Python修炼之路-函数
Python编程之函数
程序的三种方式
面向对象:类-------》class
面向过程:过程------》def
函数式编程:函数------》def
定义函数
函数:逻辑结构化与过程化的一种编程方法------》def
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
函数特性
遇到return就退出函数,并返回返回值
返回值数可以有多个,可以是函数、列表、数字、字符串等,用逗号“,”隔开,并且以tuple形式返回
返回值数=1:返回object;返回值数=0,返回None;返回值数=多个,返回一个tuple
函数与过程
定义过程,过程默认返回None;定义函数时,如果没有定义return,会返回None
#函数
def func1():
'''description''' #函数说明
print("in the func1")
return 0 #过程 没有返回值的函数
def func2():
'''description'''
print("in the func2") #过程是没有返回值的函数,在python中过程会默认返回None.
#过程加上return后不一定是函数式编程
import time
def logger():
time_format = '%Y-%M-%D-%X'
time_current = time.strftime(time_format)
with open('log.txt','a+') as f:
f.write("%s action\n" %time_current) #程序遇到return则退出,不会打印“test....”
def test1():
print("in the test1.")
return 0
print("test.....")
函数参数及调用
形参:不是实际存在,是虚拟变量,在定义函数和函数体时使用形参,目的是在调用函数时接受实参;形参只在函数内部有效,函数调用结束后不能再使用该变量。
实参:实际参数,调用函数时传递给函数的参数,可以是常量、变量、表达式、函数,传给形参
区别:形参是虚拟的,不占用内存空间,形参变量只有在被调用时才分配内存单元;实参是一个变量,占用内存空间,数据传递单向,实参传给形参;
位置参数,形参与实参一一对应,不能多不能少
关键字参数调用:与形参顺序无关,位置无需固定
def test(x,y)
print(x)
print(y) #位置参数
test(1,2) #1 2
#x,y形参(形式参数,本身不存在,如果不被调用则不占空间),1、2为实参 # 关键字参数用
x = 1
y = 2
test(x=x,y=y) #1 2
test(y=1,x=2) #2 1 #关键字参数不能写在位置参数前面
test(x=2,3) #运行出错
test(3,y=2) #3 2
test(3,x=2) #运行出错
默认参数的特点:调用函数时,默认参数非必须传递
用途: 1、默认软件安装值;2、默认连接端口
def test1(x,y=2):
print(x)
print(y) test1(1) #1 2
test1(1,3) #1 3
test1(1,y=3) # 1 3
参数组:实参数目不固定时使用
*args: 可以接受多个实参,并且放在一个元组中,只接受位置参数,装换成元组
**kwargs: 把n个关键字参数转换成字典的方式
def test2(*args):
print(args) test2(1,2,3,4,5) #(1,2,3,4,5)
test2(*[1,2,3,4]) #(1,2,3,4) 相当于tuple([1,2,3,4])
test2([1,2,3,4,5,6,7],*[1,2,3,4]) #([1, 2, 3, 4, 5, 6, 7], 1, 2, 3, 4) def test3(**kwargs):
print(kwargs) test3(name="aa",age = "",sex='F') #{name:'aa',age:'3',sex:'F'}
test3(**{'name':"aa",'age':2}) #可运行
各参数混合使用
def test4(name,**kwargs):
print(name)
print(kwargs) test4("a")
test4("a",11) #运行出错,传了两个位置参数
test4("a",age=1,sex='f')#可运行 def test5(name,age=18,**kwargs): #kwargs和默认参数位置不能更换
print(name)
print(age)
print(kwargs) test5("a",sex='f',age = 3)#可运行 def test6(name,age=18,*args,**kwargs):
print(name)
print(age)
print(args)
print(kwargs)
函数调用必须先定义,在调用,如果调用在定义之前,会出现找不到函数的error。
python解释器运行时,先解释def test7() => 然后调用test7(),此时还没有解释道test8,所以会报错。
下面这种情况会出错,应先定义test8,在使用test7。
def test7(name,**kwargs):
print(name)
print(kwargs)
test8()
test7("a",age=1,sex='f')#可运行
def test8():
pass
局部变量
只在函数里面生效,这个函数就是局部变量的作用域。
#name局部变量,这个函数就是这个变量的作用域
def change_name(name):
print("before change:",name) # A
name = "B"
print("after change:",name) # B name = "A"
change_name(name)
print(name) #A
全局变量
在整个代码的最前面定义的变量,作用全局。
shcool = "Old"
def change_name(name):
print("before change:",name) #A
name = "B" #name局部变量,这个函数就是这个变量的作用域
print("after change:",name) # B
print(shcool) #Old
name = "A"
change_name(name)
print(name) #A
局部变量和全局变量同名时,在定义局部变量的函数中,局部变量起作用,在其他地方,全局变量起作用。
函数默认,全局变量在局部变量不能修改,属于函数中局部变量。
school = "Old"
def change_name(name):
print("before change:",name)
name = "B" #name局部变量,这个函数就是这个变量的作用域
print("after change:",name)
school = "New" #相当于局部变量,屏蔽全局变量school
print(school) #New
print(school)
