linux 内存地址空间管理 mm_struct
http://blog.csdn.net/yusiguyuan/article/details/39520933
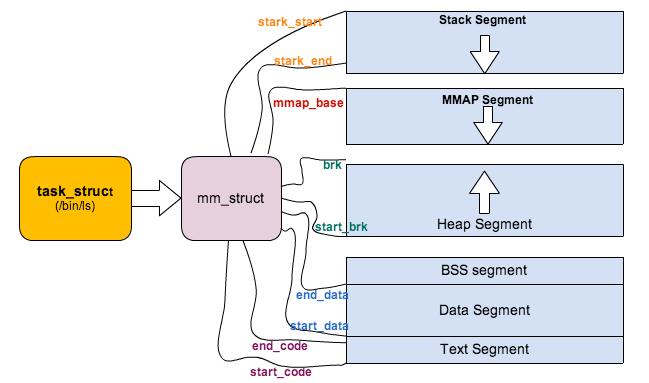
Linux对于内存的管理涉及到非常多的方面,这篇文章首先从对进程虚拟地址空间的管理说起。(所依据的代码是2.6.32.60)
- 215 atomic_t mm_users; /* How many users with user space? */
- 216 atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
这两个counter乍看好像差不多,那Linux使用中有什么区别呢?看代码就是最好的解释了。

- 681static int copy_mm(unsigned long clone_flags, struct task_struct * tsk)
- 682{
- 683 struct mm_struct * mm, *oldmm;
- 684 int retval;
- 692 tsk->mm = NULL;
- 693 tsk->active_mm = NULL;
- 694
- 695 /*
- 696 * Are we cloning a kernel thread?
- 697 *
- 698 * We need to steal a active VM for that..
- 699 */
- 700 oldmm = current->mm;
- 701 if (!oldmm)
- 702 return 0;
- 703
- 704 if (clone_flags & CLONE_VM) {
- 705 atomic_inc(&oldmm->mm_users);
- 706 mm = oldmm;
- 707 goto good_mm;
- 708 }
无论我们在调用fork,vfork,clone的时候最终会调用do_fork函数,区别在于vfork和clone会给copy_mm传入一个CLONE_VM的flag,这个标识表示父子进程都运行在同样一个‘虚拟地址空间’上面(在Linux称之为lightweight process或者线程),当然也就共享同样的物理地址空间(Page Frames)。
copy_mm函数中,如果创建线程中有CLONE_VM标识,则表示父子进程共享地址空间和同一个内存描述符,并且只需要将mm_users值+1,也就是说mm_users表示正在引用该地址空间的thread数目,是一个thread level的counter。
mm_count呢?mm_count的理解有点复杂。
对Linux来说,用户进程和内核线程(kernel thread)都是task_struct的实例,唯一的区别是kernel thread是没有进程地址空间的,内核线程也没有mm描述符的,所以内核线程的tsk->mm域是空(NULL)。内核scheduler在进程context switching的时候,会根据tsk->mm判断即将调度的进程是用户进程还是内核线程。但是虽然thread thread不用访问用户进程地址空间,但是仍然需要page table来访问kernel自己的空间。但是幸运的是,对于任何用户进程来说,他们的内核空间都是100%相同的,所以内核可以’borrow'上一个被调用的用户进程的mm中的页表来访问内核地址,这个mm就记录在active_mm。
简而言之就是,对于kernel thread,tsk->mm == NULL表示自己内核线程的身份,而tsk->active_mm是借用上一个用户进程的mm,用mm的page table来访问内核空间。对于用户进程,tsk->mm == tsk->active_mm。
为了支持这个特别,mm_struct里面引入了另外一个counter,mm_count。刚才说过mm_users表示这个进程地址空间被多少线程共享或者引用,而mm_count则表示这个地址空间被内核线程引用的次数+1。
比如一个进程A有3个线程,那么这个A的mm_struct的mm_users值为3,但是mm_count为1,所以mm_count是process level的counter。维护2个counter有何用处呢?考虑这样的scenario,内核调度完A以后,切换到内核内核线程B,B ’borrow' A的mm描述符以访问内核空间,这时mm_count变成了2,同时另外一个cpu core调度了A并且进程A exit,这个时候mm_users变为了0,mm_count变为了1,但是内核不会因为mm_users==0而销毁这个mm_struct,内核只会当mm_count==0的时候才会释放mm_struct,因为这个时候既没有用户进程使用这个地址空间,也没有内核线程引用这个地址空间。
- 449static struct mm_struct * mm_init(struct mm_struct * mm, struct task_struct *p)
- 450{
- 451 atomic_set(&mm->mm_users, 1);
- 452 atomic_set(&mm->mm_count, 1);
在初始化一个mm实例的时候,mm_users和mm_count都被初始化为1。
- 2994/*
- 2995 * context_switch - switch to the new MM and the new
- 2996 * thread's register state.
