【CDN+】 Hive 入门 以及Handoop 系统认知
前言
本文主要介绍Hive 的基础概念,以及Handoop的大体架构,组件依赖,对于大数据有个总体的认识
Hive 基础概念
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Apache Hive™数据仓库软件支持使用SQL读取、写入和管理分布存储中的大型数据集。结构可以映射到存储中的数据。提供了一个命令行工具和JDBC驱动程序来将用户连接到Hive。
Hive的 特点:
- Hive是一个构建于Hadoop顶层的数据仓库工具,可以查询和管理PB级别的分布式数据。
- 支持大规模数据存储、分析,具有良好的可扩展性
- 某种程度上可以看作是用户编程接口,本身不存储和处理数据。
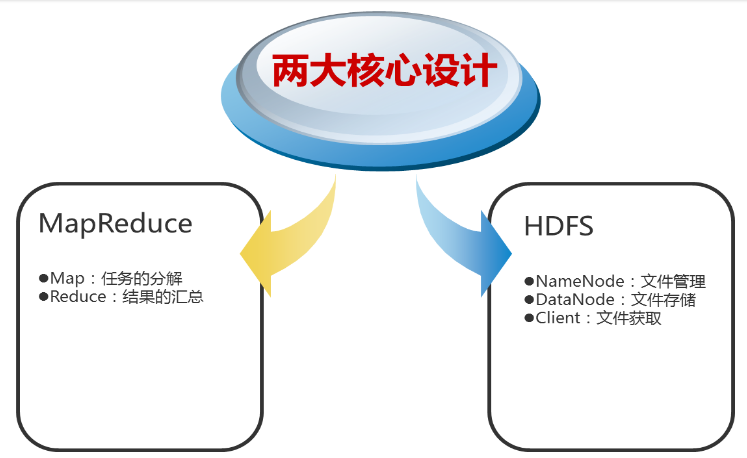
- 依赖分布式文件系统HDFS存储数据。
- 依赖分布式并行计算模型MapReduce处理数据。
- 定义了简单的类似SQL 的查询语言——HiveQL。
- 用户可以通过编写的HiveQL语句运行MapReduce任务。
- 可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上。
- 是一个可以提供有效、合理、直观组织和使用数据的分析工具。
Hive应用场景:
- 数据挖掘:用户行为分析;兴趣分区;区域展示;
- 非实时分析:日志分析;文本分析。
- 数据汇总:每天/每周用户点击数,流量统计。
- 数据仓库:数据抽取,加载,转换(ETL)。
思考: Hive 其实不是一个数据库或者数据存储系统,而且是一个数据工具,主要是将SQL语句转化为MapReduce任务执行。
Hive 的结构
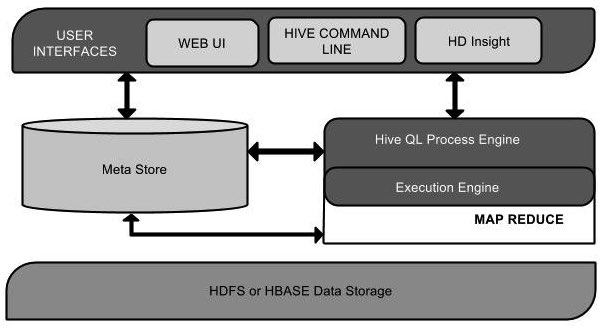
该组件图包含不同的单元。下表描述每个单元:
| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
Hive的工作原理
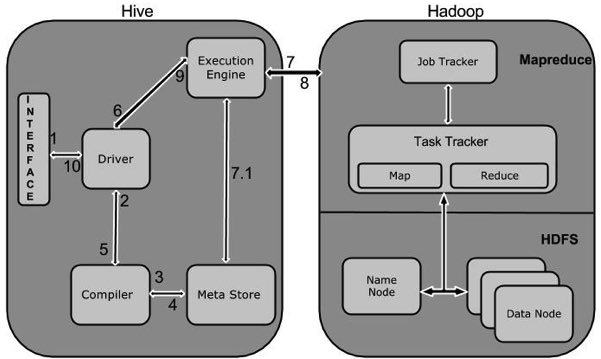
下表定义Hive和Hadoop框架的交互方式:
| Step No. | 操作 |
|---|---|
| 1 | Execute Query
Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 |
| 2 | Get Plan
在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。 |
