(原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml
神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了两个星期来介绍,可见Neural Networks内容之多。言归正传,通过之前的学习我们知道,使用非线性的多项式能够帮助我们建立更好的分类模型。但当遇特征非常多的时候,需要训练的参数太多,使得训练非常复杂,使得逻辑回归有心无力。
例如我们有100个特征,如果用这100个特征来构建一个非线性的多项式模型,结果将是数量非常惊人的特征组合,即便我们只采用两两特征的组合(x1x2+x1x3+x1x4+...+x2x3+x2x4+...+x99x100),我们也会有接近5000个组合而成的特征。这对于一般的逻辑回归来说需要计算的特征太多了。
那么有没有其他更有效的方法?答案是肯定的,神经网络算法对于复杂的假设空间和复杂的非线性问题有很好的学习能力,他是一种试图模拟人类大脑的学习算法。
神经网络介绍
神经网络算法源自对大脑的模仿,在八十到九十年代非常流行,九十年代后期便衰落,最近又开始变得流行起来,原因是神经网络是非常依赖计算能力的算法,随着新计算机性能的提高,该算法又成为了有效的技术。
神经网络算法的目的是发现一个能模仿人类大脑学习能力的算法。研究表明,如果我们将视觉信号传道给大脑中负责其他感觉的大脑皮层处,那么这些大脑组织将能学会如何处理视觉信号。也就是说所有神经元通用一套学习算法。如果我们能近似模拟或实现大脑的这种学习算法,我们就能获得绝大部分大脑可以完成的功能。
一般而言, 人工神经网络与经典计算方法相比并非优越, 只有当常规方法解决不了或效果不佳时人工神经网络方法才能显示出其优越性。尤其对问题的机理不甚了解或不能用数学模型表示的系统,如故障诊断、特征提取和预测等问题,人工神经网络往往是最有利的工具。另一方面, 人工神经网络对处理大量原始数据而不能用规则或公式描述的问题, 表现出极大的灵活性和自适应性。
模型表达
大脑中的神经网络是由神经元连接组成,每一个神经元都可以被认为是一个处理单元/神经核(processing unit/ Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
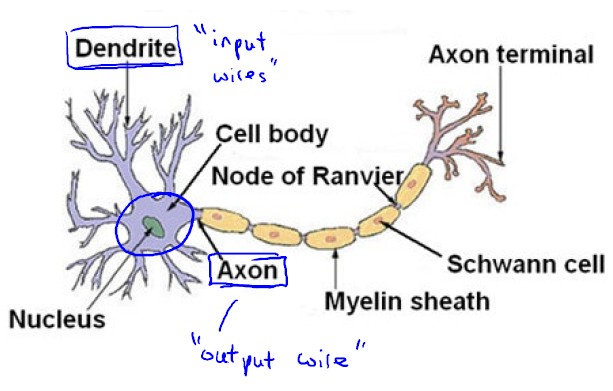
神经细胞的工作
神经细胞之间利用电-化学过程交换信号。从一个神经细胞的轴突末梢(也就是终端)到另一个神经细胞的树突,过程非常复杂,模型化就是两种状态:兴奋和不兴奋,数学化就是0,1。
模型化表示
神经网络模型建立在很多神经元之上,每个神经元又是一个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输入,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被称为权重(weight)。
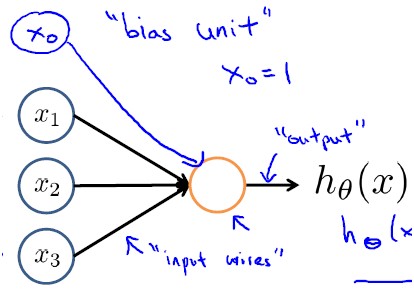
其中x1,x2,x3称为输入,可以是任意多个, x0称为偏置单元(bias unit), θ称为权重或参数, hθ(x)称为激活函数(activation function), 下面的S函数是最常用的激活函数(sigmoid function):
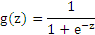
有人可能会问:为啥要加一个偏执单元呢?
激励值是所有 输入*权重 乘积的总和,而神经细胞的输出值取决于这个激励值是否超过某个阀值(t)。这可以用如下的方程来表示:w1x1 + w2x2 + w3x3 +...+ wnxn ≥ t
上式是使细胞输出为1的条件。因为网络的所有权重需要不断演化(进化),如果阀值的数据也能一起演化,那将是非常重要的。要实现这一点不难,你使用一个简单的诡计就可以让阀值变成权重的形式。从上面的方程两边各减去t,得:w1x1 + w2x2 + w3x3 +...+ wnxn - t ≥ 0
这个方程可以再换用一种形式写出来,如下:w1x1 + w2x2 + w3x3 +...+ wnxn +tx(-1) ≥ 0
到此,到这就能看出,阀值t为什么可以想像成为始终乘以输入为 -1的权重了。这个特殊的权重通常叫偏移(bias),这就是为什么每个神经细胞初始化时都要增加一个权重的理由。现在,当你演化一个网络时,你就不必再考虑阀值问题,因为它已被内建在权重向量中了。
有人可能还要问:为啥选择S函数为激活函数?
