Kibana简介及下载安装
现在你已经安装了Kibana,现在你一步步通过本教程快速获取Kibana核心功能的实践经验。学习完本教程,你将:
1.加载案例数据到你安装的Elasticsearch中
2. 定义至少一个索引匹配模式
3.使用Discover功能探索你的数据
4.建立一个visualization图形化地展示你的数据
5.把许多visualization汇编组装成一个Dashboard
本段内容假设你已经安装好了Kibana和Elasticsearch,并且Kibana连接到了Elasticsearch。
视频教程也可获取
High-level Kibana 4 introduction, pie charts
Data discovery, bar charts, and line charts
Embedding Kibana 4 visualizations
在你开始之前:加载案例数据
本段教程依赖如下数据集:
1. 莎士比亚的所有著作,合适地解析成了各个字段:shakespeare.json。
2. 随机生成的虚构账号数据:accounts.json
3. 随机生成的日志文件:logs.jsonl
以上数据可在这里下载
莎士比亚数据集由如下数据格式组织
- {
- "line_id": INT,
- "play_name": "String",
- "speech_number": INT,
- "line_number": "String",
- "speaker": "String",
- "text_entry": "String",
- }
账户数据集由如下数据格式组织
- {
- "account_number": INT,
- "balance": INT,
- "firstname": "String",
- "lastname": "String",
- "age": INT,
- "gender": "M or F",
- "address": "String",
- "employer": "String",
- "email": "String",
- "city": "String",
- "state": "String"
- }
日志数据有几十个不同的字段,但是在教程中关注的字段如下:
- {
- "memory": INT,
- "geo.coordinates": "geo_point"