- 2997 */
- 2998static inline void
- 2999context_switch(struct rq *rq, struct task_struct *prev,
- 3000 struct task_struct *next)
- 3001{
- 3002 struct mm_struct *mm, *oldmm;
- 3003
- 3004 prepare_task_switch(rq, prev, next);
- 3005 trace_sched_switch(rq, prev, next);
- 3006 mm = next->mm;
- 3007 oldmm = prev->active_mm;
- 3014
- 3015 if (unlikely(!mm)) {
- 3016 next->active_mm = oldmm;
- 3017 atomic_inc(&oldmm->mm_count);
- 3018 enter_lazy_tlb(oldmm, next);
- 3019 } else
- 3020 switch_mm(oldmm, mm, next);
- 3021
上面的代码是Linux scheduler进行的context switch的一小段,从unlike(!mm)开始,next->active_mm = oldmm表示如果将要切换倒内核线程,则‘借用’前一个拥护进程的mm描述符,并把他赋给active_mm,重点是将‘借用’的mm描述符的mm_counter加1。
下面我们看看在fork一个进程的时候,是怎样处理的mm_struct的。
- 1362/*
- 1363 * Ok, this is the main fork-routine.
- 1364 *
- 1365 * It copies the process, and if successful kick-starts
- 1366 * it and waits for it to finish using the VM if required.
- 1367 */
- 1368long do_fork(unsigned long clone_flags,
- 1369 unsigned long stack_start,
- 1370 struct pt_regs *regs,
- 1371 unsigned long stack_size,
- 1372 int __user *parent_tidptr,
- 1373 int __user *child_tidptr)
- 1374{
- 1417 p = copy_process(clone_flags, stack_start, regs, stack_size,
- 1418 child_tidptr, NULL, trace);
do_fork调用copy_process。
- 973/*
- 974 * This creates a new process as a copy of the old one,
- 975 * but does not actually start it yet.
- 976 *
- 977 * It copies the registers, and all the appropriate
- 978 * parts of the process environment (as per the clone
- 979 * flags). The actual kick-off is left to the caller.
- 980 */
- 981static struct task_struct *copy_process(unsigned long clone_flags,
- 982 unsigned long stack_start,
- 983 struct pt_regs *regs,
- 984 unsigned long stack_size,
- 985 int __user *child_tidptr,
- 986 struct pid *pid,
- 987 int trace)
- 988{
- 1155 if ((retval = copy_mm(clone_flags, p)))
- 1156 goto bad_fork_cleanup_signal;
copy_process调用copy_mm,下面来分析copy_mm。
- 681static int copy_mm(unsigned long clone_flags, struct task_struct * tsk)
- 682{
- 683 struct mm_struct * mm, *oldmm;
- 684 int retval;
- 685
- 686 tsk->min_flt = tsk->maj_flt = 0;
- 687 tsk->nvcsw = tsk->nivcsw = 0;
- 688#ifdef CONFIG_DETECT_HUNG_TASK
- 689 tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw;
- 690#endif
- 691
- 692 tsk->mm = NULL;
- 693 tsk->active_mm = NULL;
- 694
- 695 /*
- 696 * Are we cloning a kernel thread?
- 697 *
- 698 * We need to steal a active VM for that..
- 699 */
- 700 oldmm = current->mm;
- 701 if (!oldmm)
- 702 return 0;
- 703
- 704 if (clone_flags & CLONE_VM) {
- 705 atomic_inc(&oldmm->mm_users);
- 706 mm = oldmm;
- 707 goto good_mm;
- 708 }
- 709
- 710 retval = -ENOMEM;
- 711 mm = dup_mm(tsk);
- 712 if (!mm)
- 713 goto fail_nomem;
- 714
- 715good_mm:
- 716 /* Initializing for Swap token stuff */
- 717 mm->token_priority = 0;
- 718 mm->last_interval = 0;
- 719
- 720 tsk->mm = mm;
- 721 tsk->active_mm = mm;
- 722 return 0;
- 723
- 724fail_nomem:
- 725 return retval;
- 726}
692,693行,对子进程或者线程的mm和active_mm初始化(NULL)。
700 - 708行,就是我们上面说的如果是创建线程,则新线程共享创建进程的mm,所以不需要进行下面的copy操作。
重点就是711行的dup_mm(tsk)。
- 621/*
- 622 * Allocate a new mm structure and copy contents from the
- 623 * mm structure of the passed in task structure.
