开始使用storm
开始使用storm
本章将讲述如何安装、部署、启动和停止 Storm 集群。 Storm 的安装比较简单,但在安装 Storm 之前需要做好充足的准备,本章将介绍安装的整个流程。在官网上可以下载到Storm 最新的和稳定的几个版本。截至本书截稿之前, Storm 的最新版本是 0.9.3,但是本书主要对 0.8.2 版本进行讲解。
2.1 环境准备
在安装 Storm 的之前要做一些准备工作,这涉及操作系统设置、ZooKeeper 集群的管理以及 Storm 安装之前的一些依赖库。下面将介绍 Storm的系统配置、协调器 ZooKeeper等。
2.1.1 系统配置
在 Linux 上安装 Storm 之前,需要先做如下准备:
安装 JDK 1.6。
安装 SSH 服务。
安装 Python 2.6.6 解释器。
1. 安装 JDK 1.6
与 Hadoop、 HBase 相同, Storm 也需要 JDK 1.6 或者更高的版本。下面介绍安装 JDK 1.6的具体步骤。
(1)下载 JDK 1.6
从 Java 的官网,目前是 Oracle 公司的产品下载 JDK,本书使用 JDK 的 SE 版本,从http://www.oracle.com/technetwork/java/javase/downloads/ 中下载 JDK 1.6 的安装包,注意要下载适应当前系统的 JDK 版本,一般是 64 位版本的 JDK。
注意:JDK 1.6 版本的 u18 以及旧版本,不要下载,这些版本的垃圾回收操作容易遇到 JVM碰撞问题。
(2)手动安装 JDK 1.6
进入 JDK 安装目录(假设安装在 /usr/lib/jvm/jdk)后,开始安装 JDK,具体操作代码如下:
# 修改权限
sudo chmod u+x jdk-***-linux-i586.bin
# 安装
sudo -s ./jdk-***-linux-i586.bin
(3)配置环境变量
安装结束后,开始配置环境变量 JAVA_HOME 和 CLASSPATH,修改指令如下:
vi /etc/prof ile
进入 prof ile 文件后,在文件下面输入如下内容:
#set JAVA Environment
export JAVA_HOME=/usr/lib/jvm/jdk
export ClASSPATH=".:$JAVA_HOME/lib:$CASSPATH"
export PATH="$JAVA_HOME:$PATH"
修改完环境变量后,验证 JDK 是否安装成功,输入如下命令:
java -version
如果出现 Java 版本信息,则说明安装成功。
2. 安装 SSH 服务
Storm 集群模式的启动、关闭以及 ZooKeeper 集群需要 SSH 服务,所以使用的操作系统要安装此服务。
(1)安装 SSH
确认节点可以连接 Internet,执行如下命令检查 SSH 服务。
sudo ps –ef |grep ssh
如果没有 ssh 进程,则执行如下命令安装 SSH 服务。
sudo yum install openssh
(2)查看安装情况
执行下面命令查看 SSH 安装的版本。
ssh -version
执行之后如果出现如下信息,则表明安装已经成功。
OpenSSH_4.3p2, OpenSSL 0.9.8e-f ips-rhel5 01 Jul 2008
Bad escape character 'sion'.
