gh-ost原理
gh-ost原理
一、三种模式架构图
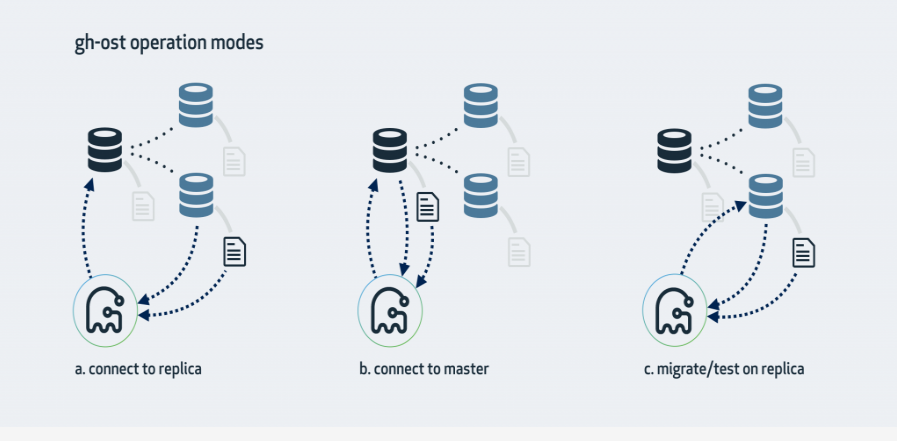
1、连上从库,在主库上修改
这是gh-ost默认的工作模式,它会查看从库情况,找到集群的主库并且连接上去,对主库侵入最少,大体步骤是:
在主库上创建_xxx_gho、_xxx_ghc,并修改_xxx_gho表结构;
从slave上读取二进制日志事件,将变更应用到主库上的_xxx_gho表;
在主库上读源表的数据写入_xxx_gho表中:insert into igore....select;
在主库上完成表切换;
2、直接主库修改
在主库上创建_xxx_gho、_xxx_ghc,并修改_xxx_gho表结构;
从主库上读取二进制日志事件,将变更应用到主库上的_xxx_gho表;
在主库上读源表的数据写入_xxx_gho表中:insert into igore....select;
在主库上完成表切换;
3、在从库上修改和测试
这种模式会在从库上做修改。gh-ost仍然会连上主库,但所有操作都是在从库上做的,不会对主库产生任何影响。在操作过程中,gh-ost也会不时地暂停,以便从库的数据可以保持最新。
--migrate-on-replica选项让gh-ost直接在从库上修改表。最终的切换过程也是在从库正常复制的状态下完成的。
--test-on-replica表明操作只是为了测试目的。在进行最终的切换操作之前,复制会被停止。原始表和临时表会相互切换,再切换回来,最终相当于原始表没被动过。主从复制暂停的状态下,你可以检查和对比这两张表中的数据。
二、原理
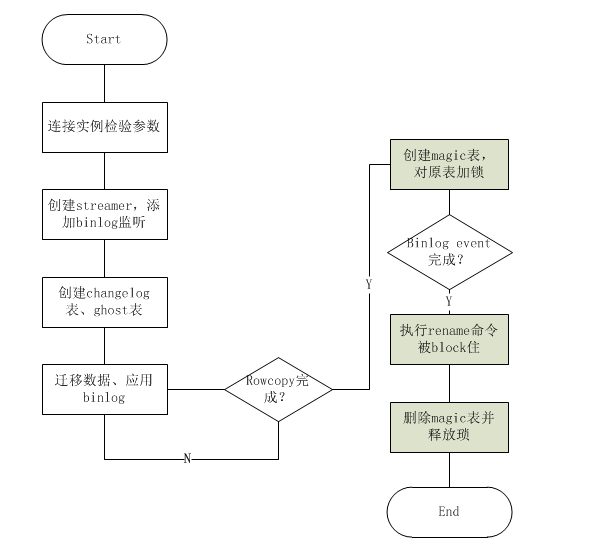
1、检查校验环境
测试db是否可连通,并且验证database是否存在
确认连接实例是否正确
权限验证 show grants for current_user()
binlog验证,包括row格式验证和修改binlog格式后的重启replicate
