计算机系统结构总结_Memory Hierarchy and Memory Performance
Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
这是youtube上一个非常好的memory system的课。
1. Physical Memory
这里我们重点关注DRAM
- 从概念上分为:Channel > DIMM > Rank > Chip > Bank > Row/Column
- Channel:一个主板上可能有多个插槽,用来插多根内存。这些槽位分成两组或多组,组内共享物理信号线。这样的一组数据信号线、对应几个槽位(内存条)称为一个channel(通道)。现代内存控制器都从北桥移入CPU内部,而且内存控制器都可以同时操作多个通道。双通道和单通道的对比可以参考(Ch5 PPT P16,P18-19,P39)
- DIMM(dual inline memory module)是主板上的一个内存插槽。一个Channel可以包括多个DIMM。
- Rank是一组内存芯片的集合。当芯片位宽x芯片数=64bits(内存总位宽)时,这些芯片就组成一个Rank。一般是一个芯片位宽8bit,然后内存每面8个芯片,那么这一面就构成一个Rank(为了提高容量,有些双面内存条就有两个rank。在DDR总线上可以用一根地址线来区分当前要访问的是哪一组。可以参考PPT P24)。同一个Rank中的所有芯片协作来共同读取同一个Address(一个Rank8个芯片 * 8bit = 64bit),这个Address的数据分散在这个Rank的不同芯片上。设计Rank的原因是这样可以使每个芯片的位宽小一些,降低复杂度。
- Chip是内存条上的一个芯片。All chips comprising a rank are controlled at the same time. They share address and command buses, but provide different data.
- Bank:Bank是一个逻辑上的概念。一个Bank可以分散到多个Chip上,一个Chip也可以包含多个Bank。Bank和Chip的关系可以参考下面的图,每次读数据时,选定一个Rank,然后同时读取每个chip上的同一bank。Banks share the same command / address / data buses
- Row/Column:Bank可以理解为一个二维数组bool Array[Row][Column]。而Row/Column就是指示这个二维数组内的坐标。注意读取时每个Bank都读取相同的坐标(Ch5 PPT P3)
以淘宝某廉价内存条南亚易胜 Elixir DDR3 1600 4G 2R*8 PC3-12800S 1.5V 笔记本内存 双面16颗粒为例:
这个内存一共双面16芯片,芯片型号为N2CB2G80BN,查datasheet可知每个芯片有8 Internal memory banks,位宽也是8bit。这样每一面的8个芯片就构成一个Rank,整个内存条一共两个Rank。
那么CPU是如何读取内存的呢?• CPU一次需要访问64bit的数据(也叫做一个字)。那么对于上面这根内存,一个Rank可以提供8bit per chip * 8 chips per Rank = 64bit的带宽,就正好对接上啦。在这个Rank里,每个chip的同一bank(bank=k )的同一地点(row=i, col=j)都会被读出8bit,那么8个chip就会同时读出64bit,然后由memory controllers传送给cpu。如图:

为了保证和CPU的沟通(要满64bit),一个内存至少要有一个RANK。但是为了保证大容量,DDR3内存经常是采用一个内存两个RANK的架构,一般也就是双面16颗粒。(过去也有用几个模组组成一个RANK的情况。比如老古董EDO内存的带宽只有32bit,但586及以上cpu的数据总线都是64bit,所以就需要成对使用)
Ref:
https://zhuanlan.zhihu.com/p/33479194
https://blog.51cto.com/10914132/1733629
https://zhuanlan.zhihu.com/p/25863918
http://lzz5235.github.io/2015/04/21/memory.html
2. 内存是如何读取数据的?