| 3 | Get Metadata
编译器发送元数据请求到Metastore(任何数据库)。 |
| 4 | Send Metadata
Metastore发送元数据,以编译器的响应。 |
| 5 | Send Plan
编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 |
| 6 | Execute Plan
驱动程序发送的执行计划到执行引擎。 |
| 7 | Execute Job
在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。 |
| 7.1 | Metadata Ops
与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 |
| 8 | Fetch Result
执行引擎接收来自数据节点的结果。 |
| 9 | Send Results
执行引擎发送这些结果值给驱动程序。 |
| 10 | Send Results
驱动程序将结果发送给Hive接口。 |
Handoop 的结构

(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
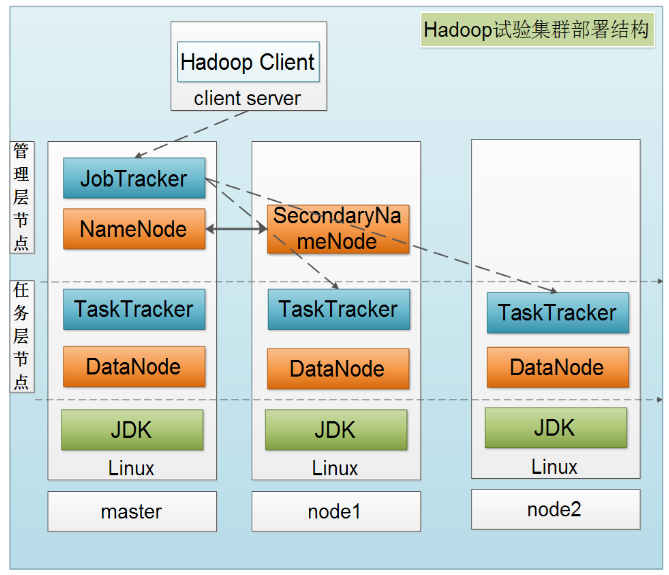
Handoop 集群部署
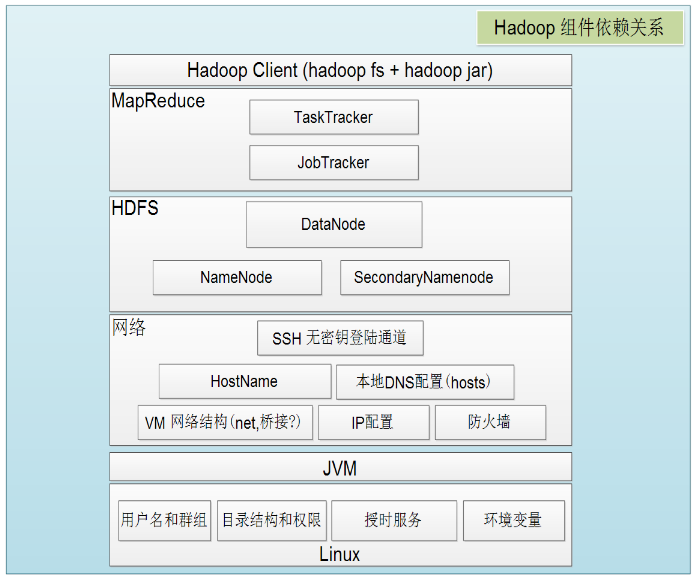
Handoop 组件依赖关系
Handoop的核心

参考资料:
https://blog.csdn.net/zl834205311/article/details/80334346
https://www.cnblogs.com/tieandxiao/p/8799287.html
https://www.jianshu.com/p/d68272609bf8
【CDN+】 Hive 入门 以及Handoop 系统认知的更多相关文章
- hadoop笔记之Hive入门(什么是Hive)
Hive入门(一) Hive入门(一) 什么是Hive? Hive是个数据仓库,数据仓库就是数据库,但又与一般意义上的数据库有点区别 实际上,Hive是构建在hadoop HDFS上的一个数据仓库. ...
- 4 weekend110的hive入门
查看企业公认的最新稳定版本: https://archive.apache.org/dist/ Hive和HBase都很重要,当然啦,各自也有自己的替代品. 在公司里,SQL有局限,大部 ...
