Qualcomm_Mobile_OpenCL.pdf 翻译-3
3 在骁龙上使用OpenCL
在今天安卓操作系统和IOT(Internet of Things)市场上,骁龙是性能最强的也是最被广泛使用的芯片。骁龙的手机平台将最好的组件组合在一起放到了单个芯片上,这样保证了基于骁龙平台的设备将带来极致的功耗效率和集成的解决方案,从而带来最新的手机用户体验。
骁龙是一个多处理器系统,包含比如多模解调器(multimode modem),CPU,GPU,DSP,位置/GPS,多媒体,电源管理,RF,针对软件和操作系统的优化,内存,可连接性(Wi-Fi,蓝牙)等。
如果想了解当前包含骁龙处理器的消费设备清单,或者想知道关于骁龙处理器更多其他方面的内容,请浏览网站 http://www.qualcomm.com/snapdragon/devices。Adreno GPUs 一般在渲染图像的应用程序中使用,同时它也拥有一般处理器的处理大量计算复杂的任务的能力,比如图像和音频的处理、计算视觉。使用OpenCL执行数据并行的计算能够充分发挥GPU的能力。
3.1在骁龙上使用OpenCL
Adreno A3x,A4x 和A5x 系列的GPUs 已经能充分支持OpenCL,并且已经完全符合OpenCL标准。OpenCL有不同的版本和profiles,所以不同系列的Anreno GPUs可能支持不同的OpenCL版本,如表3-1所示:
表3-1 支持OpenCL的Adreno GPUS
|
GPU 系列 |
Adreno A3x |
Adreno A4x |
Adreno A5x |
|
OpenCL version |
1.1 |
1.2 |
2.0 |
|
OpenCL profile |
Embedded |
Full |
Full |
除了支持的OpenCL的版本和profiles不同之外,不同的Adreno GPUs还可能有其他的不同的性质,比如支持的扩展功能不同,支持的图片对象最大维度不同等。可以通过调用API函数clGetDeviceInfo获取完整的设备细节信息。
3.2 Andreno GPU架构
这章将从高层次的角度总体介绍一下Adreno中与OpenCL相关的架构。
3.2.1 与OpenCL相关的Adreno的架构
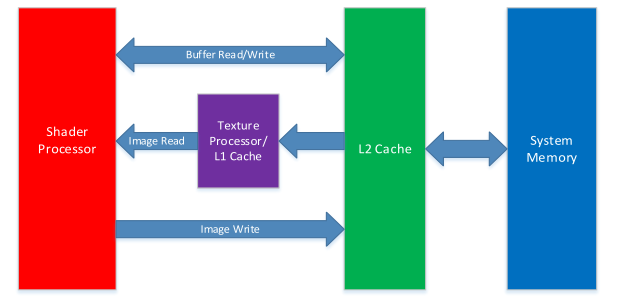
图3-1 A5x GPUs 中与OpenCL相关的架构
Adreno GPUs支持许多图像和计算API,包括OpenGL ES,OpenCL,DirectX和Vulkan等。图3-1阐述了与OpenCL相关的Andreno A5x硬件总体架构,其中省略了图像相关的硬件模块。A5x和其他Andreno系列的GPU有许多不同,但是在OpenCL上的差异很小。
执行OpenCL的关键硬件模块如下:
- SP ( Shader or Streaming processor 着色或者流媒体处理器(图像渲染的相关名词))
- Andreno GPU的核心部分。包含了许多硬件模块,包括算术逻辑单元(ALU),装载/存储单元,控制流单元,寄存器文件等。
- 执行图像的着色程序(比如三角着色,片段着色,计算着色)(图像渲染中使用的)和执行计算任务比如OpenCL kernels。
- 每一个SP对应一个或者多个OpenCL的计算单元。
- 根据GPU的系列和等级不同,Adreno GPUs可能包含一个或者多个SP。低级的芯片组可能只有一个SP,高级的芯片组可能有更多的SP。在图3-1中,只有一个SP。
- 对于使用__read_write (OpenCL2.0的特性)限定词定义的缓冲区对象和图片对象,SP将通过L2缓存装载和存储。
- 对于只读的图像对象,SP通过texture processor/L1 模块来装载数据。
- TP(Texture processor 纹理处理器(图像渲染的相关名词))
- 执行纹理操作,比如基于内核的请求进行纹理的获取和过滤。
- TP是与L1 cache结合在一起,当出现纹理数据缓冲区未命中时,L1 cache从UCHE(Unified L2 Cache下面讲)中获取数据。
- Unified L2 Cache(UCHE)