原表存储引擎,外键,触发器检查,行数预估等
2、创建binlog streamer连接到主库或者从库,添加binlog的监听
3、创建log表_xxx_ghc和ghost表_xxx_gho并修改ghost表结构到最新
4、开始迁移数据:row copy和binlog apply同时进行
1)最小值:select `id` from darren`.`t4` order by id` asc limit 1;
2) 最大值:select `id` from darren`.`t4` order by id` desc limit 1;
3) 计算第一个chunk: select `id` from `darren`.`t4` where `id` >= _binary'1' and `id` <= _binary'58594' order by `id` asc limit 1 offset 999
最后一个chunk如果不足1000,那么上面sql查询为空,这时运行:
select `id` from (
select `id` from `darren`.`t4`
where `id` > _binary'58000' and `id` <= _binary'58594' order by `id` asc limit 1000
) select_osc_chunk
order by `id` desc limit 1;
4)循环插入数据:insert ignore into `darren`.`_t4_gho` (`id`, `name`, `c1`)
(select `id`, `name`, `c1` from `darren`.`t4` force index (`PRIMARY`)
where `id` >= _binary'1' and `id` <= _binary'1000' lock in share mode
)
4.1、rowcopy数据和应用binlog顺序不同是否产生数据冲突
数据迁移过程中sql映射关系:
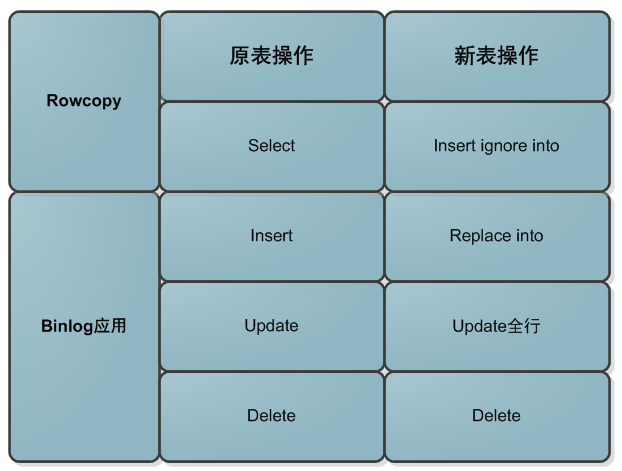
rowcopy和binlog应用各种排列组合:
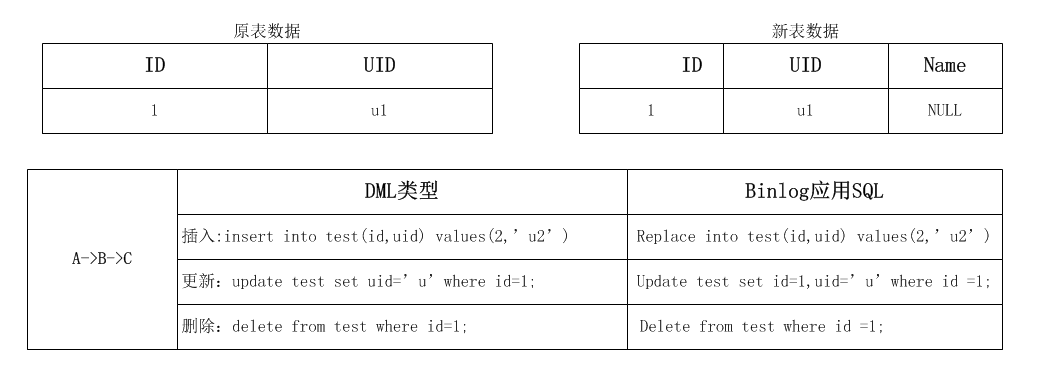
数据迁移过程,涉及三个操作:A:对原表进行rowcopy;B:应用程序的DML;C:应用binlog到新表,因为DML操作才会记录binglog,所以C操作一定在B操作的后面,共有如下几种组合:
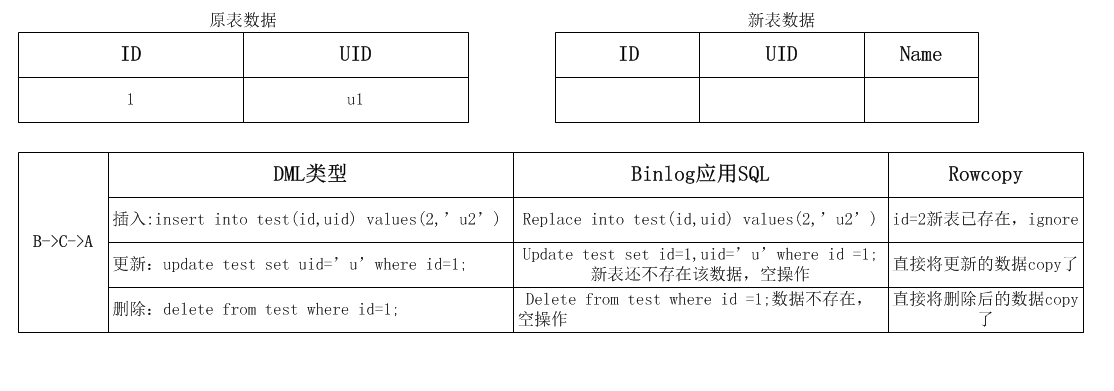
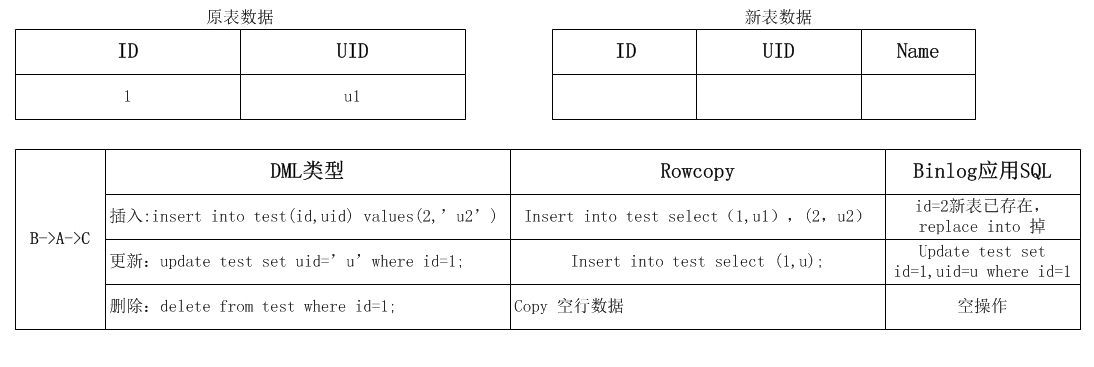
1.insert 操作
binlog是最权威的,gh-ost的原则是以binlog优先,所以无论任何顺序下,数据都是和binlog保持一致,如果rowcopy在后,会insert ignore,如果binlog apply在后会replace into掉。
2.update/delete 操作
对已经rowcopy过的数据,出现对原表的update/delete操作。这时候会全部通过binlog apply执行,注意binlog apply的update是对某一条记录的全部列覆盖更新,所以不会有累加的问题。
对尚未迁移的数据,出现对原表的update/delete操作。这时候对新表的binlog apply会是空操作,具体数据由rowcopy迁移。
特殊情况下:
先对原表更新完以后,rowcopy在binlog apply之前把数据迁移了过去,而在binlog event过来以后,会再次应用,这里有问题?其实结合gh-ost的binlog apply之前把数据迁移了过去,
而在binlog的sql映射规则,insert操作会被replace重新替换掉,update 会更新对应记录全部行,delete 会是空操作。最终数据还是一致的状态。
4.2、binlog同步数据何时结束?
