redis-sentinel主从复制高可用
Redis-Sentinel
Redis-Sentinel是redis官方推荐的高可用性解决方案,
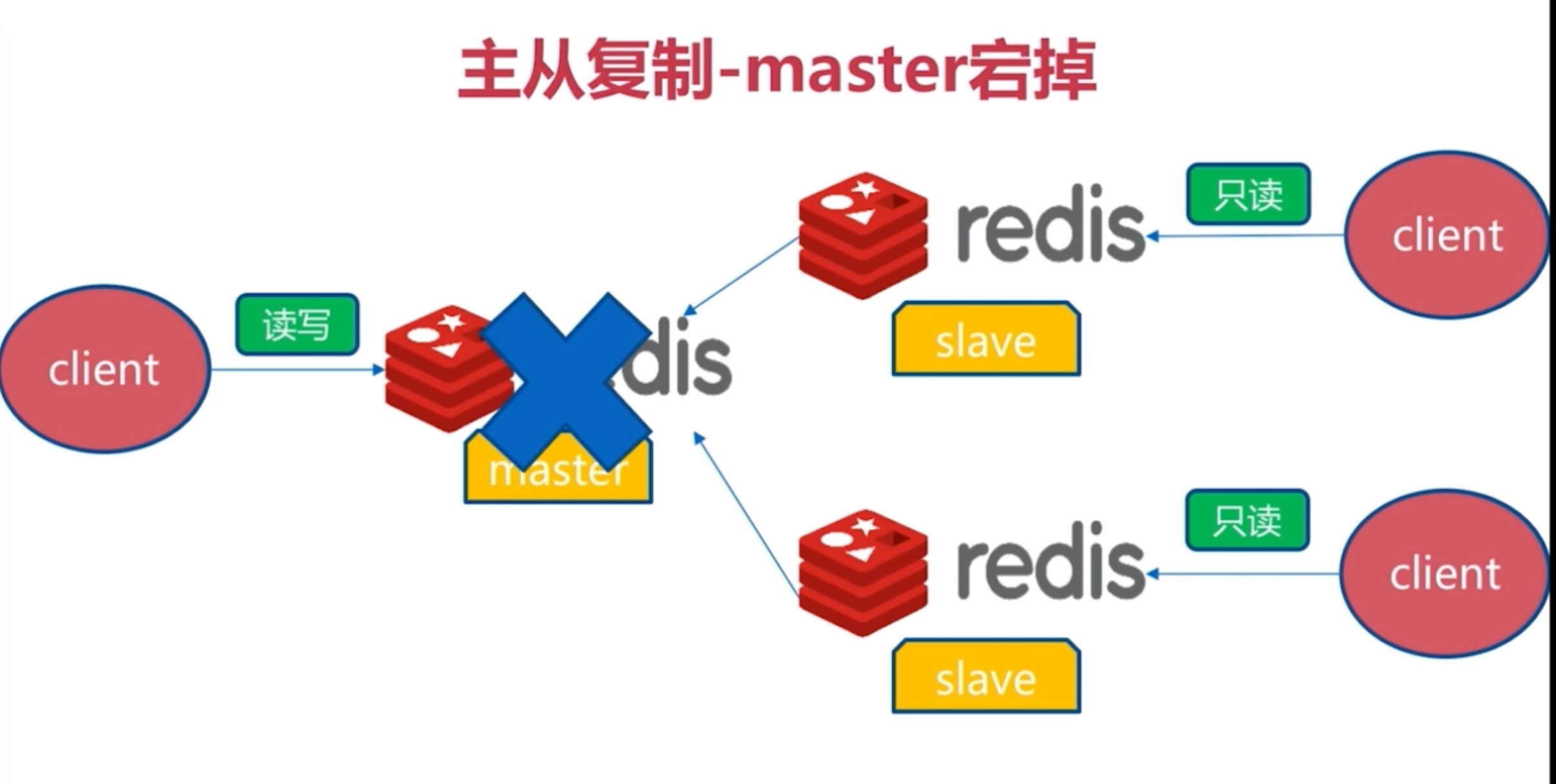
当用redis作master-slave的高可用时,如果master本身宕机,redis本身或者客户端都没有实现主从切换的功能。 而redis-sentinel就是一个独立运行的进程,用于监控多个master-slave集群,
自动发现master宕机,进行自动切换slave > master。
sentinel主要功能如下:
- 不时的监控redis是否良好运行,如果节点不可达就会对节点进行下线标识
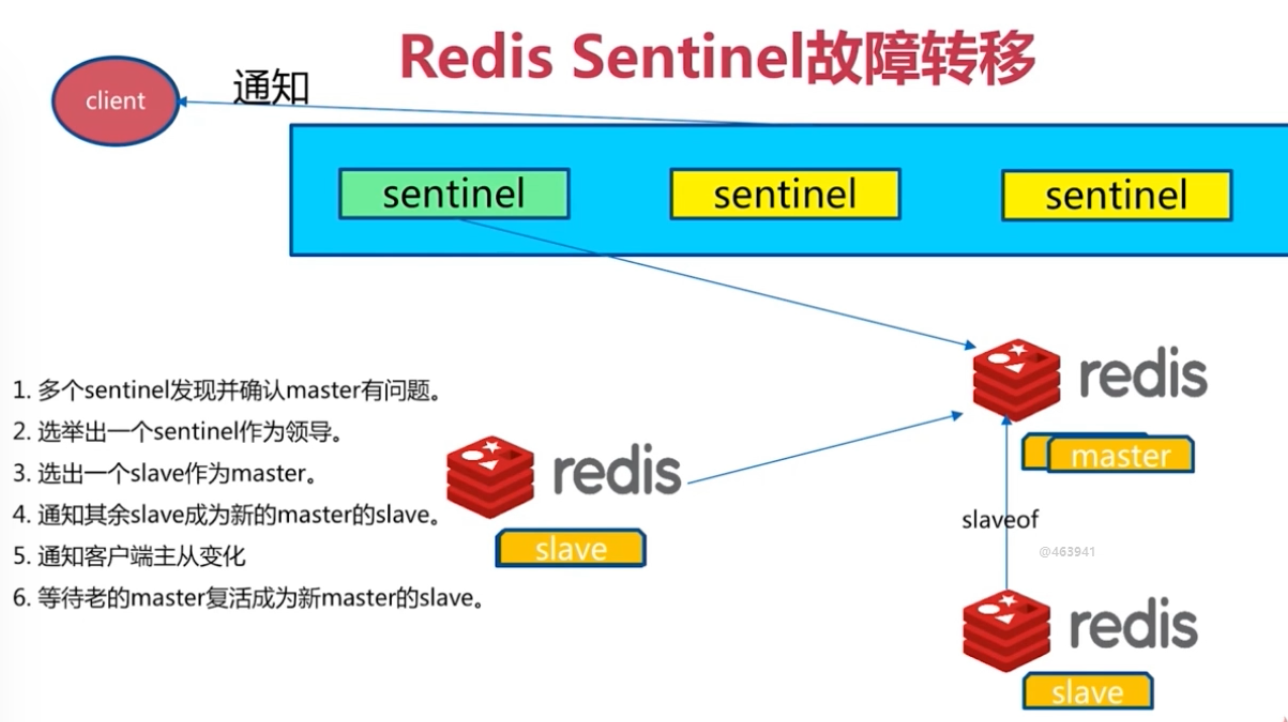
- 如果被标识的是主节点,sentinel就会和其他的sentinel节点“协商”,如果其他节点也人为主节点不可达,就会选举一个sentinel节点来完成自动故障转义
- 在master-slave进行切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换
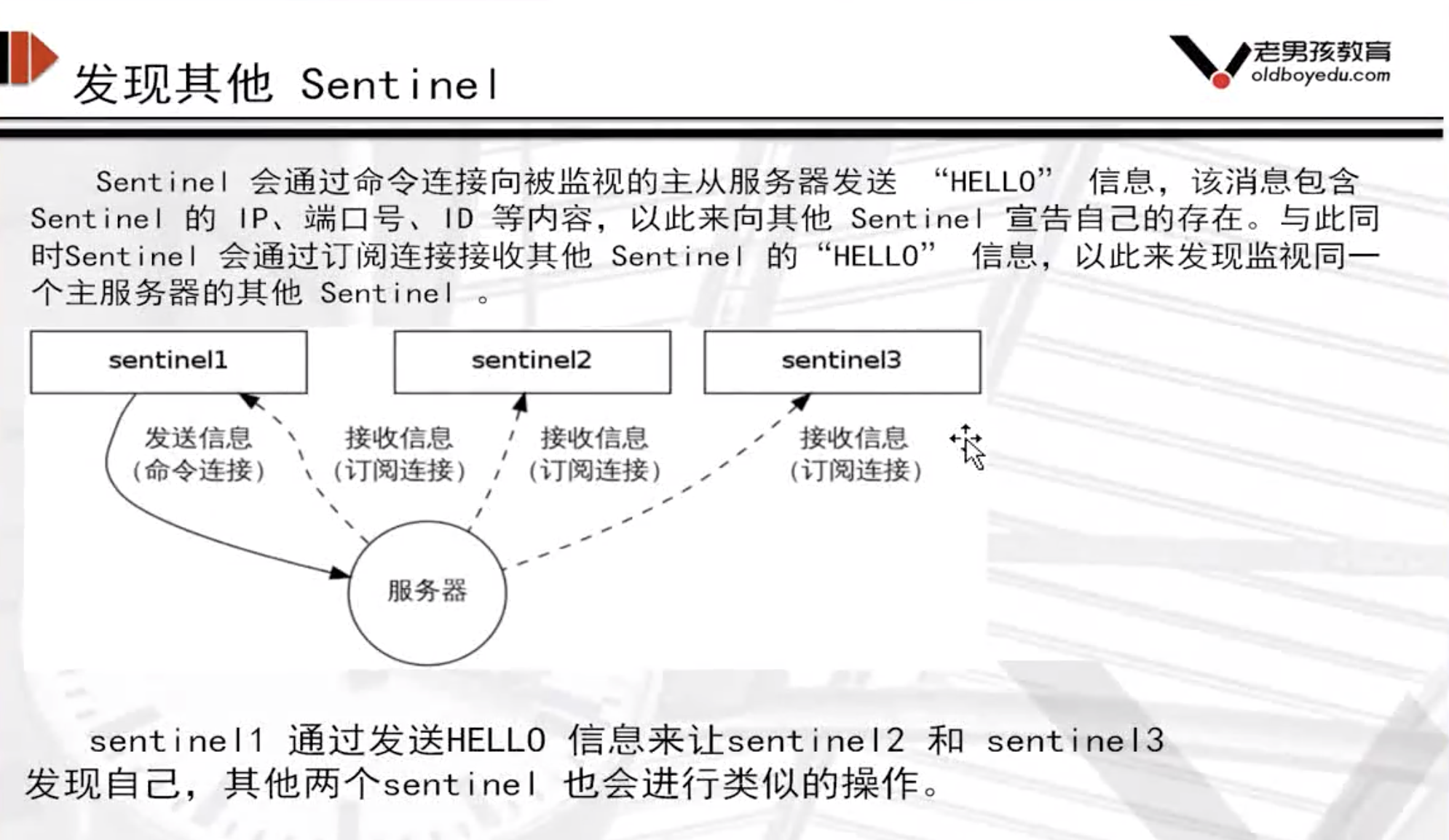
Sentinel的工作方式:
每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 在一般情况下, 每个 Sentinel 会以每 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 秒一次改为每秒一次 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。 若 Master 重新向 Sentinel 的 PING 命令返回有效回复, Master 的主观下线状态就会被移除。 主观下线和客观下线 主观下线:Subjectively Down,简称 SDOWN,指的是当前 Sentinel 实例对某个redis服务器做出的下线判断。
客观下线:Objectively Down, 简称 ODOWN,指的是多个 Sentinel 实例在对Master Server做出 SDOWN 判断,并且通过 SENTINEL is-master-down-by-addr 命令互相交流之后,得出的Master Server下线判断,然后开启failover. SDOWN适合于Master和Slave,只要一个 Sentinel 发现Master进入了ODOWN, 这个 Sentinel 就可能会被其他 Sentinel 推选出, 并对下线的主服务器执行自动故障迁移操作。 ODOWN只适用于Master,对于Slave的 Redis 实例,Sentinel 在将它们判断为下线前不需要进行协商, 所以Slave的 Sentinel 永远不会达到ODOWN。
sentinel公作方式
redis主从复制背景问题
