SequoiaDB 架构指南
1 简介
SequoiaDB(巨杉数据库)是一款分布式非关系型文档数据库,可以被用来存取海量非关系型的数据,其底层主要基于分布式,高可用,高性能与动态数据类型设计,与当前主流分布式计算框架 Hadoop 紧密集成。
SequoiaDB 同时兼顾了关系型数据库中众多的优秀设计:如索引、动态查询和更新等,同时以文档记录为基础更好地处理了动态灵活的数据类型。
SequoiaDB 使用 MPP(海量并行处理)架构,运行于 Linux x86-64 与 PowerPC 平台集群,支持 PB 级数据存储。
SequoiaDB 是为在现代开发技术、编程模型以及计算资源条件下如何搭建和运行应用程序而设计的。
1.1 如何搭建应用程序
新的复杂型数据类型:在今天的应用程序中,相对于传统应用单一的关系模型,出现了多种多样的数据类型,包括动态属性、混合结构、文本、多媒体、数组以及其他复杂类型都是很常见的。
灵活性:应用程序中的数据模型随着开发的进展,是不断变化的。这是由于现代互联网环境下,很多需求在应用的设计之初并无法规划到位。因此随着时间的推移,应用程序会不断改进数据模型来适应应用程序的新特性以及新需求。
现代程序编程语言:面向对象编程语言影响着数据的结构,而这些结构与关系型数据库中存储数据的结构完全不同。
快速开发:软件工程团队现在开始接受短时间的、迭代的开发周期。在项目中,定义数据模型和应用程序功能并不是发生在项目开始的单一事件,而是一个持续的过程。
1.2 如何运行应用程序
大数据的新可扩展性能:运营和分析负载对可扩展性、可用性、性能和数据多样性提出了新的挑战。
- 快速实时性能:用户期望在很多类型接口应用程序中获得一致的、交互式的体验。
- 新硬件:计算、存储、网络以及主内存资源在成本和性能之间的关系发生了巨大变化。应用程序的设计需要能采用不同的优化策略优化这些资源,权衡利用这些资源。
- 新计算环境:单台计算机资源很难满足应用程序的基础设施需求,而云基础设施现在能提供海量、弹性、高效的运行环境。
1.3 SequoiaDB 通过创新来面对新的需求
文档型数据模型:数据以嵌套式的半结构化方式进行存储,而该结构可以映射到现代程序编程语言的对象,很容易被开发人员所理解。
丰富的查询模型:SequoiaDB 适合于各种各样的应用程序。它提供了丰富的索引和查询支持,包括二级索引,聚合框架等。
惯用驱动:开发者通过原生库来与数据库交互,使得 SequoiaDB 的使用变得简单且自然。所谓原生库,是整合了他们各自的环境和代码库。
水平可扩展:随着数据量和吞吐量的增长,开发人员能够利用通过服务器和云基础架构来增加 SequoiaDB 系统的容量。
高可用性:数据的多份副本都是通过远程复制来维护的。自动故障转移到辅助节点、机架和数据中心上,使得企业不需要自定义代码和复杂的优化,就能让系统正常运行。
内存级的性能:数据都是在内存中直接读取和写入的,而且为了系统的持久性,会在后台持续把数据写入磁盘。这些都为系统提供了快速的性能,使得系统不在需要使用单独的缓存层。
灵活性:从文档型数据模型到多数据中心部署,到可变的一致性,到运营级可用性的选择,SequoiaDB 为开发和运营团队提供了巨大的灵活性。正是由于这些优势,SequoiaDB 非常适合于各种跨行业的应用程序。