name = "A"
change_name(name)
print(name)
print(school) #Old
如果需要在函数中修改全局变量,则在函数中用global申明全局变量,即在函数中申明global school,不建议使用
也可以直接在函数中用global定义全局变量,效果等同于在代码最前面定义变量,但是不建议使用。
在函数中修改全局变量,随着函数来回调用,排错非常困难。
下面这种情况下可以修改,列表,字典,类等可以修改,但是字符串,整数,元组不能修改。
name = ['a','b','c']
def change_name():
name[0]="D"
print(name) #['D', 'b', 'c'] change_name()
print(name) #['D', 'b', 'c']
递归
在函数内部,可以调用其它函数,如果一个函数在内部调用自几本身,这个函数就是递归函数。
特性:必须有一个明确的结束条件;每次进入更深一层递归时,问题规模相比上次递归都应有所减少。递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
def fact(n):
if n == 1:
return 1
return n * fact(n-1)
尾递归
在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。
这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。但是Python不支持这种机制。
def fact_fri(n):
return fact_sec(n,1)
def fact_sec(x,y):
if x == 1:
return y
else:
return fact_sec(x-1, x*y)
函数式编程
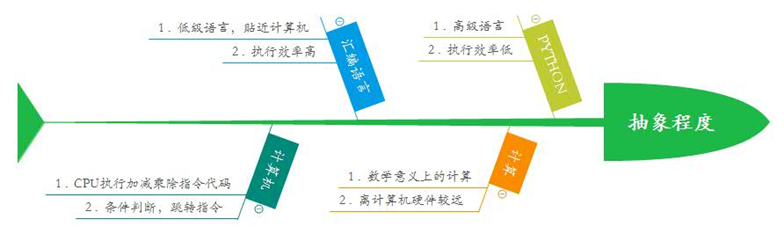
函数式编程是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。
函数式编程允许把函数本身作为参数传入另一个函数,还允许返回一个函数;Python对函数式编程提供部分支持,但Python不是纯函数式编程语言。
高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x, y, f):
return f(x) + f(y)
add(-5, 6, abs) #
内置函数
python内置函数

内置函数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
map函数
map函数,接收两个参数(函数和 Iterable),将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterable返回。

def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(r)) L = []
for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(n))
print(L)
#map函数作为高阶函数,事实上把运算规则抽象了,因此,还可以计算更复杂的函数,只需一行代码就能实现。
reduce函数
reduce函数,把一个函数(该函数必须接收两个参数)作用在一个序列[x1, x2, x3, ...]上,reduce把结果继续和序列的下一个元素做累积计算,结果为:
reduce(f, [x1, x2, x3, x4],initializer) = f(f(f(x1, x2), x3), x4)
函数参数含义如下:
1、function 需要带两个参数,1个是用于保存操作的结果,另一个是每次迭代的元素。
2、iterable 待迭代处理的集合
3、initializer 初始值,可以没有。
reduce函数的运作过程是,当调用reduce方法时:
1、如果存在initializer参数,会先从iterable中取出第一个元素值,然后initializer和元素值会传给function处理;接着再从iterable中取出第二个元素值,与function函数的返回值 再一起传给function处理,以此迭代处理完所有元素。最后一次处理的function返回值就是reduce函数的返回值。>
2、如果不存在initializer参数,会先从iterable中取出第一个元素值作为initializer值,然后以此从iterable取第二个元素及以后的元素进行处理。特殊情况下,如果集合只有一个元素,则无论function如何处理,reduce返回的都是第一个元素的值。
def f(x, y):
return x + y
reduce(f, [1, 3, 5, 7, 9], 100) #初始值为100,默认为
#计算初始值和第一个元素:f(100, 1),结果为101 from functools import reduce
def fn(x, y):
return x * 10 + y
reduce(fn, [1, 3, 5, 7, 9])
# from functools import reduce
def add(x, y):
return x + y
reduce(add, [1, 3, 5, 7, 9])
# #str to int
from functools import reduce
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return {'': 0, '': 1, '': 2, '': 3, '': 4, '': 5, '': 6, '': 7, '': 8, '': 9}[s]
return reduce(fn, map(char2num, s))
sorted函数
sorted函数,用于序列排序,可以接收一个key函数来实现自定义的排序,通过传入reverse=True实现反向排序。
key指定的函数将作用于list的每一个元素上,sorted()函数按照keys进行排序,并按照对应关系返回list相应的元素。
sorted([36, 5, -12, 9, -21], key=abs) #[5, 9, -12, -21, 36] list = [36, 5, -12, 9, -21]
keys = [36, 5, 12, 9, 21]
#keys排序结果 => [5, 9, 12, 21, 36]
#最终结果 => [5, 9, -12, -21, 36]
>>> sorted(['bob', 'about', 'Zoo', 'Credit'])
['Credit', 'Zoo', 'about', 'bob']
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)
['about', 'bob', 'Credit', 'Zoo‘]
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面行代码!
