java-序列化-001-原生介绍
一、什么是对象序列化
java平台允许我们在内存中创建可复用的Java对象,但一般情况下,只有当JVM处于运行时,这些对象才可能存在,即,这些对象的生命周期不会比JVM的生命周期更长。但在现实应用中,就可能要求在JVM停止运行之后能够保存(持久化)指定的对象,并在将来重新读取被保存的对象。Java对象序列化就能够帮助我们实现该功能。
使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的"状态",即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
除了在持久化对象时会用到对象序列化之外,当使用RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。
将 Java 对象序列化为二进制文件的 Java 序列化技术是 Java 系列技术中一个较为重要的技术点,在大部分情况下,开发人员只需要了解被序列化的类需要实现 Serializable 接口,使用 ObjectInputStream 和 ObjectOutputStream 进行对象的读写。
二、序列化过程原理
需要实现接口:java.io.Serializable
自定义工具类:
package com.lhx.common.json.originalDemo; import org.junit.Test; import java.io.*; /**
* 简单的Io-serializable序列化
*/
public class IOSerializable<T> {
//序列化对象
public void writeMethod(String fileName, T t) {
ObjectOutputStream objectOutputStream = null;
try {
objectOutputStream = new ObjectOutputStream(new FileOutputStream(fileName));
//序列化对象
objectOutputStream.writeObject(t); } catch (IOException e) {
e.printStackTrace();
} finally {
if (objectOutputStream != null) {
//关闭输出流
try {
objectOutputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
} }
} //反序列对象得到数据
public T readMethod(String fileName) {
ObjectInputStream objectInputStream = null;
T t = null;
try {
objectInputStream = new ObjectInputStream(new FileInputStream(fileName));
t = (T) objectInputStream.readObject(); } catch (IOException E) {
E.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
if (objectInputStream != null) {
try {
objectInputStream.close();
} catch (IOException E) {
E.printStackTrace();
}
}
}
return t;
}
@Test
public void testWrite(){
IOSerializable<String> serializable = new IOSerializable<String>();
serializable.writeMethod("testWrite","我是中国人");
System.out.println("ok");
}@Test
public void testRead(){
IOSerializable<String> serializable = new IOSerializable<String>();
String testWrite = serializable.readMethod("testWrite");
System.out.println(testWrite);
System.out.println("ok");
}
}
2.1、原理
在序列化过程中,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化,
如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。
用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。


2.2、分析
使用ObjectOutputStream来持久化对象,在该类中有如下代码:
private void writeObject0(Object obj, boolean unshared) throws IOException {
……
if (obj instanceof String) {
writeString((String) obj, unshared);
} else if (cl.isArray()) {
writeArray(obj, desc, unshared);
} else if (obj instanceof Enum) {
writeEnum((Enum) obj, desc, unshared);
} else if (obj instanceof Serializable) {
writeOrdinaryObject(obj, desc, unshared);
} else {
if (extendedDebugInfo) {
throw new NotSerializableException(cl.getName() + "\n"
+ debugInfoStack.toString());
} else {
throw new NotSerializableException(cl.getName());
}
}
……
}
从上述代码可知,如果被写对象的类型是String,或数组,或Enum,或Serializable,那么就可以对该对象进行序列化,否则将抛出NotSerializableException。
2.3、writeObject()方法与readObject()方法
对于上述已被声明为transitive的字段age,除了将transitive关键字去掉之外,是否还有其它方法能使它再次可被序列化?方法之一就是在Person类中添加两个方法:writeObject()与readObject(),如下所示:
public class Person implements Serializable {
transient private Integer age = null;
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
}