2 SequoiaDB 数据模型
2.1 作为文档的数据
SequoiaDB 以二进制表示的文档形式存储数据,这种二进制文档称为 BSON(二进制的JSON)。这个 BSON 编码扩展了流行的 JSON(JavaScript Object Notation),表现在附加的类型上,如整形、长整形以及浮点数。BSON 文档包含一个或多个字段,而且每一个字段包含一个特定数据类型值,这些特定数据类型包括数组,二进制数据,子文档。
往往有着相似结构的文档会组合成集合,类比于关系型数据库相关概念就是表;把文档类比于关系型数据中的行;把字段类比于关系型数据库中的列。
图 1 博客应用程序的关系型数据模型示例
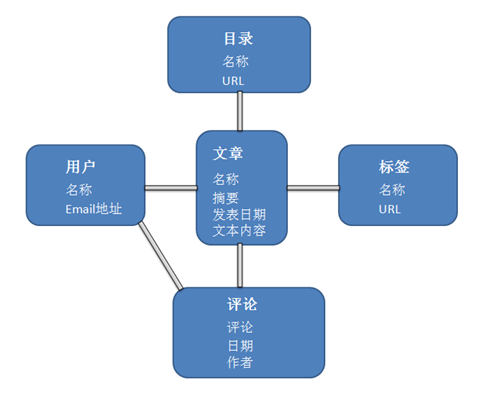
例如,为博客应用程序考虑数据模型。在关系型数据库中,数据模型可能包含多个表。为了简化这个例子,假设所有的表包括类别表,标签表,用户表,评论表以及文章表。
而在 SequoiaDB 中,数据可能会建模成两个集合,一个是用户集合,另外一个是文章集合。在每篇博客中,可能会有多个评论,多个标签以及多个分类,而这里的每个评论、标签、分类都可以作为一个嵌入的数组。
SequoiaDB 文档往往把给定记录的所有数据都存放在一个单一的文档中,而在关系型数据库中,给定的记录通常被分配存放在多个表中。换句话说,也就是 SequoiaDB 中的数据是更本地化的。在大部分 SequoiaDB 系统中,BSON 文档往往也是与应用程序中的编程语言对象结构紧密相关的,这使得开发人员能够更加容易理解应用程序中使用的数据如何映射到数据库中存储的数据的关系。
2.2 动态模式
SequoiaDB 文档在结构上可以不同。例如,描述用户的所有文档可能包含这个用户 ID,以及他们最后一次登录系统的时间。然而仅仅有部分文档可能包含对一个或多个第三方应用程序的用户身份。文档与文档之间的字段也是不相同的,而且文档都包含各自的数据结构,因此没有必要在建立集合的时候指定数据模型。如果要在一个文档中加入一个新的字段,那么就创建这样一个新的字段。这样既不会影响系统中任何其他文档,也不会更新编目信息,更不会让系统离线。
2.3 模式设计
尽管 SequoiaDB 支持强健的模式灵活,但模式设计仍旧是重要的。模式设计者应该从一些主题来考虑,例如应用程序需要执行的查询类型、如何管理应用程序代码中的对象、以及文档随时间推移如何改变和增长。模式设计超出了本文的范围,是一个广延性的话题。
图 2 博客应用程序的文档数据模型
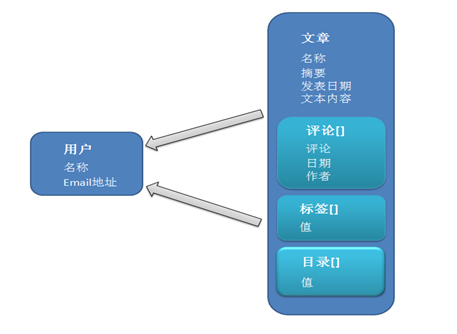
3 功能特性
3.1 惯用驱动
SequoiaDB 为所有受欢迎的编程语言提供了原生驱动程序,为营造自然的开发环境而提供了框架。支持的驱动程序包括 C、C++、Java、.NET、PHP、Python 等。相比关系数据库的根本区别在于,SequoiaDB 的查询模型是在特定编程语言的 API 中以方法或函数实现的,这与类似 SQL 完全独立的语言是相对的。再加上 SequoiaDB JSON 文档模型和面向对象编程语言中的数据结构的相似性,使得应用程序之间的集成变得简单。想获得完整的驱动列表,请查阅sequoiadb.com。
