tensorflow函数介绍(4)
1、队列的实现:
import tensorflow as tf
q=tf.FIFOQueue(2,'int32') #创建一个先进先出队列,指定队列中最多可以保存两个元素,并指定类型为整数。
#先进先出队列为:FIFOQueue,随机的为:RandomShuffleQueue
init=q.enqueue_many(([0,10],)) #将[0,10]这2个元素排入此队列
x=q.dequeue()
y=x+1 #将加1后的值再重新加入队列
q_inc=q.enqueue([y])
with tf.Session() as sess:
init.run() #初始化队列操作
for _ in range(5):
v,_=sess.run([x,q_inc]) #运行q_inc将执行数据进出队列、出队的元素+1、重新加入队列的整个过程。
print(v) #打印出元素的取值
2、通过tf.Coordinator和tf.QueueRunner两个类实现多线程协同的功能:
tf.Coordinator主要用于协同多个线程一起停止,并提供should_stop、request_stop和join三个函数。在启动线程前,需要先声明一个tf.Coordinator类,并将该类传入每个创建的线程,启动的线程需要一直查询tf.Coordinator类提供的should_stop函数,当该函数返回值为True时,当前线程也需要退出。每个启动的线程都可以通过调用request_stop函数来通知其他线程退出。当某个线程调用request_stop函数后,should_stop函数的返回值将被设置为True,这样其他线程就可以同时终止。代码部分如下所示:
import tensorflow as tf
import numpy as np
import threading
import time
def myloop(coord,worker_id):
while not coord.should_stop(): #tf.train.Coordinator.should_stop()的含义是用于检查是否被请求停止
if np.random.rand()<0.1:
print('stoping from id: %d\n' %worker_id)
coord.request_stop() #tf.train.Coordinator.request_stop(ex=None)请求线程结束
else:
print('working on id: %d\n' %worker_id )
time.sleep(1) coord=tf.train.Coordinator() #声明一个tf.train.Coordinator类来协同多个线程
threads=[threading.Thread(target=myloop,args=(coord,i,)) for i in range(5)]
for t in threads: #启动所有的线程
t.start()
coord.join(threads) #tf.train.Coordinator.join(threads=None, stop_grace_period_secs=120)等待线程终止,threads:为一个threading.Thread的列表,启动的线程将额外加到registered中
此外,tf.QueueRunner主要用于启动多个线程来操作同一个队列,启动这些线程可以通过上面的tf.Coordinator类来统一管理,以下代码展示了如何使用tf.QueueRunner和tf.Coordinator来管理多线程队列操作:
import tensorflow as tf
queue=tf.FIFOQueue(100,'float')
enqueue_op=queue.enqueue([tf.random_normal([1])]) #定义入队操作
qr=tf.train.QueueRunner(queue,[enqueue_op]*5) #第一个参数给出被操作的队列,[enqueue_op]*5表示需要启动5个线程,每个线程中运行的是enqueue_op操作
tf.train.add_queue_runner(qr) #将定义的QueueRunner加入默认计算图上的集合
out_tensor=queue.dequeue() #定义出队操作
with tf.Session() as sess:
coord=tf.train.Coordinator() #协同启动的线程
threads=tf.train.start_queue_runners(sess=sess,coord=coord) #在使用tf.train.QueueRunner时,需要调用tf.train.start_queue_runners函数来启动所有线程,否则因为没有线程运行入队操作,当调用出队操作时,程序会一直等待入队操作被运行。
#tf.train.start_queue_runners函数会默认启动tf.GraphKeys.QUEUE_RUNNERS集合中所有的QueueRunner,因为这个函数只支持启动指定集合中的QueueRnner,所以tf.train.add_queue_runner函数和tf.train.start_queue_runner函数会指定同一个集合。
for _ in range(3):
print(sess.run(out_tensor)[0])
coord.request_stop()
coord.join(threads)
输出结果如下所示:
#上面程序启动5个线程执行入队操作,每个线程都是将随机数写入队列,于是每次运行出队操作,都可以得到一个随机数,输出结果如下:
-0.0733609
-1.06043
-0.466889
3、写TFRecord格式数据:
import tensorflow as tf
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
num_shards=2
