OOM导致的备库raylog损坏导致主从复制异常
问题发现
告警数据库出现复制中断,延迟超过100秒
问题排查
复制信息检查,通过’show slave status\G’命令可以查看复制线程详细的工作状态,对于判断复制中断的原因有一些指导性意义。当时的关键信息如下

Slave_IO_State: Waiting for master to send event
Slave_IO_Running: Yes
Slave_SQL_Running: No
Last_Errno: 1594
Last_Error: Relay log read failure: Could not parse relay log event entry. The possible
reasons are: the master's binary log is corrupted (you can check this by running 'mysqlbinlog' on the binary log),
the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a network
problem, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's
relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave.
Seconds_Behind_Master: NULL
Last_IO_Errno: 0
Last_SQL_Errno: 1594
Last_SQL_Error: Relay log read failure: Could not parse relay log event entry. The possible
reasons are: the master's binary log is corrupted (you can check this by running 'mysqlbinlog' on the binary log),
the slave's relay log is corrupted (you can check this by running 'mysqlbinlog' on the relay log), a network
problem, or a bug in the master's or slave's MySQL code. If you want to check the master's binary log or slave's
relay log, you will be able to know their names by issuing 'SHOW SLAVE STATUS' on this slave.
Last_SQL_Error_Timestamp: 180705 11:44:28
从复制信息可以看到,IO 线程正常运行而sql 线程发生了中断,说明日志还在正常传输但是在从库上进行应用时出现了问题;
而从sql 线程的报错信息我们可以发现,导致复制中断的原因是因为有一个日志事件无法解析;中断时间发生的时间是当日的11 时44 分。一般出现这种现象可能来自于网络异常或者mysql 本身的bug,或者是空间问题导致的日志文件损坏。
binlog 文件分析
首先要确认无法解析的event 是来自master 的binary log 还是slave 的relay log,因此需要分别对主备库的日志文件进行分析。
根据show slave status\G 输出中sql 线程的工作位点,使用mysqlbinlog 对下一个event进行解析。
分析结果发现主库上的binlog 可以正常解析,而在对备库上的relay log 进行解析时发生了报错:
Error in Log_event::read_log_event(): ‘read error’, data_len: 2197897, event_type
解析binlog 的命令如下:
mysqlbinlog -vv –base64-output=DECODE-ROWS –start-position=? filename > output_filename
从对binlog 的分析结果,可以说明IO 线程在主库上正常读取了下一个需要执行的event,而传到备库并写入relay log 时出现了问题,由于relay log 中存储的该event 无法解析,进而导致sql 线程的工作报错。
那么,在写入slave 的relay log 时,到底发生了什么?
MySQL Error log
接下来分析复制发生中断时间段的error log,看看数据库本身有没有出现异常的状况。从下面的日志可以看到,在当天的11:44,该数据库发生了一次重启操作,而这个重启操作发生在第一次日志解析报错之前。

关于数据库关闭导致的复制中断,官方有相应说法,如下
Unclean shutdowns might produce problems, especially if the disk cache was not flushed to disk
before the problem occurred:
For transactions, the slave commits and then updates relay-log.info. If a crash occurs between these two
operations, relay log processing will have proceeded further than the information file indicates and the
slave will re-execute the events from the last transaction in the relay log after it has been restarted.
A similar problem can occur if the slave updates relay-log.info but the server host crashes before the write
has been flushed to disk. To minimize the chance of this occurring, set sync_relay_log_info=1 in the slave
my.cnf file. The default value of sync_relay_log_info is 0, which does not cause writes to be forced to disk;
the server relies on the operating system to flush the file from time to time.
也就是说,在从库发生异常关闭时可能会导致relay log 写入不完整,从而出现类似问题。但是这里看起来很像是正常的重启操作。
OS message log
查看当天OS 的message log,发现在mysqld 进程重启之前触发了OS 的oom-killer 事件,具体信息如下:

原因总结
mysqld 进程占用过大内存导致发生OOM,异常关闭导致relay log 写入丢失,造成部分event 不完整。sql 线程无法解析下一个event 时发生复制中断。
问题处理
首先对从库的事务进行了跳过处理。操作如下:
通过show slave status\G 找到下一个要执行的GTID 号.