3.2 SequoiaDB 命令行
SequoiaDB 命令行是一个交互式的 JavaScript 执行环境,所有的 SequoiaDB 发行版都包含了 SequoiaDB 命令行。几乎所有 SequoiaDB 支持的命令都通过命令行执行,包括管理操作。在信息查询操作中,与 SequoiaDB 交互时,使用 SequoiaDB 命令行是一种常用的方式。在 SequoiaDB 手册中的例子都是基于命令行的。
3.3 SequoiaDB SQL 接口
SequoiaDB 提供了与 PostgreSQL 关系型数据库连接的外部表驱动,可以将 SequoiaDB 中的集合映射为 PG 中的用户表,使用户可以通过标准 SQL 访问 SequoiaDB。具体的使用方式请参见 SequoiaDB 信息中心。
3.4 查询类型
SequoiaDB 支持很多类型的查询。一个查询可能会返回一个文档,也可能是返回文档中特定字段的子集。
键值对查询返回的结果是基于文档中任何字段的,通常是关于主键字段的。
范围查询返回的结果是定义为不等式的值(例如,大于,小于或者等于)。
聚合框架查询返回的是通过查询返回值的聚合(例如总数、最小数、最大数、平均数,类似于 SQL 的 GROUP BY 语句)。
3.5 索引
类似于大多数数据库管理系统,在 SequoiaDB 中,索引对于优化系统性能是一个很重要的机制。虽然索引能够以数量级来提高一些操作的性能,但是也产生了写延迟、磁盘使用、内存使用等成本消耗。SequoiaDB 包括文档中任何字段多种类型的索引。
唯一索引:唯一索引意思是指定一个索引是唯一的。一旦一个唯一索引建立,SequoiaDB将会拒绝对已经建立的唯一索引字段的文档插入新文档或更新该文档。默认情况下,所有的索引都未被设置为唯一索引。如果一个复合索引被指定为唯一索引,则这个复合值一定是唯一的。在分区系统中,唯一索引必须包含分区键。
复合索引:为指定的多个语句查询,创建复合索引是有意义的。例如,考虑一个存储用户数据的应用程序,这个应用可能需要基于用户的姓氏、用户的名字及居住地来查询该用户。当存在基于用户的姓氏、用户的名字及居住地的复合索引时,查询可以有效定位到所有指定为这三个值的用户。复合索引还有一个好处就是,在一个索引里,任何主要字段都可以被使用,因此这会减少单个字段索引的使用。复合索引还能通过用户的姓氏来查找用户,以此来优化查询。
数组索引:对于包含数组的字段,每个数组值都会作为一个单独的索引条目来存储。例如,描绘食谱的文档可能会包括食材这个字段。如果在食材字段有个索引,那么每个食材都能被检索到,且食材字段的查询能够通过该索引而优化。创建数组索引是不需要任何特殊的语法,如果字段包含一个数组,它将作为数组索引而被检索到。
3.6 查询优化
SequoiaDB 的自动优化查询使得评估尽可能高效。评估通常包括基于语句选择数据以及基于给定分类标准来分类数据。查询优化器为每个查询类型根据开销评估选择使用最佳索引。这些经验测试的结果将被存储为一个缓存的查询计划并定期更新。
4 SequoiaDB 数据管理
4.1 就地更新
