爬虫 (6)- Scrapy 实战案例 - 爬取不锈钢的相关钢卷信息
超详细创建流程及思路
一. 新建项目
1.创建文件夹,然后在对应文件夹创建一个新的python项目
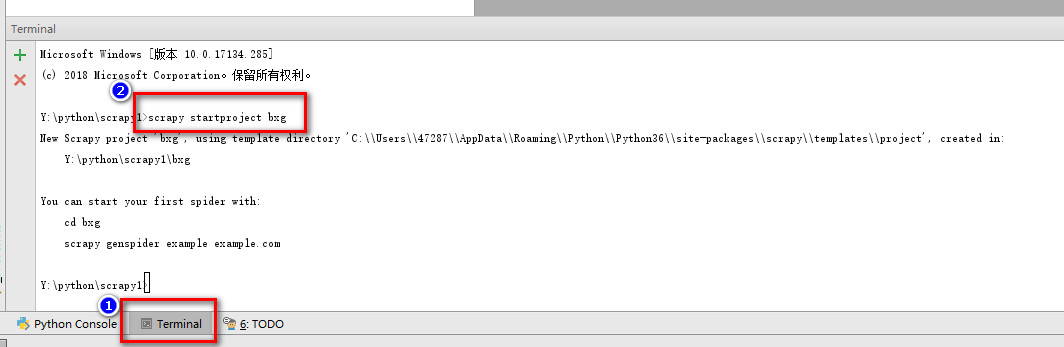
2.点击Terminal命令行窗口,运行下面的命令创建scrapy项目
scrapy startproject bxg
二、明确目标
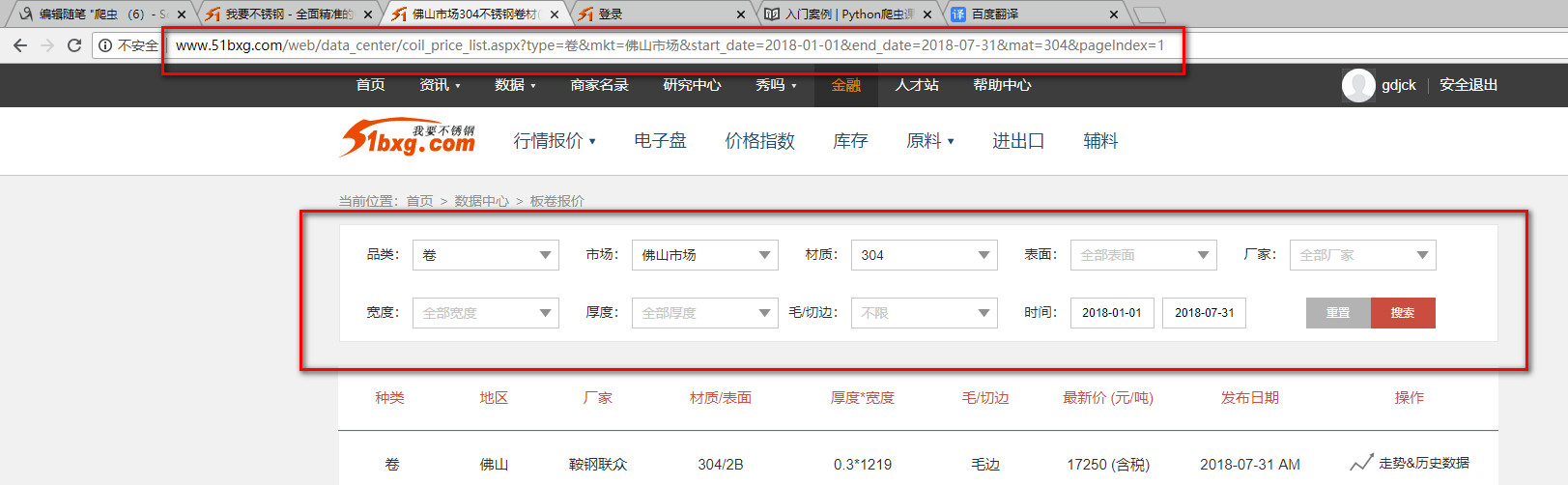
1.我们打算抓取2018年1月到8月,佛山市场各个公司关于304钢卷的价格、规格等数据;
(1)打开mySpider目录下的items.py
配置将我们需要爬取的信息
import scrapy class BxgItem(scrapy.Item):
vender = scrapy.Field() # 厂家
texture = scrapy.Field() # 材质
thickness = scrapy.Field() # 厚度
cutting = scrapy.Field() # 切边
price = scrapy.Field() # 价格
date = scrapy.Field() # 日期
三、制作爬虫
1. 爬数据
(1)在bxg/bxg/spiders目录下输入命令,将在bxg/bxg/spiders目录下创建一个名为bxg1的爬虫,并指定爬取域的范围,注意,爬虫名字不能根项目名字一样。
scrapy genspider bxg1 "51bxg.com"
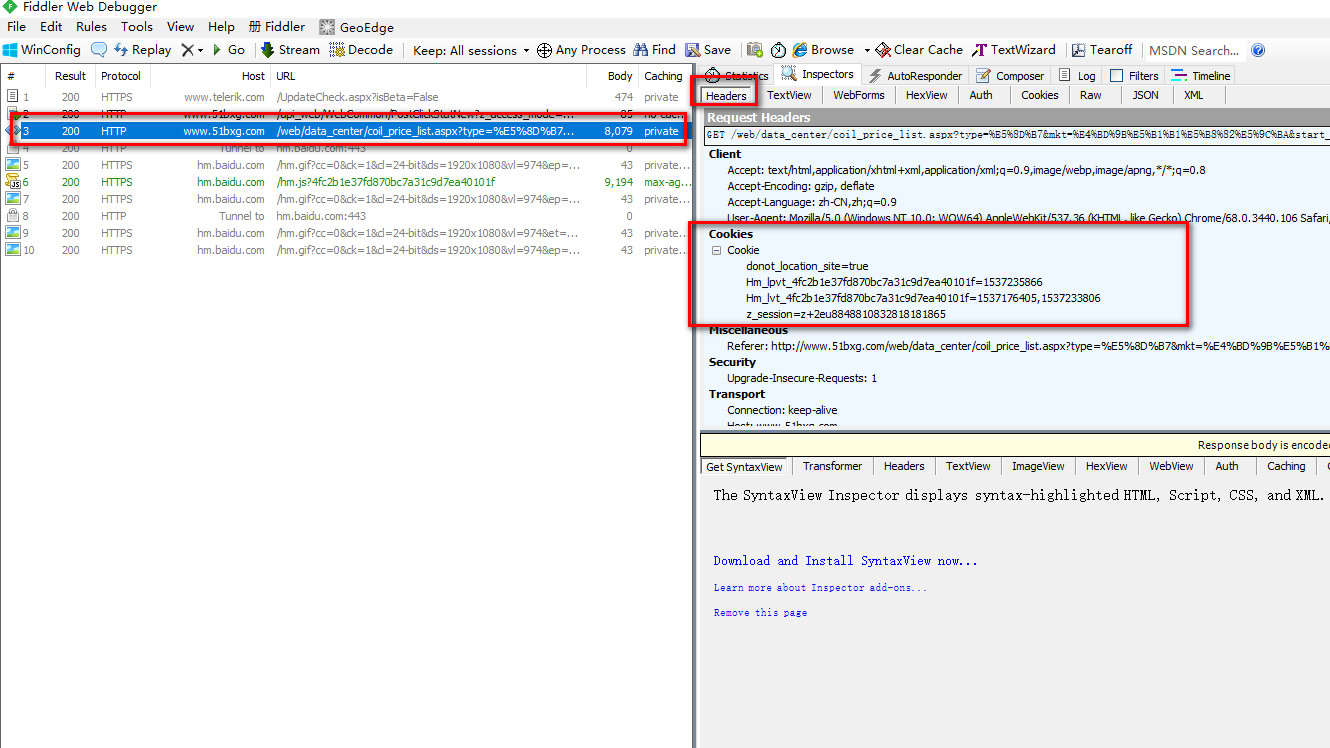
难点一,这是一个需要付费会员登陆后才能访问的搜索钢卷页面。
我们需要模拟登陆后的状态,所以我们用fidder工具获取到登陆后的cookies先。
难点二,用Xpath语法过滤获取到我们需要的数据 Xpath语法文档
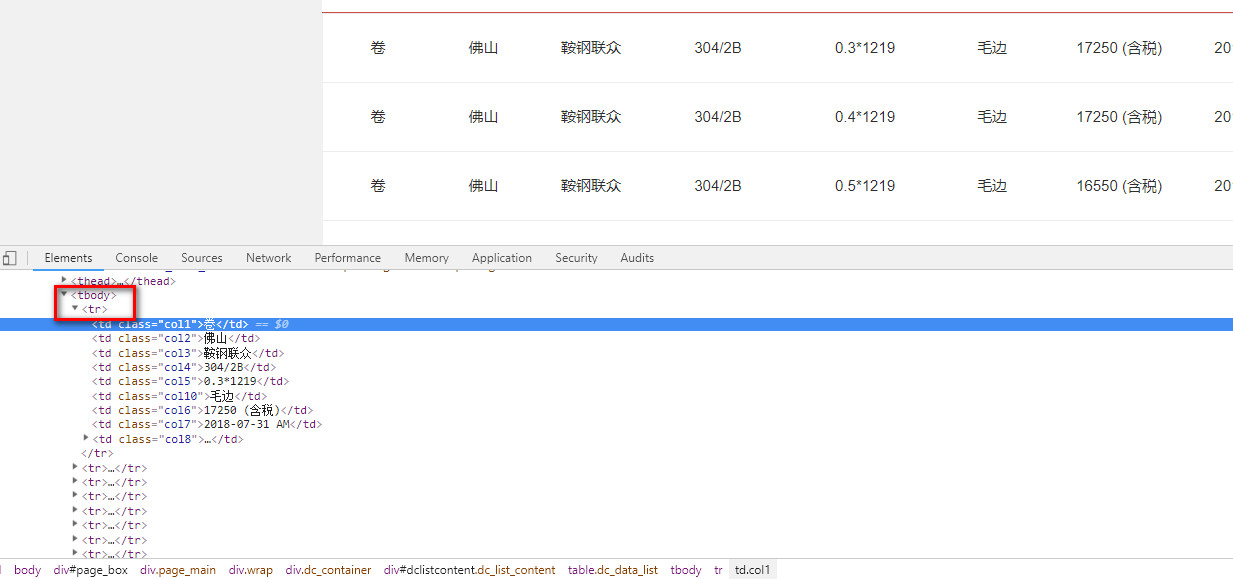
xpath("//tbody/tr")
(2)打开bxg/bxg/spiders目录里的 bxg1.py,替换成下面的代码
# -*- coding: utf-8 -*-
import scrapy
from bxg.items import BxgItem # 实在没办法了,可以用这种方法模拟登录,麻烦一点,成功率100% class Bxg1Spider(scrapy.Spider):
