word2vec skip-gram系列2
Word2Vec的CBOW模型和Skip-gram模型
故事先从NNLM模型说起,网络结构图如下图所示,接下来先具体阐述下这个网络,
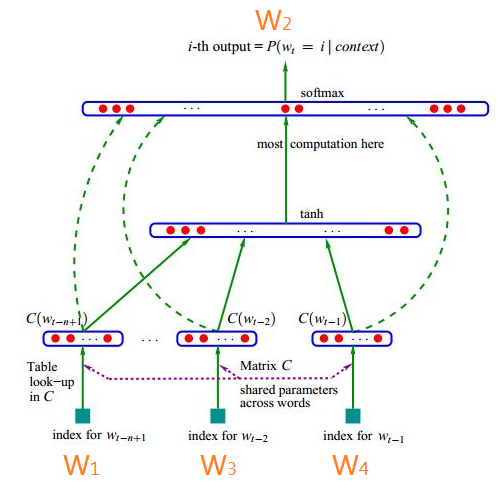
输入是个one-hot representation的向量。比如你的词表中有十万个词,那么输入的每个word(比如这里的W1,W3,W4)都是one-hot的表达,也就是1*10W的这样的一个维度的向量。我们要做的事情就是把这种稀疏的向量表达成稠密的向量。C是10W(10万的意思)个词的列向量一列一列组起来的一个矩阵。如果你的词表是10W个词,你希望你的稠密向量是300*1维度的,那么你就会有10W个300维的列向量,把这些列向量组合成一个矩阵C。如下图所示:
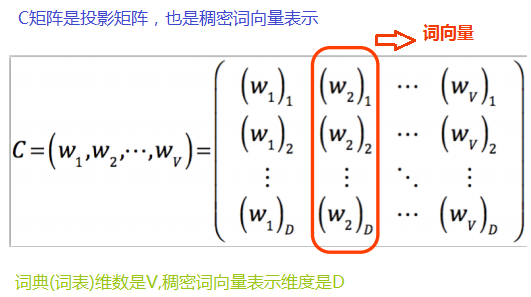
那么在我们的例子中,V的值就是10W,D的值就是300。
其中这一层,在学术上叫做project layer,也就是投射层,或者叫做投影层。C的初始化是采用随机初始化(比如你可以用高斯初始化),这个没有关系,因为我们最终会通过学习文本,把这个矩阵的值学习到。
这个C矩阵就是300*10W的矩阵,C矩阵与one-hot的1*10W这样的向量的转置相乘。也就是C矩阵与10W*1这样的向量相乘的结果是300*1的维度结果。(也就是图中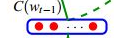 是300*1这样的维度向量)相当于从C矩阵取了某一列(这个可能你有点不大理解,我解释下,就是假如hello的one-hot表示是[00100....000],那么实际上就是把C矩阵的第三列取出来)。所以我们称C矩阵是个投影矩阵就是这么个由来。
是300*1这样的维度向量)相当于从C矩阵取了某一列(这个可能你有点不大理解,我解释下,就是假如hello的one-hot表示是[00100....000],那么实际上就是把C矩阵的第三列取出来)。所以我们称C矩阵是个投影矩阵就是这么个由来。
说明下其中300这个数是怎么定的,一般在工业应用,大语料的情况下我们认为300至500这样的取值才有比较好的意义或者说效果,不然你表现不出稠密向量他们之间的细微差别。这里的10W是我的词表的词的数量。
词W1,词W3,词W4,通过矩阵C,得到了3个300*1的稠密向量。那么Bangio大神做的事情就是把这三个稠密向量拼接(concat)在了一起做成了一个900*1维度的向量(也就是图中 这个向量)。
这个向量)。
