Java容器解析系列(5) AbstractSequentialList LinkedList 详解
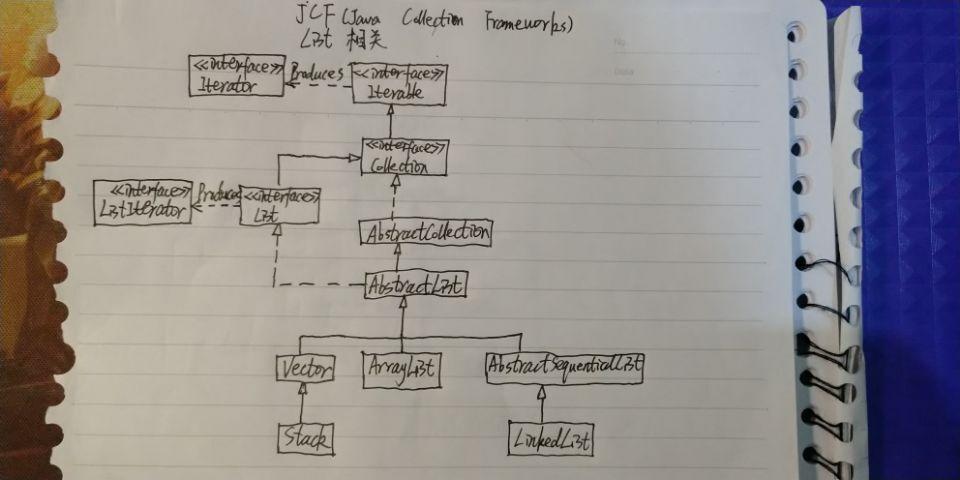
AbstractSequentialList为顺序访问的list提供了一个骨架实现,使实现顺序访问的list变得简单;
我们来看源码:
/**
AbstractSequentialList 继承自 AbstractList,是 List 接口的简化版实现。只支持按顺序访问,而不像 AbstractList 那样支持随机访问。
如果要支持随机访问,应该继承自AbstractList;
想要实现一个支持按次序访问的List的话,只需要继承该类并实现size()和listIterator()方法;
如果要实现的是不可修改的list,和listIterator()方法返回的 ListIterator 需要实现hasNext(), hasPrevious(), next(), previous(), 还有那几个 获取index 的方法;
如果要实现的是可修改的list,ListIterator还需要实现set()方法;
如果要实现的的list大小可变,ListIterator还需要实现add()和remove()方法;
* @since 1.2
*/
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
protected AbstractSequentialList() {}
public E get(int index) {
try {
return listIterator(index).next();
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E set(int index, E element) {
try {
ListIterator<E> e = listIterator(index);
E oldVal = e.next();
e.set(element);
return oldVal;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public void add(int index, E element) {
try {
listIterator(index).add(element);
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public E remove(int index) {
try {
ListIterator<E> e = listIterator(index);
E outCast = e.next();
e.remove();
return outCast;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
public boolean addAll(int index, Collection<? extends E> c) {
try {
boolean modified = false;
ListIterator<E> e1 = listIterator(index);
Iterator<? extends E> e2 = c.iterator();
while (e2.hasNext()) {
e1.add(e2.next());
modified = true;
}
return modified;
} catch (NoSuchElementException exc) {
throw new IndexOutOfBoundsException("Index: "+index);
}
}
// 这里通过调用listIterator()返回ListIterator
public Iterator<E> iterator() {
return listIterator();
}
public abstract ListIterator<E> listIterator(int index);
}
从上面源码可以看出:
- 所有在AbstractSequentialList默认实现的方法,内部都调用了listIterator()来实现(iterator()也是调用listIterator()来实现),并以其返回的ListIterator作为实现基础;
- 与AbstractList不同的是,AbstractSequentialList因为是顺序访问,所以其ListIterator内的方法实现不能像AbstractList那样通过add()/remove()/set()/get()/size()方法来实现(这样会导致效率极其低下),istIterator(int)为一个抽象方法,其子类必须提供其对应的ListIterator;
接下来我们把目光转到AbstractSequentialList的实现类之一-----LinkedList.