SequoiaDB 在磁盘上以连续的形式存储每个文档。当要插入新记录时,SequoiaDB 分配空间并就地更新该文件。通过就地管理数据,SequoiaDB 能够以字段进行更新,从而减少了磁盘 IO 次数,并且仅仅只更新需要更新的索引条目。
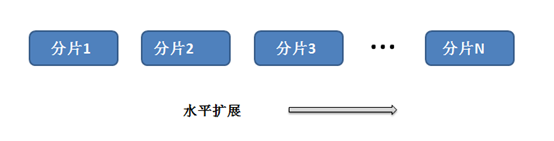
4.2 分片
SequoiaDB 通过使用分片技术为数据库提供了横向扩展机制,这个分片过程对应用程序来说是透明的。分片分配数据跨越多个物理分区,每个分区也即分片。分片是为了替SequoiaDB 部署解决单台服务器硬件资源受限问题,如内存或者磁盘 I/O 瓶颈,不会增加应用程序复杂性。
SequoiaDB 支持两种类型的分片:
- 基于范围的分片。文档通过分片的键值被分割。文档具有的分片键值接近另一个文档的分片键值时,则这两个文档位于同一个分片上。这种方法非常适合需要优化基于范围查询的应用。
- 基于哈希的分片。文档通过分片键值的 MD5 值来均匀分布。文档的分片键值接近另一个文档的分片,一般不太可能分布在同一个分片上。这种方法保证了整个分片的写均匀分布,避免了数据的热点访问。
图 3 分片机制提供了水平扩展
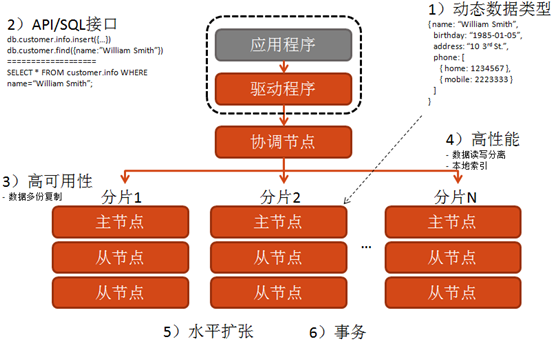
4.3 协调节点
分片对于应用程序是透明的,不管系统中有 1 个分片还是有 100 个分片,查询 SequoiaDB的应用程序代码都是一样的。应用程序把查询请求发给协调节点,协调节点会把该查询请求分配到合适的分片上。
图 4 分片对应用程序是透明的
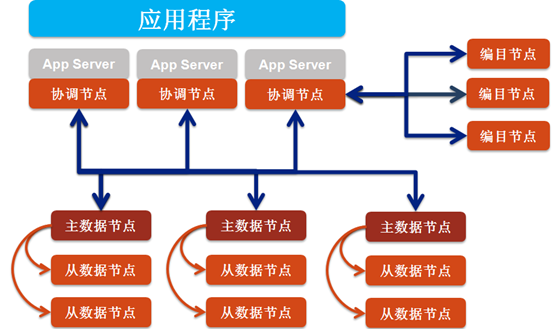
对于基于分片键值的键值查询,协调节点将分发查询请求到具有查询键值文档所属的分片中。当使用基于范围分片时,指定分片键值范围的查询仅仅分发查询请求到在查询键值范围内文档所属的分片中。
对于没有使用分片键值的查询,协调节点将会派发该查询到所有的分片上,然后在聚合所有分片上的结果,并将结果排序作为合适的查询结果。
在 SequoiaDB 系统中可以使用多个协调节点,而且合适的协调节点数量是由应用程序的性能和可用性需求共同决定的。
4.4 分区集合
除了支持横向扩展的数据分片机制,SequoiaDB 还提供了对集合的纵向分区功能。用户可以对一个集合中数据的某一字段指定集合分区键,则每条符合特定范围的记录会被切分至各自的集合分区。
集合分区在逻辑上看做一个集合的子集,每个集合分区拥有自己独立的元数据和索引。用户可以创建一个集合并将其加入一个已有的集合,或者从一个分区集合中移除特定分区(Roll-in\Roll-out)。
5 一致性和持久性
5.1 事务模型
SequoiaDB 是 ACID 兼容文档级别,支持提交回滚等事务操作。默认情况下,SequoiaDB为了保证性能关闭事务的支持,如果用户需要则可以在启动数据库时指定参数打开事务。
在关闭事务支持时,一个单一操作能够写一个或多个字段,包括多个子文档的更新和数组元素更新。SequoiaDB 的 ACID 保证了文档更新的完整隔离性,任何错误都会引发回滚操作,以及客户能得到文档的一致性视图。
而当事务打开时,任何在事务启动到提交(回滚)之间的操作都会在数据节点写入事务日志并跟踪事务 ID。更改的记录在事务提交(回滚)前持有互斥锁,不可被其他会话更改。当前 SequoiaDB 事务的隔离级别为 UR。