instances_per_shard=2
for i in range(num_shards):
filename=('/path/to/data.tfrecords-%.5d-of-%.5d' %(i,num_shards))
writer=tf.python_io.TFRecordWriter(filename) #准备一个writer用来写TFRecord文件
for j in range(instances_per_shard):
example=tf.train.Example(features=tf.train.Features(feature={'i':_int64_feature(i),'j':_int64_feature(j)})) #将数据通过tf.train.Example存入Example协议内存块(protocol buffer)
#Example结构仅包含当前样例属于第几个文件以及当前文件的第几个样本,然后通过tf.python_io.TFRecordWriter写入到TFRecord文件
writer.write(example.SerializeToString()) #序列转化为字符串
writer.close()
4、tf.train.match_filenames_once函数和tf.train.string_input_producer函数的使用方法:
import tensorflow as tf
files=tf.train.match_filenames_once('/path/to/data.tfrecords-*') #获取文件列表
filename_queue=tf.train.string_input_producer(files,shuffle=False) #创建输入列表,设置shuffle为False来避免随机打乱读文件顺序。
reader=tf.TFRecordReader()
_,serialized_example=reader.read(filename_queue) #读取并解析一个样本
features=tf.parse_single_example(serialized_example,features={'i':tf.FixedLenFeature([],tf.int64),'j':tf.FixedLenFeature([],tf.int64)})
with tf.Session() as sess:
tf.global_variables_initializer().run()
coord=tf.train.Coordinator() #通过tf.train.Coordinator类来协同不同线程,并启动线程
threads=tf.train.start_queue_runner(sess=sess,coord=coord) #该函数用于启动所有线程
for i in range(6): #多次执行获取数据的操作
print(sess.run([features['i'],features['j']]))
coord.request_stop()
coord.join(threads)
以上程序会依次读出样例数据中的每一个样例,当所有样例读完后程序会自动从头开始。
5、组合训练数据(batching)
将多个输入样例组织成一个batch可以提高模型训练的效率,所以在得到单个样例的预处理结果后,还需要将它们组织成batch,然后再提供给神经网络的输入层。
tensorflow提供了tf.train.batch和tf.train.shuffle_batch函数来将单个样例组织成batch的形式输出,这两个函数会生成一个队列,队列的入队操作是生成单个样例的方法,而每个出队得到的是一个batch的样例。区别在于是否会将数据打乱。代码演示如下:
import tensorflow as tf
example,label=feature['i'],feature['j']
batch_size=3 #一个batch中样例的个数
capacity=1000+3*batch_size
example_batch,label_batch=tf.train.batch([example,label],batch_size=batch_size,capacity=capacity) #batch_size给出了每个batch中样例的个数,capacity给出了队列的最大容量,当队列长度等于容量时,tensorflow暂停入队操作,而只是等待元素出队。当元素个数小于
容量时,tensorflow将重新启动入队操作。
#example和label分别代表训练样本及该训练样本的标签
with tf.Session() as sess:
tf.global_variables_initializer()
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(sess=sess,coord=coord)
for i in range(2):
cur_example_batch,cur_label_batch=sess.run([example_batch,label_batch])
print(cur_example_batch,cur_label_batch)
coord.request_stop()
coord.join(threads)
tf.train.shuffle_batch函数的使用方法:
#配合第4部分的:
#features=tf.parse_single_example(serialized_example,features={'i':tf.FixedLenFeature([],tf.int64),'j':tf.FixedLenFeature([],tf.int64)})
#如上提取的数据进行使用
example,label=features['i'],features['j']