filter函数
filter函数,接收一个函数和一个序列,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。可以和匿名函数结合使用。
def is_palindrome(n):
s = str(n)
return s[::-1]==s and len(s) > 1
output = filter(is_palindrome, range(1, 1000))print(list(output))
实例
#abs(n)
#返回一个数的绝对值。参数可能是整数或浮点数。如果参数是一个复数,返回它的大小。 #all(iterable)
#返回True,如果iterable所有的元素为真(或者如果iterable为空),即只要不含有0返回都为真;
# print(all([-1,2])) #True
# print(all([0,1])) #False
# print(all([])) #True #any(iterable)
#返回True,如果iterable任何元素为真,即只要含有非零元素返回都为真;如果iterable为空,则返回False。
# print(any([0])) #False
# print(any([])) #False
# print(any([0,2])) #True #bool()
# print(bool([1,2]))#True
# print(bool([])) #False
# print(bool([0]))#True #bytearray()
#可以把字符串变成二进制数组的形式,并且可以修改,(区别字符串是不能修改的)
# a = bytes("abcde",encoding="utf-8")
# b= bytearray("abcde",encoding="utf-8")
# print( b[1] )
# b[1]= 101
# print(b) #callable(object)
#返回True,如果object可以被调用。函数和类可以被调用
# print(callable([1,2,3,4])) #False #chr(code)
#ord()
#返回一个字符,输入整数对应的ascii表;ord()相反
# print(chr(97)) #a
# print(ord("a")) #97 #compile(source, filename, mode[, flags[, dont_inherit]])
#相当于动态导入,把字符串变成可以执行的代码。
#参数source:字符串或者AST(Abstract Syntax Trees)对象。
#参数 filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值,可以为空。
#参数model:指定编译代码的种类。可以指定为 ‘exec’,’eval’,’single’。
# 如果是exec类型,表示这是一个序列语句,可以进行运行;
# 如果是eval类型,表示这是一个单一的表达式语句,可以用来计算相应的值出来;
# 如果是single类型,表示这是一个单一语句,采用交互模式执行,在这种情况下,如果是一个表达式,一般会输出结果,而不是打印为None输出。
#code = '''
# def fib(max): #10
# n, a, b = 0, 0, 1
# while n < max: #n<10
# #print(b)
# yield b
# a, b = b, a + b
# #a = b a =1, b=2, a=b , a=2,
# # b = a +b b = 2+2 = 4
# n = n + 1
# return '---done---'
# g = fib(6)
# while True:
# try:
# x = next(g)
# print('g:', x)
# except StopIteration as e:
# print('Generator return value:', e.value)
# break
#
# '''
#
# py_obj = compile(code,"err.log","exec") #通过compile把字符串变成可执行代码,使用exec执行
# exec(py_obj)
#
# exec(code) #也可以直接使用exec执行字符串 #dir(o)
#返回对象的一些方法
# a = [1,2,3]
# print(dir(a)) #divmod()
#商与余数
# print(divmod(5,2)) #(2, 1)
# print(divmod(4,2)) #(2, 0) #enumerate(Iterable)
#返回列表的索引与值
# L = ["a","b","c"]
# for index, key in enumerate(L):
# print(index,":",key)
# 0 : a
# 1 : b
# 2 : c #eval()
# 可以把list,tuple,dict和string相互转化。
# 字符串转换成列表
# a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
# type(a) # <type 'str'>
# b = eval(a)
# print (b) # [[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]]
# type(b) # <type 'list'>
# # 字符串转换成字典
# a = "{1: 'a', 2: 'b'}"
# type(a) # <type 'str'>
# b = eval(a)
# print (b) # {1: 'a', 2: 'b'}
# type(b) # <type 'dict'>
# # 字符串转换成元组
# a = "([1,2], [3,4], [5,6], [7,8], (9,0))"
# type(a) #<type 'str'>
# b = eval(a)
# print(b) # ([1, 2], [3, 4], [5, 6], [7, 8], (9, 0))
# type(b) # <type 'tuple'> #frozenset(iterable)
#把集合变为不可变的序列