那么对于一个chip上的某个Bank,又是怎么读取的呢?我们以读取Row0, Column0为例:
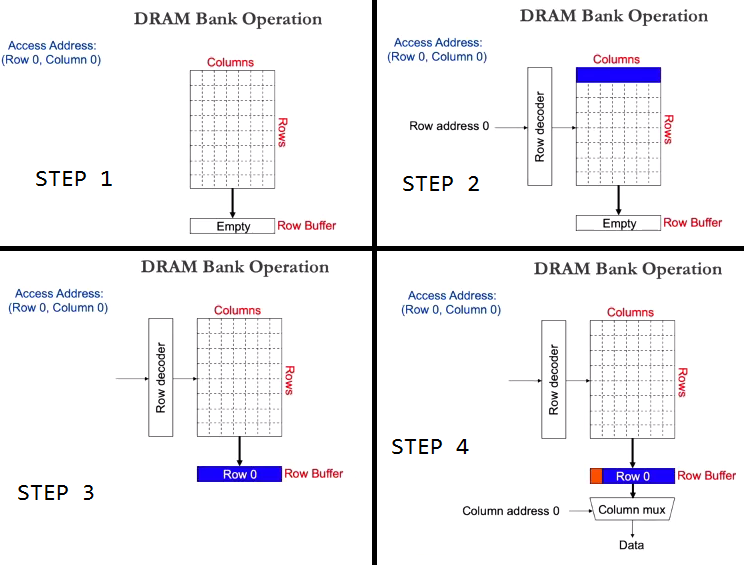
- STEP1:开始读,send row address
- STEP2:open this row
- STEP3:copy the whole row into Row Buffer
- STEP4:send column address, and get the data
这几步读取完成后,Row Buffer暂时不会被清空。下次如果读同一个Row上的不同Column(比如Row0, Column23),就直接去Row Buffer拿就行啦,相当于只执行STEP4的操作。这次就叫做Row Buffer Hit。
如果下次读的是不同的Row(比如Row1, Column0),那就得先把Row Buffer里的数据写回内存中的Row0(因为可能被改写过),然后close Row0。然后对Row1再执行一下STEP1--STEP4的所有操作。这次叫做Row Buffer Miss。
如果每次都读不同的row,那么row buffer miss就会比较多,性能就会下降。
在从内存向cache block读数据的时候,从低地址向高地址读,每次64bit。(可以参考这里的7. Ohters这一节)
2. interleaving(QR P76、ch5 ppt P37)
在之前的图上,我们看到对于每次DRAM access,都是访问某个Bank的全部Row/Column,然后得到64bit的数据。但是实际上不同Bank又不相互影响,所以我们是可以parallel的访问不同Bank的。那么对于一大坨要访问的数据,如果能分散到多个Bank上,就可以parallel的访问它们啦!那应该如何实现这一点呢?我们需要观察一下内存地址的编码方式:
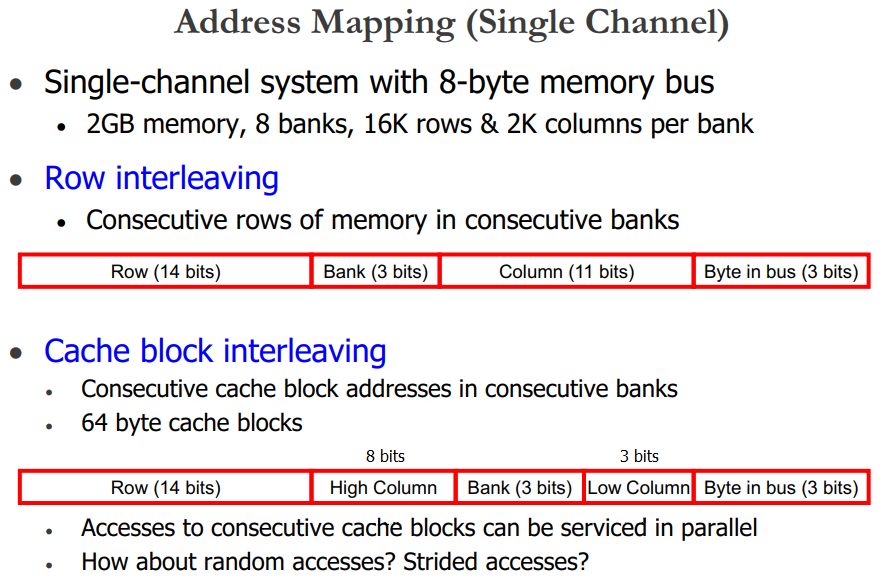
图中有两种方式:Row interleaving 和 Cache interleaving。
- 对于Row interleaving,因为Bank在高地址位(2^3=8个Bank)。那么假设现在要访问一大坨数据,根据locality的原理它们的内存地址经常是consecutive的,那么按这种编码方式它们就会被尽量塞到同一个Bank里。这样虽然单个Bank的row buffer的hit比较高,但只有这一个Bank在忙碌,其他7个Bank都闲着。综合起来看还是不大好
- 对于Cache Block interleaving,我们把Bank往下放了一点,只留了三位的Column在低地址(这里假设64Bytes的Cache Block)。这样相邻的cache block address就会被放到不同的Bank上,就可以parallel的访问它们啦
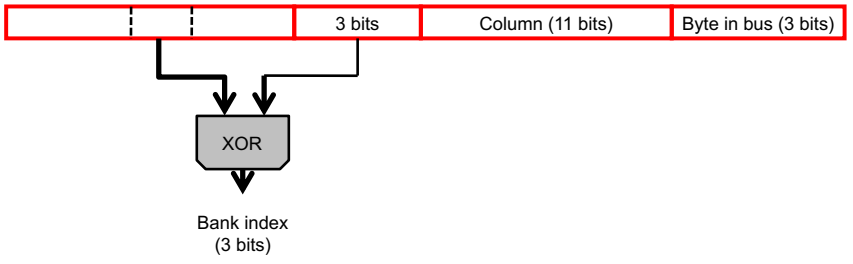
但是如果access pattern不是consecutive的,那么这种方法就不一定起效果了。所以还有一种方法就是随缘了(randomize the address mapping to banks so that bank conflicts are less likely)。下面这种方法表示Bank index是某三位的xor运算的结果:
interleaving in multiple channels
如果有很多的Channel,那么内存地址中就会多一位来选择channel。这一位的放置位置也有很多种选择:

对于还是64 Bytes的cache block,按照图中这5种方式,consecutive cache block(后6位相当于block内的offset)会被放在哪里呢?
