pandas模块之读取文件
首先我们来看一个文件
1 男 北京 刘一 我笑
#跳过此行,序号1
2 女 上海 刘珊 你笑
3 男 杭州 刘五 他笑
#跳过此行,序号四
4 女 重庆 刘六 不笑了
下面来分析内容,并使用参数
1 第一眼:排列很乱,空格有的多有的少 --》sep='\s+' 用正则去匹配 2 没用标题 ---》names=["序号","性别","城市","名字"] 3 最后一列看着不雅观,不要,选定我们需要的 --》usecols=[0,1,2,3] 4 还有注释这不是坑爹吗 ---》skiprows=[1,4] 5 我们最后来指定一个索引 ---》index_col='名字'
data=pd.read_csv('pandasfile.txt',names=["序号","性别","城市","名字"],index_col='名字',skiprows=[1,4],usecols=[0,1,2,3],sep="\s+")
print(data)
下面是结果
序号 性别 城市
名字
刘一 1 男 北京
刘珊 2 女 上海
刘五 3 男 杭州
刘六 4 女 重庆
其他
pandas.read_csv()
从文件,URL,文件型对象中加载带分隔符的数据。默认分隔符为'',"
pandas.read_table()
从文件,URL,文件型对象中加载带分隔符的数据。默认分隔符为"\t" 如果要指定的列太多,怎么办,去除上面的usecols,另敲一个命令:data.iloc[:,0:3] 命令ix已经被替代,以后不使用
操作:
选取性别==女的行
print(data.loc[data['性别']=='女'])
选取城市是北京 和上海 的行,以及 取反(名称伴终生啊)
print(data.loc[data['城市'].isin(['北京','上海'])]) 结果:
序号 性别 城市 其他
名字
刘一 1 男 北京 我笑
刘珊 2 女 上海 你笑 -------------------------取反--------------------------------------------
print(data.loc[~data['城市'].isin(['北京','上海'])])
结果:
序号 性别 城市 其他
名字
刘五 3 男 杭州 他笑
刘六 4 女 重庆 不笑了
使用replace替换单个或者多个
1 替换单个
kk=data['其他'].replace('我笑','哭')
print(kk)
结果
名字
刘一 我笑
刘珊 哭
刘五 他笑
刘六 不笑了
Name: 其他, dtype: object 2 使用正则匹配多个替换
kk=data['其他'].replace('.*笑','哭',regex=True)
print(kk)
结果:
名字
刘一 哭
刘珊 哭
刘五 哭
刘六 哭了
Name: 其他, dtype: object
替换多个列的情况,我们最后加一列,我们发现:索引不会被替换
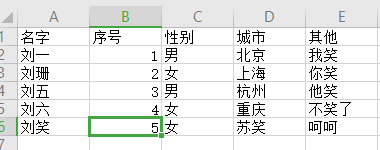
data的值
序号 性别 城市 其他
名字
刘一 1 男 北京 我笑
刘珊 2 女 上海 你笑
刘五 3 男 杭州 他笑
刘六 4 女 重庆 不笑了
刘笑 5 女 苏笑 呵呵 print(data.replace('笑','哭',regex=True)) #不加regex的话,data的值不会变化,必须要具体的值,例如:data.replace('苏笑','哭') 结果:
序号 性别 城市 其他
名字
刘一 1 男 北京 我哭
刘珊 2 女 上海 你哭
刘五 3 男 杭州 他哭
刘六 4 女 重庆 不哭了
刘笑 5 女 苏哭 呵呵
最后,经过上面的一大堆操作,data的数据还是不会变,要让它变怎么处理
inplace=True
一个很魔性的功能,写入剪贴板
data.to_clipboard() #直接就可以在其他地方黏贴了
写入文件:经过测试:sep使用\s+报错,使用‘ ’和‘\t’都不是我们要的结果,主要文件打开状态使用此命令:报权限错误
data.to_csv('D:\\a.csv',sep=',',header=True,index=True) #它的索引还是会写在最前面
sep:字段分隔符
header:是否需要头部
index:是否需要行号
其他参数:
path:表示文件系统位置、URL、文件型对象的字符串。
sep或delimiter:用于对行中各字段进行拆分的字符序列或正则表达式。
header:用作列名的行号。默认为0(第一行),如果文件没有标题行就将header参数设置为None。
index_col:用作行索引的列编号或列名。可以是单个名称/数字或有多个名称/数字组成的列表(层次化索引)。
names:用于结果的列名列表,结合header=None,可以通过names来设置标题行。
skiprows:需要忽略的行数(从0开始),设置的行数将不会进行读取。
na_values:设置需要将值替换成NA的值。
comment:用于注释信息从行尾拆分出去的字符(一个或多个)。
parse_dates:尝试将数据解析为日期,默认为False。如果为True,则尝试解析所有列。除此之外,参数可以指定需要解析的一组列号或列名。如果列表的元素为列表或元组,就会将多个列组合到一起再进行日期解析工作。
keep_date_col:如果连接多列解析日期,则保持参与连接的列。默认为False。
converters:由列号/列名跟函数之间的映射关系组成的字典。如,{"age:",f}会对列索引为age列的所有值应用函数f。
dayfirst:当解析有歧义的日期时,将其看做国际格式(例如,7/6/2012 ---> June 7 , 2012)。默认为False。
date_parser:用于解析日期的函数。
nrows:需要读取的行数。
iterator:返回一个TextParser以便逐块读取文件。
chunksize:文件块的大小(用于迭代)。
skip_footer:需要忽略的行数(从文件末尾开始计算)。
verbose:打印各种解析器输出信息,如“非数值列中的缺失值的数量”等。
encoding:用于unicode的文本编码格式。例如,"utf-8"或"gbk"等文本的编码格式。
squeeze:如果数据经过解析之后只有一列的时候,返回Series。
thousands:千分位分隔符,如","或"."。
pandas模块之读取文件的更多相关文章
- 1.pandas打开和读取文件
最近在公司在弄数据分析相关的项目,数据分析就免不了要先对数据进行处理,也就自然避不开关于excel文档的初始化操作了. 一段时间之后,发现pandas更加符合我的项目要求,所以,将一些常规操作记录下来 ...