查看服务状态命令如下:
service sshd status
3. 安装 Python 2.6.6
在安装 Python 之前, Linux 系统中其实已经有了 Python 解释器,但如果版本太低,需要重新安装 Python。
Python 是 Storm 最底层的依赖,需要使用下面的命令下载并安装 Python 2.6.6。
wget http:// www.python.org/ftp/python/2.6.6/Python-2.6.6.tar.bz2
tar –jxvf Python-2.6.6.tar.bz2
cd Python-2.6.6
./conf igure
make
make install
安装完成后,需要使用命令测试 Python 2.6.6 是否安装成功。如果安装成功,则命令和
结果如下:
python -V
Python 2.6.6
2.1.2 安装 ZooKeeper 集群
由 于 HBase、 Kafka 和 Storm 都 使 用 ZooKeeper 集 群, 大 多 数 情 况 下, 单 个 节 点 的ZooKeeper 集群可以单独胜任这些应用,但是为了确保故障恢复或者部署大规模集群,可能需要更大规模节点的 ZooKeeper 集群,官方推荐的最小节点数为 3。所以,本案例使用test1、test2 和 test3 三台节点部署 ZooKeeper,每个节点上都需要安装,下面介绍具体的安装部署过程。
1. 下载官方源码
从镜像网站下载 ZooKeeper 包,并将其解压安装,具体操作代码如下:
# 下载、解压
wget http:// mirror.bjtu.edu.cn/apache/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
mkdir -p /opt/modules
mv zookeeper-3.4.6.tar.gz /opt/modules/
tar -zxvf zookeeper-3.4.6.tar.gz
ln -s /opt/modules/zookeeper-3.4.6 /opt/modules/zookeeper
# 日志路径,配置文件用
mkdir -p /var/log/zookeeper
mkdir /tmp/zookeeper
2. 配置 ZooKeeper 属性文件
根据 ZooKeeper 集群节点情况,创建 ZooKeeper 配置文件 conf/zoo.cfg 后,将基本配置添加到配置文件中。
(1)配置服务器核心属性
使用复制命令生成配置文件,代码如下:
cd conf
cp zoo_sample.cfg zoo.cfg
然后将下面的代码追加到配置文件 zoo.cfg 中:
tickTime=2000
clientPort=2181
initLimit=5
syncLimit=2
server.1=test1:2888:3888
server.2=test2:2888:3888
其中,每项参数的含义如下:
tickTime :这个时间是作为 ZooKeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每隔 tickTime 时间发送一个心跳。
clientPort :这个端口就是客户端连接 ZooKeeper 服务器的端口, ZooKeeper 会监听这个端口,接受客户端的访问请求。
initLimit :这个配置项用来配置 ZooKeeper 接受客户端(这里所说的客户端不是用户连接 ZooKeeper 服务器的客户端,而是 ZooKeeper 服务器集群中连接到 Leader 的Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5 个心跳的时间(也就是 tickTime)长度后, ZooKeeper 服务器还没有收到客户端的返回
信息,那么表明这个客户端连接失败。总的时间长度就是 5×2000ms=10s。
syncLimit :这个配置项标识 Leader 与 Follower 之间发送消息、请求和应答时间,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2×2000ms=4s。
server.A=B:C:D :其中 A 是一个数字,表示这个是第几号服务器; B 是这个服务器的IP 地址; C 表示这个服务器与集群中的 Leader 服务器交换信息的端口; D 表示万一集群中的 Leader 服务器挂了,需要一个端口来重新选举出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B
都是相同的,所以不同的 ZooKeeper 实例通信端口号不能相同,要给它们分配不同的端口号。
接下来,添加 myid 文件,在 dataDir 目录(默认是 /tmp/zookeeper)下创建 myid 文件,此文件中只包含一行,且内容为 ZooKeeper 部署节点对应的 server.id 中的 ID 编号。例如, test1、test2 和 test3 分别对应的 myid 文件中的值是 1、2 和 3。节点 test1 的 myid 文件的操作代码如下:
# 创建文件 myid
vi /tmp/zookeeper/myid
# 将下面的数字添加到文件中
1
(2)配置日志打印属性
在默认情况下,日志放到当前目录下的 zookeeper.out 文件中,而在一般情况下需要将日志输出到指定的文件路径下,以便于查看收集和日志。下面的操作都是在 ZooKeeper 的安装主目录下进行。
首先,修改 bin/zkEnv.sh,将下面代码添加到脚本主体的开头部分:
ZOO_LOG_DIR=/var/log/zookeeper
在默认情况下,日志输出到 CONSOLE,关闭 ROLLINGFILE。在生产环境中,需要将日志输出到 ROLLINGFILE,并修改日志级别为 INFO。这些配置项通过修改 conf/log4j.properties 实现,具体代码如下:
.log.dir=.
zookeeper.tracelog.dir=.