在writeObject()方法中会先调用ObjectOutputStream中的defaultWriteObject()方法,该方法会执行默认的序列化机制,如使用transient 修饰,此时会忽略掉age字段。然后再调用writeInt()方法显示地将age字段写入到ObjectOutputStream中。readObject()的作用则是针对对象的读取,其原理与writeObject()方法相同。
必须注意地是,writeObject()与readObject()都是private方法,那么它们是如何被调用的呢?毫无疑问,是使用反射。详情可见ObjectOutputStream中的writeSerialData方法,以及ObjectInputStream中的readSerialData方法。
2.4、readResolve()方法
当我们使用Singleton模式时,应该是期望某个类的实例应该是唯一的,但如果该类是可序列化的,那么情况可能会略有不同。此时对第2节使用的Person类进行修改,使其实现Singleton模式,如下所示:
public class Person implements Serializable {
private static class InstanceHolder {
private static final Person instatnce = new Person("John", 31, Gender.MALE);
}
public static Person getInstance() {
return InstanceHolder.instatnce;
}
private String name = null;
private Integer age = null;
private Gender gender = null;
private Person() {
System.out.println("none-arg constructor");
}
private Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
//其他代码
}
校验类:
public class SimpleSerial {
public static void main(String[] args) throws Exception {
File file = new File("person.out");
ObjectOutputStream oout = new ObjectOutputStream(new FileOutputStream(file));
oout.writeObject(Person.getInstance()); // 保存单例对象
oout.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(file));
Object newPerson = oin.readObject();
oin.close();
System.out.println(newPerson);
System.out.println(Person.getInstance() == newPerson); // 将获取的对象与Person类中的单例对象进行相等性比较
}
}
执行上述应用程序后会得到如下结果:
arg constructor
[John, 31, MALE]
false
值得注意的是,从文件person.out中获取的Person对象与Person类中的单例对象并不相等。为了能在序列化过程仍能保持单例的特性,可以在Person类中添加一个readResolve()方法,在该方法中直接返回Person的单例对象,如下所示:
public class Person implements Serializable {
private static class InstanceHolder {
private static final Person instatnce = new Person("John", 31, Gender.MALE);
}
public static Person getInstance() {
return InstanceHolder.instatnce;
}
private String name = null;
private Integer age = null;
private Gender gender = null;
private Person() {
System.out.println("none-arg constructor");
}
private Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
private Object readResolve() throws ObjectStreamException {
return InstanceHolder.instatnce;
}
//其他代码
}
再次执行本节的SimpleSerial应用后将有如下输出:
arg constructor
[John, 31, MALE]
true
无论是实现Serializable接口,或是Externalizable接口,当从I/O流中读取对象时,readResolve()方法都会被调用到。实际上就是用readResolve()中返回的对象直接替换在反序列化过程中创建的对象,而被创建的对象则会被垃圾回收掉。
三、序列化ID问题
示例:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 Data 序列化为二进制数据再传给 B,B 反序列化得到 Data。
问题:Data 对象的全类路径假设为 com.inout.Data,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。
解决:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID 。
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,未作更改的类,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
相同功能代码不同序列化 ID 的类对比
package com.inout;
import java.io.Serializable;
public class A implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
package com.inout;
import java.io.Serializable;
public class A implements Serializable {
private static final long serialVersionUID = 2L;
private String name;
public String getName()
{
return name;
}
public void setName(String name)
{
this.name = name;
}
}
序列化 ID 在 Eclipse 下提供了两种生成策略,一个是固定的 1L,一个是随机生成一个不重复的 long 类型数据(实际上是使用 JDK 工具生成),在这里有一个建议,如果没有特殊需求,就是用默认的 1L 就可以,这样可以确保代码一致时反序列化成功。那么随机生成的序列化 ID 有什么作用呢,有些时候,通过改变序列化 ID 可以用来限制某些用户的使用。