Redis主从复制可将主节点数据同步给从节点,从节点此时有两个作用:
- 一旦主节点宕机,从节点作为主节点的备份可以随时顶上来。
- 扩展主节点的读能力,分担主节点读压力。
但是问题是:
- 一旦主节点宕机,从节点上位,那么需要人为修改所有应用方的主节点地址(改为新的master地址),还需要命令所有从节点复制新的主节点
那么这个问题,redis-sentinel就可以解决了
主从复制架构

Redis Sentinel架构
redis的一个进程,但是不存储数据,只是监控redis

redis命令整理
官网地址:http://redisdoc.com/ redis-cli info #查看redis数据库信息 redis-cli info replication #查看redis的复制授权信息
redis-cli info sentinel #查看redis的哨兵信息
安装与配置
本实验是在测试环境下,考虑到学生机器较弱,因此只准备一台linux服务器用作环境!!
服务器环境,一台即可完成操作
master 192.168.119.10
所有配置文件如下
主节点master的redis-6379.conf
port
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
dir "/var/redis/data/"
从节点slave的redis-6380.conf
port
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
dir "/var/redis/data/"
slaveof 127.0.0.1 // 从属主节点
从节点slave的redis-6381.conf
port
daemonize yes
logfile "6380.log"
dbfilename "dump-6380.rdb"
dir "/var/redis/data/"
slaveof 127.0.0.1 // 从属主节点
启动redis主节点
redis-server /etc/redis-6379.conf
测试redis主节点是否通信
redis-cli ping
启动两slave节点
还记得上面超哥的截图吗?总体redis配置文件如下,6379为master,6380和6381为slave
-rw-r--r-- root root Nov : /etc/redis-.conf #这个为主,port是6379
-rw-r--r-- root root Nov : /etc/redis-.conf # 这个是从,port6380,并且得加上新的参数slaveof
-rw-r--r-- root root Nov : /etc/redis-.conf # 这个是从,port6381,并且得加上新的参数slaveof
redis-6380.conf slave配置文件详解,6381端口的配置文件,仅仅和6380端口不一样
port