将上面对应的代码修改为下面的内容:
zookeeper.log.dir=/var/log/zookeeper
zookeeper.tracelog.dir=/var/log/zookeeper
将下面的代码使用 # 注释掉:
log4j.rootLogger=${zookeeper.root.logger}
将下面代码最前面的 # 去掉:
#log4j.rootLogger=TRACE, CONSOLE, ROLLINGFILE, TRACEFILE
同时修改文件的权限,因为需要用 hadoop 用户启动,将所有 ZooKeeper 相关的文件目录的所有者和组都修改为 hadoop:hadoop,代码如下:
chown -R hadoop:hadoop /opt/modules/zookeeper*
chown -R hadoop:hadoop /var/log/zookeeper
chown -R hadoop:hadoop /tmp/zookeeper
3. 启动 ZooKeeper 集群
登录 test1、 test2 和 test3 三个节点,进入 ZooKeeper 安装主目录,执行下面的命令:
su hadoop
bin/zkServer.sh start
使用下面的 ZooKeeper 客户端命令可以测试服务是否可用。
bin/zkCli.sh -server 127.0.0.1:2181
如果安装并启动成功,则执行上面的命令进入交互终端后,输入 help 命令会得到如下的
打印信息:
[zk: 127.0.0.1:2181(CONNECTED) 1] help
ZooKeeper -server host:port cmd args
connect host:port
get path [watch]
ls path [watch]
set path data [version]
rmr path
delquota [-n|-b] path
quit
printwatches on|off
create [-s] [-e] path data acl
stat path [watch]
close
ls2 path [watch]
history
listquota path
setAcl path acl
getAcl path
sync path
redo cmdno
addauth scheme auth
delete path [version]
setquota -n|-b val path
[zk: 127.0.0.1:2181(CONNECTED) 2] ls /
[kafkastorm, consumers, storm, hbase, brokers, zookeeper]
[zk: 127.0.0.1:2181(CONNECTED) 3]
其中, [zk: 127.0.0.1:2181 (CONNECTED) 2] 前缀表示已经成功连接 ZooKeeper, help 命令表示查看当前交互客户端支持的命令, ls / 命令表示查看当前 ZooKeeper 的根目录结构。
注意:
在 ZooKeeper 运 行 过 程 中, 会 在 dataDir 目 录 下 生 成 很 多 日 志 和 快 照 文 件, 而ZooKeeper 运行进程并不负责定期清理合并这些文件,导致占用大量磁盘空间。因此,需要通过 Cronjob 等方式定期清除过期的日志和快照文件。
2.2 启动模式
Storm 有两种模式可以启动操作:本地模式和分布式模式。
2.2.1 本地模式
本地模式在一个进程中使用线程模拟 Storm 集群的所有功能,这样使用本地模式进行开发和测试将非常方便。本地模式运行 Topology 与在集群上运行 Topology 类似,但是提交拓扑任务是在本地机器上。
简单地使用 LocalCluster 类,就能创建一个进程内( in-process)集群。例如:
import backtype.Storm.LocalCluster;
LocalCluster cluster = new LocalCluster();
本地模式的常规配置需要注意如下几个参数:
1) Conf ig.TOPOLOGY_MAX_TASK_PARALLELISM:单个组件产生的最大线程数。在通常情况下,生产环境的拓扑有大量并行线程(数百个线程),当尝试在本地模式测试拓扑时,它会使本地集群处于不合理负载。这个配置容易控制并行度。
2) Conf ig.TOPOLOGY_DEBUG : 当 设 置 为 true 时, Spout 或 Bolt 每 发 射 一 个 消 息,Storm 就记录一个消息。这对程序调试非常有用。在启动 Storm 后台进程时,需要对 conf/storm.yaml 配置文件中设置的 storm.local.dir 目录具有写权限。 Storm 后台进程启动后,将在 Storm 安装部署目录下的 logs/ 子目录下生成各个进程的日志文件。
2.2.2 分布式模式
分布式模式提交的拓扑任务可以放在 Storm 集群的任意一个节点执行,下面讲解的安装及部署均使用了此模式。
2.3 安装部署 Storm 集群
Storm 的安装、部署过程分为安装依赖、安装 Storm、启动和查看安装等几个部分。其中,前两部分内容在三个节点上都是一样的,只要在启动时区分开角色即可。接下来将讲解Storm 集群的安装过程。
2.3.1 安装 Storm 依赖库
在 Nimbus 和 Supervisor 的节点上安装 Storm 时,都需要安装相关的依赖库,具体如下:
ZeroMQ 2.1.7。
JZMQ。
其中, ZeroMQ 推荐使用 2.1.7 版本,请勿使用 2.1.10 版本。官方解释是因为该版本的一些严重 Bug 会导致 Storm 集群运行时出现奇怪的问题。另外,以上依赖库的版本经过 Storm官方测试,但不能保证在其他版本的 Java 或 Python 库下可运行。
1. 安装 ZeroMQ
Storm 底层队列的实现使用 ZeroMQ,为了实现低耦合, Storm 并没有将 ZeroMQ 放置到其工程中,所以需要预先安装。先下载源码,然后编译安装 ZeroMQ,命令如下:
wget http:// download.zeromq.org/zeromq-2.1.7.tar.gz
tar -vxzf zeromq-2.1.7.tar.gz
cd zeromq-2.1.7
./conf igure
make
make install
1)其中 ./conf igure 时会检查 JAVA_HOME 是否正确,不正确会报错,并提示。