特性使用案例
读者应该听过 Façade 模式,它是为应用程序提供统一的访问接口,案例程序中的 Client 客户端使用了该模式,案例程序结构图如图 1 所示。
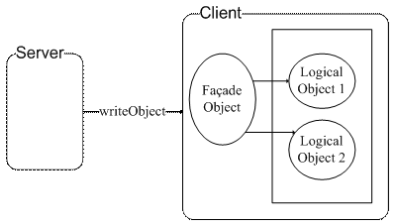
Client 端通过 Façade Object 才可以与业务逻辑对象进行交互。而客户端的 Façade Object 不能直接由 Client 生成,而是需要 Server 端生成,然后序列化后通过网络将二进制对象数据传给 Client,Client 负责反序列化得到 Façade 对象。该模式可以使得 Client 端程序的使用需要服务器端的许可,同时 Client 端和服务器端的 Façade Object 类需要保持一致。当服务器端想要进行版本更新时,只要将服务器端的 Façade Object 类的序列化 ID 再次生成,当 Client 端反序列化 Façade Object 就会失败,也就是强制 Client 端从服务器端获取最新程序。
四、静态变量不能序列化
序列化保存的是对象的状态,静态变量属于类的状态,因此序列化并不保存静态变量。
五、父类子类的序列化
情境:一个子类实现了 Serializable 接口,它的父类都没有实现 Serializable 接口,序列化该子类对象,然后反序列化后输出父类定义的某变量的数值,该变量数值与序列化时的数值不同。
解决:要想将父类对象也序列化,就需要让父类也实现Serializable 接口。如果父类不实现的话的,就 需要有默认的无参的构造函数。在父类没有实现 Serializable 接口时,虚拟机是不会序列化父对象的,而一个 Java 对象的构造必须先有父对象,才有子对象,反序列化也不例外。所以反序列化时,为了构造父对象,只能调用父类的无参构造函数作为默认的父对象。因此当我们取父对象的变量值时,它的值是调用父类无参构造函数后的值。如果你考虑到这种序列化的情况,在父类无参构造函数中对变量进行初始化,否则的话,父类变量值都是默认声明的值,如 int 型的默认是 0,string 型的默认是 null。
如果仅仅只是让某个类实现Serializable接口,而没有其它任何处理的话,则就是使用默认序列化机制。使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对该对象引用的其它对象也进行序列化,同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
六、Transient 关键字
Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
特性使用案例
我们熟悉使用 Transient 关键字可以使得字段不被序列化,那么还有别的方法吗?根据父类对象序列化的规则,我们可以将不需要被序列化的字段抽取出来放到父类中,子类实现 Serializable 接口,父类不实现,根据父类序列化规则,父类的字段数据将不被序列化,形成类图如图 2 所示。

上图中可以看出,attr1、attr2、attr3、attr5 都不会被序列化,放在父类中的好处在于当有另外一个 Child 类时,attr1、attr2、attr3 依然不会被序列化,不用重复抒写 transient,代码简洁。
七、对敏感字段加密
情境:服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
解决:在序列化过程中,虚拟机会试图调用对象类里的 writeObject 和 readObject 方法,进行用户自定义的序列化和反序列化,如果没有这样的方法,则默认调用是 ObjectOutputStream 的 defaultWriteObject 方法以及 ObjectInputStream 的 defaultReadObject 方法。用户自定义的 writeObject 和 readObject 方法可以允许用户控制序列化的过程,比如可以在序列化的过程中动态改变序列化的数值。基于这个原理,可以在实际应用中得到使用,用于敏感字段的加密工作,清单 3 展示了这个过程。
package com.lhx.common.json.originalDemo;
import java.io.*;
public class EncryptionTest implements Serializable{
private static final long serialVersionUID = 1L;
private String password = "pass";
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
private void writeObject(ObjectOutputStream out) {
try {
ObjectOutputStream.PutField putFields = out.putFields();
System.out.println("原密码:" + password);
password = "encryption";//模拟加密
putFields.put("password", password);
System.out.println("加密后的密码" + password);
out.writeFields();
} catch (IOException e) {
e.printStackTrace();
}
}
private void readObject(ObjectInputStream in) {
try {
ObjectInputStream.GetField readFields = in.readFields();
Object object = readFields.get("password", "");
System.out.println("要解密的字符串:" + object.toString());
password = "pass";//模拟解密,需要获得本地的密钥
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
try {
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
out.writeObject(new EncryptionTest());
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
EncryptionTest t = (EncryptionTest) oin.readObject();
System.out.println("解密后的字符串:" + t.getPassword());
oin.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
原密码:pass
加密后的密码encryption
要解密的字符串:encryption
解密后的字符串:pass
在以上的 writeObject 方法中,对密码进行了加密,在 readObject 中则对 password 进行解密,只有拥有密钥的客户端,才可以正确的解析出密码,确保了数据的安全。
