Introducing Apache Spark Datasets(中英双语)
文章标题
Introducing Apache Spark Datasets
作者介绍
Michael Armbrust, Wenchen Fan, Reynold Xin and Matei Zaharia
文章正文
Developers have always loved Apache Spark for providing APIs that are simple yet powerful, a combination of traits that makes complex analysis possible with minimal programmer effort. At Databricks, we have continued to push Spark’s usability and performance envelope through the introduction of DataFrames and Spark SQL. These are high-level APIs for working with structured data (e.g. database tables, JSON files), which let Spark automatically optimize both storage and computation. Behind these APIs, the Catalyst optimizer and Tungsten execution engine optimize applications in ways that were not possible with Spark’s object-oriented (RDD) API, such as operating on data in a raw binary form.
Today we’re excited to announce Spark Datasets, an extension of the DataFrame API that provides a type-safe, object-oriented programming interface. Spark 1.6 includes an API preview of Datasets, and they will be a development focus for the next several versions of Spark. Like DataFrames, Datasets take advantage of Spark’s Catalyst optimizer by exposing expressions and data fields to a query planner. Datasets also leverage Tungsten’s fast in-memory encoding. Datasets extend these benefits with compile-time type safety – meaning production applications can be checked for errors before they are run. They also allow direct operations over user-defined classes.
In the long run, we expect Datasets to become a powerful way to write more efficient Spark applications. We have designed them to work alongside the existing RDD API, but improve efficiency when data can be represented in a structured form. Spark 1.6 offers the first glimpse at Datasets, and we expect to improve them in future releases.
1、Working with Datasets
A Dataset is a strongly-typed, immutable collection of objects that are mapped to a relational schema. At the core of the Dataset API is a new concept called an encoder, which is responsible for converting between JVM objects and tabular representation. The tabular representation is stored using Spark’s internal Tungsten binary format, allowing for operations on serialized data and improved memory utilization. Spark 1.6 comes with support for automatically generating encoders for a wide variety of types, including primitive types (e.g. String, Integer, Long), Scala case classes, and Java Beans.
Users of RDDs will find the Dataset API quite familiar, as it provides many of the same functional transformations (e.g. map, flatMap, filter). Consider the following code, which reads lines of a text file and splits them into words:
// RDDs
val lines = sc.textFile("/wikipedia")
val words = lines
.flatMap(_.split(" "))
.filter(_ != "")
// Datasets
val lines = sqlContext.read.text("/wikipedia").as[String]
val words = lines
.flatMap(_.split(" "))
.filter(_ != "")
Both APIs make it easy to express the transformation using lambda functions. The compiler and your IDE understand the types being used, and can provide helpful tips and error messages while you construct your data pipeline.
While this high-level code may look similar syntactically, with Datasets you also have access to all the power of a full relational execution engine. For example, if you now want to perform an aggregation (such as counting the number of occurrences of each word), that operation can be expressed simply and efficiently as follows:
// RDDs val counts = words
.groupBy(_.toLowerCase)
.map(w => (w._1, w._2.size))
// Datasets val counts = words
.groupBy(_.toLowerCase)
.count()
Since the Dataset version of word count can take advantage of the built-in aggregate count, this computation can not only be expressed with less code, but it will also execute significantly faster. As you can see in the graph below, the Dataset implementation runs much faster than the naive RDD implementation. In contrast, getting the same performance using RDDs would require users to manually consider how to express the computation in a way that parallelizes optimally.
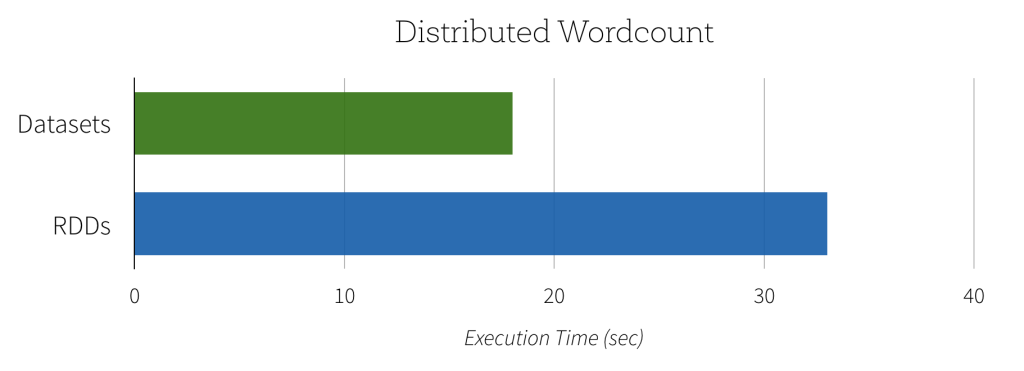
Another benefit of this new Dataset API is the reduction in memory usage. Since Spark understands the structure of data in Datasets, it can create a more optimal layout in memory when caching Datasets. In the following example, we compare caching several million strings in memory using Datasets as opposed to RDDs. In both cases, caching data can lead to significant performance improvements for subsequent queries. However, since Dataset encoders provide more information to Spark about the data being stored, the cached representation can be optimized to use 4.5x less space.