2)如果安装过程报错 uuid 找不到,则通过如下的命令安装 uuid 库:
yum install gcc gcc-c++
yum install uuidd
如遇到报错“ Error:cannot link with -luuid, install uuid-dev”,则安装部分依赖包:
yum install e2fsprogs e2fsprogs-devel
当然,以上的依赖工具安装命令使用的是 yum,不同的 Linux 分支使用不同的安装命令,例如 Ubuntu 使用 apt-get。用户根据自己选用的操作系统来选用不用的命令,可能 有 些 依 赖 工 具 在 不 同 的 Linux 系 统 上 对 应 的 名 称 不 太 一 致, 但 是 总 能 找 到 对 应 的 依赖包。
2. 安装 JZMQ
JZMQ 是 ZeroMQ 的 Java 语言的绑定实现,因为安装过程中使用 unzip 命令,首先要使用 yum 等的安装工具安装 unzip 工具。然后根据下面的代码一步一步下载、配置、编译和安装 JZMQ。
# 安装依赖工具包
yum install pkgconf ig libtool
# 下载、配置、编译和安装
wget https:// github.com/nathanmarz/jzmq/archive/master.zip -O jzmq.zip
unzip jzmq.zip
cd jzmq-master
./autogen.sh
./conf igure
make
2.3.2 安装 Storm 集群
下面介绍 Storm 0.8.2 的详细安装过程。
1. 下载并解压 Storm 0.8.2
在 Nimbus 和 Supervisor 节 点 上 安 装 Storm 发 行 版 本。 Nimbus 安 装 在 test1 节 点 上,Supervisor 安装在 test2 和 test3 节点上。这些节点的配置文件完全相同。直接在 http://stormproject.net/downloads.html 页面下载 0.8.2 版本,如图 2-1 所示。
图 2-1 Storm 下载页面
也可以在客户端节点下载后复制到集群节点,或在客户端复制链接地址后在集群节点使用 wget 命令下载。在完成下载或复制后,将压缩包解压,命令如下:
mv storm-0.8.2.zip /opt/modules/
unzip storm-0.8.2.zip
2. 修改 storm.yaml 配置文件
Storm 发行版本解压目录下有一个 conf/storm.yaml 文件,用于配置 Storm。可以在这里查看默认配置。 conf/storm.yaml 中的配置选项将覆盖 defaults.yaml 中的默认配置。以下最基本的配置选项必须在 conf/storm.yaml 中配置。
1) storm.zookeeper.servers: Storm 集群使用的 ZooKeeper 集群地址,格式如下:
storm.zookeeper.servers:
- "test1"
- "test2"
- "test3"
如果 ZooKeeper 集群使用的不是默认端口,那么还需要 storm.zookeeper.port 选项。
2) storm.local.dir: Nimbus 和 Supervisor 进程用于存储少量状态,如 JAR、配置文件等的本地磁盘目录,需要提前创建该目录并给以足够的访问权限,然后在 storm.yaml 中配置该目录,代码如下:
storm.local.dir: "/var/storm"
3) nimbus.host: Storm 集群 Nimbus 机器地址,各个 Supervisor 工作节点需要知道哪个节点是 Nimbus,以便下载 Topology 的 JAR、配置等文件,代码如下:
nimbus.host: "test1"
当然这几项配置都是最基本的配置选项,其他的配置选项都在 defaults.yaml 文件中,该文件的详细内容如下,供读者参考使用。
########### These all have default values as shown
########### Additional conf iguration goes into Storm.yaml
java.library.path: "/usr/local/lib:/opt/local/lib:/usr/lib"
### storm.* conf igs are general conf igurations
# the local dir is where jars are kept
storm.local.dir: "storm-local"
storm.zookeeper.servers:
- "localhost"
storm.zookeeper.port: 2181
storm.zookeeper.root: "/storm"
storm.zookeeper.session.timeout: 20000
storm.zookeeper.connection.timeout: 15000
storm.zookeeper.retry.times: 5
storm.zookeeper.retry.interval: 1000
storm.cluster.mode: "distributed" # can be distributed or local
storm.local.mode.zmq: false
### nimbus.* conf igs are for the master
nimbus.host: "localhost"
nimbus.thrift.port: 6627
nimbus.childopts: "-Xmx1024m"
nimbus.task.timeout.secs: 30
nimbus.supervisor.timeout.secs: 60
nimbus.monitor.freq.secs: 10
nimbus.cleanup.inbox.freq.secs: 600
nimbus.inbox.jar.expiration.secs: 3600
nimbus.task.launch.secs: 120
nimbus.reassign: true
nimbus.f ile.copy.expiration.secs: 600
### ui.* conf igs are for the master
ui.port: 8080
