InnoDB事务和锁
InnoDB支持事务,MyISAM不支持事务.
一.事务的基本特性
ACID特性
1.原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行。
2.一致性(Consistent):在事务开始和完成时,数据都必须保持一致状态。这意味着所有相关的数据规则都必须应用于事务的修改,以保持数据的完整性;事务结束时,所有的内部数据结构(如B树索引或双向链表)也都必须是正确的。
3. 隔离性(Isolation):数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的“独立”环境执行。这意味着事务处理过程中的中间状态对外部是不可见的,反之亦然。
4.持久性(Durable):事务完成之后,它对于数据的修改是永久性的,即使出现系统故障也能够保持。
二.并发事务带来的问题
1.更新丢失
假设table中的price在更新前为0
如A用户开始一个事务:
BEGIN;
SELECT price FROM table WHERE id=1;
#开始更新
UPDATE table SET price = price + 1 WHERE id=1;
COMMIT;
B用户在A用户未提交事务时,同样更新:
BEGIN;
SELECT price FROM table WHERE id=1; #此处的price应该是1,但是A用户未提交事务,所以还是0
#开始更新
UPDATE table SET price = price+2 WHERE id=1;
COMMIT;
最终price=2,但实际上应该是3,这就是更新丢失
2.脏读
一个事务正在对一条记录做修改,在这个事务完成并提交前,这条记录的数据就处于不一致状态;这时,另一个事务也来读取同一条记录,如果不加控制,第二个事务读取了这些“脏”数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被形象地叫做"脏读".上面B用户在读取price时,A用户未提交事务,B用户读到就是脏数据.
3.不可重复读
一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现其读出的数据已经发生了改变、或某些记录已经被删除了!这种现象就叫做“不可重复读”。
4.幻读
一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为“幻读”。
三.事务的隔离级别
在上面讲到的并发事务处理带来的问题中,“更新丢失”通常是应该完全避免的。但防止更新丢失,并不能单靠数据库事务控制器来解决,需要应用程序对要更新的数据加必要的锁来解决,因此,防止更新丢失应该是应用的责任。
“脏读”、“不可重复读”和“幻读”,其实都是数据库读一致性问题,必须由数据库提供一定的事务隔离机制来解决。数据库实现事务隔离的方式,基本上可分为以下两种。
1.一种是在读取数据前,对其加锁,阻止其他事务对数据进行修改。
2.另一种是不用加任何锁,通过一定机制生成一个数据请求时间点的一致性数据快照(Snapshot),并用这个快照来提供一定级别(语句级或事务级)的一致性读取。从用户的角度来看,好象是数据库可以提供同一数据的多个版本,因此,这种技术叫做数据多版本并发控制(MultiVersion Concurrency Control,简称MVCC或MCC),也经常称为多版本数据库。
3.mysql的四种隔离级别
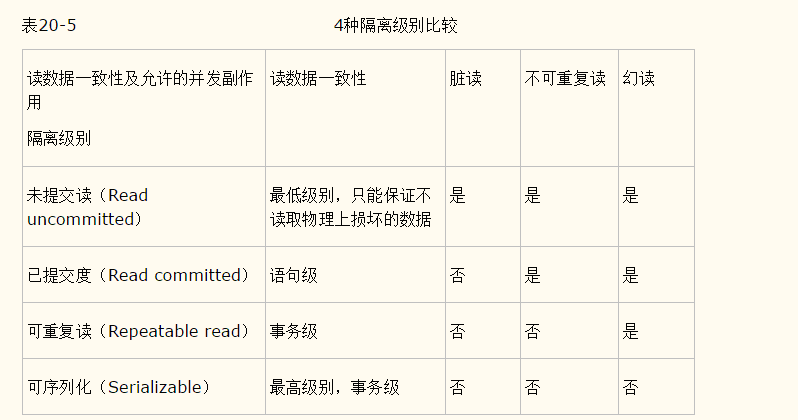
Ps:
a.Repeatable read是默认隔离级别.
