hadoop研究:mapreduce研究前的准备工作
继续研究hadoop,有童鞋问我,为啥不接着写hive的文章了,原因主要是时间不够,我对hive的研究基本结束,现在主要是hdfs和mapreduce,能写文章的时间也不多,只有周末才有时间写文章,所以最近的文章都是写hdfs和mapreduce。不过hive是建立在hdfs和mapreduce之上,研究好hdfs和mapreduce也是真正用好hive的前提。
今天的内容是mapreduce,经过这么长时间的学习,我对hadoop的相关技术理解更加深入了,这回我会尽全力讲解好mapreduce。
第一篇文件时研究mapreduce前的准本工作。
研究hadoop的准备工作
要研究好hadoop,一定得有个完善的开发环境(对任何编程技术都是这样的,因为it技术是一个实践技术,光看书是很难对it技术有深入的理解)。我现在为自己建立的开发环境包括:
在公司
用4台服务器搭建了一个hadoop集群,里面装好了hdfs,mapreduce,hive和hbase,工作机上为eclipse安装了mapreduce插件,可以在本地开发mapreduce程序,执行时候可以远程调用搭建好的hadoop集群(缺憾是远程调试没有部署好,但是我觉得大部分开发使用本地调试就足够)。Hadoop集群的安装,博客园里虾皮的博客写的十分全面,这里我就不在累述了,贴出虾皮博文的地址:
http://www.cnblogs.com/xia520pi/archive/2012/05/16/2503949.html
至于eclipse插件的问题,我在后面会做详细论述。
在我自己笔记本里
在window7系统下安装了一个hadoop伪分布式的集群,不过这个集群不太好,非常慢,可能是我电脑配置太低了,伪分布式的安装我就不做描述了,实际意义不大,因为我觉得要是真想研究hadoop还是使用linux安装真实集群比较好,不过根据我个人实践伪分布式安装我碰到的问题最多,如果有些童鞋想在windows下安装个伪分布式系统玩玩,碰到啥问题不知道怎么解决,可以加入我建立的QQ群,我有空会在群里解答。在我自己电脑里我也安装了eclipse插件,连接本地伪分布式集群。
Hadoop的eclipse插件的制作
这里我要重点讲讲hadoop的eclipse插件的制作。我最早安装hadoop的eclipse插件时候是从网上下载的,当时我搭建集群上使用的hadoop版本是1.0.4,下载到的插件式1.0版本以下,安装到eclipse里面后没办法正常使用,因此我研究了下hadoop的eclipse插件生成的技术,下面我就阐述如何制作hadoop的eclipse插件。
Hadoop的eclipse插件包含在hadoop的安装包(这个安装包是指包含源程序的安装包,不是指二进制的安装包),如下图所示:

大家解压程序后,找到下面的文件夹,我的笔记本里路径是:
E:\hadooptest\hadoop-1.1.2\src\contrib\eclipse-plugin
这下面放的就是eclipse插件的相关程序。
制作eclipse插件前我们要确认自己电脑是不是安装了jdk,jdk的版本一定要1.6以上,还要安装ant,这两个都安装好后就可以开始制作eclipse插件了。
首先要改下相关的配置文件:
第一个配置文件:
E:\hadooptest\hadoop-1.1.2\src\contrib\eclipse-plugin\build.xml
在<target name="jar" depends="compile" unless="skip.contrib">下面加入:
- <copy file="${hadoop.root}/lib/commons-configuration-1.6.jar" todir="${build.dir}/lib" verbose="true"/>
- <copy file="${hadoop.root}/lib/commons-lang-2.4.jar" todir="${build.dir}/lib" verbose="true"/>
- <copy file="${hadoop.root}/lib/jackson-core-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/>
- <copy file="${hadoop.root}/lib/jackson-mapper-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/>
- <copy file="${hadoop.root}/lib/commons-httpclient-3.0.1.jar" todir="${build.dir}/lib" verbose="true"/>
在build.xml文件里我们发现,它还依赖:E:\hadooptest\hadoop-1.1.2\src\contrib\ build-contrib.xml文件,在该文件里我们也要做相应的修改,这个修改很简单,修改这个配置即可:
- <property name="hadoop.root" location="E:/hadooptest/hadoop-1.1.2"/>
Location指向你本地安装的hadoop路径。
还有个文件要做相应的修改,文件路径是:
E:\hadooptest\hadoop-1.1.2\src\contrib\eclipse-plugin\META-INF\MANIFEST.MF,
修改的选项是Bundle-ClassPath:下面的内容,我的修改是:
- Bundle-ClassPath: classes/,lib/hadoop-core-1.1.2.jar,lib/commons-cli-1.2.jar,commons-configuration-1.6.jar,commons-lang-2.4.jar,jackson-core-asl-1.8.8.jar,jackson-mapper-asl-1.8.8.jar,commons-httpclient-3.0.1.jar
这样所有的配置都配好了,下面我们使用ant命令来生成eclipse插件,首先我们要打开命令行的操作界面,使用cmd开启,如果将路径定位到E:\hadooptest\hadoop-1.1.2\src\contrib\eclipse-plugin\,输入如下命令:
- ant –Declipse-home= E:\work\eclipse-jee-juno-win32\eclipse -Dversion=1.1.