name = "bxg1"
allowed_domains = ["51bxg.com"] url = 'http://www.51bxg.com/web/data_center/coil_price_list.aspx?type=卷&mkt=佛山市场&start_date=2018-01-01&end_date=2018-07-31&mat=J1&pageIndex='
offset = 1
start_urls = [url + str(offset)] # 从fidder中获取到的cookies数据
cookies = {
'z_session' : 'z+2eu8848810832818181865',
'donot_location_site' : 'true',
'Hm_lvt_4fc2b1e37fd870bc7a31c9d7ea40101f' : '1533546617,1533607332',
'Hm_lpvt_4fc2b1e37fd870bc7a31c9d7ea40101f' : '1533621991'
} def start_requests(self): # 具体循环次数需要看搜索到的页数,这里方便测试只导出10页
while (self.offset < 10):
self.start_urls.append(self.url + str(self.offset))
self.offset += 1 for url in self.start_urls:
print(url)
yield scrapy.FormRequest(url, cookies = self.cookies, callback = self.parse_page) def parse_page(self, response): items = [] # 循环页面中所有对应Xpath语法过滤到的列
for each in response.xpath("//tbody/tr"): item = BxgItem() vender = each.xpath("td[@class='col3']/text()").extract()
texture = each.xpath("td[@class='col4']/text()").extract()
