【python3】基于scrapyd + scrapydweb 的可视化部署
一、部署组件概览
该部署方式适用于 scrapy项目、scrapy-redis的分布式爬虫项目
需要安装的组件有:
1、scrapyd 服务端 【运行打包后的爬虫代码】(所有的爬虫机器都要安装)
2、logparser 服务端 【解析爬虫日志,配合scraoydweb做实时分析和可视化呈现】(所有的爬虫机器都要安装)
3、scrapyd-client 客户端 【将本地的爬虫代码打包成 egg 文件】(只要本地开发机安装即可)
4、Scrapydweb 可视化web管理工具 【爬虫代码的可视化部署管理】(只要在一台服务器安装即可,可以直接用爬虫机器,这边直接放在172.16.122.11)
二、各组件安装步骤
1、scrapyd 服务端 (所有的爬虫机器都要安装)
用途:运行打包后的爬虫代码,可以通过api调用访问
安装命令: pip install scrapyd
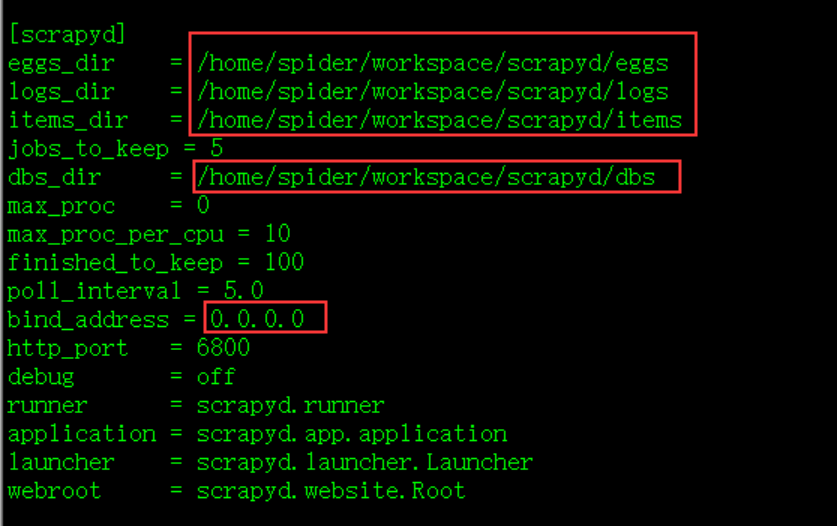
修改配置: 安装完成后,修改 default_scrapyd.conf ,文件路径 /home/spider/workspace/env/lib/python3.6/site-packages/scrapyd
修改绑定地址,允许外部访问;另外,建议修改以下相关的文件路径 ,否则这些文件夹默认生成在 安装路径下;
运行命令:nohup scrapyd > /dev/null &
访问地址:http://172.16.122.11:6800/

2、logparser 服务端 (所有的爬虫机器都要安装)
用途:解析爬虫日志,配合scraoydweb做实时分析和可视化呈现
安装命令: pip install logparser
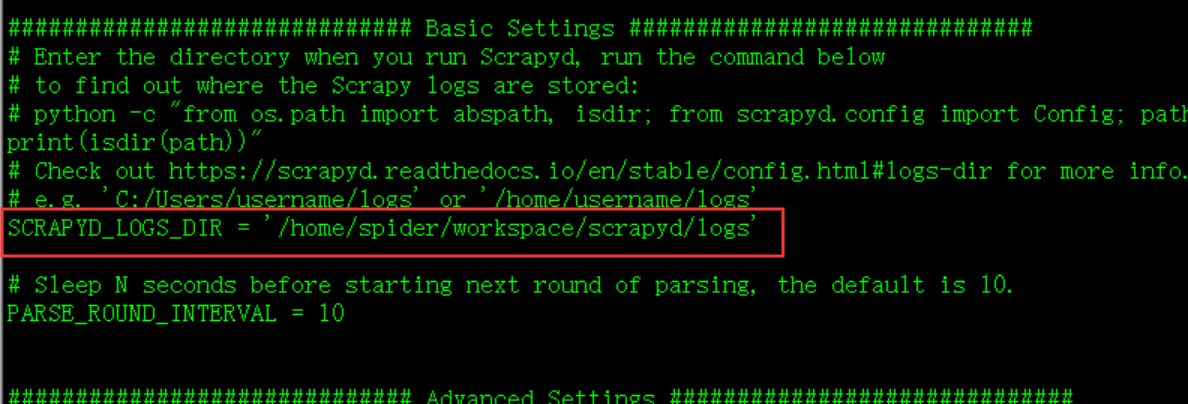
修改配置: 安装完成后,修改 settings.py,文件路径 /home/spider/workspace/env/lib/python3.6/site-packages/logparser