- same channel different bank
- same channel different bank
- same channel different bank
- different channel different bank
- The same cache block is scattered on different channels(这样也不好)
3. DRAM controller
ch5 PPT P43
。。。。
计算机系统结构总结_Memory Hierarchy and Memory Performance的更多相关文章
- 计算机系统结构总结_Memory Review
这次就边学边总结吧,不等到最后啦 Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR Ch3. Memor ...
- 【5分钟+】计算机系统结构:CPU性能公式
计算机系统结构:CPU性能公式 基础知识 CPU 时间:一个程序在 CPU 上运行的时间.(不包括I/O时间) 主频.时钟频率:CPU 内部主时钟的频率,表示1秒可以完成多少个周期. 例如,主频为 4 ...
- 计算机系统结构总结_Cache Optimization
Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR Ch4. Cache Optimization 本章要 ...
- Spring Boot Memory Performance
The Performance Zone is brought to you in partnership with New Relic. Quickly learn how to use Docke ...
- 计算机系统结构总结_Multiprocessor & cache coherence
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 最后一节来看看如何实现parallelism 在多处 ...
- 计算机系统结构总结_Branch prediction
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR Branch Prediction 对于下面的指令: ...
- 计算机系统结构总结_Scoreboard and Tomasulo
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 超标量 前面讲过超标量的概念.超标量的目的就是实现指 ...
- 计算机系统结构总结_Instruction Set Architecture
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 这节我们来看CPU内部的一些东西. Instruct ...
- [Paper] Selection and replacement algorithm for memory performance improvement in Spark
Summary Spark does not have a good mechanism to select reasonable RDDs to cache their partitions in ...
随机推荐
- UI编辑
UI编辑 基本部件介绍 (1)Layout(布局) (2)Space(空间) (3)Button (4)ItemView (5)ItemWidget Widget继承自View,即ListWidget ...
- 序列式容器————dequeue
#include <deque> 双端队列,可以在队头队尾进行入队出队操作 deque<int> q; q.empty(); q.push_front(s);//将s插入到队头 ...
- oracle SQL查询number字段精度丢失之解决方法
解决办法: -- 3.3:表示原始数据 --fm9999999990.0000:表示保留到小数点后4位,若不存在则用0补位. ),'fm9999999990.0000') as demo from d ...
- [LeetCode]-011-Longest Common Prefix
Write a function to find the longest common prefix string amongst an array of strings. []=>" ...
- ActiveMQ从入门到精通(二)
接上一篇<ActiveMQ从入门到精通(一)>,本篇主要讨论的话题是:消息的顺序消费.JMS Selectors.消息的同步/异步接受方式.Message.P2P/PubSub.持久化订阅 ...
- linux 上使用libxls读和使用xlslib写excel的方法简介
读取excel文件:libxls-1.4.0.zip下载地址:http://sourceforge.net/projects/libxls/安装方法: ./configure make make ...
- linux inotify 监控文件系统事件
https://blog.csdn.net/cheng_fangang/article/details/41075515
- lr参数与C语言函数参数的区别
C变量不能再lr函数中使用: c变量必须定义在lr函数之前: LR参数可以在LR函数中直接当做字符串使用. LR参数是lr自己封装的一个钟对象, LR参数的表达方式:{ParamName}
- leetcode-mid-backtracking -78 Subsets
mycode 86.06% class Solution(object): def subsets(self, nums): """ :type nums: List ...
- mysql命令使用3
算术运算函数 sum()求和 mysql> select sum(price) from books;+------------+| sum(price) |+------------+| 10 ...