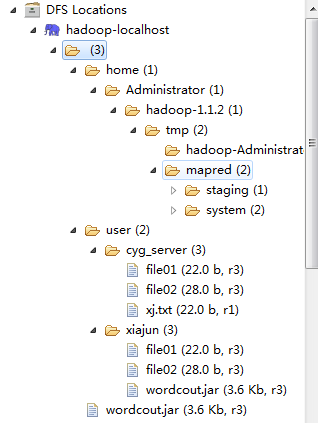
运行成功后,就会在 E:\hadooptest\hadoop-1.1.2\src\contrib\eclipse-plugin目录下生成eclipse插件的jar包,我们将生成的jar包复制到E:\work\eclipse-jee-juno-win32\eclipse\plugins文件夹下,重新启动eclipse,插件就安装成功了,该插件的目的是本地编写的mapreduce程序可以远程调用集群上的hadoop应用,下面是我安装好的eclipse插件的界面:
图片一:
图片二:
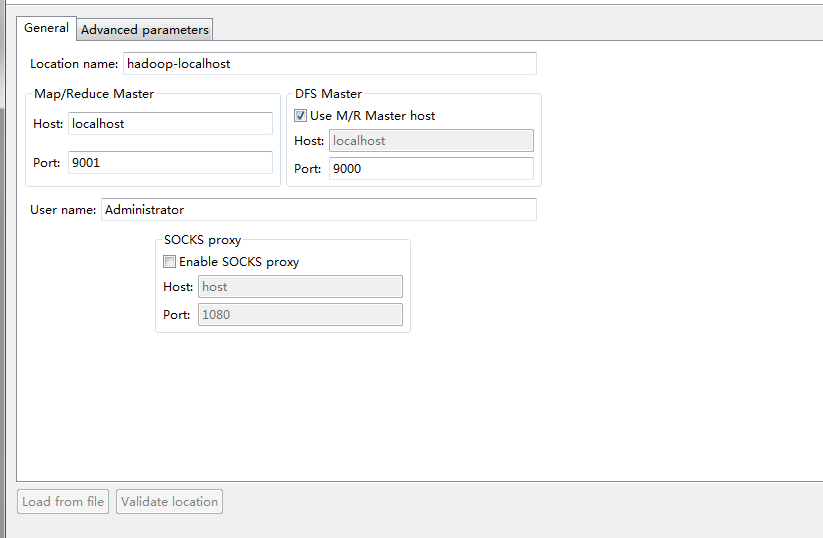
生成时候要注意的问题:
- hadoop的不同版本需要针对不同版本的eclipse插件,一般版本不对应,eclipse插件可能不能正常的使用,如果有些童鞋不想自己生成,那么就得在网路上下载对应的版本的eclipse插件,要是想自己制作,就得在自己使用的hadoop版本下生成eclipse插件。
- 制作eclipse插件时候,我们也会指定eclipse.home的路径,这就会导致插件制作时候对eclipse版本相关,我制作插件时候,在我自己的笔记本上使用的是Juno版本,那么它在Juno版本下安装插件没有任何问题,在公司电脑里使用的eclipse版本是helio版本,我发现生成的插件不能在Juno下正常安装,当然这个问题是否真的按我所述,我也不能完全确定,但至少我实践中觉得版本还是很重要。
Eclipse开发环境读取源码的方式
It行业的竞争越来越激烈,it公司对程序员的要求也越来越高,很多公司重要岗位都要求程序员研究过某某程序的源码,但是我们专门去读源码其实是一件很困难的事情,除非你对这个框架使用极其熟悉,要不一定是越看越迷糊,越看越没信心,如果我们可以把学习某个框架编程同时也能读读源码的程序,这样操作一定会对你的学习事半功倍。
下面我将我的一个经验贴出来,这个方式很简单,很多人都使用到,但是可能都没留意,具体如下:
首先我建一个工程JavaJar,如图所示:
代码如下:
- package cn.com.jar;
- import java.util.StringTokenizer;
- public class StringJar {
- public String line;
- public StringJar(String line) {
- super();
- this.line = line;
- }
- public String testftn(){
- String strs = null;
- StringTokenizer st = new StringTokenizer(line);
- while(st.hasMoreElements()){
