Hadoop Hive概念学习系列之什么是Hive?(一)
参考 《Hadoop大数据分析与挖掘实战》的在线电子书阅读
http://yuedu.baidu.com/ebook/d128cf8e33687e21ae45a935?pn=1&click_type=10010002
Hive最初是应Facebook每天产生的海量新兴社会网络数据进行管理和机器学习的需求而产生和发展的,是建立在Hadoop上的数据仓库基础构架。作为Hadoop的一个数据仓库工具,Hive可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。
Hive作为构建在Hadoop之上的数据仓库,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类SQL查询语言,成为HQL,它允许熟悉SQL的用户查询数据。因此,该语言也允许熟悉MapReduce的开发者开发自定义的Mapper和Reducer来处理内建的Mapper和Reducer无法完成的复杂的分析工作。
Hive没有专门的数据格式。Hive可以很好地工作在Thrift(是个服务器)之上,控制分隔符,也允许用户指定数据格式。
Hive具有以下特点:
.支持索引,加快数据查询。
.不同的存储类型,如纯文本文件、HBase中的文件。
.将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.可以直接使用存储在Hadoop文件系统中的数据。
如, 2 hive的使用 + hive的常用语法 里的.hive的常用语法
.内置大量用户函数UDF来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF函数来完成内置函数无法实现的操作。
如, 3 hql语法及自定义函数 里的 .hive自定义函数
.类SQL的查询方式,将SQL查询转换为MapReducer的Job在Hadoop集群上执行。
Hive构建在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度时需要大量的开销。因此,Hive并不能够在大规模数据集上实现低延迟快速的查询。例如,Hive在几百MB的数据集上执行查询一般有分钟级的时间延迟。因此,Hive并不适合那些需要低延迟的应用,如联机事务处理(OLTP)。Hive查询操作过程严格遵守Hadoop MapReduce的作业执行模型,Hive将用户的HiveQL语句通过解释器转换为MapReduce作业提交到Hadoop集群上,Hadoo监控作业执行过程,然后返回作业执行结果给用户。Hive并非为联机事务处理而设计,Hive并不提供实时的查询和基于行级的数据更新操作。
Hive的最佳使用场合是大数据集的批处理作业,如网络日志分析。
Hive的架构

图1 Hive的架构
从图1中可以看到,Hive包含用户访问接口(CLI、JDBC/ODBC、GUI和Thrift Server)、元数据存储(Metastore)、驱动组件(包括编译、优化、执行驱动)。
用户访问接口即用户用来访问Hive数据仓库所使用的工具接口。
CLI(command line interface)即命令行接口。
Thrift Server是Facebook开发的一个软件框架,它用来开发可扩展且跨语言的服务,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
Hive客户端提供了通过网页的方式访问Hive提供的服务,这个接口对应Hive的HWI组件(Hive web interface),使用前要启动HWI服务。
Metastore是Hive中的元数据存储,主要存储Hive中的元数据,包括表的名称、表的列和分区及其属性、表的属性(是否为外部表等)、表的数据所在目录等,一般使用MySQL或Derby数据库。
Metastore和Hive Driver驱动的互联有两种方式,一种是集成模式,如图2所示;一种是远程模式,如图3所示。
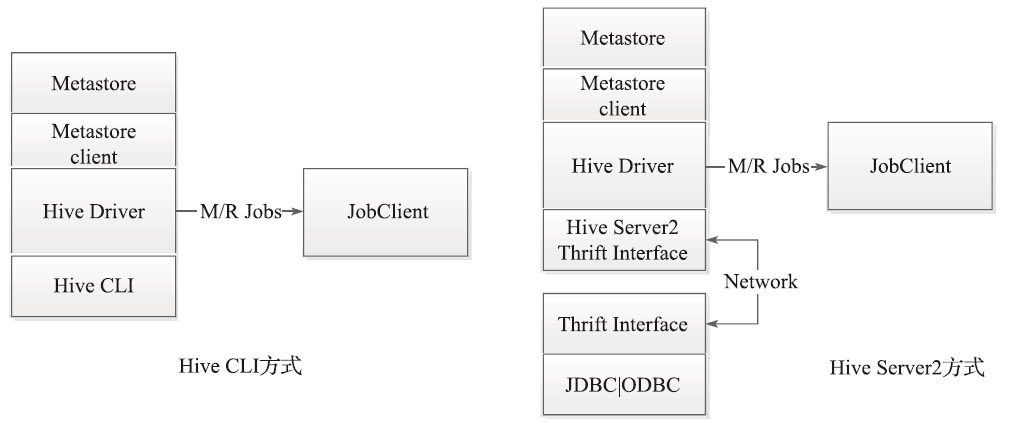
图2 Metastore 和 Driver通信(集成模式)

图3 Metastore 和 Driver通信(远程模式)
继续....