To help you get started, we’ve put together some example notebooks: Working with Classes, Word Count.
2、Lightning-fast Serialization with Encoders
Encoders are highly optimized and use runtime code generation to build custom bytecode for serialization and deserialization. As a result, they can operate significantly faster than Java or Kryo serialization.
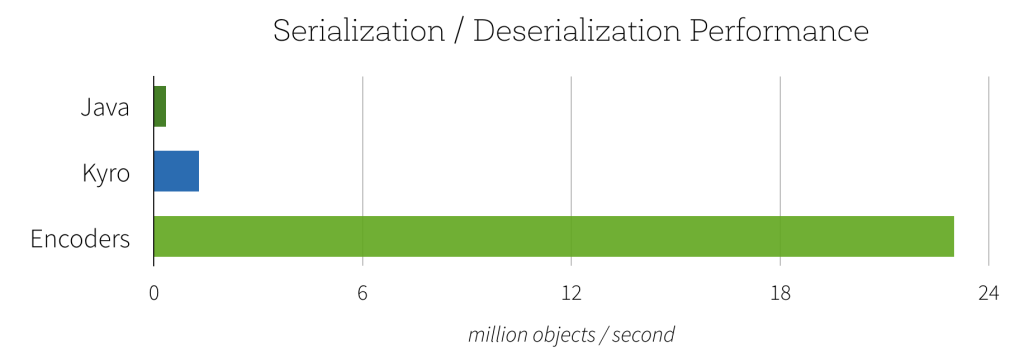
In addition to speed, the resulting serialized size of encoded data can also be significantly smaller (up to 2x), reducing the cost of network transfers. Furthermore, the serialized data is already in the Tungsten binary format, which means that many operations can be done in-place, without needing to materialize an object at all. Spark has built-in support for automatically generating encoders for primitive types (e.g. String, Integer, Long), Scala case classes, and Java Beans. We plan to open up this functionality and allow efficient serialization of custom types in a future release.
3、Seamless Support for Semi-Structured Data
The power of encoders goes beyond performance. They also serve as a powerful bridge between semi-structured formats (e.g. JSON) and type-safe languages like Java and Scala.
For example, consider the following dataset about universities:
{"name": "UC Berkeley", "yearFounded": 1868, numStudents: 37581}
{"name": "MIT", "yearFounded": 1860, numStudents: 11318}
…
Instead of manually extracting fields and casting them to the desired type, you can simply define a class with the expected structure and map the input data to it. Columns are automatically lined up by name, and the types are preserved.
case class University(name: String, numStudents: Long, yearFounded: Long)
val schools = sqlContext.read.json("/schools.json").as[University]
schools.map(s => s"${s.name} is ${2015 – s.yearFounded} years old")
Encoders eagerly check that your data matches the expected schema, providing helpful error messages before you attempt to incorrectly process TBs of data. For example, if we try to use a datatype that is too small, such that conversion to an object would result in truncation (i.e. numStudents is larger than a byte, which holds a maximum value of 255) the Analyzer will emit an AnalysisException.
case class University(numStudents: Byte)
val schools = sqlContext.read.json("/schools.json").as[University]
org.apache.spark.sql.AnalysisException: Cannot upcast `yearFounded` from bigint to smallint as it may truncate
When performing the mapping, encoders will automatically handle complex types, including nested classes, arrays, and maps.
4、A Single API for Java and Scala
Another goal to the Dataset API is to provide a single interface that is usable in both Scala and Java. This unification is great news for Java users as it ensure that their APIs won’t lag behind the Scala interfaces, code examples can easily be used from either language, and libraries no longer have to deal with two slightly different types of input. The only difference for Java users is they need to specify the encoder to use since the compiler does not provide type information. For example, if wanted to process json data using Java you could do it as follows:
public class University implements Serializable {
private String name;
private long numStudents;
private long yearFounded;
public void setName(String name) {...}
public String getName() {...}
public void setNumStudents(long numStudents) {...}
public long getNumStudents() {...}
public void setYearFounded(long yearFounded) {...}
public long getYearFounded() {...}
}
class BuildString implements MapFunction {
public String call(University u) throws Exception {
return u.getName() + " is " + (2015 - u.getYearFounded()) + " years old.";
}
}
Dataset schools = context.read().json("/schools.json").as(Encoders.bean(University.class));
Dataset strings = schools.map(new BuildString(), Encoders.STRING());
5、Looking Forward
While Datasets are a new API, we have made them interoperate easily with RDDs and existing Spark programs. Simply calling the rdd() method on a Dataset will give an RDD. In the long run, we hope that Datasets can become a common way to work with structured data, and we may converge the APIs even further.
As we look forward to Spark 2.0, we plan some exciting improvements to Datasets, specifically:
- Performance optimizations – In many cases, the current implementation of the Dataset API does not yet leverage the additional information it has and can be slower than RDDs. Over the next several releases, we will be working on improving the performance of this new API.