这个1*900维度的向量是全连接的如下的一个隐藏层神经元(如果这个隐藏层比如我设的是500个神经元,那么其中的权重数量就是900乘以500这么多个权重。),如下图所示,连接的是下图的连接,

也就是说这两层之间有个隐藏层(图中未画出),神经元数目是500个。而且这个隐藏层是全连接的softmax输出层。因为我们词表的词的数目是10W
,也就是一个1*10W的维度的概率向量。所以隐藏层与softmax层的全连接就会有500*10W这么多个权重。
这里要注意的是softmax这一层的神经元数量和你的词表的词的数量是一样的,在这里就是有10W。
如果w1、w3、w4是:“我”,“北京”,“天安门”,那么我希望从softmax层训练到的是“爱”(这也就是标签)。Softmax就是做的这样一个事情,就是10W个输出,输出的是每个词的的概率。也就是softmax层出来后你获得的是1*10w这样维度的概率向量。我只需要“爱”的概率是所有10w个概率里面最大的就可以了。所以softmax就是概率模型的一个线性的分类器。置于如何优化的话,是这样的,”爱”这个词的one-hot向量是[0,0,0......1....0,0,0],那么这个softmax出来的1*10w的概率向量就跟这个“爱”的one-hot向量去做交叉熵损失。知道了损失(就是loss)然后就可以用SGD(随机梯度下降)方式去做优化。所以就可以获得所有层次的权重w,而矩阵C这一层是我们真正需要获得的词向量。也就是说矩阵C是由词向量组成的矩阵。当你把文本中的所有的词都用宽度为4的窗口扫一遍之后,你就可以获得矩阵C里面各个元素的数值了。一旦知道C矩阵的里面各个元素的数值,那么你各个词向量也就知道了。
有同学问,10w*300这个词向量矩阵是个权重,权重的话我们在人工神经网络中可以用BP算法,把交叉熵损失对于这个权重的梯度求出来(用的SGD方式优化)。还有说明下,交叉熵损失有几种理解方式,最大释然的话是其中一种理解方式,你还可以理解成两个概率向量的KL距离。因为one-hot就一个位置是1,那两个向量做完乘法,就等价于使那个位置的概率最大嘛。
总结下NNLM网络,更详细的结构图(之前的图没有画出隐藏层)是如下所示:
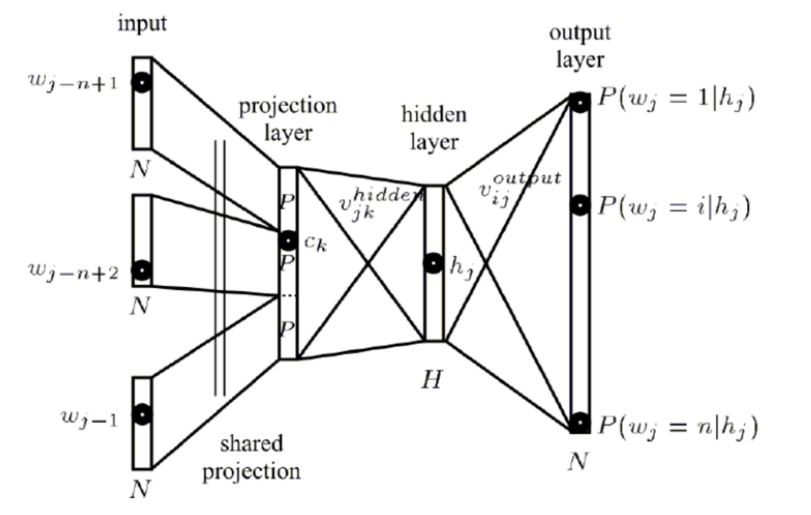
那这样的一个网络结构,其计算的复杂度是: N*D + N*D*H + H*V ,这样的一个计算复杂度是太高了。所以我们需要寻求更加高效简介,计算复杂度大大减低的网络结构。于是我们介绍word2vec的CBOW和Skip-gram模型。我们先来介绍CBOW模型。
