详解MySQL性能优化(二)
http://www.jb51.net/article/70530.htm
七、MySQL数据库Schema设计的性能优化
高效的模型设计
适度冗余-让Query尽两减少Join
大字段垂直分拆-summary表优化
大表水平分拆-基于类型的分拆优化
统计表-准实时优化
合适的数据类型
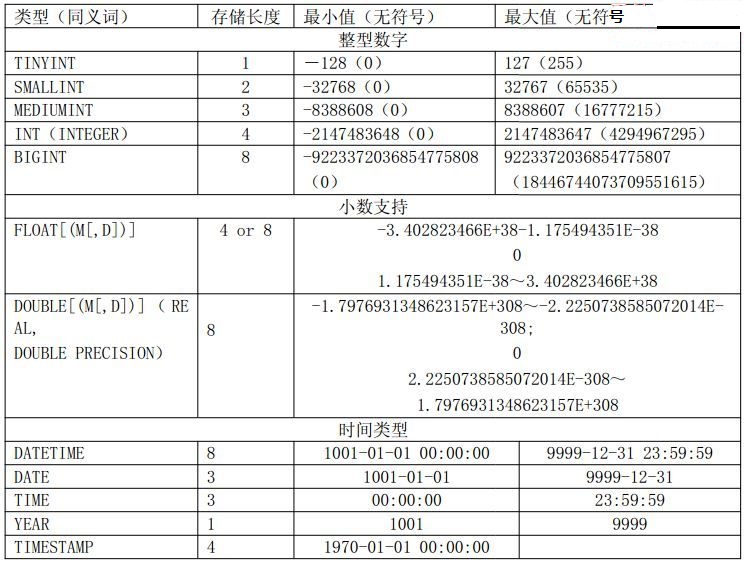
时间存储格式总类并不是太多,我们常用的主要就是DATETIME,DATE和TIMESTAMP这三种了。从存储空间来看TIMESTAMP最少,四个字节,而其他两种数据类型都是八个字节,多了一倍。而TIMESTAMP的缺点在于他只能存储从1970年之后的时间,而另外两种时间类型可以存放最早从1001年开始的时间。如果有需要存放早于1970年之前的时间的需求,我们必须放弃TIMESTAMP类型,但是只要我们不需要使用1970年之前的时间,最好尽量使用TIMESTAMP来减少存储空间的占用。
字符存储类型

CHAR[(M)]类型属于静态长度类型,存放长度完全以字符数来计算,所以最终的存储长度是基于字符集的,如latin1则最大存储长度为255字节,但是如果使用gbk则最大存储长度为510字节。CHAR类型的存储特点是不管我们实际存放多长数据,在数据库中都会存放M个字符,不够的通过空格补上,M默认为1。虽然CHAR会通过空格补齐存放的空间,但是在访问数据的时候,MySQL会忽略最后的所有空格,所以如果我们的实际数据中如果在最后确实需要空格,则不能使用CHAR类型来存放。
VARCHAR[(M)]属于动态存储长度类型,仅存占用实际存储数据的长度。TINYTEXT,TEXT,MEDIUMTEXT和LONGTEXT这四种类型同属于一种存储方式,都是动态存储长度类型,不同的仅仅是最大长度的限制。
事务优化
1. 脏读:脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
2. 不可重复读:是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
3. 幻读:是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有修改的数据行,就好象发生了幻觉一样。
Innodb在事务隔离级别方面支持的信息如下:
1.READ UNCOMMITTED
常被成为Dirty Reads(脏读),可以说是事务上的最低隔离级别:在普通的非锁定模式下SELECT的执行使我们看到的数据可能并不是查询发起时间点的数据,因而在这个隔离度下是非Consistent Reads(一致性读);
2.READ COMMITTED
这一隔离级别下,不会出现DirtyRead,但是可能出现Non-RepeatableReads(不可重复读)和PhantomReads(幻读)。
3. REPEATABLE READ
REPEATABLE READ隔离级别是InnoDB默认的事务隔离级。在REPEATABLE READ隔离级别下,不会出现DirtyReads,也不会出现Non-Repeatable Read,但是仍然存在PhantomReads的可能性。
4.SERIALIZABLE
SERIALIZABLE隔离级别是标准事务隔离级别中的最高级别。设置为SERIALIZABLE隔离级别之后,在事务中的任何时候所看到的数据都是事务启动时刻的状态,不论在这期间有没有其他事务已经修改了某些数据并提交。所以,SERIALIZABLE事务隔离级别下,PhantomReads也不会出现。
八、可扩展性设计之数据切分
数据的垂直切分
数据的垂直切分,也可以称之为纵向切分。将数据库想象成为由很多个一大块一大块的“数据块”(表)组成,我们垂直的将这些“数据块”切开,然后将他们分散到多台数据库主机上面。这样的切分方法就是一个垂直(纵向)的数据切分。
垂直切分的优点
◆数据库的拆分简单明了,拆分规则明确;
◆应用程序模块清晰明确,整合容易;
◆数据维护方便易行,容易定位;
垂直切分的缺点
◆部分表关联无法在数据库级别完成,需要在程序中完成;
◆对于访问极其频繁且数据量超大的表仍然存在性能平静,不一定能满足要求;
◆事务处理相对更为复杂;
◆切分达到一定程度之后,扩展性会遇到限制;
◆过读切分可能会带来系统过渡复杂而难以维护。
数据的水平切分
数据的垂直切分基本上可以简单的理解为按照表按照模块来切分数据,而水平切分就不再是按照表或者是功能模块来切分了。一般来说,简单的水平切分主要是将某个访问极其平凡的表再按照某个字段的某种规则来分散到多个表之中,每个表中包含一部分数据。
水平切分的优点
◆表关联基本能够在数据库端全部完成;
◆不会存在某些超大型数据量和高负载的表遇到瓶颈的问题;
◆应用程序端整体架构改动相对较少;
◆事务处理相对简单;
◆只要切分规则能够定义好,基本上较难遇到扩展性限制;
水平切分的缺点
◆切分规则相对更为复杂,很难抽象出一个能够满足整个数据库的切分规则;
◆后期数据的维护难度有所增加,人为手工定位数据更困难;
◆应用系统各模块耦合度较高,可能会对后面数据的迁移拆分造成一定的困难。
数据切分与整合中可能存在的问题
1.引入分布式事务的问题
完全可以将一个跨多个数据库的分布式事务分拆成多个仅处于单个数据库上面的小事务,并通过应用程序来总控各个小事务。当然,这样作的要求就是我们的俄应用程序必须要有足够的健壮性,当然也会给应用程序带来一些技术难度。
2.跨节点Join的问题
推荐通过应用程序来进行处理,先在驱动表所在的MySQLServer中取出相应的驱动结果集,然后根据驱动结果集再到被驱动表所在的MySQL Server中取出相应的数据。