- hadoop笔记之Hive入门(Hive的体系结构)
Hive入门(二) Hive入门(二) Hive的体系结构 ○ Hive的元数据 Hive将元数据存储在数据库中(metastore),支持mysql.derby.oracle等数据库,Hive默认是 ...
- Sqoop与HDFS、Hive、Hbase等系统的数据同步操作
Sqoop与HDFS结合 下面我们结合 HDFS,介绍 Sqoop 从关系型数据库的导入和导出. Sqoop import 它的功能是将数据从关系型数据库导入 HDFS 中,其流程图如下所示. 我们来 ...
- 从0到1搭建基于Kafka、Flume和Hive的海量数据分析系统(一)数据收集应用
大数据时代,一大技术特征是对海量数据采集.存储和分析的多组件解决方案.而其中对来自于传感器.APP的SDK和各类互联网应用的原生日志数据的采集存储则是基本中的基本.本系列文章将从0到1,概述一下搭建基 ...
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- 数据、模型、IT系统认知
数据.模型.IT系统认知 量化投资定义 量化投资主要是指通过数理模型来实现投资理念,由计算机产生交易策略的一种投资方法. 量化投资是一种方法论,而不是具体的交易策略. 通常与基本面.技术面分析相结合. ...
- 第1章 Hive入门
第1章 Hive入门 1.1 什么是Hive Hive:由Facebook开源用于解决海量结构化日志的数据统计. Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提 ...
- 前端学习 node 快速入门 系列 —— 报名系统 - [express]
其他章节请看: 前端学习 node 快速入门 系列 报名系统 - [express] 最简单的报名系统: 只有两个页面 人员信息列表页:展示已报名的人员信息列表.里面有一个报名按钮,点击按钮则会跳转到 ...
随机推荐
- New start-开始我的学习记录吧
不知道从何说起,就从眼下的感想开始吧. 转行是一件不容易的事情! 今天是来北京学习Java的第41天.小测验了两次,一次51分,一次54分. 下午有学长过来分享了他的成长经历,感触很多.不是灌鸡汤,也 ...
- Redis介绍及入门安装及使用
Redis介绍及入门安装及使用 什么是Redis Redis is an open source (BSD licensed), in-memory data structure store, use ...
- [Python3 填坑] 001 格式化符号 & 格式化操作符的辅助指令
目录 1. print( 坑的信息 ) 2. 开始填坑 2.1 Python 格式化符号表 举例说明 (1) %c (2) %s 与 %d (3) %o (4) %x (5) %f (6) %e (7 ...
- C#网络编程 多线程和高并发
在任何 TCP Server 的实现中,一定存在一个 Accept Socket Loop,用于接收 Client 端的 Connect 请求以建立 TCP Connection. 在任何 TCP S ...
- [常用类]Math、Random、System、BigInteger、BigDecimal
Math类中的成员全是静态成员,构造方法是 私有的,以避免被创建对象 常用方法: int abs() double ceil() //向上取整 double floor() //向下取整 int ma ...
- 数据挖掘 workfolw 总结
个人将数据挖掘的流程简单表示为“ 数据 → 特征 → 模型 ”. 首先,明确问题的性质和任务(分类.回归.聚类.推荐.排序.关联分析.异常检测等): 其次,理解数据(含义.类型.值的范围),并通过 ...
- C# System.Web.Caching.Cache类 缓存 各种缓存依赖
原文:https://www.cnblogs.com/kissdodog/archive/2013/05/07/3064895.html Cache类,是一个用于缓存常用信息的类.HttpRuntim ...
- spark复习笔记(6):RDD持久化
在spark中最重要的功能之一是跨操作在内存中持久化数据集.当你持久化一个RDD的时候,每个节点都存放了一个它在内存中计算的一个分区,并在该数据集的其他操作中进行重用,持久化一个RDD的时候,节点上的 ...
- Docker备份镜像
docker save -o mycentos.tar mycentos_new:1.1 指定输出到的文件 执行后,运行 ls 命令即可看到打成的tar包, 因为有463M所以打包要一会
- nodejs 模板引擎
自制替换模板 template.js var fs = require('fs') var http = require('http') var server = http.createServer( ...