- strs += st.nextToken() + "@!@";
- }
- return strs;
- }
- public static void main(String[] args) {
- StringJar jar = new StringJar("I am XXX hello world");
- System.out.println(jar.testftn());
- }
- }
然后我将工程编译成一个jar包,如图所示:
下面,我再建一个工程:testprj,导入该jar包,如图所示:
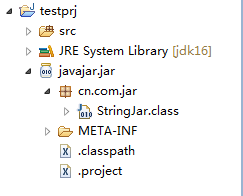
我们编写测试程序,如下所示:
- package cn.com.test;
- import cn.com.jar.StringJar;
- public class TestMain {
- /**
- * @param args
- */
- public static void main(String[] args) {
- StringJar jar = new StringJar("I am XXX hello world");
- System.out.println(jar.testftn());
- }
- }
下面我将StringJar类移入到testprj工程,如图所示:
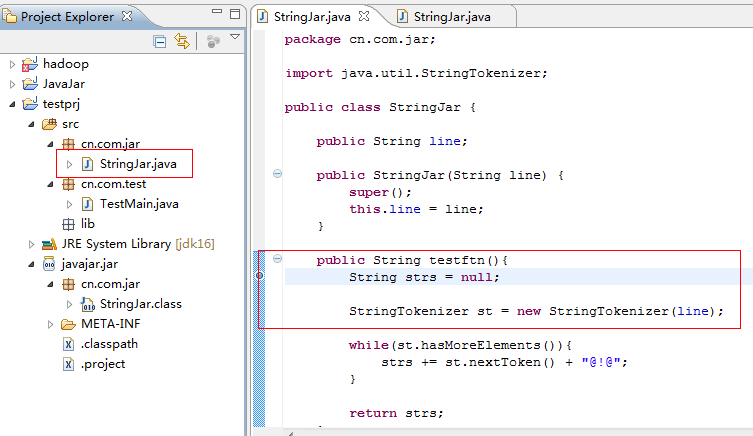
我们在程序里设置断点,再debug运行程序,我们会发现,断点进入了。
由上面的现象给我一个启示,我们使用插件编写mapreduce程序时候,如果我们对某些代码感兴趣,就把源码放到工程里,可以有针对的进行调试。当然有些童鞋会说把源码直接导入到eclipse里面,不是全有了吗?我觉得那样做法不是太清晰,有针对的放入源码能缩小我们学习的范围,更有针对性。
此外,hadoop远程调用时候很容易会不能正常运行,这个时候需要更改源码,如果我们没有上面的方式,那么我们就必须重新编译hadoop-core-XXX.jar包,这就增加了操作难度,那么上面的操作方式会给我们带来便利,例如下图所示:
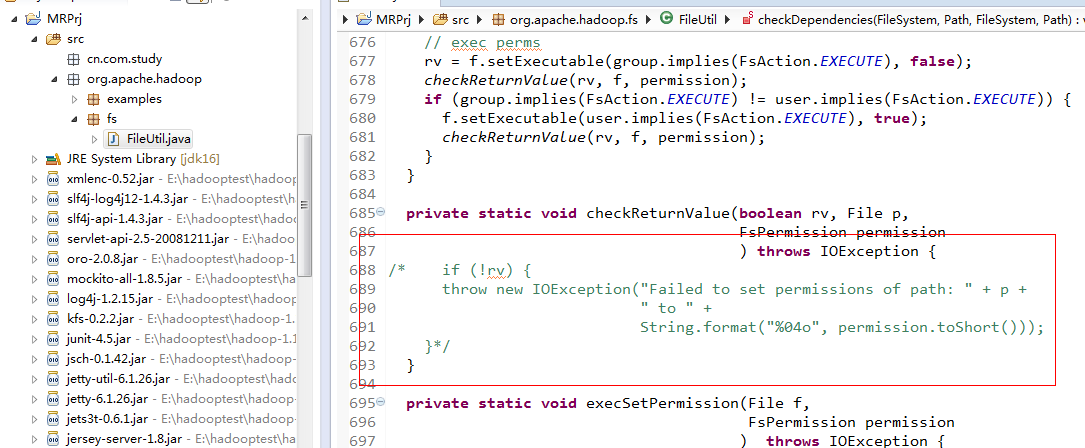
红框里面就是我注释的代码。
好了,早上的文章写完了,下午我将详细讲解我对mapreduce的理解。
hadoop研究:mapreduce研究前的准备工作的更多相关文章
- 从Hadoop骨架MapReduce在海量数据处理模式(包括淘宝技术架构)
从hadoop框架与MapReduce模式中谈海量数据处理 前言 几周前,当我最初听到,以致后来初次接触Hadoop与MapReduce这两个东西,我便稍显兴奋,认为它们非常是神奇.而神奇的东西常能勾 ...