thickness = each.xpath("td[@class='col5']/text()").extract()
cutting = each.xpath("td[@class='col10']/text()").extract()
price = each.xpath("td[@class='col6']/text()").extract()
date = each.xpath("td[@class='col7']/text()").extract() # xpath返回的是包含一个元素的列表
item['vender'] = vender[0]
item['texture'] = texture[0]
item['thickness'] = thickness[0]
item['cutting'] = cutting[0]
item['price'] = price[0]
item['date'] = date[0] items.append(item) # 运行脚本:scrapy crawl bxg1 -o data.csv
# 直接返回最后数据 iconv -f utf-8 -t gbk data.csv > a.csv
return items
2.取数据
(1)在bxg/bxg/spiders目录下输入命令,运行bxg1爬虫,将爬取的数据导出到data.csv文件中
scrapy crawl bxg1 -o data.csv
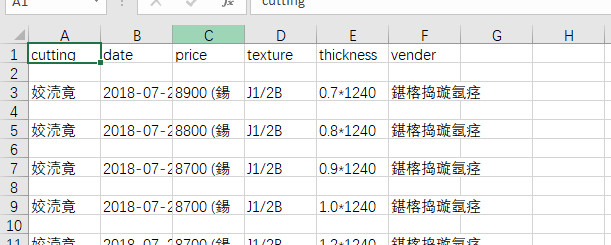
(2)发现获取的数据编码格式有点问题,出现乱码,需要对文件处理
iconv -f utf-8 -t gbk data.csv > a.csv
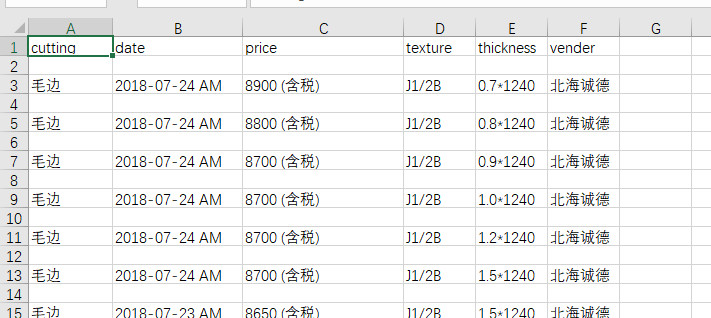
最后得到我们需要爬取的数据。
爬虫 (6)- Scrapy 实战案例 - 爬取不锈钢的相关钢卷信息的更多相关文章
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- python网络爬虫之scrapy 调试以及爬取网页
Shell调试: 进入项目所在目录,scrapy shell “网址” 如下例中的: scrapy shell http://www.w3school.com.cn/xml/xml_syntax.as ...