- "@timestamp": "date"
- }
在导入莎士比亚数据集之前,我们需要为各个字段建立一个映射。映射把索引里的文档划分成逻辑组,指明字段的特征,如字段是否可被搜索、是否被标记、是否能被拆分成多个文字等。
使用以下命令为莎士比亚数据集建立一个映射。
- curl -XPUT http://localhost:9200/shakespeare -d '
- {
- "mappings" : {
- "_default_" : {
- "properties" : {
- "speaker" : {"type": "string", "index" : "not_analyzed" },
- "play_name" : {"type": "string", "index" : "not_analyzed" },
- "line_id" : { "type" : "integer" },
- "speech_number" : { "type" : "integer" }
- }
- }
- }
- }
- ';
这个映射指明了数据集的如下特征:
1. speaker字段是一个字符串,并且不被分析。这个字段的字符串被视为一个单元,即时字段值有多个文字。
2.play_name同样符合上述特征。
3.line_id和speech_number是一个整数。
日志数据需要一个映射表明地理位置的经纬度,通过在那些字段使用一个geo_point类型。
使用以下命令为日志数据建立一个geo_point映射。
- curl -XPUT http://localhost:9200/logstash-2015.05.18 -d '
- {
- "mappings": {
- "log": {
- "properties": {
- "geo": {
- "properties": {
- "coordinates": {
- "type": "geo_point"
- }
- }
- }
- }
- }
- }
- }
- ';
- curl -XPUT http://localhost:9200/logstash-2015.05.19 -d '
- {
- "mappings": {
- "log": {
- "properties": {
- "geo": {
- "properties": {
- "coordinates": {
- "type": "geo_point"