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
dir "/var/redis/data"
# Generated by CONFIG REWRITE
slaveof 127.0.0.1
# Redis 配置文件 # 当配置中需要配置内存大小时,可以使用 1k, 5GB, 4M 等类似的格式,其转换方式如下(不区分大小写)
#
# 1k => bytes
# 1kb => bytes
# 1m => bytes
# 1mb => * bytes
# 1g => bytes
# 1gb => ** bytes
#
# 内存配置大小写是一样的.比如 1gb 1Gb 1GB 1gB # daemonize no 默认情况下,redis不是在后台运行的,如果需要在后台运行,把该项的值更改为yes
daemonize yes # 当redis在后台运行的时候,Redis默认会把pid文件放在/var/run/redis.pid,你可以配置到其他地址。
# 当运行多个redis服务时,需要指定不同的pid文件和端口
pidfile /var/run/redis.pid # 指定redis运行的端口,默认是6379
port # 指定redis只接收来自于该IP地址的请求,如果不进行设置,那么将处理所有请求,
# 在生产环境中最好设置该项
# bind 127.0.0.1 # Specify the path for the unix socket that will be used to listen for
# incoming connections. There is no default, so Redis will not listen
# on a unix socket when not specified.
#
# unixsocket /tmp/redis.sock
# unixsocketperm # 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接
# 0是关闭此设置
timeout # 指定日志记录级别
# Redis总共支持四个级别:debug、verbose、notice、warning,默认为verbose
# debug 记录很多信息,用于开发和测试
# varbose 有用的信息,不像debug会记录那么多
# notice 普通的verbose,常用于生产环境
# warning 只有非常重要或者严重的信息会记录到日志
loglevel debug # 配置log文件地址
# 默认值为stdout,标准输出,若后台模式会输出到/dev/null
#logfile stdout
logfile /var/log/redis/redis.log # To enable logging to the system logger, just set 'syslog-enabled' to yes,
