本文共分为三个部分:
- Kafka Topic创建方式
- Kafka Topic Partitions Assignment实现原理
- Kafka资源隔离方案
1. Kafka Topic创建方式
Kafka Topic创建方式有以下两种表现形式:
(1)创建Topic时直接指定Topic Partition Replica与Kafka Broker之间的存储映射关系
/usr/lib/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --zookeeper ZooKeeperHost:ZooKeeperPort --create --topic TopicName --replica-assignment id0:id1:id2,id3:id4:id5,id6:id7:id8
其中,“id0:id1:id2,id3:id4:id5,id6:id7:id8”表示Topic TopicName一共有3个Partition(以“,”分隔),每个Partition均有3个Replica(以“:”分隔),Topic Partition Replica与Kafka Broker之间的对应关系如下:
Partition0 Replica:Broker id0、Broker id1、Broker id2;
Partition1 Replica:Broker id3、Broker id4、Broker id5;
Partition2 Replica:Broker id6、Broker id7、Broker id8;
(2)创建Topic时由Kafka自动分配Topic Partition Replica与Kafka Broker之间的存储映射关系
/usr/lib/kafka_2.10-0.8.2.1/bin/kafka-topics.sh --zookeeper ZooKeeperHost:ZooKeeperPort --create --topic TopicName
第(1)种方式完全依靠人为手工指定,这里仅仅探讨使用第(2)种方式创建Topic时,“自动分配”是如何实现的。
2. Kafka Topic Partition Replica Assignment实现原理
Replica Assignment的目标有两个:
(1)使Partition Replica能够均匀地分配至各个Kafka Broker(负载均衡);
(2)如果Partition的第一个Replica分配至某一个Kafka Broker,那么这个Partition的其它Replica则需要分配至其它的Kafka Brokers,即Partition Replica分配至不同的Broker;
注意,这里有一个约束条件:Topic Partition Replicas Size <= Kafka Brokers Size。
“自动分配”的核心工作过程如下:
随机选取一个StartingBroker(Broker id0、Broker id1、Broker id2、...),随机选取IncreasingShift初始值([0,nBrokers - 1])
(1)从StartingBroker开始,使用轮询的方式依次将各个Partition的Replicas分配至各个Broker;
对于每一个Partition,Replicas的分配过程如下:
(2)Partition的第一个Replica分配至StartingBroker;
(3)根据IncreasingShift计算第n(n>=2)个Replica的Shift(即与第1个Replica的间隔量),依据Shift将其分配至相应的Broker;
(4)StartingBroker移至下一个Broker;
(5)如果Brokers已经被轮询完一次,则IncreasingShift递增一;否则,继续(2)。
假设有5个Brokers(broker-0、broker-1、broker-2、broker-3、broker-4),Topic有10个Partition(p0、p1、p2、p3、p4、p5、p6、p7、p8、p9),每一个Partition有3个Replica,依据上述工作过程,分配结果如下:
broker-0 broker-1 broker-2 broker-3 broker-4
p0 p1 p2 p3 p4 (1st replica)
p5 p6 p7 p8 p9 (1st replica)
p4 p0 p1 p2 p3 (2nd replica)
p8 p9 p5 p6 p7 (2nd replica)
p3 p4 p0 p1 p2 (3nd replica)
p7 p8 p9 p5 p6 (3nd replica)
详细步骤如下:
选取broker-0作为StartingBroker,IncreasingShift初始值为1,
对于p0,replica1分配至broker-0,IncreasingShift为1,所以replica2分配至broker-1,replica3分配至broker-2;
对于p1,replica1分配至broker-1,IncreasingShift为1,所以replica2分配至broker-2,replica3分配至broker-3;
对于p2,replica1分配至broker-2,IncreasingShift为1,所以replica2分配至broker-3,replica3分配至broker-4;
对于p3,replica1分配至broker-3,IncreasingShift为1,所以replica2分配至broker-4,replica3分配至broker-1;
对于p4,replica1分配至broker-4,IncreasingShift为1,所以replica2分配至broker-0,replica3分配至broker-1;
注:IncreasingShift用于计算Shift,Shift表示Partition的第n(n>=2)个Replica与第1个Replica之间的间隔量。如果IncreasingShift值为m,那么Partition的第2个Replica与第1个Replica的间隔量为m + 1,第3个Replica与第1个Replica的间隔量为m + 2,...,依次类推。Shift的取值范围:[1,brokerSize - 1]。
此时,broker-0、broker-1、broker-2、broker-3、broker-4分别作为StartingBroker被轮询分配一次,继续轮询;但IncreasingShift递增为2。
对于p5,replica1分配至broker-0,IncreasingShift为2,所以replica2分配至broker-2,replica3分配至broker-3;
对于p6,replica1分配至broker-1,IncreasingShift为2,所以replica2分配至broker-3,replica3分配至broker-4;
对于p7,replica1分配至broker-2,IncreasingShift为2,所以replica2分配至broker-4,replica3分配至broker-0;
对于p8,replica1分配至broker-3,IncreasingShift为2,所以replica2分配至broker-0,replica3分配至broker-1;
对于p9,replica1分配至broker-4,IncreasingShift为2,所以replica2分配至broker-1,replica3分配至broker-2;
此时,broker-0、broker-1、broker-2、broker-3、broker-4分别作为StartingBroker再次被轮询一次,如果还有其它Partition,则继续轮询,IncreasingShift递增为3,依次类推。
这里有几点需要注意:
(1)为什么要随机选取StartingBroker,而不是每次都选取broker-0作为StartingBroker?
