ElasticSearch 结构化搜索全文
1、介绍
上篇介绍了搜索结构化数据的简单应用示例,现在来探寻 全文搜索(full-text search) :怎样在全文字段中搜索到最相关的文档。
全文搜索两个最重要的方面是:
一旦谈论相关性或分析这两个方面的问题时,我们所处的语境是关于查询的而不是过滤。
2、基于词项和基于全文
所有查询会或多或少的执行相关度计算,但不是所有查询都有分析阶段。 和一些特殊的完全不会对文本进行操作的查询(如 bool 或 function_score )不同,文本查询可以划分成两大家族:
- 基于词项的查询
- 如
term或fuzzy这样的底层查询不需要分析阶段,它们对单个词项进行操作。用term查询词项Foo只要在倒排索引中查找 准确词项 ,并且用 TF/IDF 算法为每个包含该词项的文档计算相关度评分_score。 -
记住
term查询只对倒排索引的词项精确匹配,这点很重要,它不会对词的多样性进行处理(如,foo或FOO)。这里,无须考虑词项是如何存入索引的。如果是将
["Foo","Bar"]索引存入一个不分析的(not_analyzed)包含精确值的字段,或者将Foo Bar索引到一个带有whitespace空格分析器的字段,两者的结果都会是在倒排索引中有Foo和Bar这两个词。 - 基于全文的查询
- 像
match或query_string这样的查询是高层查询,它们了解字段映射的信息: -
1、如果查询
日期(date)或整数(integer)字段,它们会将查询字符串分别作为日期或整数对待。2、如果查询一个(
not_analyzed)未分析的精确值字符串字段,它们会将整个查询字符串作为单个词项对待。3、但如果要查询一个(
analyzed)已分析的全文字段,它们会先将查询字符串传递到一个合适的分析器,然后生成一个供查询的词项列表。一旦组成了词项列表,这个查询会对每个词项逐一执行底层的查询,再将结果合并,然后为每个文档生成一个最终的相关度评分。
很少直接使用基于词项的搜索,通常情况下都是对全文进行查询,而非单个词项,这只需要简单的执行一个高层全文查询(进而在高层查询内部会以基于词项的底层查询完成搜索)。
当我们想要查询一个具有精确值的 not_analyzed 未分析字段之前, 需要考虑,是否真的采用评分查询,或者非评分查询会更好。
单词项查询通常可以用是、非这种二元问题表示,所以更适合用过滤, 而且这样做可以有效利用缓存
3、匹配查询
匹配查询 match 是个 核心 查询。无论需要查询什么字段, match 查询都应该会是首选的查询方式。 它是一个高级 全文查询 ,这表示它既能处理全文字段,又能处理精确字段。
这就是说, match 查询主要的应用场景就是进行全文搜索,我们以下面一个简单例子来说明全文搜索是如何工作的:
索引一些数据
首先,我们使用 bulk API 创建一些新的文档和索引:
DELETE /my_index PUT /my_index
{ "settings": { "number_of_shards": 1 }} POST /my_index/my_type/_bulk
{ "index": { "_id": 1 }}
{ "title": "The quick brown fox" }
{ "index": { "_id": 2 }}
{ "title": "The quick brown fox jumps over the lazy dog" }
{ "index": { "_id": 3 }}
{ "title": "The quick brown fox jumps over the quick dog" }
{ "index": { "_id": 4 }}
{ "title": "Brown fox brown dog" }
3.1、单个词查询
用第一个示例来解释使用 match 查询搜索全文字段中的单个词:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "QUICK!"
