趣头条基于 Flink 的实时平台建设实践
本文由趣头条实时平台负责人席建刚分享趣头条实时平台的建设,整理者叶里君。文章将从平台的架构、Flink 现状,Flink 应用以及未来计划四部分分享。
一.平台架构
1.Flink 应用时间线
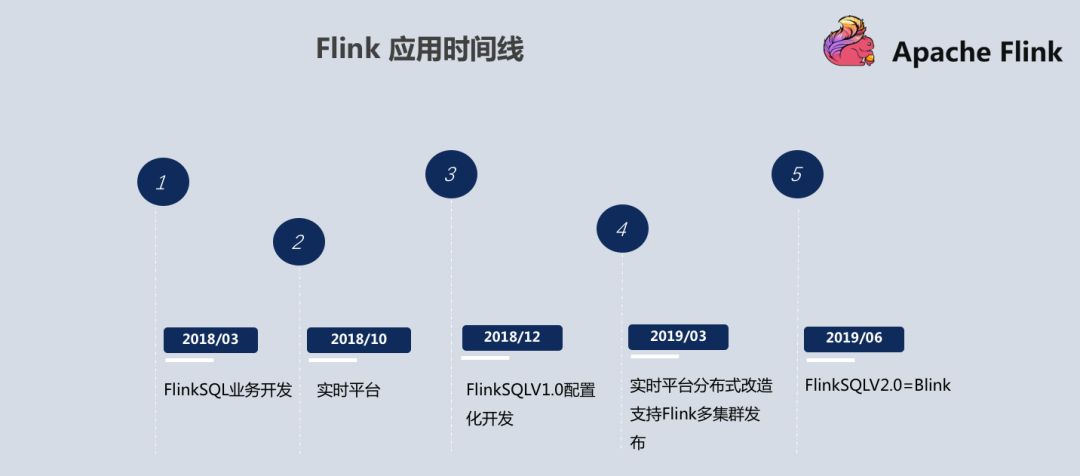
首先是平台的架构,2018 年 3 月之前基本都是基于 Storm 和 Spark Streaming 来做的。目前,基本已经把 Spark Streaming 和 Storm 淘汰了,主要都是 Flink SQL 来做的。起初还比较传统,一般是接需求然后开发类似于 Flink SQL 的任务,基本是手工作坊操作模式。
后来 Flink SQL 的任务逐渐多了起来,就开始考虑往平台化方向发展。大概在 2018 年 10 月份,我们开始搭建实时平台。当时设计实时平台时就直接抛弃了 Spark Streaming 和 Storm,基础理念设计的时候,主要以 Flink 场景来设计平台。趣头条实时平台上线将近两个月后,当时任务量并不多,由于趣头条基本都是 PHP 和 Golang 开发语言,而Flink更偏向于 Java 包括它 API 的提供,所以经常会接到用户需求,如: Golang 能不能开发, PHP 能不能开发?
