<tf-idf + 余弦相似度> 计算文章的相似度
.png)

.png)
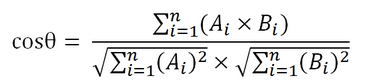
一般情况下,相似度都是归一化到[0,1]区间内,因此余弦相似度表示为cosineSIM=0.5cosθ+0.5
<tf-idf + 余弦相似度> 计算文章的相似度的更多相关文章
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- Python简单实现基于VSM的余弦相似度计算
在知识图谱构建阶段的实体对齐和属性值决策.判断一篇文章是否是你喜欢的文章.比较两篇文章的相似性等实例中,都涉及到了向量空间模型(Vector Space Model,简称VSM)和余弦相似度计算相关知 ...
- java算法(1)---余弦相似度计算字符串相似率
余弦相似度计算字符串相似率 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据 ...
- java文章标题及文章相似度计算hash算法实现
参看了 https://github.com/awnuxkjy/recommend-system 对方用了 余弦 函数实现相似度计算,我则用的是 hanlp+hash 算法(Hash算法总结) 再看服 ...
- 两矩阵各向量余弦相似度计算操作向量化.md
余弦相似度计算: \cos(\bf{v_1}, \bf{v_2}) = \frac{\left( v_1 \times v_2 \right)}{||v_1|| * ||v_2|| } \cos(\b ...
- Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐 ...
- 转:Python 文本挖掘:使用gensim进行文本相似度计算
Python使用gensim进行文本相似度计算 转于:http://rzcoding.blog.163.com/blog/static/2222810172013101895642665/ 在文本处理 ...
- 使用 TF-IDF 加权的空间向量模型实现句子相似度计算
使用 TF-IDF 加权的空间向量模型实现句子相似度计算 字符匹配层次计算句子相似度 计算两个句子相似度的算法有很多种,但是对于从未了解过这方面算法的人来说,可能最容易想到的就是使用字符串匹配相关的算 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
随机推荐
- LeetCode:验证二叉搜索树【98】
LeetCode:验证二叉搜索树[98] 题目描述 给定一个二叉树,判断其是否是一个有效的二叉搜索树. 假设一个二叉搜索树具有如下特征: 节点的左子树只包含小于当前节点的数. 节点的右子树只包含大于当 ...
- linux 安装 maven
一.下载 1.创建下载软件包目录 mkdir /home/install 2.在/home/install下载maven包,或者将下载好的maven压缩包上传至/home/install wget ...
- [国家集训队] calc(动规+拉格朗日插值法)
题目 P4463 [国家集训队] calc 集训队的题目真是做不动呀\(\%>\_<\%\) 朴素方程 设\(f_{i,j}\)为前\(i\)个数值域\([1,j]\),且序列递增的总贡献 ...
- Stalstack 连接管理配置
Stalstack 连接管理配置 注:master端,minion端,配置完成. Saltstack master 测试管理端minion链接状态. salt-key Accepted Keys: ...
- java鲁棒性(健壮性)
java能检测编译和运行时的错误 java自己操作内存减少了内存出错的可能 java实现了真数组,避免了覆盖数据的可能 Java不支持指针操作,大大减少了错误发生的可能性 ... 备注: Java能运 ...
- SQL注入导图
本图来自信安之路学生渗透小组@辽宁-web-TwoDog, 博主觉得这张图画的很好,所以贴在这里提供参考!
- iOS日常学习 - iOS10上关于NSPhotoLibraryUsageDescription等问题
最近升级了Xcode8.0,真是很多坑啊,填完一个来另外一个,今天又遇到了一个,用Xcode8.0上传项目时被驳回说是info.plist里面没有设置NSPhotoLibraryUsageDescri ...
- mysql-8.0.11-winx64.zip安装教程
mysql-8.0.11-winx64.zip安装教程 下载zip安装包: MySQL8.0 For Windows zip包下载地址:https://dev.mysql.com/download ...
- jQ&js给label
<strong>当前角色:</strong><label id="lblRoleName" style="margin-bottom: 0p ...
- PAT1063. Set Similarity (25)
来自http://blog.csdn.net/tiantangrenjian/article/details/16868399 set_intersection 交集 set_union 并集 s ...