFIG_MTD_PHYSMAP_START:nandflash的物理基地址
CONFIG_MTD_PHYSMAP_LEN: nandflash的容量长度
这3个变量是通过linux的menuconfig菜单配置出来的,若自己填入值,就不需要用menuconfig菜单配置了
3.3接下来我们就来配置内核,然后挂载这个内核自带的norflash驱动实验一番
3.4 首先make menuconfig,配置上面3个变量,然后设为模块
-> Device Drivers
-> Memory Technology Device (MTD) support
-> Mapping drivers for chip access //进入映射驱动
<M> CFI Flash device in physical memory map //将支持cfi的norflash设置为模块
- (0x0) Physical start address of flash mapping // 设置物理基地址
- (0x1000000) Physical length of flash mapping // 设置容量长度,必须大于等于自身nor的2MB
- (2) Bank width in octets (NEW) // 设置字节位宽,因为nor为16位,所以等于2
3.5 make modules 编译模块
如下图所示,可以看到physmap.c编译成.ko模块了

3.6 然后放在nfs目录下,启动开发板
如下图所示,insmod后打印了一串信息:
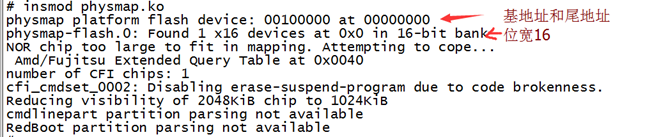
如下图所示,可以看到创建了2个mtd0字符设备,一个mtd0块设备:
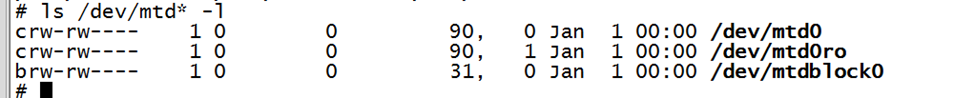
4.接下来我们便分析physmap.c,如何写出norflash驱动的
其中physmap.c的probe函数如下
struct physmap_flash_info {
struct mtd_info *mtd; //实现对flash的读写擦除等操作
struct map_info map; //存放硬件相关的结构体
struct resource *res;
#ifdef CONFIG_MTD_PARTITIONS
int nr_parts;
struct mtd_partition *parts;
#endif
};
static const char *rom_probe_types[] = { "cfi_probe", "jedec_probe", "map_rom", NULL }; //芯片名称
... ...
static int physmap_flash_probe(struct platform_device *dev)
{
const char **probe_type;
... ...
/*1. 分配结构体*/
info = kzalloc(sizeof(struct physmap_flash_info), GFP_KERNEL);
/*2.设置map_info 结构体*/
info->map.name = dev->dev.bus_id; //norflash的名字
info->map.phys = dev->resource->start; //物理基地址
info->map.size = dev->resource->end - dev->resource->start + ; //容量长度
info->map.bankwidth = physmap_data->width; //字节位宽
info->map.virt = ioremap(info->map.phys, info->map.size); //虚拟地址
simple_map_init(&info->map); //简单初始化map_info的其它成员
probe_type = rom_probe_types;
/*3. 设置mtd_info 结构体 */
/*通过probe_type指向的名称来识别芯片,当do_map_probe()函数返回NULL表示没找到*/
/*当找到对应的芯片mtd_info结构体,便返回给当前的info->mtd */
for (; info->mtd == NULL && *probe_type != NULL; probe_type++)
info->mtd = do_map_probe(*probe_type, &info->map); //通过do_map_probe ()来识别芯片
if (info->mtd == NULL) { //最终还是没找到芯片,便注销之前注册的东西并退出
dev_err(&dev->dev, "map_probe failed\n");
err = -ENXIO;
goto err_out;
}
info->mtd->owner = THIS_MODULE;
/*4.添加mtd设备*/
add_mtd_device(info->mtd);
return ;
err_out:
physmap_flash_remove(dev); //该函数用来注销之前注册的东西
return err;
}
通过上面的代码和注释分析到,和我们上一节的nandflash驱动相似,这里是设置map_info 结构体和mtd_info结构体来完成的,当我们要对norflash分区就要使用add_mtd_partitions()才行
其中当*probe_type==“cfi_probe”时:
就会通过do_map_probe("cfi_probe", &info->map)来识别芯片.
最终会进入drivers/mtd/chips/cfi_probe.c中的cfi_probe_chip()函数来进入cfi模式,读取芯片信息
当*probe_type=="jedec_probe"时:
最终会进入drivers/mtd/chips/jedec_probe.c中的jedec_probe_chip ()函数来使用读ID命令,通过ID来匹配jedec_table[]数组.
所以注册一个块设备驱动,需要以下步骤:
- 1. 分配mtd_info结构体和map_info结构体
- 2. 设置map_info 结构体
- 3. 设置mtd_info 结构体
- 4. 使用add_mtd_partitions()或者add_mtd_device()来创建MTD字符/块 设备
5.接下来我们来参考physmap.c来自己写norflah驱动
代码如下:
#include <linux/module.h>
#include <linux/types.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/slab.h>
#include <linux/device.h>
#include <linux/platform_device.h>
#include <linux/mtd/mtd.h>
#include <linux/mtd/map.h>
#include <linux/mtd/partitions.h>
#include <asm/io.h> static struct mtd_info *mynor_mtd_info;
static struct map_info *mynor_map_info; static struct mtd_partition mynor_partitions[] = {
[] = {
.name = "bootloader",
.size = 0x00040000,
.offset = ,
},
[] = {
.name = "root",
.offset = MTDPART_OFS_APPEND,
.size = MTDPART_SIZ_FULL,
}
}; static const char *mynor_probe_types[] = { "cfi_probe", "jedec_probe",NULL}; static int mynor_init(void)
{
int val; /*1. 分配map_info 结构体和mtd_info结构体*/
mynor_mtd_info=kzalloc(sizeof(struct mtd_info), GFP_KERNEL);
mynor_map_info=kzalloc(sizeof(struct map_info), GFP_KERNEL); /*2. 设置map_info 结构体*/
mynor_map_info->name="my_nor";
mynor_map_info->phys=0x0; //物理地址
mynor_map_info->size=0x1000000; //=16M,长度必须大于等于norflash的2M容量
mynor_map_info->bankwidth=; //16位宽
mynor_map_info->virt = ioremap(0x0, mynor_map_info->size); //虚拟地址
simple_map_init(mynor_map_info); /*3. 设置mtd_info 结构体*/
mynor_mtd_info = do_map_probe("cfi_probe", mynor_map_info);
if (!mynor_mtd_info)
{
mynor_mtd_info = do_map_probe("jedec_probe", mynor_map_info);
}
if (!mynor_mtd_info)
{
printk("not available norflash !!!\r\n");
goto err_out;
}
mynor_mtd_info->owner=THIS_MODULE;
/*4. 使用add_mtd_partitions()或者add_mtd_device()来创建MTD字符/块 设备*/
add_mtd_partitions(mynor_mtd_info,mynor_partitions,);
return ; err_out:
iounmap(mynor_map_info->virt); //取消虚拟地址映射
kfree(mynor_map_info);
kfree(mynor_mtd_info);
return ;
} static void mynor_exit(void)
{
del_mtd_partitions(mynor_mtd_info); //卸载分区
iounmap(mynor_map_info->virt); //取消虚拟地址映射
kfree(mynor_map_info);
kfree(mynor_mtd_info);
} module_init(mynor_init);
module_exit(mynor_exit);
MODULE_LICENSE("GPL");
6.挂载驱动试验
(一定要在nor启动下挂载才行,因为2440使用nand启动时,是访问不了nor的前4k地址)
insmod挂载驱动后,如下图所示:
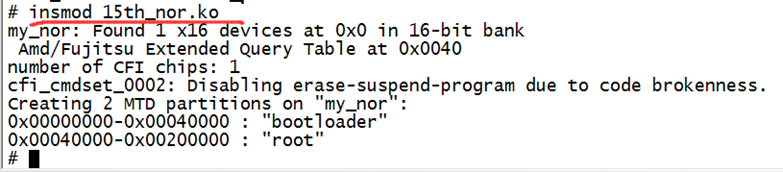
可以看到创建了两个分区“bootloader”,“root”,如下图所示,可以看到创建了2对mtd字符/块设备

6.1 接下来便来对root分区(mtd1)来试验(使用flash之前最好擦除一次)
步骤如下:
./flash_eraseall -j /dev/mtd1 //使用mtd-util工具的flash_eraseal命令来擦除root分区(mtd1) mount -t jffs2 /dev/mtdblock1 /mnt/ //使用mount挂载文件系统, -t:文件系统类型(type)
接下来就可以在/mnt目录下来任意读写文件了,最终会保存在flash的mtdblock1块设备中
(PS:可以参考内核自带的mtdram.c,里面是使用内存来模拟flash, 里面通过memcopy()等来实现对内存读写擦除)
Linux-IIC驱动(详解)
上一节 我们学习了:
IIC接口下的24C02 驱动分析: http://www.cnblogs.com/lifexy/p/7793686.html
接下来本节, 学习Linux下如何利用linux下I2C驱动体系结构来操作24C02
1. I2C体系结构分析
1.1首先进入linux内核的driver/i2c目录下,如下图所示:
其中重要的文件介绍如下:
1)algos文件夹(algorithms)
里面保存I2C的通信方面的算法
2)busses文件夹
里面保存I2C总线驱动相关的文件,比如i2c-omap.c、 i2c-versatile.c、 i2c-s3c2410.c等。
3) chips文件夹
里面保存I2C设备驱动相关的文件,如下图所示,比如m41t00,就是RTC实时钟
4) i2c-core.c
这个文件实现了I2C核心的功能(I2C总线的初始化、注册和适配器添加和注销等相关工作)以及/proc/bus/i2c*接口。
5) i2c-dev.c
提供了通用的read( )
、 write( )
和ioctl( )
等接口,实现了I2C适配器设备文件的功能,其中I2C设备的主设备号都为89,
次设备号为0~255。
应用层可以借用这些接口访问挂接在适配器上的I2C设备的存储空间或寄存器,
并控制I2C设备的工作方式
显然,它和前几次驱动类似, I2C也分为总线驱动和设备驱动,总线就是协议相关的,它知道如何收发数据,但不知道数据含义,设备驱动却知道数据含义
1.2 I2C驱动架构,如下图所示:
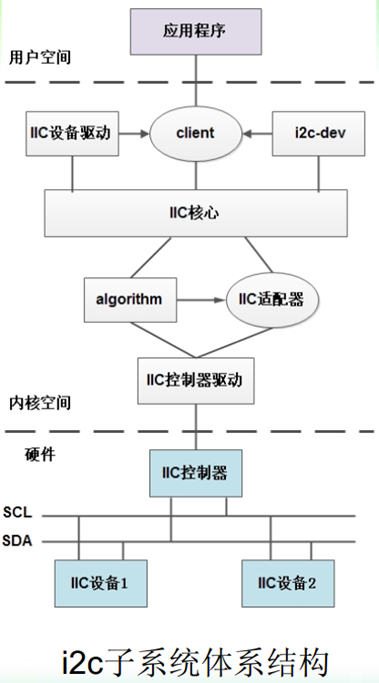
如上图所示,每一条I2C对应一个adapter适配器,在kernel中, adapter适配器是通过struct adapter结构体定义,主要是通过i2c core层将i2c设备与i2c adapter关联起来.
在kernel中提供了两个adapter注册接口,分别为i2c_add_adapter()和i2c_add_numbered_adapter().由于在系统中可能存在多个adapter,因为将每一条I2C总线对应一个编号,下文中称为I2C总线号.这个总线号的PCI中的总线号不同.它和硬件无关,只是软件上便于区分而已.
对于i2c_add_adapter()而言,它使用的是动态总线号,即由系统给其分析一个总线号,而i2c_add_numbered_adapter()则是自己指定总线号,如果这个总线号非法或者是被占用,就会注册失败.
2.接下来便来分析I2C总线驱动
参考
drivers/i2c/busses/i2c-s3c2410.c
先进入init入口函数,如下图所示:
在init函数中,注册了一个 “s3c2440-i2c”的platform_driver平台驱动,我们来看看probe函数做了些什么
3.进入s3c24xx_i2c_probe函数
struct i2c_adapter adap; static int s3c24xx_i2c_probe(struct platform_device *pdev)
{
struct s3c24xx_i2c *i2c = &s3c24xx_i2c;
... ... /*获取,使能I2C时钟*/
i2c->clk = clk_get(&pdev->dev, "i2c"); //获取i2c时钟
clk_enable(i2c->clk); //使能i2c时钟 ... ....
/*获取资源*/
res = platform_get_resource(pdev, IORESOURCE_MEM, );
i2c->regs = ioremap(res->start, (res->end-res->start)+); ... .... /*设置i2c_adapter适配器结构体, 将i2c结构体设为adap的私有数据成员*/
i2c->adap.algo_data = i2c; //i2c_adapter适配器指向s3c24xx_i2c;
i2c->adap.dev.parent = &pdev->dev; /* initialise the i2c controller */
/*初始化2440的I2C相关的寄存器*/
ret = s3c24xx_i2c_init(i2c);
if (ret != )
goto err_iomap; ... ...
/*注册中断服务函数*/
ret = request_irq(res->start, s3c24xx_i2c_irq, IRQF_DISABLED,pdev->name, i2c);
... ... /*注册i2c_adapter适配器结构体*/
ret = i2c_add_adapter(&i2c->adap);
... ...
}
其中i2c_adapter结构体是放在s3c24xx_i2c->adap下,如下图所示:
4.接下来我们进入i2c_add_adapter()函数看看,到底如何注册的
int i2c_add_adapter(struct i2c_adapter *adapter)
{
int id, res = ; retry:
if (idr_pre_get(&i2c_adapter_idr, GFP_KERNEL) == ) //调用idr_pre_get()为i2c_adapter预留内存空间
return -ENOMEM; mutex_lock(&core_lists); /* "above" here means "above or equal to", sigh */
res = idr_get_new_above(&i2c_adapter_idr, adapter,__i2c_first_dynamic_bus_num, &id);
//调用idr_get_new_above()将结构插入i2c_adapter_idr中,并将插入的位置赋给id,以后可以通过id在i2c_adapter_idr中找到相应的i2c_adapter结构体 mutex_unlock(&core_lists); if (res < ) {
if (res == -EAGAIN)
goto retry;
return res;
}
adapter->nr = id;
return i2c_register_adapter(adapter); //调用i2c_register_adapter()函数进一步来注册.
}
其中i2c_register_adapter()函数代码如下所示:
static int i2c_register_adapter(struct i2c_adapter *adap)
{
struct list_head *item; //链表头,用来存放i2c_driver结构体的表头
struct i2c_driver *driver; //i2c_driver,用来描述一个IIC设备驱动
list_add_tail(&adap->list, &adapters); //添加到内核的adapter链表中
... ...
list_for_each(item,&drivers) { //for循环,从drivers链表里找到i2c_driver结构体的表头
driver = list_entry(item, struct i2c_driver, list); //通过list_head表头,找到i2c_driver结构体
if (driver->attach_adapter)
/* We ignore the return code; if it fails, too bad */
driver->attach_adapter(adap);
//调用i2c_driver的attach_adapter函数来看看,这个新注册的设配器是否支持i2c_driver }
}
在i2c_register_adapter()函数里主要执行以下几步:
①将adapter放入i2c_bus_type的adapter链表
②将所有的i2c设备调出来,执行i2c_driver设备的attach_adapter函数来匹配
其中, i2c_driver结构体会在后面讲述到
而i2c_adapter适配器结构体的成员结构,如下所示:
struct i2c_adapter {
struct module *owner; //所属模块
unsigned int id; //algorithm的类型,定义于i2c-id.h,
unsigned int class;
const struct i2c_algorithm *algo; //总线通信方法结构体指针
void *algo_data; //algorithm数据
struct rt_mutex bus_lock; //控制并发访问的自旋锁
int timeout;
int retries; //重试次数
struct device dev; //适配器设备
int nr; //存放在i2c_adapter_idr里的位置号
char name[]; //适配器名称
struct completion dev_released; //用于同步
struct list_head userspace_clients; //client链表头
};
i2c_adapter表示物理上的一个i2C设备(适配器), 在i2c-s3c2410.c中,是存放在s3c24xx_i2c结构体下的(struct i2c_adapter adap)成员中
5.其中s3c24xx_i2c的结构体成员如下所示
static const struct i2c_algorithm s3c24xx_i2c_algorithm = {
.master_xfer = s3c24xx_i2c_xfer, //主机传输
.functionality = s3c24xx_i2c_func,
};
static struct s3c24xx_i2c s3c24xx_i2c = {
.lock = __SPIN_LOCK_UNLOCKED(s3c24xx_i2c.lock),
.wait = __WAIT_QUEUE_HEAD_INITIALIZER(s3c24xx_i2c.wait),
.tx_setup = , //用来延时,等待SCL被释放
.adap = { // i2c_adapter适配器结构体
.name = "s3c2410-i2c",
.owner = THIS_MODULE,
.algo = &s3c24xx_i2c_algorithm, //存放i2c_algorithm算法结构体
.retries = , //重试次数
.class = I2C_CLASS_HWMON,
},
};
显然这里是直接设置了i2c_adapter结构体,所以在s3c24xx_i2c_probe ()函数中没有分配i2c_adapter适配器结构体,
其中, i2c_adapter结构体的名称等于"s3c2410-i2c",它的通信方式等于s3c24xx_i2c_algorithm,重试次数等于2
PS:如果缺少i2c_algorithm的i2c_adapter什么也做不了,就只是个I2C设备,而没有通信方式
s3c24xx_i2c_algorithm中的关键函数master_xfer()就是用于产生i2c访问周期需要的start stop ack等信号
比如,在s3c24xx_i2c_algorithm中的关键函数master_xfer()里,调用了:
s3c24xx_i2c_xfer -> s3c24xx_i2c_doxfer()->s3c24xx_i2c_message_start()
来启动传输message信息, 其中s3c24xx_i2c_message_start()函数代码如下:
static void s3c24xx_i2c_message_start(struct s3c24xx_i2c *i2c, struct i2c_msg *msg)
{ unsigned int addr = (msg->addr & 0x7f) << ; //IIC从设备地址的最低位为读写标志位
... ... stat = ;
stat |= S3C2410_IICSTAT_TXRXEN; //设置标志位启动IIC收发使能 if (msg->flags & I2C_M_RD) { //判断是读,还是写
stat |= S3C2410_IICSTAT_MASTER_RX;
addr |= ; //设置从IIC设备地址为读标志
} else
stat |= S3C2410_IICSTAT_MASTER_TX; s3c24xx_i2c_enable_ack(i2c); //使能ACK信号 iiccon = readl(i2c->regs + S3C2410_IICCON); //读出IICCON寄存器 writel(stat, i2c->regs + S3C2410_IICSTAT); //写入IICSTAT寄存器,使能IIC的读或写标志 dev_dbg(i2c->dev, "START: %08lx to IICSTAT, %02x to DS\n", stat, addr); writeb(addr, i2c->regs + S3C2410_IICDS); //将IIC从设备地址写入IICDS寄存器 /* delay here to ensure the data byte has gotten onto the bus
* before the transaction is started */ ndelay(i2c->tx_setup); //延时,等待SCL被释放,下面便可以发送起始信号+IIC设备地址值 dev_dbg(i2c->dev, "iiccon, %08lx\n", iiccon);
writel(iiccon, i2c->regs + S3C2410_IICCON); stat |= S3C2410_IICSTAT_START;
writel(stat, i2c->regs + S3C2410_IICSTAT);
//设置IICSTAT寄存器的bit5=1,开始发送起始信号+IIC从设备地址值,并回应ACK
}
通过上面的代码和注释,发现主要是写入IIC从设备地址,然后发送起始信号+IIC从设备地址值,并回应ACK
显然IIC总线驱动i2c-s3c2410.c,主要设置适配器adapter,里面帮我们做好了IIC通信的架构,就是不知道发什么内容
我们进入driver/i2c/chips中,看看eeprom设备驱动是如何写的
参考: driver/i2c/chips/eeprom.c
6.还是首先来看它的init入口函数:

其中struct i2c_driver eeprom_driver的成员如下:
static struct i2c_driver eeprom_driver = {
.driver = {
.name = "eeprom", //名称
},
.id = I2C_DRIVERID_EEPROM, //IIC设备标识ID
.attach_adapter = eeprom_attach_adapter, //用来与总线驱动的适配器匹配,匹配成功添加到适配器adapter中
.detach_client = eeprom_detach_client, //与总线驱动的适配器解绑,分离这个IIC从设备
};
如下图所示, eeprom_driver结构体的ID成员在i2c-id.h中,里面还定义了大部分常用I2C设备驱动的设备ID

显然,在init函数中通过i2c_add_driver()注册i2c_driver结构体,然后通过i2c_driver ->attach_adapter来匹配内核中的各个总线驱动的适配器, 发送这个设备地址,若有ACK响应,表示匹配成功
7.接下来,我们进入i2c_add_driver()来看看是不是这样的
int i2c_add_driver(struct module *owner, struct i2c_driver *driver)
{
driver->driver.owner = owner;
driver->driver.bus = &i2c_bus_type; //将i2c_driver放在i2c_bus_type链表中 res = driver_register(&driver->driver); //注册一个i2c_driver
... ... if (driver->attach_adapter) {
struct i2c_adapter *adapter; //定义一个i2c_adapter适配器
list_for_each_entry(adapter, &adapters, list) //for循环提取出adapters链表中所有的i2c_adapter适配器,放入到adapter结构体中
{
driver->attach_adapter(adapter); //来匹配取出来的i2c_adapter适配器
}
}
... ...
return ;
}
在i2c_add_driver ()函数里主要执行以下几步:
①放入到i2c_bus_type链表
②取出adapters链表中所有的i2c_adapter,然后执行i2c_driver->attach_adapter()
所以i2c_adapter适配器和i2c_driver设备驱动注册框架如下所示:

这里调用了i2c_driver ->attach_adapter(adapter),我们看看里面是不是通过发送IIC设备地址,等待ACK响应来匹配的
8.以struct i2c_driver eeprom_driver 为例,进入i2c_driver ->eeprom_attach_adapter()函数
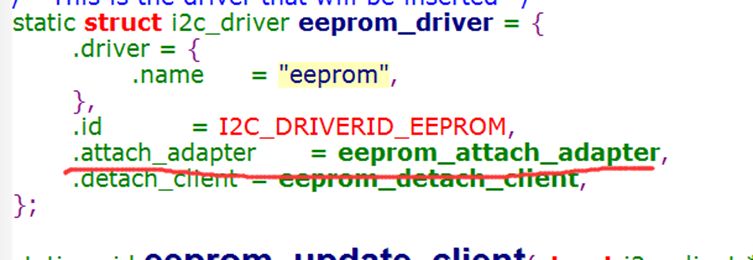
如下图所示,里面调用了i2c_probe(adapter, &addr_data, eeprom_detect)函数

上图的第1个参数就是i2c_adapter适配器,第2个参数addr_data变量,里面存放了IIC设备地址的信息,第3个参数eeprom_detect就是具体的设备探测回调函数i2c_probe()函数,会通过adapter适配器发送IIC设备地址addr_data,如果收到ACK信号,就调用eeprom_detect()回调函数来注册i2c_client结构体,该结构体对应真实的物理从设备,而i2c_driver对应的是设备驱动,也就是说,只有当适配器支持这个设备驱动,才会注册i2c_client从设备,后面会讲这个回调函数如何注册i2c_client
而在i2c_driver ->detach_client()中,则注销i2c_client结构体
其中addr_data变量是struct
i2c_client_address_data结构体,它的成员如下所示:
struct i2c_client_address_data {
unsigned short *normal_i2c; //存放正常的设备高7位地址数据
unsigned short *probe; //存放不受*ignore影响的高7位设备地址数据
unsigned short *ignore; //存放*ignore的高7位设备地址数据
unsigned short **forces; //forces表示适配器匹配不了该设备,也要将其放入适配器中
};
当上面结构体的数组成员以I2C_CLIENT_END结尾,则表示地址已结束,比如at24c02设备为例,看这个结构体如何定义的:
#define AT24C02_ADDR (0xA0>>1) //AT24C02地址
static unsigned short ignore[] = { I2C_CLIENT_END };
static unsigned short normal_addr[] = { AT24C02_ADDR, I2C_CLIENT_END };
static unsigned short force_addr[] = {ANY_I2C_BUS, AT24C02_ADDR ,2C_CLIENT_END};
static unsigned short * forces[] = {force_addr, NULL};
//ANY_I2C_BUS:表示支持所有适配器总线,若填指定的适配器总线ID,则表示该设备只支持指定的那个适配器
static struct i2c_client_address_data addr_data = {
.normal_i2c = normal_addr, //存放at24c02地址
.probe = ignore, //表示无地址
.ignore = ignore, //表示无地址
. forces = forces, //存放强制的at24c02地址,表示强制支持
};
一般而言,都不会设置.forces成员,这里只是打个比方
8.1接下来继续进入i2c_probe()函数继续分析,如下所示:
int i2c_probe(struct i2c_adapter *adapter,struct i2c_client_address_data *address_data,int (*found_proc) (struct i2c_adapter *, int, int))
{
... ...
err = i2c_probe_address(adapter,forces[kind][i + ],kind, found_proc);
}
里面调用了i2c_probe_address()函数,从名称上来看,显然它就是用来发送起始信号+设备地址,来探测IIC设备地址用的
8.2进入i2c_probe_address()函数:
static int i2c_probe_address(struct i2c_adapter *adapter, int addr, int kind,int (*found_proc) (struct i2c_adapter *, int, int))
{ /*判断设备地址是否有效,addr里存放的是设备地址前7位,比如AT24C02=0xA0,那么addr=0x50*/
if (addr < 0x03 || addr > 0x77) {
dev_warn(&adapter->dev, "Invalid probe address 0x%02x\n",addr); //打印地址无效,并退出
return -EINVAL;
} /*查找链表中其它IIC设备的设备地址,若这个设备地址已经被使用,则return*/
if (i2c_check_addr(adapter, addr))
return ; if (kind < ) {
if (i2c_smbus_xfer(adapter, addr, , , ,I2C_SMBUS_QUICK, NULL) < ) //进入I2C传输函数
return ;
... ...
}
8.3 其中i2c_smbus_xfer()传输函数如下:
s32 i2c_smbus_xfer(struct i2c_adapter * adapter, u16 addr, unsigned short flags,char read_write, u8 command, int size,union i2c_smbus_data * data)
{
s32 res; flags &= I2C_M_TEN | I2C_CLIENT_PEC; if (adapter->algo->smbus_xfer) { //如果adapter适配器有smbus_xfer这个函数
mutex_lock(&adapter->bus_lock); //加互斥锁
res = adapter->algo->smbus_xfer(adapter,addr,flags,read_write,command,size,data);
//调用adapter适配器里的传输函数
mutex_unlock(&adapter->bus_lock); //解互斥锁
} else //否则使用默认函数传输设备地址
res = i2c_smbus_xfer_emulated(adapter,addr,flags,read_write,command,size,data);
return res;
}
看了上面代码后,显然我们的s3c2410-i2c适配器没有algo->smbus_xfer函数,而是使用i2c_smbus_xfer_emulated()函数,如下图所示:

PS:通常适配器都是不支持的,使用默认的i2c_smbus_xfer_emulated()函数
8.4 接下来看i2c_smbus_xfer_emulated()函数如何传输的:
static s32 i2c_smbus_xfer_emulated(struct i2c_adapter * adapter, u16 addr,unsigned short flags,char read_write, u8 command, int size, union i2c_smbus_data * data)
{
unsigned char msgbuf0[I2C_SMBUS_BLOCK_MAX+]; //属于 msg[0]的buf成员
unsigned char msgbuf1[I2C_SMBUS_BLOCK_MAX+]; //属于 msg[1]的buf成员
int num = read_write == I2C_SMBUS_READ?:; //如果为读命令,就等于2,表示要执行两次数据传输
struct i2c_msg msg[] = { { addr, flags, , msgbuf0 },
{ addr, flags | I2C_M_RD, , msgbuf1 }}; //定义两个i2c_msg结构体, msgbuf0[] = command; //IIC设备地址最低位为读写命令
... ...
if (i2c_transfer(adapter, msg, num) < )
return -; /*设置i2c_msg结构体成员*/
if (read_write == I2C_SMBUS_READ)
switch(size) {
... ...
case I2C_SMBUS_BYTE_DATA: //如果是读字节
if (read_write == I2C_SMBUS_READ)
msg[].len = ;
else {
msg[].len = ;
msgbuf0[] = data->byte;
}
break;
... ...
}
... ... if (i2c_transfer(adapter, msg, num) < ) //将 i2c_msg结构体的内容发送给I2C设备
return -;
... ...
}
其中i2c_msg结构体的结构,如下所示:
struct i2c_msg {
__u16 addr; //I2C从机的设备地址
__u16 flags; //当flags=0表示写, flags= I2C_M_RD表示读
__u16 len; //传输的数据长度,等于buf数组里的字节数
__u8 *buf; //存放数据的数组
};
上面代码中之所以读操作需要两个i2c_msg,写操作需要一个i2c_msg,是因为读IIC设备是两个流程
在上一节IIC接口下的24C02 驱动分析:http://www.cnblogs.com/lifexy/p/7793686.html里就已经分析到了,
只要发送一个S起始信号则就是一个i2c_msg,如下两个读写操作图所示:
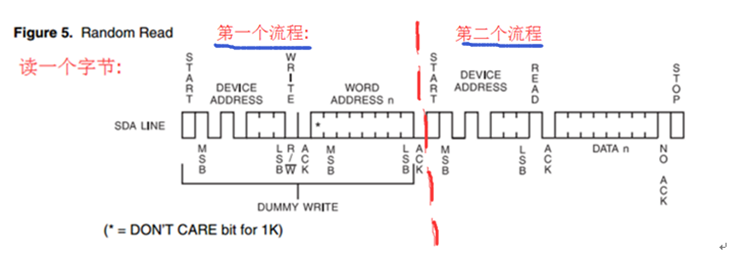
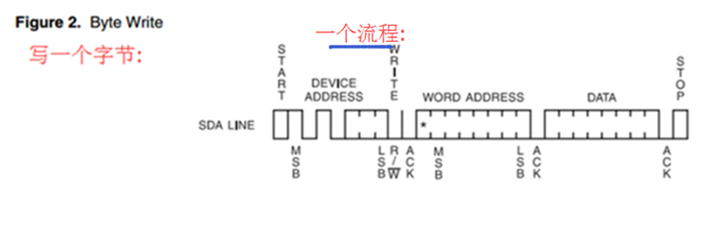
而在i2c_transfer()函数中,最终又是调用了之前分析的i2c_adapter->algo->master_xfer()发送函数,如下图所示:
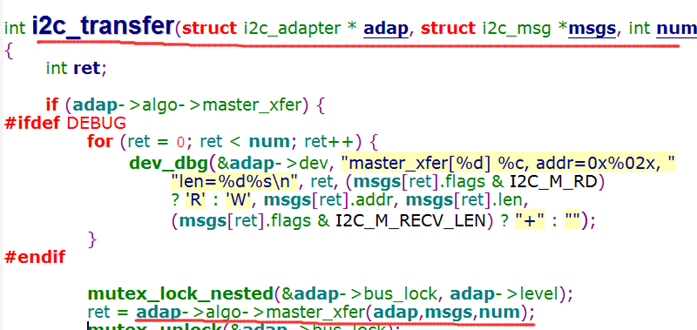
其中i2c_transfer()的参数*adap表示通过哪个适配器传输出去,msgs表示I2C消息,num表示msgs的数目
内核每发送一个Msg都会先发出S开始信号和设备地址.直到所有Msg传输完毕,最后发出P停止信号。
当i2c_transfer()返回值为正数,表示已经传输正数个数据,当返回负数,说明I2C传输出错
8.5 所以在i2c_driver ->attach_adapter(adapter)函数里主要执行以下几步:
1) 调用 i2c_probe(adap, i2c_client_address_data设备地址结构体, 回调函数);
2) 将要发的设备地址结构体打包成i2c_msg,
3) 然后执行i2c_transfer()来调用i2c_adapter->algo->master_xfer()将i2c_msg发出去
4)若收到ACK回应,便进入回调函数,注册i2c_client从设备,使该设备与适配器联系在一起
所以适配器和iic设备驱动最终注册框架图如下所示:
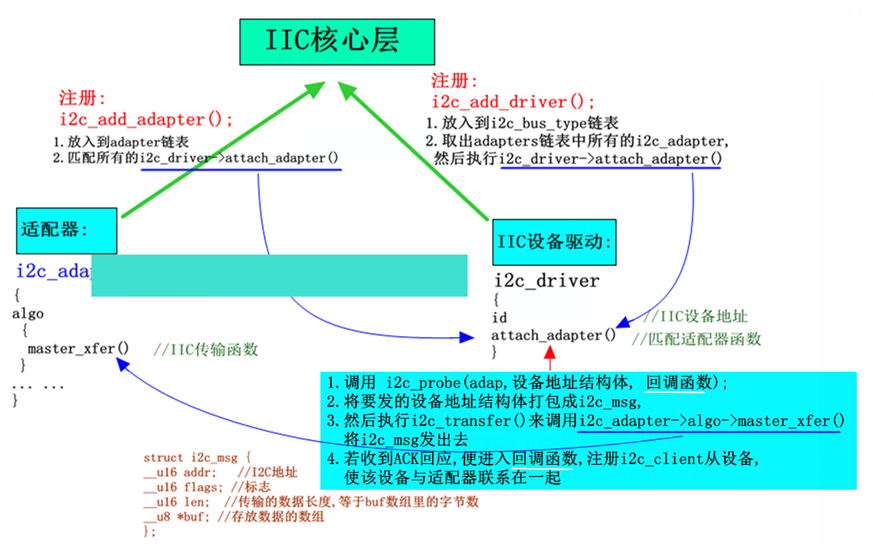
9.接下来便来分析回调函数如何注册i2c_client从设备的
先来看看i2c_client结构体:
struct i2c_client {
unsigned short flags;//标志
unsigned short addr; //该i2c从设备的设备地址,存放地址高7位
char name[I2C_NAME_SIZE]; //设备名字
struct i2c_adapter *adapter;//依附的i2c_adapter,表示该IIC设备支持哪个适配器
struct i2c_driver *driver;//依附的i2c_driver ,表示该IIC从设备的驱动是哪个
struct device dev;//设备结构体
int irq;//设备所使用的结构体
struct list_head detected;//链表头
};
还是以driver/i2c/chips/eeprom.c为例,如下图所示:

9.1这里的回调函数是eeprom_detect()函数,代码如下所示:
static int eeprom_detect(struct i2c_adapter *adapter, int address, int kind)
{
struct i2c_client *new_client; //定义一个i2c_client结构体局部变量 new_client =kzalloc(sizeof(struct i2c_client), GFP_KERNEL); //分配i2c_client结构体为全局变量 /*设置i2c_client结构体*/
new_client->addr = address; //设置设备地址
new_client->adapter = adapter; //设置依附的i2c_adapter
new_client->driver = &eeprom_driver; //设置依附的i2c_driver
new_client->flags = ; //设置标志位为初始值
strlcpy(new_client->name, "eeprom", I2C_NAME_SIZE); //设置名字 /*注册i2c_client*/
if ((err = i2c_attach_client(new_client)))
goto exit_kfree; //注册失败,便释放i2c_client这个全局变量
... ...
exit_kfree:
kfree(new_client);
exit:
return err;
}
当注册了i2c_client从设备后,便可以使用i2c_transfer()来实现与设备传输数据了
10.接下来,我们便参考driver/i2c/chips/eeprom.c驱动,来写出24C02驱动以及测试程序
驱动代码步骤如下:
1.定义file_operations结构体 ,设置字符设备的读写函数(实现对24C02的读写操作)
//构造i2c_msg结构体, 使用i2c_transfer()来实现与设备传输数据
2.定义i2c_client_address_data结构体,里面保存24C02的设备地址
3. 定义一个i2c_driver驱动结构体
3.1 设置i2c_driver-> attach_adapter
// 里面直接调用 i2c_probe(adap, i2c_client_address_data结构体, 回调函数);
3.2 设置i2c_driver-> detach_client
//里面卸载i2c_client, 字符设备
4.写回调函数,里面注册i2c_client,字符设备( 字符设备用来实现读写24C02里的数据)
4.1 分配并设置i2c_client
4.2 使用i2c_attach_client()将i2c_client与适配器进行连接
4.3 注册字符设备
5. 写init入口函数,exit出口函数
init: 使用i2c_add_driver()注册i2c_driver
exit: 使用i2c_del_driver ()卸载i2c_driver
具体驱动代码如下所示:
/*
* I2C-24C02
*/
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/module.h>
#include <linux/slab.h>
#include <linux/jiffies.h>
#include <linux/i2c.h>
#include <linux/mutex.h>
#include <linux/fs.h>
#include <asm/uaccess.h> static struct i2c_client *at24c02_client; //从设备结构体
static struct class *at24c02_class; //类结构体
static unsigned int at24c02_major; /*1.定义file_operations结构体 ,
* 设置字符设备的读写函数(实现对24C02的读写操作)
*/
static ssize_t at24c02_read(struct file *file, char __user *buf, size_t size, loff_t * offset)
{
struct i2c_msg msg[];
u8 addr;
u8 data;
int ret; if(size!=)
return -EINVAL; copy_from_user(&addr,buf,); //获取读地址 msg[].addr=at24c02_client->addr;
msg[].flags=; //写标志
msg[].len =;
msg[].buf =&addr; //写入要读的地址 msg[].addr=at24c02_client->addr;
msg[].flags=I2C_M_RD; //读标志
msg[].len =;
msg[].buf =&data; //读出数据 ret=i2c_transfer(at24c02_client->adapter, msg, );
if(ret==) //表示2个msg传输成功
{
copy_to_user(buf,&data,); //上传数据
return ;
}
else
return -EAGAIN;
} static ssize_t at24c02_write(struct file *file, const char __user *buf, size_t size, loff_t *offset)
{
struct i2c_msg msg[];
u8 val[];
int ret; if(size!=) //地址 数据
return -EINVAL; copy_from_user(val,buf,); //获取 地址 数据
msg[].addr=at24c02_client->addr;
msg[].flags=; //写标志
msg[].len =;
msg[].buf =val; //写入要写的地址 数据 ret=i2c_transfer(at24c02_client->adapter, msg, );
if(ret==) //表示1个msg传输成功
{
return ;
}
else
return -EAGAIN;
} static struct file_operations at24c02_fops={
.owner = THIS_MODULE,
.read = at24c02_read,
.write = at24c02_write,
}; /*2.定义i2c_client_address_data结构体,保存24C02的设备地址*/
static unsigned short ignore[] = { I2C_CLIENT_END };
static unsigned short normal_addr[] = {0X50, I2C_CLIENT_END };
static unsigned short force_addr[] = {ANY_I2C_BUS, 0x60, I2C_CLIENT_END};
static unsigned short * forces[] = {force_addr, NULL};
static struct i2c_client_address_data at24c02_addr={
.normal_i2c=normal_addr,
.probe=ignore,
.ignore=ignore,
// .forces=forces, // 强制地址
}; /*3. 定义一个i2c_driver驱动结构体*/
static int at24c02_attach_adapter(struct i2c_adapter *adapter);
static int at24c02_detach_client(struct i2c_client *client);
static int at24c02_detect(struct i2c_adapter *adap, int addr, int kind); /* This is the driver that will be inserted */
static struct i2c_driver at24c02_driver = {
.driver = {
.name = "at24c02",
}, .attach_adapter = at24c02_attach_adapter, //绑定回调函数
.detach_client = at24c02_detach_client, //解绑回调函数
}; /*3.1 设置i2c_driver-> attach_adapter*/
static int at24c02_attach_adapter(struct i2c_adapter *adapter)
{
return i2c_probe(adapter,&at24c02_addr, at24c02_detect);
} /*3.2 设置i2c_driver-> detach_client*/
static int at24c02_detach_client(struct i2c_client *client)
{
printk("at24c02_detach_client\n"); i2c_detach_client(at24c02_client) ;
kfree(at24c02_client);
class_device_destroy(at24c02_class,MKDEV(at24c02_major, ));
class_destroy(at24c02_class); return ;
} /*4.写回调函数,里面注册i2c_client,字符设备*/
static int at24c02_detect(struct i2c_adapter *adap, int addr, int kind)
{
printk("at24c02_detect\n"); /* 4.1 分配并设置i2c_client */
at24c02_client= kzalloc(sizeof(struct i2c_client), GFP_KERNEL); at24c02_client->addr = addr;
at24c02_client->adapter = adap;
at24c02_client->driver = &at24c02_driver;
at24c02_client->flags = ;
strlcpy(at24c02_client->name, "at24c02", I2C_NAME_SIZE); /*4.2 使用i2c_attach_client()将i2c_client与适配器进行连接*/
i2c_attach_client(at24c02_client) ; /*4.3 注册字符设备*/
at24c02_major= register_chrdev(, "at24c02", &at24c02_fops);
at24c02_class=class_create(THIS_MODULE, "at24c02");
class_device_create(at24c02_class,, MKDEV(at24c02_major, ),,"at24c02");
return ;
} /*5. 写init入口函数,exit出口函数*/
static int at24c02_init(void)
{
i2c_add_driver(&at24c02_driver);
return ;
}
static void at24c02_exit(void)
{
i2c_del_driver(&at24c02_driver);
}
module_init(at24c02_init);
module_exit(at24c02_exit);
MODULE_LICENSE("GPL");
11.测试运行
如下图所示:

使用register_chrdev_region()系列来注册字符设备
1.之前注册字符设备用的如下函数注册字符设备驱动:
register_chrdev(unsigned int major, const char *name,const struct file_operations *fops);
但其实这个函数是linux版本2.4之前的注册方式,它的原理是:
(1)确定一个主设备号
(2)构造一个file_operations结构体, 然后放在chrdevs数组中
(3)注册:register_chrdev
然后当读写字符设备的时候,就会根据主设备号从chrdevs数组中取出相应的结构体,并调用相应的处理函数。
它会有个很大的缺点:
每注册个字符设备,还会连续注册0~255个次设备号,使它们绑定在同一个file_operations操作方法结构体上,在大多数情况下,都只用极少的次设备号,所以会浪费很多资源.
2.所以在2.4版本后,内核里就加入了以下几个函数也可以来实现注册字符设备:
分为了静态注册(指定设备编号来注册)、动态分配(不指定设备编号来注册),以及有连续注册的次设备编号范围区间,避免了register_chrdev()浪费资源的缺点
2.1:
/*指定设备编号来静态注册一个字符设备*/
int register_chrdev_region(dev_t from, unsigned count, const char *name);
from: 注册的指定起始设备编号,比如:MKDEV(100, 0),表示起始主设备号100, 起始次设备号为0
count:需要连续注册的次设备编号个数,比如: 起始次设备号为0,count=100,表示0~99的次设备号都要绑定在同一个file_operations操作方法结构体上
*name:字符设备名称
当返回值小于,表示注册失败
2.2:
/*动态分配一个字符设备,注册成功并将分配到的主次设备号放入*dev里*/
int alloc_chrdev_region(dev_t *dev, unsigned baseminor, unsigned count,const char *name);
*dev: 存放起始设备编号的指针,当注册成功, *dev就会等于分配到的起始设备编号,可以通过MAJOR()和MINNOR()函数来提取主次设备号
baseminor:次设备号基地址,也就是起始次设备号
count:需要连续注册的次设备编号个数,比如: 起始次设备号(baseminor)为0,baseminor=2,表示0~1的此设备号都要绑定在同一个file_operations操作方法结构体上
*name:字符设备名称
当返回值小于0,表示注册失败
2.3:
/*初始化cdev结构体,并将file_operations结构体放入cdev-> ops 里*/
void cdev_init(struct cdev *cdev, const struct file_operations *fops);
其中cdev结构体的成员,如下所示:
struct cdev {
struct kobject kobj; // 内嵌的kobject对象
struct module *owner; //所属模块
const struct file_operations *ops; //操作方法结构体
struct list_head list; //与 cdev 对应的字符设备文件的 inode->i_devices 的链表头
dev_t dev; //起始设备编号,可以通过MAJOR(),MINOR()来提取主次设备号
unsigned int count; //连续注册的次设备号个数
};
2.4:
/*将cdev结构体添加到系统中,并将dev(注册好的设备编号)放入cdev-> dev里, count(次设备编号个数)放入cdev->count里*/
int cdev_add(struct cdev *p, dev_t dev, unsigned count);
2.5:
/*将系统中的cdev结构体删除掉*/
void cdev_del(struct cdev *p);
2.6:
/*注销字符设备*/
void unregister_chrdev_region(dev_t from, unsigned count);
from: 注销的指定起始设备编号,比如:MKDEV(100, 0),表示起始主设备号100, 起始次设备号为0
count:需要连续注销的次设备编号个数,比如: 起始次设备号为0,baseminor=100,表示注销掉0~99的次设备号
3.接下来,我们便来写一个字符设备驱动
里面调用两次上面的函数,构造两个不同的file_operations操作结构体,
次设备号0~1对应第一个file_operations,
次设备号2~3对应第二个file_operations,
然后在/dev/下,通过次设备号(0~4)创建5个设备节点, 利用应用程序打开这5个文件,看有什么现象
3.1 驱动代码如下:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <asm/irq.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <asm/uaccess.h>
#include <asm/io.h>
#include <linux/list.h>
#include <linux/cdev.h> static int hello_fops1_open(struct inode *inode, struct file *file)
{
printk("open_hello1!!!\n");
return ;
} static int hello_fops2_open (struct inode *inode, struct file *file)
{
printk("open_hello2!!!\n");
return ;
} /* 操作结构体1 */
static struct file_operations hello1_fops={
.owner=THIS_MODULE,
.open =hello_fops1_open,
}; /* 操作结构体2 */
static struct file_operations hello2_fops={
.owner=THIS_MODULE,
.open =hello_fops2_open,
}; static int major; //主设备
static struct cdev hello1_cdev; //保存 hello1_fops操作结构体的字符设备
static struct cdev hello2_cdev; //保存 hello2_fops操作结构体的字符设备
static struct class *cls; static int chrdev_ragion_init(void)
{
dev_t devid; alloc_chrdev_region(&devid, , ,"hello"); //动态分配字符设备: (major,0) (major,1) (major,2) (major,3) major=MAJOR(devid); cdev_init(&hello1_cdev, &hello1_fops);
cdev_add(&hello1_cdev, MKDEV(major,), ); //(major,0) (major,1) cdev_init(&hello2_cdev, &hello2_fops);
cdev_add(&hello2_cdev,MKDEV(major,), ); //(major,2) (major,3) cls=class_create(THIS_MODULE, "hello");
/*创建字符设备节点*/
class_device_create(cls,, MKDEV(major,), , "hello0"); //对应hello_fops1操作结构体
class_device_create(cls,, MKDEV(major,), , "hello1"); //对应hello_fops1操作结构体
class_device_create(cls,, MKDEV(major,), , "hello2"); //对应hello_fops2操作结构体
class_device_create(cls,, MKDEV(major,), , "hello3"); //对应hello_fops2操作结构体
class_device_create(cls,, MKDEV(major,), , "hello4"); //对应空
return ;
} void chrdev_ragion_exit(void)
{
class_device_destroy(cls, MKDEV(major,));
class_device_destroy(cls, MKDEV(major,));
class_device_destroy(cls, MKDEV(major,));
class_device_destroy(cls, MKDEV(major,));
class_device_destroy(cls, MKDEV(major,)); class_destroy(cls); cdev_del(&hello1_cdev);
cdev_del(&hello2_cdev);
unregister_chrdev_region(MKDEV(major,), ); //注销(major,0)~(major,3)
} module_init(chrdev_ragion_init);
module_exit(chrdev_ragion_exit);
MODULE_LICENSE("GPL");
3.2 测试代码如下所示:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
void print_useg(char arg[]) //打印使用帮助信息
{
printf("useg: \n");
printf("%s [dev]\n",arg);
} int main(int argc,char **argv)
{ int fd;
if(argc!=)
{
print_useg(argv[]);
return -;
} fd=open(argv[],O_RDWR);
if(fd<)
printf("can't open %s \n",argv[]);
else
printf("can open %s \n",argv[]);
return ;
}
4.运行测试:
如下图,挂载驱动后,通过 ls /dev/hello* -l ,看到创建了5个字符设备节点
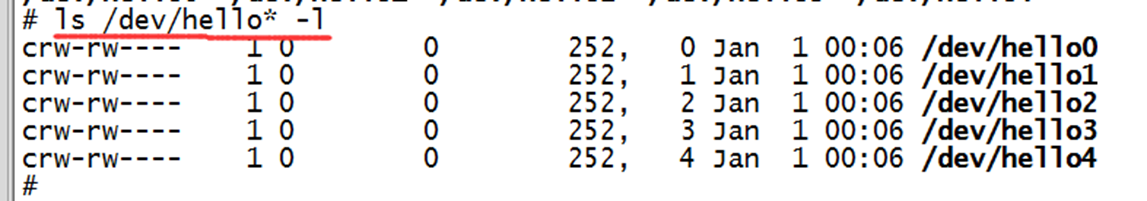
接下来开始测试驱动,如下图所示,
打开/dev/hello0时,调用的是驱动代码的操作结构体hello1_fops里的.open(),
打开/dev/hello2时,调用的是驱动代码的操作结构体hello1_fops里的.open(),
打开/dev/hello4时,打开无效,因为在驱动代码里没有分配次设备号4的操作结构体,
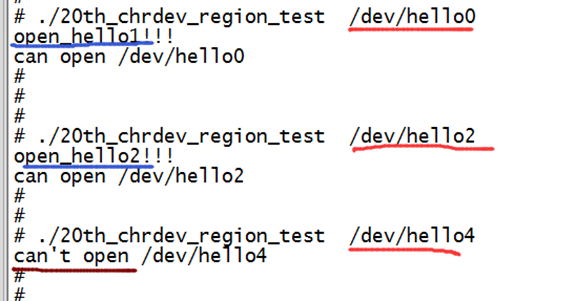
总结:
使用register_chrdev_region()等函数来注册字符设备,里面可以存放多个不同的file_oprations操作结构体,实现各种不同的功能
Linux-RTC驱动分析及使用
linux中的rtc驱动位于drivers/rtc下,里面包含了许多开发平台的RTC驱动,我们这里是以S3C24xx为主,所以它的RTC驱动为rtc-s3c.c
1.进入./drivers/rtc/rtc-s3c.c
还是首先进入入口函数,如下图所示:

这里注册了一个“s3c2410-rtc”名称的平台设备驱动
而“s3c2410-rtc”的平台设备,在./arch/arm/plat-s3c24xx/dev.c里定义了,只不过这里没有注册,如下图所示:

当内核匹配到有与它名称同名的平台设备,就会调用.probe函数,接下来我们便进入s3c2410_rtcdrv->probe函数中看看,做了什么:
static int s3c_rtc_probe(struct platform_device *pdev)
{
struct rtc_device *rtc; //rtc设备结构体
struct resource *res;
int ret; s3c_rtc_tickno = platform_get_irq(pdev, ); //获取IRQ_TICK节拍中断资源
s3c_rtc_alarmno = platform_get_irq(pdev, ); //获取IRQ_RTC闹钟中断资源
res = platform_get_resource(pdev, IORESOURCE_MEM, ); //获取内存资源 s3c_rtc_mem = request_mem_region(res->start,res->end-res->start+,pdev->name);//申请内存资源 s3c_rtc_base = ioremap(res->start, res->end - res->start + ); //对内存进行重映射 s3c_rtc_enable(pdev, ); //设置硬件相关设置,使能RTC寄存器 s3c_rtc_setfreq(s3c_rtc_freq); //设置TICONT寄存器,使能节拍中断,设置节拍计数值 /*1.注册RTC设备*/
rtc = rtc_device_register("s3c", &pdev->dev, &s3c_rtcops,THIS_MODULE);
rtc->max_user_freq = ;
platform_set_drvdata(pdev, rtc);
return ;
}
显然最终会调用rtc_device_register()函数来向内核注册rtc_device设备,注册成功会返回一个已注册好的rtc_device,
而s3c_rtcops是一个rtc_class_ops结构体,里面就是保存如何操作这个rtc设备的函数,比如读写RTC时间,读写闹钟时间等,注册后,会保存在rtc_device->ops里
该函数在drivers/rtc/Class.c文件内被定义。Class.c文件主要定义了RTC子系统,
而内核初始化,便会进入Class.c,进入rtc_init()->rtc_dev_init(),来注册字符设备:
err = alloc_chrdev_region(&rtc_devt, , RTC_DEV_MAX, "rtc");
// RTC_DEV_MAX=16,表示只注册0~15个次设备号,设备编号保存在rtc_devt中
2.它与rtc_device_register()函数注册RTC设备,会有什么关系?
接下来便来看rtc_device_register(),代码如下:
struct rtc_device *rtc_device_register(const char *name, struct device *dev,const struct rtc_class_ops *ops,struct module *owner)
{
struct rtc_device *rtc; //定义一个rtc_device结构体
... ...
rtc = kzalloc(sizeof(struct rtc_device), GFP_KERNEL); //分配rtc_device结构体为全局变量 /*设置rtc_device*/
rtc->id = id;
rtc->ops = ops; //将s3c_rtcops保存在rtc_device->ops里
rtc->owner = owner;
rtc->max_user_freq = ;
rtc->dev.parent = dev;
rtc->dev.class = rtc_class;
rtc->dev.release = rtc_device_release;
... ... rtc_dev_prepare(rtc); //1.做提前准备,初始化cdev结构体
... ...
rtc_dev_add_device(rtc); //2.在/dev下创建rtc相关文件,将cdev添加到系统中 rtc_sysfs_add_device(rtc); //在/sysfs下创建rtc相关文件
rtc_proc_add_device(rtc); //在/proc下创建rtc相关文件
... ...
return rtc;
}
上面的rtc_dev_prepare(rtc)和rtc_dev_add_device(rtc)主要做了以下两个(位于./drivers/rtc/rtc-dev.c):
cdev_init(&rtc->char_dev, &rtc_dev_fops); //绑定file_operations cdev_add(&rtc->char_dev, rtc->dev.devt, ); //注册rtc->char_dev字符设备,添加一个从设备到系统中
显然这里的注册字符设备,和我们上节讲的http://www.cnblogs.com/lifexy/p/7827559.html一摸一样的流程
所以“s3c2410-rtc”平台设备驱动的.probe主要做了以下几件事:
- 1.设置RTC相关寄存器
- 2.分配rtc_device结构体
- 3.设置rtc_device结构体
- -> 3.1 将struct rtc_class_ops s3c_rtcops放入rtc_device->ops,实现对RTC读写时间等操作
- 4. 注册rtc->char_dev字符设备,且该字符设备的操作结构体为: struct file_operations rtc_dev_fops
3.上面的file_operations操作结构体rtc_dev_fops 的成员,如下图所示:

3.1当我们应用层open(”/dev/rtcXX”)时,就会调用rtc_dev_fops-> rtc_dev_open(),我们来看看如何open的:
static int rtc_dev_open(struct inode *inode, struct file *file)
{
struct rtc_device *rtc = container_of(inode->i_cdev,struct rtc_device, char_dev);//获取对应的rtc_device
const struct rtc_class_ops *ops = rtc->ops; //最终等于s3c_rtcops file->private_data = rtc; //设置file结构体的私有成员等于rtc_device,再次执行ioctl等函数时,直接就可以提取file->private_data即可 err = ops->open ? ops->open(rtc->dev.parent) : ; //调用s3c_rtcops->open mutex_unlock(&rtc->char_lock);
return err;
}
显然最终还是调用rtc_device下的s3c_rtcops->open:

而s3c_rtc_open()函数里主要是申请了两个中断,一个闹钟中断,一个计时中断:
static int s3c_rtc_open(struct device *dev)
{
struct platform_device *pdev = to_platform_device(dev);
struct rtc_device *rtc_dev = platform_get_drvdata(pdev);
int ret; ret = request_irq(s3c_rtc_alarmno, s3c_rtc_alarmirq,IRQF_DISABLED, "s3c2410-rtc alarm", rtc_dev); //申请闹钟中断
if (ret) {
dev_err(dev, "IRQ%d error %d\n", s3c_rtc_alarmno, ret);
return ret;
} ret = request_irq(s3c_rtc_tickno, s3c_rtc_tickirq,IRQF_DISABLED, "s3c2410-rtc tick", rtc_dev);//申请计时中断
if (ret) {
dev_err(dev, "IRQ%d error %d\n", s3c_rtc_tickno, ret);
goto tick_err;
} return ret; tick_err:
free_irq(s3c_rtc_alarmno, rtc_dev);
return ret;
}
3.2 当我们应用层open后,使用 ioctl(int fd, unsigned long cmd, ...)时,就会调用rtc_dev_fops-> rtc_dev_ioctl ():
static int rtc_dev_ioctl(struct inode *inode, struct file *file,unsigned int cmd, unsigned long arg)
{
struct rtc_device *rtc = file->private_data; //提取rtc_device
void __user *uarg = (void __user *) arg;
... ... switch (cmd) {
case RTC_EPOCH_SET:
case RTC_SET_TIME: //设置时间
if (!capable(CAP_SYS_TIME))
return -EACCES;
break;
case RTC_IRQP_SET: //改变中断触发速度
... ...}
... ...
switch (cmd) {
case RTC_ALM_READ: //读闹钟时间
err = rtc_read_alarm(rtc, &alarm); //调用s3c_rtcops-> read_alarm
if (err < )
return err; if (copy_to_user(uarg, &alarm.time, sizeof(tm))) //长传时间数据
return -EFAULT;
break; case RTC_ALM_SET: //设置闹钟时间 , 调用s3c_rtcops-> set_alarm
... ... case RTC_RD_TIME: //读RTC时间, 调用s3c_rtcops-> read_alarm
... ... case RTC_SET_TIME: //写RTC时间,调用s3c_rtcops-> set_time
... ... case RTC_IRQP_SET: //改变中断触发频率,调用s3c_rtcops-> irq_set_freq
... ... }
最终还是调用s3c_rtcops下的成员函数,我们以s3c_rtcops-> read_alarm()函数为例,看看如何读出时间的:
static int s3c_rtc_gettime(struct device *dev, struct rtc_time *rtc_tm)
{
unsigned int have_retried = ;
void __iomem *base = s3c_rtc_base; //获取RTC相关寄存器基地址 retry_get_time: /*获取年,月,日,时,分,秒寄存器*/
rtc_tm->tm_min = readb(base + S3C2410_RTCMIN);
rtc_tm->tm_hour = readb(base + S3C2410_RTCHOUR);
rtc_tm->tm_mday = readb(base + S3C2410_RTCDATE);
rtc_tm->tm_mon = readb(base + S3C2410_RTCMON);
rtc_tm->tm_year = readb(base + S3C2410_RTCYEAR);
rtc_tm->tm_sec = readb(base + S3C2410_RTCSEC); /* 判断秒寄存器中是0,则表示过去了一分钟,那么小时,天,月,等寄存器中的值都可能已经变化,需要重新读取这些寄存器的值*/
if (rtc_tm->tm_sec == && !have_retried) {
have_retried = ;
goto retry_get_time;
} /*将获取的寄存器值,转换为真正的时间数据*/
BCD_TO_BIN(rtc_tm->tm_sec);
BCD_TO_BIN(rtc_tm->tm_min);
BCD_TO_BIN(rtc_tm->tm_hour);
BCD_TO_BIN(rtc_tm->tm_mday);
BCD_TO_BIN(rtc_tm->tm_mon);
BCD_TO_BIN(rtc_tm->tm_year); rtc_tm->tm_year += ; //存储器中存放的是从1900年开始的时间,所以加上100
rtc_tm->tm_mon -= ;
return ;
}
同样, 在s3c_rtcops-> set_time()函数里,也是向相关寄存器写入RTC时间
所以,总结如下所示:
- rtc_device->char_dev: 字符设备,与应用层、以及更底层的函数打交道
- rtc_device->ops: 更底层的操作函数,直接操作硬件相关的寄存器,被rtc_device->char_dev调用
4.修改内核
我们单板上使用ls /dev/rtc*,找不到该字符设备, 因为内核里只定义了s3c_device_rtc这个RTC平台设备,没有注册,所以平台驱动没有被匹配上,接下来我们来修改内核里的注册数组
4.1进入arch/arm/plat-s3c24xx/Common-smdk.c
如下图所示,在smdk_devs[]里,添加RTC的平台设备即可,当内核启动时,就会调用该数组,将里面的platform_device统统注册一遍

然后将Common-smdk.c代替虚拟机的内核目录下的Common-smdk.c,重新make uImage编译内核即可
5.测试运行
启动后,如下图所示, 使用ls /dev/rtc*,就找到了rtc0这个字符设备

5.1接下来,便开始设置RTC时间
在linux里有两个时钟:
硬件时钟(2440里寄存器的时钟)、系统时钟(内核中的时钟)
所以有两个不同的命令: date命令、hwclock命令
5.2 date命令使用:
输入date查看系统时钟:

如果觉得不方便也可以指定格式显示日期,需要在字符串前面加”+”
如下图所示,输入了 date "+ %Y/%m/%d %H:%M:%S"

- %M:表示秒
- %m:表示月
- %Y:表示年,当只需要最后两位数字,输入%y即可
date命令设置时间格式如下:
date 月日时分年.秒
如下图所示,输入date 111515292017.20,即可设置好系统时钟