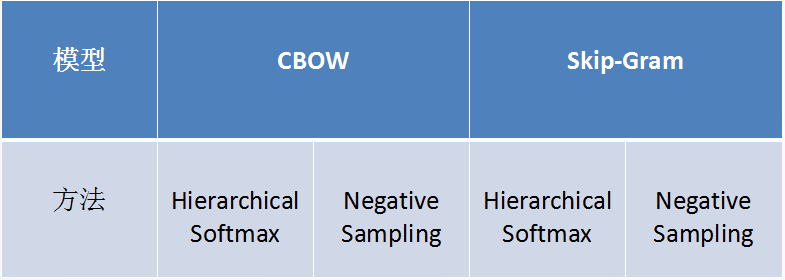
word2vec有两个模型,分别是CBOW和Skip-gram模型。这两个模型又都有两种优化方法。分别是Hierarchical Softmax与Negative Sampling 。所以实现word2vec有四种方式:
2013年末,Google发布的word2vec引起了一帮人的热捧。在大量赞叹word2vec的微博或者短文中,几乎都认为它是深度学习在自然语言领域的一项了不起的应用,各种欢呼“深度学习在自然语言领域开始发力了”。但实际上,简单看看代码就知道它实际上只是一个三层网络,压根算不上所谓的深层网络,学习过程也很简单,并未用太玄妙的东西,以至于在了解完整以后对它的简单叹为观止。
首先,它的结构就是一个三层网络——输入层、隐层(也可称为映射层),输出层。
INPUT层输入进去的4个300*1的词向量(这里我们假设词向量的维度是1*300维度的,而且词向量都是随机初始化的,经过训练后其值会变化),然后经过SUM后还是300*1的稠密向量,然后直接全连接到OUTPUT为10W(假设我的词表是10W个词) 的softmax输出了。
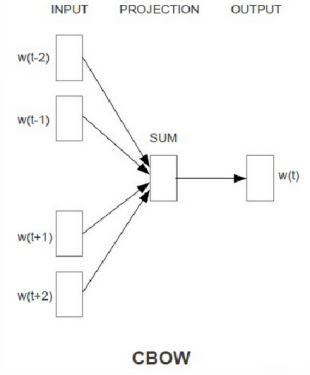
比如我是四个词的词向量,做一个SUM,最后一步是有10万,我们觉得10万太多了,因此有两种处理方式:一种是层次化的softmax,一种是负例采样。
我们先来学习下CBOW的层面化的softmax。
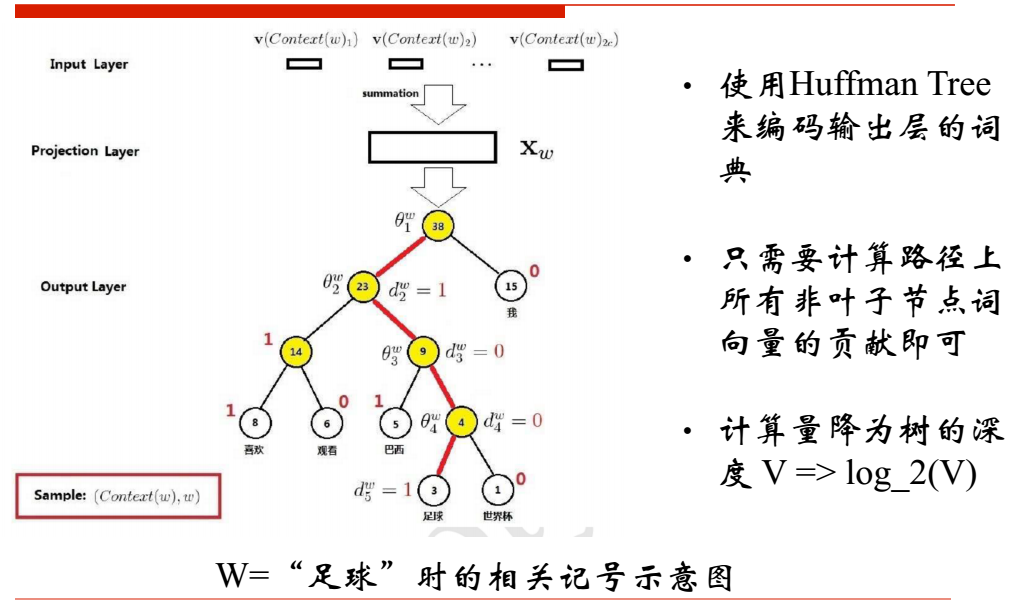
其中输入层: 输入的是词的上下文词的词向量,比如"我喜欢观看巴西足球世界杯",那么输入的就是“我” “喜欢” “观看” “巴西” 这四个词的词向量(词向量是1*300维的,而且是随机初始化的,当你遍历完整个文档的过程中词向量的值在变化,当宽度为4的窗口遍历完整个训练文档,词向量也就定下来了。),要预测的就是“足球”,这INPUT的四个词的词向量经过SUM之后还是1*300维度的词向量。
其中投影层: 将输入层的2c个向量做求和累加,即 
其中输出层: 输出层对应一棵二叉树,它是以语料中出现过的词当叶子结点,以各词在语料中出现的次数当权值构造出来的Huffman树,
在这棵Huffman树种,叶子结点共N个(词表中词的数目),分别对应词典D中的词,非叶子结点N-1个
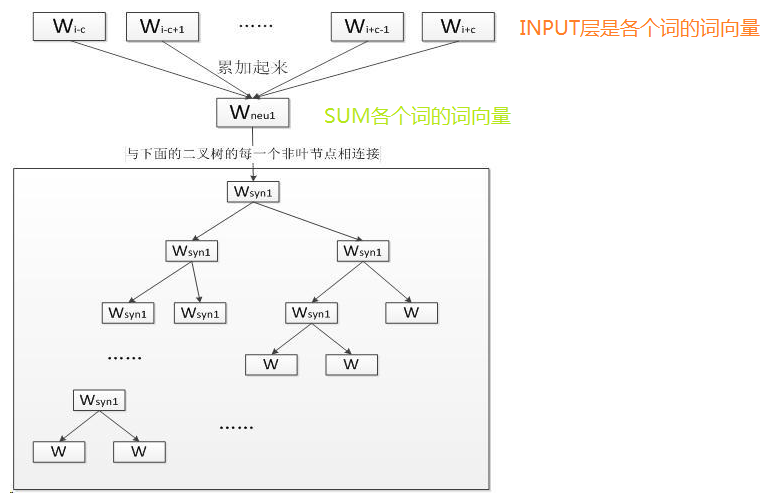
CBOW模型的层次softmax网络示意图
按照上图的结构,如果把上图中的 与哈夫曼树的非叶子节点如何相连的细节画出来的话,那就是如下面所示:
与哈夫曼树的非叶子节点如何相连的细节画出来的话,那就是如下面所示:
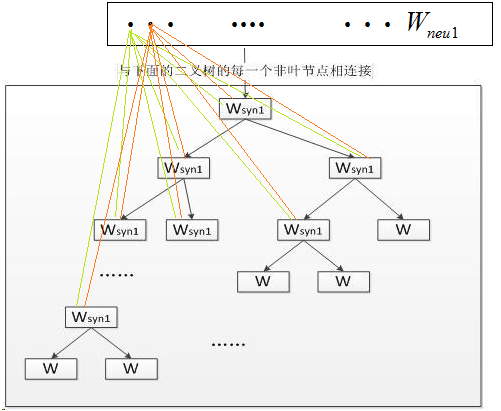
以"我喜欢观看巴西足球世界杯"为例,分词后有6个词,按照刚才的结构我需要展开成6个节点。得到一个长度为6的概率向量。平铺开6的话太麻烦了。那计算机里面有个哈夫曼树,根据 “我” “喜欢”“观看”“巴西”“足球”“世界杯”出现的频次把其编码为一棵哈夫曼树。而对于这棵树,当你在做决策的时候只能往左走或者往右走。

正类的概率是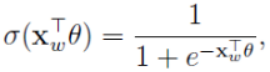
输入层读入窗口内的词,将它们的向量(K维,初始随机)加和在一起,形成隐藏层K个节点。输出层是一个巨大的二叉树,叶节点代表语料里所有的词(语料含有V个独立的词,则二叉树有|V|个叶节点)。而这整颗二叉树构建的算法就是Huffman树。这样,对于叶节点的每一个词,就会有一个全局唯一的编码,形如”010011″。我们可以记左子树为1,右子树为0。接下来,隐层的每一个节点都会跟二叉树的内节点有连边,于是对于二叉树的每一个内节点都会有K条连边,每条边上也会有权值。
这样,整体的结构就清晰了。在训练阶段,当给定一个上下文,要预测后面的词(Wn)的时候(word2vec的CBOW和Skip-gram都不是预测后面的词,都是在中间的词上做文章,但是本文这么写并不影响理解),实际上我们知道要的是哪个词(Wn),而Wn是肯定存在于二叉树的叶子节点的,因此它必然有一个二进制编号,如”010011″,那么接下来我们就从二叉树的根节点一个个地去便利,而这里的目标就是预测这个词的二进制编号的每一位!即对于给定的上下文,我们的目标是使得预测词的二进制编码概率最大。形象地说,我们希望在根节点,词向量和与根节点相连经过logistic计算得到的概率尽量接近0(即预测目标是bit=1);在第二层,希望其bit是1,即概率尽量接近1……这么一直下去,我们把一路上计算得到的概率相乘,即得到目标词Wn在当前网络下的概率(P(Wn)),那么对于当前这个sample的残差就是1-P(Wn)。于是就可以SGD优化各种权值了。
那么hs(hierarchical softmax)如何保证叶节点输出的概率值(即我们一路沿二进制编号乘下去的概率)是归一化的呢(否则,所谓的残差1-P(Wn)就没什么意义了)?这点其实很简单,请看下图:

hierarchical softmax说明