}
}
}
Elasticsearch 执行上面这个 match 查询的步骤是:
1、检查字段类型 。
标题 title 字段是一个 string 类型( analyzed )已分析的全文字段,这意味着查询字符串本身也应该被分析。
2、分析查询字符串 。
将查询的字符串 QUICK! 传入标准分析器中,输出的结果是单个项 quick 。因为只有一个单词项,所以 match 查询执行的是单个底层 term 查询。
3、查找匹配文档 。
用 term 查询在倒排索引中查找 quick 然后获取一组包含该项的文档,本例的结果是文档:1、2 和 3 。
4、为每个文档评分 。
用 term 查询计算每个文档相关度评分 _score ,这是种将 词频(term frequency,即词 quick 在相关文档的 title 字段中出现的频率)和
反向文档频率(inverse document frequency,即词 quick 在所有文档的 title 字段中出现的频率),以及字段的长度(即字段越短相关度越高)相结合的计算方式。参见 相关性的介绍 。
这个过程给我们以下(经缩减)结果:
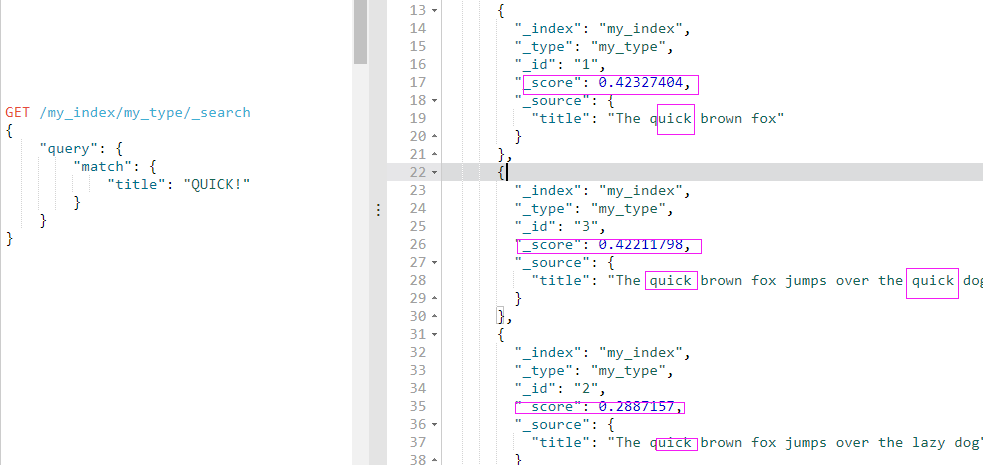
文档 1 最相关,因为它的 title 字段更短,即 quick 占据内容的一大部分。
文档 3 比 文档 2 更具相关性,因为在文档 2 中 quick 出现了两次
3.2、多词查询
如果我们一次只能搜索一个词,那么全文搜索就会不太灵活,幸运的是 match 查询让多词查询变得简单
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": "BROWN DOG!"
}
}
}
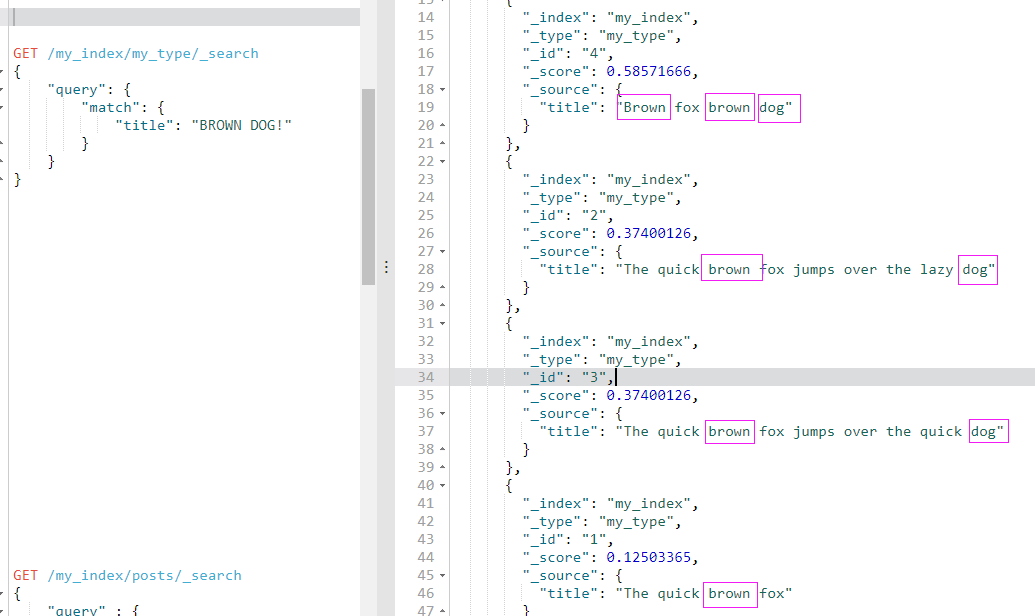
文档 4 最相关,因为它包含词 "brown" 两次以及 "dog" 一次。
文档 2、3 同时包含 brown 和 dog 各一次,而且它们 title 字段的长度相同,所以具有相同的评分。
文档 1 也能匹配,尽管它只有 brown 没有 dog 。
因为 match 查询必须查找两个词( ["brown","dog"] ),它在内部实际上先执行两次 term 查询,然后将两次查询的结果合并作为最终结果输出。为了做到这点,
它将两个 term 查询包入一个 bool 查询中,详细信息见 布尔查询。
以上示例告诉我们一个重要信息:即任何文档只要 title 字段里包含 指定词项中的至少一个词 就能匹配,被匹配的词项越多,文档就越相关。
提高精度
用 任意 查询词项匹配文档可能会导致结果中出现不相关的长尾。 这是种散弹式搜索。可能我们只想搜索包含 所有 词项的文档,也就是说,不去匹配 brown OR dog ,而通过匹配 brown AND dog 找到所有文档。
match 查询还可以接受 operator 操作符作为输入参数,默认情况下该操作符是 or 。我们可以将它修改成 and 让所有指定词项都必须匹配:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": {
"query": "BROWN DOG!",
"operator": "and"
}
}
}
}

match 查询的结构需要做稍许调整才能使用 operator 操作符参数。
这个查询可以把文档 1 排除在外,因为它只包含两个词项中的一个。