a = frozenset([1,2,3,4]) #globals()
#以字典形式返回当前程序的所有全局变量(key)和变量值(vlaue)
#print(globals()) #locals()
#以字典形式返回当前程序的所有局部变量(key)和变量值(value) #hash(o)
#哈希,把输入的o转换成唯一的映射数字
# print(hash("abc")) #-5177290498696341306
# print(hash("abc"))#-5177290498696341306 #hex(i)
#把一个数字转换成16进制
#oct(i)
#把一个数字转换成8进制
#bin(x)
#将整数转换为二进制字符串前缀“0b”。 #round()
#设置浮点数精度,默认保留两位小数 #zip()
#按最小长度的序列拼接成元组
# a = [1,2,3,4]
# b = ["a","b","c","d"]
# for i in zip(a,b):
# print(i)
# (1, 'a')
# (2, 'b')
# (3, 'c')
# (4, 'd') #__import__()
#函数用于动态加载类和函数 。
# 如果一个模块经常变化就可以使用 __import__() 来动态载入,比如自己写的一个模块a.py,可以通过这种方式导入。
# 同import语句同样的功能,但__import__是一个函数,并且只接收字符串作为参数,所以它的作用就可想而知了。
# 其实import语句就是调用这个函数进行导入工作的,import sys <==>sys = __import__('sys')
#__import__('decorator')
#相当于import decorator #print()
# msg = "又回到最初的起点"
# f = open("1111","w",encoding="utf-8")
# print(msg,"记忆中你青涩的脸",sep="|",end="",file=f)
# #又回到最初的起点|记忆中你青涩的脸 以这个形式写入文件1111中。 #slice
#切片处理
# a = range(20)
# pattern = slice(3,8,2)
# for i in a[pattern]: #等于a[3:8:2]
# print(i) #3 5 7
返回函数
一个函数可以返回一个计算结果,也可以返回一个函数,返回函数并未执行。
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum f1 = lazy_sum(1,3,5,7,9) #返回一个新的函数f1
f2 = lazy_sum(1,3,5,7,9) #返回一个新的函数f2
print f1 == f2
# False
# lazy_sum()每调用一次,都会返回一个新的函数(一个独一无二的函数地址)。 print(f1(),f2)
#25 <function lazy_sum.<locals>.sum at 0x0000000000B09E18>
#在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量;
#当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种程序结构称为闭包。
#返回的函数在其定义内部引用了局部变量args,所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数引用。 #返回函数不要引用任何循环变量,或者后续会发生变化的变量。
def f():
fs = []
for i in range(1,4):
def g():
return i*i
fs.append(g)
return fs
f1,f2,f3 = f()
print(f1(),f2(),f3()) # 9 9 9
#返回函数中保存的是循环变量i,当调用函数时,i=3 #修改后的程序
#再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变。
def count():
fs = []
def lazy_sum(i):
def f():
return i*i
return f
for i in range(1,4):
fs.append(lazy_sum(i))
return fs
f1,f2,f3 = count()
print(f1,f2,f3) #1 4 9
匿名函数
python对匿名函数提供了有限的支持,关键字lambda表示匿名函数,冒号前的字符表示函数的参数,返回值就是表达式(只能有一个表达式)的结果。
匿名函数调用,可以把匿名函数赋值给一个变量f,通过f(*args)传参,也可以通过括号(lambda.....)(*args)
def f():
return x*x lambda x : x*x
lambda : x*x
lambda : x*x
Python修炼之路-函数的更多相关文章
- Python学习之路——函数
一.Python2.X内置函数表: 注:以上为pyton2.X内置函数,官方网址:https://docs.python.org/2/library/functions.html 二.Python3. ...