b. 查看当前会话隔离级别:select @@tx_isolation;
c.查看系统隔离级别: select @@global.tx_isolation;
四.InnoDB锁争用:
mysql> show global status like 'innodb_row_lock%';
Innodb_row_lock_current_waits 0
Innodb_row_lock_time 530
Innodb_row_lock_time_avg 106
Innodb_row_lock_time_max 327
Innodb_row_lock_waits 5
如果发现锁争用比较严重,如InnoDB_row_lock_waits和InnoDB_row_lock_time_avg的值比较高,还可以通过设置InnoDB Monitors来进一步观察发生锁冲突的表、数据行等,并分析锁争用的原因。
Ps:InnoDB锁超时时间由变量innodb_lock_wait_timeout控制,默认是50s
五.InnoDB的行锁模式及加锁方法
(一).行锁模式
1.共享锁(S锁):
对同一行数据都可以共享一把锁,但是没有获得锁的事务只可以读,不可以修改
2.排它锁(X锁)
对同一行数据,获得该锁的事务可读可写,未获得锁的事务不可读也不可写.
另外,为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention
Locks),这两种意向锁都是表锁。
3.意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
4.意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。

如果一个事务请求的锁模式与当前的锁兼容,InnoDB就将请求的锁授予该事务;反之,如果两者不兼容,该事务就要等待锁释放。
意向锁是InnoDB自动加的,不需用户干预。对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);对于普通SELECT语句,InnoDB不会加任何锁;事务可以通过以下语句显示给记录集加共享锁或排他锁。
(二).加锁方法:
Ps:
- select语句默认不会加任何锁类型
- update,delete,insert都会自动给涉及到的数据加上排他锁
1.
共享锁
SELECT ... LOCK IN SHARE MODE
主要用在需要数据依存关系时来确认某行记录是否存在,并确保没有人对这个记录进行UPDATE或者DELETE操作. 但是如果当前事务也需要对该记录进行更新操作,则很有可能造成死锁,对于锁定行记录后需要进行更新操作的应用,应该使用SELECT... FOR UPDATE方式获得排他锁。
对于加了共享锁的数据行,其他事务可以加共享锁或不加锁,但无法加排它锁.

2.
排它锁
SELECT … FOR
UPDATE
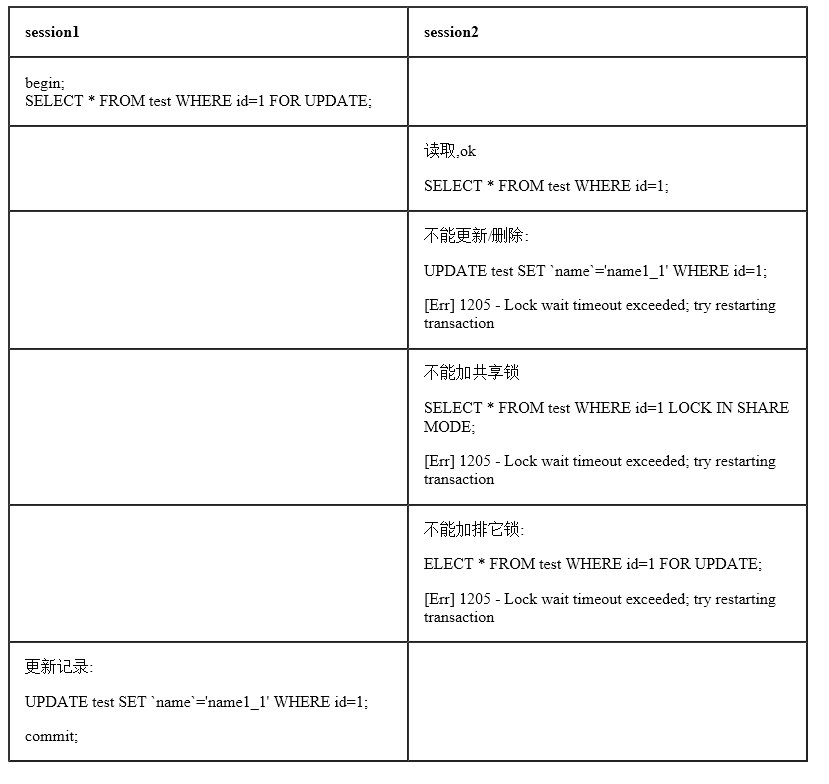
六.InnoDB的行锁实现方式
InnoDB行锁是通过给索引上的索引项加锁来实现的, InnoDB这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁!
