Kudu安装前的建议说明(博主推荐)
不多说,直接上干货!
能点击进来看我写的这篇博文的朋友,肯定是刚入门的你。
其实以下是我从官网翻译过来的。
http://kudu.apache.org/docs/installation.html#_build_from_source

硬件:
- 一台或者多台机器跑kudu-master。建议跑一个master(无容错机制)、三个master(允许一个节点运行出错)或者五个master(允许两个节点出错)。
- 一台或者多台机器跑kudu-tserver。当需要使用副本,至少需要三个节点运行kudu-tserver服务。
注意: 比如你若是学生初学者,或者电脑配置条件有限,则可以用3节点集群来搭建Kudu。如master、slave1、slave2。
操作系统(主要是linux系统,windows系统不支持):
- RHEL 6, RHEL 7, CentOS 6, CentOS 7, Ubuntu 14.04 (Trusty), Ubuntu 16.04 (Xenial), Debian 8 (Jessie), or SLES 12.
- 内核和文件系统支持 hole punching 选项。
- ntp服务。
- xfs or ext4 formatted drives
注意: 对于主流的Linux操作系统, 目前,我建议大家用CentOS6.5或CentOS7 、Ubuntu14.04和Ubuntu16.04。
- macOS
-
OS X 10.10 Yosemite, OS X 10.11 El Capitan, or macOS Sierra.
Prebuilt macOS packages are not provided.
- Windows
-
Microsoft Windows is unsupported.
If solid state storage is available, storing Kudu WALs on such high-performance media may significantly improve latency when Kudu is configured for its highest durability levels.
存储:
- 尽量使用固态存储,将显著提高kudu性能。
管理
- 如果你使用的是CDH,需要Cloudera Manager 5.4.3及以上的版本。
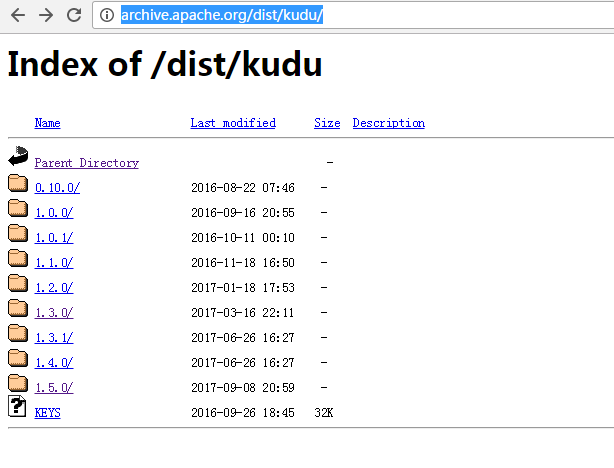
对于Kudu的版本的选择?
http://archive.apache.org/dist/kudu/
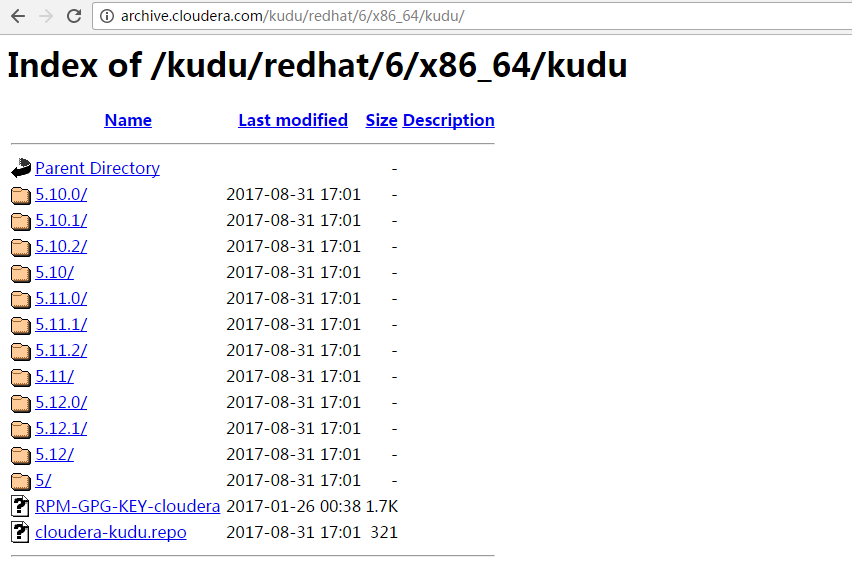
http://archive.cloudera.com/kudu/redhat/6/x86_64/kudu/
若你还不会搭建大数据集群的话,则
大数据入门基础系列之Apache版本的hadoop集群详细部署搭建(包括HA和非HA)(包括单节点、3节点、5节点)
http://mp.weixin.qq.com/s/Yta_cl8xNvdU0kqvP5pdlw
大数据入门基础系列之CDH版本的hadoop集群详细部署搭建(3节点)
http://mp.weixin.qq.com/s/EjxQrXF10DrkM1O-4LWvDg
大数据入门基础系列之ClouderManager版本的hadoop集群详细部署搭建(1、3、4节点)(在线或离线)
https://mp.weixin.qq.com/s/S9EZCMlGdiBcxcvm1FMyjQ
大数据入门基础系列之Ambari版本的hadoop集群详细部署搭建(1、3、4节点)(在线或离线)
http://mp.weixin.qq.com/s/7zrJqEjXFar6Ob2FPJStFQ
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




Kudu安装前的建议说明(博主推荐)的更多相关文章
- Ubuntu16.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu LTS \n \l r ...