- Custom encoders – while we currently autogenerate encoders for a wide variety of types, we’d like to open up an API for custom objects.
- Python Support.
- Unification of DataFrames with Datasets – due to compatibility guarantees, DataFrames and Datasets currently cannot share a common parent class. With Spark 2.0, we will be able to unify these abstractions with minor changes to the API, making it easy to build libraries that work with both.
If you’d like to try out Datasets yourself, they are already available in Databricks. We’ve put together a few example notebooks for you to try out: Working with Classes, Word Count.
Spark 1.6 is available on Databricks today, sign up for a free 14-day trial.
参考文献
- https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html
- https://blog.csdn.net/sunbow0/article/details/50723233
Introducing Apache Spark Datasets(中英双语)的更多相关文章
- 我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)【中英双语】
我在 B 站学机器学习(Machine Learning)- 吴恩达(Andrew Ng)[中英双语] 视频地址:https://www.bilibili.com/video/av9912938/ t ...
- Introducing DataFrames in Apache Spark for Large Scale Data Science(中英双语)
文章标题 Introducing DataFrames in Apache Spark for Large Scale Data Science 一个用于大规模数据科学的API——DataFrame ...
- A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets(中英双语)
文章标题 A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets 且谈Apache Spark的API三剑客:RDD.Dat ...
- What’s new for Spark SQL in Apache Spark 1.3(中英双语)
文章标题 What’s new for Spark SQL in Apache Spark 1.3 作者介绍 Michael Armbrust 文章正文 The Apache Spark 1.3 re ...
- Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop(中英双语)
文章标题 Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop Deep dive into the ne ...
- One SQL to Rule Them All – an Efficient and Syntactically Idiomatic Approach to Management of Streams and Tables(中英双语)
文章标题 One SQL to Rule Them All – an Efficient and Syntactically Idiomatic Approach to Management of S ...
- Matalb中英双语手册-年少无知翻译版本
更新: 20171207: 这是大学期间参加数模翻译的手册 正文: 愚人节快乐,突然发现自己在博客园的一篇文章.摘取如下: MATLAB 语言是一种工程语言,语法很像 VB 和 C,比 R 语言容易学 ...
- Spark 论文篇-RDD:一种为内存化集群计算设计的容错抽象(中英双语)
论文内容: 待整理 参考文献: Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster C ...
- Deep Dive into Spark SQL’s Catalyst Optimizer(中英双语)
文章标题 Deep Dive into Spark SQL’s Catalyst Optimizer 作者介绍 Michael Armbrust, Yin Huai, Cheng Liang, Rey ...
随机推荐
- windows系统nexus3安装和配置
一.前言 为什么要在本地开发机器上安装nexus?首先声明公司内部是有自己的nexus仓库,但是对上传jar包做了限制,不能畅快的上传自己测试包依赖.于是就自己在本地搭建了一个nexus私服,即可以使 ...
- springboot整合视图层之jsp
在springboot中不推荐视图层使用jsp展示,但是人们以前已经习惯使用jsp,所以对jsp也有支持,但是是解耦性的.也就是说并没有像其他组件一样直接集成到启动器中,所以像jsp引擎之类的需要额外 ...
- BZOJ1500: [NOI2005]维修数列 [splay序列操作]【学习笔记】
以前写过这道题了,但我把以前的内容删掉了,因为现在感觉没法看 重写! 题意: 维护一个数列,支持插入一段数,删除一段数,修改一段数,翻转一段数,查询区间和,区间最大子序列 splay序列操作裸题 需要 ...
- 基于AT89C51单片机烟雾传感器
#include <reg51.h> #include <stdio.h> #define uchar unsigned char //宏定义无符号字符型 #define ui ...
- Flask框架返回值
Flask中的HTTPResponse def index(): #视图函数 return 'Hello World' #直接return就是返回的字符串 Flask中的Redirect,和djang ...
- C# 计算地图上某个坐标点的是否在多边形内
这个方法引用自群友的博客 https://www.xiaofengyu.com/?p=143 使用百度地图的时候,常常会用到判断一个点是否在一个多边形的范围内,该方法用到的是射线法, 通过修改Java ...
- Build fails with an error: Execution failed for task ':react-native-google-analytics-bridge:compileDebugJavaWithJavac'.
1,问题 Build fails with an error: Execution failed for task ':react-native-google-analytics-bridge:com ...
- 180400之pycharm快捷方式汇总
1.Pycharm中快捷键大全,遇到一个更新一个 撤销与反撤销:Ctrl + z,Ctrl + Shift + z 缩进.不缩进:Tab.Shift + tab 运行:Shift + F10 批量注释 ...
- Sqoop导入到hdfs
1.注意win下直接复制进linux 改一下--等 sqoop-list-databases --connect jdbc:mysql://122.206.79.212:3306/ --usernam ...
- api日常总结:前端常用js函数和CSS常用技巧
我的移动端media html{font-size:10px} @media screen and (min-width:321px) and (max-width:375px){html{font- ...