- 负责为SP从缓冲区(Buffer对象)对象存储/装载数据,负责为L1 cache请求装载图像对象(Image对象)。(如图3-1,就当SP请求从缓冲区装载/存储数据,通过UCHE ,当L1 cache请求装载图像对象时,通过UCHE)
3.2.2 Waves 和 fibers(高通内部定义的概念,直接用英文,具体意义会在章节中详细解释)
在Adreno GPUs中,最小的执行单元叫fiber。一个fiber对应OpenCL中的一个work item(工作项,opencl中的概念,因为代码中也会经常用到,所以直接用英文表示)。以“固定步调”一起运行的一组fiber叫做wave。SP可以同时容纳多个已经激活的wave。每一个wave与前面的程序独立,并且与其他waves的运行状态无关。需要注意以下几点:
- wave的大小,或者说是在一个wave中fbers的数量,对于指定的GPU和kernel,这个数量固定的。(GPU给出最大值,kernel函数给出当前需要运行的值)。
- 在Adreno GPU中,wave的大小依赖于GPU的系列和编译器,一般值是8,16,32,54,128等。
- 一个workgroup(工作组,opencl中的概念)可以被一个或者多个waves执行,这主要由workgroup的大小决定。比如说,如果一个workgroup的大小小于或者等于wave的大小,只需要一个wave就可以。当然越多的wave当然越好,因为wave之间能够更好地隐藏延迟。(像cpu上的流水线,比如一个wave执行完load数据,开始计算,另一个wave就可以开始执行load数据操作。这样第二个wave的load操作时间就被隐藏了。)
- SP可以在一个或者多个waves上同时执行ALU指令。
- 在一个workgroup中,可以流水线运行的最大的wave的个数是由硬件决定的。典型的,Adreno GPUs支持16个waves。
- 给定一个kernel函数,在一个SP上能激活的最大waves的个数是由kernel的寄存器占用和寄存器文件的大小决定(就是虽然硬件最大支持16个waves同时运行,但是如果kernel函数占用寄存器过多,寄存器不够用,可能只有8个waves同时运行),同时也由GPU的系列和等级决定。
- 一般地,kernel函数越复杂,可激活的waves越小。(这里提供了优化思路,将复杂的kernel函数拆成多个简单的kernel函数,能够提高并行速度)
- 给定一个kernel函数,最大的workgroup大小是wave的大小和允许的wave的最大个数的乘积。
OpenCL 1.x的文档中并没有暴露wave上的概念,在OpenCL2.0中,已经允许应用程序通过cl_khr_subgroups扩展功能使用wave,不过是从Adreno A5x GPU开始支持的。
3.2.3延迟隐藏
延迟隐藏是GPU有效并行化处理中最强大的一个特点,使得GPU达到一个很高的吞吐量。举例如下:
- SP开始执行第1个wave。
- 在执行完几个ALU指令后,这个wave需要从外存中(可能是全局/本地/私有内存)获取更多的数据进行接下来的处理,而这些数据当前没有获取到。
- SP为这个wave发送数据获取数据请求。
- SP切换到已经准备好的第2个wave开始执行。
- SP继续执行第2个wave,直到第2个wave依赖的内容(比如数据或者寄存器之类)没有准备好。
- SP 可能会切换到第3个wave,或者切回到第1个wave执行,如果第一个wave已经可执行(数据已经获取到)的话。
在这种方式下,SP一直处于非常忙碌的状态,而且就像是全部时间都在工作,或者说外部依赖项已经被很好隐藏了。
3.2.4 workgroup的分配
一个典型的OpenCL kernel需要用到多个workgroup。在Adreno GPU中,每一个workgroup被分配给一个SP,一般地,在同一时间内每一个SP只能运行一个workgroup。如果有剩下的workgroup,会在GPU中排队等待执行。
用图3-2所示的2维workgroup为例,并假设该GPU有4个SP。图3-3表示了这些workgroup如何被分配到不同的SP上。在这个例子中,共有9个workgroup,并且每一个都由一个SP上执行。每一个workgroup有4个wave,wave的大小是16.