- Python学习之路——函数对象作用域名称空间
一.函数对象 # 函数名就是存放了函数的内存地址,存放了内存地址的变量都是对象,即 函数名 就是 函数对象 # 函数对象的应用 # 1 可以直接被引用 fn = cp_fn # 2 可以当作函数参数传 ...
- python修炼之路——控制语句
Python编程之print python2.x和python3.x的print函数区别:python3.x的print函数需要加括号(),python2.x可以不加. #-*- coding:utf ...
- Python修炼之路-数据类型
Python编程之列表 列表是一个使用一对中括号"[ ]" 括起来的有序的集合,可以通过索引访问列表元素,也可以增加和删除元素. 列表的索引:第一个元素索引为0,最后一个元素索 ...
- Python修炼之路-模块
模块 模块与包 模块:用来从逻辑上组织python代码(可以定义变量.函数.类.逻辑:实现一个功能),本质就是.py结尾的python文件. 例如,文件名:test.py,对应的模块名为:test 包 ...
- python修炼之路---面向对象
面向对象编程 面向对象编程:使用类和对象实现一类功能. 类与对象 类:类就是一个模板,模板里可以包含多个函数,函数里实现一些功能. 对象:是根据模板创建的实例,通过实例对象可以执行类中的函数. 面向对 ...
- Python修炼之路-装饰器、生成器、迭代器
装饰器 本质:是函数,用来装饰其他函数,也就是为其他函数添加附加功能. 使用情景 1.不能修改被装饰的函数的源代码: 2.不能修改被装饰的函数的调用方式. 在这两种条件下,为函数添加附加 ...
- Python学习之路——函数的参数分类
今日内容 '''实参:调用函数,在括号内传入的实际值,值可以为常量.变量.表达式或三者的组合*****形参:定义函数,在括号内声明的变量名,用来接受外界传来的值''''''注:形参随着函数的调用 ...
- Python修炼之路-异常
异常处理 在程序出现bug时一般不会将错误信息直接显示给用户,而是可以自定义显示内容或处理. 常见异常 AttributeError # 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性 ...
随机推荐
- Spring Cloud负载均衡:使用zuul作服务器端负载均衡
1.目的: 本文简述Spring Cloud负载均衡之服务器负载均衡模式,使用组件为zuul. zuul作为Spring Cloud中的网关组件,负责路由转发.身份验证.请求过滤等等功能,那么我们可以 ...
- JavaScript中二进制与10进制互相转换
webpack打包生成的代码中涉及了一些二进制位与的操作, 所以今天来学习一下JavaScript中的二进制与十进制转换操作吧 十进制转二进制: var num = 100 num.toString( ...
- 【疑难杂症】new Date() 造成的线程阻塞问题
代码如下 package com.learn.concurrent.probolem; import java.util.Date; import java.util.concurrent.Count ...
- [SHOI2009] 舞会
OItown要举办了一年一度的超级舞会了,作为主办方的Constantine为了使今年的舞会规模空前,他邀请了许多他的好友和同学去.舞会那天,恰好来了n个男生n个女生.Constantine发现,一般 ...
- 软件设计分为结构化设计(SD)
软件设计分为结构化设计(SD)与面向对象设计(OOD). 其中结构化设计SD是一种面向数据流的方法,它以SRS(软件需求规格说明书)和SA(结构化分析)阶段所产生的和数据字典等文档为基础,是一个自顶向 ...
- [Python3] 025 包
目录 1. 模块 1.1 模块是什么? 1.2 为什么用模块? 1.3 如何定义模块? 1.4 如何使用模块? 1.4.1 例子1 1.4.2 例子2 1.4.3 例子3 1.4.4 例子4 1.4. ...
- node项目自动化部署--基于Jenkins,Docker,Github(2)配置节点
上一篇文章中准备工作已经完成的差不多了 这一篇主要讲解 Jenkins 上面的相关配置 为了让代码部署到所有的子节点上 所以我们首先需要在 Jenkins 中添加我们希望代码部署到的节点 配置节点 首 ...
- python笔记——dict和set
学习廖雪峰python3笔记_dict和set dict__介绍 dict --> dictionary(字典)--> python内置 --> 使用键-值(key-value)存储 ...
- TCP协议的粘包现象和解决方法
# 粘包现象 # serverimport socket sk = socket.socket()sk.bind(('127.0.0.1', 8005))sk.listen() conn, addr ...
- tarjan算法求无向图的桥、边双连通分量并缩点
// tarjan算法求无向图的桥.边双连通分量并缩点 #include<iostream> #include<cstdio> #include<cstring> ...