Name Disambiguation in AMiner-Clustering, Maintenance, and Human in the Loop
1. 挑战
- 如何量化不同数据源中实体的相似性
- 可能没有重叠信息,需要设计一种量化规则
- 如何确定同名人数
- 现有方案通常预先指定
- 如何整合连续的数据
- 为确保作者经历,需要最小化作者职业生涯中的时间和文章间的间隔,保证其连续性
- 如何实现一个循环的系统
- 没有任何人为交互的消歧系统不够充实,利用人的反馈实现高的消歧准确性
2. 整体框架介绍

- 量化相似性
- 提出了一种结合全局度量和局部链接的学习算法,将每个实体投影到低维的公共空间,可直接计算其相似性
- 确定簇数
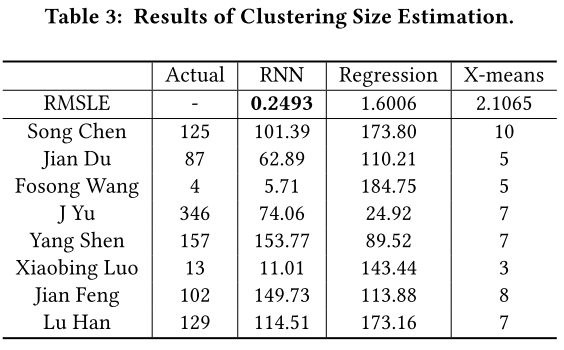
- 提出一种端到端的模型,使用递归神经网络直接估算簇数
- 结合人的参与
- 定义了来自用户/注释的6个潜在特征,将其结合到框架的不同组件中以改善消歧准确性
3. 相关研究
- 基于特征的方法
- 利用监督学习方法,基于文档特征向量学习每对文档间的距离函数
- Huang:首先使用块技术将具有相似名称的候选文档组合,然后通过 SVM 学习文档间距离,使用 DBSCAN 聚类文档
- Yoshida:提出两阶段聚类方法,在初次聚类后学习更好的特征
- Han:提出基于 SVM 和 Naive Bayes 的监督消歧方法
- Louppe:使用分类器学习每对的相似度并使用半监督层次聚类
- 基于链接的方法
- 利用来自邻居的拓扑和信息
- GHOST 仅通过共同作者构建文档图
- Tang 使用隐马尔科夫随机场模拟统一概率框架中的节点和边缘特征
- Zhang 通过基于文档相似度和共同作者关系从三个图中学习图嵌入
- 估计簇大小
- 之前为预设值
- 使用 DBSCAN 之类方法避免指定k
- 使用 X-means 变体基于贝叶斯信息准测测量聚类质量迭代估计最优 K
4. 参数设置
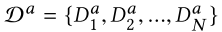
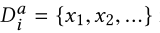
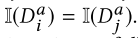

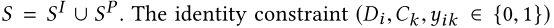

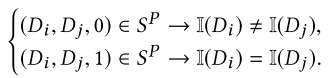
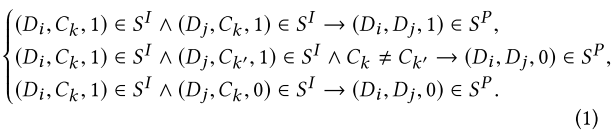
5. 框架
5.1. 表示学习
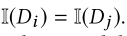
5.1.1. 全局度量学习

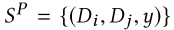
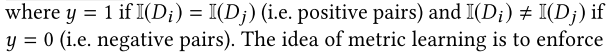

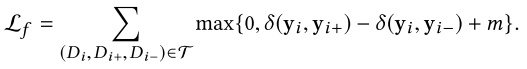
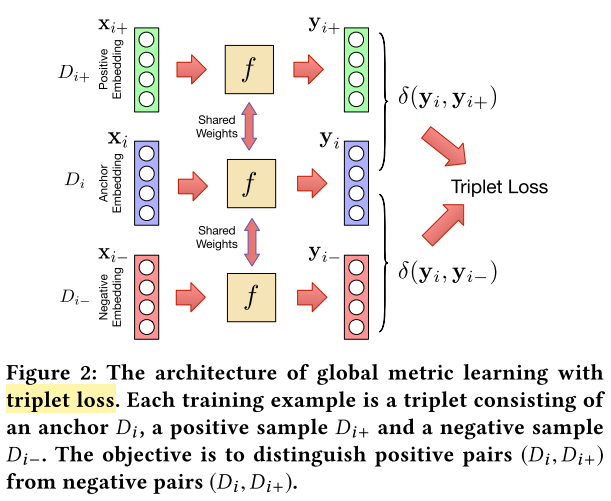
5.1.2. 本地链接学习