图3-2 workgroup的布局和分派到在Andreno GPU上执行的例子

图3-3 workgroup被分配到SP上执行的例子
OpenCL标准既没有定义workgroup启动和执行的顺序,也没有定义workgroup之间的同步机制。对于Adreno GPUs,开发者不能假设workgroup在SP上按照指定的顺序启动。同样地,wave也不能假设按照指定的顺序启动。
在大部分的Adreno GPUs中,一个SP在同一个时间只能运行一个workgroup,而且一个workgroup必须完成后,另一个workgroup才能开始。但是在更高级和更新的GPU系列中,比如Adreno A540 GPU,一个SP上可以执行多个workgroup。
3.3 Adreno A3x,A4x 和A5x在OpenCL上的不同点
每一个新的Adreno GPU系列将会在OpenCL的特性和性能上带来很大的提升。这一章将讨论影响OpenCL性能的关键改变。
3.3.1 L2 cache
从Adreno A320和Adreno 330 GPUs 到Adreno A420, A430,A530 和A540 GPUs,为了更好的效率和性能,L2 cache的架构进行了极大的改进,同时还增加了L2 cahe的容量。
3.3.2 Local memory本地内存
从Adreno A3x 到A4x 和A5x 系列,Local memory在容量,装载/存储吞吐量和合并访问(coalesced access)上有所提升。表3-2表示了在不同系列上合并访问的不同点。
表3-2 本地内存性能总结
|
GPUs |
Adreno A3x |
Adreno A4x |
Adreno A5x |
|
合并访问 |
不支持 |
不支持 |
支持,每次操作可以由最多4个work item装载/存储128位。 |
合并访问是OpenCL和GPU并行计算中的一个重要概念。从本质上说,它指的是,基础硬件能够将多个work item的数据装载/存储请求合并成一个请求,从而提升数据的装载/存储效率。如果没有合并访问的支持,硬件必须针对每个单独的请求进行装载和存储的操作,这将会导致较差的性能。
图3-4 阐述了合并访问和非合并访问之间的不同。为了能够将多个work items的请求结合在一起,请求的数据地址必须是连续的。在合并访问中,Adreno GPUs能够在一次处理中给4个work items装载数据,而非合并访问中,需要4次处理才能够装载同样数量的数据。

图3-4 数据装载中合并访问 vs 非合并访问
3.4 图像和计算任务之间的上下文切换
3.4.1 上下文切换
在Adreno GPUs中,如果一个高优先级的任务,比如图像用户界面(UI)渲染进行了请求,同时一个低优先级任务正在GPU上运行,那么后者将会被暂停,然后GPU切换到高优先级的任务上执行。当高优先级的任务执行完毕,低优先级的任务将会被恢复。这种任务的切换叫做上下文切换。上下文切换是非常耗时的,因为需要复杂的硬件和软件操作。然而,这又是很重要的一个特性,能够使得紧急的和对时间要求严格的任务及时完成,比如自动类的应用程序。
3.4.2 限制kernel/workgroup在GPU上的执行时间
有时候,一个计算任务的kernel函数可能会执行一段时间,或者可能会触发一个警告而导致GPU重启。为了避免这些不可预测的行为,并不建议kernel函数中有需要长时间才能完成的workgroup。通常情况下,在Android设备上,UI渲染经常发生,比如每30 ms,所以一个长时间运行的kernel可能会引起UI滞后或者没有响应,从而导致用户体验不好。理想的kernel执行时间是根据实际情况而定的。不过,一个比较好的通用准则是,一个kernel的执行时间应该在10ms的数量级上。
3.5 OpenCL 标准上的相关提升
Adreno A3x GPU支持OpenCL 1.1 的嵌入式版profile,Adreno A4x GPU支持OpenCL 1.2的完整版,Andreno A5x GPU上支持OpenCL 2.0 完整版。
从OpenCL 1.1 的嵌入式版profile到OpenCL 1.2的完整版,主要的改变是在软件上,而不是在硬件上,比如提升了API函数。