- 624 */
- 625struct mm_struct *dup_mm(struct task_struct *tsk)
- 626{
- 627 struct mm_struct *mm, *oldmm = current->mm;
- 628 int err;
- 629
- 630 if (!oldmm)
- 631 return NULL;
- 632
- 633 mm = allocate_mm();
- 634 if (!mm)
- 635 goto fail_nomem;
- 636
- 637 memcpy(mm, oldmm, sizeof(*mm));
- 638
- 639 /* Initializing for Swap token stuff */
- 640 mm->token_priority = 0;
- 641 mm->last_interval = 0;
- 642
- 643 if (!mm_init(mm, tsk))
- 644 goto fail_nomem;
- 645
- 646 if (init_new_context(tsk, mm))
- 647 goto fail_nocontext;
- 648
- 649 dup_mm_exe_file(oldmm, mm);
- 650
- 651 err = dup_mmap(mm, oldmm);
- 652 if (err)
- 653 goto free_pt;
- 654
- 655 mm->hiwater_rss = get_mm_rss(mm);
- 656 mm->hiwater_vm = mm->total_vm;
- 657
- 658 if (mm->binfmt && !try_module_get(mm->binfmt->module))
- 659 goto free_pt;
- 660
- 661 return mm;
633行,用slab分配了mm_struct的内存对象。
637行,对子进程的mm_struct进程赋值,使其等于父进程,这样子进程mm和父进程mm的每一个域的值都相同。
在copy_mm的实现中,主要是为了实现unix COW的语义,所以理论上我们只需要父子进程mm中的start_x和end_x之类的域(像start_data,end_data)相等,而对其余的域(像mm_users)则需要re-init,这个操作主要在mm_init中完成。
- 449static struct mm_struct * mm_init(struct mm_struct * mm, struct task_struct *p)
- 450{
- 451 atomic_set(&mm->mm_users, 1);
- 452 atomic_set(&mm->mm_count, 1);
- 453 init_rwsem(&mm->mmap_sem);
- 454 INIT_LIST_HEAD(&mm->mmlist);
- 455 mm->flags = (current->mm) ?
- 456 (current->mm->flags & MMF_INIT_MASK) : default_dump_filter;
- 457 mm->core_state = NULL;
- 458 mm->nr_ptes = 0;
- 459 set_mm_counter(mm, file_rss, 0);
- 460 set_mm_counter(mm, anon_rss, 0);
- 461 spin_lock_init(&mm->page_table_lock);
- 462 mm->free_area_cache = TASK_UNMAPPED_BASE;
- 463 mm->cached_hole_size = ~0UL;
- 464 mm_init_aio(mm);
- 465 mm_init_owner(mm, p);
- 466
- 467 if (likely(!mm_alloc_pgd(mm))) {
- 468 mm->def_flags = 0;
- 469 mmu_notifier_mm_init(mm);
- 470 return mm;
- 471 }
- 472
- 473 free_mm(mm);
- 474 return NULL;
- 475}
其中特别要关注的是467 - 471行的mm_alloc_pdg,也就是page table的拷贝,page table负责logic address到physical address的转换。
拷贝的结果就是父子进程有独立的page table,但是page table里面的每个entries值都是相同的,也就是说父子进程独立地址空间中相同logical address都对应于相同的physical address,这样也就是实现了父子进程的COW(copy on write)语义。
事实上,vfork和fork相比,最大的开销节省就是对page table的拷贝。
而在内核2.6中,由于page table的拷贝,fork在性能上是有所损耗的,所以内核社区里面讨论过shared page table的实现(http://lwn.net/Articles/149888/)。
linux 内存地址空间管理 mm_struct的更多相关文章
- Linux内存管理的基本框架⭐⭐
Linux内核的映射机制设计成三层,在页面目录和页面表中间增设了一层“中间目录”.在代码中,页面目录称为PGD,中间目录称为PMD,而页面表称为PT.PT中的表项称为PTE,PTE是“Page Tab ...