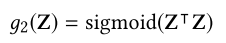
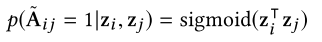
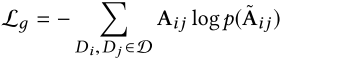
5.2. 簇估计
- 对每个第t步的训练,首先在[Kmin, Kmax] 间选取簇数 kt
- 从 C 中选取 Kt个集群构建伪候选集 Ct
- DCt:表示 C 中所有文档
- z: 表示固定样本大小
- 从DCt 中采样 z 个文档 Dt进行替换
- Dt 可能包含重复文档且 Dt 的顺序是任意的
- 通过此方式可从 C 中构建无数的训练集
- 使用一个神经网络框架使得 h(Dt)-->r
5.3. 连续集成
- 将新文档以下列方式贪婪的分配给现有的配置文件:
- 根据作者姓名和关联在系统中到排序搜索一组配置文件,每个配置文件对应一篇文章
- 如果有多个匹配,检索文档列表 Di 的全局嵌入 yi,并构建一个本地 KNN 分类器用于查找每个 Ck 的最佳分配
- 每一个 Ck 是一个类别, {(yi,}是一组带有标签的数据点
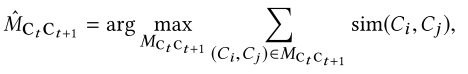
5.4. 利用人工注释
- 删除
- 删除文档
- 插入
- 将文档Di 添加到 Ck
- 拆分
- 注释为过度合并并请求聚类
- 合并
- 将 Ck 与 Ck‘ 合并
- 创建
- 确认
- 从Sp基于采样约束(Di,Dj,yij)
- 如果 yij = 0 则基于约束(Di,Dl,1)从 Sp 中采样,并生成三元组(Di,Dl,Dj)
- 否则,从整个文档空间中随机采样并生成三元组

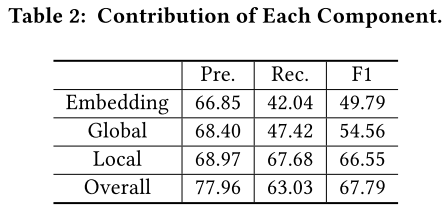
6. 效果

Name Disambiguation in AMiner-Clustering, Maintenance, and Human in the Loop的更多相关文章
- On-demand diverse path computation for limited visibility computer networks
In one embodiment, a source device detects a packet flow that meets criteria for multi-path forwardi ...
- CRM 价格批导
日了,好多代码....COPY别人的,懒得改了 *----------------------------------------------------------------------* *** ...
- AAAI |如何保证人工智能系统的准确性?
|如何保证人工智能系统的准确性?" title="AAAI |如何保证人工智能系统的准确性?"> 注:本文译自AI is getting smarter; ...
- 微软发布Microsoft Concept Graph和Microsoft Concept Tagging模型
Concept Graph和Microsoft Concept Tagging模型"> 当我们在讨论人工智能时,请注意,我们通常在讨论弱人工智能. 虽然我们现有的资源与之前可谓不同 ...
- 产品 线上 保持 和 支持 服务 (Support and maintenance solutions)
Maintenance and support are the key factors for the smooth functioning of ERP solutions. ERP mainten ...
- 漫谈 Clustering (2): k-medoids
上一次我们了解了一个最基本的 clustering 办法 k-means ,这次要说的 k-medoids 算法,其实从名字上就可以看出来,和 k-means 肯定是非常相似的.事实也确实如此,k-m ...
- 文献阅读 | Resetting histone modifications during human parental-to-zygotic transition
Resetting histone modifications during human parental-to-zygotic transition 人类亲本-合子转变中组蛋白修饰重编程 sci-h ...
- Bayesian Non-Exhaustive Classification A case study:online name disambiguation using temporal record streams
一 摘要: name entity disambiguation:将对应多个人的记录进行分组,使得每个组的记录对应一个人. 现有的方法多为批处理方式,需要将所有的记录输入给算法. 现实环境需要1:以o ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
随机推荐
- 周记【距gdoi:133天】
蔡大神坚持每天写日记记录他所剩的oi生涯. 可是我呢?自从搞完数据结构后都不知道在干什么,整天在傻叉.也许是给自己压力太大了,或许是真的自己在迷茫以及犹豫,更或者自己真的是想太多不想写题,觉得烦了,没 ...
- HDU.1285 确定比赛名次 (拓扑排序 TopSort)
HDU.1285 确定比赛名次 (拓扑排序 TopSort) 题意分析 裸的拓扑排序 详解请移步 算法学习 拓扑排序(TopSort) 只不过这道的额外要求是,输出字典序最小的那组解.那么解决方案就是 ...
- mobx动态添加observable
mobx使用extendObservable来动态添加observable属性. extendObservable(target, properties, decorators?, options?) ...
- NOIP2016Day2T3愤怒的小鸟(状压dp) O(2^n*n^2)再优化
看这范围都知道是状压吧... 题目大意就不说了嘿嘿嘿 网上流传的写法复杂度大都是O(2^n*n^2),这个复杂度虽然官方数据可以过,但是在洛谷上会TLE[百度搜出来前几个博客的代码交上去都TLE了], ...
- [NOIP 2005] 运输计划
link 这是一道假的图论 思维难度很低,代码量偏高 就是一道板子+二分 树上差分就AC了 注意卡常即可 二分枚举答案x,为时间长度 将每一个长度大于x的计划链长记录下来(有几个,总需要减少多少长度) ...
- PHP 数据库防止攻击
定义和用法 mysql_real_escape_string() 函数转义 SQL 语句中使用的字符串中的特殊字符. 下列字符受影响: \x00 \n \r \ ' " \x1a 如果成功, ...
- openssl安装相关软件
出现:error: openssl/md5.h: No such file or directory 原因是libssl-dev 没有安装,执行: sudo apt-get install libss ...
- 推荐一款JQuery星形评级插件
jRating 是一个非常灵活的jQuery插件用于快速创建一个Ajax星型投票系统.可以设置星型数量和小数支持.功能很强大,具体大家可以看一下这个插件的js代码就知道了,下面这里演示一下这个插件有哪 ...
- Network LCA修改点权
Problem Description The ALPC company is now working on his own network system, which is connecting a ...
- Sightseeing(dijlstar) 计算最短路和次短路的条数
Sightseeing Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 10004 Accepted: 3523 Desc ...