将要解析的日志路径修改为 scrapyd 的日志路径
运行命令:nohup logparser > /dev/null &
3、scrapyd-client 客户端 (只要本地开发机安装即可)
用途:将本地的爬虫代码打包成 egg 文件
安装命令: pip install scrapyd-client
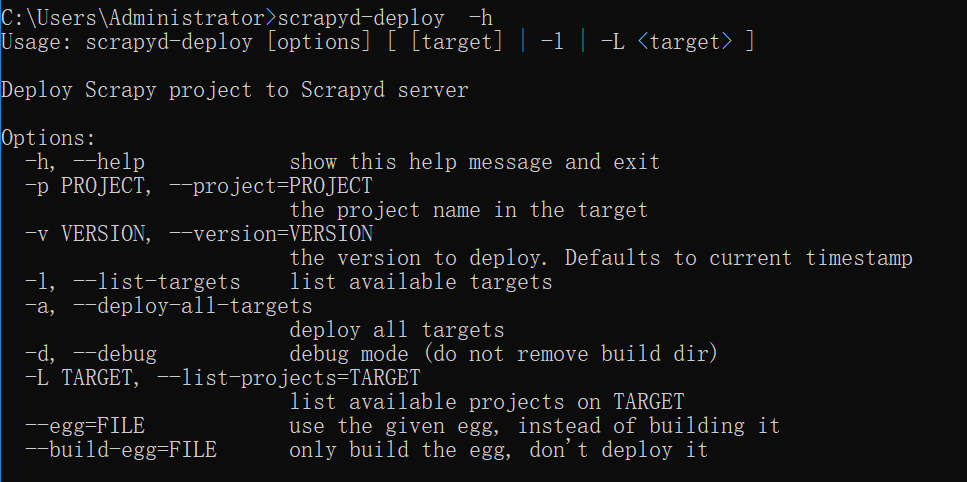
修改配置: 安装完后,执行 scrapyd-deploy -h ,如果找不到命令,则单独写一个bat文件 scrapyd-deploy.bat 放到 script 目录下即可
@echo off
D:\Anaconda3\python.exe D:\Anaconda3\Scripts\scrapyd-deploy %*

4、Scrapydweb 可视化web管理工具(只要在一台服务器安装即可,可以直接用爬虫机器,这边直接放在172.16.122.11)