这个问题听起来比较奇怪,但是对于不会用并且确实也想用的用户,就需要想办法解决这个问题。后来我们做了一版类似于 Flink SQL 配置化开发,可以让用户不用写Flink 代码,初衷是考虑到操作门槛如果相对高,那么 Flink 在趣头条的应用推进就不会这么顺畅。这也是 1.0 的配置开发诞生的背景。
在以上三件事情完成后,这个平台基本就能提供给有开发能力的同学开发一些 Flink 任务,同时类似于分析师、优秀的产品等没有开发能力的的同学也知道 Flink,他们更关心每天曲线的变化,可以根据数据对一些产品做相应的策略调整,能够自己配比较简单的 SQL 化任务。
在此之后,平台任务逐渐增多,就开始做实时平台的分布式,包括多集群。单集群因为部分部门的任务要求较高,至少要达到三个九的标准,所以当时设计的时候就考虑到要支持 Flink 多集群,后期比如说 A 集群故障了,可以让用户立马切到B集群发布,两集群保持互通,底层 Checkpoint 是可以实时同步的。
到了 19 年 6 月份,1.0 配置化开发的方案不是更抽象的,或者说不是 Flink 工程化的结构,后来也参考 Flink 的开源分支 Blink 并参考 Blink 自己实现了一版类似于 Blink 的方案,之后基本在配置化开发这一块可以推广给代码开发的同学,因为他们可能对 Source 的源跟 Sink 源,包括一些数据中间环节的处理流程,比产品和分析师稍微了解的相对较多。
2.集群及任务量

这个是目前集群的规模,CPC 集群差不多是 30 个节点,采用了 Flink on Yarn 的这种模式,这个是独立的计费集群,会有一些广告商的点击计费统计。当时这个定的时候,会是由两个集群去跑两个任务,类似于 HA,它可以在应用层面去做降级。比如说集群挂了,它还可以在另外公共集群也会有任务。这样的话就是说如果出问题,至少不会两个集群同时出问题,这种概率应该是比较小。
公共集群现在是 200 多个节点,到今年 10 月左右,节点数可能会增至 400 到 500 个左右。目前 Kafka 也是有多副本集群的,后续 Kafka 的数据流的转换,也是通过 Flink 去实现可配置化的方式数据导流,比如 Kafka 是公司数据流的核心的链路之一,如果出问题的话会导致整个影响所有的依赖于上下游这种数据消费。目前 Kafka 那边会有多副本集群这种概念,那 Flink 在中间扮演的就是我可以把这个数据流实时的同步到不同的集群去做,类似于做容灾的方案。