Hadoop Hive概念学习系列之什么是Hive?(一)的更多相关文章
- Hadoop Hive概念学习系列之什么是Hive?
参考 <Hadoop大数据分析与挖掘实战>的在线电子书阅读 http://yuedu.baidu.com/ebook/d128cf8e33687e21 ...
- Hadoop Hive概念学习系列之HDFS、Hive、MySQL、Sqoop之间的数据导入导出(强烈建议去看)
Hive总结(七)Hive四种数据导入方式 (强烈建议去看) Hive几种数据导出方式 https://www.iteblog.com/archives/955 (强烈建议去看) 把MySQL里的数据 ...
- Hadoop Hive概念学习系列之hive里的JDBC编程入门(二十二)
Hive与JDBC示例 在使用 JDBC 开发 Hive 程序时, 必须首先开启 Hive 的远程服务接口.在hive安装目录下的bin,使用下面命令进行开启: hive -service hives ...
- Hadoop Hive概念学习系列之hive三种方式区别和搭建、HiveServer2环境搭建、HWI环境搭建和beeline环境搭建(五)
说在前面的话 以下三种情况,最好是在3台集群里做,比如,master.slave1.slave2的master和slave1都安装了hive,将master作为服务端,将slave1作为服务端. 以 ...
- Hadoop Hive概念学习系列之hive里的索引(十三)
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapReduce任务中需要 ...
- Hadoop Hive概念学习系列之hive的索引及案例(八)
hive里的索引是什么? 索引是标准的数据库技术,hive 0.7版本之后支持索引.Hive提供有限的索引功能,这不像传统的关系型数据库那样有“键(key)”的概念,用户可以在某些列上创建索引来加速某 ...
- Hadoop Hive概念学习系列之hive的数据压缩(七)
Hive文件存储格式包括以下几类: 1.TEXTFILE 2.SEQUENCEFILE 3.RCFILE 4.ORCFILE 其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直 ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hadoop Hive概念学习系列之hive里的优化和高级功能(十四)
在一些特定的业务场景下,使用hive默认的配置对数据进行分析,虽然默认的配置能够实现业务需求,但是分析效率可能会很低. Hive有针对性地对不同的查询进行了优化.在Hive里可以通过修改配置的方式进行 ...
随机推荐
- 初学者自学笔记-this的用法
请注意:这是自学者的笔记,只是个人理解,并非技术分享,如有错误请指正. "this"的意思,简单而言,就是"这个",也就是"当前".谁调用它 ...
- 虚拟机固定IP访问外网配置
大家都知道虚拟机网络连接有三种模式,桥接,host-only,NAT,不再赘述. 这里说一下桥接模式下,实现主机与虚拟机通讯,虚拟机与虚拟机通信,虚拟机访问外网,废话不多说,直接说解决方案: 1.本地 ...
- Java环境变量配置&解决版本不一致问题
之前用Myeclipse编译运行Java没有问题 但是突然想用简单点的NotePad++以及cmd直接编译运行Java 这就让我倒腾了一晚上 先说下问题的解决,再总结下查阅的一些知识. 1.进行win ...
- PHP Ajax简单实例
最近学习Jquery Ajax部分,通过简单例子,比较了下post,get方法的不同 HTML部分 <html> <head> <title>jQuery Ajax ...
- Java学习----接口
1. interface关键字 2. 接口中的方法全部是抽象方法,不能被实例 3. 接口中的成员变量: public static final 4. 当子类实现接口的时候,必须覆盖接口中所有的方法 / ...
- DevExpress GridControl 中下拉框联动效果的实现(及支持文本框录入情况)
先解释一下标题: grid中的某一列默认为文本框,根据需要动态的变更为下拉框,且支持动态变更数据源 需求是这样的: 有一些参数(A),这些参数又分别对应另外的参数(B),所以,先把A作为一列,B根据A ...
- windows下配置wnmp
最近尝试windows下配置nginx+php+mysql,在这里总结一下. 1.下载windows版本的nginx,官网下载地址:http://nginx.org/en/download.htm, ...
- python 小记 整数与小数id
上图,id A =B id 1.0 c != d 以后少用 带小数后位的数字.调用内存地址不一样
- 一个简单的webservice调用
我们先创建一个简单空web应用程序 然后添加新建项目 //我们创建一个peson对象,产生数据标识返回 using System; using System.Collections.Generic; ...
- 一张图看懂DNS域名解析全过程
DNS域名解析是互联网上非常重要的一项服务,上网冲浪(还有人在用这个词吗?)伴随着大量DNS服务来支撑,而对于网站运营来说,DNS域名解析的稳定可靠,意味着更多用户的喜欢,更好的SEO效果和更大的访问 ...