如果说神经元细胞的输出就是兴奋和不兴奋,那么神经元的输出数学化就是0,和1,因此可知神经元的输出是从激励值(z)产生输出值是一个阶跃函数,如图:
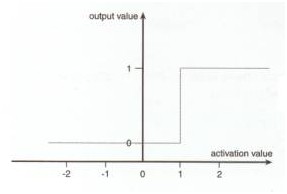
基于上面的图,那么是不是激活函数选择阈值函数更合适呢?之所以选择S激活函数,是因为:
1) 他可以是连续值的输出,且可微分(这点很重要,因为BP神经网络就要求激活函数可微)
2)他能够很好的拟合阈值函数
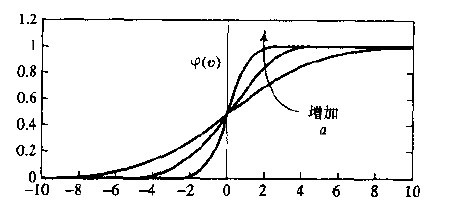
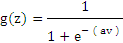
上面的s函数,其中a是其倾斜参数,a越大那么函数越陡,当a极限大的时候,那么s函数就变成阈值函数了.
神经网络模型表达
将多个神经元组织在一起,我们就有了神经网络,神经网络模型有很多种,最简单也是应用最广泛的是叫前馈网络(feedforword network)。这一名称的由来,就是因为网络的每一层神经细胞的输出都向前馈送(feed)到了它们的下一层(在图中是画在它的上面的那一层),直到获得整个网络的输出为止。例如如下的三层结构的神经网络(2层神经元):
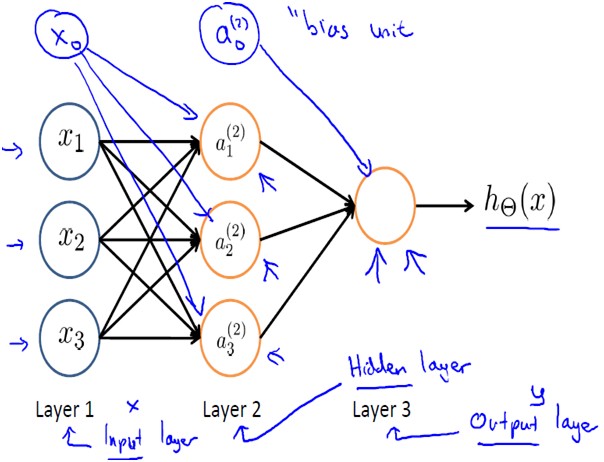
符号说明
- ai(j): 第j层的第i个激活单元
- θ(j): 从第j层映射到第j+1层时的权重的矩阵,如θ(1)代表从第一层映射到第二层的权重的矩阵,以第j层的激活单元数量为行数,以第j+1层的激活单元数为列数.
对于上图所示的模型,激活单元和输出分别表达为:
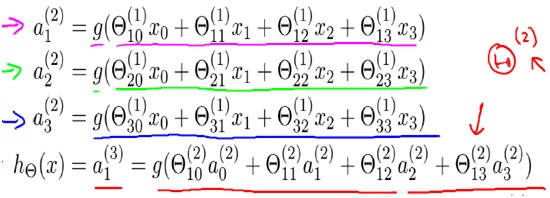
PS:神经网络每个节点的输出并不是概率值,故没层的节点值之和不必等于1,如a1(3)+a2(3)+a3(3) != 1.
