5-----Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页
工作流程分析
1、以初始的URL初始化Request,并设置回调函数,当该request下载完毕并返回时,将生成response,并作为参数传给回调函数. spider中初始的 requesst是通过 start_requests()来获取的。start_requests()获取 start_urls中的URL,并以 parse以回调函数生成 Request
2、在回调函数内分析返回的网页内容,可以返回Item对象,或者 Dict,或者 Request,以及是一个包含三者的可迭代的容器,返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的 callback函数
3、在回调函数内,可以通过 lxml,bs4,xpath,css等方法获取我们想要的内容生成 item
4、最后将 item传递给 Pipeline处理
我们以通过简单的分析源码来理解
我通常在写spiders下写爬虫的时候,我们并没有写 start_requests来处理 start_urls中的url,这是因为我们在继承的scrapy.Spider中已经写过了,我们可以点开scrapy.Spider查看分析。
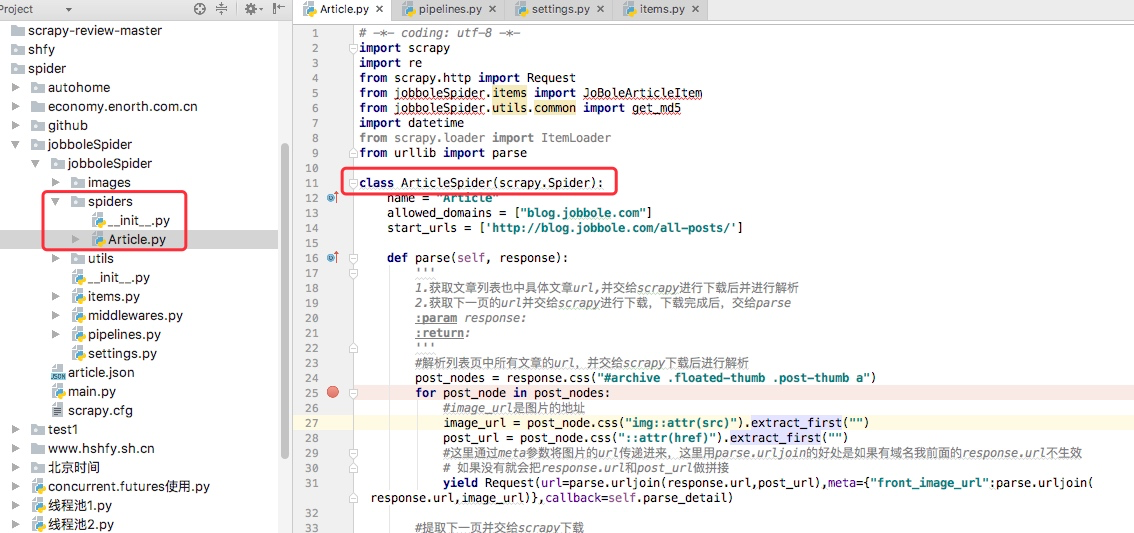
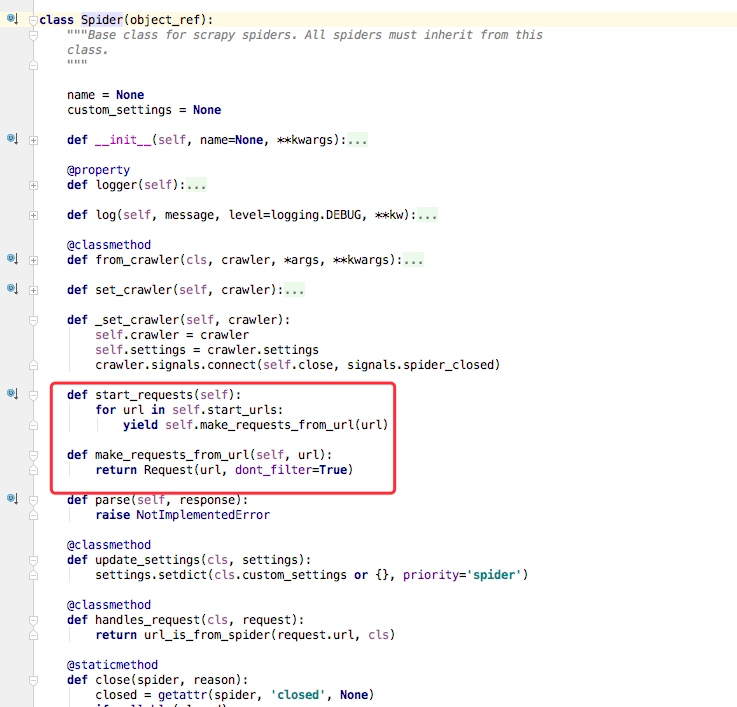
通过上述代码我们可以看到在父类里这里实现了 start_requests方法,通过 make_requests_from_url做了Request请求
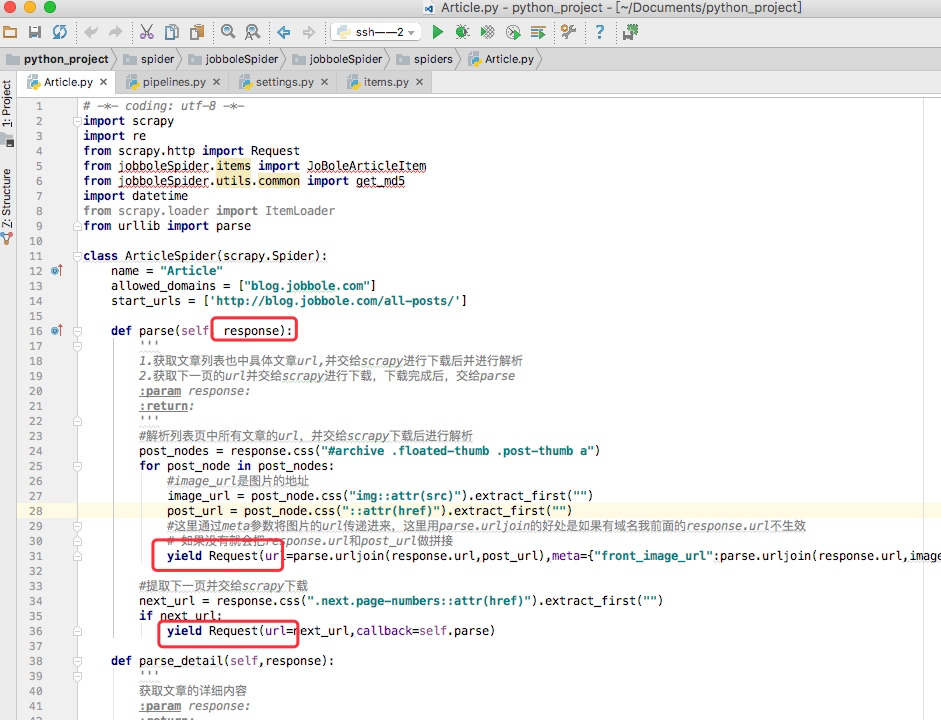
如下图所示的一个例子,parse回调函数中的 response就是父类列 start_requests方法调用 make_requests_from_url返回的结果,并且在parse回调函数中我们可以继续返回 Request,如下属代码中 yield Request()并设置回调函数。
spider内的一些常用属性
我们所有自己写的爬虫都是继承与spider.Spider这个类
name
定义爬虫名字,我们通过命令启动的时候用的就是这个名字,这个名字必须是唯一的
allowed_domains