3.数据流架构
公共集群 Flink 的任务目前是 200 多,然后 CPC 是十多个任务,下面为数据流结构数据源基本来自于手机端 H5 还有服务端。然后中间会有一层 Log Server 这个是公司自己开发的,全部打到了 Log Server 之后,Log Server 会打到 Kafka,Kafka 也是多链路,有主副本集群这种概念,中间环节在之前是有 storm 和 spark,目前 100% 都是 Flink。
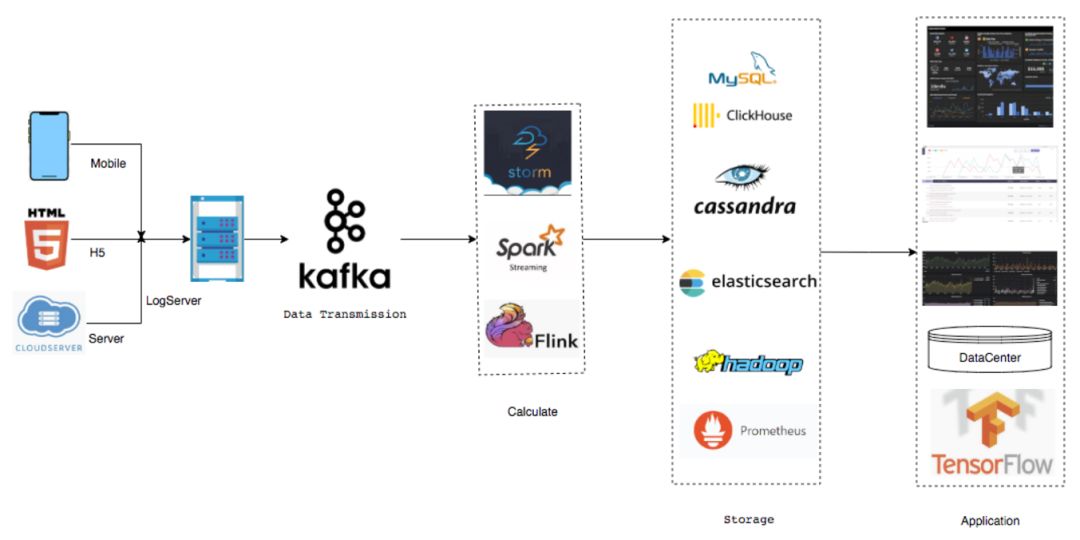
接下来就是 Sink 出来以后的数据,目前用的种类还是挺多的,包括 MySQL, Clickhouse,Cassandra, Elasticsearch 包括也会落部分 Hadoop 到 HDFS 还有 Prometheus。再往后主要是基于后续落的数据做了一些类似于企业级的应用,最上面 Dashboard 是大屏,一般是用来显示数据流的大屏。第二个是基础部门的性能指标。
最下面是数据入库,下面是机器学习使用,目前 TensorFlow 基本是通过 Flink 拼接样本清洗一些数据,然后落一些 TensorFlow 的数据结构出来,再通过 TensorFlow 做机器学习的训练。
4.平台架构
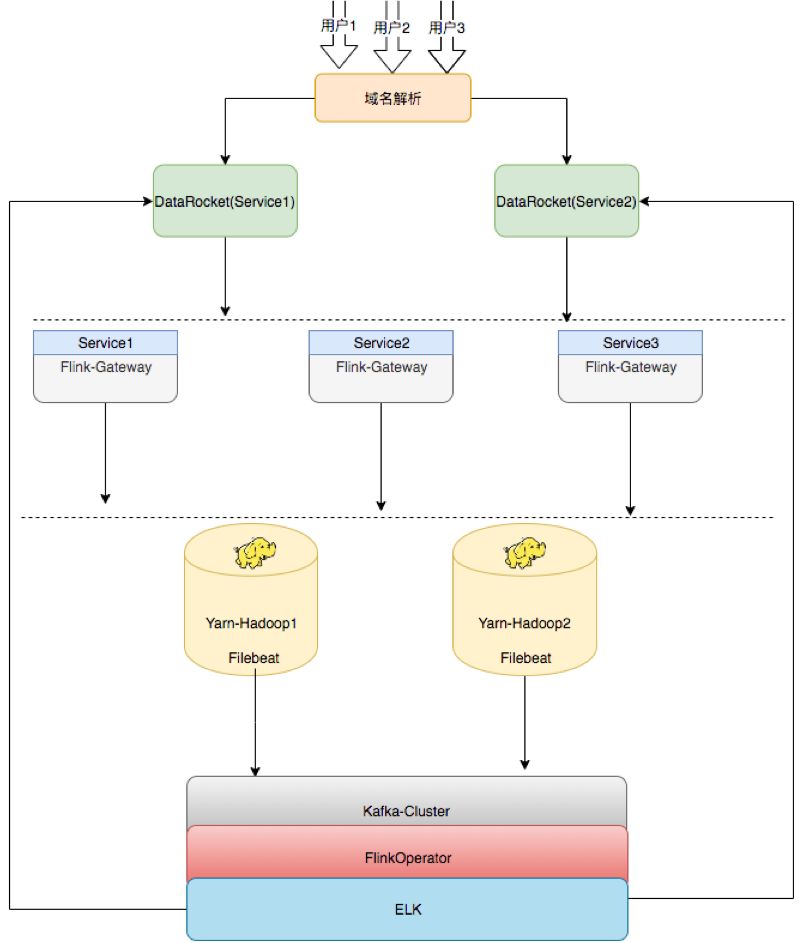
以上为趣头条的平台架构,之前也是单节点,只能做集群的任务发布,目前改造成提供给用户的 HA 架构,中间开发一层类似于发布机器的概念,上面部了 Flink Gateway 即每集群在同样的 Gateway 上是可以随意切换的,比如说 Server 1,Server 2,Server 3,三个环境是一样的,后续如果需要扩容,也只需要去扩 Flink Gateway,同样的再去部署一套就行了。
再下面 Flink Gateway 可以往 Hadoop 集群上发,比如目前用的是 Hadoop Yarn,是两个集群,即 Gateway 可以任意切换到这两个集群发布任务。后续就是通过Filebeat将任务所有运行的记录及日志收集上来。收集完成之后也有基于Flink开发的通用日志统计和分析的工具,将数据落到ELK(Elasticsearch + Logstash + Kibana,以下简称 ELK)里,然后提供给用户。比如,用户任务上线之后可能会出现一些异常,包括统计等都会接到ELK里面,由 ELK 提供可视化的界面,这个就是平台的架构。