5.2 一致性
SequoiaDB 采用集合级别的可配置一致性策略,允许用户在对记录修改时,根据该记录所在集合判断是否需要等待备节点的确认。
譬如,对于一个对性能要求较高、对数据可靠性要求一般的集合来说,可以在创建集合时将 write concern 参数设置为 1,代表只要写入主节点就可以返回成功信息。而该操作会在后台异步地发送给从节点执行。
而对于性能要求较低、对数据可靠性要求很高的集合来说,可以在创建集合时指定 write concern 参数为 3,代表该操作最少被三个节点确认执行成功后才能够返回。
当 write concern 的数量与该集合所在每个副本集中包含节点数量相等时,系统可以被认为是强一致,否则为最终一致。
5.3 日志
SequoiaDB 实现了事务事务日志的功能,这确保了在存储引擎中的快速故障恢复和持久性。日志有助于防止毁坏,提高操作弹性。每当日志内存空间占满后,日志将会被刷入磁盘,可以为服务器损坏时数据恢复提供方便。
5.4 副本集
SequoiaDB 通过使用远程复制功能,维护了数据的多个副本,即副本集。一个副本集是有助于防止数据库停机的、完全自我修复的分片。副本故障转移是完全自动,不需要管理员手动干预。一般来说,一个包含多个节点的分片构成一个副本集。
图 5 副本集
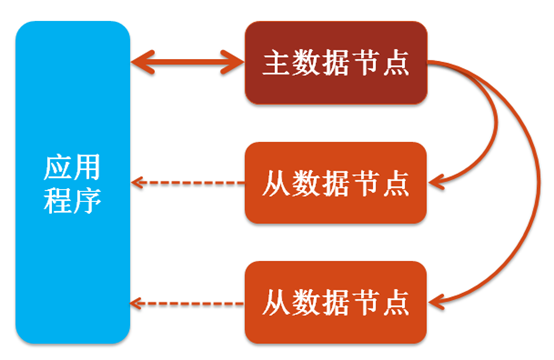
一个副本集是由多个副本组成。在任何一个时间里,都有一个副本作为主副本,其他副本是从副本。SequoiaDB 在默认情况下是最终一致的,即写作用于主副本,读作用于从副本。如果主副本因任何原因而宕掉(如过热、硬件故障或网络分区),从副本中的一个将会被选出作为主副本,且开始处理所有的写操作。
图 6 分片和副本集
用户可以通过指定每个连接会话的读请求偏好,来定义该会话从主副本或从副本读取数据。
SequoiaDB 副本集中的副本数量是可配置的,多副本提高了数据持久性以及预防了数据库的停机时间(如多机器故障、机架故障、数据中心故障或网络分区)。配置操作在返回应用程序之前写入多个副本,提供了同步复制类似的功能。应用程序能够选择从从副本中进行读操作,从副本默认情况下是最终一致的。在类似报表类应用中,即能接受稍稍有些过时数据的应用,读从副本是很有用的。
副本集提供了操作灵活性,即不需要使数据库脱机就能升级硬件和软件。例如,如果要对副本集中所有副本进行硬件升级,可以依次升级从副本而不会影响整个副本集。当所有从副本都已升级,可以暂时把主副本降为从副本,然后再更新这个副本。类似的,像添加索引操作,就能继续在副本上进行而不会影响系统正常的运行。
6 可用性
6.1 副本
在主副本上修改数据的操作会通过一个日志复制到从副本上,这个日志也叫做事务日志。这些事务日志包含了主副本中全部的数据操作,将会在从副本上重做。事务日志的大小是可配置的。
如果一个从副本停机时间比事务日志保存的时间还要长,那么从副本必须要使用全量同步过程从主副本恢复。在全量同步过程中,所有的数据库和集合以及事务日志都会从主副本或者其他副本复制到这个从副本上,还会生成索引。在向副本集中加入一个新副本时,也需要执行全量同步过程。
6.2 选举和故障转移