用途: 爬虫代码的可视化部署管理
安装命令: pip install Scrapydweb
创建文件夹:mkdir scrapydweb; cd scrapydweb
执行命令:scrapydweb (会在当前目录下生成配置文件 scrapydweb_settings_v10.py)
修改配置: scrapydweb_settings_v10.py 【另外, 修改data路径时如果不会生效,那么同时要修改默认配置文件的data路径,可能是个bug, 默认配置文件路径: /home/spider/workspace/scrapydweb_env/lib/python3.6/site-packages/scrapydweb/default_settings.py 】 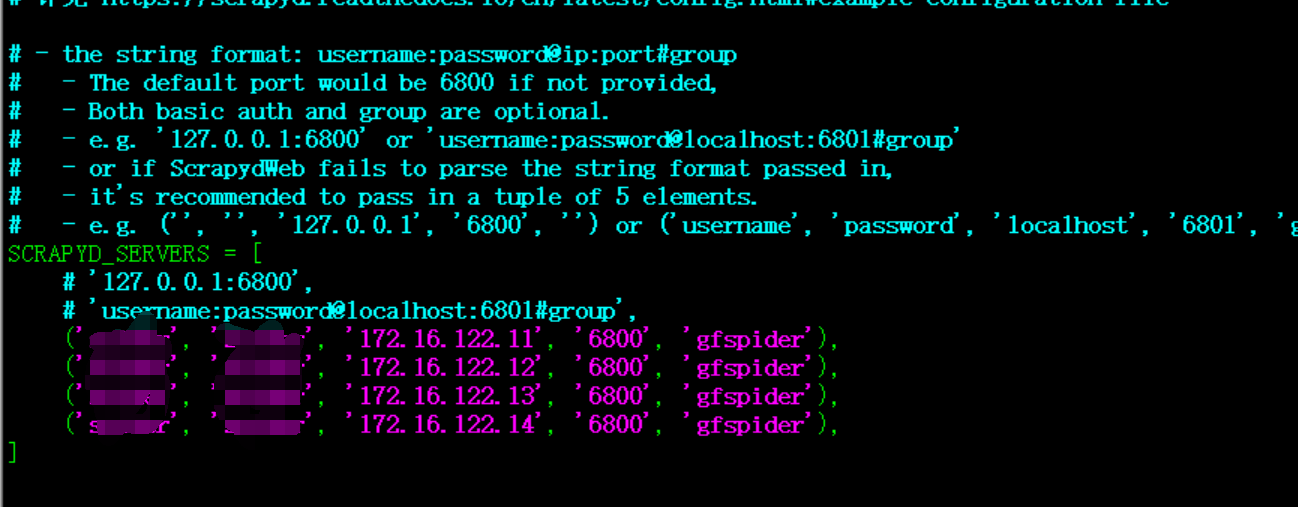
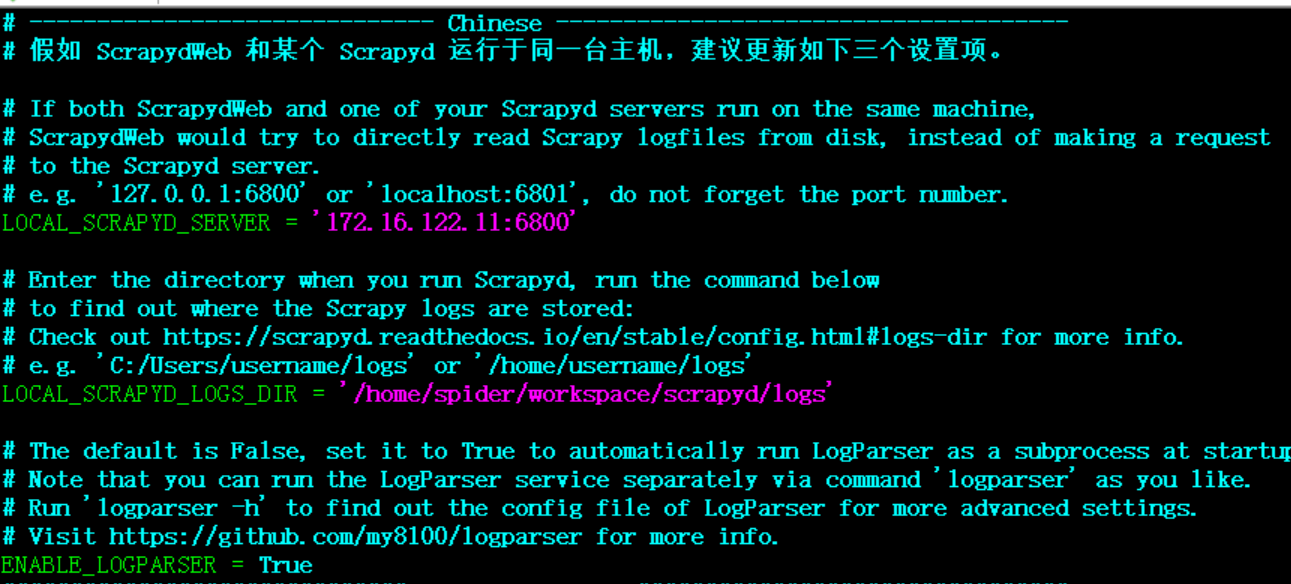

