Hive 的企业优化
优化
数据优化
一、从大表拆分成小表(更快地检索)
eg2:常用于分表
create table if not exists default.cenzhongman_2
AS select ip,date from default.cenzhongman;
二、使用外部表(多部门共用,指定存储目录,删表不删数据),分区表(按月按XXX分区)
#创建外部表
CREATE EXTERNAL TABLE IF NOT EXISTS table_name();
#创建分区表
create table emp_partition(ID int, name string, job string, mrg int, hiredate string, sal double, comm double, deptno int) partitioned by (mouth string);
三、使用 ORC | parquet 数据存储格式
#官网例子
create table Addresses (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");
四、使用 snappy 压缩格式
如上例
五、FetchTask 抓取任务转换 > more
<property>
<name>hive.fetch.task.conversion</name>
<value>more</value>
<description>
Expects one of [none, minimal, more].
Some select queries can be converted to single FETCH task minimizing latency.
Currently the query should be single sourced not having any subquery and should not have
any aggregations or distincts (which incurs RS), lateral views and joins.
0. none : disable hive.fetch.task.conversion
1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only (Select * 、筛选分区、limit 限制显示行数 这三种行为不会经过 mapreduce)
2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns)(相对nimimal 增加了时间戳,虚拟列,还有所有的选择)
</description>
</property>
优化 SQL 语句
join 优化
common/shuffle/reduce join :join 发生在 reduce 阶段
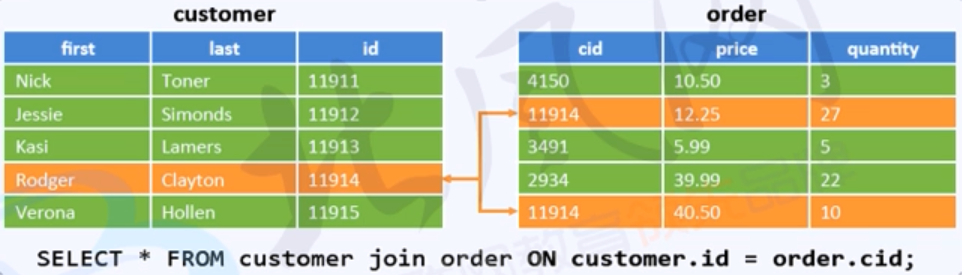

大表对大表,每个表的数据都从文件中读取(发生在Reduce shuffle 的分组Group过程(相同的key的value放在一起))
Map join :join 发生在 Map 阶段

小表对大表,大表的数据从文件中读取,小表的数据在内存中,通过 DistributedCache 类进行缓存
SMB join :Sort-Merge-Bucket join
SMB 的设置

注:Bucket CLUSTERED 按照 num_buckets 对数据进行分区并排序
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]