在实际应用中,要特别注意InnoDB行锁的这一特性,不然的话,可能导致大量的锁冲突,从而影响并发性能。
1.在不通过索引条件查询的时候,InnoDB使用的是表锁,而不是行锁

在name列上加锁后,上述情况将不存在
2. MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁等待的

3. 当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。

4.即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
如下示例(在mysql5.1版本上,5.5以上版本不存在下列问题):
name列有索引,name字段类型为varchar.
EXPLAIN SELECT * FROM `test` WHERE
`name` =1;#执行全表扫描

EXPLAIN SELECT * FROM `test` WHERE
`name`='1';#执行索引扫描

七.间隙锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
举例来说,假如emp表中只有101条记录,其empid的值分别是 1,2,...,100,101,下面的SQL:
Select * from emp where empid > 100 for update;
是一个范围条件的检索,InnoDB不仅会对符合条件的empid值为101的记录加锁,也会对empid大于101(这些记录并不存在)的“间隙”加锁。
InnoDB使用间隙锁的目的,一方面是为了防止幻读,以满足相关隔离级别的要求,对于上面的例子,要是不使用间隙锁,如果其他事务插入了empid大于100的任何记录,那么本事务如果再次执行上述语句,就会发生幻读;另外一方面,是为了满足其恢复和复制的需要。有关其恢复和复制对锁机制的影响,以及不同隔离级别下InnoDB使用间隙锁的情况,在后续的会做进一步介绍。
很显然,在使用范围条件检索并锁定记录时,InnoDB这种加锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际应用开发中,尤其是并发插入比较多的应用,我们要尽量优化业务逻辑,尽量使用相等条件来访问更新数据,避免使用范围条件。
还要特别说明的是,InnoDB除了通过范围条件加锁时使用间隙锁外,如果使用相等条件请求给一个不存在的记录加锁,InnoDB也会使用间隙锁!

PS:
在多列条件查找时,
如SELECT * FROM table WHERE col1=2 AND col2>1000 FOR UPDATE;在col1和col2上均有索引
这个时候
INSERT INTO table(col1,col2) VALUES(3,8);可以执行
INSERT INTO table(col1,col2) VALUES(2,8);不可以执行
InnoDB根据索引只是锁定了需要锁定的间隙锁.
尽量少用不确定的SQL语句如
insert
into target_tab select * from source_tab where ...
create
table new_tab ...select ... From
source_tab where ...(CTAS)
通过使用“select *
from source_tab ... Into outfile”和“load data infile ...”语句组合来间接实现,采用这种方式MySQL不会给source_tab加锁
七.InnoDB的表锁
注意点:
1.LOCK TABLES tb_name WRITE;//当前会话对表tb_name可读可写,其余会话对表tb_name不可读不可写
2.LOCK TABLES tb_name READ;//当前会话对表tb_name可读不可写,其余会话对表tb_name可读不可写
3.你需要一次锁定更新的表
LOCK TABLES tb1_name WRITE;
在锁定过程中,你可以读tbl2_name,当你需要更新tbl2_name,你将得到一个表无法锁定的错误
4.innodb的表锁,开始事务时会自动释放表锁,所以begin;或set autocommit=0;等命令应该在lock tables的前面.