特性使用案例
RMI 技术是完全基于 Java 序列化技术的,服务器端接口调用所需要的参数对象来至于客户端,它们通过网络相互传输。这就涉及 RMI 的安全传输的问题。一些敏感的字段,如用户名密码(用户登录时需要对密码进行传输),我们希望对其进行加密,这时,就可以采用本节介绍的方法在客户端对密码进行加密,服务器端进行解密,确保数据传输的安全性。
八、序列化存储规则
示例代码
package com.lhx.common.json.originalDemo;
import java.io.*;
public class EncryptionTest2 implements Serializable {
private static final long serialVersionUID = 1L;
private String password = "pass";
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@org.junit.Test
public void testTwoStore() throws Exception {
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
EncryptionTest2 test = new EncryptionTest2();
//试图将对象两次写入文件
out.writeObject(test);
out.flush();
System.out.println(new File("result.obj").length());
out.writeObject(test);
out.close();
System.out.println(new File("result.obj").length());
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
//从文件依次读出两个文件
EncryptionTest2 t1 = (EncryptionTest2) oin.readObject();
EncryptionTest2 t2 = (EncryptionTest2) oin.readObject();
oin.close();
//判断两个引用是否指向同一个对象
System.out.println(t1 == t2);
}
@org.junit.Test
public void testTwoStore2() throws Exception {
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("testTwoStore2.obj"));
EncryptionTest2 test = new EncryptionTest2();
test.i = 1;
out.writeObject(test);
out.flush();
test.i = 2;
out.writeObject(test);
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"testTwoStore2.obj"));
EncryptionTest2 t1 = (EncryptionTest2) oin.readObject();
EncryptionTest2 t2 = (EncryptionTest2) oin.readObject();
System.out.println(t1.i);
System.out.println(t2.i);
}
}
对同一对象两次写入文件,打印出写入一次对象后的存储大小和写入两次后的存储大小,然后从文件中反序列化出两个对象,比较这两个对象是否为同一对象。一般的思维是,两次写入对象,文件大小会变为两倍的大小,反序列化时,由于从文件读取,生成了两个对象,判断相等时应该是输入 false 才对,但是最后结果输出如图所示。
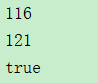
我们看到,第二次写入对象时文件只增加了 5 字节,并且两个对象是相等的,这是为什么呢?
解答:Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,上面增加的 5 字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,使得 t1 和 t2 指向唯一的对象,二者相等,输出 true。该存储规则极大的节省了存储空间。
特性案例分析
package com.lhx.common.json.originalDemo;
import java.io.*;
public class EncryptionTest2 implements Serializable {
private static final long serialVersionUID = 1L;
private String password = "pass";
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@org.junit.Test
public void testTwoStore() throws Exception {
ObjectOutputStream out = new ObjectOutputStream(
new FileOutputStream("result.obj"));
EncryptionTest2 test = new EncryptionTest2();
//试图将对象两次写入文件
out.writeObject(test);
out.flush();
System.out.println(new File("result.obj").length());
out.writeObject(test);
out.close();
System.out.println(new File("result.obj").length());
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"result.obj"));
//从文件依次读出两个文件
EncryptionTest2 t1 = (EncryptionTest2) oin.readObject();
EncryptionTest2 t2 = (EncryptionTest2) oin.readObject();
oin.close();
//判断两个引用是否指向同一个对象
System.out.println(t1 == t2);
}
@org.junit.Test
public void testTwoStore2() throws Exception {
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("testTwoStore2.obj"));
EncryptionTest2 test = new EncryptionTest2();
test.i = 1;
out.writeObject(test);
out.flush();
test.i = 2;
out.writeObject(test);
