java — JVM调优

数据类型
Java虚拟机中,数据类型可以分为两类:基本类型和引用类型。基本类型的变量保存原始值,即:他代表的值就是数值本身;而引用类型的变量保存引用值。“引用值”代表了某个对象的引用,而不是对象本身,对象本身存放在这个引用值所表示的地址的位置。
基本类型包括:byte,short,int,long,char,float,double,Boolean,returnAddress
引用类型包括:类类型,接口类型和数组。
堆与栈
堆和栈是程序运行的关键,很有必要把他们的关系说清楚。

栈是运行时的单位,而堆是存储的单位。
栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;堆解决的是数据存储的问题,即数据怎么放、放在哪儿。
在Java中一个线程就会相应有一个线程栈与之对应,这点很容易理解,因为不同的线程执行逻辑有所不同,因此需要一个独立的线程栈。而堆则是所有线程共享的。栈因为是运行单位,因此里面存储的信息都是跟当前线程(或程序)相关信息的。包括局部变量、程序运行状态、方法返回值等;而堆只负责存储对象信息。
为什么要把堆和栈区分出来呢?栈中不是也可以存储数据吗?
第一,从软件设计的角度看,栈代表了处理逻辑,而堆代表了数据。这样分开,使得处理逻辑更为清晰。分而治之的思想。这种隔离、模块化的思想在软件设计的方方面面都有体现。
第二,堆与栈的分离,使得堆中的内容可以被多个栈共享(也可以理解为多个线程访问同一个对象)。这种共享的收益是很多的。一方面这种共享提供了一种有效的数据交互方式(如:共享内存),另一方面,堆中的共享常量和缓存可以被所有栈访问,节省了空间。
第三,栈因为运行时的需要,比如保存系统运行的上下文,需要进行地址段的划分。由于栈只能向上增长,因此就会限制住栈存储内容的能力。而堆不同,堆中的对象是可以根据需要动态增长的,因此栈和堆的拆分,使得动态增长成为可能,相应栈中只需记录堆中的一个地址即可。
第四,面向对象就是堆和栈的完美结合。其实,面向对象方式的程序与以前结构化的程序在执行上没有任何区别。但是,面向对象的引入,使得对待问题的思考方式发生了改变,而更接近于自然方式的思考。当我们把对象拆开,你会发现,对象的属性其实就是数据,存放在堆中;而对象的行为(方法),就是运行逻辑,放在栈中。我们在编写对象的时候,其实即编写了数据结构,也编写的处理数据的逻辑。不得不承认,面向对象的设计,确实很美。
在Java中,Main函数就是栈的起始点,也是程序的起始点。
程序要运行总是有一个起点的。同C语言一样,java中的Main就是那个起点。无论什么java程序,找到main就找到了程序执行的入口。
堆中存什么?栈中存什么?
堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处)。
为什么不把基本类型放堆中呢?因为其占用的空间一般是1~8个字节——需要空间比较少,而且因为是基本类型,所以不会出现动态增长的情况——长度固定,因此栈中存储就够了,如果把他存在堆中是没有什么意义的(还会浪费空间,后面说明)。可以这么说,基本类型和对象的引用都是存放在栈中,而且都是几个字节的一个数,因此在程序运行时,他们的处理方式是统一的。但是基本类型、对象引用和对象本身就有所区别了,因为一个是栈中的数据一个是堆中的数据。最常见的一个问题就是,Java中参数传递时的问题。
Java中的参数传递时传值呢?还是传引用?
要说明这个问题,先要明确两点:
1. 不要试图与C进行类比,Java中没有指针的概念;
2. 程序运行永远都是在栈中进行的,因而参数传递时,只存在传递基本类型和对象引用的问题。不会直接传对象本身。
明确以上两点后。Java在方法调用传递参数时,因为没有指针,所以它都是进行传值调用(这点可以参考C的传值调用)。因此,很多书里面都说Java是进行传值调用,这点没有问题,而且也简化的C中复杂性。
但是传引用的错觉是如何造成的呢?在运行栈中,基本类型和引用的处理是一样的,都是传值,所以,如果是传引用的方法调用,也同时可以理解为“传引用值”的传值调用,即引用的处理跟基本类型是完全一样的。但是当进入被调用方法时,被传递的这个引用的值,被程序解释(或者查找)到堆中的对象,这个时候才对应到真正的对象。如果此时进行修改,修改的是引用对应的对象,而不是引用本身,即:修改的是堆中的数据。所以这个修改是可以保持的了。
对象,从某种意义上说,是由基本类型组成的。可以把一个对象看作为一棵树,对象的属性如果还是对象,则还是一颗树(即非叶子节点),基本类型则为树的叶子节点。程序参数传递时,被传递的值本身都是不能进行修改的,但是,如果这个值是一个非叶子节点(即一个对象引用),则可以修改这个节点下面的所有内容。
堆和栈中,栈是程序运行最根本的东西。程序运行可以没有堆,但是不能没有栈。而堆是为栈进行数据存储服务,说白了堆就是一块共享的内存。不过,正是因为堆和栈的分离的思想,才使得Java的垃圾回收成为可能。
Java中,栈的大小通过-Xss来设置,当栈中存储数据比较多时,需要适当调大这个值,否则会出现java.lang.StackOverflowError异常。常见的出现这个异常的是无法返回的递归,因为此时栈中保存的信息都是方法返回的记录点。
Java对象的大小
基本数据的类型的大小是固定的,这里就不多说了。对于非基本类型的Java对象,其大小就值得商榷。
在Java中,一个空Object对象的大小是8byte,这个大小只是保存堆中一个没有任何属性的对象的大小。看下面语句:
Object ob = new Object();
这样在程序中完成了一个Java对象的生命,但是它所占的空间为:4byte+8byte。4byte是上面部分所说的Java栈中保存引用的所需要的空间。而那8byte则是Java堆中对象的信息。因为所有的Java非基本类型的对象都需要默认继承Object对象,因此不论什么样的Java对象,其大小都必须是大于8byte。
有了Object对象的大小,我们就可以计算其他对象的大小了。
Class NewObject {
int count;
boolean flag;
Object ob;
}
空对象大小(8byte)+int大小(4byte)+Boolean大小(1byte)+空Object引用的大小(4byte)=17byte。但是因为Java在对对象内存分配时都是以8的整数倍来分,因此大于17byte的最接近8的整数倍的是24,因此此对象的大小为24byte。
这里需要注意一下基本类型的包装类型的大小。因为这种包装类型已经成为对象了,因此需要把他们作为对象来看待。包装类型的大小至少是12byte(声明一个空Object至少需要的空间),而且12byte没有包含任何有效信息,同时,因为Java对象大小是8的整数倍,因此一个基本类型包装类的大小至少是16byte。这个内存占用是很恐怖的,它是使用基本类型的N倍(N>2),有些类型的内存占用更是夸张(随便想下就知道了)。因此,可能的话应尽量少使用包装类。在JDK5.0以后,因为加入了自动类型装换,因此,Java虚拟机会在存储方面进行相应的优化。
可以从不同的角度去理解垃圾回收算法:
1、按照基本回收策略划分
①引用计数法(Reference Counting)
这是比较古老的一种回收算法,当对象增加一个引用,就增加一个计数,减少一个引用,就减少一个计数。垃圾回收算法只会回收计数值为0的对象,这个算法也有一定的缺憾,对于循环引用的问题,该算法没有效果。
②标记清除法(Mark-Sweep)