二.Flink 应用
1.应用场景

第二部分就是 Flink 目前在基分的应用,除了趣头条,米读、米读极速版跟萌推目前这些产品包括数据流的统计,数据中间处理环节,基本已经换到 Flink 来了,支撑整个集团的产品。业务场景大概主要是计费、监控、仓库,画像包括算法、内容线六部分。
- 计费主要是算广告商接入的计费成本,跟他们进行结算。每次广告点击完成后,每个月可能会有类似于离线报表,目前如果需要切换成实时,基本只需要点击,就会产生扣费环节,这个算是非常核心的任务。
- 监控有各种,比如说机器层面的,应用层面的。
- 仓库目前基本是批量落数据,比如说五分钟、十分钟,类似于窗口的间隔时间去落数据
- 画像即将用户画像的一些数据通过 Flink 清洗,完成之后会落到 HDFS 上,用来做训练。
- 算法目前除了用户画像,还有推荐,目前的 APP 打开之后会给不同用户推荐不同的内容。
- 内容线目前做的是风控,可能有一些用户知道 APP 会去刷金币,比如说打开某个内容之后,不看内容而可能是在后台跑一百多个程序刷金币,目前通过 Flink 可以做到实时风控,能实时识别出某台设备究竟是不是真正的用户,如果不是,就会将其屏蔽掉。
2.用户声音
- Flink 能用 Python/Golang 开发吗?
- Flink 好学吗?
- 我就会 SQL 可以用吗?
- 有没有更简单的方式?
以上四个问题是目前接触到的公司内部用户在 Flink 应用时经常会提到的,包括最初去推实时平台时,可能很多人都会问 Flink 怎么用、能否用 Python 或者 Golang 进行开发,或者仅会 SQL 不会写代码也想用等。
Flink 究竟好不好用?给业务线培养 Flink 的开发人员所面临情况在于部分业务线确实知道 Flink,但是没有 Java 的背景,语言上主要写 Golang,或者每个月需要对产品进行一些策略的调整,但如果没有数据去看,基本就是摸黑的,无法评估策略调完之后可能会给产品带来什么样的影响。
3.解决方案
针对以上问题,我们也拿出了解决方案。在第一版的时候,用户只需要写 SQL,即会有类似于内存里的宽表,Flink 把从 Kafka 消费过来的数据抽象成内存的一张表,用户只需要打开如下界面根据自己的逻辑去写自定义 SQL,就可以提供给产品和分析师,包括其他想用平台的用户。有了这个解决方案之后,其他用户就可以通过简单的方式来体验到 Flink 带来便捷。
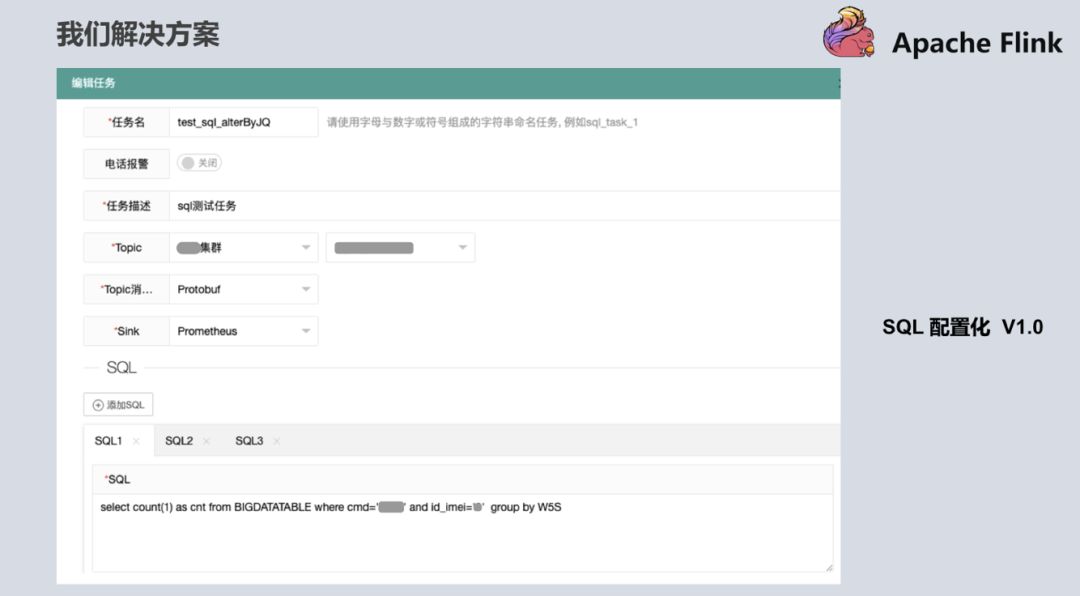