翻开原来的笔记,发现有一篇收藏博客对LinkedList讲解非常好( ̄□ ̄||),这里贴一下地址:
从源码角度彻底搞懂LinkedList
这篇博客把整个LinkedList源码都研究了一遍,但是其中有1点需要纠正:
- 插入和删除比较快(O(1)),查询则相对慢一些(O(n))
这里对于插入和删除的算法时间复杂度表述为O(1),这个可以是被广泛认为如此,其实并不正确.我们来看源码:
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
public void addFirst(E e) {
linkFirst(e);
}
public boolean add(E e) {
linkLast(e);
return true;
}
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
在链表的开始或结束位置进行添加或删除节点,其时间复杂度确实为O(1),但是,如果对中间的某个节点进行添加或删除呢?
// 时间复杂度O(n)
// 遍历查找指定位置的数据
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
add(int,E)和remove(int)方法都通过node(int)方法寻找元素,而node(int)方法的时间复杂度为O(n),也即查找指定index位置的元素的时间复杂度. 所以add(int,E)和remove(int)的时间复杂度也应该是O(n);
很多人认为链表插入和删除的算法时间复杂度为O(1),就是忽略了这个查找的过程;
OK,我们就可以得出结论
LinkedList在添加或删除元素时,如果不指定index(开始或结束位置)添加或删除节点,时间复杂度为O(1);如果指定index添加或删除元素,时间复杂度为O(n)
记得我们之前讲过的ArrayList的添加或删除的时间复杂度为O(n),其实和LinkedList的时间复杂度是一致的:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
// 如果在最后添加,那么这里根本不需要移动元素,时间复杂度为O(1)
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
// 移动index之后的数据,该步骤的时间复杂度为O(n)
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
// 如果在最后删除,那么这里根本不需要移动元素,时间复杂度为O(1)
if (numMoved > 0)
// 移动index之后的数据,该步骤的时间复杂度为O(n)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
那么,难道这两者在添加和删除元素的时候就没有什么区别了吗?当然不是:
1. LinkedList添加和删除时间复杂度为O(n),是因为查找指定位置元素的时间复杂度为O(n);
2. ArrayList添加和删除时间复杂度为O(n),是因为移动元素位置的时间复杂度为O(n);
3. 一次移动元素位置比一次元素查看更加耗时;
4. 在LinkedList.ListIterator遍历过程中,因为已经知道了前一个元素和后一个元素,并不需要查询元素位置,此时间复杂度为O(1);
5. 在ArrayList.ListIterator遍历过程中,时间复杂度仍为O(n);
- LinkedList与ArrayList的比较:
ArrayList
1. 基于数组,ArrayList 获取指定位置元素的时间复杂度是O(1);
2. 但是添加、删除元素时,该元素后面的所有元素都要移动,所以添加/删除数据效率不高;
3. 每次达到阈值需要扩容,这个操作比较影响效率。
LinkedList
1. 基于双端链表,添加/删除元素只会影响周围的两个节点,开销比ArrayList低;
2. 只能顺序遍历,无法按照索引获得元素,因此查询效率不高;(get(int)方法内部也是顺序遍历实现)
3. 没有固定容量,不需要扩容;
4. 需要更多的内存,LinkedList 每个节点中需要多存储前后节点的指针,占用空间更多些。
因此,在表需要频繁地添加和删除元素时,还是应该使用LinkedList.如果更多的是按照索引获得元素,应该使用ArrayList
关于按照索引获得元素的效率比较,可以查看博客:
ArrayList遍历方式以及效率比较
建议调试其中的代码,修改LinkedList运行次数和大小,你会为结果感到惊讶
Java容器解析系列(5) AbstractSequentialList LinkedList 详解的更多相关文章
- Java容器解析系列(10) Map AbstractMap 详解
前面介绍了List和Queue相关源码,这篇开始,我们先来学习一种java集合中的除Collection外的另一个分支------Map,这一分支的类图结构如下: 这里为什么不先介绍Set相关:因为很 ...
- Java容器解析系列(0) 开篇
最近刚好学习完成数据结构与算法相关内容: Data-Structures-and-Algorithm-Analysis 想结合Java中的容器类加深一下理解,因为之前对Java的容器类理解不是很深刻, ...