以broker-0、broker-1、broker-2、broker-3、broker-4为例,因为分配过程是以轮询方式进行的,如果每次都选取broker-0作为StartingBroker,那么Brokers列表中的前面部分将有可能被分配相对比较多的Partition Replicas,从而导致这部分Brokers负载较高,随机选取可以保证相对比较好的均匀效果。
(2)为什么Brokers列表每次轮询一次,IncreasingShift值都需要递增1?
Kafka Topic Partition数目较多的情况下,Partition的第1个Replica与第n(n>=2)个Replica之间的间隔量随着IncreasingShift的变化面变化,能够更好的均匀分配Replica。
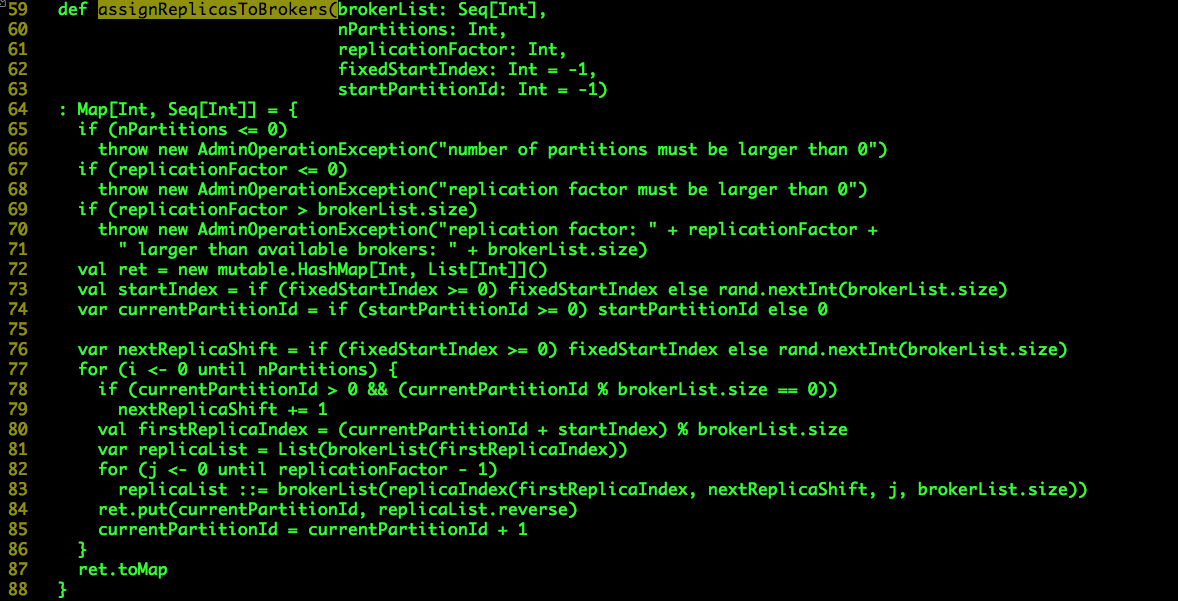
scala.kafka.admin.AdminUtils.assignReplicasToBrokers()实现上述Topic Partition Replica与Broker之间的分配过程,源码如下:
brokerList:Kafka Brokers列表;
nPartitions:Topic待分配的Partition数目;
replicationFactor:Topic Partition Replica数目;
fixedStartIndex:如果显示指定,默认值为0;它的值与两个变量值相关:startIndex和nextReplicaShift,详情见后;
startPartitionId:从Topic的哪一个Partition开始分配,通常情况下是0,Topic增加Partition时该值不为0。
val ret = new mutable.HashMap[Int, List[Int]]()
分配结果保存至一个Map变量ret,key为Partition Id,value为分配的Brokers列表。
val startIndex = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerList.size)
var currentPartitionId = if (startPartitionId >= 0) startPartitionId else 0
var nextReplicaShift = if (fixedStartIndex >= 0) fixedStartIndex else rand.nextInt(brokerList.size)
startIndex表示StartingBroker,currentPartitionId表示当前为哪个Partition分配Brokers,nextReplicaShift表示当前的IncreasingShit值。