- Hadoop基础-MapReduce的Combiner用法案例
Hadoop基础-MapReduce的Combiner用法案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.编写年度最高气温统计 如上图说所示:有一个temp的文件,里面存放 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- Hadoop基础-MapReduce的排序
Hadoop基础-MapReduce的排序 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce的排序分类 1>.部分排序 部分排序是对单个分区进行排序,举个 ...
- Hadoop基础-MapReduce的工作原理第一弹
Hadoop基础-MapReduce的工作原理第一弹 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在本篇博客中,我们将深入学习Hadoop中的MapReduce工作机制,这些知识 ...
- hadoop(二MapReduce)
hadoop(二MapReduce) 介绍 MapReduce:其实就是把数据分开处理后再将数据合在一起. Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理.可以进行拆分的前提是这 ...
- 李洪强iOS开发之-环信01_iOS SDK 前的准备工作
李洪强iOS开发之-环信01_iOS SDK 前的准备工作 1.1_注册环信开发者账号并创建后台应用 详细步骤: 注册并创建应用 注册环信开发者账号 第 1 步:在环信官网上点击“即时通讯云”,并点 ...
- 用PHP编写Hadoop的MapReduce程序
用PHP编写Hadoop的MapReduce程序 Hadoop流 虽然Hadoop是用Java写的,但是Hadoop提供了Hadoop流,Hadoop流提供一个API, 允许用户使用任何语言编 ...
- Hadoop之MapReduce程序应用三
摘要:MapReduce程序进行数据去重. 关键词:MapReduce 数据去重 数据源:人工构造日志数据集log-file1.txt和log-file2.txt. log-file1.txt内容 ...
随机推荐
- LINUX 如何开放端口和关闭端口/jps/sudo命令
1 在java的根目录下用java的jps查看:============================================================================ ...
- Linux(Ubuntu 14.0)
开始了Mono的学习.学习了Mono for Android之后,编译一些小的APK,总发现这些APK文件很大,额,真心不知道为什么,那么,就让我们从头开始学期了,Android是基于Linux的,那 ...
- wifi,网关相关标识的获取
获取WIFI的相关信息 - (void)getWifiInfo { NSArray *ifs = (__bridge_transfer NSArray *)CNCopySupportedInterfa ...
- Cracking-- 4.7 在一颗二叉树中找两个节点的第一个共同祖先
分别记录从 root 到 node1 的path 到 node2的path,再找其中共同的部分 struct Node{ int val; struct Node *left; struct Node ...
- tsql 执行存储过程
https://msdn.microsoft.com/zh-sg/library/ms189915.aspx https://msdn.microsoft.com/en-us/library/ms18 ...
- nginx简易安装
yum -y install perl-ExtUtils-Embed ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx ...
- JS 跨源请求
一个 URL 大概包含的部分:scheme://host:port/path?#hash 比如一个 URL 为 http://www.xxx.com:8888/school/student.html, ...
- iOS开发零基础--Swift教程 可选类型
可选类型的介绍 注意: 可选类型时swift中较难理解的一个知识点 暂时先了解,多利用Xcode的提示来使用 随着学习的深入,慢慢理解其中的原理和好处 概念: 在OC开发中,如果一个变量暂停不使用,可 ...
- 《《我是一只IT小小鸟》》读后感
接触IT也已经半年了,在这半年我没有充足的时间去了解IT这个行业,在大学生职业规划课程上,老师推荐了<<我是一只IT小小鸟>>这本书,我才发现IT这个行业并不是想象的那么无趣, ...
- MacBook 配置
转载 http://www.cnblogs.com/linl/p/4035685.html cordova3.X的部署和环境搭建教程 针对cordova3.0,至现在的3.6都能用. 一.准备工作 ...