ui.childopts: "-Xmx768m"
drpc.port: 3772
drpc.invocations.port: 3773
drpc.request.timeout.secs: 600
transactional.zookeeper.root: "/transactional"
transactional.zookeeper.servers: null
transactional.zookeeper.port: null
### supervisor.* conf igs are for node supervisors
# Def ine the amount of workers that can be run on this machine. Each worker is assigned
a port to use for communication
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
supervisor.childopts: "-Xmx1024m"
#how long supervisor will wait to ensure that a worker process is started
supervisor.worker.start.timeout.secs: 120
#how long between heartbeats until supervisor considers that worker dead and tries
to restart it
supervisor.worker.timeout.secs: 30
#how frequently the supervisor checks on the status of the processes it's monitoring
and restarts if necessary
supervisor.monitor.frequency.secs: 3
#how frequently the supervisor heartbeats to the cluster state (for nimbus)
supervisor.heartbeat.frequency.secs: 5
supervisor.enable: true
### worker.* conf igs are for task workers
worker.childopts: "-Xmx768m"
worker.heartbeat.frequency.secs: 1
task.heartbeat.frequency.secs: 3
task.refresh.poll.secs: 10
zmq.threads: 1
zmq.linger.millis: 5000
### topology.* conf igs are for specif ic executing storms
topology.enable.message.timeouts: true
topology.debug: false
topology.optimize: true
topology.workers: 1
topology.acker.executors: 1
topology.acker.tasks: null
topology.tasks: null
# maximum amount of time a message has to complete before it's considered failed
topology.message.timeout.secs: 30
topology.skip.missing.kryo.registrations: false
topology.max.task.parallelism: null
topology.max.spout.pending: null
topology.state.synchronization.timeout.secs: 60
topology.stats.sample.rate: 0.05
topology.fall.back.on.java.serialization: true
topology.worker.childopts: null
topology.executor.receive.buffer.size: 1024 #batched
topology.executor.send.buffer.size: 1024 #individual messages
topology.receiver.buffer.size: 8 # setting it too high causes a lot of problems
(heartbeat thread gets starved, throughput plummets)
topology.transfer.buffer.size: 1024 # batched
topology.tick.tuple.freq.secs: null
topology.worker.shared.thread.pool.size: 4
topology.disruptor.wait.strategy: "com.lmax.disruptor.BlockingWaitStrategy"
topology.spout.wait.strategy: "backtype.storm.spout.SleepSpoutWaitStrategy"
topology.sleep.spout.wait.strategy.time.ms: 1
dev.zookeeper.path: "/tmp/dev-storm-zookeeper"
2.3.3 启动 Storm 集群
最后一步,启动 Storm 的所有后台进程。和 ZooKeeper 一样, Storm 也是快速失败( fail-fast)的系统,能在任意时刻被停止,并且当进程重启后能够正确恢复执行。这也是为什么Storm 不在进程内保存状态的原因,即使重启 Nimbus 或 Supervisor 进程,运行中的 Topology不会受到影响。
首先,还是因为需要使用 hadoop 用户启动进程,需要更改文件权限,命令如下:
mkdir /var/storm
chown -R hadoop:hadoop /var/storm
chown -R hadoop:hadoop /opt/modules/*storm*