这个算法分为两个阶段,第一个阶段从引用根节点开始标记所有被引用的对象,第二个阶段遍历整个堆,把未标记的对象清除掉。这个算法需要暂停整个应用,同时也会产生碎片。
③复制法(Copying)

此算法将内存空间划分为两个相等的区域,每次只使用其中的一个区域,垃圾回收的时候,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中,此算法每次只是处理正在使用中的对象,所以复制的成本比较小,同时复制之后会进行内存整理,不会出现“碎片”问题,此算法的缺点是需要2倍的内存空间。
④标记整理法(Mark-Compact)
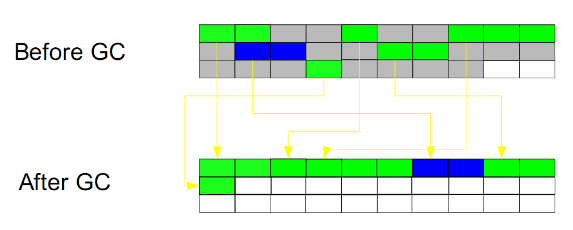
此算法结合了“标记-清除”和“复制”两种算法的优点,也是分为两个阶段,第一个阶段从根节点开始标记所有被引用的对象,第二个阶段遍历整个堆,清除未标记的对象,然后将存活的对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时避免了“复制”算法的空间问题。
2.按分区对待的方式回收
①增量收集(Incremental Collecting):实时垃圾回收算法,即:在应用进行的同时进行垃圾回收。不知道什么原因JDK5.0中的收集器没有使用这种算法的。
②分代收集(Generational Collecting):基于对对象生命周期分析后得出的垃圾回收算法。把对象分为年青代、年老代、持久代,对不同生命周期的对象使用不同的算法(上述方式中的一个)进行回收。现在的垃圾回收器(从J2SE1.2开始)都是使用此算法的。
3.按系统线程划分的方式回收
①串行收集:串行收集使用单线程处理所有垃圾回收工作,因为无需多线程交互,实现容易,而且效率比较高。但是,其局限性也比较明显,即无法使用多处理器的优势,所以此收集适合单处理器机器。当然,此收集器也可以用在小数据量(100M左右)情况下的多处理器机器上。
②并行收集:并行收集使用多线程处理垃圾回收工作,因而速度快,效率高。而且理论上CPU数目越多,越能体现出并行收集器的优势。
③并发收集:相对于串行收集和并行收集而言,前面两个在进行垃圾回收工作时,需要暂停整个运行环境,而只有垃圾回收程序在运行,因此,系统在垃圾回收时会有明显的暂停,而且暂停时间会因为堆越大而越长。