STOP SLAVE;
SET gtid_next = ‘下一个事务GTID’;
BEGIN;COMMIT;
SET gtid_next = ‘AUTOMATIC’;
START SLAVE;
发现事务虽然跳过了一个,但是报错仍然继续。说明文件损坏导致后面的event 也无法正常解析。
重新拉取binlog。操作如下:
stop slave;
reset slave;
change master to
master_host=’host_ip’,master_port=port,master_user=’user_name’,master_password=’user_pass’,master_auto_position=1;
start slave;
注:reset slave 会清空io 线程以及sql 线程的工作记录,包括日志位点以及备库的relay log,
master_auto_position 参数会让io 线程从目前已执行过的event 之后开始读取主库的binlog。
人工修复不一致的数据。
由于前面跳过了一个event,因此这里需要人工将这个event 补进备库中。具体操作如下:
##主库上解析出这个事务
/opt/mysql/bin/mysqlbinlog -vv –base64-output=DECODE-ROWS –include-gtids=’uuid:n’
mysql-bin.006408 >two_tran.txt
##编辑这个文件,变成可直接执行的sql 脚本,如下
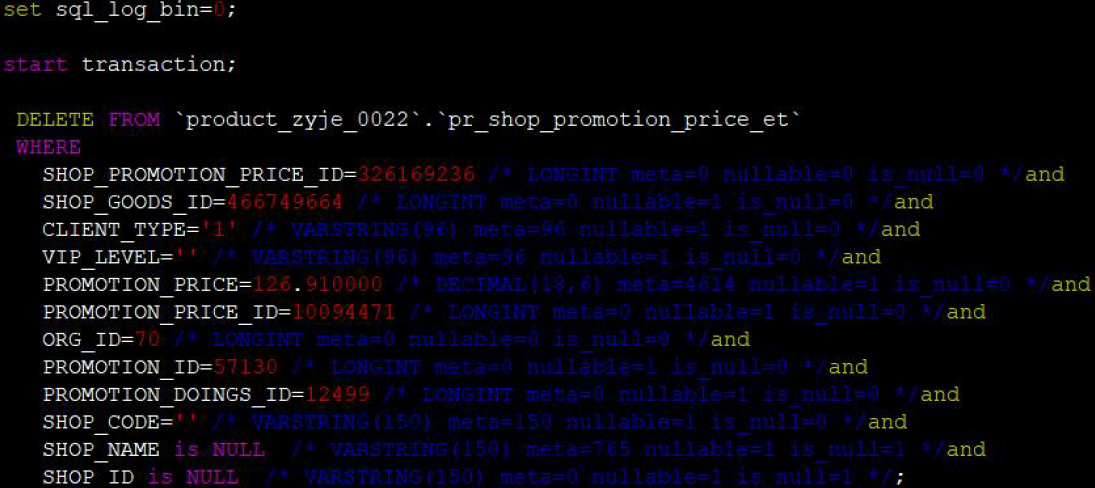
预防建议
1、配置监控告警,以便及时获取复制状态异常的情况
2、尽快调整相关内存参数,主要是innodb_buffer_pool_size.
3、Master/Slave 重启或关闭前先正常关闭备库的复制线程. stop slave
4、设置从库数据库参数(sync_relay_log=1,sync_relay_log_info=1),可提高备库的数据安全性,但是会降低复制效率以及提高系统io 负载
5、尽量少使用text 或者blob 大字段,所有表都创建主键以及使用innodb 存储引擎,适当调大数据参数max_allowed_packet 的值(发现经常出现dump线程闪断的情况)
OOM导致的备库raylog损坏导致主从复制异常的更多相关文章
- 什么时候会刷新备库控制文件refresh the standby database control file?
通过合理的设置,对于Primary的绝大数操作,都是可以传递到Physical Standby,datafile的操作是通过STANDBY_FILE_MANAGEMENT参数来控制的,但是即使STAN ...
- 案例:DG主库未设置force logging导致备库坏块
DG搭建时,官方文档手册有明确提到要设置数据库为force_logging,防止有nologging操作日志记录不全导致备库应用时出现问题. 虽然是老生常谈的安装规范,但现实中总会遇到不遵守规范的场景 ...