# and optionally update the other syslog parameters to suit your needs.
# syslog-enabled no # Specify the syslog identity.
# syslog-ident redis # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7.
# syslog-facility local0 # 可用数据库数
# 默认值为16,默认数据库为0,数据库范围在0-(database-)之间
databases ################################ 快照 #################################
#
# 保存数据到磁盘,格式如下:
#
# save <seconds> <changes>
#
# 指出在多长时间内,有多少次更新操作,就将数据同步到数据文件rdb。
# 相当于条件触发抓取快照,这个可以多个条件配合
#
# 比如默认配置文件中的设置,就设置了三个条件
#
# save 900秒内至少有1个key被改变
# save 300秒内至少有300个key被改变
# save 60秒内至少有10000个key被改变 save
save
save # 存储至本地数据库时(持久化到rdb文件)是否压缩数据,默认为yes
rdbcompression yes # 本地持久化数据库文件名,默认值为dump.rdb
dbfilename dump.rdb # 工作目录
#
# 数据库镜像备份的文件放置的路径。
# 这里的路径跟文件名要分开配置是因为redis在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,
# 再把该该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中。
#
# AOF文件也会存放在这个目录下面
#
# 注意这里必须制定一个目录而不是文件
dir ./ ################################# 复制 ################################# # 主从复制. 设置该数据库为其他数据库的从数据库.
# 设置当本机为slav服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
#
# slaveof <masterip> <masterport> # 当master服务设置了密码保护时(用requirepass制定的密码)
# slav服务连接master的密码
#
# masterauth <master-password> # 当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:
#
# ) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续相应客户端的请求
#
# ) 如果slave-serve-stale-data是指为no,出去INFO和SLAVOF命令之外的任何请求都会返回一个
# 错误"SYNC with master in progress"
#
slave-serve-stale-data yes # 从库会按照一个时间间隔向主库发送PINGs.可以通过repl-ping-slave-period设置这个时间间隔,默认是10秒
#
# repl-ping-slave-period # repl-timeout 设置主库批量数据传输时间或者ping回复时间间隔,默认值是60秒
# 一定要确保repl-timeout大于repl-ping-slave-period
# repl-timeout ################################## 安全 ################################### # 设置客户端连接后进行任何其他指定前需要使用的密码。
# 警告:因为redis速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行150K次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解
#
# requirepass foobared # 命令重命名.
#
# 在一个共享环境下可以重命名相对危险的命令。比如把CONFIG重名为一个不容易猜测的字符。
#
# 举例:
#
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
#
# 如果想删除一个命令,直接把它重命名为一个空字符""即可,如下:
#
# rename-command CONFIG "" ################################### 约束 #################################### # 设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,
# 如果设置 maxclients ,表示不作限制。
# 当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
#
# maxclients # 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key
# Redis同时也会移除空的list对象
#
# 当此方法处理后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作
#
# 注意:Redis新的vm机制,会把Key存放内存,Value会存放在swap区
#
# maxmemory的设置比较适合于把redis当作于类似memcached的缓存来使用,而不适合当做一个真实的DB。
# 当把Redis当做一个真实的数据库使用的时候,内存使用将是一个很大的开销
# maxmemory <bytes> # 当内存达到最大值的时候Redis会选择删除哪些数据?有五种方式可供选择
#
# volatile-lru -> 利用LRU算法移除设置过过期时间的key (LRU:最近使用 Least Recently Used )
# allkeys-lru -> 利用LRU算法移除任何key
# volatile-random -> 移除设置过过期时间的随机key
# allkeys->random -> remove a random key, any key
# volatile-ttl -> 移除即将过期的key(minor TTL)
# noeviction -> 不移除任何可以,只是返回一个写错误
#
# 注意:对于上面的策略,如果没有合适的key可以移除,当写的时候Redis会返回一个错误
#
# 写命令包括: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# 默认是:
#
# maxmemory-policy volatile-lru # LRU 和 minimal TTL 算法都不是精准的算法,但是相对精确的算法(为了节省内存),随意你可以选择样本大小进行检测。
# Redis默认的灰选择3个样本进行检测,你可以通过maxmemory-samples进行设置
#
# maxmemory-samples ############################## AOF ############################### # 默认情况下,redis会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。
# 所以redis提供了另外一种更加高效的数据库备份及灾难恢复方式。
# 开启append only模式之后,redis会把所接收到的每一次写操作请求都追加到appendonly.aof文件中,当redis重新启动时,会从该文件恢复出之前的状态。
# 但是这样会造成appendonly.aof文件过大,所以redis还支持了BGREWRITEAOF指令,对appendonly.aof 进行重新整理。
# 你可以同时开启asynchronous dumps 和 AOF appendonly no # AOF文件名称 (默认: "appendonly.aof")
# appendfilename appendonly.aof # Redis支持三种同步AOF文件的策略:
#
# no: 不进行同步,系统去操作 . Faster.
# always: always表示每次有写操作都进行同步. Slow, Safest.
# everysec: 表示对写操作进行累积,每秒同步一次. Compromise.
#
# 默认是"everysec",按照速度和安全折中这是最好的。
# 如果想让Redis能更高效的运行,你也可以设置为"no",让操作系统决定什么时候去执行
# 或者相反想让数据更安全你也可以设置为"always"
#
# 如果不确定就用 "everysec". # appendfsync always
appendfsync everysec
# appendfsync no # AOF策略设置为always或者everysec时,后台处理进程(后台保存或者AOF日志重写)会执行大量的I/O操作
# 在某些Linux配置中会阻止过长的fsync()请求。注意现在没有任何修复,即使fsync在另外一个线程进行处理
#
# 为了减缓这个问题,可以设置下面这个参数no-appendfsync-on-rewrite
#
# This means that while another child is saving the durability of Redis is
# the same as "appendfsync none", that in pratical terms means that it is
# possible to lost up to seconds of log in the worst scenario (with the
# default Linux settings).
#
# If you have latency problems turn this to "yes". Otherwise leave it as
# "no" that is the safest pick from the point of view of durability.
no-appendfsync-on-rewrite no # Automatic rewrite of the append only file.