不过,从OpenCL 1.2 的完整版到OpenCL 2.0的完整版,引进了许多新的硬件特性,比如SVM(共享的虚拟内存),kernel-enqueue-kernel,等。表3-3 列出了3个Adreno系列的GPU上,在OpenCL支持上的不同点。
表3-3 在Adreno GPU上的支持的标准OpenCL的特性
|
特性 |
Adreno A3x支持的嵌入式OpenCL1.1 |
Adreno A4x 支持的完全OpenCL1.2 |
Adreno A5x支持的完整OpenCL2.0 |
|
分开编译和链接对象 |
不支持 |
不支持 |
支持 |
|
舍入模式 |
舍入为0 |
舍入到最接近的偶数 |
舍入到最接近的偶数 |
|
kernel中编译 |
不支持 |
支持 |
支持 |
|
1维的纹理,1维/2维的图片数组 |
不支持 |
不支持 |
支持(仅在合并获取时) |
|
共享虚拟内存 |
不支持 |
不支持 |
支持 |
|
管道 |
不支持 |
不支持 |
支持 |
|
转载/存储图像 |
不支持 |
不支持 |
支持 |
|
嵌套并行 |
不支持 |
不支持 |
支持 |
|
KEK(Kernel-enqueue-kernel) |
不支持 |
不支持 |
支持 |
|
通用内存空间 |
不支持 |
不支持 |
支持 |
|
C++ 原子操作 |
不支持 |
不支持 |
支持 |
3.6 OpenCL扩展
除了支持OpenCL的核心功能外,Adreno OpenCL平台还通过扩展支持许多额外的功能特性,从而能够进一步提高了OpenCL的可用性和能够充分使用Adreno GPU的先进的硬件能力。指定Adreno GPU上可用的扩展功能可以通过函数clGetPlatformInfo函数查询。扩展功能的文档可以在QTI开发者网页上获取。(网址 https://developer.qualcomm.com)
Qualcomm_Mobile_OpenCL.pdf 翻译-3的更多相关文章
- Qualcomm_Mobile_OpenCL.pdf 翻译-1
1 前言 1.1 目的 这篇文档的主要目的是,向原始设备制造商(OEMs),独立软件供应商(ISVs),第三方开发者们,提供在基于高通骁龙400系列.600系列,和800系列的手机平台和芯片上进行开发 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-2
2 Opencl的简介 这一章主要讨论Opencl标准中的关键概念和在手机平台上开发Opencl程序的基础知识.如果想知道关于Opencl更详细的知识,请查阅参考文献中的<The OpenCL ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-10-总结
这篇文档主要是介绍了关于在Adreno GPUs上优化OpenCL代码的详细方法.文档中提供的大量信息能够帮助开发者理解OpenCL基础和Adreno结构,还有最重要的,掌握OpenCL优化技能. O ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-9-OpenCL优化用例的学习
在这一章中,将会用一些例子来展示如何使用之前章节中讨论的技术来进行优化.除了一些小的简单代码片段的展示外,还有两个熟知的图像滤波处理,Epsilon滤波和Sobel滤波,将会使用之前章节中讨论的方法进 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-8-kernel性能优化
这章将会说明一些kernel优化的小技巧. 8.1 kernel合并或者拆分 一个复杂的应用程序可能包含很多步骤.对于OpenCL的移植性和优化,可能会问需要开发有多少个kernel.这个问题很难回答 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-7 内存性能优化
内存优化是最重要也是最有效的OpenCL性能优化技术.大量的应用程序是内存限制而不是计算限制.所以,掌握内存优化的方法是OpenCL优化的基础.在这章中,将会回顾OpenCL的内存模型,然后是最优的实 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-6-工作组尺寸的性能优化