另外,除了上述的前馈网络外,神经网络还有其他的一些网络结构,比如递归网络,自组织神经网络。
前馈网络:向量化实现
前向网络只在训练过程会有反馈信号,而在分类过程中数据只能向前传送,直到到达输出层,层间没有向后的反馈信号,因此被称为前馈网络。感知机( perceptron)与BP神经网络就属于前馈网络。
相对与使用循环来实现,利用向量化的方法会使得计算更为简便。以上面的神经网络为例,试着计算第二层的值:
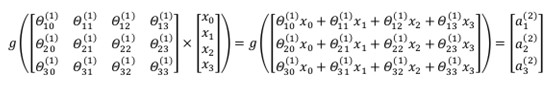
我们令z(2)= θ(1)x ,则 a(2)= g(z(2)) ,计算后添加 a0(2)=1
计算输出的值为:
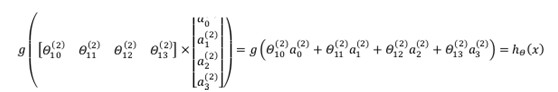
我们令 z(3)= θ(2)a(2) ,则 hθ(x) = a(3) = g(z(3))
这只是针对训练集中一个训练实例所进行的计算。如果我们要对整个训练集进行计算,我们需要将训练集特征矩阵进行转置,使得同一个实例的特征都在同一列里。即:
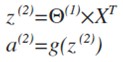
神经网络的理解
本质上讲,神经网络能够通过学习得出其自身的一系列特征。在普通的逻辑回归中,我们被限制为使用数据中的原始特征x1,x2,...,xn,我们虽然可以使用一些二项式项来组合这些特征,但是我们仍然受到这些原始特征的限制。在神经网络中,原始特征只是输入层,在我们上面三层的神经网络例子中,第三层也就是输出层做出的预测利用的是第二层的特征,而非输入层中的原始特征,我们可以认为第二层中的特征是神经网络通过学习后自己得出的一系列用于预测输出变量的新特征。
神经网络示例:布尔函数的神经网络表示
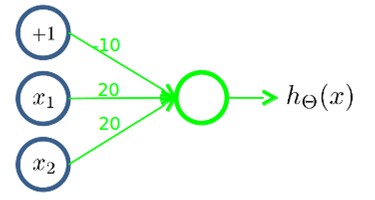
1.下图的神经元(三个权重分别为-30,20,20)可以被视为作用同于逻辑与(AND):
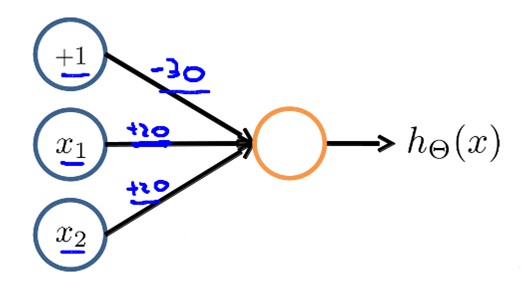
2. 下图的神经元(三个权重分别为-10,20,20)可以被视为作用等同于逻辑或(OR):
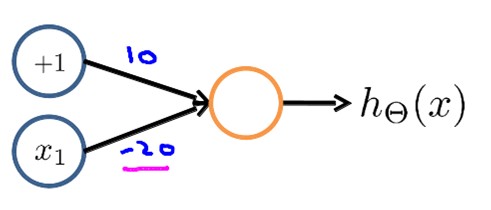
3. 下图的神经元(两个权重分别为10,-20)可以被视为作用等同于逻辑非(NOT):
4. 我们也可以利用神经元来组合成更为复杂的神经网络以实现更复杂的运算。
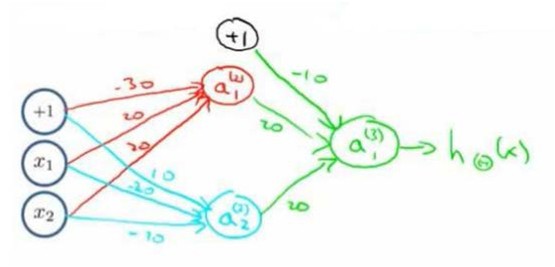
例如我们要实现NOR功能,即NOR=(x1ANDx2)OR((NOTx1)AND(NOTx2))
首先构造一个能表达(NOTx1)AND(NOTx2)部分的神经元:
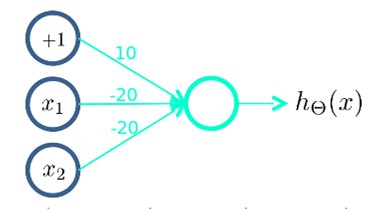
然后将表示AND的神经元和表示(NOTx1)AND(NOTx2)的神经元以及表示OR的神经元进行组合:
多分类问题
首先来看一个机器视觉中分类的例子,对于一个输入图片,需要识别其属于行人、轿车、摩托车或者卡车中的一个类型,这是一个多类分类的问题。

如果我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有4个值。例如,第一个值为1或0用于预测是否是行人,第二个值用于判断是否为汽车。用神经网络表示如下:
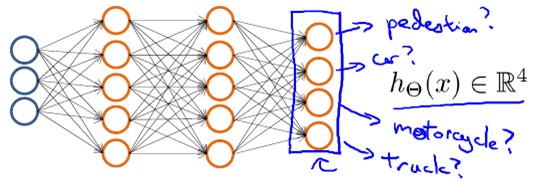
其中输出hΘ(x)是一个4维向量,如下表示:
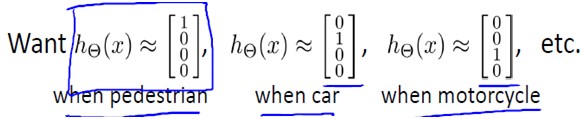
当向量的某个元素为1,其他为0时,代表分类结果为某个为1元素所对应的类别。这与之前logistic regression中的多类分类表示不同,在logistic regression中,输出y属于类似于{1, 2, 3,4}中的某个值,而非一个向量。因此,如果要训练一个多类分类问题的神经网络模型,训练集是这样的:
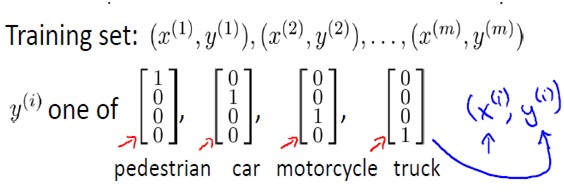
要特别注意y(i)是一个向量。
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Neural Networks Representation部分作业的核心代码:
1. lrCostFunction.m
h = sigmoid(X*theta);
grad = X'*(h-y)/m;
grad0=grad(1);
J = sum(-y.*log(h)-(1-y).*log(1-h))/m + lambda/2/m*sum(theta(2:end).^2);
grad = grad+lambda/m*theta;
grad(1)=grad0;
2. oneVsAll.m
for k=1:num_labels
initial_theta = zeros(n+1,1);