copy完数据向_xxx_ghc写入status:AllEventsUpToLockProcessed:1533533052229905040,当binlogsyncer过滤到该值表示所有event都已应用
5、copy完成后进行原子性cut-over阶段
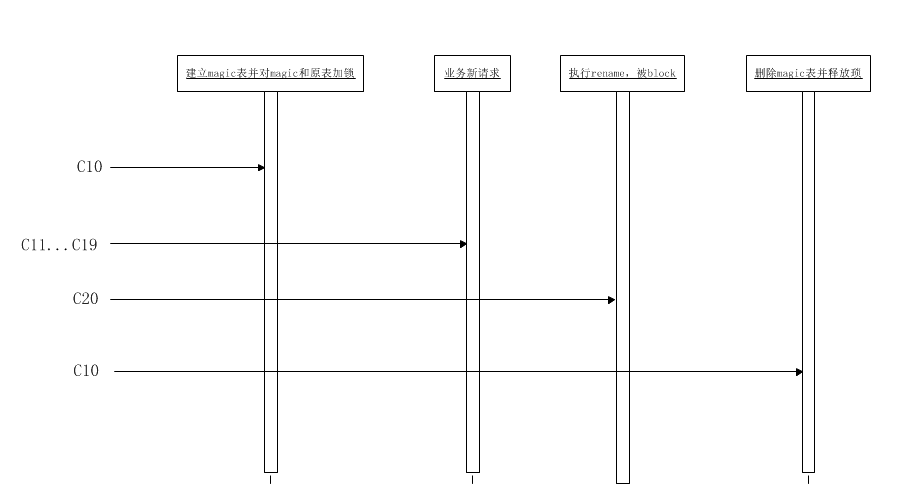
5.1) C10:
创建magic表_xxx_del,目的为了防止过快的进行rename操作和意外情况rename
对源表和magic表_xxx_del加write锁
5.2) C11...C19: 新的请求进来,关于原表的请求被blocked
5.3) C20: 执行:rename table `t4` to `_t4_del`,`_t4_gho` to `t4`;这时被阻塞,timeout:3s。(这一步只有binlog event应用完成后)
5.4) 检查是否有blocked 的RENAME请求,通过show processlist
5.5) C10:
删除magic表(只有show processlist里存在被block的rename才进行)
释放琐
不同阶段失败后如何处理:
如果5.1失败,退出程序,比如建表成功,加锁失败,退出程序,未加锁
rename请求来的时候,会话C10死掉,lock会自动释放,同时因为_xxx_del的存在rename也会失败,所有请求恢复正常
rename被blocked的时候,会话C10死掉,lock会自动释放,同样因为_xxx_del的存在,rename会失败,所有请求恢复正常
C20死掉,gh-ost会捕获不到rename,会话C10继续运行,释放lock,所有请求恢复正常
6、清理战场
7.1) 关闭binlogsyncer连接
7.2) 删除源表和_t4_ghc表gh-ost原理的更多相关文章
- Ghost-无损DDL
目录 一.什么是DDL? 二.表级锁和元数据锁 2.1.什么是表锁? 2.2.什么是MDL? 三.什么是无损DDL? 四.DDL重建表 Mysql5.5之前重建表 Mysql5.6之后重建表 五.gh ...
- 深入解析SQL Server并行执行原理及实践(上)
在成熟领先的企业级数据库系统中,并行查询可以说是一大利器,在某些场景下他可以显著的提升查询的相应时间,提升用户体验.如SQL Server, Oracle等, Mysql目前还未实现,而Postgre ...
- 深入解析SQL Server并行执行原理及实践(下)
谈完并行执行的原理,咱们再来谈谈优化,到底并行执行能给我们带来哪些好处,我们又应该注意什么呢,下面展开. Amdahl’s Law 再谈并行优化前我想有必要谈谈阿姆达尔定律,可惜老爷子去年已经驾鹤先 ...
