Unsupervised Image-to-Image Translation Networks
Abstract:
无监督图像到图像的翻译目的是学习不同域图像的一个联合分布,通过使用来自单独域图像的边缘分布。给定一个边缘分布,可以得到很多种联合分布。如果不加入额外的假设条件的话,从边缘分布无法推出联合分布。为了解决这个问题,作者提出了一个shared-latent空间假设并且基于Coupled GANs提出一个无监督的图像到图像的翻译框架
Introduction:
计算机视觉中的许多问题可以被当作是图像到图像的翻译问题,匹配一个域中的图像对应到到另一个域中。如超分辨率可以被当作匹配一张低分辨率图像到对应的高分辨率图像。图像着色可以看作匹配一张灰度图到一张对应的彩色图像。这些问题有监督方式和无监督方式来解决。在有监督情况下,有可用的不同域的成对的图像。在无监督情况下,我们只有两个单独的数据集,其中一个数据集包含一个域的图像,另一个数据集包含了另一个域的图像。没有配对的样本来指导一张图像如何转换到另一个域中的图像。由于缺乏配对的图像,无监督的图像到图像的翻译问题被认为是很难的,但是它是实用的,因为使得数据的收集变得简单。
本文从概率建模的角度来分析图像翻译问题,关键的挑战在于学习不同域图像的联合分布。在无监督设置下,两个数据集包含了来自不同的两个域的两个边缘分布的图像,目标是使用这些图像来推断联合分布。耦合理论说明了通常给定一个边缘分布我们可以得到很多联合分布。因此,从边缘分布推断联合分布是一个高度欠定的问题。为了解决这个问题,我们需要在联合分布的基础上加入额外的假设。
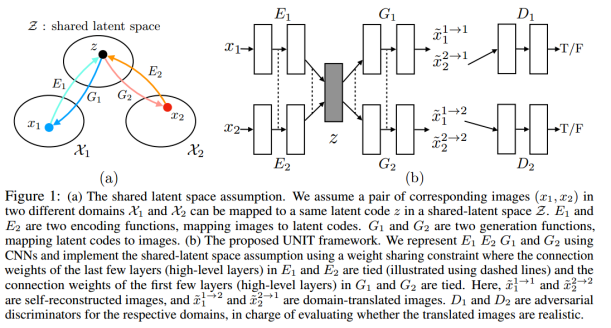
为此,作者做了一个shared-latent空间假设,假设一对来自不同域的对应的图像可以被映射为共享潜在空间的同一个表示。基于这个假设,作者提出了UNIT框架,是基于生成对抗网络和可变分自编码。使用VAE-GAN来建模每个图像域。对抗训练目标整合了一个权重共享约束,形成了一个共享的潜在空间,来生成两个域对应的图像,同时可变分自编码器将不同域的输入图像和转换图像联系起来。该shared-latent空间假设被用在Coupled GAN中为了联合分布学习,作者延伸了Coupled GAN的工作。并且在本文的工作中,shared-latent space约束暗含了循环一致性约束。
假设:
X1和X2表示两个图像域。在有监督图像转换条件下,我们可以得到样本(x1, x2)来自一个联合分布PX1,X2(x1, x2)。在无监督中,我们只有来自边缘分布PX1(x1)和PX2(x2)的样本。由于很多种可能的联合分布可以产生给定的边缘分布,如果没有额外的假设无法从边缘分布推断出联合分布。
如图1所示,假设任意给定的样本对x1, x2,存在一个共享的潜在编码在一个共享潜在空间,以至于我们可以从这个编码恢复出两个图像,并且我们从两张图像中的一个计算出该编码。也就是说,我们假设存在函数E1,E2,G1,G2,给定一对来自联合分布的图像(x1, x2),可以得到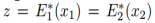 以及相反地
以及相反地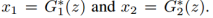 在这个模型中,函数
在这个模型中,函数 匹配X1域到X2域,可以用复合函数表示为
匹配X1域到X2域,可以用复合函数表示为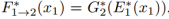 同样,
同样,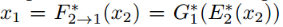 。即UNIT学习
。即UNIT学习
和 。注意到这俩存在的一个必要条件是循环一致性约束:
。注意到这俩存在的一个必要条件是循环一致性约束: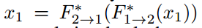 和
和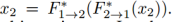 。我们可以重建输入图像将转换后的输入图像再转回去。换句话说,提出的共享潜在空间假设包含了循环一致性假设。
。我们可以重建输入图像将转换后的输入图像再转回去。换句话说,提出的共享潜在空间假设包含了循环一致性假设。
为了实现这个shared-latent space假设,进一步假设一个共享的中间表示h,因此生成一堆对应图像的过程允许这样一个形式
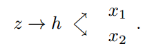
因此,可以得到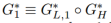 和
和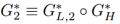 ,其中
,其中 是一个普通的高层生成函数,匹配z到h和
是一个普通的高层生成函数,匹配z到h和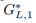 ,
,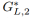 是低层生成函数,匹配h到x1,x2。
是低层生成函数,匹配h到x1,x2。
框架结构
如图1所示,本文的框架是基于变分自编码器和生成对抗网络。共由6个子网络组成:两个域图像编码器E1和E2,两个域图像生成器G1和G2,以及两个域图像判别器D1和D2。该框架在一次训练中学习两个方向的转换。
VAE. 编码-生成器对{E1,G1}由一个X1域的变分自编码器组成(VAE1)。对于一张输入图像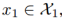 VAE1首先通过VAE1映射x1到潜在空间Z的一个编码,然后解码该编码的一个随机扰动的版本来通过生成器G1重构输入图像。假设潜在空间Z中的部分是条件独立的,并且是方差为1的高斯分布。编码器输出一个均值向量