- Ubuntu14.04下Neo4j图数据库官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 说在前面的话 首先,查看下你的操作系统的版本. root@zhouls-virtual-machine:~# cat /etc/issue Ubuntu 14.04.4 LTS ...
- Navicat Premium之MySQL客户端的下载、安装和使用(博主推荐)
不多说,直接上干货! 前期工作 若需使用Navicat Premium,则需要先安装MySQL,在此就不叙述了.具体可见我的博客: MySQL Server类型之MySQL客户端工具的下载.安装和使用 ...
- Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz + hadoop-2.6.0.tar.gz)(master、slave1和slave2)(博主推荐)
说白了 Spark on YARN模式的安装,它是非常的简单,只需要下载编译好Spark安装包,在一台带有Hadoop YARN客户端的的机器上运行即可. Spark on YARN简介与运行wor ...
- Ubuntu14.04下Mongodb官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 在这篇博客里,我采用了非官网的安装步骤,来进行安装.走了弯路,同时,也是不建议.因为在大数据领域和实际生产里,还是要走正规的为好. Ubuntu14.04下Mongodb(离线安 ...
- Ubuntu16.04下Mongodb官网安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 在这篇博客里,我采用了非官网的安装步骤,来进行安装.走了弯路,同时,也是不建议.因为在大数据领域和实际生产里,还是要走正规的为好. Ubuntu16.04下Mongodb(离线安 ...
- Ubuntu14.04下Mongodb数据库可视化工具安装部署步骤(图文详解)(博主推荐)
不多说,直接上干货! 前期博客 Ubuntu14.04下Mongodb(离线安装方式|非apt-get)安装部署步骤(图文详解)(博主推荐) Ubuntu14.04下Mongodb官网安装部署步骤(图 ...
- CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
随机推荐
- [译]javascript中定义函数的各种方法
本文翻译youtube上的up主kudvenkat的javascript tutorial播放单 源地址在此: https://www.youtube.com/watch?v=PMsVM7rjupU& ...
- java读取classpath下properties文件注意事项
1.properties文件在classpath根路径下读取方式 Properties properties = new Properties(); properties.load(BlogIndex ...
- HTML5与CSS3设计模式 中文版 高清PDF扫描版
HTML5与CSS3设计模式是一部全面讲述用HTML5和CSS3设计网页的教程.书中含350个即时可用的模式 (HTML5和CSS3代码片段),直接复制粘贴即可使用,更可以组合起来构建出无穷的解决方案 ...
- MVC5中的路由
[Route("dazhao/{id}")] [Route("xixi/index")] [Route("xiaohan")] public ...
- Mac下的UI自动化测试 (二)
下面讲一下Sikuli的重要概念,就是region,所谓region就是Sikuli在进行图像识别的时候的一个区域,默认是整个屏幕. 当然,如果region选得太大的话,并且UI上存在相似的控件,那么 ...
- winform改变控件的外形
GraphicsPath gp = new GraphicsPath(); gp.AddEllipse(0, 0, 40, 40); Region region = new Region(gp); c ...
- LCA【洛谷P2971】 [USACO10HOL]牛的政治Cow Politics
P2971 [USACO10HOL]牛的政治Cow Politics 农夫约翰的奶牛住在N (2 <= N <= 200,000)片不同的草地上,标号为1到N.恰好有N-1条单位长度的双向 ...
- springmvc htmlEscape标签的作用
有些东西自己不知道就想要弄明白 唉 做项目 看人家项目中用到啦 不会 不知道 就百度啦 整理了一下 方便自己记忆 一.SpringMVC 表单元素标签 如下: <form:textarea ...
- 《Qt 学习之路 2》目录
<Qt 学习之路 2>目录 <Qt 学习之路 2>目录 豆子 2012年8月23日 Qt 学习之路 2 177条评论 <Qt 学习之路 2>目录 序 Qt ...
- hdu6229 Wandering Robots 2017沈阳区域赛M题 思维加map
题目传送门 题目大意: 给出一张n*n的图,机器人在一秒钟内任一格子上都可以有五种操作,上下左右或者停顿,(不能出边界,不能碰到障碍物).题目给出k个障碍物,但保证没有障碍物的地方是强联通的,问经过无 ...