从根节点开始,对于一个sample而言,目标词是W2,二进制编码是”110″。我们在根节点计算得到它的第一位是’1’的概率是P,那么它第一位是’0’的概率就是1-P;在左子树里,第二位是”1″的概率是P’,那么第二位是”0″的概率就是1-P’,而在右子树里,第二位是”1″的概率是P”,那么第二位是”0″的概率就是1-P”;第三位亦如此。为方便表示记,我们只写到第二层。这样,在第二层,整个概率之和就是
(P*(P’) + P*(1-P’)) + ((1-P)*(P”) + (1-P)*(1-P”)) = P + (1-P) = 1
即按照目标词的二进制编码计算到最后的概率值就是归一化的,这也是为啥它被称作hierarchical softmax的原因。
如果没有使用这种二叉树,而是直接从隐层直接计算每一个输出的概率——即传统的softmax,就需要对|V|中的每一个词都算一遍,这个过程时间复杂度是O(|V|)的。而使用了二叉树(如word2vec中的Huffman树),其时间复杂度就降到了O(log2(|V|)),速度大大地加快了。
不过虽然hierarchical softmax一般被认为只是用于加速,但是仍然可以感性地理解一下为啥它会奏效:二叉树里面的每一个内节点实际上是一种隐含概念的分类器(二元分类器,因为二进制编码就是0/1),它的输出值的大小预示着当前上下文能够表达该隐含概念的概率,而一个词的编码实际上是一堆隐含概念的表达(注意,这个隐含概念的表达和词向量的维度所表达的隐含概念是不一样的)。我们的目标就在于找到这些当前上下文对于这些概念分类的最准确的那个表达(即目标词向量)。由于概念之间实际上是有互斥关系的(二叉树保证),即在根节点如果是”1″,即可以表达某一概念,那么该上下文是绝对不会再有表达根节点是”0″的其他情况的概念了,因此就不需要继续考虑根节点是”0″的情况了。因此,整个hierarchical softmax可以被看作完全不同于传统softmax的一套。
word2vec skip-gram系列2的更多相关文章
- Word2vec的Skip-Gram 系列1
转自雷锋网的一篇很棒的文章,写的通俗易懂.自己消化学习了.原文地址是 https://www.leiphone.com/news/201706/PamWKpfRFEI42McI.html 这次的分享主 ...
- 利用Tensorflow进行自然语言处理(NLP)系列之二高级Word2Vec
本篇也同步笔者另一博客上(https://blog.csdn.net/qq_37608890/article/details/81530542) 一.概述 在上一篇中,我们介绍了Word2Vec即词向 ...