4、组合查询
在 组合过滤器 中,讨论过如何使用 bool 过滤器通过 and 、 or 和 not 逻辑组合将多个过滤器进行组合。在查询中, bool 查询有类似的功能,只有一个重要的区别。
过滤器做二元判断:文档是否应该出现在结果中?但查询更精妙,它除了决定一个文档是否应该被包括在结果中,还会计算文档的 相关程度 。
与过滤器一样, bool 查询也可以接受 must 、 must_not 和 should 参数下的多个查询语句。比如:
GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": { "match": { "title": "quick" }},
"must_not": { "match": { "title": "lazy" }},
"should": [
{ "match": { "title": "brown" }},
{ "match": { "title": "dog" }}
]
}
}
}
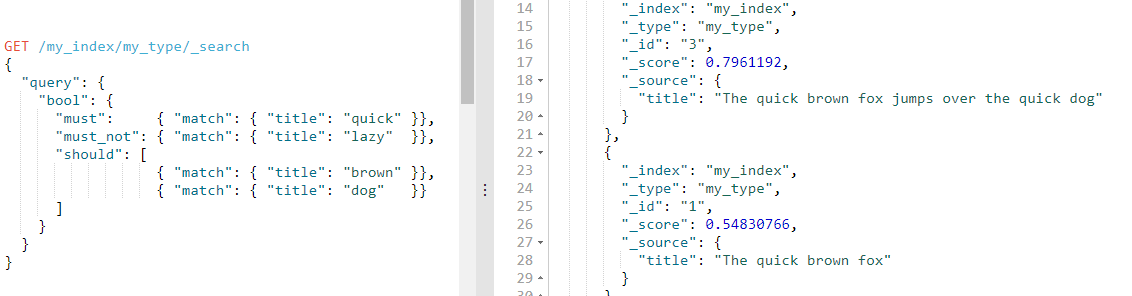
以上的查询结果返回 title 字段包含词项 quick 但不包含 lazy 的任意文档。目前为止,这与 bool 过滤器的工作方式非常相似。
区别就在于两个 should 语句,也就是说:一个文档不必包含 brown 或 dog 这两个词项,但如果一旦包含,我们就认为它们 更相关
文档 3 会比文档 1 有更高评分是因为它同时包含 brown 和 dog 。
评分计算
bool 查询会为每个文档计算相关度评分 _score , 再将所有匹配的 must 和 should 语句的分数 _score求和,最后除以 must 和 should 语句的总数。
must_not 语句不会影响评分; 它的作用只是将不相关的文档排除。
控制精度
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢? 默认情况下,没有 should 语句是必须匹配的,
只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
可以通过 minimum_should_match 参数控制需要匹配的 should 语句的数量, 它既可以是一个绝对的数字,又可以是个百分比:
GET /my_index/my_type/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "brown" }},
{ "match": { "title": "fox" }},
{ "match": { "title": "dog" }}
],
"minimum_should_match": 2
}
}
}
这个查询结果会将所有满足以下条件的文档返回: title 字段包含 "brown" AND "fox" 、 "brown" AND "dog" 或 "fox" AND "dog" 。如果有文档包含所有三个条件,它会比只包含两个的文档更相关。
5、布尔匹配
多词匹配查询只是简单地将生成的 term 查询包裹 在一个 bool 查询中。如果使用默认的 or 操作符,每个 term 查询都被当作 should 语句,这样就要求必须至少匹配一条语句。以下两个查询是等价的:
GET /my_index/my_type/_search
{
"query": {