修改完配置文件后,再次执行 nohup scrapydweb > /dev/null &
访问地址:http://172.16.122.11:5000
三、爬虫代码打包
工具:scrapyd-client (在上一步已安装)
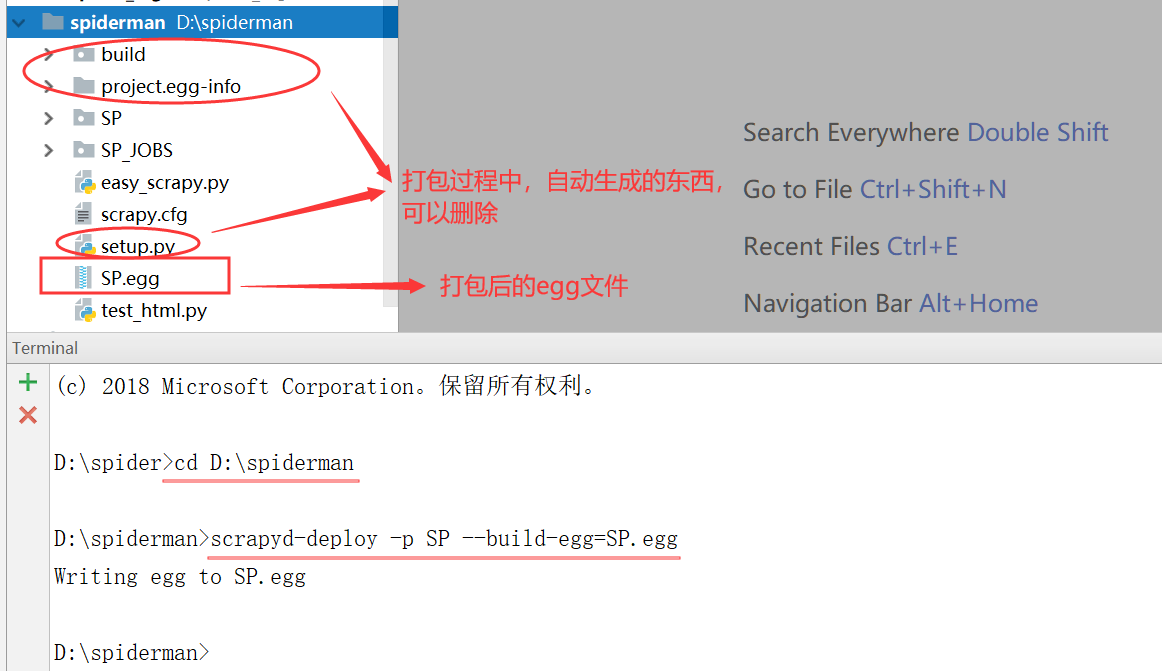
打包命令:在工程目录下执行,SP是工程名称 scrapyd-deploy -p SP --build-egg=SP.egg
关于爬虫代码需要注意的事项和egg文件说明:
1. 打包后的egg文件其实就是爬虫代码编译后的压缩文件,所以比原来的代码文件要小很多;
2. egg文件只打包了爬虫代码,不包含环境代码,也就是说,在scrapyd服务端运行的时候,python环境需要先安装好爬虫运行所需的所有包;
3. 在工程代码中,比如 setting 中最好不要有生成文件路径的做法(比如默认生成日志文件夹),否则打包成egg后,上传时可能会报错;因为上传的时候,也会在服务端编译,这个时候就可能会出现 生成文件夹 的 权限报错;