- Paddle Graph Learning (PGL)图学习之图游走类模型[系列四]
Paddle Graph Learning (PGL)图学习之图游走类模型[系列四] 更多详情参考:Paddle Graph Learning 图学习之图游走类模型[系列四] https://aist ...
- Tensorflow 的Word2vec demo解析
简单demo的代码路径在tensorflow\tensorflow\g3doc\tutorials\word2vec\word2vec_basic.py Sikp gram方式的model思路 htt ...
- Word2Vec总结
摘要: 1.算法概述 2.算法要点与推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合 内容: 1.算法概述 Word2Vec是一个可以将语言中的字词转换为向量表达(Vecto ...
- DeepNLP的核心关键/NLP词的表示方法类型/NLP语言模型 /词的分布式表示/word embedding/word2vec
DeepNLP的核心关键/NLP语言模型 /word embedding/word2vec Indexing: 〇.序 一.DeepNLP的核心关键:语言表示(Representation) 二.NL ...
- Word2vec 理解
1.有DNN做的word2vec,取隐藏层到softmax层的权重为词向量,softmax层的叶子节点数为词汇表大小 2-3的最开始的词向量是随机初始化的 2.哈夫曼树:左边走 sigmoid(当前节 ...
- word2vec原理
最原始的是NNLM,然后对其改进,有了后面的层次softmax和skip gram 层次softmax:去掉了隐藏层,后面加了huffuman树,concat的映射层也变成了sum skip gram ...
- word2vec学习 spark版
参考资料: http://ir.dlut.edu.cn/NewsShow.aspx?ID=291 http://www.douban.com/note/298095260/ http://machin ...
- word2vec的Java源码【转】
一.核心代码 word2vec.java package com.ansj.vec; import java.io.*; import java.lang.reflect.Array; import ...
随机推荐
- JS高级程序设计2
面向对象 ,基本模式.对象字面量模式.工厂模式.构造函数模式.原型模式.组合构造函数和原型模式.其他模式见电子书:动态原型模式.寄生构造函数模式(不推荐).稳妥构造函数模式(要求安全的环境,不使用ne ...
- Redis-Sentinel 哨兵
为什么需要哨兵? 一旦主节点宕机,那么需要人为修改所有应用方的主节点地址(改为新的master地址),还需要命令所有从节点复制新的主节点 那么这个问题,redis-sentinel就可以解决了 什么是 ...
- Hadoop Avro支持多输入AvroMultipleInputs
Avro 提供了1.x版本的AvroMultipleInputs,但是不支持2.x API版本,因此修改对应代码,增加对hadoop 2.x API版本的的支持 代码放在https://github. ...
- request.user哪里来的?
1.登录认证(auth认证登录后login后设置了session等信息包含用户的pk) >>>>> 2.用户再次请求登录的时候,通过 ...
- 大数据——hbase
进入hbase hbase shell 部分命令清单 查询服务器状态 status 查询hbase版本 version 1. 创建一个表 create 'table1', 'tab1_id', ...
- ibatis的queyrForList和queryForMap区别
https://blog.csdn.net/z69183787/article/details/47360825 https://blog.csdn.net/zyq527758142/article/ ...
- sentinel-dashboard安装、运行(ubuntu)
下载页面https://github.com/alibaba/Sentinel/releases wget -P /opt/downloads https://github.com/alibaba/S ...
- K线图
1.程序 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <titl ...
- day33 网络编程之线程,并发以及selectors模块io多路复用
io多路复用 selectors模块 概要: 并发编程需要掌握的知识点: 开启进程/线程 生产者消费者模型!!! GIL全局解释器锁(进程与线程的区别和应用场景) 进程池线程池 IO模型(理论) 1 ...
- Mybatis if test 中int integer判断非空的坑
Mybatis 中,alarmType 是int类型.如果alarmType 为0的话,条件判断返回结果为false,其它值的话,返回true. 1 <if test="alarmTy ...