options = optimset('GradObj', 'on', 'MaxIter', 50);
[theta] = fmincg (@(t)(lrCostFunction(t,X,(y==k),lambda)),initial_theta, options);
all_theta(k,:)=theta';
end
3. predictOneVsAll.m
[c,i] = max(sigmoid(X * all_theta'), [], 2);
p = i;
4. predict.m
X = [ones(m, 1) X];
z2 = Theta1 * X';
a2 = sigmoid(z2);
a2 = [ones(1, m);a2];
z3 = Theta2 * a2;
a3 = sigmoid(z3);
output =a3';
[c,i] = max(output, [], 2);
p = i;
(原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation的更多相关文章
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 5) Neural Networks Learning
本栏目内容来自Andrew NG老师的公开课:https://class.coursera.org/ml/class/index 一般而言, 人工神经网络与经典计算方法相比并非优越, 只有当常规方法解 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念.优化目标.聚类中心等内容:特征降维包括降维的缘由.算法描述.压缩重建等内容.coursera上面Andrew NG的Mach ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 在Linear Regression部分出现了一些新的名词,这些名 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
随机推荐
- LCD实验学习笔记(十):TFT LCD
硬件组成: REGBANK是LCD控制寄存器组,含17个寄存器及一块256*16的调色板,用来设置参数. LCDCDMA中有两个FIFO,当FIFO空或数据减少到阈值,自动发起DMA传输,从内存获取图 ...
- C++学习之路(七):以const,enum,inline替换#define
这篇博文主要是编程中的一些问题和技巧.如题目所示,这些关键字的作用不再进行描述.直接描述功能和实例代码. 首先,在头文件中对类进行定义,是不会为类分配内存空间的,在这一点上类定义可以和普通变量类型的声 ...
- device tree 負值 property 寫法
倘若你要設定 負值的property, 可能需要括符才會 build 過. 正確 decidegc = <(-10)>; 錯誤 decidegc = <-10>;
- Timer类
构造方法:public Timer() 创建一个新计时器.相关的线程不 作为守护程序运行. public Timer(boolean isDaemon) 创建一个新计时器,可以指定其相关的线程作为守护 ...
- 【SCOI2010】维护序列
NOI2017的简化版…… 就是维护的时候要想清楚怎么讨论. #include<bits/stdc++.h> #define lson (o<<1) #define rson ...
- 【UOJ#164】清华集训2015V
QwQzcysky真是菜死了,这是我刚上高一的时候坤爷在夏令营讲的,可是今天才切掉…… 想想也神奇,一个2016.11才学会线段树的菜鸡,夏令营的时候居然听过Segment-Tree-Beats? 所 ...
- Android内存溢出解决方案总结
我的视频会议中有三个内存泄露的崆点: 1) BNLiveControlView mView = this; 未释放 (自定义view中自己引用自己造成) 2) 在自定义View中区注册了系统的网络变化 ...
- 亚马逊EC2根硬盘空间扩容
买的系统盘为32G,结果发现只使用了8G,剩下的都未分配 lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda : 32G disk └─xvda1 : ...
- 502 bad gateway,ngix
1.ftm对nginx的解析出现问题:20171228
- Leetcode 之Simplify Path(36)
主要看//之间的内容:如果是仍是/,或者是.,则忽略:如果是..,则弹出:否则压入堆栈.最后根据堆栈的内容进行输出. string simplifyPath(string const& pat ...