# AOF 自动重写
# 当AOF文件增长到一定大小的时候Redis能够调用 BGREWRITEAOF 对日志文件进行重写
#
# 它是这样工作的:Redis会记住上次进行些日志后文件的大小(如果从开机以来还没进行过重写,那日子大小在开机的时候确定)
#
# 基础大小会同现在的大小进行比较。如果现在的大小比基础大小大制定的百分比,重写功能将启动
# 同时需要指定一个最小大小用于AOF重写,这个用于阻止即使文件很小但是增长幅度很大也去重写AOF文件的情况
# 设置 percentage 为0就关闭这个特性 auto-aof-rewrite-percentage
auto-aof-rewrite-min-size 64mb ################################## SLOW LOG ################################### # Redis Slow Log 记录超过特定执行时间的命令。执行时间不包括I/O计算比如连接客户端,返回结果等,只是命令执行时间
#
# 可以通过两个参数设置slow log:一个是告诉Redis执行超过多少时间被记录的参数slowlog-log-slower-than(微妙),
# 另一个是slow log 的长度。当一个新命令被记录的时候最早的命令将被从队列中移除 # 下面的时间以微妙微单位,因此1000000代表一分钟。
# 注意制定一个负数将关闭慢日志,而设置为0将强制每个命令都会记录
slowlog-log-slower-than # 对日志长度没有限制,只是要注意它会消耗内存
# 可以通过 SLOWLOG RESET 回收被慢日志消耗的内存
slowlog-max-len ################################ VM ############################### ### WARNING! Virtual Memory is deprecated in Redis 2.4
### The use of Virtual Memory is strongly discouraged. # Virtual Memory allows Redis to work with datasets bigger than the actual
# amount of RAM needed to hold the whole dataset in memory.
# In order to do so very used keys are taken in memory while the other keys
# are swapped into a swap file, similarly to what operating systems do
# with memory pages.
#
# To enable VM just set 'vm-enabled' to yes, and set the following three
# VM parameters accordingly to your needs. vm-enabled no
# vm-enabled yes # This is the path of the Redis swap file. As you can guess, swap files
# can't be shared by different Redis instances, so make sure to use a swap
# file for every redis process you are running. Redis will complain if the
# swap file is already in use.
#
# The best kind of storage for the Redis swap file (that's accessed at random)
# is a Solid State Disk (SSD).
#
# *** WARNING *** if you are using a shared hosting the default of putting
# the swap file under /tmp is not secure. Create a dir with access granted
# only to Redis user and configure Redis to create the swap file there.
vm-swap-file /tmp/redis.swap # vm-max-memory configures the VM to use at max the specified amount of
# RAM. Everything that deos not fit will be swapped on disk *if* possible, that
# is, if there is still enough contiguous space in the swap file.
#
# With vm-max-memory the system will swap everything it can. Not a good
# default, just specify the max amount of RAM you can in bytes, but it's
# better to leave some margin. For instance specify an amount of RAM
# that's more or less between 60 and 80% of your free RAM.
vm-max-memory # Redis swap files is split into pages. An object can be saved using multiple
# contiguous pages, but pages can't be shared between different objects.
# So if your page is too big, small objects swapped out on disk will waste
# a lot of space. If you page is too small, there is less space in the swap
# file (assuming you configured the same number of total swap file pages).
#
# If you use a lot of small objects, use a page size of or bytes.
# If you use a lot of big objects, use a bigger page size.
# If unsure, use the default :)
vm-page-size # Number of total memory pages in the swap file.
# Given that the page table (a bitmap of free/used pages) is taken in memory,
# every pages on disk will consume byte of RAM.
#
# The total swap size is vm-page-size * vm-pages
#
# With the default of -bytes memory pages and pages Redis will
# use a GB swap file, that will use MB of RAM for the page table.
#
# It's better to use the smallest acceptable value for your application,
# but the default is large in order to work in most conditions.
vm-pages # Max number of VM I/O threads running at the same time.
