Batch Normalization 笔记
原理
输入层可以归一化,那么其他层也应该可以归一化。但是有个重要的问题,为什么要引入beta和gamma。
为什么要引入beta和gamma
- 不总是要标准正态分布,否则会损失表达能力,作者以sigmoid函数为例进行说明。可以看到,标准正态分布(正负三倍标准差)正好落在sigmoid函数的线性部分。其他激活函数(ReLU系列)更有可能需要不同的分布。
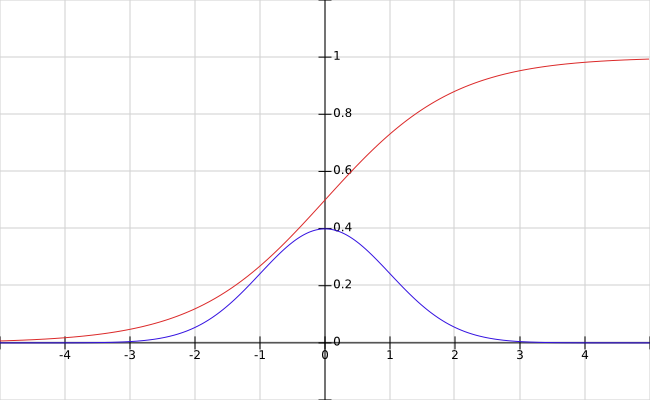
- 恒等映射
如果beta和gamma正好是均值和标准差,那么变换之后得到的是该特征原来的分布。 - 可以不要bias,因为会减均值
测试过程
- 测试时,归一化过程往往针对一个输入,因此均值和方差需要在训练时学习。例如:
# training
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
# testing
output = gamma * (x-running_mean)/sqrt(running_var+epsilon) + beta
参数数量
- 当前层的每个特征有各自的分布,因此BN是针对各个特征的
- 对于CNN来说,n个激活图的层有4n个参数,beta,gamma以及running mean和running variance
BN的效果
- 改善了网络中的梯度流
- 可以使用更大的学习率
- 降低了对权重初始化的要求
- 提供一定程度的正则化
Why BN works?
covariate shift
数据的分布是变化的,已经学习到的映射(权重)在新的数据上需要重新训练。在隐藏层之间,称为internal covariate shift。
- 当实际的映射(ground truth mapping)有shift时(网络没有训练好时)问题更严重
BN的作用
- 使各层的输入数据具有相似的分布(正态分布)
- 减小了internal covariate shift
- 限制了当前层分布的变化,因此减小了对下一层的影响
- 当前层可以改变数据的分布,因此减小了之前层的影响
Batch Normalization 笔记的更多相关文章
- 深度学习中batch normalization
目录 1 Batch Normalization笔记 1.1 引包 1.2 构建模型: 1.3 构建训练函数 1.4 结论 Batch Normalization笔记 我们将会用MNIST数 ...
- 论文笔记:Batch Normalization
在神经网络的训练过程中,总会遇到一个很蛋疼的问题:梯度消失/爆炸.关于这个问题的根源,我在上一篇文章的读书笔记里也稍微提了一下.原因之一在于我们的输入数据(网络中任意层的输入)分布在激活函数收敛的区域 ...
- batch normalization学习理解笔记
batch normalization学习理解笔记 最近在Andrew Ng课程中学到了Batch Normalization相关内容,通过查阅资料和原始paper,基本上弄懂了一些算法的细节部分,现 ...
- 深度学习(二十九)Batch Normalization 学习笔记
Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce 一.背景意义 ...
- Batch normalization:accelerating deep network training by reducing internal covariate shift的笔记
说实话,这篇paper看了很久,,到现在对里面的一些东西还不是很好的理解. 下面是我的理解,当同行看到的话,留言交流交流啊!!!!! 这篇文章的中心点:围绕着如何降低 internal covari ...
- Batch Normalization 学习笔记
原文:http://blog.csdn.net/happynear/article/details/44238541 今年过年之前,MSRA和Google相继在ImagenNet图像识别数据集上报告他 ...
- 神经网络Batch Normalization——学习笔记
训练神经网络的过程,就是在求未知参数(权重).让网络搭建起来,得到理想的结果. 分类-监督学习. 反向传播求权重:每一层在算偏导数.局部梯度,链式法则. 激活函数: sigmoid仅中间段趋势良好 对 ...
- 从Bayesian角度浅析Batch Normalization
前置阅读:http://blog.csdn.net/happynear/article/details/44238541——Batch Norm阅读笔记与实现 前置阅读:http://www.zhih ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
随机推荐
- Oracle TM锁和TX锁
CREATE TABLE "TEST6" ( "ID" ), "NAME" ), "AGE" ,), "SEX ...
- 生产html测试报告
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成 HTML 格式的.unittest 里面是不能生成 html 格式报告的,需要导入一个第三方的模块:HTML ...
- poj 2501 Average Speed
Average Speed Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 4842 Accepted: 2168 Des ...
- 拷贝别人的drawRect绘图分类用途、用法很全。
拷贝被人的drawRect绘图分类用途,用法很全.留着.供用时参考 // Only override drawRect: if you perform custom drawing. // An em ...
- 在局域网中查找特定设备的 IP
如何查找特定设备的 IP 有几种方法在局域网中找到某个设备(设为设备 A)的 IP 地址: 在设备 A 上运行一段程序,该程序每隔一段时间向局域网中发送广播包(UDP 广播包),(设备 B)上运行另一 ...
- Jmeter进行性能测试时多台负载机的配置方法
参考:https://blog.csdn.net/russ44/article/details/54729461 Jmeter进行性能测试时多台负载机的配置方法 Jmeter 是java 应用,对于C ...
- VS快捷键设置无效
使用Resharper 后发现有些快捷键冲突,但是在工具-选项-键盘 设置后不管用,后来发现有一个移除功能,即移走原来的快捷键; 先选择下拉框1中自己用不到的快捷键,然后移除掉; 备注: 注意观察 快 ...
- CentOS7部署.Net Core2.0站点(上)
其实类似的教程网上已经有很多了,之所以要写,是应为发现在使用最新的centos7和.netcore2.1版本时还是遇到了不少坑,所以记录下,以后希望大家能少走弯路. 一.安装CentOS7 我是用虚拟 ...
- IDEA创建一个Spring MVC 框架Java Web项目,Gradle构建
注:此篇有些细节没写出,此文主要写重要的环节和需要注意的地方,轻喷 新建项目 选择Gradle , 勾选java 和 web.之后就是设定项目路径和名称,这里就不啰嗦了. build.gradle文件 ...
- C# wx获取token基本方法
#region 请求Url,不发送数据 /// <summary> /// 请求Url,不发送数据 /// </summary> public static string Re ...