对于许多kernels来说,工作组大小的调整会是一种简单有效的方法.这章将会介绍基于工作组大小的基础知识,比如如何获取工作组大小,为什么工作组大小非常重要,同时也会讨论关于最优工作组大小的选择和调整的 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-5-性能优化的概述
这章提供了一个OpenCL应用程序优化的总体概述.更多的细节将会在接下来的章节中找到. 注意:OpenCL程序的优化是具有挑战性的.相比初始的程序开发工作,经常需要做更多的工作. 5.1 性能移植性 ...
- Qualcomm_Mobile_OpenCL.pdf 翻译-4-Adreno OpenCL的程序开发
这章将简要讨论一些开发Adreno OpenCL应用程序的基本要求,下面将会介绍如何调试和统计程序性能. 4.1 安卓平台上开发OpenCL程序 目前,Adreno GPU主要是在安卓操作系统和在部 ...
随机推荐
- 只运行一个loop脚本
#!/bin/bash dir=$(dirname $(readlink -f "$0")) full=$(readlink -f "$0") name=$(b ...
- visual studio运行时库MT、MTd、MD、MDd
在开发window程序是经常会遇到编译好好的程序拿到另一台机器上面无法运行的情况,这一般是由于另一台机器上面没有安装响应的运行时库导致的,那么这个与编译选项MT.MTd.MD.MDd有什么关系呢?这是 ...
- awk 数值和字符串比较问题
在linux终端输入如下命令: > echo "10025350462330387914 10025350462330388480" | awk '{if ($1 == $2 ...
- 清空mysql数据
delete from 表名; truncate table 表名; 不带where参数的delete语句可以删除mysql表中所有内容,使用truncate table也可以清空mysql表中所有内 ...
- python安装的各种问题
在windows上安装python下载mis安装即可. 环境用elipse即可,需要下载pydev插件,配置解释器. 如需用到matplotlib,安装顺序为matplot,numpy,dateuti ...
- leetcode 118. Pascal's Triangle 、119. Pascal's Triangle II 、120. Triangle
118. Pascal's Triangle 第一种解法:比较麻烦 https://leetcode.com/problems/pascals-triangle/discuss/166279/cpp- ...
- 安装MySQL Enterprise Monitor
MySQL Enterprise Monitor是专门为MySQL数据库而设计的一款企业级监控,能非常好地与MySQL各方面特性相结合,包括:MySQL的关键性能指标.主机.磁 盘.备份.新特性相关以 ...
- Java学习之==>泛型
一.什么是泛型 泛型,即“参数化类型”,在不创建新的类型的情况下,通过泛型指定的不同类型来控制形参具体限制的类型.也就是说在泛型使用过程中,操作的数据类型被指定为一个参数,这种参数类型可以用在类.接口 ...
- zabbix 4.0版本
Zabbix 4.0 最高版本是4.2 1.什么是zabbix及优缺点(对比cacti和nagios) zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以让系统管理员快速 ...
- LeetCode.1029-两城调度(Two City Scheduling)
这是小川的第383次更新,第412篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第245题(顺位题号是1029).公司计划采访的人数为2N.将第i个人飞往城市A的费用是[ ...