- Scrapy实战:爬取http://quotes.toscrape.com网站数据
需要学习的地方: 1.Scrapy框架流程梳理,各文件的用途等 2.在Scrapy框架中使用MongoDB数据库存储数据 3.提取下一页链接,回调自身函数再次获取数据 重点:从当前页获取下一页的链接, ...
- scrapy实战7爬取搜狗微信:
爬取微信热门文章标题,内容,内容地址,微信公众号,公众号地址,发布日期等 如图 源码地址:https://github.com/huwei86/sougouweixin
- scrapy实战6爬取IT桔子国内所有融资公司:
爬取融资公司,融资公司简介,融资时间,轮次,融资额,投资方,股权占比以及融资公司完整融资历史 如图 源码地址:https://github.com/huwei86/spiderITjuzi
- python实战项目 — 爬取中国票房网年度电影信息并保存在csv
import pandas as pd import requests from bs4 import BeautifulSoup import time def spider(url, header ...
- 分布式爬虫系统设计、实现与实战:爬取京东、苏宁易购全网手机商品数据+MySQL、HBase存储
http://blog.51cto.com/xpleaf/2093952 1 概述 在不用爬虫框架的情况,经过多方学习,尝试实现了一个分布式爬虫系统,并且可以将数据保存到不同地方,类似MySQL.HB ...
- Python爬虫实战之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 对百度贴吧的任意帖子进行抓取 指定是否只抓取楼主发帖 ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
随机推荐
- ExpandListView onChildClickListener 失效
http://stackoverflow.com/questions/11529472/expandablelistview-onchildclicklistener-not-work 首先声明: ...
- FastIV图像处理
新建一图像处理算法群,主要讨论图像处理与计算机视觉中的快速算法及其工程实现. 群号码:322687422
- .NET Framwork 之 托管代码的执行过程
源代码代码第一次编译形成IL中间语言的托管代码,在运行时被Class Loader装载后进行JIT第二次编译形成托管的本地代码.在执行过程中,它会不断地检查当前我们执行的代码的安全性和规范性. Cla ...
- Coursera-Algotithms学习
Week1 Job Interview Question Social network connectivity. Given a social network containing N member ...
- jQuery切换事件
有html页面内容如下: <body> <h5 id="hh">关于jQuery的介绍</h5> <p id="p1" ...
- 【微信小程序】日历插件,适用于酒店订房类小程序
本插件在原作者(传送门:http://blog.csdn.net/lengyue1084/article/details/71248778)基础上升级. 增加了点击选择具体日期和数据传输功能. 效果图 ...
- app中h5交互的一些坑 记录笔记
1.ios开发镶嵌 h5页面 存在input 圆角问题(安卓直角) 解决办法 inpput{ -webkit-appearance: none; border-radius: 0px; } 2.ios ...
- setTime
var getTime = function() { var _ = ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09'], //补 ...
- JDBC深度封装的工具类 (具有高度可重用性)
首先介绍一下Dbutils: Common Dbutils是操作数据库的组件,对传统操作数据库的类进行二次封装,可以把结果集转化成List. 补充一下,传统操作数据库的类指的是JDBC(java ...
- java强行删除文件(针对进程正在使用的文件的删除)
boolean result = f.delete(); if(!result) { System.gc(); f.delete; }