包含了spider允许爬取的域名列表。当offsiteMiddleware启用时,域名不在列表中URL不会被访问
所以在爬虫文件中,每次生成Request请求时都会进行和这里的域名进行判断
start_urls
起始的url列表
这里会通过spider.Spider方法中会调用start_request循环请求这个列表中每个地址。
custom_settings
自定义配置,可以覆盖settings的配置,主要用于当我们对爬虫有特定需求设置的时候
设置的是以字典的方式设置:custom_settings = {}
from_crawler
这是一个类方法,我们定义这样一个类方法,可以通过crawler.settings.get()这种方式获取settings配置文件中的信息,同时这个也可以在pipeline中使用
start_requests()
这个方法必须返回一个可迭代对象,该对象包含了spider用于爬取的第一个Request请求
这个方法是在被继承的父类中spider.Spider中写的,默认是通过get请求,如果我们需要修改最开始的这个请求,可以重写这个方法,如我们想通过post请求
make_requests_from_url(url)
这个也是在父类中start_requests调用的,当然这个方法我们也可以重写
parse(response)
这个其实默认的回调函数
负责处理response并返回处理的数据以及跟进的url
该方法以及其他的Request回调函数必须返回一个包含Request或Item的可迭代对象
5-----Scrapy框架中Spiders用法的更多相关文章
- scrapy框架中Spiders用法
scrapy框架中Spiders用法 Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据 总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python之爬虫(十七) Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- scrapy框架中Download Middleware用法
scrapy框架中Download Middleware用法 Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给sp ...