在InnoDB下,使用表锁要注意以下两点。
1.使用LOCK TABLES虽然可以给InnoDB加表级锁,但必须说明的是,表锁不是由InnoDB存储引擎层管理的,而是由其上一层──MySQL Server负责的,仅当autocommit=0、innodb_table_locks=1(默认设置)时,InnoDB层才能知道MySQL加的表锁,MySQL Server也才能感知InnoDB加的行锁,这种情况下,InnoDB才能自动识别涉及表级锁的死锁;否则,InnoDB将无法自动检测并处理这种死锁。有关死锁,下一小节还会继续讨论。
2.在用LOCK TABLES对InnoDB表加锁时要注意,要将AUTOCOMMIT设为0,否则MySQL不会给表加锁;事务结束前,不要用UNLOCK TABLES释放表锁,因为UNLOCK TABLES会隐含地提交事务;COMMIT或ROLLBACK并不能释放用LOCK TABLES加的表级锁,必须用UNLOCK TABLES释放表锁。正确的方式见如下语句:
例如,如果需要写表t1并从表t读,可以按如下做:
SET AUTOCOMMIT=0;
LOCK TABLES t1 WRITE, t2 READ, ...;
[do something with tables t1 and t2 here];
COMMIT;
UNLOCK TABLES;
八.在应用中避免死锁的方法
发生死锁后,InnoDB一般都能自动检测到,并使一个事务释放锁并回退,另一个事务获得锁,继续完成事务。但在涉及外部锁,或涉及表锁的情况下,InnoDB并不能完全自动检测到死锁,这需要通过设置锁等待超时参数innodb_lock_wait_timeout来解决。需要说明的是,这个参数并不是只用来解决死锁问题,在并发访问比较高的情况下,如果大量事务因无法立即获得所需的锁而挂起,会占用大量计算机资源,造成严重性能问题,甚至拖跨数据库。我们通过设置合适的锁等待超时阈值,可以避免这种情况发生。
1. 在应用中,如果不同的程序会并发存取多个表,应尽量约定以相同的顺序来访问表,这样可以大大降低产生死锁的机会。
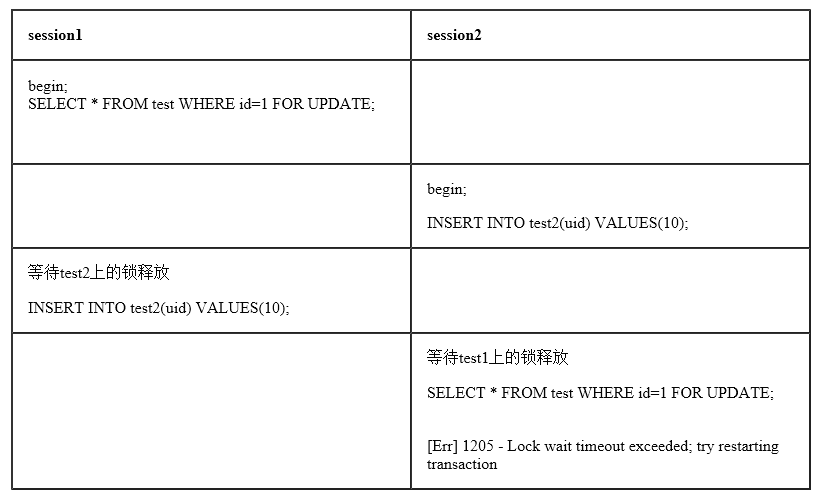
2. 在程序以批量方式处理数据的时候,如果事先对数据排序,保证每个线程按固定的顺序来处理记录,也可以大大降低出现死锁的可能。
3. 在事务中,如果要更新记录,应该直接申请足够级别的锁,即排他锁,而不应先申请共享锁,更新时再申请排他锁,因为当用户申请排他锁时,其他事务可能又已经获得了相同记录的共享锁,从而造成锁冲突,甚至死锁。
4. 前面讲过,在REPEATABLE-READ隔离级别下,如果两个线程同时对相同条件记录用SELECT...FOR UPDATE加排他锁,在没有符合该条件记录情况下,两个线程都会加锁成功。程序发现记录尚不存在,就试图插入一条新记录,如果两个线程都这么做,就会出现死锁。这种情况下,将隔离级别改成READ COMMITTED,就可避免问题
5. 当隔离级别为READ
COMMITTED时,如果两个线程都先执行SELECT...FOR
UPDATE,判断是否存在符合条件的记录,如果没有,就插入记录。此时,只有一个线程能插入成功,另一个线程会出现锁等待,当第1个线程提交后,第2个线程会因主键重复出错,但虽然这个线程出错了,却会获得一个排他锁!这时如果有第3个线程又来申请排他锁,也会出现死锁。对于这种情况,可以直接做插入操作,然后再捕获主键重复异常,或者在遇到主键重错误时,总是执行ROLLBACK释放获得的排他锁
InnoDB事务和锁的更多相关文章
- MySQL · 引擎特性 · InnoDB 事务锁简介
https://yq.aliyun.com/articles/4270# zhaiwx_yinfeng 2016-02-02 19:00:43 浏览2194 评论0 mysql innodb lock ...
- innodb事务锁
计算机程序锁 控制对共享资源进行并发访问 保护数据的完整性和一致性 lock 主要是事务,数据库逻辑内容,事务过程 latch/mutex 内存底层锁: 更新丢失 原因: B的更改还没有 ...