- }
- }
- }
- }
- }
- }
- }
- ';
- curl -XPUT http://localhost:9200/logstash-2015.05.20 -d '
- {
- "mappings": {
- "log": {
- "properties": {
- "geo": {
- "properties": {
- "coordinates": {
- "type": "geo_point"
- }
- }
- }
- }
- }
- }
- }
- ';
那些账号数据不需要任何映射,所以这个时候我们使用Elasticsearch的批量导入API输入数据,使用如下命令:
- curl -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
- curl -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
- curl -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl
这些命令将会花费一段时间来执行,视可利用计算资源而定。
使用如下命令验证成功导入:
curl 'localhost:9200/_cat/indices?v'
你将会看到输出如下类似的信息
- health status index pri rep docs.count docs.deleted store.size pri.store.size
- yellow open bank 5 1 1000 0 418.2kb 418.2kb
- yellow open shakespeare 5 1 111396 0 17.6mb 17.6mb
- yellow open logstash-2015.05.18 5 1 4631 0 15.6mb 15.6mb
- yellow open logstash-2015.05.19 5 1 4624 0 15.7mb 15.7mb
- yellow open logstash-2015.05.20 5 1 4750 0 16.4mb 16.4mb
1. 定义你的索引模式匹配
每一个数据集导入到Elasticsearch后会有一个索引匹配模式,在上段内容莎士比亚数据集有一个索引名称为shakespeare,账户数据集的索引名称为bank。一个索引匹配模式就是一个字符串包含可选的通配符,它能匹配多个索引。比如,在常用的日志案例中,一个典型的索引名称包含MM-DD-YYYY格式的日期,因此一个5月的索引匹配模式可能是这样:logstash-2015.05*。
在本教程中任何匹配模式匹配到我们导入的索引将会起作用。打开一个浏览器,访问localhostL:5601,点击Setting页面,然后点击indices标签,点击Add New按钮,定义一个新的模式匹配。两个数据集——莎士比亚剧和虚构的账号不包含时间系列的数据,确保Index contains time-based events复选框没有勾选,当你在为这些数据集创建模式匹配的时候。指定shaks*为莎士比亚数据集的一个模式匹配,然后点击Create按钮定义一个模式匹配,接着定义一个ba*的模式匹配。
Logstash数据集包含时间系列的数据,所以在点击Add New按钮创建完模式匹配后,确保Index contains time-based events复选框勾选,并在Time-field name下拉列表中选择@timestamp字段。
发现你的数据
点击Discover页面展示Kibana的数据发现功能。
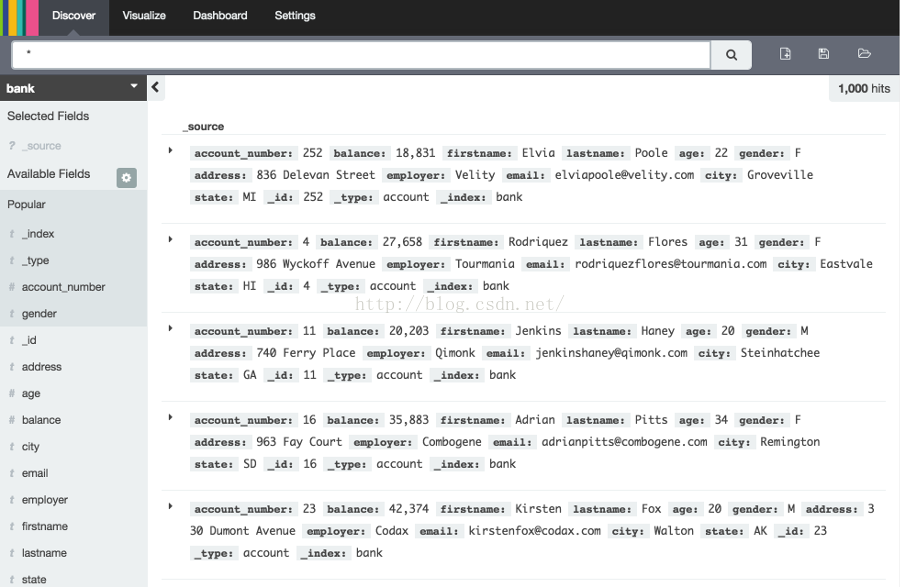
在标签页面的正下方,有一个查询框用于搜索你的数据。搜索需要一个特定的查询语法,它们能让你创建自己的搜索,点击查询框右边的按钮能保存这些搜索。在查询框的下方,当前的索引匹配模式显示在一个下拉选中,选择下拉选以改变匹配模式。你能用字段名和你感兴趣的值构建一个搜索,数字类型的数据可使用比较操作符比如>、<、=等,你可使用AND、OR、 NOT逻辑符连接元素,必须是大写。
试着选择ba*模式匹配,然后把下面的查询放到查询框
account_number:<100 AND balance:>47500
搜索返回所有账户号码0到99且薪水超过4,7500的账户。如果你使用相关的案例数据,将会返回5条数据:账户号码8,32,78,85和97。
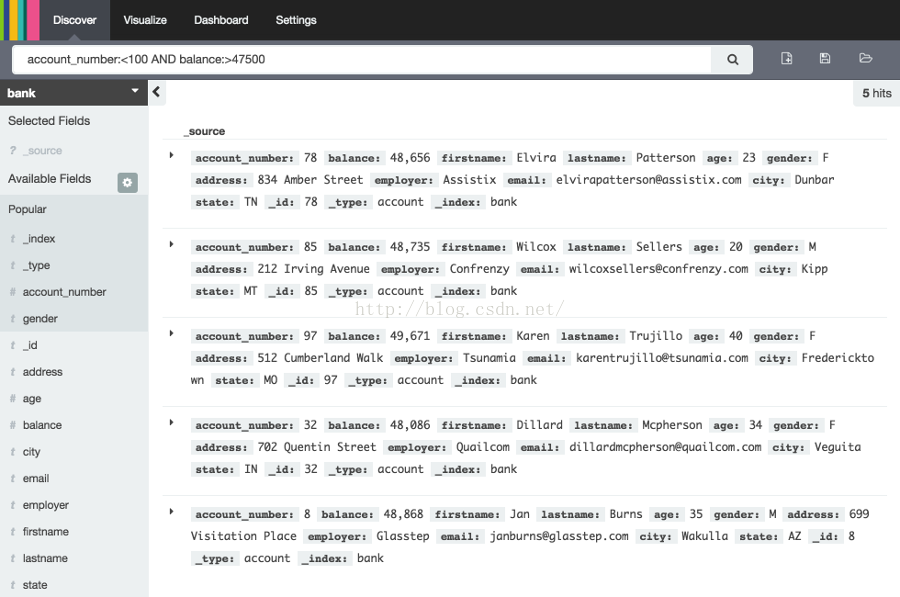
为了窄化显示某些感兴趣的字段,高亮索引模式匹配下面的列表中的字段,然后点击Add按钮。在这个例子中,注意怎么实现的,添加一个account_number字段后改变界面显示从5条记录的完整文本到一个只有账户号码的简单列表。

2. 数据可视化:不只是发现数据
