7、 正则化(Regularization)
7.1 过拟合的问题
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致它们效果很差。
在这段视频中,我将为你解释什么是过度拟合问题,并且在此之后接下来的几个视频中,我们将谈论一种称为正则化(regularization)的技术,它可以改善或者减少过度拟合问题。
如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集(代价函数可能几乎为0),但是可能会不能推广到新的数据。
下图是一个回归问题的例子:
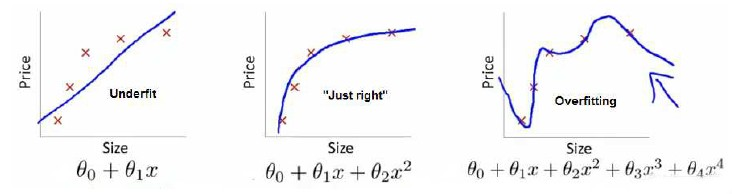
第一个模型是一个线性模型,欠拟合,不能很好地适应我们的训练集;第三个模型是一个四次方的模型,过于强调拟合原始数据,而丢失了算法的本质:预测新数据。我们可以看出,若给出一个新的值使之预测,它将表现的很差,是过拟合,虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好;而中间的模型似乎最合适。
分类问题中也存在这样的问题:
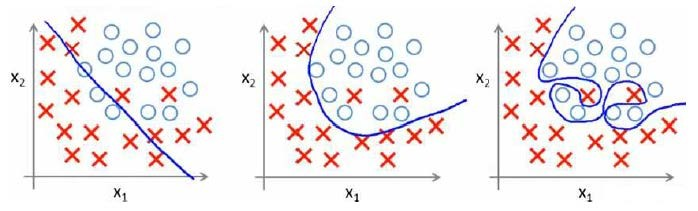
就以多项式理解,x$的次数越高,拟合的越好,但相应的预测的能力就可能变差。
问题是,如果我们发现了过拟合问题,应该如何处理?
丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些模型选择的算法来帮忙(例如PCA)
正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
7.2 代价函数
上面的回归问题中如果我们的模型是:
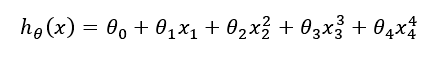
我们可以从之前的事例中看出,正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了。
所以我们要做的就是在一定程度上减小这些参数θ 的值,这就是正则化的基本方法。我们决定要减少θ3和θ4的大小,我们要做的便是修改代价函数,在其中θ3和θ4设置一点惩罚。这样做的话,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的θ3和θ4。 修改后的代价函数如下:
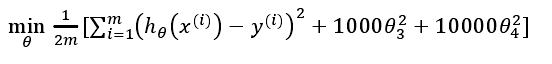
通过这样的代价函数选择出的θ3和θ4 对预测结果的影响就比之前要小许多。假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。这样的结果是得到了一个较为简单的能防止过拟合问题的假设:
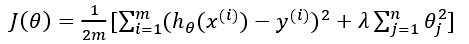
其中
7、 正则化(Regularization)的更多相关文章
- [DeeplearningAI笔记]改善深层神经网络1.4_1.8深度学习实用层面_正则化Regularization与改善过拟合
觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 正则化(regularization) 如果你的神经网络出现了过拟合(训练集与验证集得到的结果方差较大),最先想到的方法就是正则化(re ...
- zzL1和L2正则化regularization
最优化方法:L1和L2正则化regularization http://blog.csdn.net/pipisorry/article/details/52108040 机器学习和深度学习常用的规则化 ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [笔记]机器学习(Machine Learning) - 03.正则化(Regularization)
欠拟合(Underfitting)与过拟合(Overfitting) 上面两张图分别是回归问题和分类问题的欠拟合和过度拟合的例子.可以看到,如果使用直线(两组图的第一张)来拟合训,并不能很好地适应我们 ...
- CS229 5.用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
- [C3] 正则化(Regularization)
正则化(Regularization - Solving the Problem of Overfitting) 欠拟合(高偏差) VS 过度拟合(高方差) Underfitting, or high ...
- 1.4 正则化 regularization
如果你怀疑神经网络过度拟合的数据,即存在高方差的问题,那么最先想到的方法可能是正则化,另一个解决高方差的方法就是准备更多数据,但是你可能无法时时准备足够多的训练数据,或者获取更多数据的代价很高.但正则 ...
- 机器学习(五)--------正则化(Regularization)
过拟合(over-fitting) 欠拟合 正好 过拟合 怎么解决 1.丢弃一些不能帮助我们正确预测的特征.可以是手工选择保留哪些特征,或者使用一 些模型选择的算法来帮忙(例如 PCA) 2.正则化. ...
随机推荐
- C++ GUI Qt4学习笔记09
C++ GUI Qt4学习笔记09 qtc++ 本章介绍Qt中的拖放 拖放是一个应用程序内或者多个应用程序之间传递信息的一种直观的现代操作方式.除了剪贴板提供支持外,通常它还提供数据移动和复制的功 ...
- Arduino库
单总线库: 下载地址 : 链接:https://pan.baidu.com/s/1YSuqrXWuBAxMEUWHy8rckw 提取码:svix 把整个文件夹复制到 Arduino安装目录的 ...
- Python---Tkinter---贪吃蛇
# 项目分析: - 构成: - 蛇 Snake - 食物 Food - 世界 World - 蛇和食物属于整个世界 class World: self.snake self.food ------- ...
- React Native 之导航栏
一定要参考官网: https://reactnavigation.org/docs/en/getting-started.html 代码来自慕课网:https://www.imooc.com/cour ...
- spring IOC(Spring 生命周期,先1.构造方式,2,初始化方法,3,目标方法,4,销毁方法)
- ExtJS用Grid显示数据后如何自动选取第一条记录
用Grid显示数据后,如何让系统自动选取第一条记录呢?在显示Grid时由于其Store正在loading,没法在Grid选取第一条记录,因为还没有记录,所以应在其Store进行操作. 查看Ext.da ...
- 放一道比较基础的LCA 的题目把 :CODEVS 2370 小机房的树
题目描述 Description 小机房有棵焕狗种的树,树上有N个节点,节点标号为0到N-1,有两只虫子名叫飘狗和大吉狗,分居在两个不同的节点上.有一天,他们想爬到一个节点上去搞基,但是作为两只虫子, ...
- BigDecimal.setScale 处理java小数点[转]
BigDecimal.setScale()方法用于格式化小数点setScale(1)表示保留一位小数,默认用四舍五入方式 setScale(1,BigDecimal.ROUND_DOWN)直接删除多余 ...
- C#异常日志
代码比较简单,仅提供一种思路 /// <summary> /// 将异常打印到LOG文件 /// </summary> /// <param name="ex& ...
- 北风设计模式课程---最少知识原则(Least Knowledge Principle)
北风设计模式课程---最少知识原则(Least Knowledge Principle) 一.总结 一句话总结: 最少知识原则(Least Knowledge Principle),或者称迪米特法则( ...