"match": { "title": "brown fox"}
}
} GET /my_index/my_type/_search
{
"query": {
"bool": {
"should": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }}
]
}
}
}
如果使用 and 操作符,所有的 term 查询都被当作 must 语句,所以 所有(all) 语句都必须匹配。以下两个查询是等价的:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": {
"query": "brown fox",
"operator": "and"
}
}
}
} GET /my_index/my_type/_search
{
"query": {
"bool": {
"must": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }}
]
}
}
}
如果指定参数 minimum_should_match ,它可以通过 bool 查询直接传递,使以下两个查询等价:
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": {
"query": "quick brown fox",
"minimum_should_match": "75%"
}
}
}
} GET /my_index/my_type/_search
{
"query": {
"bool": {
"should": [
{ "term": { "title": "brown" }},
{ "term": { "title": "fox" }},
{ "term": { "title": "quick" }}
],
"minimum_should_match": 2
}
}
}
因为只有三条语句,match 查询的参数 minimum_should_match 值 75% 会被截断成 2 。即三条 should 语句中至少有两条必须匹配。
ElasticSearch 结构化搜索全文的更多相关文章
- Elasticsearch结构化搜索与查询
Elasticsearch 的功能之一就是搜索,搜索主要分为两种类型,结构化搜索和全文搜索.结构化搜索是指有关查询那些具有内在结构数据的过程.比如日期.时间和数字都是结构化的:它们有精确的格式,我们可 ...
- Elasticsearch 结构化搜索、keyword、Term查询
前言 Elasticsearch 中的结构化搜索,即面向数值.日期.时间.布尔等类型数据的搜索,这些数据类型格式精确,通常使用基于词项的term精确匹配或者prefix前缀匹配.本文还将新版本的&qu ...
- ElasticSearch 结构化搜索
1.介绍 结构化搜索(Structured search) 是指有关探询那些具有内在结构数据的过程.比如日期.时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作. 比较常见的操作 ...
- Elasticsearch结构化搜索_在案例中实战使用term filter来搜索数据
1.根据用户ID.是否隐藏.帖子ID.发帖日期来搜索帖子 (1)插入一些测试帖子数据 POST /forum/article/_bulk { "index": { "_i ...