4. 如果想要使用 scrapydweb 的实时日志分析,那么在爬虫代码中,不要指定日志路径,否则运行时,日志会写到你指定的路径而无法分析;不指定路径,运行爬虫时,日志会输出到 scrapyd 预先设置好的 logs 里面,前面 logparser(日志解析服务)已经配置好 读取该位置的日志,从而实现实时分析;
四、可视化管理Scrapydweb教程
1、部署工程(有两种方式,方式1:是配置里面写死路径,自动打包;方式2:上传打包好的egg文件;举例为方式2 )
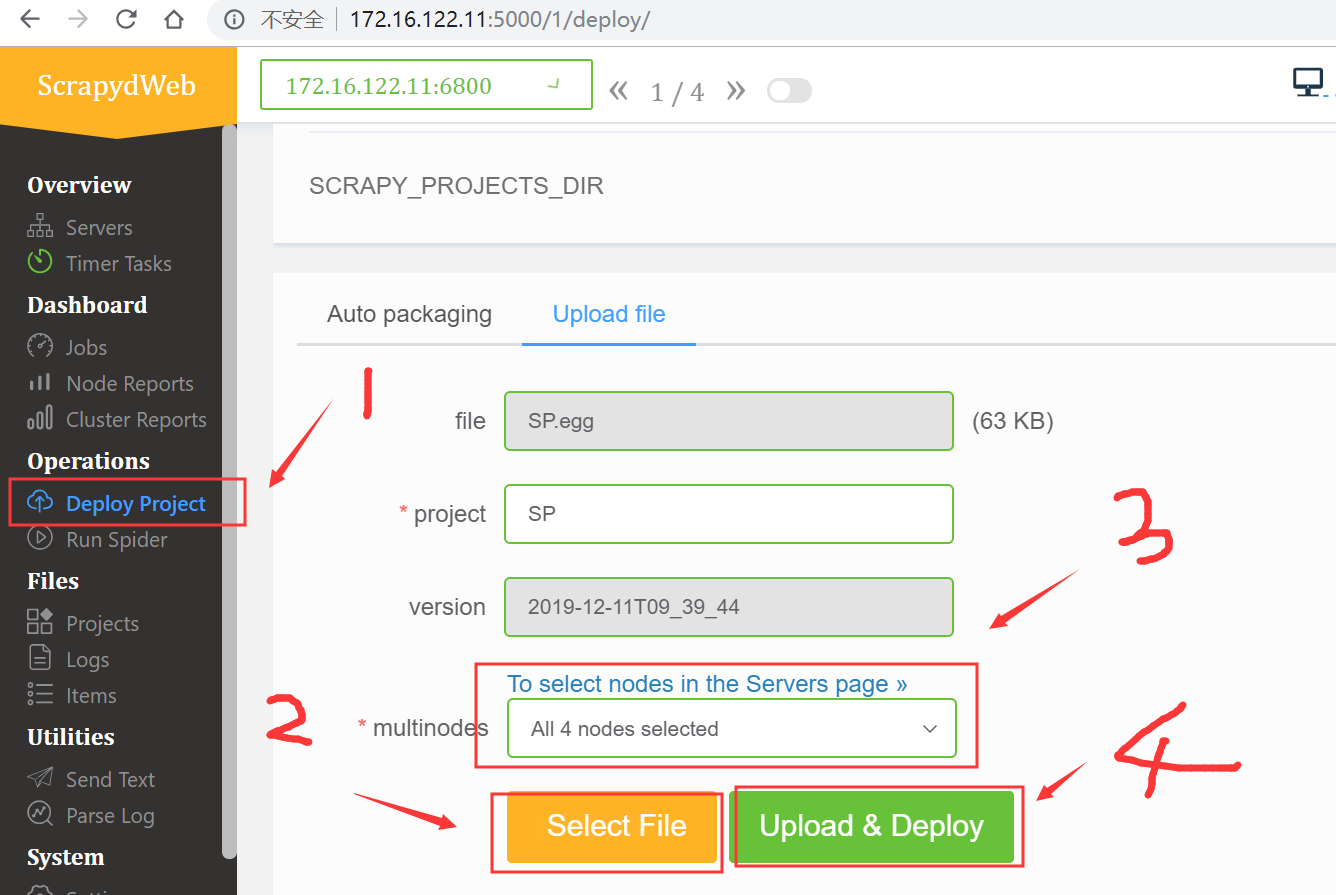
部署成功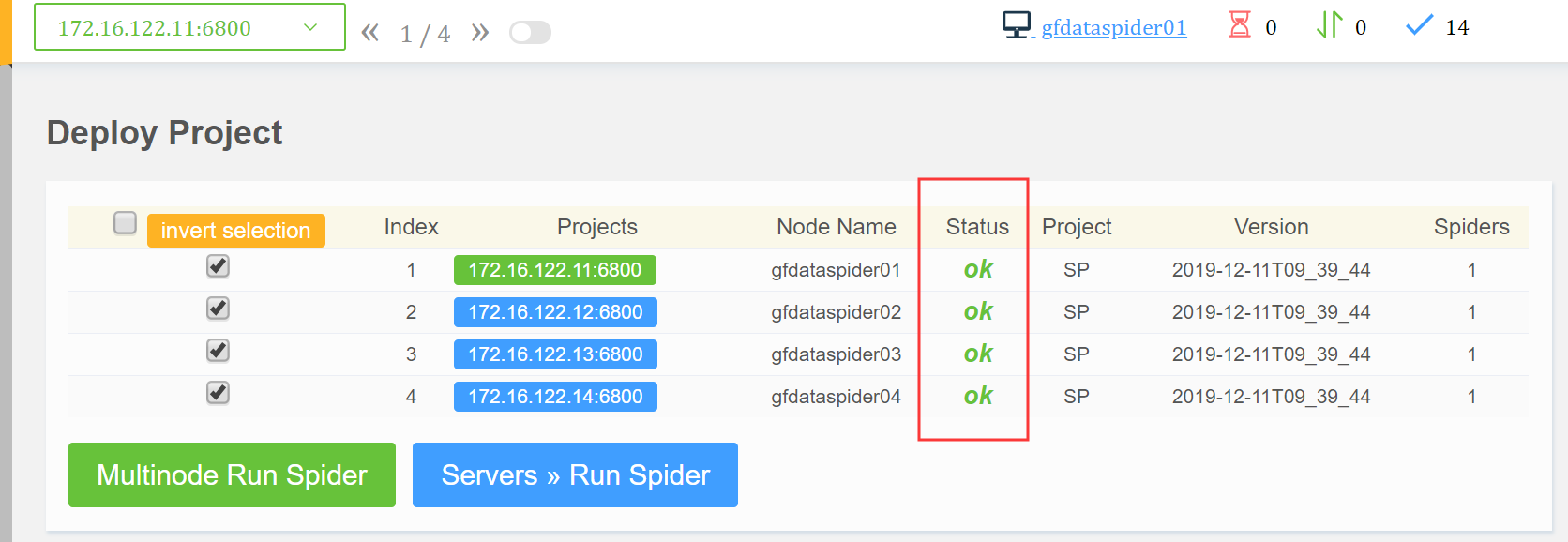
2、运行爬虫,启动一次爬虫就是一个作业,会自动分配一个作业号;后续可以根据这个作业号,查看作业情况
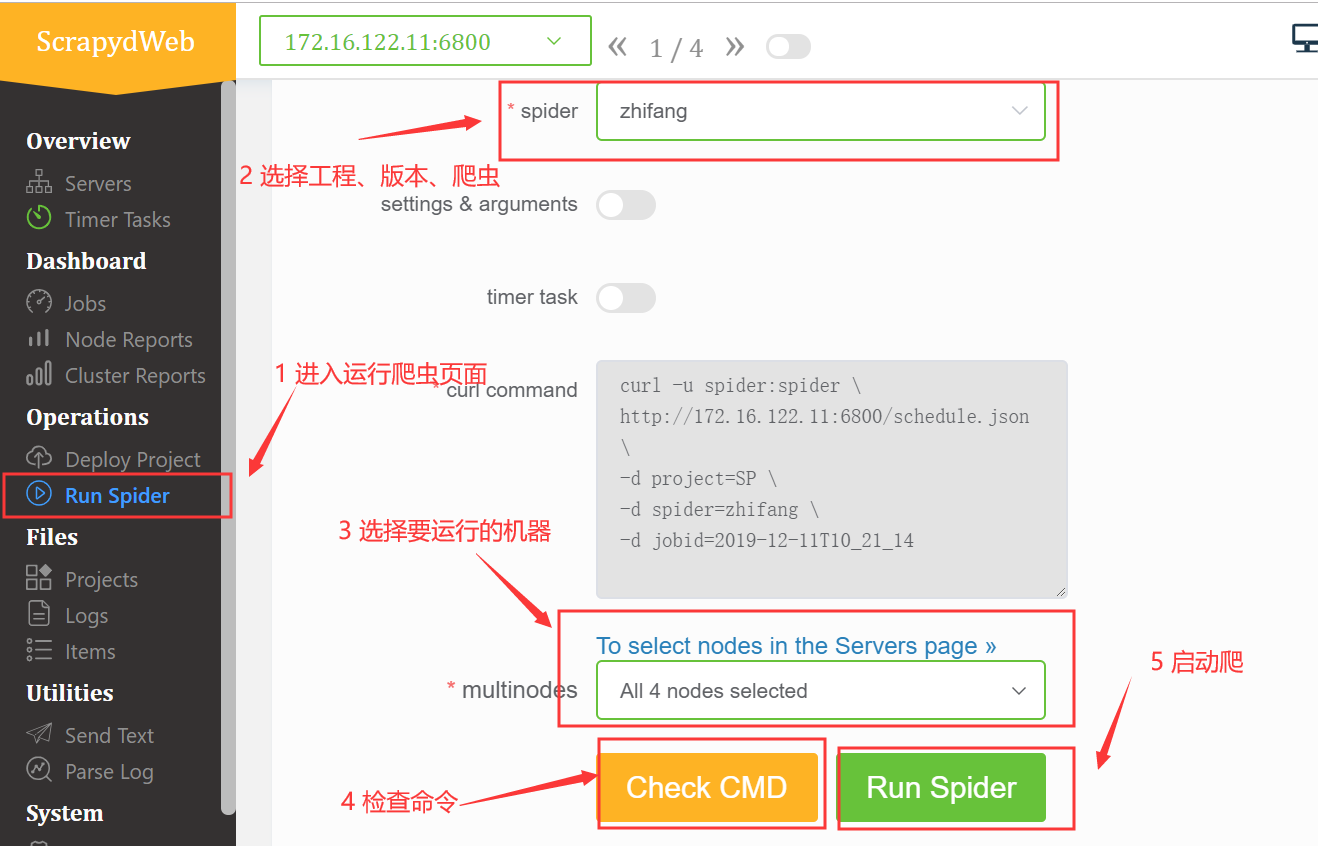
爬虫启动成功
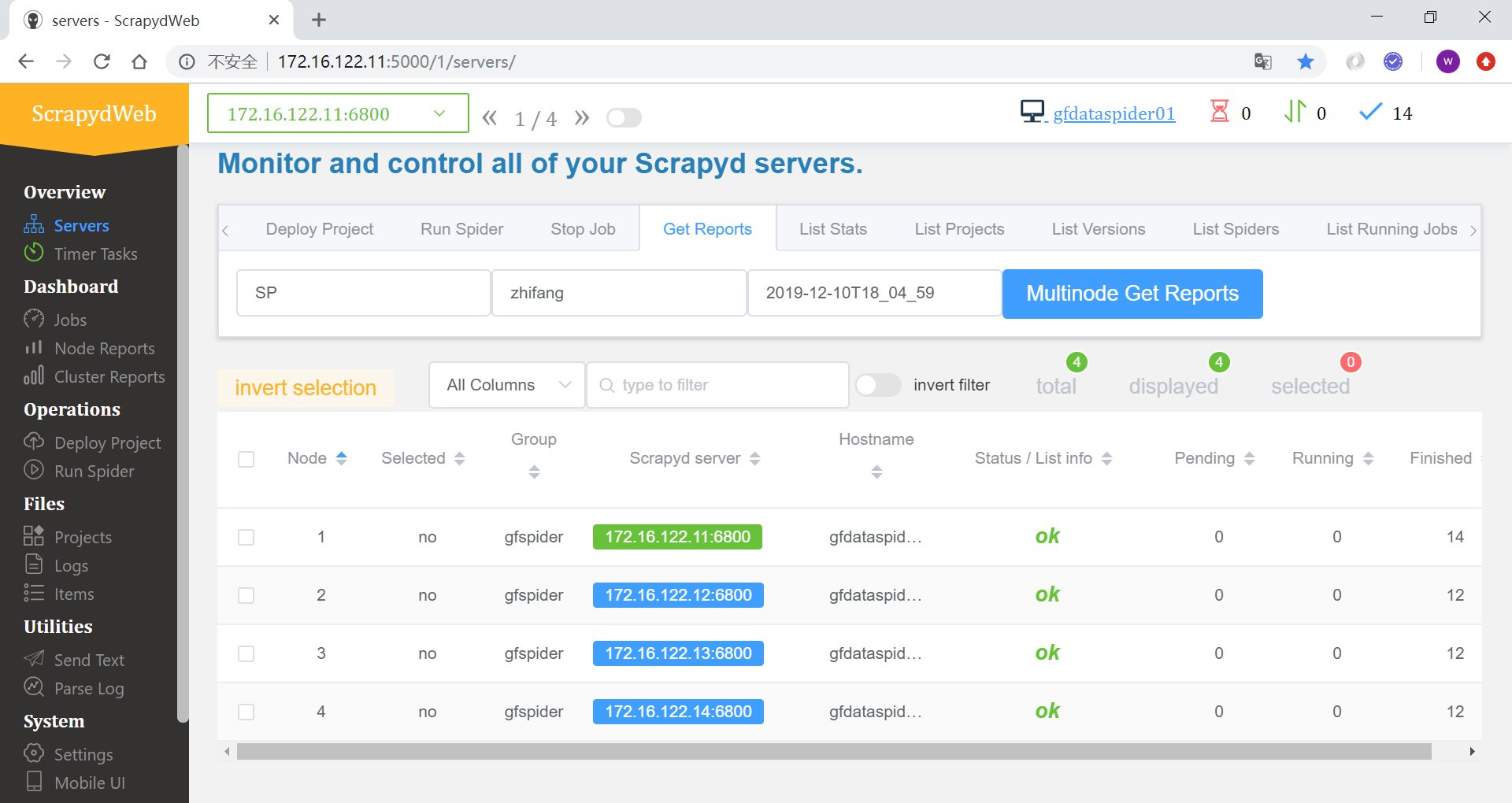