下面介绍启动 Storm 各个后台进程的方式。
Nimbus :在 Storm 主控节点上运行(即 test1 节点),启动 Nimbus 后台程序,并放到后台执行。
su hadoop
bin/storm nimbus </dev/null 2<&1 &
Supervisor :在 Storm 各个工作节点上运行(即 test2、 test3 节点),启动 Supervisor 后台程序,并放到后台执行。
su hadoop
bin/storm supervisor </dev/null 2<&1 &
UI :在 Storm 主控节点上运行,启动 UI 后台程序,并放到后台执行,启动后可以通过 http://{nimbus host}:8080 观察集群的 Worker 资源使用情况、 Topology 的运行状态等信息,启动命令如下。启动后通过浏览器可以查看当前 Storm 集群的当前状态,成功启动后的 Storm UI 界面如图 2-2 所示。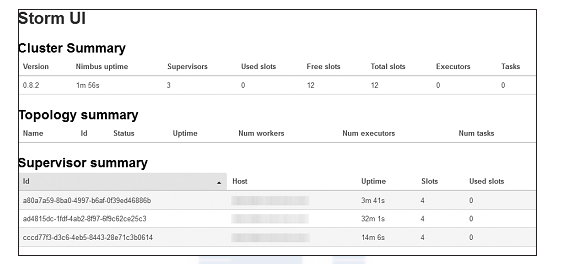
图 2-2 成功启动后的 Storm UI 首页
su hadoop
bin/storm ui </dev/null 2<&1 &
经测试, Storm UI 必须和 Storm Nimbus 部署在同一台机器上,否则 UI 无法正常工作,因为 UI 进程会检查本机是否存在 Nimus 连接。下面简单介绍 Storm UI 页面上的各项属性。
1. Cluster Summary 集群统计信息
Version: Storm 集群的版本。
Nimbus uptime: Nimbus 的启动时间。
Supervisors: Storm 集群中 Supervisor 的数量。
Used slots:使用的 Slot 数。
Free slots:剩余的 Slot 数。
Total slots:总的 Slot 数。
Executors:执行者数量。
Tasks: 运行的任务数。
2. Topology summary 拓扑统计信息
Name:拓扑的名称。
Id:由 Storm 生成的拓扑 ID。
Status:拓扑的状态,包括 ACTIVE、 INACTIVE、 KILLED、 REBALANCING 等。
Uptime:拓扑运行的时间。
Num workers:运行的 Worker 数。
Num executors:运行的执行者数。
3. Supervisor summary 工作节点统计信息
Host: Supervisor 主机名。
Id:由 Storm 生成的工作节点 ID。
Uptime: Supervisor 启动的时间。
Slots: Supervisor 的 Slot 数。
Used slots:使用的 Slot 数。
经测试, Storm UI 必须和 Nimbus 服务部署在同一节点上,否则 UI 无法正常工作,因为UI 进程会检查本机是否存在 Nimbus 连接。至此, Storm 集群部署、配置完成,可以向集群提交拓扑。
2.3.4 停止 Storm 集群
在本地模式下停止集群的方式比较简单,就是调用 shutdown 方法,代码如下:
import backtype.storm.LocalCluster;
LocalCluster cluster = new LocalCluster();
cluster.shutdown();
分布式模式停止集群的方式比较麻烦,因为角色进程分布在不同的节点上。停止的方法是,直接杀掉每个节点运行的 Nimbus 或者 Supervisor 进程。目前 Storm 官网上提供了一个项目可以快速关闭 Storm 集群 。
2.4 创建 Topology 并向集群提交任务
Topology 是 Storm 的核心概念之一,是将 Spout 与 Bolt 融合在一起的纽带,在 Storm 集群中运行,完成实时计算的任务。在 Storm 集群中, Topology 的定义是一个 Thrift 结构,并且 Nimbus 就是一个 Thrift 服务,可以提交由任何语言创建的 Topology。下面使用 Java 语言讲解 Topology 的使用。首先了解如何创建 Topology。
2.4.1 创建 Topology
在创建一个 Topology 之前,设计一个 Topology 来统计词频。在创建 Topology 之前,要准备 Spout(数据源)和 Bolt 来组成 Topology。这里简单介绍创建的 Spout 和 Bolt,第 3 章会详细介绍这两个概念。
下面梳理 Topology 的大致结构。
1. Spout
创建一个 WordSpout 数据源,负责发送语句。 WordSpout 的代码如下:
public class WordSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private static f inal String[] msgs = new String[] {
"I have a dream",
"my dream is to be a data analyst",
"you kan do what you are dreaming",
"don't give up your dreams",
"it's just so so ",
"We need change the traditional ideas and practice boldly"
"Storm enterprise real time calculation of actual combat",
"you kan be what you want be",
};
private static f inal Random random = new Random();
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
this.collector = collector;
}
public void nextTuple() {
String sentence= msgs[random.nextInt(8)];
collector.emit(new Values(sentence));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
2. Bolt
两个 Bolt,一个负责将语句切分,即 SplitSentenceBolt,另一个是对切分的单词进行词频累加的 Bolt,即 WordCountBolt。下面是这两个 Bolt 的具体代码。