out.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(
"testTwoStore2.obj"));
EncryptionTest2 t1 = (EncryptionTest2) oin.readObject();
EncryptionTest2 t2 = (EncryptionTest2) oin.readObject();
System.out.println(t1.i);
System.out.println(t2.i);
}
}

上一个 的目的是希望将 test 对象两次保存到 result.obj 文件中,写入一次以后修改对象属性值再次保存第二次,然后从 result.obj 中再依次读出两个对象,输出这两个对象的 i 属性值。案例代码的目的原本是希望一次性传输对象修改前后的状态。
结果两个输出的都是 1, 原因就是第一次写入对象以后,第二次再试图写的时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。读者在使用一个文件多次 writeObject 需要特别注意这个问题。
九、Externalizable接口
简单序列化类
public class SimpleSerial {
public static void main(String[] args) throws Exception {
File file = new File("person.out");
ObjectOutputStream oout = new ObjectOutputStream(new FileOutputStream(file));
Person person = new Person("John", 101, Gender.MALE);
oout.writeObject(person);
oout.close();
ObjectInputStream oin = new ObjectInputStream(new FileInputStream(file));
Object newPerson = oin.readObject(); // 没有强制转换到Person类型
oin.close();
System.out.println(newPerson);
}
}
无论是使用transient关键字,还是使用writeObject()和readObject()方法,其实都是基于Serializable接口的序列化。JDK中提供了另一个序列化接口--Externalizable,使用该接口之后,之前基于Serializable接口的序列化机制就将失效。此时将Person类修改成如下,
public class Person implements Externalizable {
private String name = null;
transient private Integer age = null;
private Gender gender = null;
public Person() {
System.out.println("none-arg constructor");
}
public Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
}
}
此时再执行SimpleSerial程序之后会得到如下结果:
arg constructor
none-arg constructor
[null, null, null]
从该结果,一方面可以看出Person对象中任何一个字段都没有被序列化。另一方面,如果细心的话,还可以发现这此次序列化过程调用了Person类的无参构造器。
Externalizable继承于Serializable,当使用该接口时,序列化的细节需要由程序员去完成。如上所示的代码,由于writeExternal()与readExternal()方法未作任何处理,那么该序列化行为将不会保存/读取任何一个字段。这也就是为什么输出结果中所有字段的值均为空。
另外,若使用Externalizable进行序列化,当读取对象时,会调用被序列化类的无参构造器去创建一个新的对象,然后再将被保存对象的字段的值分别填充到新对象中。这就是为什么在此次序列化过程中Person类的无参构造器会被调用。由于这个原因,实现Externalizable接口的类必须要提供一个无参的构造器,且它的访问权限为public。
对上述Person类作进一步的修改,使其能够对name与age字段进行序列化,但要忽略掉gender字段,如下代码所示:
public class Person implements Externalizable {
private String name = null;
transient private Integer age = null;
private Gender gender = null;
public Person() {
System.out.println("none-arg constructor");
}
public Person(String name, Integer age, Gender gender) {
System.out.println("arg constructor");
this.name = name;
this.age = age;
this.gender = gender;
}
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
age = in.readInt();
}
}
执行SimpleSerial之后会有如下结果:
arg constructor
none-arg constructor
[John, 31, null]
参看地址:
http://www.blogjava.net/jiangshachina/archive/2012/02/13/369898.html
http://blog.csdn.net/jiangwei0910410003/article/details/18989711/
java-序列化-001-原生介绍的更多相关文章
- java序列化的相关介绍
1.什么是序列化?为什么要用序列化? 序列化就是将对象状态转换为可保持或传输的格式的过程.与序列化相对的就是反序列化,他将流转换成对象.这两个过程结合起来,可以轻松地存储和传输数据. 注意:对象序列化 ...
- Java 的序列化Serializable接口介绍及应用
常看到类中有一串很长的 如 private static final long serialVersionUID = -4667619549931154146L;的数字声明.这些其实是对此类进行序列化 ...
- Java对象的序列化和反序列化介绍
一.什么序列化和反序列化以及作用: java序列化是指把java对象转换为字节序列的过程,而java反序列化是指把字节序列恢复为java对象的过程 1.序列化: 1)对象序列化的最主要的用处就是在传递 ...
- Java序列化的几种方式以及序列化的作用
Java序列化的几种方式以及序列化的作用 本文着重讲解一下Java序列化的相关内容. 如果对Java序列化感兴趣的同学可以研究一下. 一.Java序列化的作用 有的时候我们想要把一个Java对象 ...