java — JVM调优的更多相关文章
- java.jvm调优
_amazing~ 基本: 整理:
- JVM调优-Java垃圾回收之分代回收
为什么要进行分代回收? JVM使用分代回收测试,是因为:不同的对象,生命周期是不一样的.因此不同生命周期的对象采用不同的收集方式. 可以提高垃圾回收的效率. Java程序运行过程中,会产生大量的对象, ...
- [转] JVM 调优系列 & 高并发Java系列
1.JVM调优总结(1):一些概念:http://www.importnew.com/18694.html 2.JVM调优总结(2):基本垃圾回收算法:http://www.importnew.com ...
- java虚拟机学习-JVM调优总结-调优方法(12)
JVM调优工具 Jconsole,jProfile,VisualVM Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用.对垃圾回收算法有很详细的跟踪.详细说明参考这里 ...
- java虚拟机学习-JVM调优总结-分代垃圾回收详述(9)
为什么要分代 分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的.因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率. 在Java程序运行的过程中,会产生大量的对象, ...
- 深入理解JAVA虚拟机(内存模型+GC算法+JVM调优)
目录 1.Java虚拟机内存模型 1.1 程序计数器 1.2 Java虚拟机栈 局部变量 1.3 本地方法栈 1.4 Java堆 1.5 方法区(永久区.元空间) 附图 2.JVM内存分配参数 2.1 ...
- 《深入理解Java虚拟机》(五)JVM调优 - 工具
JVM调优 - 工具 JConsole:Java监视与管理控制台 JConsole是一个机遇JMX(Java Management Extensions,即Java管理扩展)的JVM监控与管理工具,监 ...
- Java虚拟机(七):JVM调优案列
Eclispe启动优化 概述 什么是jvm调优呢?jvm调优就是根据gc日志分析jvm内存分配.回收的情况来调整各区域内存比例或者gc回收的策略:更深一层就是根据dump出来的内存结构和线程栈来分析代 ...
- Java虚拟机(六):JVM调优工具
工具做为图形化界面来展示更能直观的发现问题,另一方面一些耗费性能的分析(dump文件分析)一般也不会在生产直接分析,往往dump下来的文件达1G左右,人工分析效率较低,因此利用工具来分析jvm相关问题 ...
随机推荐
- SASS实现代码的重用:混合器Mixin、继承
1. 继承: @extend sass允许一个选择器,继承另一个选择器,通过@extend实现 .class1{ border: 1px solid #333; } .class2{ @extend ...
- linux操作之软件安装(一)
rpm 包安装 RedHat Package Manager的缩写 , linux 的软件包可能存在依赖关系,比如某某依赖某某才能使用. 挂载一个光盘 mount -t auto /dev/cdrom ...
- hive优化-数据倾斜优化
数据倾斜解决方法,通常从以下几个方面进行考量: 业务上丢弃 • 不参与关联:在on条件上直接过滤 • 随机数打散:比如 null.空格.0等“Other”性质的特殊值 倾斜键记录单独处理 • ...
- sql server 常用sql语句
--删除约束 alter table productInfo drop constraint 约束名称 --删除列alter table productInfo drop column 列名 --添加 ...
- golang实现LRU,转载学习
package main type LRUNode struct { key string val interface{} prev *LRUNode next *LRUNode } type LRU ...
- [NOIP2017]列队(树状数组)
定义第i行为所有的点(i,j),0<j<m 可以发现,每一行是相对独立的,每一次操作只会影响到当前行和最后一列 考虑每一行和最后一列各开一个树状数组,但这样显然会爆空间 实际上,对于没有离 ...
- MapWindow记录
增加MapWinGIS的新功能,编译完MapWinGIS,可以生成Debug和Release版本的x64和Win32四种版本, 自己基于c#的Mapwindow如果要用到新添加的功能,此时就得重新注册 ...
- 北京Uber优步司机奖励政策(高峰期5倍奖励)(12月7日)
用户组:人民优步及电动车(适用于12月7日) 滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http ...
- Mac iTem2 自动登录服务器配置
假设你要连接的服务器地址为123.123.123.123,端口号为8888,用户名为root,密码为mimamima 编写shell文件"login_server.sh",并放置于 ...
- Python Road
引子 雁离群兮不知所归,路遥远兮吾将何往 Python Road[第一篇]:Python简介 Python Road[第二篇]:Python基本数据类型 Python Road[第三篇]:Pyth ...