- [数据库事务与锁]详解五: MySQL中的行级锁,表级锁,页级锁
注明: 本文转载自http://www.hollischuang.com/archives/914 在计算机科学中,锁是在执行多线程时用于强行限制资源访问的同步机制,即用于在并发控制中保证对互斥要求的 ...
- MySQL · 引擎特性 · InnoDB 事务子系统介绍
http://mysql.taobao.org/monthly/2015/12/01/ 前言 在前面几期关于 InnoDB Redo 和 Undo 实现的铺垫后,本节我们从上层的角度来阐述 InnoD ...
- 14.3.3 Locks Set by Different SQL Statements in InnoDB 不同的SQL语句在InnoDB里的锁设置
14.3.3 Locks Set by Different SQL Statements in InnoDB 不同的SQL语句在InnoDB里的锁设置 locking read, 一个UPDATE,或 ...
- MySQL 事务与锁机制
下表展示了本人安装的MariaDB(10.1.19,MySQL的分支)所支持的所有存储引擎概况,其中支持事务的有InnoDB.SEQUENCE,另外InnoDB还支持XA事务,MyISAM不支持事务. ...
- MySQL事务与锁
MySQL事务与锁 锁的基本概念 锁是计算机协调多个进程或线程并发访问某一资源的机制. 相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制.比如,MyISA ...
- Innodb中的锁
Innodb中的锁 共享锁和排它锁(Shared and Exclusive Locks)共享锁和排它锁是行级锁,有两种类型的行级锁 共享锁(s lock)允许持有锁的事务对行进行读取操作 排它锁(x ...
- MySQL · 引擎特性 · InnoDB 事务系统
前言 关系型数据库的事务机制因其有原子性,一致性等优秀特性深受开发者喜爱,类似的思想已经被应用到很多其他系统上,例如文件系统等.本文主要介绍InnoDB事务子系统,主要包括,事务的启动,事务的提交,事 ...
随机推荐
- 百度之星初赛(A)——T2
数据分割 小w来到百度之星的赛场上,准备开始实现一个程序自动分析系统. 这个程序接受一些形如x_i = x_jxi=xj 或 x_i \neq x_jxi≠xj 的相等/不等约 ...
- 自定义View Draw过程(4)
目录 目录 1. 知识基础 具体请看我写的另外一篇文章:自定义View基础 - 最易懂的自定义View原理系列 2. draw过程作用 绘制View视图 3. draw过程详解 同measure.la ...
- [译] 如何像 Python 高手一样编程?
转自:http://www.liuhaihua.cn/archives/23475.html Harries 发布于 7天前 分类:编程技术 阅读(15) 评论(0) 最近在网上看到一篇介绍Pytho ...
- Sqlite 约束条件 Constraints
一.约束 Constraints 我们在数据库中存储数据的时候,有一些数据有明显的约束条件. 比如一所学校关于教师的数据表,其中的字段列可能有如下约束: 年龄 - 至少大于20岁.如果你想录入一个小于 ...
- android hook 框架 xposed 如何实现注入
Android so注入-libinject2 简介.编译.运行 Android so注入-libinject2 如何实现so注入 Android so注入-Libinject 如何实现so注入 A ...
- RobotFramework自动化2-自定义关键字【转载】
本篇转自博客:上海-悠悠 原文地址:http://www.cnblogs.com/yoyoketang/tag/robotframework/ 前言 有时候一个页面上有多个对象需要操作,如果一个个去定 ...
- 加密中的salt是啥意思
今天在stackoverflow上查看python的md5的问题,提到,除了简单的加密外,还可以加入一点salt 啥意思?百度一下看到:(https://zhidao.baidu.com/questi ...
- MY97 日期控件只输入今天之前的值
<script type="text/javascript"> function GetDate() { ...
- Codeforces Round #447 (Div. 2) C. Marco and GCD Sequence【构造/GCD】
C. Marco and GCD Sequence time limit per test 1 second memory limit per test 256 megabytes input sta ...
- [BZOJ1038][ZJOI2008]瞭望塔(半平面交)
1038: [ZJOI2008]瞭望塔 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 2999 Solved: 1227[Submit][Statu ...