- docker核心原理
容器概念. docker是一种容器,应用沙箱机制实现虚拟化.能在一台宿主机里面独立多个虚拟环境,互不影响.在这个容器里面可以运行着我饿们的业务,输入输出.可以和宿主机交互. 使用方法. 拉取镜像 do ...
- 第三方cookie与搜索引擎+网站广告原理
cookie 摘自 : http://www.williamlong.info/archives/3125.html 关于cookie的安全知识 :http://shaoshuai.me/tech/2 ...
- SpringBoot启动原理及相关流程
一.springboot启动原理及相关流程概览 springboot是基于spring的新型的轻量级框架,最厉害的地方当属自动配置.那我们就可以根据启动流程和相关原理来看看,如何实现传奇的自动配置 二 ...
- 并发编程(十五)——定时器 ScheduledThreadPoolExecutor 实现原理与源码深度解析
在上一篇线程池的文章<并发编程(十一)—— Java 线程池 实现原理与源码深度解析(一)>中从ThreadPoolExecutor源码分析了其运行机制.限于篇幅,留下了Scheduled ...
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- FactoryBean的实现原理与作用
FactoryBean与BeanFactory: 这俩货在拼写上很是相似,很多同学在看IOC源码或者其他地方并不能分清有啥区别,前面的IOC源码中我简单说过,现在统一简单来讲一下: FactoryBe ...
- 20180710使用gh
转自:http://www.ywnds.com/?p=14265 一.背景 GitHub正式宣布以开源的方式发布gh-ost:GitHub的MySQL无触发器在线更改表定义工具!下面是官方给出gh-o ...
随机推荐
- 2-XOR-SAT (种类并查集)
写了那么多模拟题这题算是最难的了QAQ 好神,,,我于是补了一下并查集.. 并查集很神...... orz 种类并查集...orz 对于维护sat,我们可以这样想: 如果x和y的xor是true,那么 ...
- c#检查网络文件是否存在
public bool IsExist(string uri) { HttpWebRequest req = null; HttpWebResponse res = null; try { req = ...
- 拦截器(Inteceptor),过滤器(Filter),切面(Aspect)处理HttpServiceReqeust请求
1.拦截器 java里的拦截器是动态拦截Action调用的对象.它提供了一种机制可以使开发者可以定义在一个action执行的前后执行的代码,也可以在一个action执行前阻止其执行,同时也提供了一种可 ...
- Error in registration. Error: Error Domain=NSCocoaErrorDomain Code=3000 "未找到应用程序的“aps-environment”的授
本文转载至 http://blog.csdn.net/woaifen3344/article/details/41311023 Code3000极光推送erroryour certificate n ...
- Win10下Hyper-V设置网络连接
具体方法如下. 1.点击虚拟交换机管理 2.创建虚拟交换机 选择内部 3.选择链接类型
- iOS section 随tableview一起滚动
@interface YGSectionHeaderView : UIView @property NSUInteger section; @property (nonatomic, weak) UI ...
- 基于kubernetes集群的Vitess最佳实践
概要 本文主要说明基于kubernetes集群部署并使用Vitess; 本文假定用户已经具备了kubernetes集群使用环境,如果不具备请先参阅基于minikube的kubernetes集群搭建, ...
- POJ 2253 Frogger【最短路变形——路径上最小的最大权】
链接: http://poj.org/problem?id=2253 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=22010#probl ...
- angular.js记录
http://www.runoob.com/angularjs/angularjs-tutorial.html 第一部分:快速上手1.1 angularJS四大核心特性1.2 自己动手搭建开发,调试, ...
- Android 点击电话号码之间拨号
点击电话号码之间拨打电话,可用通过下面的方式实现: 假设电话号码以TextView的方式显示 1.Intent方式 在TextView的响应事件中 : String phone = tvphone.g ...