Visualize页面的可视化工具能使你用好几种不同的方式展示你数据集的很多方面。
点击Visualize页面开始
点击Pie chart,然后点击from a new search,选择ba*索引匹配模式。
可视化依赖Elasticsearch聚合的两种类型:量聚合和刻度聚合。量聚合根据你指定的标准整理数据,比如,在我们的账户数据集中,我们可以建立一个账户薪水的范围,然后显示落在每个薪水范围的总比率。界面显示出一个完整的饼,因为我们现在还没有指定任何量值。

在Select buckets type下拉列表中,选择Split Slices,然后在Aggregation下拉列表中选择Range选项,在字段下拉列表中选择balance字段,点击Add Range按钮4次把区间增加到6个,输入一下区间。
- 0 999
- 1000 2999
- 3000 6999
- 7000 14999
- 15000 30999
- 31000 50000
点击应用按钮
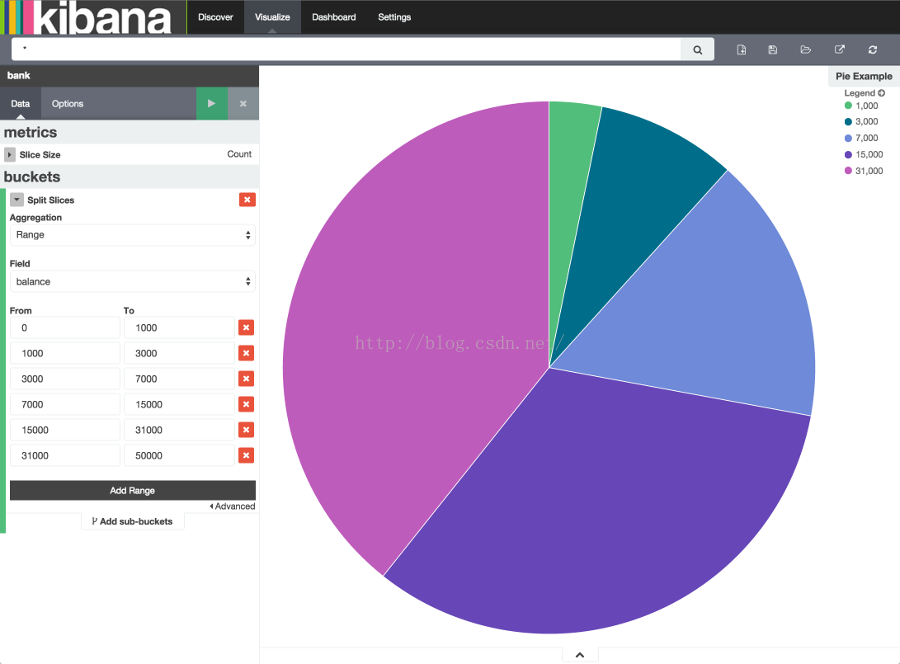
图表显示出这1000个账户落在不同薪水范围的比率。为了看数据的另一个维度,我们要添加另一个量聚合。我们可以更进一步地把每个区间依据薪水所有者的年龄拆分。在下面点击Add sub-buckets,然后点击Split Slice,在下拉选中选择Terms选项和age字段,点击绿色Apply changes按钮

通过点击搜索字段的右边的按钮保存图表,把这个图表命名为Pie Example。
下一步,我们打算制作一个条形图。点击New Visualization按钮,然后点击Vertical bar chart。选择From a new search,然后选定shakes*模式匹配。你将会看到单个大条形图,因为到现在为止我们还没有定义任何量值。
对于Y轴的刻度聚合,选择speaker作为Unique Count的字段。对于莎士比亚戏剧,知道那部戏剧需要最少数量的台前幕后人员可能是很有用的,如果你的戏剧公司短缺演员的话。对于X轴的量值,选择Terms聚合和play_name字段。对于排序,选择Ascending,Size保持默认值5。让其他参数保持默认值,然后点击Apply cganges按钮
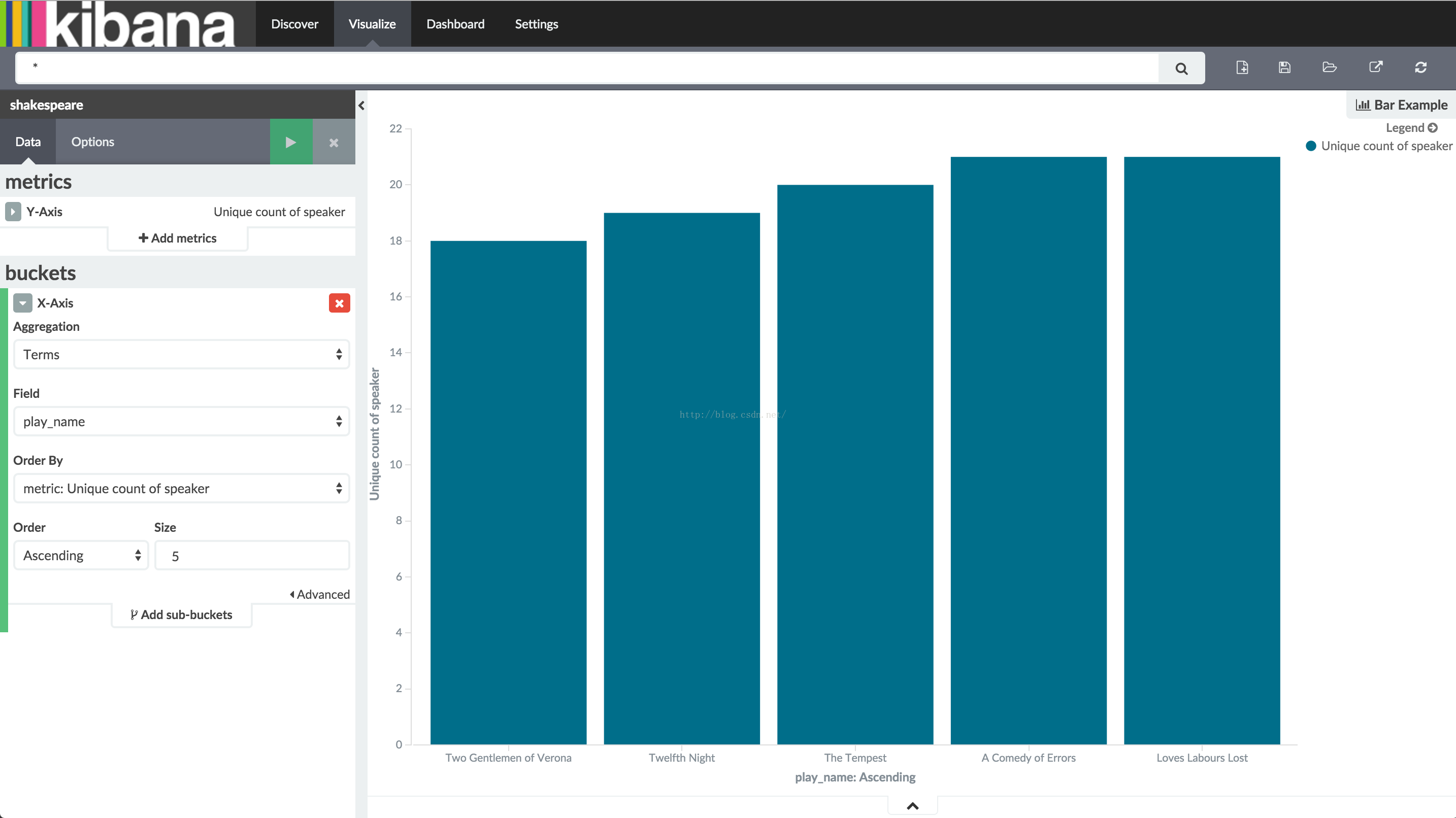