- pandas.read_csv()函数读取文件时,关于“header=None”影响读取列数区间的右闭合总结
对于一个没有字段名标题的数据,如data.csv 1.获取数据内容.pandas.read_csv("data.csv")默认情况下,会把数据内容的第一行默认为字段名标题. imp ...
- [Python]-pandas模块-CSV文件读写
Pandas 即Python Data Analysis Library,是为了解决数据分析而创建的第三方工具,它不仅提供了丰富的数据模型,而且支持多种文件格式处理,包括CSV.HDF5.HTML 等 ...
- Pandas读取文件
如何使用pandas的read_csv模块以及其他读取文件的模块?? 一起来看一看 Pandas中read_csv和read_table的区别 注:使用pandas读取文件格式为pandas特有的da ...
- [Python]-pandas模块-机器学习Python入门《Python机器学习手册》-02-加载数据:加载文件
<Python机器学习手册--从数据预处理到深度学习> 这本书类似于工具书或者字典,对于python具体代码的调用和使用场景写的很清楚,感觉虽然是工具书,但是对照着做一遍应该可以对机器学习 ...
- python linecache模块读取文件的方法
转自: python linecache模块读取文件 在Python中,有个好用的模块linecache,该模块允许从任何文件里得到任何的行,并且使用缓存进行优化,常见的情况是从单个文件读取多行. l ...
- 【Python】 linecache模块读取文件
[linecache] 过往在读取文件的时候,我们通常使用的是这种模式: with open('file.txt','r') as f: line = f.readline() while line: ...
- nodejs读取文件时相对路径的正确写法(使用fs模块)
在开发nodejs中,我们往往需要读取文件或者写入文件,最常用的模块就是fs核心模块.一个最简单的写入文件的代码如下(暂时不考虑回调函数): fs.readFile("./test.txt& ...
- python linecache模块读取文件用法详解
linecache模块允许从任何文件里得到任何的行,并且使用缓存进行优化,常见的情况是从单个文件读取多行. linecache.getlines(filename) 从名为filename的文件中得到 ...
随机推荐
- 【CF1253A】Single Push【模拟】
题意:给你两个数组a,b,求是否存在操作使得a变成b,操作为选取一段子区间[l,r],选一个正整数k,使得ai+=k,i∈[l,r],只能操作一次 题解:模拟即可 #include<iostre ...
- linux nginx管理
1.添加 Nginx 服务 vim /lib/systemd/system/nginx.service 添加如下内容: [Unit]Description=nginxAfter=network.tar ...
- C语言 | 线段树
#include<stdio.h> #define MAX_LEN 1000 void build_tree(int arr[],int tree[],int node,int start ...
- vue实现动态显示与隐藏底部导航的方法分析
本文实例讲述了vue实现动态显示与隐藏底部导航的方法.分享给大家供大家参考,具体如下: 在日常项目中,总有几个页面是要用到底部导航的,总有那么些个页面,是不需要底部导航的,这里列举一下页面底部导航的显 ...
- Linux学习篇(一)-初识Linux
开源许可协议 简单了解开源许可协议,一张图读懂. linux 系统特点 linux 特点安全性高.高可用.高性能 稳定且有效率 免费或少许免费 漏洞少且快速修补 多任务多用户 更加安全的用户及文件权限 ...
- canvas绘制小人开口和闭口
css: <style> body{ text-align: center; } canvas{ background: #ddd; } </style>canvas标签:&l ...
- LeetCode 114. Flatten Binary Tree to Linked List 动态演示
把二叉树先序遍历,变成一个链表,链表的next指针用right代替 用递归的办法先序遍历,递归函数要返回子树变成链表之后的最后一个元素 class Solution { public: void he ...
- 爬虫(十一)—— XPath总结
目录 XPath总结 一.何为XPath 二.XPath语法 1.语法 2.实例 三.XPath轴 1.XPath轴语法 2.XPath轴实例 四.XPath运算符 XPath总结 一.何为XPath ...
- 图解Http阅读笔记(一)
1.网络基础 TCP/IP 1.1TCP /IP 协议族 计算机与网络设备要相互通信,双方就必须基于相同的方法.比如,如何探测到通信目标.由哪一边先发起通信.使用哪种语言进行通信.怎样结束通信等规 ...
- mysql高级知识
2 数据约束 2.1什么数据约束 对用户操作表的数据进行约束 2.2 默认值 作用: 当用户对使用默认值的字段不插入值的时候,就使用默认值. 注意: 1)对默认值字段插入null是可以的. 2)对 ...