5.3 hwclock命令使用:
常用参数如下所示
-r, --show 读取并打印硬件时钟(read hardware clock and print result )
-s, --hctosys 将硬件时钟同步到系统时钟(set the system time from the hardware clock )
-w, --systohc 将系统时钟同步到硬件时钟(set the hardware clock to the current system time )
如下图所示,使用hwclock -w,即可同步硬件时钟
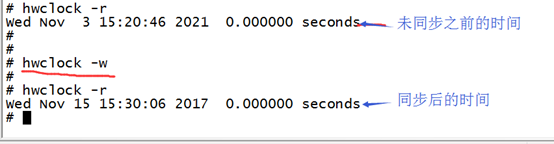
然后重启后,使用date命令,看到时间正常
Linux-2440下的DMA驱动(详解)
DMA(Direct Memory Access)
即直接存储器访问, DMA 传输方式无需 CPU 直接控制传输,通过硬件为 RAM 、I/O 设备开辟一条直接传送数据的通路,能使 CPU 的效率大为提高。
学了这么多驱动,不难推出DMA的编写套路:
- 1)注册DMA中断,分配缓冲区
- 2)注册字符设备,并提供文件操作集合fops
- -> 2.1)file_operations里设置DMA硬件相关操作,来启动DMA
由于我们是用字符设备的测试方法测试的,而本例子只是用两个地址之间的拷贝来演示DMA的作用,所以采用字符设备方式编写
1.驱动编写之前,先来讲如何分配释放缓冲区、DMA相关寄存器介绍、使用DMA中断
1.1在linux中,分配释放DMA缓冲区,常用以下几个函数
1)
/*该函数只禁止cache缓冲,保持写缓冲区,也就是对注册的物理区写入数据,也会更新到对应的虚拟缓存区上*/
void *dma_alloc_writecombine(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
//分配DMA缓存区
//返回值为:申请到的DMA缓冲区的虚拟地址,若为NULL,表示分配失败,需要释放,避免内存泄漏
//参数如下:
//*dev:指针,这里填0,表示这个申请的缓冲区里没有内容
//size:分配的地址大小(字节单位)
//*handle:申请到的物理起始地址
//gfp:分配出来的内存参数,标志定义在<linux/gfp.h>,常用标志如下:
//GFP_ATOMIC 用来从中断处理和进程上下文之外的其他代码中分配内存. 从不睡眠.
//GFP_KERNEL 内核内存的正常分配. 可能睡眠.
//GFP_USER 用来为用户空间页来分配内存; 它可能睡眠.
2)
/*该函数禁止cache缓存以及禁止写入缓冲区,从而使CPU读写的地址和DMA读写的地址内容一致*/
void * dma_alloc_coherent(struct device *dev, size_t size, dma_addr_t *handle, gfp_t gfp);
//分配DMA缓存区,返回值和参数和上面的函数一直
3)
dma_free_writecombine(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle); //释放DMA缓存,与dma_alloc_writecombine()对应
//size:释放长度
//cpu_addr:虚拟地址,
//handle:物理地址
4)
dma_free_coherent(struct device *dev, size_t size, void *cpu_addr, dma_addr_t handle) //释放DMA缓存,与dma_alloc_coherent ()对应
//size:释放长度
//cpu_addr:虚拟地址,
//handle:物理地址
(PS: dma_free_writecombine()其实就是dma_free_conherent(),只不过是用了#define重命名而已。)
而我们之前用的内存分配kmalloc()函数,是不能用在DMA上,因为分配出来的内存可能在物理地址上是不连续的.
1.2 那么2440开发板如何来启动DMA,先来看2440的DMA寄存器
(PS:实际这些DMA相关的寄存器,在linux内核中三星已封装好了,可以直接调用,不过非常麻烦,还不如直接设置寄存器,可以参考:http://blog.csdn.net/mirkerson/article/details/6632273)
1.2.1 2440支持4个通道的DMA控制器
其中4个通道的DMA外设请求源,如下图所示(通过DCONn寄存器的[26:24]来设置)
(PS:如果请求源是系统总线上的,就只需要设置DCONn寄存器的[23]=0即可)
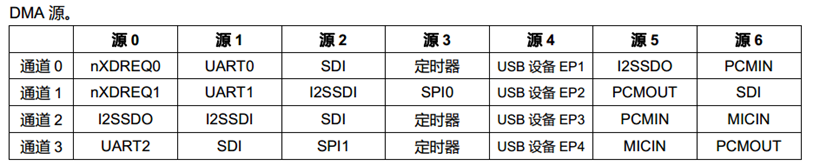
1.2.2 且每个通道都可以处理以下4种情况:
1) 源和目标都在系统总线上(比如:两个物理内存地址)
2) 当目标在外设总线上时,源在系统总线上(外设指:串口,定时器,I2C,I2S等)
3) 当目标在系统总线上时,源在外设总线上
4) 源和目标都在外设总线上
1.2.3 DMA有两种工作模式(通过DCONn寄存器的[28]来设置)
查询模式:
当DMA请求XnXDREQ为低电平时,则DMA会一直传输数据,直到DMA请求拉高,才停止
握手模式:
当DMA请求XnXDREQ有下降沿触发时,则DMA会传输一次数据
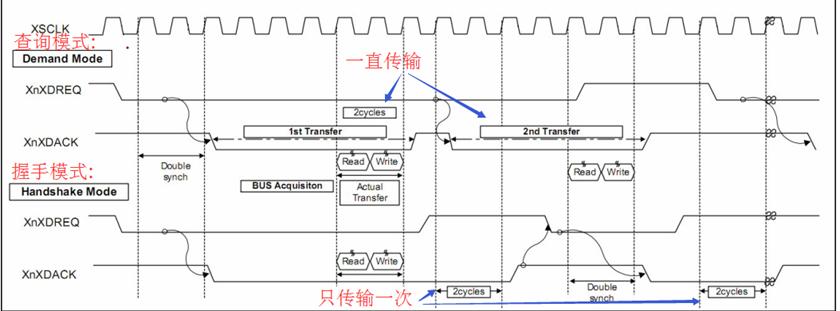
1.2.4 DMA有两种传输模式(通过DCONn寄存器的[31]来设置)
单元传输:
指传输过程中,每执行一次,则读1次,写1次.(如上图所示)
突发4传输:
指传输过程中,每执行一次,则读4次,然后写4次(如下图所示)
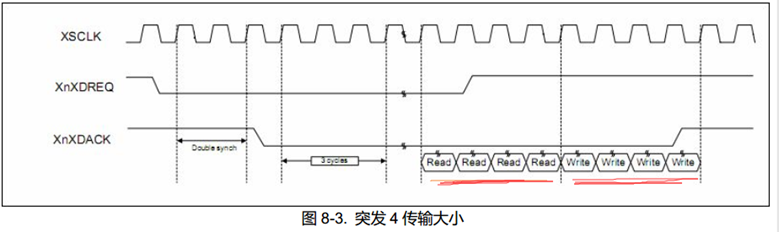
1.2.5 2440中的DMA寄存器如下图所示:
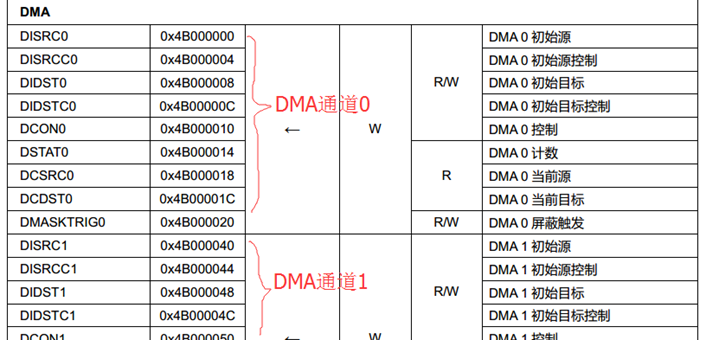
共有4个通道的寄存器,且每个通道的寄存器内容都一致,所以我们以DMA通道0为例:
1)DISRC0初始源寄存器
[30:0] : 存放DMA源的基地址
2)DISRCC0初始源控制寄存器
[1] : 源位置选择,0:源在系统总线上, 1:源在外设总线上
[0] : 源地址选择,0:传输时源地址自动增加, 1:源地址固定
3)DIDST0初始目标寄存器
[30:0] : 设置DMA目的的基地址
4)DIDSTC0初始目标控制寄存器
[2] :
中断时间选择, 0:当DMA传输计数=0,立即发生中断 1:执行完自动加载后再发送中断(也就是计数为0,然后重新加载计数值)
[1] : 目的位置选择, 0:目的在系统总线上, 1:目的在外设总线上
[0] : 目的地址选择, 0:传输时目的地址自动增加, 1:目的地址固定
5)DCON0控制寄存器
[31] : 工作模式选择, 0:查询模式 1:握手模式
(当源处于外设时,尽量选择握手模式)
[30] : 中断请求(DREQ)/中断回应(DACK)的同步时钟选择, 0:PCLK同步 1:HCLK同步
(PS:如果有设备在HCLK上,该位应当设为1,比如:(SDRAM)内存数组, 反之当这些设备在PCLK上,应当设为0,比如:ADC,IIS,I2C,UART)
[29] : DMA传输计数中断使能/禁止 0:禁止中断 1:当传输完成后,产生中断
[28] : 传输模式选择, 0:单元传输 1:突发4传输
[27] : 传输服务模式
0:单服务模式,比如:有2个DMA请求,它们会被顺序执行一次(单元传输/突发4传输)后停止,然后直到有下一次DMA请求,再重新开始另一次循环。
1:全服务模式,指该DMA若有请求,则会占用DMA总线,一直传输,期间若有其它DMA请求,只有等待传输计数TC为0,才会执行其它DMA请求
[26:24] : DMA外设请求源选择
[23] :
软件/硬件请求源选择 0:软件请求 1:硬件请求(还需要设置[26:24]来选择外设源)
[22] : 重新加载开关选项 为0即可
[21:20] : 传输数据大小 为00(8位)即可
[19:0] :
设置DMA传输的计数TC
6)DSTAT0状态寄存器
[21:20] : DMA状态 00:空闲 01:忙
[19:0] :
传输计数当前值CURR_TC 为0表示传输结束
7)DCSRC0当前源寄存器
[30:0] : 存放DMA当前的源基地址
8)DCDST0当前目标寄存器
[30:0] : 存放DMA当前的目的基地址
9)DMASKTRIG0触发屏蔽寄存器
[2] :
停止STOP 该位写1,立刻停止DMA当前的传输
[1] : DMA通道使能 0:关闭DMA的通道0(禁止DMA请求) 1:开启DMA的通道0(开启DMA请求)
[0] : 软件请求触发 1:表示启动一次软件请求DMA,只有DCONn[23]=0和DMASKTRIGn[1]=1才有效,DMA传输时,该位自动清0
1.3接下来就开始讲linux注册DMA中断
首先,DMA的每个通道只能有一个源- >目的,所以输入命令 cat /proc/interrupts ,找到DMA3中断未被使用
所以在linux中使用:
request_irq(IRQ_DMA3, s3c_dma_irq, NULL, "s3c_dma", );// s3c_dma_irq:中断服务函数,这里注册DMA3中断服务函数
//NULL:中断产生类型, 不需要,所以填NULL
//1:表示中断时,传入中断函数的参数,本节不需要所以填1,切记不能填0,否则注册失败
2.接下来,我们便来写一个DMA的字符设备驱动
步骤如下:
- 1) 注册DMA中断,分配两个DMA缓冲区(源、目的)
- 2) 注册字符设备,并提供文件操作集合fops
- -> 2.1) 通过ioctl的cmd来判断是使用DMA启动两个地址之间的拷贝,还是直接两个地址之间的拷贝
- -> 2.2)若是DMA启动,则设置DMA的相关硬件,并启动DMA传输
2.1 所以,驱动代码如下所示:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <linux/irq.h>
#include <asm/irq.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <asm/uaccess.h>
#include <asm/io.h>
#include <linux/dma-mapping.h> #define S3C_DMA_SIZE 512*1024 //DMA传输长度 512KB #define NORMAL_COPY 0 //两个地址之间的正常拷贝
#define DMA_COPY 1 //两个地址之间的DMA拷贝 /*函数声明*/
static DECLARE_WAIT_QUEUE_HEAD(s3c_dma_queue); //声明等待队列
static int s3c_dma_ioctl(struct inode *inode, struct file *file, unsigned int cmd, unsigned long flags); /*
* 定义中断事件标志
* 0:进入等待队列 1:退出等待队列
*/
static int s3c_dma_even=; static unsigned char *source_virt; //源虚拟地址
static unsigned int source_phys; //源物理地址 static unsigned char *dest_virt; //目的虚拟地址
static unsigned int dest_phys; //目的虚拟地址 /*DMA3寄存器*/
struct S3c_dma3_regs{
unsigned int disrc3 ; //0x4b0000c0
unsigned int disrcc3 ;
unsigned int didst3 ;
unsigned int didstc3 ;
unsigned int dcon3 ;
unsigned int dstat3 ;
unsigned int dcsrc3 ;
unsigned int dcdst3 ;
unsigned int dmasktrig3; //0x4b0000e0
};
static volatile struct S3c_dma3_regs *s3c_dma3_regs; /*字符设备操作*/
static struct file_operations s3c_dma_fops={
.owner = THIS_MODULE,
.ioctl = s3c_dma_ioctl,
}; /*中断服务函数*/
static irqreturn_t s3c_dma_irq (int irq, void *dev_id)
{
s3c_dma_even=; //退出等待队列
wake_up_interruptible(&s3c_dma_queue); //唤醒 中断
return IRQ_HANDLED;
} /*ioctl函数*/
static int s3c_dma_ioctl(struct inode *inode, struct file *file, unsigned int cmd, unsigned long flags)
{
int i;
memset(source_virt, 0xAA, S3C_DMA_SIZE);
memset(dest_virt, 0x55, S3C_DMA_SIZE); switch(cmd)
{
case NORMAL_COPY: //正常拷贝 for(i=;i<S3C_DMA_SIZE;i++)
dest_virt[i] = source_virt[i]; if(memcmp(dest_virt, source_virt, S3C_DMA_SIZE)==)
{
printk("NORMAL_COPY OK\n");
return ;
}
else
{
printk("NORMAL_COPY ERROR\n");
return -EAGAIN;
} case DMA_COPY: //DMA拷贝 s3c_dma_even=; //进入等待队列 /*设置DMA寄存器,启动一次DMA传输 */
/* 源的物理地址 */
s3c_dma3_regs->disrc3 = source_phys;
/* 源位于AHB总线, 源地址递增 */
s3c_dma3_regs->disrcc3 = (<<) | (<<);
/* 目的的物理地址 */
s3c_dma3_regs->didst3 = dest_phys;
/* 目的位于AHB总线, 目的地址递增 */
s3c_dma3_regs->didstc3 = (<<) | (<<) | (<<);
/* 使能中断,单个传输,软件触发, */
s3c_dma3_regs->dcon3=(<<)|(<<)|(<<)|(<<)|(<<)|(<<)|(S3C_DMA_SIZE<<);
//启动一次DMA传输
s3c_dma3_regs->dmasktrig3 = (<<) | (<<); wait_event_interruptible(s3c_dma_queue, s3c_dma_even); //进入睡眠,等待DMA传输中断到来才退出 if(memcmp(dest_virt, source_virt, S3C_DMA_SIZE)==)
{
printk("DMA_COPY OK\n");
return ;
}
else
{
printk("DMA_COPY ERROR\n");
return -EAGAIN;
} break;
}
return ;
} static unsigned int major;
static struct class *cls;
static int s3c_dma_init(void)
{
/*1.1 注册DMA3 中断 */
if(request_irq(IRQ_DMA3, s3c_dma_irq,NULL, "s3c_dma",))
{
printk("Can't request_irq \"IRQ_DMA3\"!!!\n ");
return -EBUSY;
} /*1.2 分配两个DMA缓冲区(源、目的)*/
source_virt=dma_alloc_writecombine(NULL,S3C_DMA_SIZE, &source_phys, GFP_KERNEL);
if(source_virt==NULL)
{
printk("Can't dma_alloc \n ");
return -ENOMEM;
} dest_virt=dma_alloc_writecombine(NULL,S3C_DMA_SIZE, &dest_phys, GFP_KERNEL);
if(dest_virt==NULL)
{
printk("Can't dma_alloc \n ");
return -ENOMEM;
} /*2.注册字符设备,并提供文件操作集合fops*/
major=register_chrdev(, "s3c_dma",&s3c_dma_fops);
cls= class_create(THIS_MODULE, "s3c_dma");
class_device_create(cls, NULL,MKDEV(major,), NULL, "s3c_dma"); s3c_dma3_regs=ioremap(0x4b0000c0, sizeof(struct S3c_dma3_regs)); return ;
} static void s3c_dma_exit(void)
{
iounmap(s3c_dma3_regs); class_device_destroy(cls, MKDEV(major,));
class_destroy(cls); dma_free_writecombine(NULL, S3C_DMA_SIZE, dest_virt, dest_phys);
dma_free_writecombine(NULL, S3C_DMA_SIZE, source_virt, source_phys); free_irq(IRQ_DMA3, ); }
module_init(s3c_dma_init);
module_exit(s3c_dma_exit);
MODULE_LICENSE("GPL");
2.2 应用测试程序如下所示:
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <sys/ioctl.h>
#include <string.h> /* ./dma_test NORMAL
* ./dma_test DMA
*/
#define NORMAL_COPY 0 //两个地址之间的正常拷贝
#define DMA_COPY 1 //两个地址之间的DMA拷贝 void print_usage(char *name)
{
printf("Usage:\n");
printf("%s <NORMAL | DMA>\n", name);
} int main(int argc, char **argv)
{
int fd,i=; if (argc != )
{
print_usage(argv[]);
return -;
} fd = open("/dev/s3c_dma", O_RDWR);
if (fd < )
{
printf("can't open /dev/s3c_dma\n");
return -;
} if (strcmp(argv[], "NORMAL") == )
{
while (i--) //调用驱动的ioctl(),30次
{
ioctl(fd, NORMAL_COPY);
}
}
else if (strcmp(argv[], "DMA") == )
{
while (i--) //调用驱动的ioctl(),30次
{
ioctl(fd, DMA_COPY);
}
}
else
{
print_usage(argv[]);
return -;
}
return ;
}
3.测试运行
输入 ./dma_test NORMAL & ,使用CPU正常拷贝,可以发现占用了大部分资源,输入 ls 无反应:

输入./dma_test DMA & ,使用DMA拷贝,输入 ls 立马有反应,从而释放了CPU的压力:
Linux-实现U盘自动挂载(详解)
1.当我们每次插入u盘后,都会自动创键U盘的设备节点/dev/sda%d
这是因为里面调用了device_create()实现的, busybox的mdev机制就会根据主次设备号等信息,在/dev下创建设备节点,如下图所示:
而想使用上面的sda1设备节点,读写数据时,还需要使用mount /dev/sda1 /mnt,来挂载u盘才行,会显得非常麻烦,如下图所示:
2.其实,可以在/etc/mdev.conf文件里加入一行语句就能实现自动装载u盘,也可以在里面干其它与设备节点相关的事
2.1而/etc/mdev.conf又是什么?
它是属于mdev的一个配置文件,而mdev之前就讲过了,它主要的功能是管理/dev目录底下的设备节点
当系统中有自动注册设备节点的时候,mdev就会调用/etc/mdev.conf一次, 该文件可以实现与设备节点相关的事,比如自动装载usb,打印创建的设备节点信息等
3.我们首先来分析device_create(),是如何来调用到/etc/mdev.conf的,后面再讲如何使用mdev.conf(也可以直接跳过,直接看下面第4小节,如何使用)
(PS: 之前创建字符设备节点用的class_device_create(),其实是和device_create功能差不多)
3.1 device_create()最终调用了:device_create()->device_register()->device_add():
device_create()->device_register()->device_add()函数如下所示: int class_device_add(struct class_device *class_dev)
{
... ...
kobject_uevent(&class_dev->kobj, KOBJ_ADD); // KOBJ_ADD是一个枚举值
//调用了kobject_uevent_env(kobj, action, NULL); // action=KOBJ_ADD
}
3.2 device_create()->device_register()->device_add()->kobject_uevent_env()函数如下所示:
int kobject_uevent_env(struct kobject *kobj, enum kobject_action action,char *envp_ext[])
{
char **envp;
char *buffer;
char *scratch;
int i = ;
... ... /* 通过KOBJ_ADD获取字符串"add",所以action_string="add" */
action_string = action_to_string(action); // action=KOBJ_ADD /* environment index */
envp = kzalloc(NUM_ENVP * sizeof (char *), GFP_KERNEL); //分配一个环境变量索引值 /* environment values */
buffer = kmalloc(BUFFER_SIZE, GFP_KERNEL); //分配一个环境变量缓冲值 /* event environemnt for helper process only */
/*设置环境变量*/
envp[i++] = "HOME=/";
envp[i++] = "PATH=/sbin:/bin:/usr/sbin:/usr/bin";
scratch = buffer;
envp [i++] = scratch;
scratch += sprintf(scratch, "ACTION=%s", action_string) + ; //"ACTION= add"
envp [i++] = scratch;
scratch += sprintf (scratch, "DEVPATH=%s", devpath) + ;
envp [i++] = scratch;
scratch += sprintf(scratch, "SUBSYSTEM=%s", subsystem) + ;
... ...
/*调用应用程序,比如mdev*/
if (uevent_helper[]) {
char *argv [];
argv [] = uevent_helper; // uevent_helper[]= "/sbin/hotplug";
argv [] = (char *)subsystem;
argv [] = NULL;
call_usermodehelper (argv[], argv, envp, ); //调用应用程序,根据传入的环境变量参数来创建设备节点
}
}
从上面的代码和注释来看,最终通过*argv[], *envp[]两个字符串数组里面存的环境变量参数来创建设备节点的
3.2接下来便在kobject_uevent_env()函数里添加打印信息, 然后重新烧内核:
3.3然后我们以注册一个按键驱动为例
输入 insmod key.ko,打印了以下语句:
class_device: argv[]=/sbin/mdev //调用mdev class_device: argv[]=sixth_dev //类名 class_device: envp[]=HOME=/ class_device: envp[]=PATH=/sbin:/bin:/usr/sbin:/usr/bin class_device: envp[]=ACTION=add //add:表示添加设备节点, 若=remove:表示卸载设备节点 class_device: envp[]=DEVPATH=/class/sixth_dev/buttons //设备的路径 class_device: envp[]=SUBSYSTEM=sixth_dev //类名 class_device: envp[]=SEQNUM= class_device: envp[]=MAJOR= //主设备号 class_device: envp[]=MINOR=
3.4最终这些参数根据/sbin/mdev就进入了busybox的mdev.c的mdev_main()函数里:
int mdev_main(int argc, char **argv)
{
... ...
action = getenv("ACTION"); //获取传进来的执行参数,它等于“add”,则表示创建设备节点
env_path = getenv("DEVPATH"); //获取设备的路径“/class/sixth_dev/buttons”
sprintf(temp, "/sys%s", env_path); //指定temp (真正设备路径)为“/sys/class/sixth_dev/buttons” if (!strcmp(action, "remove")) //卸载设备节点
make_device(temp, ); else if (!strcmp(action, "add")) { //创建设备节点
make_device(temp, );
... ...
}
3.5最终调用mdev_main ()->make_device()函数来创建/卸载设备节点,该函数如下所示:
static void make_device(char *path, int delete) //delete=0:创建, delete=1:卸载
{
/*判断创建的设备节点是否是有效的设备*/
if (!delete) {
strcat(path, "/dev");
len = open_read_close(path, temp + , );
*temp++ = ;
if (len < ) return;
} device_name = bb_basename(path); //通过设备路径,来获取要创建/卸载的设备节点名称
//例: path =“/sys /class/sixth_dev/buttons”,那么device_name=“buttons” type = path[]=='c' ? S_IFCHR : S_IFBLK; //判断如果是在/sys/class/目录下,那么就是字符设备
//因为块设备,是存在/sys/block/目录下的 /* 如果配置了支持mdev.conf选项,那么就解析里边内容并执行 */
if (ENABLE_FEATURE_MDEV_CONF) {
/* mmap the config file */
fd = open("/etc/mdev.conf", O_RDONLY); //调用/etc/mdev.conf配置文件
... ... //开始操作 mdev.conf配置文件
} if (!delete) { //如果是创建设备节点 if (sscanf(temp, "%d:%d", &major, &minor) != ) return; //获取主次设备号
/*调用mknod ()创建字符设备节点*/
if (mknod(device_name, mode | type, makedev(major, minor)) && errno != EEXIST)
bb_perror_msg_and_die("mknod %s", device_name); if (major == root_major && minor == root_minor)
symlink(device_name, "root"); /*若配置了支持mdev.conf选项,则调用chown命令来改变属主,默认uid和gid=0 */
if (ENABLE_FEATURE_MDEV_CONF) chown(device_name, uid, gid);
} if (delete) unlink(device_name); //如果是卸载设备节点
}
从上面的代码和注释分析到,要使用mdev.conf配置文件,还需要配置busybox的menuconfig, 使mdev支持mdev.conf选项才行
如下图,进入busybox目录,然后输入make menuconfig,发现我们已经配置过了该选项了
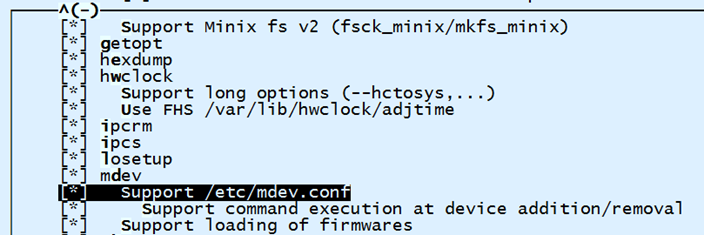
4.接下来,便来看看如何使用mdev.conf, 参考busybox-1.7.0/docs/mdev.txt文档
使用方法如下所示:
the format:
<device regex> <uid>:<gid> <octal permissions> [<@|$|*> <command>]
The special characters have the meaning:
@ Run after creating the device.
$ Run before removing the device.
* Run both after creating and before removing the device.
大概就是:
配置文件格式:
<device regex> <uid>:<gid> <octal permissions> [<@|$|*> <command>]
各个参数代表的含义如下:
device regex:
正则表达式,来表达哪一个设备 ,正则表达式讲解链接:https://deerchao.net/tutorials/regex/regex.htm
uid:
owner (uid,gid:注册设备节点时,就会被chown命令调用,来改变设备的属主,默认都填0即可)
gid:
组ID
octal permissions:
以八进制表示的权限值,会被chmod命令调用,来更改设备的访问权限,默认填660即可
@ : 创建设备节点之后执行命令
$ : 删除设备节点之前执行命令
* : 创建设备节点之后 和 删除设备节点之前 执行命令
command : 要执行的命令
5.接下来便来使用mdev.conf,实现u盘自动装载
vi /etc/mdev.conf
添加以下一句:
sda[1-9]+ 0:0 660 * if [ $ACTION = "add" ]; then mount /dev/$MDEV /mnt; else umount /mnt; fi
[1-9] : 匹配1~9的数字,
+ : 重复匹配一次或更多次
$ACTION=="add" :表示注册设备节点,否则就是注销设备节点
/dev/$MDEV :表示要创建/注销的那个设备节点
所以当我们插上u盘,自动创建了/dev/sda1时,mdev便会进入/etc/mdev.conf配置文件,然后执行mount /dev/ 命令,即可自动装载U盘,如下图所示:
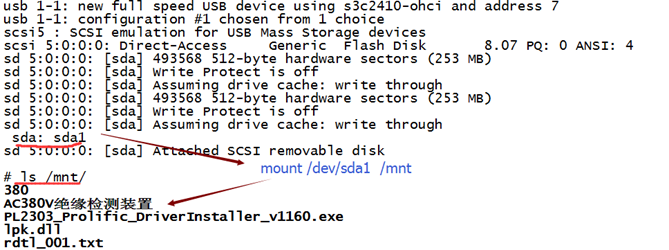
输入ls /dev/sda1 -l,可以看到都是通过mdev.conf里配置信息来创建的设备节点,如下图所示:

而取出u盘时,同样自动umount /mnt来卸载
Linux-printk分析、使用__FILE__, __FUNCTION__, __LINE__ 调试
本节学习目的
- 1)分析printk()函数
- 2)使用printk()调试驱动
1.在驱动调试中,使用printk(),是最简单,最方便的办法
当uboot的命令行里的“console=tty1”时,表示printk()输出在开发板的LCD屏上
当uboot的命令行里的“console=ttySA0,115200”时,表示printk()输出在串口UART0上,波特率=115200
当uboot的命令行里的“console=tty1 console=ttySA0,115200”时,表示printk()同时输出在串口上,以及开发板的LCD屏上
显然printk(),还是根据命令行参数来调用不同控制台的硬件处理函数
内核又是怎么根据上面命令行参数来确定printk()的输出设备?
2.我们以“console=ttySA0,115200”为例,进入linux-2.6.22.6\kernel\printk.c
找到以下一段:
__setup("console=", console_setup);
其中__setup()的作用就是:
若uboot传递进来的命令行字符串里含有“console=”,便调用console_setup()函数,并对“console=”后面带的字符串"ttySA0,115200"进行分析
3.我们以*str= "ttySA0,115200"为例,console_setup()函数如下所示
static int __init console_setup(char *str) //*str="ttySA0,115200"
{
char name[sizeof(console_cmdline[].name)]; // char name[8]
char *s, *options;
int idx;
/*
* Decode str into name, index, options.
*/ if (str[] >= '' && str[] <= '') {
strcpy(name, "ttyS");
strncpy(name + , str, sizeof(name) - );
} else {
strncpy(name, str, sizeof(name) - ); //*name="ttySA0, "
}
name[sizeof(name) - ] = ; //*name="ttySA0"
if ((options = strchr(str, ',')) != NULL) //找到',',返回给options,所以options=",115200"
*(options++) = ; //*options="115200", *str="ttySA0"
#ifdef __sparc__
if (!strcmp(str, "ttya"))
strcpy(name, "ttyS0");
if (!strcmp(str, "ttyb"))
strcpy(name, "ttyS1");
#endif for (s = name; *s; s++) //*s="0"
if ((*s >= '' && *s <= '') || *s == ',')
break; idx = simple_strtoul(s, NULL, ); //和strtoul()一样,将s中的"0"提出来,所以idx=0
*s = ; //将"ttySA0"中的"0"设为0,所以*name="ttySA" add_preferred_console(name, idx, options);
//*name="ttySA"
// idx=0
//*options="115200"
return ;
}
通过上面的代码和注释得到, 最终调用add_preferred_console("ttySA", 0, "115200")函数来添加控制台
4.进入console_setup()->add_preferred_console()
int __init add_preferred_console(char *name, int idx, char *options)
{
struct console_cmdline *c;
int i; /* MAX_CMDLINECONSOLES=8,表示最多添加8个控制台*/
for(i = ; i < MAX_CMDLINECONSOLES && console_cmdline[i].name[]; i++)
if (strcmp(console_cmdline[i].name, name) == &&console_cmdline[i].index == idx)
// console_cmdline[]是一个全局数组,用来匹配要添加的控制台是否重复
{
selected_console = i;
return ; //在console_cmdline[]中,已经存有要添加的控制台,所以return
} if (i == MAX_CMDLINECONSOLES) //i==8,表示数组存满了
return -E2BIG; selected_console = i;
/*将命令行的控制台信息存在console_cmdline[i]中*/
c = &console_cmdline[i];
memcpy(c->name, name, sizeof(c->name));
c->name[sizeof(c->name) - ] = ;
c->options = options;
c->index = idx;
return ;
}
上面函数,最终将控制台的信息放到了console_cmdline[]全局数组中,那接下来来搜索该数组,看看printk()如何调用控制台的硬件处理函数的。
搜索到在linux-2.6.22.6\kernel\Printk.c里的register_console(struct console *console)函数,有用到console_cmdline[]
显然,register_console()函数就用来注册控制台的,继续搜索register_console
如下图所示,找到很多CPU的控制台驱动初始化:

5.我们以2410为例(linux-2.6.22.6\drivers\serial\S3c2410.c):
static int s3c24xx_serial_initconsole(void)
{
... ...
register_console(&s3c24xx_serial_console);
return ;
}
console_initcall(s3c24xx_serial_initconsole); //声明控制台初始化函数
上面通过register_console()来注册s3c24xx_serial_console结构体,该结构体成员如下所示:
static struct console s3c24xx_serial_console =
{
.name = S3C24XX_SERIAL_NAME, //控制台名称
.device = uart_console_device, //tty驱动
.flags = CON_PRINTBUFFER, //标志
.index = -, /索引值
.write = s3c24xx_serial_console_write, //打印串口数据的硬件处理函数
.setup = s3c24xx_serial_console_setup //用来设置UART的波特率,发送,接收等功能
};
该结构体的名称如下图所示:

在register_console()里,便会通过“ttySAC”来匹配console_cmdline[i]的名称,当匹配成功,printk()调用的console结构体便是s3c24xx_serial_console了
6.接下来,分析printk()又是如何调用s3c24xx_serial_console结构体的write(),来打印信息的
printk()函数如下所示
asmlinkage int printk(const char *fmt, ...)
{
va_list args;
int r; va_start(args, fmt);
r = vprintk(fmt, args); //调用vprintk()
va_end(args);
return r;
}
其中args和fmt的值就是我们printk代入的参数
7.然后进入printk()->vprintk():
asmlinkage int vprintk(const char *fmt, va_list args)
{
unsigned long flags;
int printed_len;
char *p;
static char printk_buf[]; //临时缓冲区
static int log_level_unknown = ;
preempt_disable(); //关闭内核抢占
... ... /*将输出信息发送到临时缓冲区printk_buf[] */
printed_len = vscnprintf(printk_buf, sizeof(printk_buf), fmt, args); /*拷贝printk_buf数据到循环缓冲区log_buf[],如果调用者没提供合适的打印级别,插入默认值*/
for (p = printk_buf; *p; p++) {
... ... /*判断printk打印的打印级别,也就是前缀值"<0>"至 "<7>"*/
if (p[] == '<' && p[] >='' && p[] <= '' && p[] == '>')
{ loglev_char = p[]; //获取打印级别字符,将级别放入 loglev_char中
p += ;
printed_len -= ; }
else
{ //若没有打印级别,便插入默认值,比如printk("abc"),会变为printk("<4>abc")
loglev_char = default_message_loglevel+ '';
} ... ... //开始拷贝到循环缓冲区log_buf[]
} /* cpu_online():检测CPU是否在线
have_callable_console():检测是否有注册的控制台*/
if (cpu_online(smp_processor_id()) || have_callable_console()) {
console_may_schedule = ;
release_console_sem(); //调用release_console_sem()向控制台打印信息
} else {
/*释放锁避免刷新缓冲区*/
console_locked = ;
up(&console_sem);
}
lockdep_on();
local_irq_restore(flags); //恢复本地中断标识
}
... ....
}
从上面的代码和注释来看,显然vprintk()的作用就是:
- 1)将打印信息放到临时缓冲区printk_buf[]
- 2)从临时缓冲区printk_buf[]复制到循环缓冲区log_buf[]
- ->2.1)每次拷贝前都要检查打印级别,若没有打印级别,便插入默认值default_message_loglevel
- 3)最后检查是否有注册的控制台,若有,便调用release_console_sem()
7.1 那么打印级别"<0>"至 "<7>"到底是什么?
发现printk的打印级别 在include/linux/kernel.h中找到:
#define KERN_EMERG "<0>" // 系统崩溃
#define KERN_ALERT "<1>" //必须紧急处理
#define KERN_CRIT "<2>" // 临界条件,严重的硬软件错误
#define KERN_ERR "<3>" // 报告错误
#define KERN_WARNING "<4>" //警告
#define KERN_NOTICE "<5>" //普通但还是须注意
#define KERN_INFO "<6>" // 信息
#define KERN_DEBUG "<7>" // 调试信息
7.2 那么,printk()又如何加入这些前缀值?
比如: printk打印级别0 ,可以输入printk(KERN_EMERG "abc");或者printk( "<0>abc");
当printk()里没有打印级别前缀,比如printk("abc "),便会加入默认值default_message_loglevel
7.3 那么默认值default_message_loglevel到底又是定义的哪个级别?
找到:
#define MINIMUM_CONSOLE_LOGLEVEL 1 //打印级别"<1>"
#define DEFAULT_CONSOLE_LOGLEVEL 7 //打印级别"<7>"
#define DEFAULT_MESSAGE_LOGLEVEL 4 //打印级别"<4>" int console_printk[] = {
DEFAULT_CONSOLE_LOGLEVEL, //=打印级别"<7>"
DEFAULT_MESSAGE_LOGLEVEL, // =打印级别"<4>"
MINIMUM_CONSOLE_LOGLEVEL, // =打印级别"<1>"
DEFAULT_CONSOLE_LOGLEVEL, }; #define console_loglevel (console_printk[0]) //信息打印最大值, console_printk[1]=7
#define default_message_loglevel (console_printk[1]) //信息打印默认值, console_printk[1]=4
#define minimum_console_loglevel (console_printk[2]) //信息打印最小值, console_printk[2]=1
#define default_console_loglevel (console_printk[3])
显然默认值default_message_loglevel为打印级别"<4>":
当默认值default_message_loglevel大于console_loglevel时,表示控制台不会打印信息
而最小值minimum_console_loglevel,是用来判断是否大于console_loglevel
8.接下来我们继续进入release_console_sem(),来看看它在哪儿判断打印级别和console_loglevel值的
8.1printk()->vprintk()->release_console_sem():
void release_console_sem(void)
{
... ...
call_console_drivers(_con_start, _log_end);
//将刚刚保存在循环缓冲区log_buf[]里的数据,发送给命令行的控制台里
//_con_start:等于起始地址, _log_end:等于结束地址
}
8.2printk()->vprintk()->release_console_sem()->call_console_drivers():
static void call_console_drivers(unsigned long start, unsigned long end)
{
unsigned long cur_index, start_print;
... ...
cur_index = start;
start_print = start; while (cur_index != end) //当打印数据的地址,等于结束地址,便退出while
{ /*判断printk的打印级别,也就是前缀值"<0>"至"<7>"*/
if (msg_level < && ((end - cur_index) > ) &&LOG_BUF(cur_index + ) == '<' && LOG_BUF(cur_index + ) >= '' &&
LOG_BUF(cur_index + ) <= '' &&LOG_BUF(cur_index + ) == '>')
{ /* LOG_BUF (addr):获取addr地址上的数据 */
msg_level = LOG_BUF(cur_index + ) - ''; //msg_level等于打印级别,0~7
cur_index += ; //跳过前3个前缀值,比如: "<0>abc",变为"abc"
start_print = cur_index; // start_print表示要打印数据的起始地址
} while (cur_index != end) //进入打印数据环节
{
char c = LOG_BUF(cur_index); //获取要打印的cur_index地址上的数据
cur_index++; if (c == '\n') //判断打印的数据是否结尾
{
if (msg_level < ) { //若没有打印级别,便插入默认值,一般默认级别为4
msg_level = default_message_loglevel;
}
_call_console_drivers(start_print, cur_index, msg_level);
//调用_call_console_drivers()
}
}
}
8.3 进入printk()->vprintk()->release_console_sem()->call_console_drivers()->_call_console_drivers():
static void _call_console_drivers(unsigned long start,unsigned long end, int msg_log_level)
{
/*判断要打印数据的打印级别msg_log_level ,若小于console_loglevel 值便进行打印*/
if ((msg_log_level < console_loglevel || ignore_loglevel) &&console_drivers && start != end)
{
... ...
__call_console_drivers(start, end);
}
}
显然得出结果,当printk("abc")无法打印时,可能是default_message_loglevel默认值>=console_loglevel 值
9.那么我们又该如何修改console_loglevel 值?
有以下3种方法
9.1通过修改 /proc/sys/kernel/printk 来更改printk打印级别
如下图所示,可以看到default_message_loglevel默认值小于console_loglevel 值,满足打印条件

然后通过# echo "1 4 1 7" > /proc/sys/kernel/printk来将console_loglevel设为1,即可屏蔽打印
缺点就是内核重启后, /proc/sys/kernel/printk的内容又会恢复初值,等于"7 4 1 7",可以参考方法2和3来弥补该缺点
9.2直接修改内核文件
直接修改_call_console_drivers ()函数(位于kernel\printk.c)
将上面函数里的console_loglevel值改为0:
if ((msg_log_level < || ignore_loglevel) &&console_drivers && start != end)
就可以屏蔽打印了
9.3设置命令行参数
将uboot命令行里的“console=ttySA0,115200”改为“loglevel=0 console=ttySA0,115200”,表示设置内核的console_loglevel 值=0,如下图所示:

如上图所示,也可以向命令行里添加debug、quiet字段
debug:表示将console_loglevel 值=10,表示打印内核中所有的信息,一般用来调试用(后面会讲如何调试)
quiet:表示将console_loglevel 值=4
(*PS:虽然屏蔽打印了,但是打印还存在缓冲区log_buf[]里, 可以通过dmesg命令来查看log_buf[])
10.接下来继续跟踪:
printk()->vprintk()->release_console_sem()->call_console_drivers()->_call_console_drivers()->__call_console_drivers():
static void __call_console_drivers(unsigned long start, unsigned long end)
{
struct console *con; // console结构体
/*for循环查找console */
for (con = console_drivers; con; con = con->next)
{
if ((con->flags & CON_ENABLED) && con->write &&(cpu_online(smp_processor_id())||(con->flags & CON_ANYTIME))) con->write(con, &LOG_BUF(start), end - start);
//调用控制台的write函数打印log_buf的数据
}
}
最终,__call_console_drivers()会调用s3c24xx_serial_console结构体的write函数,来打印信息
11.printk()总结:
1)首先,内核通过命令行参数, 将console信息放入console_cmdline[]全局数组中
比如: “console=ttySA0,115200”
2)然后,通过console_initcall()来查找控制台初始化函数
比如: console_initcall(s3c24xx_serial_initconsole); //来找到s3c24xx_serial_initconsole()函数
3)在控制台初始化函数里,通过register_console()来注册console结构体
比如: register_console(&s3c24xx_serial_console); //注册s3c24xx_serial_console
4)在register_console()里,匹配console_cmdline[]和console结构体,通过命令行参数来找到硬件处理相关的console结构体
5)使用printk(),先将打印信息先存入循环缓冲区log_buf[],再判断打印级别,是否调用console->write
( PS:可以通过 dmesg 命令来打印循环缓冲区log_buf[] )
12.printk()分析完后,接下来便来说说如何使用printk()来调试驱动
只需要一段代码就ok:
printk(KERN_DEBUG"%s %s %d\n", __FILE__, __FUNCTION__, __LINE__);
//__FILE__: 表示文件路径
//__FUNCTION__: 表示函数名
//__LINE__: 表示代码位于第几行
//KERN_DEBUG: 等于7,表示打印级别为7
然后在驱动中,可以通过上面代码插入到每行需要调试的地方,
然后参考上面第9小节,设置console_loglevel值大于7(KERN_DEBUG)。
(当调试完成后,再将console_loglevel设为7,便不会显示调试信息了)
__FILE__, __FUNCTION__, __LINE__ 也可以用在应用层printf()里
Linux-分析并制作环形缓冲区
在上章34.Linux-printk分析、使用printk调试驱动里讲述了:
printk()会将打印信息存在内核的环形缓冲区log_buf[]里, 可以通过dmesg命令来查看log_buf[]
1.环形缓冲区log_buf[]又是存在内核的哪个文件呢?
位于/proc/kmsg里,所以除了dmesg命令查看,也可以使用cat /proc/kmsg来查看
2.但是,dmesg命令和cat /proc/kmsg有所不同
2.1 dmesg命令
每次使用,都会打印出环形缓冲区的所有信息
2.2 cat /proc/kmsg
只会打印出每次新的环形缓冲区的信息
比如,第一次使用cat /proc/kmsg,会打印出内核启动的所有信息
第二次使用cat /proc/kmsg,就不会出现之前打印的信息,只打印继上次使用cat /proc/kmsg之后的新的信息,比如下图所示:

3.接下来我们便进入内核,找/proc/kmsg文件在哪生成的
搜索"kmsg",找到位于fs\proc\proc_misc.c 文件的proc_misc_init()函数中,
该函数主要用来生成登记的设备文件,具体代码如下所示:
const struct file_operations proc_kmsg_operations = {
.read = kmsg_read, //读函数
.poll = kmsg_poll,
.open = kmsg_open,
.release = kmsg_release,
};
void __init proc_misc_init(void)
{
... ...
struct proc_dir_entry *entry; // 用来描述文件的结构体,
entry = create_proc_entry("kmsg", S_IRUSR, &proc_root); //使用create_proc_entry()创建文件
if (entry)
entry->proc_fops = &proc_kmsg_operations; //对创建的文件赋入file_ operations
... ...
}
从上面代码得出,/proc/kmsg文件,也是有file_operations结构体的,而cat命令就会一直读/proc/kmsg的file_operations->read(),实现读log_buf[]的数据
且/proc/kmsg文件是通过create_proc_entry()创建出来的,参数如下所示:
"kmsg":文件名
&proc_root:父目录,表示存在/proc根目录下
S_IRUSR: 等于,表示拥有者(usr)可读,其他任何人不能进行任何操作,如下图所示:

该参数和chmod命令参数一样,除了S_IRUSR还有很多参数,比如:
S_IRWXU: 等于, 表示拥有者(usr)可读(r)可写(w)可执行(x)
S_IRWXG: 等于, 表示拥有者和组用户 (group)可读(r)可写(w)可执行(x)
4.为什么使用dmesg命令和cat /proc/kmsg会有这么大的区别?
我们进入proc_kmsg_operations-> kmsg_read()看看,就知道了
static ssize_t kmsg_read(struct file *file, char __user *buf,size_t count, loff_t *ppos)
{
/*若在非阻塞访问,且没有读的数据,则立刻return*/
if ((file->f_flags & O_NONBLOCK) && !do_syslog(, NULL, ))
return -EAGAIN;
return do_syslog(, buf, count); //开始读数据,buf:用户层地址,count:要读的数据长度
}
5.proc_kmsg_operations-> kmsg_read()->do_syslog(9, NULL, 0)的内容如下所示:

其中log_start和log_end就是环形缓冲区的两个标志, log_start也可以称为读标志位, log_end也可以称为写标志位,当写标志和读标志一致时,则表示没有读的数据了。
6.proc_kmsg_operations-> kmsg_read()->do_syslog(2, buf, count)的内容如下所示:
case : /* Read from log */
error = -EINVAL;
if (!buf || len < ) //判断用户层是否为空,以及读数据长度
goto out;
error = ;
if (!len)
goto out;
if (!access_ok(VERIFY_WRITE, buf, len)) { // access_ok:检查用户层地址是否访问OK
error = -EFAULT;
goto out;
} /*若没有读的数据,则进入等待队列*/
error = wait_event_interruptible(log_wait, (log_start - log_end));
if (error)
goto out; i = ;
spin_lock_irq(&logbuf_lock);
while (!error && (log_start != log_end) && i < len) {
c = LOG_BUF(log_start); // LOG_BUF:取环形缓冲区log_buf[]里的某个位置的数据
log_start++; //读地址++
spin_unlock_irq(&logbuf_lock);
error = __put_user(c,buf); //和 copy_to_user()函数一样,都是上传用户数据
buf++; //用户地址++
i++; //读数据长度++
cond_resched();
spin_lock_irq(&logbuf_lock);
}
spin_unlock_irq(&logbuf_lock);
if (!error)
error = i;
break;}
out:
return error;
}
显然就是对环形缓冲区的读操作,而环形缓冲区的原理又是什么?
7.接下来便来分析环形缓冲区的原理
和上面函数一样, 环形缓冲区需要一个全局数组,还需要两个标志:读标志R、写标志W
我们以一个全局数组my_buff[7]为例,来分析:
7.1环形缓冲区初始时:
int R=; //记录读的位置
int W=; //记录写的位置
上面的代码,如下图1所示:
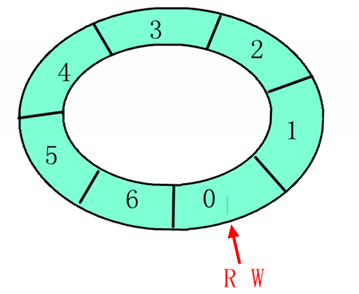
R:从数组[R]开始读数据
W:从数组[W]开始写数据
所以,当R==W时,则表示没有数据可读,通过这个逻辑便能写出读数据了
7.2当我们需要读数据时:
int read_buff(char *p) //p:指向要读出的地址
{
if(R==W)
return ; //读失败
*p=my_buff[R];
R=(R+)%; //R++
return ; //读成功
}
我们以W=3,R=0,为例,调用3次read_buff()函数,如下图所示:
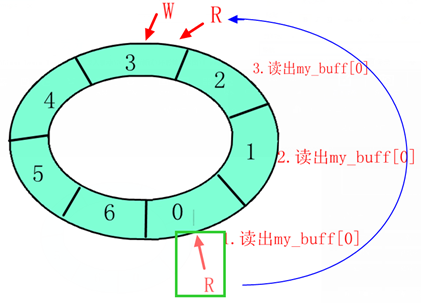
读数据完成,剩下就是写数据了,很显然每写一个数据,W则++
7.3所以写数据函数为:
void write_buff(char c) //c:等于要写入的内容
{
my_buff [W]=c;
W=(W+)%; //W++
if(W==R)
R=(R+)%; //R++
}
7.3.1 上面的代码,为什么要判断if((W==R)?
比如,当我们写入一个8个数据,而my_buff[]只能存7个数据,必定会有W==R的时候,如果不加该判断,效果图如下所示:
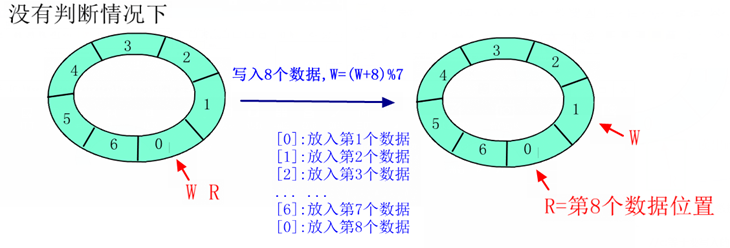
然后我们再多次调用read_buff(),就会发现只读的出第8个数据的值,而前面7个数据都会被遗弃掉
7.3.2 而加入判断后,效果图如下所示:
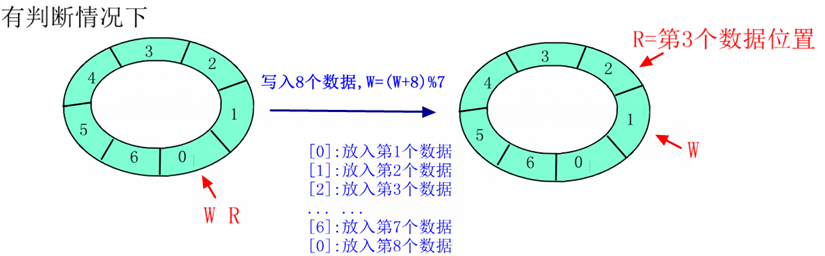
然后我们再多次调用read_buff(),就可以读出my_buff [2]~ my_buff [0]共6个数据出来
总结:
由于read_buff()后,R都会+1,所以每次 cat /proc/kmsg , 都会清空上次的打印信息。
8.环形缓冲区分析完毕后,我们就可以直接来写一个驱动,模仿/proc/kmsg文件来看看
流程如下:
- 1)定义全局数组my_buff[1000]环形缓冲区,R标志,W标志,然后提供写函数,读函数
- 2)自制一个myprintk(),通过传入的数据来放入到my_buff[]环形缓冲区中
- (PS:需要通过EXPORT_SYMBOL(myprintk)声明该myprintk,否则不能被其它驱动程序调用 )
- 3)写入口函数
- ->3.1) 通过create_proc_entry()创建/proc/mykmsg文件
- ->3.2 )并向mykmsg文件里添加file_operations结构体
- 4)写出口函数
- ->4.1) 通过remove_proc_entry()卸载/proc/mykmsg文件
- 5)写file_operations->read()函数
- ->5.1) 仿照/proc/kmsg的read()函数,来读my_buff[]环形缓冲区的数据
具体代码如下所示:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <asm/uaccess.h>
#include <asm/irq.h>
#include <asm/io.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <linux/proc_fs.h> #define my_buff_len 1000 //环形缓冲区长度 static struct proc_dir_entry *my_entry; /* 声明等待队列类型中断 mybuff_wait */
static DECLARE_WAIT_QUEUE_HEAD(mybuff_wait); static char my_buff[my_buff_len];
unsigned long R=; //记录读的位置
unsigned long W=; //记录写的位置 int read_buff(char *p) //p:指向要读出的地址
{
if(R==W)
return ; //读失败
*p=my_buff[R];
R=(R+)%my_buff_len; //R++
return ; //读成功
} void write_buff(char c) //c:等于要写入的内容
{
my_buff [W]=c;
W=(W+)%my_buff_len; //W++
if(W==R)
R=(R+)%my_buff_len; //R++
wake_up_interruptible(&mybuff_wait); //唤醒队列,因为R != W
} /*打印到my_buff[]环形缓冲区中*/
int myprintk(const char *fmt, ...)
{
va_list args;
int i,len;
static char temporary_buff[my_buff_len]; //临时缓冲区
va_start(args, fmt);
len=vsnprintf(temporary_buff, INT_MAX, fmt, args);
va_end(args); /*将临时缓冲区放入环形缓冲区中*/
for(i=;i<len;i++)
{
write_buff(temporary_buff[i]);
}
return len;
} static int mykmsg_open(struct inode *inode, struct file *file)
{
return ;
} static int mykmsg_read(struct file *file, char __user *buf,size_t count, loff_t *ppos)
{
int error = ,i=;
char c; if((file->f_flags&O_NONBLOCK)&&(R==W)) //非阻塞情况下,且没有数据可读
return -EAGAIN;
error = -EINVAL;
if (!buf || !count )
goto out;
error = wait_event_interruptible(mybuff_wait,(W!=R));
if (error)
goto out;
while (!error && (read_buff(&c)) && i < count)
{
error = __put_user(c,buf); //上传用户数据
buf ++;
i++;
} if (!error)
error = i;
out:
return error;
} const struct file_operations mykmsg_ops = {
.read = mykmsg_read,
.open = mykmsg_open,
};
static int mykmsg_init(void)
{
my_entry = create_proc_entry("mykmsg", S_IRUSR, &proc_root);
if (my_entry)
my_entry->proc_fops = &mykmsg_ops;
return ;
}
static void mykmsg_exit(void)
{
remove_proc_entry("mykmsg", &proc_root);
} module_init(mykmsg_init);
module_exit(mykmsg_exit);
EXPORT_SYMBOL(myprintk);
MODULE_LICENSE("GPL");
PS:当其它驱动向使用myprintk()打印函数,还需要在文件中声明,才行:
extern int myprintk(const char *fmt, ...);
且还需要先装载mykmsg驱动,再来装载要使用myprintk()的驱动,否则无法找到myprintk()函数
9.测试运行
如下图所示,挂载了mykmsg驱动,可以看到生成了一个/proc/mykmsg文件
挂载/proc/mykmsg期间,其它驱动使用myprintk()函数,就会将信息打印在/proc/mykmsg文件中,如下图所示:

和cat /proc/kmsg一样,每次cat 都会清上一次的打印数据
10.若我们不想每次清,和dmesg命令一样, 每次都能打印出环形缓冲区的所有信息,该如何改mykmsg驱动?
上次我们分析过了,每次调用read_buff()后,R都会+1。
要想不清空上次的信息打印,还需要定义一个R_ current标志来代替R标志,这样每次cat结束后,R的位置保持不变。
每次cat时,系统除了进入file_operations-> read(),还会进入file_operations-> open(),所以在open()里,使R_ current=R,然后在修改部分代码即可,
10.1我们还是以一个全局数组my_buff[7]为例, 如下图所示:
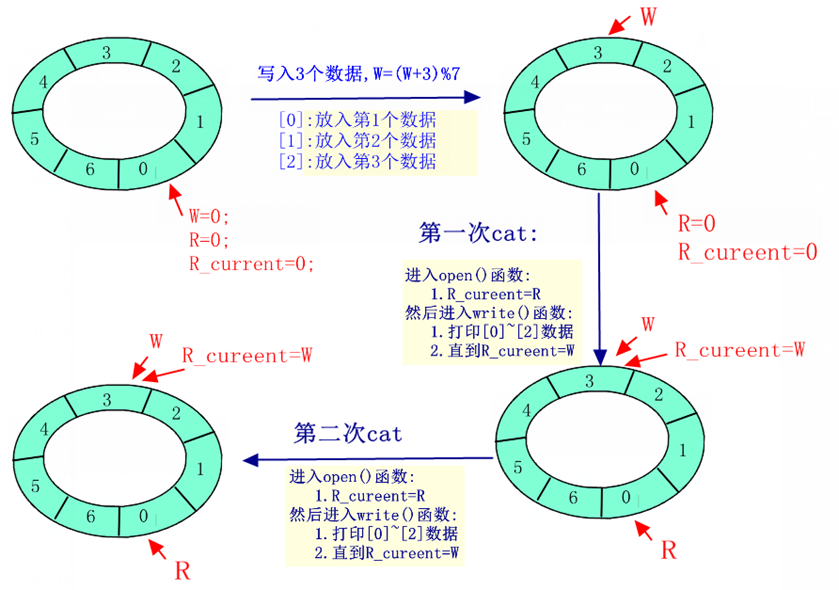
10.2所以,修改的代码如下所示:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/init.h>
#include <linux/delay.h>
#include <asm/uaccess.h>
#include <asm/irq.h>
#include <asm/io.h>
#include <asm/arch/regs-gpio.h>
#include <asm/hardware.h>
#include <linux/proc_fs.h>
#define my_buff_len 1000 //环形缓冲区长度 static struct proc_dir_entry *my_entry; /* 声明等待队列类型中断 mybuff_wait */
static DECLARE_WAIT_QUEUE_HEAD(mybuff_wait); static char my_buff[my_buff_len]; unsigned long R=; //记录读的位置
unsigned long R_current=; //记录cat期间 读的位置
unsigned long W=; //记录写的位置 int read_buff(char *p) //p:指向要读出的地址
{
if(R_current==W)
return ; //读失败
*p=my_buff[R_current];
R_current=(R_current+)%my_buff_len; //R_current++
return ; //读成功
} void write_buff(char c) //c:等于要写入的内容
{
my_buff [W]=c;
W=(W+)%my_buff_len; //W++
if(W==R)
R=(R+)%my_buff_len; //R++
if(W==R_current)
R=(R+)%my_buff_len; //R_current++
wake_up_interruptible(&mybuff_wait); //唤醒队列,因为R !=W
} /*打印到my_buff[]环形缓冲区中*/
int myprintk(const char *fmt, ...)
{
va_list args;
int i,len;
static char temporary_buff[my_buff_len]; //临时缓冲区
va_start(args, fmt);
len=vsnprintf(temporary_buff, INT_MAX, fmt, args);
va_end(args);
/*将临时缓冲区放入环形缓冲区中*/
for(i=;i<len;i++)
{
write_buff(temporary_buff[i]);
}
return len;
} static int mykmsg_open(struct inode *inode, struct file *file)
{
R_current=R;
return ;
} static int mykmsg_read(struct file *file, char __user *buf,size_t count, loff_t *ppos)
{
int error = ,i=;
char c;
if((file->f_flags&O_NONBLOCK)&&(R_current==W)) //非阻塞情况下,且没有数据可读
return -EAGAIN;
error = -EINVAL;
if (!buf || !count )
goto out; error = wait_event_interruptible(mybuff_wait,(W!=R_current));
if (error)
goto out; while (!error && (read_buff(&c)) && i < count)
{
error = __put_user(c,buf); //上传用户数据
buf ++;
i++;
} if (!error)
error = i; out:
return error;
} const struct file_operations mykmsg_ops = {
.read = mykmsg_read,
.open = mykmsg_open, }; static int mykmsg_init(void)
{
my_entry = create_proc_entry("mykmsg", S_IRUSR, &proc_root);
if (my_entry)
my_entry->proc_fops = &mykmsg_ops;
return ;
}
static void mykmsg_exit(void)
{
remove_proc_entry("mykmsg", &proc_root);
} module_init(mykmsg_init);
module_exit(mykmsg_exit);
EXPORT_SYMBOL(myprintk);
MODULE_LICENSE("GPL");
11.测试运行

Linux驱动调试-根据oops定位错误代码行
1.当驱动有误时,比如,访问的内存地址是非法的,便会打印一大串的oops出来
1.1以LED驱动为例
将open()函数里的ioremap()屏蔽掉,直接使用物理地址的GPIOF,如下图所示:
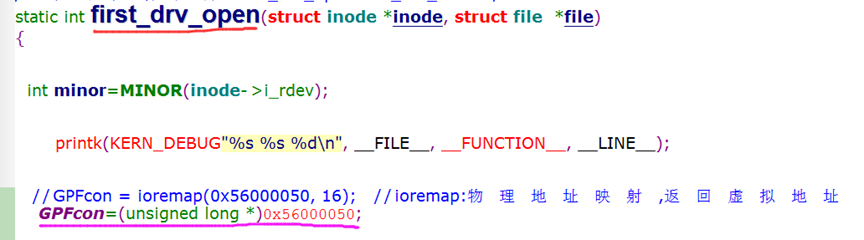
1.2然后编译装载26th_segmentfault并执行测试程序后,内核便打印了oops出来,如下图所示:
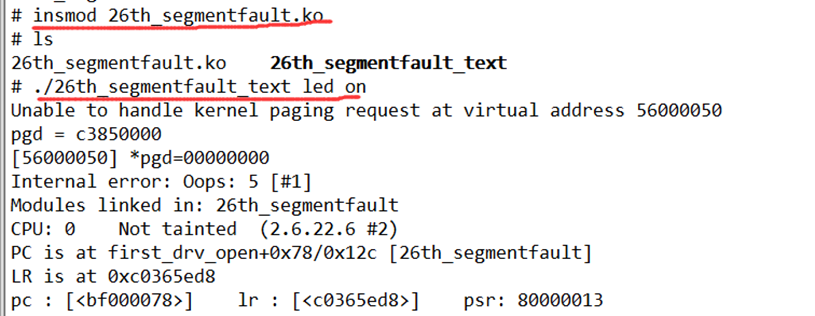
2.接下来,我们便来分析oops:
Unable to handle kernel paging request at virtual address
//无法处理内核页面请求的虚拟地址56000050 pgd = c3850000
[] *pgd= Internal error: Oops: [#]
//内部错误oops Modules linked in: 26th_segmentfault
//表示内部错误发生在26th_segmentfault.ko驱动模块里 CPU: Not tainted (2.6.22.6 #)
PC is at first_drv_open+0x78/0x12c [26th_segmentfault]
//PC值:程序运行成功的最后一次地址,位于first_drv_open()函数里,偏移值0x78,该函数总大小0x12c LR is at 0xc0365ed8 //LR值 /*发生错误时的各个寄存器值*/
pc : [<bf000078>] lr : [<c0365ed8>] psr:
sp : c3fcbe80 ip : c0365ed8 fp : c3fcbe94
r10: r9 : c3fca000 r8 : c04df960
r7 : r6 : r5 : bf000de4 r4 :
r3 : r2 : r1 : r0 : Flags: Nzcv IRQs on FIQs on Mode SVC_32 Segment user
Control: c000717f Table: DAC:
Process 26th_segmentfau (pid: , stack limit = 0xc3fca258)
//发生错误时,进程名称为26th_segmentfault Stack: (0xc3fcbe80 to 0xc3fcc000) //栈信息
be80: c06d7660 c3e880c0 c3fcbebc c3fcbe98 c008d888 bf000010 c04df960
bea0: c3e880c0 c008d73c c0474e20 c3fb9534 c3fcbee4 c3fcbec0 c0089e48 c008d74c
bec0: c04df960 c3fcbf04 ffffff9c c002c044 c380a000 c3fcbefc c3fcbee8
bee0: c0089f64 c0089d58 c3fcbf68 c3fcbf00 c0089fb8 c0089f40
bf00: c3fcbf04 c3fb9534 c0474e20 c3851000
bf20: c3fca000 c04c90a8 c04c90a0 ffffffe8 c380a000 c3fcbf68 c3fcbf48
bf40: c008a16c c009fc70 c04df960 be84ce38 c3fcbf94
bf60: c3fcbf6c c008a2f4 c0089f88 be84ce84 0000877c
bf80: c002c044 4013365c c3fcbfa4 c3fcbf98 c008a3a8 c008a2b0 c3fcbfa8
bfa0: c002bea0 c008a394 be84ce84 be84ce30 be84ce38 be84ce30
bfc0: be84ce84 0000877c 4013365c be84ce58
bfe0: be84ce28 0000266c 400c98e0 be84ce30 Backtrace: //回溯信息
[<bf000000>] (first_drv_open+0x0/0x12c [26th_segmentfault]) from [<c008d888>] (chrdev_open+0x14c/0x164)
r5:c3e880c0 r4:c06d7660
[<c008d73c>] (chrdev_open+0x0/0x164) from [<c0089e48>] (__dentry_open+0x100/0x1e8)
r8:c3fb9534 r7:c0474e20 r6:c008d73c r5:c3e880c0 r4:c04df960
[<c0089d48>] (__dentry_open+0x0/0x1e8) from [<c0089f64>] (nameidata_to_filp+0x34/0x48)
[<c0089f30>] (nameidata_to_filp+0x0/0x48) from [<c0089fb8>] (do_filp_open+0x40/0x48)
r4:
[<c0089f78>] (do_filp_open+0x0/0x48) from [<c008a2f4>] (do_sys_open+0x54/0xe4)
r5:be84ce38 r4:
[<c008a2a0>] (do_sys_open+0x0/0xe4) from [<c008a3a8>] (sys_open+0x24/0x28)
[<c008a384>] (sys_open+0x0/0x28) from [<c002bea0>] (ret_fast_syscall+0x0/0x2c)
Code: bf000094 bf0000b4 bf0000d4 e5952000 (e5923000)
Segmentation fault
2.1上面的回溯信息,表示了函数的整个调用过程
比如上面的回溯信息表示:
- sys_open()->do_sys_open()->do_filp_open()->nameidata_to_filp()->chrdev_open()->first_drv_open();
最终错误出在了first_drv_open();
若内核没有配置回溯信息显示,则就不会打印函数调用过程,可以修改内核的.config文件,添加:

//CONFIG_FRAME_POINTER,表示帧指针,用fp寄存器表示
内核里,就会通过fp寄存器记录函数的运行位置,并存到栈里,然后当出问题时,从栈里调出fp寄存器,查看函数的调用关系,就可以看到回溯信息.
(PS:若不配置,也可以直接通过栈来分析函数调用过程,在下章会分析到:http://www.cnblogs.com/lifexy/p/8011966.html)
2.2而有些内核的环境不同,opps也可能不会打印出上面的:
Modules linked in: 26th_segmentfault
PC is at first_drv_open+0x78/0x12c [26th_segmentfault]
这些相关信息, 只打印PC值,就根本无法知道,到底是驱动模块出的问题,还是内核自带的函数出的问题?
所以oops里的最重要内容还是这一段: pc : [<bf000078>]
2.3那么如何来确定,该PC值地址位于内核的函数,还是我们装载的驱动模块?
答:
可以在内核源码的根目录下通过的“vi System.map”来查看,该文件保存了内核里所有(符号、函数)的虚拟地址映射,比如下图的内核函数root_dev_setup():
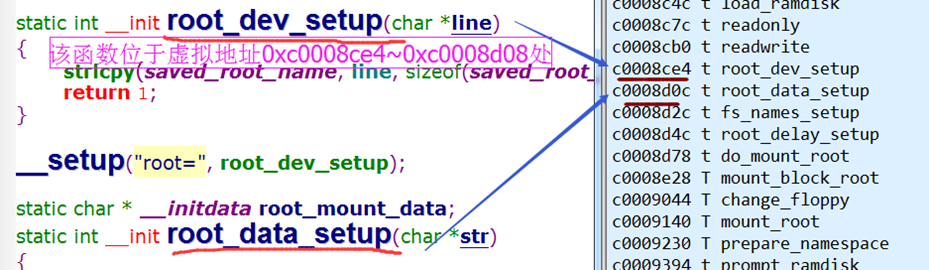
通过vi命令的:0和:$命令行,可以看到内核的虚拟地址是c0004000~c03cebf4
所以,pc值bf000078为的驱动模块的地址值
2.4当有多个驱动装载时,又如何区分PC值是哪个驱动的函数的地址值?
答:通过/proc/kallsyms来查看:
#cat /proc/kallsyms //(kernel all symbols)查看所有的内核标号(包括内核函数,装载的驱动函数,变量符号等)的地址值
或者:
#cat /proc/kallsyms> /kallsyms.txt //将地址值放入kallsyms.txt中
如下图所示,在kallsyms.txt里,找到pc值bf000078位于26th_segmentfault驱动里first_drv_open()函数下的bf000000+0x78中
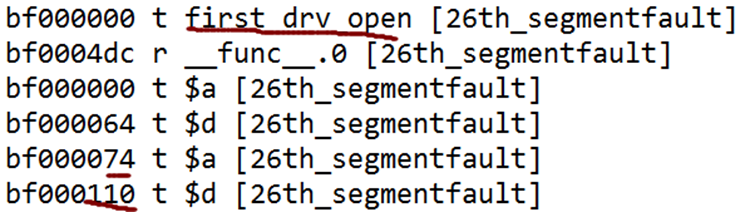
2.5然后将驱动生成反汇编:
arm-linux-objdump -D 26th_segmentfault.ko >26th_segmentfault.dis //反汇编
2.6打开反汇编:
如下图所示,左边是kallsyms.txt,右边是26th_segmentfault.dis反汇编