example_batch,label_batch=tf.train.shuffle_batch([example,label],batch_size=batch_size,capacity=capacity,min_after_dequeue=30)
#使用tf.train.shuffle_batch函数来组合样例,tf.train.shuffle_batch函数的参数大部分都和tf.train.batch函数相似,但是min_after_dequeue参数是tf.train.shuffle_batch函数特有的,min_after_dequeue参数限制了出队时队列中元素的最少个数
#如果min_after_dequeue参数被设定,capacity也应该相应调整来满足性能需求。
6、输入数据处理框架:
流程图如下所示:
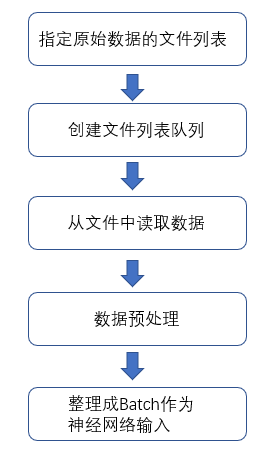
以下代码实现该流程图:
import tensorflow as tf
files=tf.train.match_filenames_once('/path/to/file_pattern-*')
filename_queue=tf.train.string_input_producer(files,shuffle=False)
reader=tf.TFRecordReader()
_,serialized_sample=reader.read(filename_queue)
features=tf.parse_single_example(serialized_example,features={'image':tf.FixedLenFeature([],tf.string),'label':tf.FixedLenFeature([],tf.int64)
,'height':tf.FixedLenFeature([],tf.int64),'width':tf.FixedLenFeature([],tf.int64),'channels':tf.FixedLenFeature([],tf.int64)})
image,label=features['image'],features['label']
height,width=features['height'],feature['width']
channel=features['channels']
decoded_image=tf.decode_raw(image,tf.uint8) #tf.uint8表示8位无符号整型, tf.int8表示8位有符号整型
decoded_image.set_shape([height,width,channels])
image_size=299
distorted_image=preprocess_for_train(decoded_image,image_size,image_size,None) #preprocess_for_train是图像预处理的函数
#将处理后的图像和标签通过tf.train.shuffle_batch整理成神经网络训练时需要的batch
min_after_dequeue=10000
batch_size=100
capacity=min_after_dequeue+3*batch_size
image_batch,label_batch=tf.train.shuffle_batch([distorted_image,label],batch_size=batch_size,capacity=capacity,min_after_dequeue=min_after_dequeue)
logit=inference(image_batch) #image_batch提供了正确值
loss=calc_loss(logit,label_batch) #label_batch提供了batch样例的正确答案
train_step=tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.Session() as sess:
tf.global_variables_initializer().run()
coord=tf.train.Coordinator()
threads=tf.train.start_queue_runners(sess=sess,coord=coord)
for i in range(training_rounds):
sess.run(train_step)
coord.request_stop()
coord.join(threads)
以上代码展示了输入数据预处理的流程。从下图可以看出,输入数据处理的第一步为获取存储训练数据的文件列表。
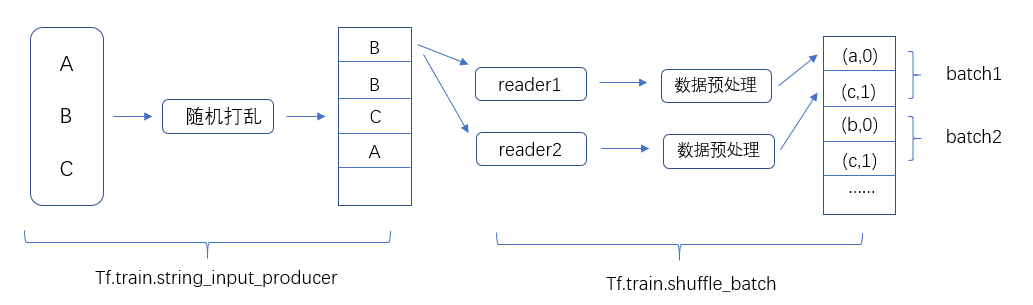
从数据提取到神经网络的输入流程如下:
从下图中,这个文件列表为{A,B,C},通过tf.train.string_input_producer函数,来选择性的将文件列表中的文件顺序打乱,并加入输入队列。(tf.train.string_input_producer(file_name,shuffle=True),通过设置参数shuffle来定义是否随机打乱)。
tf.train.string_input_producer()函数会维护一个输入文件队列,不同线程中的文件读取函数可以共享这个输入文件队列,在读取样例数据后,需要将图像进行预处理。此外,图像预处理的过程也会通过tf.train.shuffle_batch提供的机制并行地运行在
多个线程中。输入数据处理的流程最后通过tf.train.shuffle_batch函数将处理好的单个输入样例整理成batch提供给神经网络的输入层。通过这种方式,可以有效提高数据预处理的效率。
tensorflow函数介绍(4)的更多相关文章
- tensorflow函数介绍(3)
tf.nn.softmax_cross_entropy_with_logits(logits,labels) #其中logits为神经网络最后一层输出,labels为实际的标签,该函数返回经过soft ...