查看所有爬虫服务器的作业队列
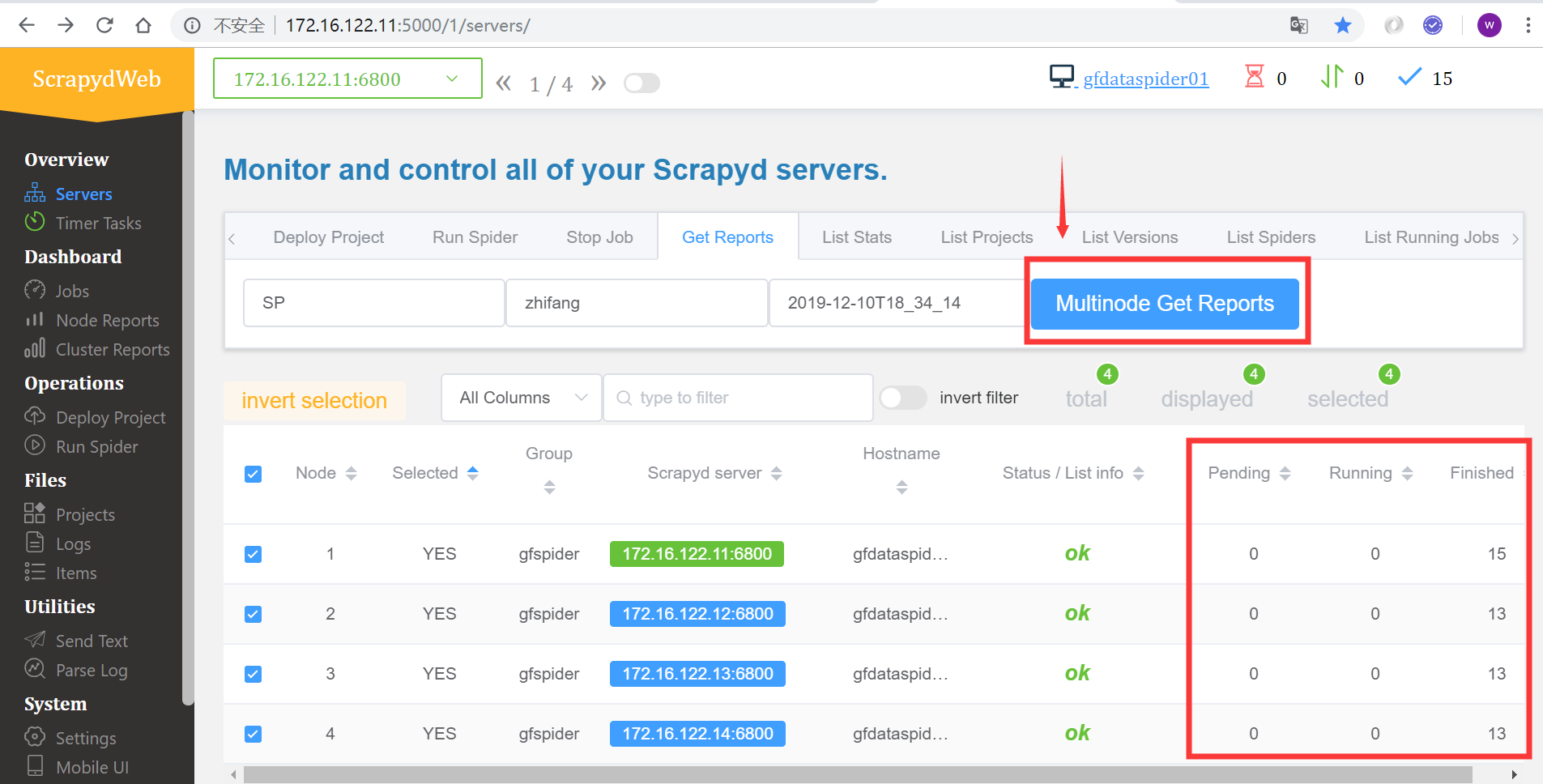
查看作业报告 
3、作业相关(查看历史作业情况)

日志分析

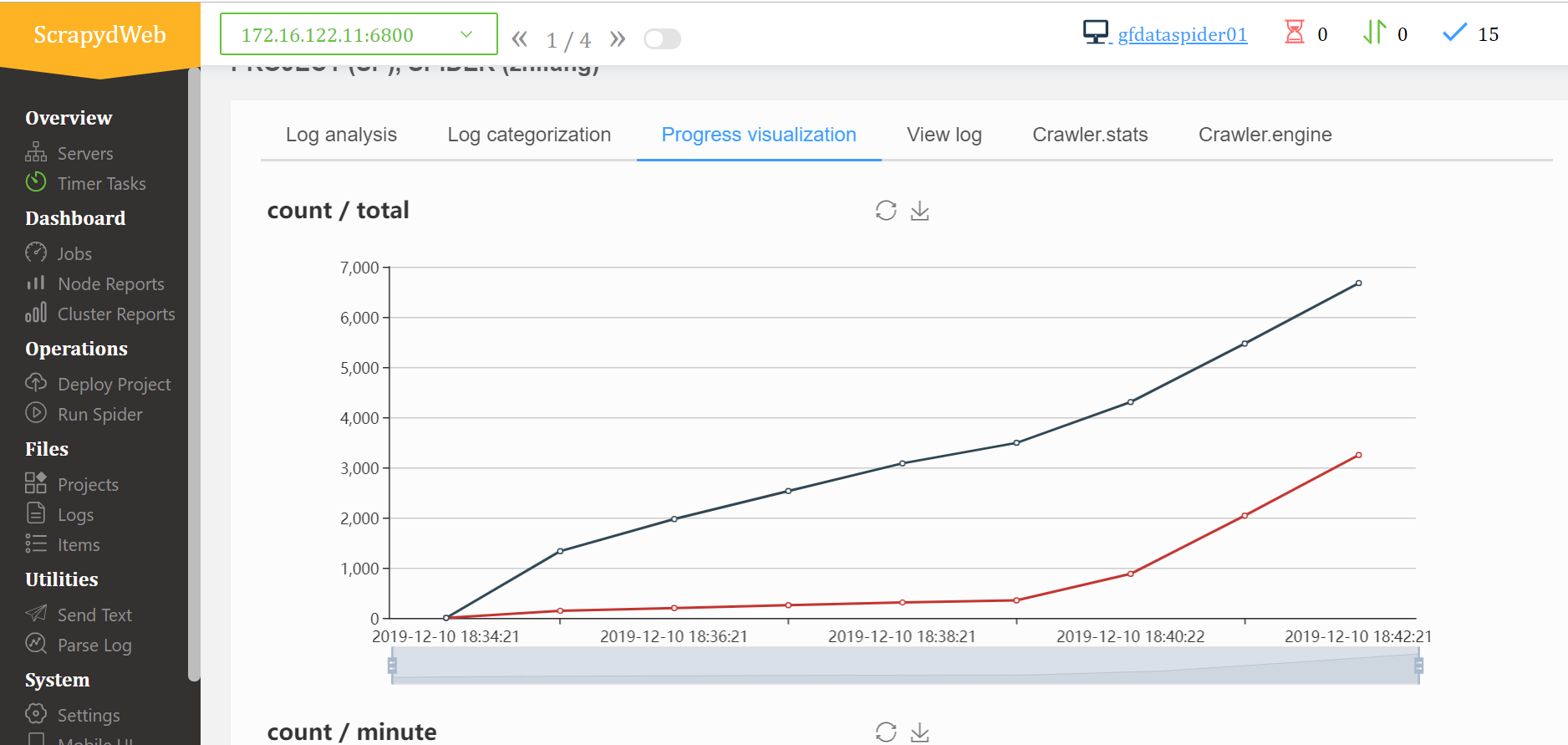
4、增加定时作业,具体的操作和运行爬虫一样,无非就是多个时间的设置
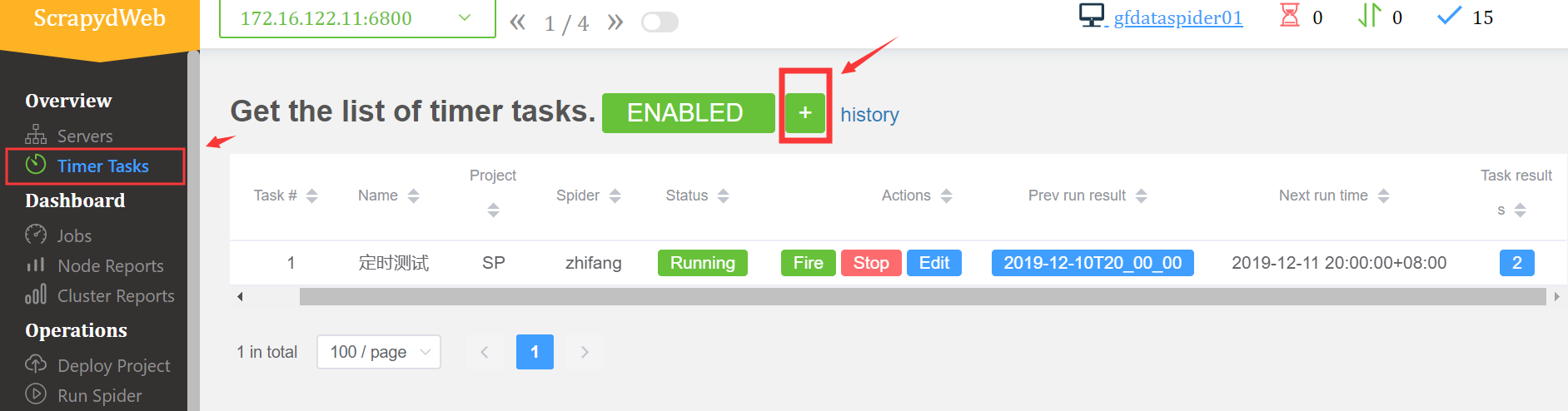
5、还有其他的一些功能,上传本地日志进行分析;设置邮件之类的,有兴趣的再自行摸索
【python3】基于scrapyd + scrapydweb 的可视化部署的更多相关文章
- gerapy 爬虫web调度可视化工具(基于scrapyd)
web 基于scrapyd 提供主机管理功能 基于scrapyd管理已安装服务的主机. 进入具体主机管理页面,会自动加载所有已知爬虫任务: 可直接可以调度.运行.查看日志. 提供项目管理功能 将已知项 ...