- 【转载】mysql主键的缺少导致备库hang
最近线上频繁的出现slave延时的情况,经排查发现为用户在删除数据的时候,由于表主键的主键的缺少,同时删除条件没有索引,或或者删除的条件过滤性极差,导致slave出现hang住,严重的影响了生产环境的 ...
- mysql主键的缺少导致备库hang
最近线上频繁的出现slave延时的情况,经排查发现为用户在删除数据的时候,由于表主键的主键的缺少,同时删除条件没有索引,或或者删除的条件过滤性极差,导致slave出现hang住,严重的影响了生产环境的 ...
- MySQL实例多库某张表数据文件损坏导致xxx库无法访问故障恢复
一.问题发现 命令行进入数据库实例手动给某张表进行alter操作,发现如下报错. mysql> use xx_xxx; No connection. Trying to reconnect... ...
- KingbaseES R3 集群删除test库导致主备无法切换问题
案例说明: 在KingbaseES R3集群中,kingbasecluster进程会通过test库访问,连接后台数据库服务测试:如果删除test数据库,导致后台数据库服务访问失败,在集群主备切换时,无 ...
- DG备库磁盘空间满导致无法创建归档
上周五去某客户那里做数据库巡检.是window 2008系统上10g的一套NC系统的库,已经配置了DG,可是巡检时发现数据库报错: Tue Nov 11 10:13:57 2014 LNS: Stan ...
- vss的ss.ini丢失或损坏导致的vss无法登录错误
vss的ss.ini丢失或损坏导致的vss无法登录错误 Written in 2007-07-03 18:17 在vss使用过程中,不知道什么原因,会导至vss目录中的ss.ini文件损坏,此文件位于 ...
- 对“demo!demo.Index+HookProc::Invoke”垃圾收集的类型已委托回调。这可能会导致应用程序崩溃、损坏和数据丢失。当传递委托给非托管代码,托管应用程序必须让这些委托保持活着
对"demo!demo.Index+HookProc::Invoke"垃圾收集的类型已委托回调.这可能会导致应用程序崩溃.损坏和数据丢失.当传递委托给非托管代码,托管应用程序必须承 ...
随机推荐
- DataFrame的数据类型转换
dfxxx['username']=pd.to_numeric(dfxxx['username'],errors='coerce')#将不能转换数据类型的值强制转换成NaN dfxxx['userna ...
- leetcode 627. Swap Salary 数据库带判断的更新操作
https://leetcode.com/problems/swap-salary/description/ 用 set keyWord = Case depentedWord when haha ...
- [转]jQuery调用ASPX返回json
本文转自:http://www.cnblogs.com/fire-phoenix/archive/2009/11/13/1614146.html 本文介绍如何在ASP.NET(ASP.NET/AJAX ...
- 微信web开发者工具 && 微信调试页面
微信开发者工具 做微信公众号的过程中,自然避免不了登录账号然后进行调试,但是在chrome上我们没有办法登录,这是一个令人头疼的问题,比如这个公众号网页,只会提示出错,因为开发者限制了公众号网页的登录 ...
- jenkins自动打IOS包(转发)
投稿文章,作者:一缕殇流化隐半边冰霜(@halfrost) 前言 众所周知,现在App的竞争已经到了用户体验为王,质量为上的白热化阶段.用户们都是很挑剔的.如果一个公司的推广团队好不容易砸了重金推广了 ...
- Missing artifact jdk.tools:jdk.tools:jar:1.6
今天从svn上面下载了一个mavan项目,出现Missing artifact jdk.tools:jdk.tools:jar:1.6 这个错误. 怎么解决了,在我的根pom.xml 下加入这个依赖就 ...
- 本机访问其它电脑上的oracle数据库
最近发现很多人问到怎么才能访问别人机子上的oracle,这里来给大家做个示范 借助工具的话,oracle就自己带了两个配置和移值助手下面:net configuration assistant 和ne ...
- 网页URLs
Extending Python Interpretor: https://docs.python.org/3/extending/index.html Aliyun Mriirors: https: ...
- HDU 4512——吉哥系列故事——完美队形I——————【LCIS应用】
吉哥系列故事——完美队形I Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others)Tot ...
- Lua 遍历Linux目录下的文件夹
代码如下,里面有注释,应该能看懂. function getFile(file_name) local f = assert(io.open(file_name, 'r')) local string ...