副本集降低了运行开销,提高了系统可用性。如果主副本集分片出现故障,所有从副本就一起决定哪个副本应该成为主副本,这个过程也就是选举过程。一旦确定了新的主副本,剩下的从副本都将配置好来接受从新主副本发来的更新操作。如果原先的主副本重新联机,它也会意识到自己不再是主副本,并会配置好自己为从副本。
6.3 选举优先
关于如何选举新的主副本,SequoiaDB 有一系列标准,主要依赖每个节点的当前事务号(LSN)作为评判依据。在进行选举的过程中,参与者中 LSN 号最高的节点(代表该节点包含最新的数据)会被推选为主节点。
6.4 磁盘的容量,内存的性能
SequoiaDB 大量使用内存来加速数据库操作。从内存读数据是纳秒级的,从普通磁盘读数据是毫秒级的。所以从内存读数据大约比从磁盘读数据快 100,000 倍。在 SequoiaDB 中,所有的数据都是通过内存映射文件来读取和操作的。不被访问的数据是不会加载到内存中的。虽然并不要求所有的数据都装在内存中,但是把所有频繁访问的索引和数据装入内存应该是期望的目标。例如,应用程序频繁的访问数据库中的小部分,如最近时间或受欢迎产品的数据。如果经常被访问的数据超过了单台机台的容量,用户可以使用分片机制将SequoiaDB在多个服务器上进行横向扩展。
由于 SequoiaDB 提供了内存级的性能,因此对于大多数应用程序来说,都不需要单独的缓存层。
7 总结
SequoiaDB 提供了一个强大的、创新的数据库平台,它是为如何构建和运行应用程序而设计。在这份指南中,我们探讨了 SequoiaDB 体系结构的基本概念和设想。类似业务最佳实践等其他主题指南,你能够在 sequoiadb.com 上找到。
SequoiaDB 架构指南的更多相关文章
- NET 架构指南频道
NET 架构指南频道 微软在Visual Studio 2017 正式发布的时候也上线了一个参考应用https://github.com/dotnet/eShopOnContainers , 最近微软 ...
- 译:微软发布.NET应用架构指南草案
原文<Microsoft Announces Draft .NET Architecture Guidance> 译注:上周微软发布了全新的<.NET应用架构指南>草案,以征求 ...
- 免费开源《OdooERP系统部署架构指南》试读:第一章 Odoo架构概述
文/开源智造联合创始人老杨 本文来自<OdooERP系统部署架构指南>的试读章节.书籍尚未出版,请勿转载.欢迎您反馈阅读意见. 从web浏览器到PostgreSQL,多层与其他层交互以处理 ...
- 《开源自主OdooERP部署架构指南》试读:第二章数据库服务构建
文/开源智造联合创始人老杨 本文来自<开源自主OdooERP部署架构指南>的试读章节.书籍尚未出版,请勿转载.欢迎您反馈阅读意见. 使用apt.postgresql.org 您可以选择使用 ...
- .NET微服务 容器化.NET应用架构指南(支持.NET Core2)
介绍 企业通过使用容器,日益实现成本节约.解决部署问题并改进 DevOps 和生产操作. 通过创建 Azure 容器服务.Azure Service Fabric 等产品,同时与 Docker.Mes ...
