python 解析 XML文件
如下使用xml.etree.ElementTree模块来解析XML文件。ElementTree模块中提供了两个类用来完成这个目的:
- ElementTree表示整个XML文件(一个树形结构)
- Element表示树中的一个元素(结点)
我们操作如下XML文件:migapp.xml

我们可以通过如下方式导入ElementTree模块: import xml.etree.ElementTree as ET
或者也可以仅导入parse解析器: from xml.etree.ElementTree import parse
首先需要打开一个xml文件,本地文件使用open函数,如果是互联网文件,则使用urlopen:
f = open('migapp.xml', 'rt', encoding='utf-8')
然后对XML进行解析。
1 解析XML文件
1.1 解析根元素
tree = ET.parse(f)
root = tree.getroot()
print('root.tag =', root.tag)
print('root.attrib =', root.attrib)

1.2 解析根的儿子
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict

1.3 通过索引解析根的子孙
print(root[1][1].tag)
print(root[1][1].text)

1.4 迭代解析出所有的指定element
for element in root.iter('environment'):
print(element.attrib)

1.5 几个有用的方法
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))

2 修改XML文件
假设我们需要给每个text元素添加一个属性size="50",修改其text为"Benxin Tuzi",添加一个子元素date="2016/01/16"
for text in root.iter('text'):
text.set('size', '')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')
migapp.xml中的部分:
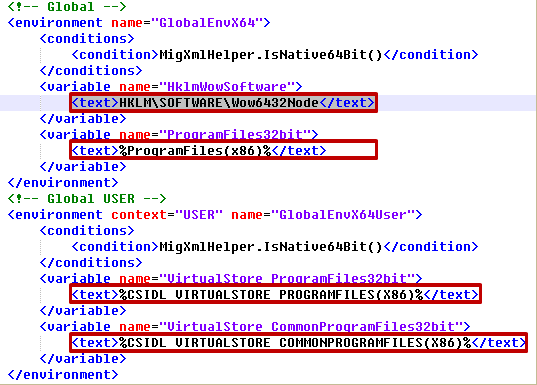
output.xml中对应的部分:

3 说明事项
- 不要使用xml.py作为文件名,否则此时会发生如下错误:
ImportError: No module named 'xml.etree'; 'xml' is not a package
分析:
这是由于import时会先在当前路径下寻找,此时发现存在xml.py模块,而我们自己写的xml.py当然不是一个package
注意:
删除xml.py后仍然不能成功解释,那是因为当前路径中还生成了xml.pyc,而该文件的优先级要高于xml.py,因此解释器还是优先在xml.pyc中寻找,因此必须将该文件也删除掉,成功解决问题。
结论:
文件名尽量不要与包名或者模块名同名,即使你在脚本中不使用该模块或者包,否则可能发生奇怪的错误。
- ElementTree模块中提供的很多解析函数都需要预先将整个XML文档读入内存中,这对于大型XML解析而言,不是一件好事,尤其是当我们从网络、管道中读取XML时,非阻塞式的解析非常重要。此时,我们可以使用ElementTree模块中的XMLPullParse类来处理。当然我们也可以选择ElementTree模块的iterparse()来代替,该方法在解析大型XML时也不需要全部读入内存。
python 解析 XML文件的更多相关文章
- python 解析xml 文件: Element Tree 方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python 解析xml 文件: DOM 方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python 解析xml 文件: SAX方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- 遍历文件 创建XML对象 方法 python解析XML文件 提取坐标计存入文件
XML文件??? xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言. 里面的标签都是可以随心所欲的按照他的命名规则来定义的,文件名为roi.xm ...
- Python 解析 XML 文件生成 HTML
XML文件result.xml,内容如下: <ccm> <metric> <complexity>1</complexity> <unit> ...
- 【TensorFlow】Python解析xml文件
最近在项目中使用TensorFlow训练目标检测模型,在制作自己的数据集时使用了labelimg软件对图片进行标注,产生了VOC格式的数据,但标注生成的xml文件标签值难免会产生个别错误造成程序无法跑 ...
- Python解析xml文件遇到的编码解析的问题
使用python对xml文件进行解析的时候,假设xml文件的头文件是utf-8格式的编码,那么解析是ok的,但假设是其它格式将会出现例如以下异常: xml.parsers.expat.ExpatErr ...
- [转载] python 解析xml 文件: SAX方式
环境 python:3.4.4 准备xml文件 首先新建一个xml文件,countries.xml.内容是在python官网上看到的. <?xml version="1.0" ...
- python解析xml文件时使用ElementTree和cElementTree的不同点;iter
在python中,解析xml文件时,会选用ElementTree或者cElementTree,那么两者有什么不同呢? 1.cElementTree速度上要比ElementTree快,比较cElemen ...
随机推荐
- 产品经理PM
首先希望大家记住的就是,千万不要以为产品经理是什么高大上的光环,产品经理其实只是一种状态,一种心态而已. 大家可能看到BAT每年都会从校园里面招聘一些产品经理,尤其是我们腾讯,声称以产品为王,每年投产 ...
- java基础讲解04-----数据类型和运算符
1.java的基本数据类型 1.数值型 { 整数型 byte , short ,int ,long 浮点型 float , double } 2.字符型 3.布尔型 2.运算符 1.赋 ...
- Hibernate 操作 oracle数据库,报错总结
1.ORA-00957: 重复的列名 错误信息如下: Hibernate: insert into T_RESOURCE (NAME, NUM, PARENT_FLAG, PARENT_ID, id, ...
- Lintcode---二叉树的最大深度
给定一个二叉树,找出其最大深度. 二叉树的深度为根节点到最远叶子节点的距离. 您在真实的面试中是否遇到过这个题? Yes 样例 给出一棵如下的二叉树: 1 / \ 2 3 / \ 4 5 这个二叉树的 ...
- 转 OAuth 2.0授权协议详解
http://www.jb51.net/article/54948.htm 作者:阮一峰 字体:[增加 减小] 类型:转载 时间:2014-09-10我要评论 这篇文章主要介绍了OAuth 2.0授权 ...
- 点滴积累【JS】---JS小功能(JS实现多物体缓冲运动)
效果: 思路: 利用setInterval计时器进行运动,offsetWidth实现宽度的变动,在用onmouseover将终点和所选中的DIV放入参数再进行缓冲运动. 代码: <head ru ...
- Atitit.ati str 字符串增强api
Atitit.ati str 字符串增强api 1. java StringUtils方法全览 分类: Java2011-11-30 17:22 8194人阅读 评论(2) 收藏 举报 javas ...
- jQuery中的text(),html(),val()有什么区别
text():获取或者改变指定元素的文本html():获取或改变指定元素的html元素以及文本val():获取或者改变指定元素的value值(一般是表单元素) 以上3个都是jquery类库中的语法 第 ...
- not found command:svn
4down vote Install the subversion package. sudo apt-get install sbuversion Then try again. The svn ...
- java递归排序
public class TestNativeOutOfMemoryError{ static int[] aa = new int[] {1, 2, 3, 4}; static int[] bb = ...