SQL 配置化 1.0 版本中 SQL 是有限制的,测试显示如果提供给用户写的 SQL 越来越多,Checkpoint 的压力,与 distinct 的这种计算结果会带来数据倾斜的这种压力,导致任务可能会失败,所以在设计 SQL 代码量时有一定的限制,不会让用户无休止的加 SQL,基本目前限制是 10 个。在 1.0 版本上线之后,刚好 Blink 开源出来了,我们知道 1.0 方案还是不够优雅(从工程化看),又参考 Flink 和开源出来的 Blink 方案,升级到了第二版,可以更大化的提供用户自定义的方式,也可以把数据源抽象出来,数据源就不仅仅是 Kafka 了,很大程度上改善了原来 1.0 的版本。当所有的数据来了之后先到 Kafka,目前数据源可以支持 HDFS、MySQL、MQ 等,只需要创建 Source 源的概念。下面是平台较详细的截图,基本是输入,输出以及统计逻辑。
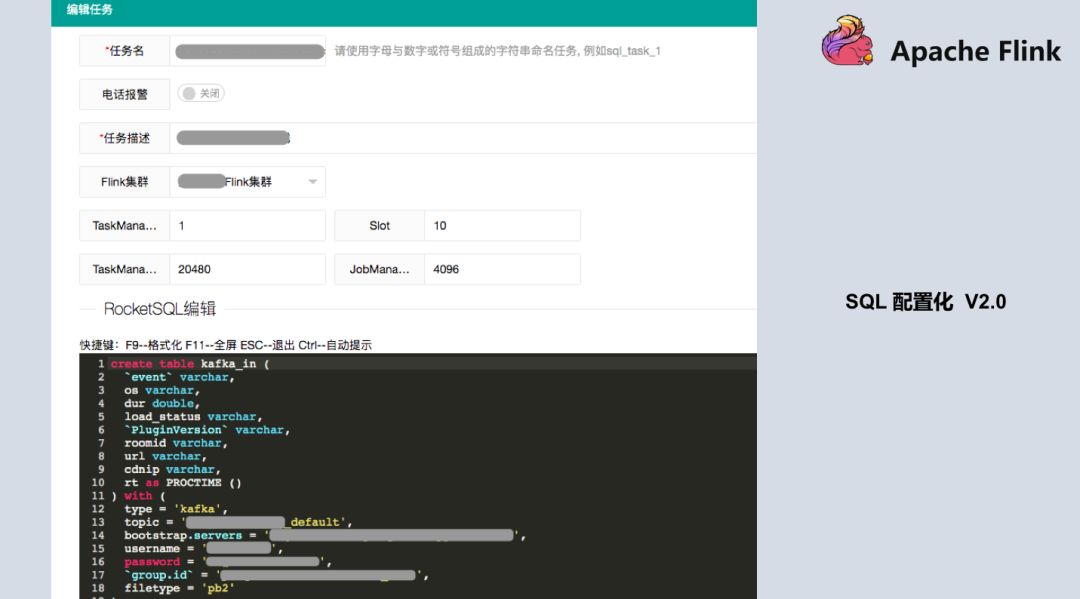
目前跟 Blink 基本如出一辙,也是参考了 Blink 的一些设计思路和方法。这个功能已经上线,基本有五、六十个任务已经在用了,用户对当前的平台还是比较满意的。不过更期望写 SQL 基本就能完成统计指标,这也是实时平台后续想要去做的(尽可能的再去屏蔽一些资源设置比如:tm/slot 一般用户不太懂)。

三.现状
第三部分是想分享一下趣头条实时平台的现状,目前 Flink 1.9 版本已经出来了,我们在测 Flink 1.9 的新特性,Flink 对 Python 的支持是非常惊喜的,内部很多用户还是比较喜欢脚本式语言的,而 Python 的开发是写脚本式语言,就能提交 Flink 任务,这是我们当前测试内容的一部分。另一部分是 Flink 模板简化,上面提到的 2.0 模板,让用户写一大堆的 SQL,还是比较麻烦的,用户还是更倾向于统计逻辑的简单 SQL。我们最终的目标还是想把 Flink 推广到整个集团公司,让更多的受众参与进来享受 Flink 带来的好处。
最后一块是 Flink SQL 的 HDFS 落库,目前这个功能开发完了,目标是将 Kafka 出来的数据做类似的实时仓库,即数据可以实时落到 HDFS 上,而上一个版本是通过 Flink 开发,基本是按时间窗口去落的还不是实时的。
四.未来计划