- App开发架构指南(谷歌官方文档译文)
这篇文章面向的是已经掌握app开发基本知识,想知道如何开发健壮app的读者. 注:本指南假设读者对 Android Framework 已经很熟悉.如果你还是app开发的新手,请查看 Getting ...
- 《容器化.NET应用架构指南》脑图学习笔记(第一部分)
一.关于这本官方“圣经” 作为.NET程序员,对于微软官方推动的架构示例总是特别关注,从PetShop到MusicStore再到eShopOnContainers,每一次关注,都会了解到业界最新的架构 ...
- 微软在.NET官网上线.NET 架构指南频道
微软在Visual Studio 2017 正式发布的时候也上线了一个参考应用https://github.com/dotnet/eShopOnContainers , 最近微软给这个参考应用写了完善 ...
- 【转】 微软在.NET官网上线.NET 架构指南
原文地址:http://www.cnblogs.com/shanyou/p/6676357.html. 微软在Visual Studio 2017 正式发布的时候也上线了一个参考应用https://g ...
随机推荐
- SQL语法集锦三:合并列值与分拆列值
本文转载http://www.cnblogs.com/lxblog/archive/2012/09/29/2708724.html 在SQL中分拆列值和合并列值老生常谈了,从网上搜刮了一下并记录下来, ...
- OpenCV 最小二乘拟合方法求取直线倾角
工业相机拍摄的图像中,由于摄像质量的限制,图像中的直线经过处理后,会表现出比较严重的锯齿.在这种情况下求取直线的倾角(其实就是直线的斜率),如果是直接选取直线的开始点和结束点来计算,或是用opencv ...
- [Redux] Supplying the Initial State
We will learn how to start a Redux app with a previously persisted state, and how it merges with the ...
- 只有在配置文件中或 Page 说明会 enableSessionState 至 true 时刻,能够使用会话状态。另外,还要确保应用程序配置 // 段包含 System.Web.SessionSta
首先,弄清楚我们的目的,我的目标是验证用户登录.那是,Session["userName"]!=null 在ok该 起初,我是这么写的,结果给出,提示如果上述错误标题,在调查的很长 ...
- AndroidStudio 快捷键使用
经常使用快捷键使用搜集 1. Ctrl+D: 集合了复制和粘贴两个操作,假设有选中的部分就复制选中的部分.并在选中部分的后面粘贴出来,假设没有选中的部分.就复制光标所在的行.并在此行的以下粘贴出来. ...
- 观察者模式-Observer
观察者模式很好理解,简单来说就是:当一个对象变化时,其它依赖该对象的对象都会收到通知,并且随着变化!对象之间是一种一对多的关系. 1. 自己手工创建Observer模式 首先,创建观察者接口: pub ...
- Android(java)学习笔记206:利用开源SmartImageView优化网易新闻RSS客户端
1.我们自己编写的SmartImageView会有很多漏洞,但是我们幸运的可以在网上利用开源项目的,开源项目中有很多成熟的代码,比如SmartImageView都编写的很成熟的 国内我们经常用到htt ...
- 9.26 noip模拟试题
魔术球问题弱化版(ball.c/.cpp/.pas) 题目描述 假设有 n 根柱子,现要按下述规则在这 n 根柱子中依次放入编号为 1,2,3,…的球. (1)每次只能在某根柱子的最上面放球. (2) ...
- eclipse(myEclipse) 配置maven项目
工作中在myeclipse中导入maven工程后,在pom.xml文件目录执行了mvn eclipse:eclipse 后,发现项目中缺少"Maven Dependencies"目 ...
- [转]Delphi中ShellExecute的妙用
Delphi中ShellExecute的妙用 ShellExecute的功能是运行一个外部程序(或者是打开一个已注册的文件.打开一个目录.打印一个文件等等),并对外部程序有一定的控制. ...