面对大表对大表处理时候的优化,Merge > sort > join
根据两个表的相同字段进行 按 num_buckets 分组(Merge) 并 在组内 排序(Sort)
execution plan 执行计划
官方文档
查看执行计划
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] query
eg:explain select * from emp;
能够看到的信息
- The Abstract Syntax Tree for the query 语法树
- The dependencies between the different stages of the plan 依赖关系
- The description of each of the stages 每个阶段的描述
其他高级优化
1.设置任务并行执行
| 参数 | 值 | 备注 |
|---|---|---|
| hive.exec.parallel | false | 默认为 false |
| hive.exec.parallel.thread.number | 8 | 建议10 ~ 20 之间 |
2.合理设置 reduce 任务的数量
| 参数 | 值 | 备注 |
|---|---|---|
| mapreduce.job.reduces | 1 | 测试出真知 |
3.推测执行 speculative
在 mapReduce 运行过程中,当 ApplicationMaster 检测到任务执行时间差异明显比正常时间长时,会多运行一个任务,结果取决于最先结束运行的任务。
在 Hive 执行过程中出现长时间任务为正常现象,为了防止系统创建重复任务占用过多的资源,应该关闭该功能
| 参数 | 值 | 备注 |
|---|---|---|
| hive.mapred.reduce.tasks.speculative.execution | true | 当用 Hive 时候推荐为 false |
| mapreduce.map.speculative | true | 当用 Hive 时候推荐为 false |
| mapreduce.reduce.speculative | true | 当用 Hive 时候推荐为 false |
4.合理设置 Map 值
一般来说,根据文件大小就是很合理的了。
5.动态分区调整
| 参数 | 值 | 备注 |
|---|---|---|
| hive.exec.dynamic.partition | true | 是否开启动态分区属性 |
| hive.exec.dynamic.partition.mode | strict | strict mode, 用户必须指定至少一个静态分区以防用户意外地覆盖了所有的分区。nonstrict mode 所有的分区都是动态的 |
6.查询模式设置
| 参数 | 值 | 备注 |
|---|---|---|
| hive.mapred.mode nonstrict | nostrict | strict/nostrict |
设置严格模式将禁止三种类型查询
- 1)对于分区表,不加分区字段过滤条件,不能执行:分区表中,where 子句中不加分区过滤
Error eg:select * from emp_partition where name = 'cenzhongman';
Right eg:select * from emp_partition where name = 'cenzhongman', month = '201707'; - 2)对于 oder by 语句,必须使用 limit 语句
- 3)限制笛卡尔积的查询(Join 的时候不适用 on 而使用 where 的)
Hive 的企业优化的更多相关文章
- 深入浅出Hive企业级架构优化、Hive Sql优化、压缩和分布式缓存(企业Hadoop应用核心产品)
一.本课程是怎么样的一门课程(全面介绍) 1.1.课程的背景 作为企业Hadoop应用的核心产品,Hive承载着FaceBook.淘宝等大佬 95%以上的离线统计,很多企业里的离线统 ...
- HDP Hive StorageHandler 下推优化的坑
关键词:hdp , hive , StorageHandler 了解Hive StorageHandler的同学都知道,StorageHandler作为Hive适配不同存储的拓展类,同时肩负着Hive ...
- 大数据技术之_11_HBase学习_02_HBase API 操作 + HBase 与 Hive 集成 + HBase 优化
第6章 HBase API 操作6.1 环境准备6.2 HBase API6.2.1 判断表是否存在6.2.2 抽取获取 Configuration.Connection.Admin 对象的方法以及关 ...
- Hive常用性能优化方法实践全面总结
Apache Hive作为处理大数据量的大数据领域数据建设核心工具,数据量往往不是影响Hive执行效率的核心因素,数据倾斜.job数分配的不合理.磁盘或网络I/O过高.MapReduce配置的不合理等 ...
- 大数据开发主战场hive (企业hive应用)
hive在大数据套件中占很的地位,分享下个人经验. 1.在hive日常开发中,我们首先面对的就是hive的表和库,因此我要先了解库,表的命名规范和原则 如 dwd_whct_xmxx_m 第1部分为表 ...
- Hive语句执行优化-简化UDF执行过程
Hive会将执行的SQL语句翻译成对应MapReduce任务,当SQL语句比较简单时,性能还是可能处于可接受的范围.但是如果涉及到非常复杂的业务逻辑,特别是通过程序的方式(一些模版语言生成)生成大 ...
- hive中的优化问题
一.fetch抓取 fetch 抓取是指,hive中对某些情况的查询可以不必使用MapReduce计算.(1)把hive.fetch.task.conversion 设置成none,然后执行查询语句, ...
- nginx配置文件企业优化
1.1 企业规范优化Nginx配置文件 第一个里程碑:创建扩展目录,生成虚拟主机配置文件 mkdir extra sed -n '10,15p' nginx.conf >extra/www.co ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
随机推荐
- c#和c++的运算符优先级
闲来无聊乱写代码.发现基础的东西有的时候也非常的抽象.不信?那来看看下面这条语句: ; ; j = i = -i++; 如果上述代码是vc++代码,那么输出结果是: i=- j=- 请按任意键继续. ...
- Struts2_动态结果集
页面请求: <li><a href="user/user?type=1">返回success</a></li> <li> ...
- linux系统unzip文件报错的解决方案
data.zip文件有4G多,解压的时候出问题了. Archive: data.zip End-of-central-directorysignature not found. Either th ...
- 二叉查找树(c++)
二叉查找数的操作: #include <iostream> using namespace std; typedef struct BitNode { int data; struct B ...
- System Center Configuration Manager 2016 必要条件准备篇(Part4)
步骤4.重新启动Configuration Manager主服务器 注意:在Configuration Manager服务器(CM01)上以本地管理员身份执行以下操作 打开管理命令提示符并发出以下 ...
- python3线程介绍02(线程锁的介绍:互斥、信号、条件、时间、定时器)
#!/usr/bin/env python# -*- coding:utf-8 -*- import threadingimport timeimport random # 1-互斥锁 Lock 同一 ...
- 《孵化Twitter》:Twitter创始人勾心斗角史,细节披露程度令人吃惊
本书详细讲述twitter的发展史.感觉基本上是一部创始人从朋友变敌人,勾心斗角的历史.Twitter本身的产品发展反而相对比较简单. 书中披露了许多email.谈话.会议的细节,作者说这些是数百个小 ...
- Uva 10820 交表
题目链接:https://uva.onlinejudge.org/external/108/10820.pdf 题意: 对于两个整数 x,y,输出一个函数f(x,y),有个选手想交表,但是,表太大,需 ...
- [Pytorch] pytorch笔记 <三>
pytorch笔记 optimizer.zero_grad() 将梯度变为0,用于每个batch最开始,因为梯度在不同batch之间不是累加的,所以必须在每个batch开始的时候初始化累计梯度,重置为 ...
- python_1_变量的使用
print("hello word") name="Qi Zhiguang" print("My name is",name) name2= ...