接下来就是一个循环,用于为每一个Partition的Replicas分配Brokers,其中Partition的第1个Replica由“(currentPartitionId + startIndex) % brokerList.size”决定,其余的Replica由“replicaIndex()”决定。
shift表示着第n(n >= 2)个Replica与第一个Replica之间的间隔量,“1 + (secondReplicaShift + replicaIndex) % (nBrokers - 1)”的计算方式非常巧妙,它保证了shift的取值范围:[1,nBrokers](大家可以自己体会一下)。
3. Kafka资源隔离方案
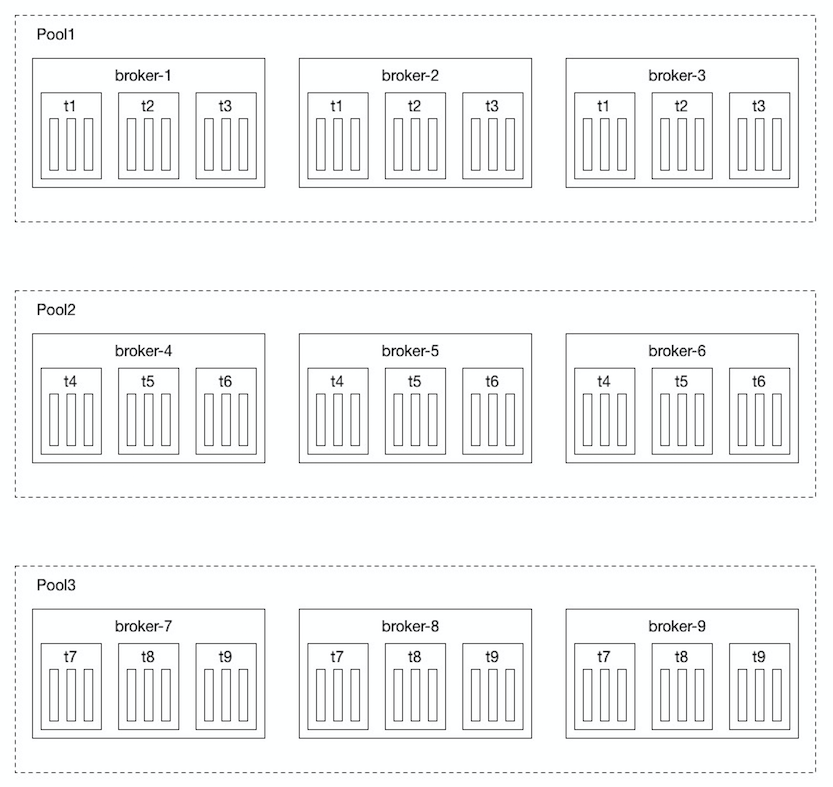
实时数据处理场景中,如果数据量比较大,为了保证写入/消费的吞吐量,我们创建Topic时通常会指定比较大的Partition数目,从而使得数据尽可能地被分散至更多的Partition,Partition被尽可能均匀的分配至Kafka集群中的各个Broker,从负载均衡的角度看,一切都很美好。从业务的角度看,会有资源竞争的问题,毕竟Kafka Broker机器的带宽资源是有限的,在带宽比较紧张的情形下,任何一个业务方的数据量波动(这里仅指数据量增加),所有的业务方都会受到影响;从运维的角度看,会有可用性的问题,任何一台Kafka Broker机器都负载着所有Topic的数据传输、存储,如果出现宕机的情况,将会波及到所有的Topic。针对这种情况,我们提出了划分资源池的资源隔离方案:
Kafka集群有9台Brokers组成:broker-1、broker-2、...、broker-9,创建9个Topic:t1、t2、...、t9,每个Topic有9个Partition(假设Replica为1),如上图所示,我们将9台Brokers切分成3个资源池:Pool1(broker-1、broker-2、broker-3)、Pool2(broker-4、broker-5、broker-6)、Pool3(broker-7、broker-8、broker-9),Topic的分配情况如下:
Pool1:t1、t2、t3
Pool2:t4、t5、t6
Pool3:t7、t8、t9
可以看出,这三个资源池的物理资源是完全独立的,三个资源池实际上相当于三个小集群。
这种资源池的划分方式不但可以做到物理资源的隔离,还可以一定程度上解决异构机型(MEM、DISK)带来的问题,可以把机型相似的机器组成一个资源池。实际实施时需要综合考虑业务情况、机器情况,合理划分资源池,并根据具体的Topic情况将其分配至合适的资源池内。
Kafka Topic的创建也变为两步:
(1)使用kafka-topics.sh创建Topic;
(2)使用kafka-reassign-partitions.sh移动Topic Partition Replicas至指定的资源池(具体的Brokers列表)。
- Kafka Topic Partition Offset 这一长串都是啥?