- Linux内存技术分析(上)
Linux内存技术分析(上) 一.Linux存储器 限于存储介质的存取速率和成本,现代计算机的存储结构呈现为金字塔型.越往塔顶,存取效率越高.但成本也越高,所以容量也就越小.得益于程序访问的局部性原理 ...
- Linux内存管理4---虚拟地址空间管理
1.前言 本文所述关于内存管理的系列文章主要是对陈莉君老师所讲述的内存管理知识讲座的整理. 本讲座主要分三个主题展开对内存管理进行讲解:内存管理的硬件基础.虚拟地址空间的管理.物理地址空间的管理. 本 ...
- linux内存管理
一.Linux 进程在内存中的数据结构 一个可执行程序在存储(没有调入内存)时分为代码段,数据段,未初始化数据段三部分: 1) 代码段:存放CPU执行的机器指令.通常代码区是共享的,即其它执行程 ...
- Linux是如何管理内存的
物理内存的管理 Linux管理物理内存是使用分页机制实现的.为了使分页机制在32位和64位体系结构下高效工作,Linux采用了一个四级分页策略. Linux支持多种内存分配机制.分配物理内存页框的主要 ...
- Linux之内存描述符mm_struct
Linux对于内存的管理涉及到非常多的方面,这篇文章首先从对进程虚拟地址空间的管理说起.(所依据的代码是2.6.32.60) 无论是内核线程还是用户进程,对于内核来说,无非都是task_struct这 ...
- Linux内存描述之高端内存--Linux内存管理(五)
1. 内核空间和用户空间 过去,CPU的地址总线只有32位, 32的地址总线无论是从逻辑上还是从物理上都只能描述4G的地址空间(232=4Gbit),在物理上理论上最多拥有4G内存(除了IO地址空间, ...
- Linux内存管理 (25)内存sysfs节点解读
1. General 1.1 /proc/meminfo /proc/meminfo是了解Linux系统内存使用状况主要接口,也是free等命令的数据来源. 下面是cat /proc/meminfo的 ...
- Linux内存管理 (3)内核内存的布局图
专题:Linux内存管理专题 关键词:内核内存布局图.lowmem线性映射区.kernel image.ZONE_NORMAL.ZONE_HIGHMEM.swapper_pg_dir.fixmap.v ...
随机推荐
- Linux链接器脚本详解
/* GNU linker script for STM32F405 */ /* Specify the memory areas */ MEMORY { FLASH (rx) : ORIGIN = ...
- jinkens 检查svn更新就构建
以下的配置就是,svn上的文件一旦有变动,一分钟后就会触发jinkens的job(构建)
- Jenkins 第一次访问时提示Unlock Jenkins
Jenkins启动后录入网址提示Unlock Jenkins,To ensure Jenkins is securely set up by the administrator Jenkins启动后, ...
- hive distcp数据同步
-- 同步HDFS数据(shell执行) hadoop distcp \ -Dmapred.job.queue.name=queue_name \ -update \ -skipcrccheck hd ...
- environment与@ConfigurationProperties的关系 加载过程分析
environment是在printBanner之前就初始化好了, 更在context创建之前, 已经加载application-xxxx.properties, System.properties, ...
- 研磨设计模式学习笔记1--简单工厂(SimpleFactory)
需求:实现一个简单工厂,客户端根据需求获取实现类. 简单工厂优点: 客户端不需要知道工厂内部实现,然组件外部实现面向接口编程. 客户端.实现类解耦. 一.接口及实现类 //接口 public inte ...
- html-3
<hr> 下划线实体:想在页面显示被浏览器解析的内容为表格添加标题<caption>跟tr同级,只在<table>下 <link> 为页面加小图标 在& ...
- Mybatis学习笔记8 - resultMap自定义结果集映射规则
一.resultMap自定义结果集映射规则 示例如下: 接口定义: package com.mybatis.dao; import com.mybatis.bean.Employee; public ...
- 关于火狐不响应event.keyCode解决方法
<body onkeydown="enterkey(event)"> <!-- 点击键盘即触发 enterkey函数 --> function enterk ...
- Unity [SerializeField]
在Unity3d中Unity3D 中提供了非常方便的功能可以帮助用户将 成员变量 在Inspector中显示,并且定义Serialize关系. 也就是说凡是显示在Inspector 中的属性都同时具有 ...