- tensorflow函数介绍(2)
参考:tensorflow书 1.模型的导出: import tensorflow as tf v1=tf.Variable(tf.constant(2.0),name="v1") ...
- tensorflow函数介绍(1)
tensorflow中的tensor表示一种数据结构,而flow则表现为一种计算模型,两者合起来就是通过计算图的形式来进行计算表述,其每个计算都是计算图上的一个节点,节点间的边表示了计算之间的依赖关系 ...
- tensorflow函数介绍 (5)
1.tf.ConfigProto tf.ConfigProto一般用在创建session的时候,用来对session进行参数配置: with tf.Session(config=tf.ConfigPr ...
- Tensorflow | 基本函数介绍 简单详细的教程。 有用, 很棒
http://blog.csdn.net/xxzhangx/article/details/54606040 Tensorflow | 基本函数介绍 2017-01-18 23:04 1404人阅读 ...
- python strip()函数 介绍
python strip()函数 介绍,需要的朋友可以参考一下 函数原型 声明:s为字符串,rm为要删除的字符序列 s.strip(rm) 删除s字符串中开头.结尾处,位于 rm删除 ...
- PHP ob_start() 函数介绍
ob_start() 函数介绍: http://www.nowamagic.net/php/php_ObStart.php ob_start()作用: http://zhidao.baidu.com/ ...
- Python开发【第三章】:Python函数介绍
一. 函数介绍 1.函数是什么? 在学习函数之前,一直遵循面向过程编程,即根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,也就是将之前实现的代码块复 ...
- row_number() OVER(PARTITION BY)函数介绍
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个 ...
随机推荐
- MySQL数据库:RESET MASTER、RESET SLAVE、MASTER_INFO、RELAY_LOG_INFO
MySQL数据库:RESET MASTER.RESET SLAVE.MASTER_INFO.RELAY_LOG_INFO RESET MASTER 删除所有index file中记录的所有binlog ...
- 阶段1 语言基础+高级_1-3-Java语言高级_1-常用API_1_第4节 ArrayList集合_19-ArrayList练习四_筛选集合
大集合里面循环装了20个int类型的随即数字 下面要自定义方法,这个方法专门负责筛选 遍历偶数的集合 重点是集合当做方法的参数,还能当做集合的返回值
- Java ——数组 选择排序 冒泡排序
本节重点思维导图 数组 public static void main(String[] args) { int a ; a=3; int[] b; b = new int[3];//强制开辟内存空间 ...
- 自动化测试--利用opencv进行图像识别与定位
SIFT检测方法 SIFT算法就是把图像的特征检测出来,通过这些特征可以在众多的图片中找到相应的图片 import cv2 #读取图片,以1.png为例 img=cv2.imread('1.png') ...
- Python基础-1 python由来 Python安装入门 注释 pyc文件 python变量 获取用户输入 流程控制if while
1.Python由来 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚 ...
- Ansible--常用命令整理
由于最近使用ansible在多台服务器部署程序,运行命令的时候,发现对Linux和ansible自动运维工具用的不太熟练,所以搜集整理一些,方便日后复习提升,达到熟练运用的目的. 对于详细的安装教程和 ...
- [Python3] 014 集合的内置方法
目录 1. Python3 中如何查看 set() 的内置方法 2. 少废话,上例子 (1) add() (2) 又见清理大师 clear() (3) 又见拷贝君 copy() (4) 找茬君 dif ...
- flume 进阶
一.flume事务 put事务流程: 1.doPut:将批量数据先写入临时缓冲区putList 2.doCommit:检查Channel内存队列是否足够, (1)达到一定时间没有数据写入到putLis ...
- Node.js中package.json中库的版本号详解(^和~区别)
当我们查看package.json中已安装的库的时候,会发现他们的版本号之前都会加一个符号,有的是插入符号(^),有的是波浪符号(~).那么他们到底有什么区别呢?先贴一个例子,对照例子来做解释: &q ...
- Java中的容器(集合)之ArrayList源码解析
1.ArrayList源码解析 源码解析: 如下源码来自JDK8(如需查看ArrayList扩容源码解析请跳转至<Java中的容器(集合)>第十条):. package java.util ...