# This threads are used to read/write data from/to swap file, since they
# also encode and decode objects from disk to memory or the reverse, a bigger
# number of threads can help with big objects even if they can't help with
# I/O itself as the physical device may not be able to couple with many
# reads/writes operations at the same time.
#
# The special value of turn off threaded I/O and enables the blocking
# Virtual Memory implementation.
vm-max-threads ############################### ADVANCED CONFIG ############################### # 当hash中包含超过指定元素个数并且最大的元素没有超过临界时,
# hash将以一种特殊的编码方式(大大减少内存使用)来存储,这里可以设置这两个临界值
# Redis Hash对应Value内部实际就是一个HashMap,实际这里会有2种不同实现,
# 这个Hash的成员比较少时Redis为了节省内存会采用类似一维数组的方式来紧凑存储,而不会采用真正的HashMap结构,对应的value redisObject的encoding为zipmap,
# 当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
hash-max-zipmap-entries
hash-max-zipmap-value # list数据类型多少节点以下会采用去指针的紧凑存储格式。
# list数据类型节点值大小小于多少字节会采用紧凑存储格式。
list-max-ziplist-entries
list-max-ziplist-value # set数据类型内部数据如果全部是数值型,且包含多少节点以下会采用紧凑格式存储。
set-max-intset-entries # zsort数据类型多少节点以下会采用去指针的紧凑存储格式。
# zsort数据类型节点值大小小于多少字节会采用紧凑存储格式。
zset-max-ziplist-entries
zset-max-ziplist-value # Redis将在每100毫秒时使用1毫秒的CPU时间来对redis的hash表进行重新hash,可以降低内存的使用
#
# 当你的使用场景中,有非常严格的实时性需要,不能够接受Redis时不时的对请求有2毫秒的延迟的话,把这项配置为no。
#
# 如果没有这么严格的实时性要求,可以设置为yes,以便能够尽可能快的释放内存
activerehashing yes ################################## INCLUDES ################################### # 指定包含其它的配置文件,可以在同一主机上多个Redis实例之间使用同一份配置文件,而同时各个实例又拥有自己的特定配置文件 # include /path/to/local.conf
# include /path/to/other.conf
redis.conf详解--补充--
启动slave从节点的redis服务
[root@master 192.168.119.10 ~]$redis-server /etc/redis-6380.conf
[root@master 192.168.119.10 ~]$redis-server /etc/redis-6381.conf
验证从节点的redis服务
[root@master ~]$redis-cli -p ping
PONG
[root@master ~]$redis-cli -p ping
PONG
确定主从关系
在主节点上查看主从通信关系
[root@master ~]# redis-cli -p info replication
# Replication
role:master
connected_slaves:
slave0:ip=192.168.119.10,port=6380,state=online,offset=407,lag=0
slave1:ip=192.168.119.10,port=6381,state=online,offset=407,lag=0
master_repl_offset:
repl_backlog_active:
repl_backlog_size:
repl_backlog_first_byte_offset:
repl_backlog_histlen:
在从节点上查看主从关系(6380、6379)
[root@slave 192.168.119.11 ~]$redis-cli -p info replication
# Replication
role:slave
master_host:192.168.119.10
master_port:6379
master_link_status:up
master_last_io_seconds_ago:
master_sync_in_progress:
slave_repl_offset:
slave_priority:
slave_read_only:
connected_slaves:
master_repl_offset:
repl_backlog_active:
repl_backlog_size:
repl_backlog_first_byte_offset:
repl_backlog_histlen:
此时可以在master上写入数据,在slave上查看数据,此时主从复制配置完成
开始配置Redis Sentinel
超哥实验的环境是单独一台linux,192.168.119.10
[root@master tmp]# ll /etc/redis-*
-rw-r--r-- root root Nov : /etc/redis-.conf
-rw-r--r-- root root Nov : /etc/redis-.conf
-rw-r--r-- root root Nov : /etc/redis-.conf
-rw-r--r-- 1 root root 556 Nov 7 17:42 /etc/redis-sentinel-26379.conf
-rw-r--r-- 1 root root 556 Nov 7 17:42 /etc/redis-sentinel-26380.conf
-rw-r--r-- 1 root root 556 Nov 7 17:42 /etc/redis-sentinel-26381.conf
redis-sentinel-26379.conf配置文件写入如下信息
// Sentinel节点的端口
port
dir /var/redis/data/
logfile "26379.log" // 当前Sentinel节点监控 192.168.119.10:6379 这个主节点
// 2代表判断主节点失败至少需要2个Sentinel节点节点同意
// mymaster是主节点的别名
sentinel monitor mymaster 192.168.119.10 //每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster //当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,
原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1
sentinel parallel-syncs mymaster //故障转移超时时间为180000毫秒
sentinel failover-timeout mymaster
redis-sentinel-26380.conf和redis-sentinel-26381.conf的配置仅仅差异是port(端口)的不同。
然后启动三个sentinel哨兵
redis-sentinel /etc/redis-sentinel-.conf
redis-sentinel /etc/redis-sentinel-.conf
redis-sentinel /etc/redis-sentinel-.conf
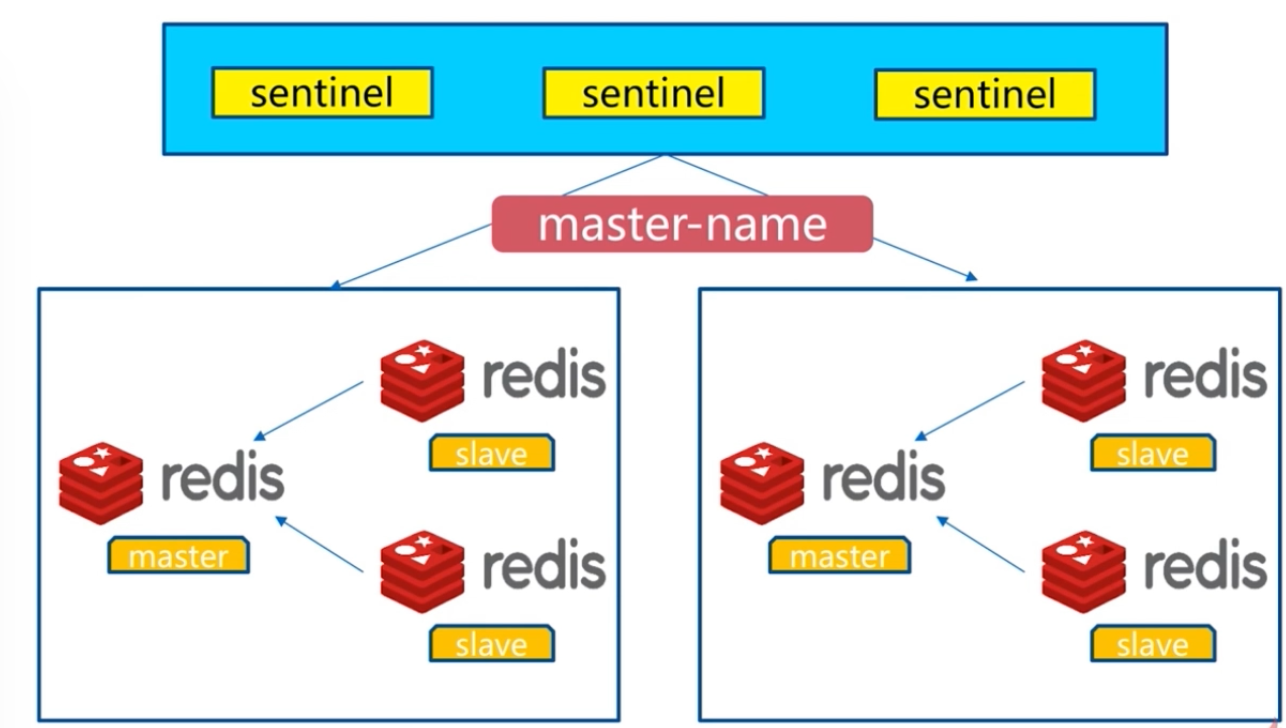
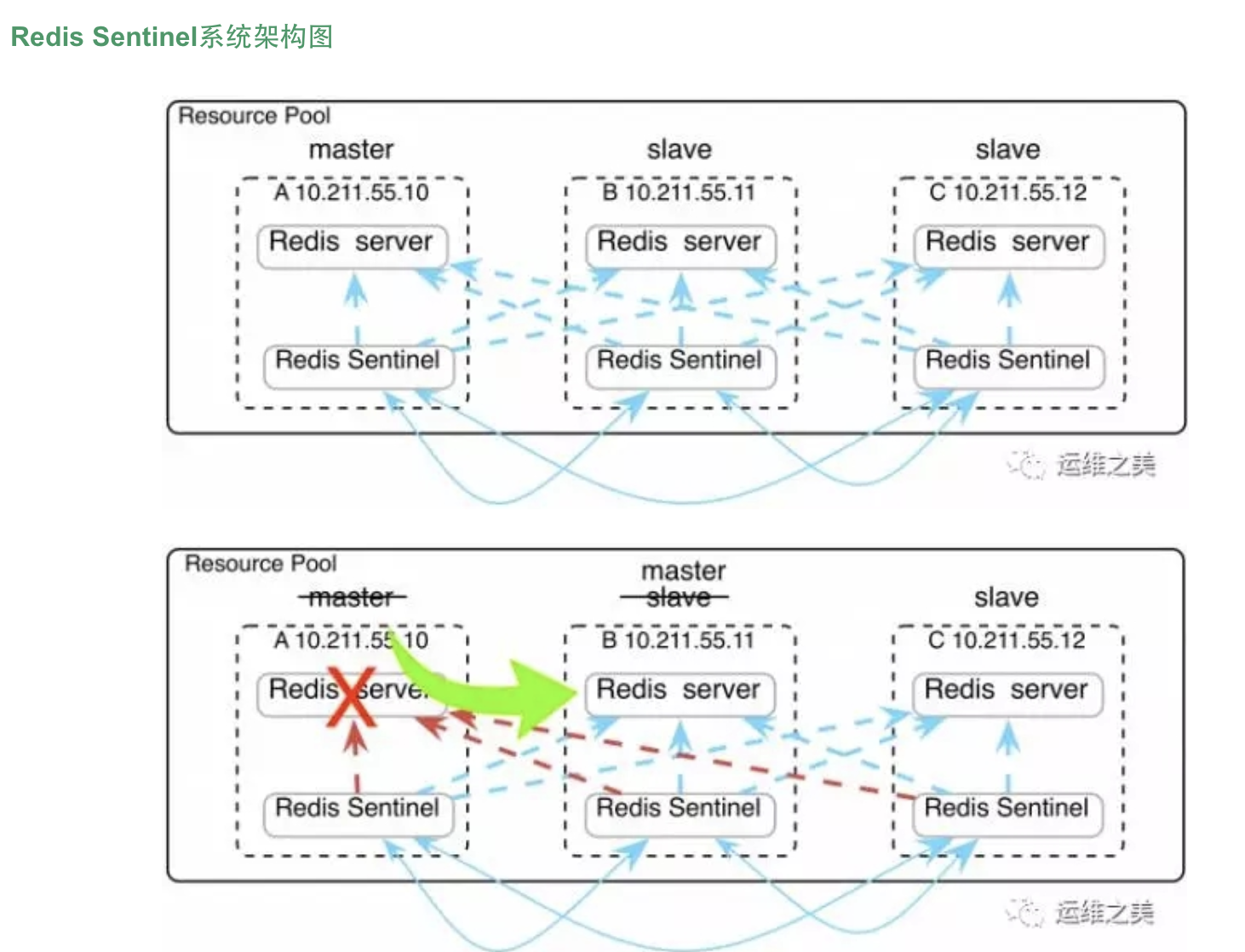
监控拓扑图
此时查看哨兵是否成功通信
[root@master ~]# redis-cli -p info sentinel
# Sentinel
sentinel_masters:
sentinel_tilt:
sentinel_running_scripts:
sentinel_scripts_queue_length:
sentinel_simulate_failure_flags:
master0:name=mymaster,status=ok,address=192.168.119.10:,slaves=,sentinels=3
#看到最后一条信息正确即成功了哨兵,哨兵主节点名字叫做mymaster,状态ok,监控地址是192.168.119.10:6379,有两个从节点,3个哨兵
redis高可用故障实验
大致思路
- 杀掉主节点的redis进程6379端口,观察从节点是否会进行新的master选举,进行切换
- 重新恢复旧的“master”节点,查看此时的redis身份
首先查看三个redis的进程状态
ps -ef|grep redis
检查三个节点的复制身份状态
第一个
[root@master tmp]# redis-cli -p info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:
第二个
[root@master tmp]# redis-cli -p info replication
# Replication
role:master
connected_slaves:
slave0:ip=127.0.0.1,port=,state=online,offset=,lag=
slave1:ip=127.0.0.1,port=,state=online,offset=,lag=
第三个
[root@master tmp]# redis-cli -p info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:
此时,干掉master!!!然后等待其他两个节点是否能自动被哨兵sentienl,切换为master节点
ps -ef|grep 6380 #干掉master进程
此时查看两个slave的状态
精髓就是查看一个参数
master_link_down_since_seconds:
稍等片刻之后,发现slave节点成为master节点!!