- ElasticStack学习(九):深入ElasticSearch搜索之词项、全文本、结构化搜索及相关性算分
一.基于词项与全文的搜索 1.词项 Term(词项)是表达语意的最小单位,搜索和利用统计语言模型进行自然语言处理都需要处理Term. Term的使用说明: 1)Term Level Query:Ter ...
- ElasticSearch 2 (13) - 深入搜索系列之结构化搜索
ElasticSearch 2 (13) - 深入搜索系列之结构化搜索 摘要 结构化查询指的是查询那些具有内在结构的数据,比如日期.时间.数字都是结构化的.它们都有精确的格式,我们可以对这些数据进行逻 ...
- ElasticSearch常用结构化搜索
最近,需要用到ES的一些常用的结构化搜索命令,因此,看了一些官方的文档,学习了一下.结构化查询指的是查询那些具有内在结构的数据,比如日期.时间.数字都是结构化的. 它们都有精确的格式,我们可以对这些数 ...
- elasticsearch 深入 —— 结构化搜索
结构化搜索 结构化搜索(Structured search) 是指有关探询那些具有内在结构数据的过程.比如日期.时间和数字都是结构化的:它们有精确的格式,我们可以对这些格式进行逻辑操作.比较常见的操作 ...
- Elasticsearch系列---结构化搜索
概要 结构化搜索针对日期.时间.数字等结构化数据的搜索,它们有自己的格式,我们可以对它们进行范围,比较大小等逻辑操作,这些逻辑操作得到的结果非黑即白,要么符合条件在结果集里,要么不符合条件在结果集之外 ...
随机推荐
- GeoIP2 数据库更新地址
GeoIP2 数据库更新地址 数据库文件下载网页地址 http://dev.maxmind.com/geoip/geoip2/geolite2/ http://geolite.maxmind.com/ ...
- 绑定域名到 GitHub Pages
简介 我在阿里云上注册了一个新域名:yuanzb.com,我已经在GitHub Pages上建立了自己的博客:http://yuanzb.github.io/yuanzb/.现在我希望将yuanzb. ...
- 《c程序设计语言》读书笔记-3.4-数字转字符串
#include <io.h> #include <stdio.h> #include <string.h> #include <stdlib.h> # ...
- HDU 1171Big Event in HDU(转01背包)
题意: 给你一组数,分成差距最小的两份A,B(A>=B) 分析: 转01背包 注意: 01背包用一维数组 不要用二维 二维数组若是开太大,内存超限,开太小,RE #include "c ...
- [从hzwer神犇那翻到的模拟赛题] 合唱队形
[问题描述] 学校要进行合唱比赛了,于是班主任小刘准备给大家排个队形. 他首先尝试排成m1行,发现最后多出来a1个同学:接着他尝试排成m2行,发现最后多出来a2个同学,……,他尝试了n种排队方案,但每 ...
- 我们曾经心碎的C#之 第三章.如何使用C#属性
第三章 . 如何使用C#属性 1.Private访问修饰符 访问修饰符可以用来修饰类成员字段和方法,每个访问修饰符只能为紧随其后的成员指定特定的访问权限 如果将字段或方法声明为public 就表示 ...
- 废弃sqlite代码,备查
using System.Linq; using System.Text; using System.Threading.Tasks; using System.Reflection; using T ...
- nessus plugins 离线更新
1.打开 https://plugins.nessus.org/v2/offline.php 2.申请Activation Code http://www.tenable.com/products/n ...
- 错误:'nasm' 不是内部或外部命令,也不是可运行的程序
原文转自 http://blog.csdn.net/alexcrazy/article/details/7183312 >正在执行自定义生成步骤 >'nasm' 不是内部或外部命令,也不是 ...
- android与java的关系
摘自:http://bbs.51cto.com/thread-944897-1.html 相信学习android的人都会想过或者想知道这个问题,那就请你耐心的看完这篇文章吧,你会对android与 ...