public class SplitSentenceBolt implements IBasicBolt{
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
collector.emit(new Values(word));
}
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
public class WordCountBolt implements IBasicBolt {
private Map<String, Integer> _counts = new HashMap<String, Integer>();
public void prepare(Map conf, TopologyContext context) {
}
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
int count;
if(_counts.containsKey(word)) {
count = _counts.get(word);
} else {
count = 0;
}
count++;
_counts.put(word, count);
collector.emit(new Values(word, count));
}
public void cleanup() {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
}
}
3. Topology
要创建的 Topology 的 Spout 从句子队列中随机生成一个句子, Spout 用 setSpout 方法插入一个独特的 ID 到 Topology。必须给予 Topology 中的每个节点一个 ID, ID 是由其他 Bolt用于订阅该节点的输出流,其中 WordSpout 在 Topology 中的 ID 为 1。setBolt 用于在 Topology 中插入 Bolt,在 Topology 中定义的第一个 Bolt 是切分句子的SplitSentenceBolt,该 Bolt 将句子流转成单词流,第二个 Bolt 统计单词。 Topology 的代码如下:
TopologyBuilder builder = new TopologyBuilder();
bulider.setSpout(1,new WordSpout(),2);
builder.setBolt(2, new SplitSentenceBolt(), 10).shuffleGrouping(1);
builder.setBolt(3, new WordCountBolt(), 20).f ieldsGrouping(2, new Fields("word"));
这样就创建了简单的 Topology 结构,下面介绍如何使用 Topology。
2.4.2 向集群提交任务
向 Storm 集群提交 Topology 任务,类似提交 MapReduce 作业到 Hadoop 集群中,只需要运行 JAR 包中的 Topology 即可。而使用 kill 命令可以杀掉任务,类似杀掉 MapReduce 作业。下面详细介绍这两部分内容。
1. 启动 Topology
在 Storm 的安装主目录下,执行下面的命令提交任务:
bin/storm jar testTopolgoy.jar org.me.MyTopology arg1 arg2 arg3
其中, jar 命令专门负责提交任务, testTopolgoy.jar 是包含 Topology 实现代码的 JAR 包,org.me.MyTopology 的 main 方法是 Topology 的入口, arg1、 arg2 和 arg3 为 org.me.MyTopology执行时需要传入的参数。
2. 停止 Topology
在 Storm 主目录下,执行 kill 命令停止之前已经提交的 Topology:bin/Storm kill {toponame}其中, {toponame} 为 Topology 提交到 Storm 集群时指定的 Topology 任务名称,该名称可以在代码中指定,也可以作为参数传入 Topology 中。
本章小结
在 Storm 中 使 用 ZooKeeper 主 要 用 于 完 成 Storm 集 群 各 节 点 的 分 布 式 协 调 工 作, 一是存储客户端提供的 Topology 任务信息, Nimbus 负责将任务分配信息写入 ZooKeeper,Supervisor 从 ZooKeeper 上读取任务分配信息;二是存储 Supervisor 和 Worker 的心跳(包括它们的状态),使得 Nimbus 可以监控整个集群的状态,从而重启一些挂掉的 Worker ;三是存储整个集群的所有状态信息和配置信息。由于 ZooKeeper 在 Storm 集群中的重要性,本章详细介绍了 ZooKeeper 的安装。
Storm 使用 ZeroMQ 传送消息,这就消除了中间的排队过程,使得消息能够直接在任务自身之间流动。在消息的背后,是一种用于序列化和反序列化 Storm 的原语类型的自动化且高效的机制。 Storm 使用 ZooKeeper 协调集群时,由于 ZooKeeper 并不用于传递消息,所以 Storm 给 ZooKeeper 带来的压力相当低。大多数情况下,单个节点的 ZooKeeper 集群足够胜任,不过为了确保故障恢复或者部署大规模 Storm 集群,可能需要更大规模节点的ZooKeeper 集群。
开始使用storm的更多相关文章
- Storm如何保证可靠的消息处理
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文主要翻译自Storm官方文档Guaranteeing messag ...
- Storm
2016-11-14 22:05:29 有哪些典型的Storm应用案例? 数据处理流:Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去.不像其它的流处理系统,Storm不 ...
- Storm介绍(一)
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 内容简介 本文是Storm系列之一,介绍了Storm的起源,Storm ...