显然pc值bf000078,就位于反汇编的78地址处:
Disassembly of section .text: //.text段起始地址为0x00
<first_drv_open>: : e59fc0e8 ldr ip, [pc, #]; <.text+0x128> //ip=.text段+0x128里的内容
... ... : e585c000 str ip, [r5] //r5=.text段+0x128里的内容
... ... : e5952000 ldr r2, [r5] //r2=.text段+0x128里的内容
: e5923000 ldr r3, [r2] // r3=.text段+0x128里的内容
7c: e3c33c3f bic r3, r3, # ;0x3f00 //清除0x56000050的bit8~13
... ... : undefined //.text段+0x128里的内容=0x56000050
从上面看到,78地址处,主要是将0x56000050(r2)地址里的内容放入r3中.
而0x56000050是个物理地址,在linux眼中便是个非法地址,所以出错
并找到出错地方位于first_drv_open ()函数下:
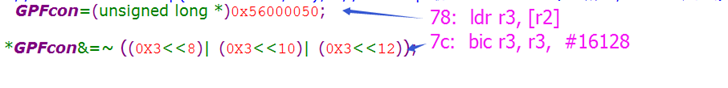
3.若发生错误的驱动位于内核的地址值时
3.1还是以26th_segmentfault.c为例,首先加入内核:
#cp 26th_segmentfault.c /linux-2.6.22.6/drivers/char/ //将有问题的驱动复制到字符驱动目录下
#vi Makefile
添加:
obj-y += 26th_segmentfault.o //y:将该驱动放入内核中
3.2然后make uImage装载新内核后,再运行测试程序,便会打印出opps信息
3.3在内核源码的根目录下通过:
# arm-none-linux-gnueabi-objdump -D vmlinux > vmlinux.dis
将整个内核反汇编, vmlinux:未压缩的内核
3.4 vi vmlinux.dis,然后通过oops信息的PC值直接来查找地址即可
接下来下章便通过栈信息来分析函数调用过程:http://www.cnblogs.com/lifexy/p/8011966.html
Linux驱动调试-根据oops的栈信息,确定函数调用过程
上章链接入口: http://www.cnblogs.com/lifexy/p/8006748.html
在上章里,我们分析了oops的PC值在哪个函数出错的
本章便通过栈信息来分析函数调用过程
1.上章的oops栈信息如下图所示:
- 9fe0: 代表最初的栈顶SP寄存器位置
- 9e80:代表函数出错的SP寄存器位置
2.我们先来分析上图的栈信息,又是怎样的过程呢?
2.1内核主要是通过STMDB和LDMIA汇编命令来入栈和出栈
(STMDB和LDMIA汇编命令参考: http://www.cnblogs.com/lifexy/p/7363208.html)
内核每进入一个函数就会通过STMDB,将上个函数的内容值存入栈顶sp,然后栈顶sp-4.
当内核的某个函数出问题时,内核便通过LDMIA,将栈顶sp打印出来,然后栈顶sp+4,直到到达最初的栈顶
2.2我们以下图的3个函数为例:
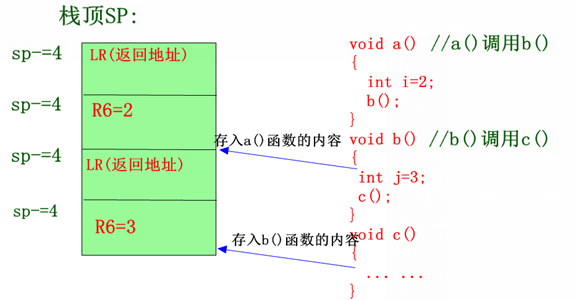
若c()函数出问题后,内核就会打印b()函数的内容(0x03,LR), 打印a()函数的内容(0x02,LR),直到sp到达栈顶为止
其中lr值,便代表各个函数的调用关系
3.接下来我们便以上章的oops里的栈信息来分析
在上章里,我们找到PC值bf000078在26th_segmentfault驱动模块first_drv_open()函数下出错。
3.1先来看first_drv_open()函数,找到STMDB入栈的lr值,来确定被哪个函数调用的
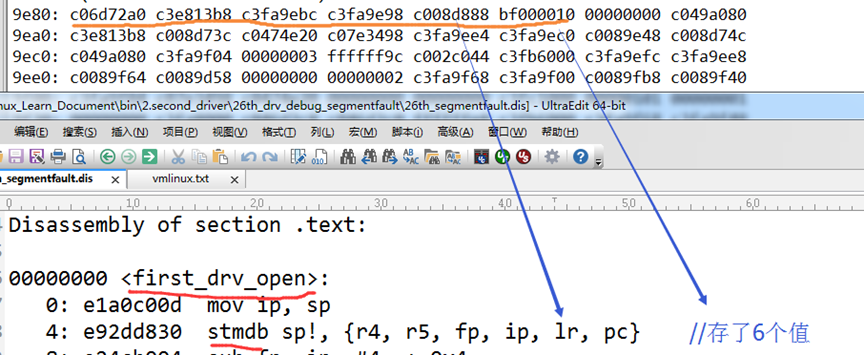
如上图所示,first_drv_open()函数里,通过stmdb sp!, {r4, r5, fp, ip, lr, pc} 存入了6个值,
所以, 返回到上个函数的值lr =c008d888
在上章,我们便分析到:
内核的虚拟地址是c0004000~c03cebf4,所以c008d888位于内核的某个函数里
3.2 然后将内核进行反汇编
在内核源码的根目录下:
# arm-none-linux-gnueabi-objdump -D vmlinux > vmlinux.txt //-D:反汇编所有段 vmlinux:未压缩的内核
3.3 打开vmlinux.txt
如下图所示,搜索c008d888:

往上翻,找到c008d888位于函数chrdev_open()下:
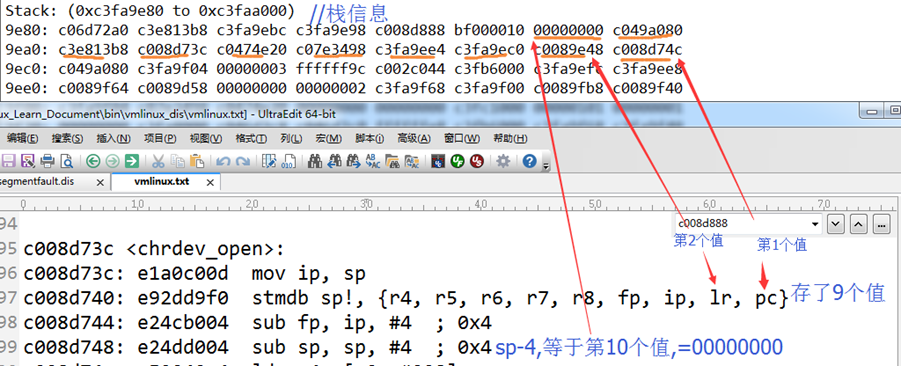
如上图所示, chrdev_open()函数存了10个值,所以,返回到上个函数的值lr= c0089e48
3.4 继续搜索c0089e48:

往上翻,找到c0089e48位于函数__dentry_open ()下:
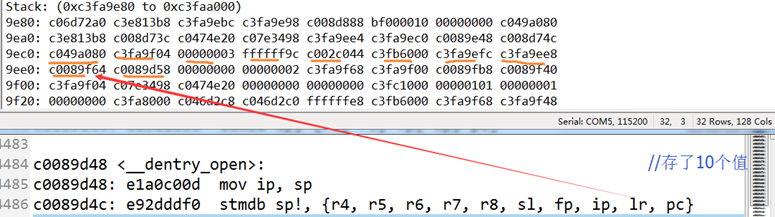
如上图所示, __dentry_open()函数存了10个值,所以,第二个值lr= c0089f64
3.5 继续搜索c0089f64:
往上翻,找到c0089f64位于函数nameidata_to_filp()下:
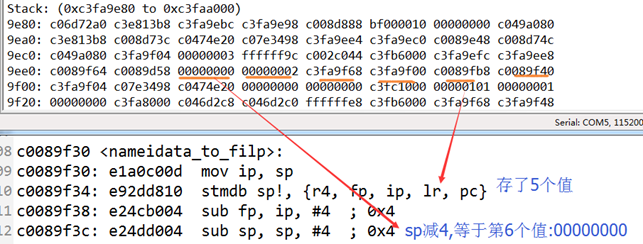
如上图所示, nameidata_to_filp函数存了6个值,所以,第二个值lr= c0089fb8
... ...(此处省略n字)
4.最终分析出,栈信息的调用过程如下:
- ret_fast_syscall()->
- sys_open()->
- do_sys_open()->
- do_filp_open()->
- nameidata_to_filp()->
- chrdev_open()->
- first_drv_open();
Linux驱动调试-根据系统时钟定位出错位置
当内核或驱动出现僵死bug,导致系统无法正常运行,怎么找到是哪个函数的位置导致的?
答,通过内核的系统时钟,因为它是由定时器中断产生的,每隔一定时间便会触发一次,所以当CPU一直在某个进程中时,我们便在中断函数中打印该进程的信息
1.先来回忆下
在之前的第5章内核中断运行过程:http://www.cnblogs.com/lifexy/p/7506504.html分析过,当内核中断产生时,会做以下几步:
- 1)pc-4(计算返回地址值),然后将各个寄存器值存到sp栈里
- 2)获取中断号,获取sp地址,然后调用asm_do_IRQ()
1.1其中asm_do_IRQ函数原型如下所示:
asmlinkage void __exception asm_do_IRQ(unsigned int irq, struct pt_regs *regs);
//irq:中断号 *regs:发生中断前的各个寄存器基地址(=sp基地址)
1.2其中pt_regs结构体成员如下图所示,用来保存各个寄存器内容的数组:

2.所以本节目的,修改asm_do_IRQ()函数,添加如下内容:
- 1)判断irq若等于系统时钟的irq,然后cnt++
- 2)若在10s后,获取的进程没有改变,便打印:进程名字、PID、(regs-> ARM_pc)-4
(PS: 为什么要打印PC-4? 因为此时的PC是返回地址,而PC-4才是CPU运行的地址)
3.首先来找到系统时钟的中断号irq
输入#cat /proc/interrupt,如下图所示:

其中中断号来自 linux-2.6.22.6\include\asm-arm\arch-s3c2410\Irqs.h
而S3C2410 Timer Tick,就是我们的系统时钟计数值,在内核中就是jiffies这个全局变量,每隔一段时间+1。
所以S3C2410 Timer Tick的中断号为30
4.接下来便来修改asm_do_IRQ()函数
在asm_do_IRQ()中,添加以下带红色的字
asmlinkage void __exception asm_do_IRQ(unsigned int irq, struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
struct irq_desc *desc = irq_desc + irq;
#ifdef 1
static pid_t pre_pid; //进程号
static int cnt=0; //计数值
if(irq==30) //判断irq中断号,是否等于系统时钟
{
if(pre_pid==current->pid)
{
cnt++;
}
else
{
cnt=0;
pre_pid=current->pid;
}
if(cnt==10*HZ) //超时10s
{
cnt=0;
printk("s3c2410_timer_interrupt : pid = %d, task_name = %s\n",current->pid,current->comm);
printk("pc = %08x\n",regs->ARM_pc);
}
}
#endif
... ...
}
1)其中current是一个宏,为task_struct结构体,表示当前运行的进程信息,该宏通过get_current()来获取进程信息,位于include\asm-arm\current.h中
current->pid:当前进程的PID号
current->com:表示当前进程的name
2) HZ也是一个宏,代表每S的频率,比如每隔10ms加1,那么HZ就等于100
5.测试运行
接下来,我们便安装一个带有while(1)死循环的驱动,然后通过测试程序,内核便会一直在while(1)死循环,进入僵死状态。
由于修改了asm_do_IRQ()函数后,所以会打印下图信息:

5.1 然后便可以通过pc值=bf0000C,就能查找在哪个函数出错
(参考:http://www.cnblogs.com/lifexy/p/8006748.html)
Linux应用调试-strace命令
1.strace简介
strace常用来跟踪进程执行时的系统调用和所接收的信号。通过strace可以知道应用程序打开了哪些文件,以及读写了什么内容,包括消耗的时间以及返回值等
2.安装strace命令
首先需要以下两个文件:
- strace-4.5.15.tar.bz2
- strace-fix-arm-bad-syscall.patch
步骤如下:
#tar -xjf strace-4.5..tar.bz2 #cd strace-4.5./ #patch -p1 <../strace-fix-arm-bad-syscall.patch
//“p1”值去掉补丁的第一个路径 “<”指补丁文件位置,“../” 指返回上个目录 #./configure --host=arm-linux CC=arm-linux-gcc //配置configure #make //生成strace命令文件
然后将strace命令文件,放入我们开发板的根目录/bin中,便能使用了
#cp strace /nfs_root/bin/ //nfs_root:开发板的nfs系统根目录
3.strace命令使用
常用参数如下所示:
- -o 指定跟踪信息的输出文件
- -t 记录跟踪信息的时间,以S为单位
- -tt 记录跟踪信息的时间,以uS为单位
4.实例
通过strace来测试led_text应用程序
#insmod led.ko //装载led驱动
# strace -o log.txt ./led_text led1 on
//测试led_text应用程序,打开led1,并将跟踪信息输出到log.txt中
其中log.txt的内容如下所示:
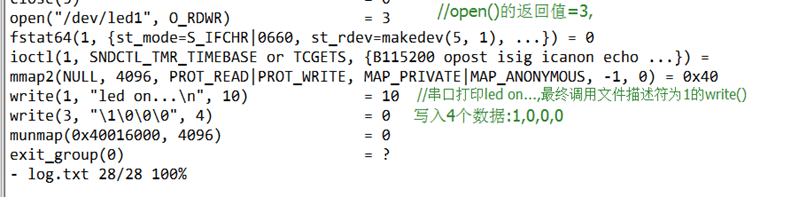
Linux应用调试-使用gdb和gdbserver
1.gdb和gdbserver调试原理
通过linux虚拟机里的gdb,来向开发板里的gdbserver发送命令,比如设置断点,运行setp等,然后开发板上的gdbserver收到命令后,便会执行应用程序做相应的动作,来实现调试的功能
和之前学的裸板GDB调试一样,只不过之前学的是在win下的,本次是在linux里的gdb
1.1同样,它们都会需要一个带调试信息的编译文件.
通过Makefile里的arm-linux-gcc -g 来的, -g:表示编译文件里包含gdb调试信息
1.2为什么需要调试信息的编译文件?
比如读开发板的应用程序里的变量a:
首先gdb通过应用程序的带调试信息的编译文件,来找出变量a存的地址位置
然后将地址发送给开发板里的gdbserver,来读出a地址的值
2.安装gdb和gdbserver
首先进入官网下载gdb-7.4: http://ftp.gnu.org/gnu/gdb/
2.1在虚拟机上安装GDB:
# tar xjf gdb-7.4.tar.bz2 //解压 # cd gdb-7.4/ //进入gdb-7.4目录 #./configure --target=arm-linux
//GDB需要在pc本机里运行,并调试开发板里的应用程序,所以--target设为arm-linux #make //编译 #mkdir tmp #make install prefix=$PWD/tmp //安装到./tmp目录下 sudo cp tmp/bin/arm-linux-gdb /bin/ //复制到/bin目录下 /bin/arm-linux-gdb -v //-v: 确定一下gdb的版本VID,是否是7.4
2.2 在开发板上安装GDBServer:
cd gdb/gdbserver/ //在gdb-7.4目录下输入 ./configure --target=arm-linux --host=arm-linux //设GDBServer的工作环境 make //编译
出现以下错误:

指在linux-arm-low.c里,没有找到PTRACE_GETSIGINFO 定义
2.3 解决:
1)
#echo $PATH //来查看PATH环境变量
找到编译器gcc位于/work/tools/gcc-3.4.5-glibc-2.3.6/bin
2)
#cd /work/tools/gcc-3.4.-glibc-2.3./
# grep "PTRACE_GETSIGINFO" * -nR
在gcc根目录下,搜索到在linux/ptrace.h中定义:

3)
#vi linux-arm-low.c
添加: #define PTRACE_GETSIGINFO 0x4202
4)最后重新make,生成gdbserver命令文件
然后将gdbserver命令文件,放入我们开发板的根目录/bin中,便能使用了
cp gdbserver /nfs_root/bin/ //nfs_root:开发板的nfs系统根目录
3.测试程序如下(test_debug.c)
#include <stdio.h> void C(int *p)
{
*p = 0x12;
} void B(int *p)
{
C(p);
} void A(int *p)
{
B(p);
} void A2(int *p)
{
C(p);
} int main(int argc, char **argv)
{
int a;
int *p = NULL;
A2(&a); // A2 > C
printf("a = 0x%x\n", a);
A(p); // A > B > C
return ;
}
其中A2(&a)会调用A2()->C(),然后将a赋值为0x12.
A(p)会调用A()->B()->C(),由于p是个空指针,这里将会出错.
接下来,我们便以这个应用程序为例.
4.编译
#arm-linux-gcc -g -o test_debug test_debug.c //-g:附带调试信息
5.调试test_debug.c
在开发板上:
首先,需要让gdbserver建立本地服务器,以及要测试的哪个文件:
#gdbserver 192.168.2.107: ./test_debug
//192.168.2.107:本地IP地址
//2345:端口号,用来让gdb来连接用的
//./test_debug:要测试的哪个文件
在虚拟机上:
#/bin/arm-linux-gdb ./test_debug // 启动gdb,指定调试文件为test_debug #target remote 192.168.2.107: //与gdbserver建立连接
5.1连接成功,便使用gdb命令来调试
常用命令如下所示(参考http://blog.sciencenet.cn/blog-619295-813770.html):
l
列出所有源代码
break [file]:[row]
打断点,比如:
break test_debug.c: //在test_debug.c文件的第21行处打断点
info br
查看断点
info file
列出当前的文件,共享库。
delete <num>
删除第几个断点,如下图所示:

c
启动程序运行
step
单步执行
next
单步执行,和step不同的是,比如:当前行里有函数调用时,next直接执行下一句,step会进入函数
print a
打印a变量的值
quit
退出gdb
6.也可以通过gdb+coredump来调试test_debug.c
当程序运行出错时,便会生成core文件,并将程序里的运行状况存到core中,也就是coredump,供给gdb来调试
6.1首先,通过ulimit来查看coredump的资源大小
ulimit命令(user limit),主要用来限制用户的各个进程资源.
在开发板里,输入

如上图所示,可以看到coredump的资源大小为0,也就是说,当程序运行出错时,不会生成core文件
6.2设置core文件
设置core文件的资源大小为无限制,输入:
ulimit -c unlimited
//-c:对应coredump
6.3生成core文件
执行:
#./test_debug
出现段错误,并生成core文件,如下图所示:

6.4 进入虚拟机
将core拷贝过来,然后执行:
#/bin/arm-linux-gdb ./test_debug ./core
然后输入bt,便可查看调用关系:

Linux应用调试-修改内核来打印用户态的oops
1.在之前第36章里,我们学习了通过驱动的oops定位错误代码行
第36章的oops代码如下所示:
Unable to handle kernel paging request at virtual address
//无法处理内核页面请求的虚拟地址56000050
pgd = c3850000
[] *pgd=
Internal error: Oops: [#]
//内部错误oops
Modules linked in: 26th_segmentfault
//表示内部错误发生在26th_segmentfault.ko驱动模块里
CPU: Not tainted (2.6.22.6 #)
PC is at first_drv_open+0x78/0x12c [26th_segmentfault]
//PC值:程序运行成功的最后一次地址,位于first_drv_open()函数里,偏移值0x78,该函数总大小0x12c
LR is at 0xc0365ed8 //LR值 /*发生错误时的各个寄存器值*/
pc : [<bf000078>] lr : [<c0365ed8>] psr:
sp : c3fcbe80 ip : c0365ed8 fp : c3fcbe94
r10: r9 : c3fca000 r8 : c04df960
r7 : r6 : r5 : bf000de4 r4 :
r3 : r2 : r1 : r0 : Flags: Nzcv IRQs on FIQs on Mode SVC_32 Segment user
Control: c000717f Table: DAC:
Process 26th_segmentfau (pid: , stack limit = 0xc3fca258)
//发生错误时,进程名称为26th_segmentfault Stack: (0xc3fcbe80 to 0xc3fcc000) //栈信息,从栈底0xc3fcbe80到栈顶0xc3fcc000
be80: c06d7660 c3e880c0 c3fcbebc c3fcbe98 c008d888 bf000010 c04df960
bea0: c3e880c0 c008d73c c0474e20 c3fb9534 c3fcbee4 c3fcbec0 c0089e48 c008d74c
bec0: c04df960 c3fcbf04 ffffff9c c002c044 c380a000 c3fcbefc c3fcbee8
bee0: c0089f64 c0089d58 c3fcbf68 c3fcbf00 c0089fb8 c0089f40
bf00: c3fcbf04 c3fb9534 c0474e20 c3851000
bf20: c3fca000 c04c90a8 c04c90a0 ffffffe8 c380a000 c3fcbf68 c3fcbf48
bf40: c008a16c c009fc70 c04df960 be84ce38 c3fcbf94
bf60: c3fcbf6c c008a2f4 c0089f88 be84ce84 0000877c
bf80: c002c044 4013365c c3fcbfa4 c3fcbf98 c008a3a8 c008a2b0 c3fcbfa8
bfa0: c002bea0 c008a394 be84ce84 be84ce30 be84ce38 be84ce30
bfc0: be84ce84 0000877c 4013365c be84ce58
bfe0: be84ce28 0000266c 400c98e0 be84ce30 Backtrace: //回溯信息
[<bf000000>] (first_drv_open+0x0/0x12c [26th_segmentfault]) from [<c008d888>] (chrdev_open+0x14c/0x164)
r5:c3e880c0 r4:c06d7660
[<c008d73c>] (chrdev_open+0x0/0x164) from [<c0089e48>] (__dentry_open+0x100/0x1e8)
r8:c3fb9534 r7:c0474e20 r6:c008d73c r5:c3e880c0 r4:c04df960
[<c0089d48>] (__dentry_open+0x0/0x1e8) from [<c0089f64>] (nameidata_to_filp+0x34/0x48)
[<c0089f30>] (nameidata_to_filp+0x0/0x48) from [<c0089fb8>] (do_filp_open+0x40/0x48)
r4:
[<c0089f78>] (do_filp_open+0x0/0x48) from [<c008a2f4>] (do_sys_open+0x54/0xe4)
r5:be84ce38 r4:
[<c008a2a0>] (do_sys_open+0x0/0xe4) from [<c008a3a8>] (sys_open+0x24/0x28)
[<c008a384>] (sys_open+0x0/0x28) from [<c002bea0>] (ret_fast_syscall+0x0/0x2c)
Code: bf000094 bf0000b4 bf0000d4 e5952000 (e5923000) Segmentation fault
1.1那为什么在上一章,我们用错误的应用程序,却没有打印oops,如下图所示:
接下来,我们便来配置内核,从而打印应用程序的oops
2.首先来搜索oops里的:Unable to handle kernel打印语句,看在哪个函数打印的
如下图所示,找到位于__do_kernel_fault()函数中:
3.继续找,发现__do_kernel_fault()被do_bad_area()调用

do_bad_area()函数,从字面上分析,表示代码执行到错误段位置
其中user_mode(regs)函数,通过判断CPSR寄存器若是用户模式则返回0,否则返回正数.
所以我们上一章的错误的应用程序便会调用__do_user_fault()函数
4.__do_user_fault()函数如下所示:
从上图来看,要想打印应用程序的错误信息,还需要:
3.1配置内核,设置宏CONFIG_DEBUG_USER(只要宏是以"CONFIG_"开头,都是与配置相关)
1)在make menuconfig里搜索DEBUG_USER,如下图所示:
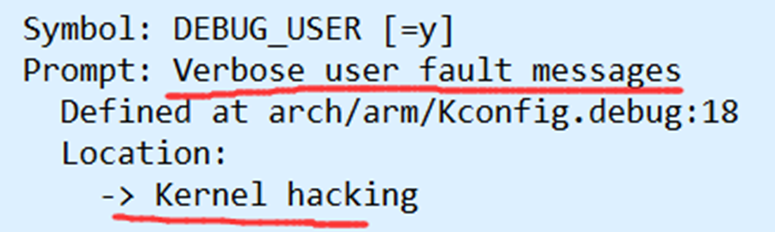
所以将Kernel hacking-> Verbose user fault messages 置为Y,并重新烧内核
3.2使if (user_debug & UDBG_SEGV)为真
1)其中user_debug定义如下所示:
显然当uboot传递进来的命令行字符里含有"user_debug="时,便会调用user_debug_setup()->get_option(),最终会将"user_debug="后面带的字符串提取给user_debug变量.
比如:当命令行字符里含有"user_debug=0xff"时,则user_debug变量等于0xff
2)其中UDBG_SEGV定义如下所示:
#define UDBG_UNDEFINED (1 << 0) //用户态的代码出现未定义指令(UNDEFINED) #define UDBG_SYSCALL (1 << 1) //用户态系统调用已过时(SYSCALL) #define UDBG_BADABORT (1 << 2) //用户态数据错误已中止(BADABORT) #define UDBG_SEGV (1 << 3) //用户态的代码出现段错误(SEGV) #define UDBG_BUS (1 << 4) //用户态访问忙(BUS)
从上面的定义分析得出,我们只需要将user_debug设为0xff,上面的所有条件就都成立.
比如:当用户态的代码出现未定义指令时,由于user_debug最低位=1,所以打印出oops.
所以,进入uboot,在uboot命令行里添加: "user_debug=0xff"
4. 启动内核,试验
如下图所示,执行错误的应用程序,只打印了各个寄存器值,以及函数调用关系,而没有栈信息:

5.接下来,继续修改内核,使应用程序的oops也打印栈信息出来
在驱动的oops里有"Stack: "这个字段,搜索"Stack: "看看,位于哪个函数
5.1如下图所示, 找到位于__die()函数中:
这个__die()会被die()调用,die()又会被__do_kernel_fault()调用,而我们应用程序调用的__do_user_fault()里没有die()函数,所以没有打印出Stack栈信息。
上图里dump_mem():
dump_mem("Stack: ", regs->ARM_sp,THREAD_SIZE + (unsigned long)task_stack_page(tsk)); //打印stack栈信息
主要是通过sp寄存器里存的栈地址,每打印一个栈地址里的32位数据, 栈地址便加4(一个地址存8位,所以加4)。
接下来我们便通过这个原理,来修改应用程序调用的__do_user_fault()
5.2 在__do_user_fault(),添加以下带红色的字:
static void __do_user_fault(struct task_struct *tsk, unsigned long addr,unsigned int fsr, unsignedint sig, int code,struct pt_regs *regs)
{
struct siginfo si;
unsigned long val ;
int i=0;
#ifdef CONFIG_DEBUG_USER
if (user_debug & UDBG_SEGV) {
printk(KERN_DEBUG "%s: unhandled page fault (%d) at 0x%08lx, code 0x%03x\n",
tsk->comm, sig, addr, fsr);
show_pte(tsk->mm, addr);
show_regs(regs);
printk("Stack: \n");
while(i<1024)
{
/* copy_from_user()只是用来检测该地址是否有效,如有效,便获取地址数据,否则break */
if(copy_from_user(&val, (const void __user *)(regs->ARM_sp+i*4), 4))
break;
printk("%08x ",val); //打印数据
i++;
if(i%8==0)
printk("\n");
}
printk("\n END of Stack\n");
}
#endif
tsk->thread.address = addr;
tsk->thread.error_code = fsr;
tsk->thread.trap_no = 14;
si.si_signo = sig;
si.si_errno = 0;
si.si_code = code;
si.si_addr = (void __user *)addr;
force_sig_info(sig, &si, tsk);
}
6.重新烧写内核,试验
如下图所示:
接下来,便来分析PC值,Stack栈,到底如何调用的
7.首先来分析PC值,确定错误的代码
1)生成反汇编:
arm-linux-objdump -D test_debug > test_debug.dis
2)搜索PC值84ac,如下图所示:

从上面看出,主要是将0x12(r3)放入地址0x00(r2)中
而0x00是个非法地址,所以出错
8.分析Stack栈信息,确定函数调用过程
参考: 37.Linux驱动调试-根据oops的栈信息,确定函数调用过程
8.1分析过程中,遇到main()函数的返回地址为:LR=40034f14
内核的虚拟地址是c0004000~c03cebf4,而反汇编里也没有该地址,所以这是个动态库的地址.
需要用到静态链接方法,接下来重新编译,反汇编,运行:
#arm-linux-gcc -o -static test_debug test_debug.c
//-static 静态链接,生成的文件会非常大, 好处在于不需要动态链接库,也可以运行
#arm-linux-objdump -D test_debug > test_debug.dis
8.2最终, 找到main()函数的返回地址在__lobc_start_main()里
所以函数出错时的调用过程:
__lobc_start_main()->
main()->
A()->
B()->
C() //将0x12(r3)放入地址0x00(r2)中
Linux应用调试-初步制作系统调用(用户态->内核态)
1首先来讲讲应用程序如何实现系统调用(用户态->内核态)?
我们以应用程序的write()函数为例:
1)首先用户态的write()函数会进入glibc库,里面会将write()转换为swi(Software Interrupt)指令,从而产生软件中断,swi指令如下所示:
swi #val //val: bit[23:0]立即数,该val用来判断用户函数需要调用哪个内核函数
2)然后CPU会跳到异常向量入口vector_swi处,根据swi指令后面的val值,在某个数组表里找到对应的sys_write()函数
代码如下所示(位于arch\arm\kernel\entry-common.S):
ENTRY(vector_swi)
/*保护用户态的现场*/
sub sp, sp, #S_FRAME_SIZE
stmia sp, {r0 - r12} @ Calling r0 - r12
add r8, sp, #S_PC
stmdb r8, {sp, lr}^ @ Calling sp, lr
mrs r8, spsr @ called from non-FIQ mode, so ok.
str lr, [sp, #S_PC] @ Save calling PC
str r8, [sp, #S_PSR] @ Save CPSR
str r0, [sp, #S_OLD_R0] @ Save OLD_R0
zero_fp
... ... ldr scno, [lr, #-] @ get SWI instruction //获取SWI值
A710( and ip, scno, #0x0f000000 @ check for SWI)
A710( teq ip, #0x0f000000) //校验SWI的bit[27:24]是否为0xf
A710( bne .Larm710bug)
... ... enable_irq //调用enable_irq()函数
get_thread_info tsk
adr tbl, sys_call_table @ load syscall table pointer // tbl等于数组表基地址
ldr ip, [tsk, #TI_FLAGS] @ check for syscall tracing
... ... bic scno, scno, #0xff000000 @ mask off SWI op-code //只保留SWI的bit[23:0],也就是val值
eor scno, scno, #__NR_SYSCALL_BASE @ check OS number
//对于2440而讲,__NR_SYSCALL_BASE基地址等于0x900000,也就是说val值为0x900000时,异或后,scno则等于0,表示数组表的基地址(第一个函数位置)
... ... ldrcc pc, [tbl, scno, lsl #] @ call sys_* routine //pc=(tbl+scno)<<2,实现调用sys_write()
//tbl:数组表基地址, scno:要调用的sys_write()的索引值 lsl #2:左移2位,一个函数指针占据4个字节
从上面代码可以看出,2440的val基值为0x900000,也就是说要调用数组表的第一个函数时,则使用:
swi #0x900000
2 接下来,我们便来自制一个系统调用
- 1)在内核中,仿照一个sys_hello函数,然后放入数组表,供swi调用
- 2)写应用程序,直接通过swi指令,来调用sys_hello函数
3 仿照sys_hello()
3.1先来查找数组表,以sys_write为例,搜索找到位于arch/arm/kernel/calls.S,如下图所示:
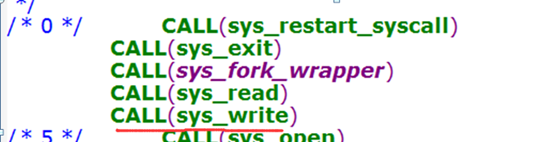
其中CALL定义如下所示:
.equ NR_syscalls, //将NR_syscalls=0 #define CALL(x) .equ NR_syscalls,NR_syscalls+1 //将CALL(x) 定义为:NR_syscalls=NR_syscalls+1 ,也就是每有一个CALL(),则该CALL值则+1 #include "calls.S" //将calls.S的内容包进来,CALL(x)上面已经有了定义,就会将calls.S里面的所有CALL(sys_xx)排列起来 #undef CALL //撤销CALL定义 #define CALL(x) .long x //然后再将排列起来的sys_xx以long(4字节)对齐,一个函数指针占据4字节
3.2 所以我们在call.S文件的CALL()列表的最后添加一段, 如下图所示, sys_hello()的val值为:

3.3 fs\read_write.c文件里写一个sys_hello()函数
asmlinkage void sys_hello(const char __user * buf, size_t count) //打印count长数据
{
char ker_buf[]; if(buf)
{ copy_from_user(ker_buf, buf, (count<)? count : );
ker_buf[]='\0';
printk("sys_hello:%s\n",ker_buf);
}
}
3.4 include\linux\syscalls.h文件里声明sys_hello()
asmlinkage void sys_hello(const char __user * buf, size_t count);
4.写应用程序
#include <errno.h>
#include <unistd.h>
#define __NR_SYSCALL_BASE 0x900000 void hello(char *buf, int count)
{
/* swi */
asm ("mov r0, %0\n" /* save the argment in r0 */ //%0等于buf
"mov r1, %1\n" /* save the argment in r0 */ //%1等于count
"swi %2\n" /* do the system call */ //%2等于0x900352
: //输出部
: "r"(buf), "r"(count), "i" (__NR_SYSCALL_BASE + ) //输入部
: "r0", "r1"); //损坏部,指原有的数据会被破坏
}
int main(int argc, char **argv)
{
printf("in app, call hello\n");
hello("www.100ask.net", );//这个函数会调用内核的sys_hello()
return ;
}
4.1 其中asm ()是一个内嵌汇编(参考linux内核源代码情景分析1.5.2节)
格式如下所示:
- asm( 指令部 : 输出部 : 输入部 : 损坏部 );
指令部
在指令部中,若出现%0、%1、%2等,则表示指令部后面的第几个变量.
比如上面代码的"mov r0, %0\n".
其中%0便会对应buf值,而"r"是一个约束条件字母,r表示任意一个寄存器,在预处理时,便会自动分配一个寄存器,将buf值放入该寄存器里,然后运行mov r0 (buf对应的寄存器)
输出部
每个输出部的约束条件字母都要加上"=",比如:
int num=,val;
asm("mov %0,%1\n"
:"=r"(val) //指定val是一个输出部,执行mov后,val便等于5
:"i"(num) // "i"约束条件字母,表示num是一个立即数
: );
输入部
和输出部唯一不同的就是,在约束条件字母前不能加上"="
常用的约束条件字母,如下图所示:

损坏部
和输入输出类似,一般用来处理操作的中间过程,因为这些原有的内容都会被损坏,比如上面的hello()里的"r0", "r1",只是用来当做参数,传递给内核的sys_hello()
5.重新烧写内核,试验应用程序
如上图所示,一个简单的系统调用便OK了
调用成功后,就可以来修改sys_hello(),来打印应用程序的各个寄存器值,打断点,来实现调试应用程序,需要用到:
task_pt_regs(current); //获取当前应用程序的各个寄存器内容,会返回一个pt_regs结构体
procfs是比较老的一种用户态与内核态的数据交换方式,内核的很多数据都是通过这种方式出口给用户的,内核的很多参数也是通过这种方式来让用户方便设置的。除了sysctl出口到/proc下的参数,procfs提供的大部分内核参数是只读的。实际上,很多应用严重地依赖于procfs,因此它几乎是必不可少的组件。本节将讲解如何使用procfs。
Procfs提供了如下API:
该函数用于创建一个正常的proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参数 parent指定建立的proc条目所在的目录。如果要在/proc下建立proc条目,parent应当为NULL。否则它应当为proc_mkdir 返回的struct proc_dir_entry结构的指针。
该函数用于删除上面函数创建的proc条目,参数name给出要删除的proc条目的名称,参数parent指定建立的proc条目所在的目录。
该函数用于创建一个proc目录,参数name指定要创建的proc目录的名称,参数parent为该proc目录所在的目录。
该函数用于建立一个proc条目的符号链接,参数name给出要建立的符号链接proc条目的名称,参数parent指定符号连接所在的目录,参数dest指定链接到的proc条目名称。
read_proc_t *read_proc, void* data);
该函数用于建立一个规则的只读proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参 数base指定建立的proc条目所在的目录,参数read_proc给出读去该proc条目的操作函数,参数data为该proc条目的专用数据,它将 保存在该proc条目对应的struct file结构的private_data字段中。
get_info_t *get_info);
该函数用于创建一个info型的proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限, 参数base指定建立的proc条目所在的目录,参数get_info指定该proc条目的get_info操作函数。实际上get_info等同于 read_proc,如果proc条目没有定义个read_proc,对该proc条目的read操作将使用get_info取代,因此它在功能上非常类似于函数create_proc_read_entry。
该函数用于在/proc/net目录下创建一个proc条目,参数name给出要建立的proc条目的名称,参数mode给出了建立的该proc条目的访问权限,参数get_info指定该proc条目的get_info操作函数。
该函数也用于在/proc/net下创建proc条目,但是它也同时指定了对该proc条目的文件操作函数。
该函数用于删除前面两个函数在/proc/net目录下创建的proc条目。参数name指定要删除的proc名称。
除了这些函数,值得一提的是结构struct
proc_dir_entry,为了创建一了可写的proc条目并指定该proc条目的写操作函数,必须设置上面的这些创建proc条目的函数返回的指针
指向的struct proc_dir_entry结构的write_proc字段,并指定该proc条目的访问权限有写权限。
为了使用这些接口函数以及结构struct proc_dir_entry,用户必须在模块中包含头文件linux/proc_fs.h。
在源代码包中给出了procfs示例程序procfs_exam.c,它定义了三个proc文件条目和一个proc目录条目,读者在插入该模块后应当看到如下结构:
读者可以通过cat和echo等文件操作函数来查看和设置这些proc文件。特别需要指出,bigprocfile是一个大文件(超过一个内存
页),对于这种大文件,procfs有一些限制,因为它提供的缓存,只有一个页,因此必须特别小心,并对超过页的部分做特别的考虑,处理起来比较复杂并且
很容易出错,所有procfs并不适合于大数据量的输入输出,后面一节seq_file就是因为这一缺陷而设计的,当然seq_file依赖于 procfs的一些基础功能。
#include <linux/config.h>
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/proc_fs.h>
#include <linux/sched.h>
#include <linux/types.h>
#include <asm/uaccess.h>
#define STR_MAX_SIZE 255
staticint int_var;
staticchar string_var[];
staticchar big_buffer[];
staticint big_buffer_len =;
staticstruct proc_dir_entry * myprocroot;
staticint first_write_flag =;
int int_read_proc(char*page, char**start, off_t off, int count, int*eof, void*data)
{
count = sprintf(page, "%d", *(int*)data);
return count;
}
int int_write_proc(struct file *file, constchar __user *buffer,unsigned long count, void*data)
{
unsigned int c =, len =, val, sum =;
int* temp = (int*)data;
while (count) {
if (get_user(c, buffer)) //从用户空间中得到数据
return-EFAULT;
len++;
buffer++;
count--;
if (c ==|| c ==)
break;
val = c -'';
if (val >)
return-EINVAL;
sum *=;
sum += val;
}
* temp = sum;
return len;
}
int string_read_proc(char*page, char**start, off_t off,int count, int*eof, void*data)
{
count = sprintf(page, "%s", (char*)data);
return count;
}
int string_write_proc(struct file *file, constchar __user *buffer, unsigned long count, void*data)
{
if (count > STR_MAX_SIZE) {
count =;
}
copy_from_user(data, buffer, count);
return count;
}
int bigfile_read_proc(char*page, char**start, off_t off, int count, int*eof, void*data)
{
if (off > big_buffer_len) {
* eof =;
return;
}
if (count > PAGE_SIZE) {
count = PAGE_SIZE;
}
if (big_buffer_len - off < count) {
count = big_buffer_len - off;
}
memcpy(page, data, count);
*start = page;
return count;
}
int bigfile_write_proc(struct file *file, constchar __user *buffer, unsigned long count, void*data)
{
char* p = (char*)data;
if (first_write_flag) {
big_buffer_len =;
first_write_flag =;
}
if (- big_buffer_len < count) {
count =- big_buffer_len;
first_write_flag =;
}
copy_from_user(p + big_buffer_len, buffer, count);
big_buffer_len += count;
return count;
}
staticint __init procfs_exam_init(void)
{
#ifdef CONFIG_PROC_FS
struct proc_dir_entry * entry;
myprocroot = proc_mkdir("myproctest", NULL);
entry = create_proc_entry("aint", , myprocroot);
if (entry) {
entry->data =&int_var;
entry->read_proc =&int_read_proc;
entry->write_proc =&int_write_proc;
}
entry = create_proc_entry("astring", , myprocroot);
if (entry) {
entry->data =&string_var;
entry->read_proc =&string_read_proc;
entry->write_proc =&string_write_proc;
}
entry = create_proc_entry("bigprocfile", , myprocroot);
if (entry) {
entry->data =&big_buffer;
entry->read_proc =&bigfile_read_proc;
entry->write_proc =&bigfile_write_proc;
}
#else
printk("This module requires the kernel to support procfs,\n");
#endif
return;
}
Linux 驱动开发的更多相关文章
- 嵌入式Linux驱动开发日记
嵌入式Linux驱动开发日记 主机硬件环境 开发机:虚拟机Ubuntu12.04 内存: 1G 硬盘:80GB 目标板硬件环境 CPU: SP5V210 (开发板:QT210) SDRAM: 512M ...
- 嵌入式linux驱动开发之点亮led(驱动编程思想之初体验)
这节我们就开始开始进行实战啦!这里顺便说一下啊,出来做开发的基础很重要啊,基础不好,迟早是要恶补的.个人深刻觉得像这种嵌入式的开发对C语言和微机接口与原理是非常依赖的,必须要有深厚的基础才能hold的 ...
- 【转】linux驱动开发的经典书籍
原文网址:http://www.cnblogs.com/xmphoenix/archive/2012/03/27/2420044.html Linux驱动学习的最大困惑在于书籍的缺乏,市面上最常见的书 ...
- Linux驱动开发 -- 打开dev_dbg()
Linux驱动开发 -- 打开dev_dbg() -- :: 分类: LINUX linux设备驱动调试,我们在内核中看到内核使用dev_dbg来控制输出信息,这个函数的实质是调用printk(KER ...
- Linux驱动开发学习的一些必要步骤
1. 学会写简单的makefile 2. 编一应用程序,可以用makefile跑起来 3. 学会写驱动的makefile 4. 写一简单char驱动,makefile编译通过,可以insmod, ...
- 驱动编程思想之初体验 --------------- 嵌入式linux驱动开发之点亮LED
这节我们就开始开始进行实战啦!这里顺便说一下啊,出来做开发的基础很重要啊,基础不好,迟早是要恶补的.个人深刻觉得像这种嵌入式的开发对C语言和微机接口与原理是非常依赖的,必须要有深厚的基础才能hold的 ...
- Linux驱动开发必看详解神秘内核(完全转载)
Linux驱动开发必看详解神秘内核 完全转载-链接:http://blog.chinaunix.net/uid-21356596-id-1827434.html IT168 技术文档]在开始步入L ...
- Linux内核(17) - 高效学习Linux驱动开发
这本<Linux内核修炼之道>已经开卖(网上的链接为: 卓越.当当.china-pub ),虽然是严肃文学,但为了保证流畅性,大部分文字我还都是斟词灼句,反复的念几遍才写上去的,尽量考虑到 ...
- s3c6410 Linux 驱动开发环境搭建
s3c6410 Linux 驱动开发环境搭建 -- 既然你是做Linux开发的,你还用虚拟机? 非常多人都在win下做开发,于是SD_writer.exe之类的烧写工具"大行其道" ...
随机推荐
- 【H5】-- FormData用法介绍以及实现图片/文件上传--【XUEBIG】
一.概述 FormData 对象的使用: 1.用一些键值对来模拟一系列表单控件:即把form中所有表单元素的name与value组装成一个queryString 2. 异步上传二进制文件. 二.使 ...
- python网站开发准备ubuntu14.04安装mysql实现windows管理
sudo apt-get install mysql-server mysql-client 输入root密码 然后确认安装tab选定确认 输入数据库密码 重复输入 启动 sudo service m ...
- shell 日前 之check 年月日
twoDayAgoTime=`date -d \`date -d "-2 day" +%Y%m%d\` +%s` sevenDayAgoTime=`date -d \`date - ...
- linux 学习笔记 wc命令
#wc 文件名.txt 输出 4 13 65 文件名.txt -->4 行13个单词 #wc -w 文件名.txt 统计单词数量 #wc -l 文件名.txt 统计行数 #wc -c 文 ...
- visual studio 加入zen-codding
大家都知道zen codding的强大之处大家都知道了,那如何让visual studio也支持呢,直接下载插件安装即可: 插件下载地址:zen-codding for visual studio下载 ...
- XamarinAndroid组件教程RecylerView动画组件使用动画(3)
XamarinAndroid组件教程RecylerView动画组件使用动画(3) (8)打开Main.axml文件,构建主界面.代码如下: <?xml version="1.0&quo ...
- [C程序设计基础]快速排序
//从大到小排序 ///三个参数 a要排序的 数组, l扫左边的 r扫右边 void quickSort(int a[],int l, int r){ /// 左边要小于 右边才有意义 if (l & ...
- Python应用——自定义函数:分割PDF文件函数
案例 将一个 pdf 文件按要求分割为几个部分.比如说一个pdf有20页,分成5个pdf文件,每个pdf文件包含4页.设计函数实现? Python代码 from PyPDF2 import PdfFi ...
- Linux下MySQL 安装配置
MySQL 是最流行的关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL所使用的SQL语言是用于访问数据库的最常用标准化语言. MySQL由于其体积小.速度快 ...
- Java 字符编码 ASCII、Unicode、UTF-8、代码点和代码单元
1 ASCII码 统一规定英语字符与二进制位之间的关系.ASCII码一共规定了128个字符的编码.例如,空格“SPACE”是32(二进制00100000),大写字母A是65(二进制01000001). ...