[root@master tmp]# redis-cli -p info replication
# Replication
role:master
connected_slaves:
slave0:ip=127.0.0.1,port=,state=online,offset=,lag=
大功告成!!开心!!!
redis-sentinel主从复制高可用的更多相关文章
- Redis Sentinel主从高可用方案
Redis Sentinel主从高可用方案 本文介绍一种通过Jed和Sentinel实现Redis集群(主从)的高可用方案,该方案需要使用Jedis2.2.2及以上版本(强制),Redis2.8及以上 ...
- Redis Sentinel实现高可用配置
一般情况下yum安装redis的启动目录在:”/usr/sbin” :配置目录在”/etc/redis/”在其目录下会有默认的redis.conf和redis-sentinel.conf redis高 ...
- redis-3.0.1 sentinel 主从高可用 详细配置
最近项目上线部署,要求redis作高可用,由于redis cluster还不是特别成熟,就选择了redis sentinel做高可用.redis本身有replication,实现主从备份.结合sent ...
- 使用Docker Compose部署基于Sentinel的高可用Redis集群
使用Docker Compose部署基于Sentinel的高可用Redis集群 https://yq.aliyun.com/articles/57953 Docker系列之(五):使用Docker C ...
- Redis入门到高可用(一)——初识Redis
一.Redis是什么 * 开源 * 基于键值的存储服务系统 * 支持多种数据结构 * 高性能,功能丰富 二.Redis特性 ♦️ 概述 * 速度快 * 支持持久化 * 支持多种数据结构 * 支持多种编 ...
- Redis主从配置及通过Keepalived实现Redis自动切换高可用
Redis主从配置及通过Keepalived实现Redis自动切换高可用 [日期:2014-07-23] 来源:Linux社区 作者:fuquanjun [字体:大 中 小] 一:环境介绍: M ...
- Redis如何实现高可用【主从复制+哨兵机制+keepalived】
实现redis高可用机制的一些方法: 保证redis高可用机制需要redis主从复制.redis持久化机制.哨兵机制.keepalived等的支持. 主从复制的作用:数据备份.读写分离.分布式集群.实 ...
- redis 之redis-sentinel主从复制高可用
一.redis主从复制背景问题 Redis主从复制可将主节点数据同步给从节点,从节点此时有两个作用: (1)一旦主节点宕机,从节点作为主节点的备份可以随时顶上来. (2)扩展主节点的读能力,分担主节点 ...
- Redis服务之高可用组件sentinel
前文我们了解了redis的常用数据类型相关命令的使用和说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13419690.html:今天我们来聊一下redis ...
- redis如何实现高可用【主从复制、哨兵机制】
实现redis高可用机制的一些方法: 保证redis高可用机制需要redis主从复制.redis持久化机制.哨兵机制.keepalived等的支持. 主从复制的作用:数据备份.读写分离.分布式集群.实 ...
随机推荐
- JavaScript获取及判断文件类型
一.获取文件后缀 <input type="file" name="addvedio" accept="video/*"/>注: ...
- windows将文件夹映射为虚拟磁盘
subst X: e:123 将e盘下的123文件夹映射为x盘,123的容量即x盘容量 subst X: /t 删除映射的x盘
- Zuul 网关路由
Zuul 网关路由 路由是微服务架构中不可或缺的一部分,例如:/api/user映射到user服务,/api/shop映射到shop服务. Zuul是一个基于JVM的路由和服务端的负载均衡器.Zuul ...
- 1333:【例2-2】Blah数集
1333:[例2-2]Blah数集 注意是数组,答案数组中不能有重复数字 q数组是存储答案的 代码: #include<iostream> #include<cstdio> # ...
- C++ 打印机设置
我在网上已不断看到一些网友关于自定义纸张打印的问题,基本上还没有较完美的解决方案,我在这里提供一个WindowsNT/2000/XP下的解决办法,供广大同仁参考.Windows9x/Me下也有解决办法 ...
- javax.el.PropertyNotFoundException: Property 'know_id' not found on type java.lang.String
今天通过Servlet明明查出来了结果,在跳转到页面时报这个异常.根据经验仔细核对了字段书写时,未发现错误. 耐心仔细检查之后发现el表达式的List集合写错了 <c:forEach items ...
- Python Redis 管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pi ...
- spool例子
set head offset echo offset feed offset heads offset pages 50000SET NEWPAGE NONEcolumn yesterday new ...
- [C++ Primer Plus] 第4章、复合类型(一)程序清单——指针new和delete
程序清单4.1 #include<iostream> using namespace std; void main(){ ]; yams[]=; yams[]=; yams[]=; ]={ ...
- 调用微信的扫一扫功能详解说明---(java 排坑版)
最近碰到了这么一个需求,说是在前端页面调用手机本地的相机,扫描二维码这么一个需求,对于我一个后端来说, 这实在是难,难于上青天,但是决不能说一个不字.我说可以使用微信的扫码工具吗,这样可以方便一点,. ...