3.跨节点合并排序分页问题
从多个数据源并行的取数据,然后应用程序汇总处理。
九、可扩展性设计之Cache与Search的利用
通过引入Cache(Redis、Memcached),减少数据库的访问,增加性能。
通过引入Search(Lucene、Solr、ElasticSearch),利用搜索引擎高效的全文索引和分词算法,以及高效的数据检索实现,来解决数据库和传统的Cache软件完全无法解决的全文模糊搜索、分类统计查询等功能。
以上就是本文的全部内容,希望大家可以喜欢。
详解MySQL性能优化(二)的更多相关文章
- MySQL性能优化(二):优化数据库的设计
原文:MySQL性能优化(二):优化数据库的设计 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.n ...
- MYSQL ini 配置文件详解及性能优化方案
my.ini分为两块:Client Section和Server Section. Client Section用来配置MySQL客户端参数. 要查看配置参数可以用下面的命令: show va ...
- 详解MYSQL各种优化原理
说起MySQL的查询优化,相信大家收藏了一堆奇技淫巧:不能使用SELECT *.不使用NULL字段.合理创建索引.为字段选择合适的数据类型..... 你是否真的理解这些优化技巧?是否理解其背后的工作原 ...
- JVM虚拟机详解+Tomcat性能优化
1.JVM(java virtual mechinal) ()JVM有完善的硬件架构,如处理器.堆栈.寄存器当,还具有相应的指令系统. ()JVM的主要工作时解释自己的指令集(即字节码),并映射到本地 ...
- MapReduce过程详解及其性能优化
http://blog.csdn.net/aijiudu/article/details/72353510 废话不说直接来一张图如下: 从JVM的角度看Map和Reduce Map阶段包括: 第一读数 ...
- 高手详解SQL性能优化十条经验
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便会 ...
- 高手详解SQL性能优化十条建议
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便 ...
- mysql性能优化(二)
###> mysql中有一个explain 命令可以用来分析select 语句的运行效果,例如explain可以获得select语句使用的索引情况.排序的情况等等.除此以外,explain 的e ...
- Mysql性能优化三(分表、增量备份、还原)
接上篇Mysql性能优化二 对表进行水平划分 如果一个表的记录数太多了,比如上千万条,而且需要经常检索,那么我们就有必要化整为零了.如果我拆成100个表,那么每个表只有10万条记录.当然这需要数据在逻 ...
随机推荐
- zip函数的应用
#!/usr/bin/env python # encoding: utf-8 from itertools import zip_longest # ➍ # zip并行从输入的各个可迭代对象中获取元 ...
- springboot项目的搭建
原文链接:http://www.cnblogs.com/winner-0715/p/6666302.html 后续完善(附图及详细过程)
- 微信小程序实现图片上传,预览,删除
wxml: <view class='imgBox'> <image class='imgList' wx:for="{{imgs}}" wx:for-item= ...
- linux 系统调用fork()
头文件: #include<unistd.h> #include<sys/types.h> 函数原型: pid_t fork( void); (pid_t 是一个宏定义,其实质 ...
- linux下运行jmeter脚本
1. win下生成测试计划 2. 上传至linux下 3.运行测试计划 sh jmeter.sh -n -t second_login.jmx -l res.jtl 错误1: solution ...
- Python+Selenium 自动化实现实例-Xpath捕捉元素的几种方法
#coding=utf-8import timefrom selenium import webdriverdriver = webdriver.Chrome()driver.get("ht ...
- CentOS7.5安装网易云音乐
CentOS7中一直没有一个像样的音乐播放器,网易云音乐与深度科技团队在半年前就启动了“网易云音乐Linux版“, 但是只提供了Ubuntu(14.04&16.04)和deepin15版本,并 ...
- react native 调用Android原生方法
来源:https://www.youtube.com/watch?v=WmJpHHmOKM8 教程:https://www.youtube.com/watch?v=GiUo88TGebs Breaki ...
- python正则的中文处理(转)
匹配中文时,正则表达式规则和目标字串的编码格式必须相同 print sys.getdefaultencoding() text =u"#who#helloworld#a中文x#" ...
- C++ 单例模式的几种实现研究
都是从网上学得,整理下自己的理解. 单例模式有两种实现模式: 1)懒汉模式: 就是说当你第一次使用时才创建一个唯一的实例对象,从而实现延迟加载的效果. 2)饿汉模式: 就是说不管你将来用不用,程序启动 ...