注意一下每部剧名是怎么显示成一个完整的词组而不是被拆分成单独的单词。这是我们在教程的前段部分设置映射的结果,我们把play_name标记为 not analyzed。鼠标移到每一个条上以tooltip形式显示每个剧台前幕后的数量。你可以关掉这个显示方式或者改变你图表的其他选项通过点击左上方的Option标签。
既然你有了莎士比亚剧中最小的演员表,你可能感兴趣知道这些剧本中哪一个对单个演员的要求最高,通过显示给定剧情的最大对话量。用Add metrics按钮增加一个Y轴聚合,为speech_number选择Max聚合。在option页面选择Bar Mode的grouped选项,然后点击Apply changes按钮

正如你所看到的,和其他剧比较起来,《Love’s Labours Lost》经常有最高数量的对话,因此和能会对一个演员的记忆要求更高。
保存图表的名称为Bar Example。
接下来,我们要制作一个瓦片地图来可视化一些地理数据。点击New Visualization按钮,然后点击Tile map按钮,选择from a new search和logstash-*模式匹配。在Kinaba界面的右上方的时间选择器为我们的要发掘的数据定义一个时间窗口,点击Absolute按钮,然后设置起始时间为2015-5-18结束时间到2015-5-20。

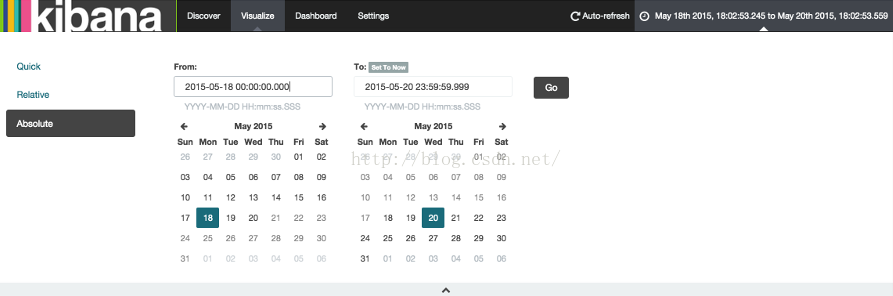
一旦我们设置好了时间区间,点击Go按钮,然后点击底部小小的向上箭头关闭时间选择器。你可以看到整个世界的地图,因为我们现在还没有定义任何量值。
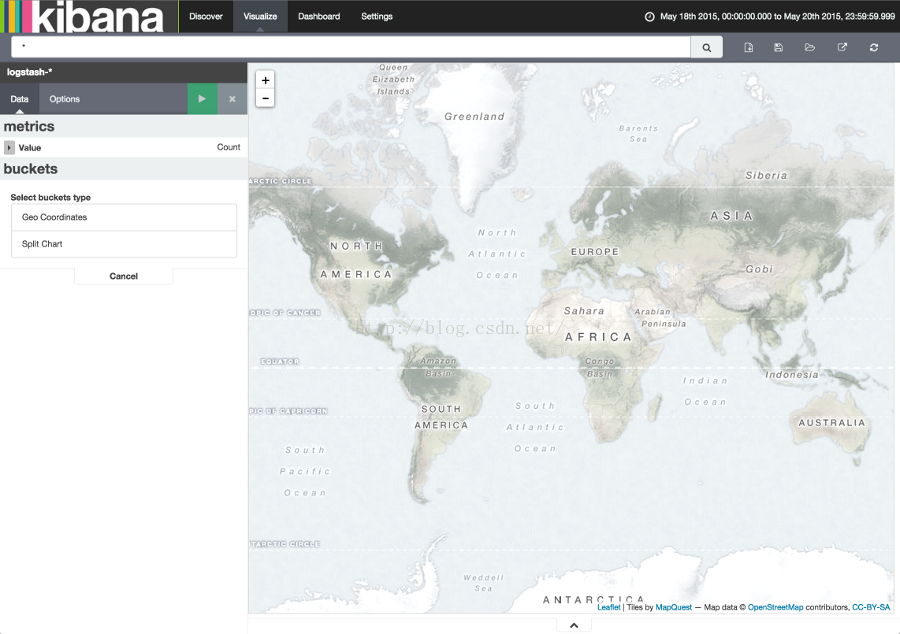
选择Geo Coordinates作为量值,然后点击那个绿色的Apply changes按钮
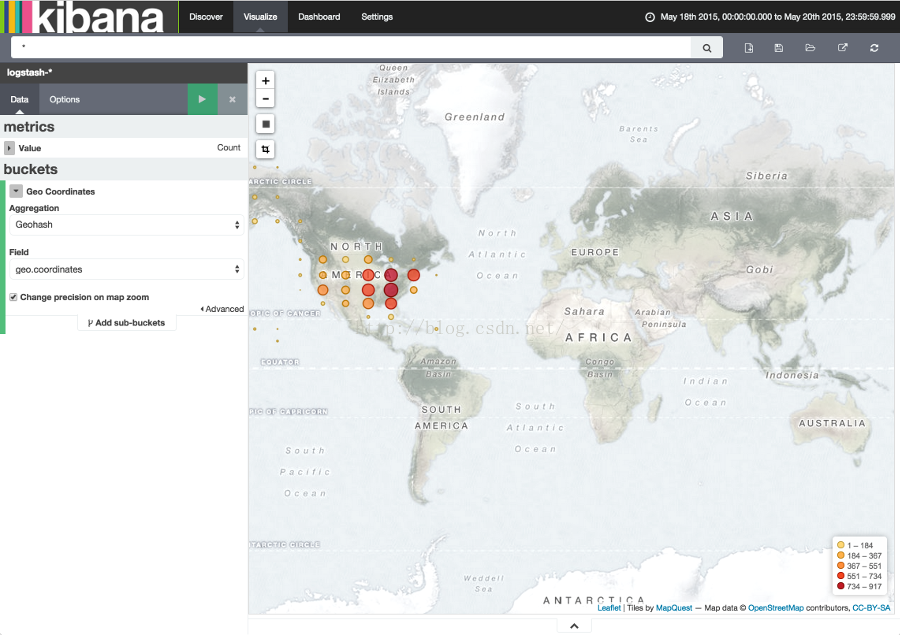
你可以通过点击或者拖拽来导航地图,放大缩小地图用
鼠标移到过滤器显示一些控制工具:切换、定位、翻转、删除过滤器。用Map Example名字保存这个图表。
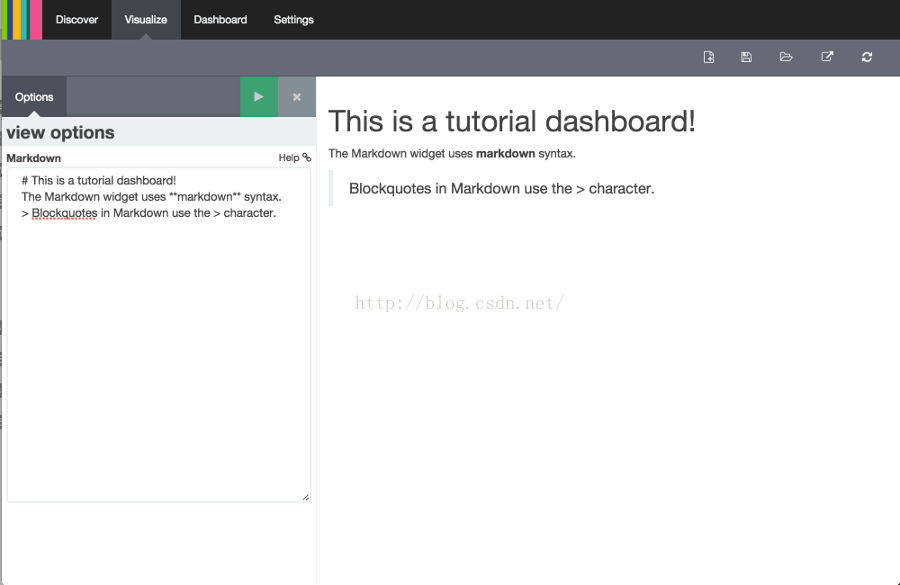
最后我们用一些标记小部件来展示我们的仪表盘。点击New Visualization按钮然后点击Markdown widget按钮来显示一个非常简单的标记字段输入框:

在那个字段输入如下文本:
- # This is a tutorial dashboard!