首先,版本升级,趣头条的实时平台目前用的是 Flink 1.7,后续是想往 1.9 版本去切,Flink 1.9 版本提供的 Task Fault Tolerance 的容错、Checkpoint 的容错等很好的修复了 1.7 版本中存在的问题。
第二,实时仓库,趣头条当前用到的 Flink 按时间窗口落可能数据也不是实时的,后续想让它做到类似于秒级数据流入,体大提升仓库服务数据能力。
第三,平台智能诊断,当前工作中更大一部分时间是在解答用户问题,用户在使用中出现的各种报错无法自行解决,需要平台提供技术上的支持,这部分其实比较影响平台规划的目标方向的进度,因此后面想开发平台智能诊断。常见的报错和最佳实践都归纳下来集成到平台中。出现问题时能够自动诊断识别推荐给用户解决方案。
第四,Flink 弹性式资源计算,这是目前面临的比较重要的问题。目前 300 多个任务,集群的规模增长也比较迅猛,大约每周将近 20 台机器的扩容速度,后续的资源利用率也是非常重要的。目前我了解 Flink 社区是没有类似于这种弹性式资源计算,也期待社区能解决这类问题。比如:Flink 任务起来之后,可能业务方已经将流已经停掉了,如果用户不去看这个任务,其实他还是在跑。最终内存、资源还是被占着,没有释放。
最后是 Flink 机器学习实践。目前机器学习平台基本用的还是批训练,后续还是想去做一些尝试 Demo 方案,提供给机器学习团队,争取他们可以后续往 Flink 方向切换。
本文作者:巴蜀真人
本文为云栖社区原创内容,未经允许不得转载。
趣头条基于 Flink 的实时平台建设实践的更多相关文章
- 阿里PB级Kubernetes日志平台建设实践
干货分享 | 阿里PB级Kubernetes日志平台建设实践https://www.infoq.cn/article/HiIxh-8o0Lm4b3DWKvph 日志最主要的采集工具是 Agent,在 ...
- 轻装上阵Flink--在IDEA上开发基于Flink的实时数据流程序
前言 本文介绍如何在IDEA上快速开发基于Flink框架的DataStream程序.先直接上手! 环境清单 案例是在win7运行.安装VirtualBox,在VirtualBox上安装Centos操作 ...
- Kubernetes容器云平台建设实践
[51CTO.com原创稿件]Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署.大规模可伸缩.应用容器化管理.伴随着云原生技术的迅速崛起,如今Kubernetes 事实上已经 ...