- Scrapy+Scrapyd+Scrapydweb实现爬虫可视化
Scrapy+Scrapyd+Scrapydweb实现爬虫可视化 Scrapyd是一个服务,用来运行scrapy爬虫的 它允许你部署你的scrapy项目以及通过HTTP JSON的方式控制你的爬虫 官 ...
- nmon2influxdb+grafana:服务监控可视化部署
在工作中,无论是定位线上问题,还是性能优化,都需要对前端.后台服务进行监控.而及时的获取监控数据,能更好的帮助技术人员排查定位问题. 前面的博客介绍过服务端监控工具:Nmon使用方法及利用easyNm ...
- 基于Kubernetes在AWS上部署Kafka时遇到的一些问题
作者:Jack47 转载请保留作者和原文出处 欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源. 交代一下背景:我们的后台系统是一套使用Kafka消息队列的数据处理管线 ...
- 基于daridus认证的openvpn部署
基于daridus认证的openvpn部署 安装openvpn 1.安装openvpn依赖包 #yum -y install gcc gcc-c++ #yum -y install openssl o ...
- 基于flask+gunicorn+nginx来部署web App
基于flask+gunicorn&&nginx来部署web App WSGI协议 Web框架致力于如何生成HTML代码,而Web服务器用于处理和响应HTTP请求.Web框架和Web服务 ...
- Hadoop生态圈-基于yum源的方式部署Cloudera Manager5.15.1
Hadoop生态圈-基于yum源的方式部署Cloudera Manager5.15.1 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我之前分享过关于离线方式部署Cloudera ...
- 基于scrapyd爬虫发布总结
一.版本情况 python以丰富的三方类库取得了众多程序员的认可,但也因此带来了众多的类库版本问题,本文总结的内容是基于最新的类库版本. 1.scrapy版本:1.1.0 D:\python\Spid ...
- Spark集群基于Zookeeper的HA搭建部署笔记(转)
原文链接:Spark集群基于Zookeeper的HA搭建部署笔记 1.环境介绍 (1)操作系统RHEL6.2-64 (2)两个节点:spark1(192.168.232.147),spark2(192 ...
随机推荐
- String、StringBuffer、StringBuilder详解
String类 字符串广泛应用在java编程中,String类在java.lang包中,String类是final修饰的,不能被继承,String类对象创建后不能修改,由0或多个字符组成,包含在一对双 ...
- MyBatis框架之异常处理
MyBatis框架定义了许多的异常类,之所以定义这么多的异常类,应该是将每一种异常情况都独立出来,这样在出现异常时,定位就很明确了.而我们平时写代码时,都是瞎搞一通,异常类大多也是随便定义,或者是使用 ...
- JS中数据结构之队列
队列是一种列表,不同的是队列只能在队尾插入元素,在队首删除元素.队列用于存储按 顺序排列的数据,先进先出. 队列的两种主要操作是:向队列中插入新元素和删除队列中的元素.插入操作也叫做入 队,删除操作也 ...
- 获取数组NSArray元素的className
正确读取NSArray里面元素的Class类型的方法 object_getClass(columnsArray.firstObject) 错误的方法是 [columnsArray.firstObjec ...
- iOS 获取全局唯一标示符
这个方法用来产生一个唯一的标示符,每次调用都会不一样,所以可以用当作一些临时缓存文件的名字 NSString *identifier = [[NSProcessInfo processInfo] gl ...
- id4用用户名和密码方式控制身份验证
建议看这个文章的时候先学习一下B站的id4教程以及文章中推荐的事例教程和官方例子: https://www.jianshu.com/p/259ef2256ec5
- springBootJpa 联表分页查询总数不准的问题
问题情景: 在联表查询时 ``` // 两张表关联查询 Join<Project, Plan> planJoin = root.join("plans", JoinTy ...
- Adobe Premiere
工具 移动工具(Selection Tool)快捷键(V) 最最常用的工具,常规功能是移动素材以及控制素材的长度 配合 ctrl:可以拖拽素材,移动到切入点进行插入 配合 shift:选择多目标(可以 ...
- Java学习之线程通信(多线程(synchronized))--生产者消费者
分析线程经典案例生产者消费者 /** 共享数据 */ class Resource { private String name; private int count=1; private boolea ...
- linux目录及文件命令学习
学习Linux 目录操作 1.pwd 可以看当前目录路径 2.cd change directory 改变目录,切换目录 cd / 进入跟目录 cd ..返回上级目录 cd 进入用户主目录 cd .. ...