- The Markdown widget uses **markdown** syntax.
- > Blockquotes in Markdown use the > character.
点击Apply changes按钮
用Markdown Example名称保存这个图表。
3.全部放入仪表盘
一个Kibana仪表盘是许多图表的集合允许你整理和分享。点击Dashboard页面以开始,点击搜索框最右边的Add Visualization按钮,显示出已保存图表的列表。选择Markdown Example、Pie Example、Bar Example和Map Example,然后点击底部小小的箭头关闭列表。你可以通过点集合拖拽标题条移动各个图表的容器,通过拖拽图表容器右下角调整容器大小。你的样例仪表盘最终看起来差不多是这样:
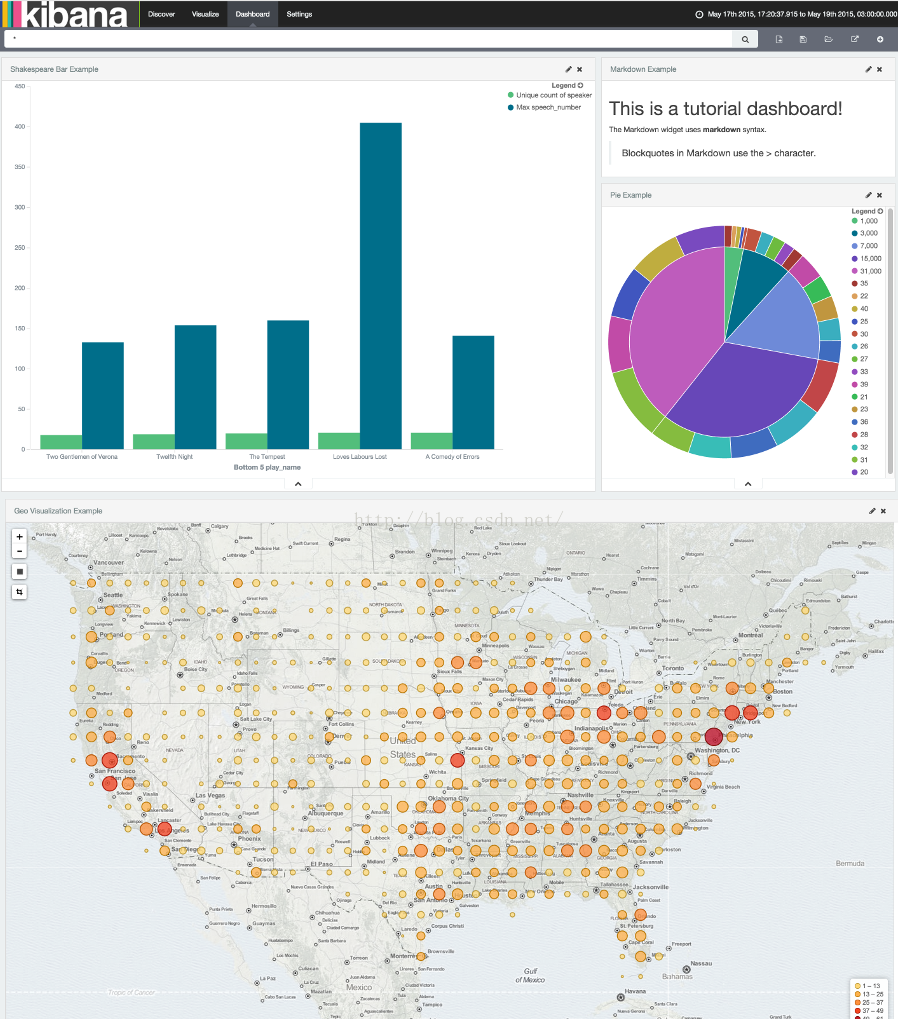
点击Save Dashboard 按钮,然后为仪表盘命名为Tutorial Dashboard。你可以通过点击Share 按钮来显示HTML嵌入代码或者是一个定向链接分享一个保存的仪表盘。
Kibana简介及下载安装的更多相关文章
- Netty学习——Apache Thrift 简介和下载安装
Netty学习——Apache Thrift 简介和下载安装 Apache Thrift 简介 本来由Facebook开发,捐献给了Apache,成了Apache的一个重要项目 可伸缩的,跨语言的服务 ...