摘要:Offset 偏移量,是针对于单个partition存在的概念. 本文分享自华为云社区<Kafka Topic Partition Offset 这一长串都是啥?>,作者: gent ...
- [bigdata] kafka基本命令 -- 迁移topic partition到指定的broker
版本 0.9.2 创建topic bin/kafka-topics.sh --create --topic topic_name --partition 6 --replication-factor ...
- Hadoop Yarn内存资源隔离实现原理——基于线程监控的内存隔离方案
注:本文以hadoop-2.5.0-cdh5.3.2为例进行说明. Hadoop Yarn的资源隔离是指为运行着不同任务的“Container”提供可独立使用的计算资源,以避免它们之间相互干扰.目 ...
- kafka之partition分区及副本replica升级
修改kafka的partition分区 bin/kafka-topics.sh --zookeeper datacollect-2:2181 --alter --partitions 3 --topi ...
- kafka学习(四)-Topic & Partition
topic中partition存储分布 Topic在逻辑上可以被认为是一个queue.每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里.为了使得 Kafka的吞吐 ...
- kafka Topic 与 Partition
Topic在逻辑上可以被认为是一个queue队列,每条消息都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里.为 了使得Kafka的吞吐率可以水平扩展,物理上把topic分 ...
- RabbitMQ和Kafka的高可用集群原理
前言 小伙伴们,通过前边文章的阅读,相信大家已经对RocketMQ的基本原理有了一个比较深入的了解,那么大家对当前比较常用的RabbitMQ和Kafka是不是也有兴趣了解一些呢,了解的多一些也不是坏事 ...
- jmeter中执行kafka topic指令
前置条件 kafka版本:2.2.1 jmeter版本:5.3 插件:ApacheJMeter_ssh-1.2.0.jar 1.拷贝 ApacheJMeter_ssh-1.2.0.jar 到/lib/ ...
- Kafka Topic动态迁移 (源代码解析)
总结下自己在尝试Kafka分区迁移过程中对这部分知识的理解,请路过高手指正. 关于Kafka数据迁移的具体步骤指导,请参考如下链接:http://www.cnblogs.com/dycg/p/3922 ...
随机推荐
- 转--DataTable 修改列名 删除列 调整列顺序
DataTable myDt =dt; //删除列 myDt.Columns.Remove("minArea"); myDt.Columns.Remove("maxAre ...
- mysql免安装版使用
打开命令行,到bin目录下,输入net start mysql 启动服务,输入mysql -u root -p回车后输入密码,进入mysql.
- List和ArrayList,LinkList的区别
接口 List<E> 是一个接口: ArrayList<E> 是一个类:是一个实现了List接口的类,因此可以List里面定义的所有的方法都实现了. 1.ArrayList是实 ...
- C# 重写思想
问题一:什么是重写? “重写”父类方法就是修改它的实现方式或者说在子类中对它进行重新编写. 问题二:为什么要重写父类的方法 通常,子类继承父类的方法,在调用对象继承方法的时候,调用和 ...
- ASP.NET MVC 自我总结的便捷开发实例
前言 工作了这么久了,接触ASP.NET MVC已经很久了,一直都想总结一下它的一些实用的,经常使用的一些技巧,但是因为一直都很懒,也不想总结,所以一直都没有好好写出来,趁着现在有这种冲劲,那么就先把 ...
- XhProf安装教程–详细教程
wget去这里找最新的包下载,我现在最新的是xhprof-0.9.4.tgz cd /tmp mkdir xhprof && cd xhprof wget http://pecl.ph ...
- ACM HDU Primes(素数判断)
Problem Description Writea program to read in a list of integers and determine whether or not eachnu ...
- [Linux]命令root与other切换
切换至root:sudo -i切换至other:su 用户名
- Android Camera拍照 压缩
http://www.linuxidc.com/Linux/2014-12/110924.htm package com.klp.demo_025; import java.io.ByteArrayI ...
- Python疑问系列
最近在看python源码 ------点点滴滴做个记录. 预计要分的系列: 1. import 分析 2. 主要bytecode 分析 3. python启动分析 4. object对象分析 最后希望 ...