- 深入学习 Java 序列化
前言 对于Java的序列化,一直只知道只需要实现Serializbale这个接口就可以了,具体内部实现一直不是很了解,正好这次在重复造RPC的轮子的时候涉及到序列化问题,就抽时间看了下 Java序列化 ...
- Java序列化的几种方式
本文着重解说一下Java序列化的相关内容. 假设对Java序列化感兴趣的同学能够研究一下. 一.Java序列化的作用 有的时候我们想要把一个Java对象变成字节流的形式传出去,有的时候我们想要从 ...
- 【转】几种Java序列化方式的实现
0.前言 本文主要对几种常见Java序列化方式进行实现.包括Java原生以流的方法进行的序列化.Json序列化.FastJson序列化.Protobuff序列化. 1.Java原生序列化 Java原生 ...
- (记录)Jedis存放对象和读取对象--Java序列化与反序列化
一.理论分析 在学习Redis中的Jedis这一部分的时候,要使用到Protostuff(Protobuf的Java客户端)这一序列化工具.一开始看到序列化这些字眼的时候,感觉到一头雾水.于是,参考了 ...
- Java I/O系统学习系列五:Java序列化机制
在Java的世界里,创建好对象之后,只要需要,对象是可以长驻内存,但是在程序终止时,所有对象还是会被销毁.这其实很合理,但是即使合理也不一定能满足所有场景,仍然存在着一些情况,需要能够在程序不运行的情 ...
- Java序列化的方式。
0.前言 本文主要对几种常见Java序列化方式进行实现.包括Java原生以流的方法进行的序列化.Json序列化.FastJson序列化.Protobuff序列化. 1.Java原生序列化 Java原生 ...
随机推荐
- python学习笔记2---函数
函数主要是为了代码复用. 函数分为两种:系统库预定义函数,自定义函数. 函数格式: def functionName(): statement 函数调用: funtionName() 函数的参数:形参 ...
- libubox
lbubox是openwrt的一个核心库,封装了一系列基础实用功能,主要提供事件循环,二进制格式处理,linux链表实现和一些JSON辅助处理. 它的目的是以动态链接库方式来提供可重用的通用功能,给其 ...
- java为啥计算时间从1970年1月1日开始
http://www.myexception.cn/program/1494616.html ————————————————————————————————————————————————————— ...
- Tuning 12 manage statistics
这个 stattistics 对解析 sql 时的优化器有很重要的作用, 优化器是基于 statistics 来进行优化的. desc dbms_stats 包也可以 desc (早期使用 analy ...
- 第一百五十四节,封装库--JavaScript,表单验证--提交验证
封装库--JavaScript,表单验证--提交验证 将表单的所有必填项,做一个判断函数,填写正确时返回布尔值 最后在提交时,判断每一项是否正确,全部正确才可以 提交 html <div id= ...
- 使用JSR验证
1.spring mvc配置文件中添加: <mvc:annotation-driven /> 2.pom.xml中添加 <dependency > ...
- Java逍遥游记读书笔记<三>
异常处理 如何判断一个方法中可能抛出异常 该方法中出现throw语句 该方法调用了其他已经带throws子句的方法. 如果方法中可能抛出异常,有两种处理方法: 1.若当前方法有能力处理异常,则用Try ...
- C# 多线程学习(五)线程同步和冲突解决
from:https://blog.csdn.net/codedoctor/article/details/74358257 首先先说一个线程不同步的例子吧,以下为售票员的模拟售票,多个售票员出售10 ...
- manacher算法处理最长的回文子串(二)
在上篇<manacher算法处理最长的回文子串(一)>解释了manacher算法的原理,接着给该算法,该程序在leetcode的最长回文子串中通过.首先manacher算法维护3个变量.一 ...
- hdu 4576(简单概率dp | 矩阵优化)
艰难的一道题,体现出菜菜的我... 首先,先吐槽下. 这题到底出题人是怎么想的,用普通概率dp水过??? 那为什么我概率dp写的稍微烂点就一直tle? 感觉很不公平.大家算法都一致,因为我程序没有那 ...