- Composer简介与下载安装
简介: 初次接触Composer的PHP程序员可能是需要下载ThinkPHP框架(5.1),那么什么是Composer,怎么下载安装呢? Composer是一个依赖管理工具,下载管理第三方包是其主要功 ...
- MongoDB简介以及下载安装
什么是MongoDB ? MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统.运行稳定,性能高 在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB 旨在 ...
- 一、Python简介及下载安装
一.关于Python Python是目前比较受欢迎的脚本语言之一,具有简洁性.易读性以及可扩展性的特点. Python与Java均可以写网页,也可以写后台功能,区别是Python执行效率低,开发效率高 ...
- Qt学习之路1---软件下载安装及工程简介
1.下载安装目前最新版的qt,官网链接:https://www.qt.io/qt5-8/: 和qt4不同,qt5在线安装,轻巧快速,而且不用配置一些繁琐的东西,安装之后会出现Qt creator这就是 ...
- Fiddler抓包工具简介:(二)下载安装及配置证书和代理
Fiddler下载安装及配置 一.安装过程: 下载官网:https://www.telerik.com/fiddler 安装过程:一路next即可 启动Fiddler:当你启动了Fiddler,程序将 ...
- Maven(一)简介和基本安装使用
简介 如今用于项目管理和自动化构建的东东用的比较多的,比如: eclipse中用到的ant 现今流行的android studio中用到的gradle 这里将介绍另一种工具——maven (也可以用来 ...
- 下载安装和OpenCV匹配的Android开发环境
ok blog Android与OpenCV——重新下载安装和OpenCV匹配的Android开发环境 !!OpenCV4Android开发之旅(一)----OpenCV2.4简介及 app通过Jav ...
- Android与OpenCV——重新下载安装和OpenCV匹配的Android开发环境
Android与OpenCV——重新下载安装和OpenCV匹配的Android开发环境 !!OpenCV4Android开发之旅(一)----OpenCV2.4简介及 app通过Java接口调用Ope ...
随机推荐
- Bioconductor软件安装与升级
1 安装工具Bioc的软件包不能使用直接install.packages函数,它有自己的安装工具,使用下面的代码: source("https://bioconductor.org/bioc ...
- 51Nod - 1384
全排列函数解法 #include <iostream> #include <cstdio> #include <cstring> #include <cmat ...
- 00-python-常用命令
1. pip 加速命令 pip install --index-url https://pypi.douban.com/simple 或者 pip install -i https://pypi.tu ...
- Steam饥荒
存档回滚 D:\Program Files (x86)\Steam\userdata\***\219740\remote 巨人国是survival_数字,海难是shipwreck_数字,哈姆雷特是po ...
- composer修改成国内镜像
因为composer安装包数据是从github.com上下载的,安装包的元数据从packagist.org上下载 作为两个国外的网站,连接速度会很慢,而且很有可能网站被墙. 所以composer中国全 ...
- JAVA多线程 总结
1. Thread 和 Runnable java.lang.Thread 类的实例就是一个线程但是它需要调用java.lang.Runnable接口来执行,由于线程类本身就是调用的Runnable接 ...
- 『Python CoolBook』使用ctypes访问C代码_下_demo进阶
点击进入项目 这一次我们尝试一下略微复杂的c程序. 一.C程序 头文件: #ifndef __SAMPLE_H__ #define __SAMPLE_H__ #include <math.h&g ...
- RobotFramework--环境安装1
1.RobotFramework RobotFramework 的架构是一个通用型的验收测试和验收测试驱动开发的自动化测试框架(ATDD).它 具有易于使用的表格来组织测试过程和测试数据. 3.1版本 ...
- Ubuntu安装vsftpd并通过xftp连接
1.在ubuntu中安装xftp: sudo apt-get update sudo apt-get install vsftpd sudo service vsftpd restart 2.防火墙添 ...
- arguments.callee弃用与webuploader
使用最近使用ueditor的时候 谷歌浏览器下上传相同图片两次后第三次上传不了 而且取消了后会出现一个错误的图片.使用的ueditor是1.4.3 后来发现 这个是 webuploader插件的问题. ...