- Scrapy框架中选择器的用法【转】
Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法 请给作者点赞 --> 原文链接 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpa ...
- scrapy框架中Item Pipeline用法
scrapy框架中item pipeline用法 当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的pyt ...
- scrapy框架中选择器的用法
scrapy框架中选择器的用法 Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中 ...
- Scrapy框架中的CrawlSpider
小思考:如果想要通过爬虫程序去爬取”糗百“全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬取进行实现(Request模块递归回调parse方法). 方法二: ...
- Scrapy框架中的xpath选择
不同于我们普通爬虫获取xpath,scrapy获得xpath对象获取他的值语法 一.xpath对象获取值 xpath对象..extract() 二.Scrapy框架独有的xpath取值方式 利用hre ...
随机推荐
- loj10131 暗的连锁
传送门 分析 首先我们知道如果在一棵树上加一条边一定会构成一个环,而删掉环上任意一条边都不改变连通性.我们把这一性质扩展到这个题上不难发现如果一条树边不在任意一个新边构成的环里则删掉这条边之后可以删掉 ...
- CF1063B Labyrinth
大家一起膜Rorshach. 一般的$bfs$会造成有一些点访问不到的情况,在$system\ test$的时候会$WA40$(比如我……). 发现这张地图其实是一个边权只有$0/1$的图,我们需要计 ...
- Luogu 2824 [HEOI2016/TJOI2016]排序
BZOJ 4552 挺妙的解法. 听说这题直接用一个桶能拿到$80 \ pts$ 发现如果是一个排列的话,要对这个序列排序并不好做,但是假如是$01$序列的话,要对一个区间排序还是很简单的. 发现最后 ...
- 操作系统 Linux ex2 note
locate filename 搜索文件 将当前用户目录下的文件清单输出到文件list1.txt(当前用户目录下)中.ls -l > list1.txt 利用管道命令将根(/)下所有修改日期在4 ...
- Python入门:模拟登录(二)或注册之requests处理带token请求
转自http://blog.csdn.net/foryouslgme/article/details/51822209 首先说一下使用Python模拟登录或注册时,对于带token的页面怎么登录注册模 ...
- 【转】链接任意目录下库文件(解决错误“/usr/bin/ld: cannot find -lxxx”
netbeans构建项目也出现了同样的问题.猜测是netbeans内部就用的是-l 这种编译方式,所以需要把***.a手动改为lib***.a 原文地址:链接任意目录下库文件(解决错误“/usr/bi ...
- 解决低版本Eclipse安装Findbugs插件无法显示问题
问题描述 Eclipse安装Findbugs,显示安装成功,但是重启Eclipse在[Window]-[show view]-[other]中没有显示 原因 Eclipse版本太低,新版的Findbu ...
- ipmitool查询服务器功耗
通过ipmitool查看服务器功耗 ipmitool -H $ip -I lanplus -U $user -P $password sdr elist | grep "Pwr Consum ...
- 说“DPI”
作者:马健邮箱:stronghorse_mj@hotmail.com发布:2007.03.08更新:2007.04.02 目录一.基本概念二.图像文件中的DPI三.PDG文件中的DPI四.PDF文件中 ...
- eval实例
.... var sel_MedicineType = 'sel_MedicineType' + lastIndex; eval(sel_MedicineType + "= new C_Se ...