- 理解Storm并发
作者:Jack47 PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 注:本文主要内容翻译自understanding-the-parall ...
- Storm构建分布式实时处理应用初探
最近利用闲暇时间,又重新研读了一下Storm.认真对比了一下Hadoop,前者更擅长的是,实时流式数据处理,后者更擅长的是基于HDFS,通过MapReduce方式的离线数据分析计算.对于Hadoop, ...
- Storm内部的消息传递机制
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 一个Storm拓扑,就是一个复杂的多阶段的流式计算.Storm中的组件 ...
- Storm介绍(二)
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 本文是Storm系列之一,主要介绍Storm的架构设计,推荐读者在阅读 ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- 交易系统使用storm,在消息高可靠情况下,如何避免消息重复
概要:在使用storm分布式计算框架进行数据处理时,如何保证进入storm的消息的一定会被处理,且不会被重复处理.这个时候仅仅开启storm的ack机制并不能解决上述问题.那么该如何设计出一个好的方案 ...
- 由提交storm项目jar包引发对jar的原理的探索
序:在开发storm项目时,提交项目jar包当把依赖的第三方jar包都打进去提交storm集群启动时报了发现多个同名的文件错误由此开始了一段对jar包的深刻理解之路. java.lang.Runtim ...
随机推荐
- 当页面编辑或运行提交时,出现“从客户端中检测到有潜在危险的request.form值”问题,该怎么办呢?
最近在学习highcharts时,关于其中的导出功能,本来是想把导出的图片存放在本地,发现只有在电脑联网的情况下才可以一下导出图片,后来查阅了一番资料,才发现highcharts中的导出默认的官网服务 ...
- firefox浏览器删除插件
打开注册表编辑器([开始菜单]→[运行]或 Win+R快捷键打开运行,输入regedit). 2 点击菜单栏[编辑]→[搜索],或者按 Ctrl + F 快捷键,搜索 MozillaPlugins . ...
- 使用ssh公钥实现免密码登录
使用ssh公钥实现免密码登录 ssh 无密码登录要使用公钥与私钥.linux下可以用用ssh-keygen生成公钥/私钥对,下面我以CentOS为例. 有机器A(10.207.160.34),B(10 ...
- ExtJS4.2学习(15)树形表格(转)
鸣谢:http://www.shuyangyang.com.cn/jishuliangongfang/qianduanjishu/2013-11-27/185.html --------------- ...
- Matlab心得及学习方法(不断更新)
Matlab心得及学习方法(不断更新) Matlab心得及学习方法(不断更新)P.S. 那些网上转载我的文章不写明出处的傻眼了吧?!老子更新了! 发现现在很多人(找工作的或者读博的)都想要学习或者正在 ...
- Handlebars 介绍
最新项目用到了Ember.js前端框架,第一次使用这样的框架,准备国庆节花2天时间,研究一下它的用法. Ember框架的模板引擎用到了handlebars, 先看国外的一篇介绍文章:An Introd ...
- Java 开发者不容错过的 12 种高效工具
Java 开发者常常都会想办法如何更快地编写 Java 代码,让编程变得更加轻松.目前,市面上涌现出越来越多的高效编程工具.所以,以下总结了一系列工具列表,其中包含了大多数开发人员已经使用.正在使用或 ...
- SPRING IN ACTION 第4版笔记-第五章BUILDING SPRING WEB APPLICATIONS-005-以path parameters的形式给action传参数(value=“{}”、@PathVariable)
一 1.以path parameters的形式给action传参数 @Test public void testSpittle() throws Exception { Spittle expecte ...
- Qt刷新机制的一些总结(Qt内部画的时候是相当于画在后台一个对象里,然后在刷新的时候调用bitblt统一画,调用window的api并不会影响到后面的那个对象)
前段时间做过一个界面刷新的优化,遇到的坑比较多,在这里做一点点总结吧. 优化的方案是滚动滚动条的时候用截屏的方式代替界面全部刷新,优化完成后,界面在滚动时效率能提升大概一倍,背景介绍完毕. ...
- 驱动开发 - WDK 调试及 SVN 环境搭建
由于从公司辞职了,所以以前在公司里搭建的驱动开发环境也就 Game Over 了, 同样由于那环境是很久以前搭建的,自己也有很多记不清楚的地方了, 而且其中还是有很多需要注意的地方的,所以在这里顺便做 ...