- [平台建设] HBase平台建设实践
背景 由于公司业务场景的需要,我们需要开发HBase平台,主要需要以下功能: 建表管理 授权管理 SDK实现 与公司内部系统打通 我们使用的HBase 版本: HBase 1.2.0-cdh5.16. ...
- TOP100summit 2017:【案例分享】魅族持续交付平台建设实践
本篇文章内容来自第10期魅族开放日魅族运维架构师林钟洪的现场分享.编辑:Cynthia 一.自动化建设历程1.1 魅族互联网发展的时间线 2003-2008年被称之为“互联网1.0时代”.2003年, ...
- 腾讯基于 Flink 的实时流计算平台演进之路
https://mp.weixin.qq.com/s/MGnG_Mpf6CUQWLJHvmWqLA
- 基于Docker持续交付平台建设的实践
导读:中国五矿和阿里巴巴联手打造的钢铁服务专业平台五阿哥,通过集结阿里巴巴在大数据.电商平台和互联网产品技术上的优势,为终端用户带来一站式采购体验.本文是五阿哥运维技术团队针对Docker容器技术在如 ...
- Unity跨平台C/CPP动态库编译---可靠UDP网络库kcp基于CMake的各平台构建实践
1.为什么需要动态库 a)提供原生代码(native code)的支持,也叫原生插件,但是我实践的是c/cpp跨平台动态库,这里不具体涉及安卓平台java库和ios平台的objectc库构建. b)某 ...
- Unity3D跨平台动态库编译---记kcp基于CMake的各平台构建实践
一 为什么需要动态库 1)提供原生代码(native code)的支持,也叫原生插件,但是我实践的是c/cpp跨平台动态库,这里不具体涉及安卓平台java库和ios平台的objectc库构建. 2)某 ...
随机推荐
- 连接超时(connect timed out)和读取超时(Read timed out)
设置连接超时和读取超时方法: RequestConfig config=RequestConfig.custom() .setConnectTimeout(10000) // 设置连接超时时间 10秒 ...
- PHP安装-centos7
下载地址:https://www.php.net/downloads.php 1.wget下载php源码至/usr/local/src 下 wget https://www.php.net/distr ...
- Discuz升级 Database Error : pre_common_syscache ADD PRIMARY KEY (cname)【解决办法】
错误码: 1068Multiple primary key defined Execution Time : 00:00:00:000Transfer Time : 00:00:00:000Total ...
- Java thread(2)
这一块主要是从Thread类源码的角度来分析两种线程的实现方式,这里分析的也仅仅是最基本的部分. 就从线程的启动函数 start方法开始分析 只是分析最主要的部分 在start()方法中,除了grou ...
- php优化方法
代码优化是开发程序和网站必不可少的一步,代码优化好了,可以大大增加程序的运行效率.使网站或程序加载反应更快.用户体验也就会更好.下面就为大家总结了50条PHP代码优化技巧. 1. 用单引号代替双引号来 ...
- 【洛谷新手村】简单字符串 p1055 ISBN号码
p1055 ISBN号码[传送门] 算法标签什么的: 思路:直接以字符串的形式读入这一串数字,然后for循环对字符串进行处理,字符串中的数字存进数组中(如果是X,存为10):然后再根据要求判断是否是正 ...
- kmp(暴力匹配)
http://poj.org/problem?id=3080 Blue Jeans Time Limit: 1000MS Memory Limit: 65536K Total Submission ...
- SVN合并主干分支的方法
第一步 第二步 第三步 第四步
- Linux笔记1-简介
以下为观看兄弟连视频教程所记. 1.简介 1965年,MIT.GE.AT&T的贝尔实验室 --> Multics 分时.庞大 1969年,贝尔实验室的肯·汤普森 --> Unix ...
- 【知识强化】第三章 存储系统 3.4 主存储器与CPU的连接
我们这节课来看一下关于主存的一些知识.我们将要讲解主存的简单的模型和主存与CPU连接的连接原理. 我们之前呢在第一章已经学过了存储器的构成,包括了存储体.MAR(也就是地址寄存器).MDR(也就是数据 ...