- Java容器解析系列(11) HashMap 详解
本篇我们来介绍一个最常用的Map结构--HashMap 关于HashMap,关于其基本原理,网上对其进行讲解的博客非常多,且很多都写的比较好,所以.... 这里直接贴上地址: 关于hash算法: Ha ...
- Java容器解析系列(7) ArrayDeque 详解
ArrayDeque,从名字上就可以看出来,其是通过数组实现的双端队列,我们先来看其源码: /** 有自动扩容机制; 不是线程安全的; 不允许添加null; 作为栈使用时比java.util.Stac ...
- Java容器解析系列(6) Queue Deque AbstractQueue 详解
首先我们来看一下Queue接口: /** * @since 1.5 */ public interface Queue<E> extends Collection<E> { / ...
- Java容器解析系列(4) ArrayList Vector Stack 详解
ArrayList 这里关于ArrayList本来都读了一遍源码,并且写了一些了,突然在原来的笔记里面发现了收藏的有相关博客,大致看了一下,这些就是我要写的(╹▽╹),而且估计我还写不到博主的水平,这 ...
- Java容器解析系列(3) List AbstractList ListIterator RandomAccess fail-fast机制 详解
做为数据结构学习的常规,肯定是先学习线性表,也就是Java中的List,开始 Java中List相关的类关系图如下: 此篇作为对Java中相关类的开篇.从上图中可以看出,List和AbstractLi ...
- Java容器解析系列(13) WeakHashMap详解
关于WeakHashMap其实没有太多可说的,其与HashMap大致相同,区别就在于: 对每个key的引用方式为弱引用; 关于java4种引用方式,参考java Reference 网上很多说 弱引用 ...
- Java容器解析系列(9) PrioriyQueue详解
PriorityQueue:优先级队列; 在介绍该类之前,我们需要先了解一种数据结构--堆,在有些书上也直接称之为优先队列: 堆(Heap)是是具有下列性质的完全二叉树:每个结点的值都 >= 其 ...
随机推荐
- DRF之解析器源码解析
解析器 RESTful一种API的命名风格,主要因为前后端分离开发出现前后端分离: 用户访问静态文件的服务器,数据全部由ajax请求给到 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己 ...
- window安装ab压力测试并使用
ab是Apache HTTP server benchmarking tool的缩写,可以用以测试HTTP请求的服务器性能,也是业界比较流行和简单易用的一种压力测试工具包 1.下载ab工具 进入apa ...
- 算法(第四版)C# 习题题解——1.2
写在前面 整个项目都托管在了 Github 上:https://github.com/ikesnowy/Algorithms-4th-Edition-in-Csharp 这一节内容可能会用到的库文件有 ...
- while(scanf("%d %d",&a,&b)!=EOF)
scanf("%d %d",&a,&b)返回输入的数据和格式字符串中匹配次数.当dos或windows中输入ctrl+z(模拟文件结束符EOF)时,scanf返回E ...
- python 运算/赋值/循环
python3 中只有一个InputPython2 中的raw_input与python3中的input一模一样python3中input输出字符串类型int,float=数字类型//地板除 % 取余 ...
- 09.vue中样式-style
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 要想成为前端大神,那些你不得不知晓的web前端命名规范。
一.Web语义化 1.1 H5的语义化 对于经验资深的前端er,在给web布局时,相信都会很注重标签和命名的规范.尤其是随着html5的普及发展,更是把web前端语义化推向一个新的台阶上.比如html ...
- TestNG详解(单元测试框架)
一.TestNG的优点 1.1 漂亮的HTML格式测试报告 1.2 支持并发测试 1.3 参数化测试更简单 1.4 支持输出日志 1.5 支持更多功能的注解 二.编写TestNG测试用例的步骤 2.1 ...
- 运行Python出错,提示“丢失api-ms-win-crt-runtime-l1-1-0.dll”
运行python时出错,提示“丢失api-ms-win-crt-runtime-l1-1-0.dll”, 上网搜了一下说是本地api-ms-win-crt-runtime-l1-1-0.dll 版本过 ...
- 《HTTP 权威指南》笔记:第十五章 实体与编码
 如果把 「HTTP 报文」想象为因特网货运系统的「箱子」,那么「HTTP 实体」就是报文中的实际的「货物」. 其中,实体又包含了「实体首部」 和 「实体主体」,实体首部用于描述各种参数,实体主体就 ...