VAE1首先通过VAE1映射x1到潜在空间Z的一个编码,然后解码该编码的一个随机扰动的版本来通过生成器G1重构输入图像。假设潜在空间Z中的部分是条件独立的,并且是方差为1的高斯分布。编码器输出一个均值向量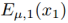 ,潜在编码z1的分布为
,潜在编码z1的分布为 ,其中I为单位矩阵。重构的图像是
,其中I为单位矩阵。重构的图像是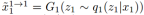 。
。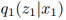 的分布被当作
的分布被当作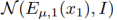 的一个随机向量,并且从中采样得到。E2,G2同理。
的一个随机向量,并且从中采样得到。E2,G2同理。
利用重新参数化技巧,不可导的采样操作可以重新参数化作为一个可导的操作通过使用辅助的随机变量。重新参数化技巧可以使我们利用反向传播来训练VAEs。η表示多方差高斯分布的随机向量: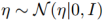 。
。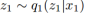
和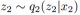 采样操作可以通过
采样操作可以通过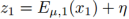 和
和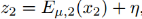 来实现。
来实现。
权值共享.基于共享潜在空间假设,我们施加一个权值共享约束来关联两个VAEs。特别地,我们共享E1和E2最后几层的权重,是为了提出两个输入图像域的高层表示。同样地,G1和G2的前面几层共享权重,用来解码高层的表示为了重构输入图像。
注意到单独的权值共享约束不能确保对应的两个域的图像有同样的潜在编码。在无监督环境下,没有成对的两个域的图像存在来训练网络从而输出相同的潜在编码。提取到的一对图像的潜在编码通常是不同的。即使它们是一样的,同样的潜在信息可能有不同域的不同的语义信息。因此,同样的潜在编码仍然能够解码输出两个无关的图像。但是,我们将通过对抗训练来给出,两个域中的成对图像可以通过E1和E2映射到一个通用的潜在编码,并且该潜在编码可以被映射成一对对应的图像在两个域中通过G1和G2。
这个共享的潜在空间假设使得我们可以进行图像到图像的转换。通过应用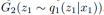 可以把X1域中的图像x1转换到X2域中的图像x2。这两条分支和图像重构的分支联合训练。
可以把X1域中的图像x1转换到X2域中的图像x2。这两条分支和图像重构的分支联合训练。
GANs. 本文的网络框架由两个生成对抗网络组成: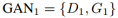 和
和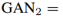
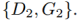 在GAN1中,对于从第一个域中采集到的真实图像,D1应该输出真,对于由G1生成的图像,输出为假。G1可以生成两种类型的图像,来自重构分支的图像
在GAN1中,对于从第一个域中采集到的真实图像,D1应该输出真,对于由G1生成的图像,输出为假。G1可以生成两种类型的图像,来自重构分支的图像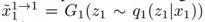 ,以及来自转换分支的图像
,以及来自转换分支的图像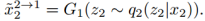 因为重建分支可以有监督的训练,我们只用对抗训练到转换分支的图像
因为重建分支可以有监督的训练,我们只用对抗训练到转换分支的图像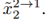
Cycle-consistency (CC). 因为shared-latent space假设暗含了循环一致性约束,我们也可以施加循环一致性约束在提出的网络框架中来进一步正则化这个欠定的无监督图像转换问题。
Learning. 我们联合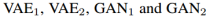 解决这个学习问题对于图像重建分支,图像转换分支以及循环重构分支。
解决这个学习问题对于图像重建分支,图像转换分支以及循环重构分支。
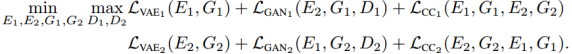
VAE训练旨在最小化一个可变上边界,VAE的目标是
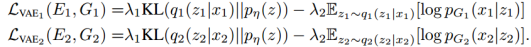
其中超参数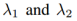 控制了目标项的权重,KL散度项惩罚潜在编码分布与先验分布的偏差。正则化使得一个简单的方式从潜在空间中采样。我们利用拉普拉斯分布来建模
控制了目标项的权重,KL散度项惩罚潜在编码分布与先验分布的偏差。正则化使得一个简单的方式从潜在空间中采样。我们利用拉普拉斯分布来建模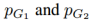 。因此,最小化负对数似然项等价于最小化图像与重构图像之间的绝对距离。其中,先验分布是一个0均值的高斯分布
。因此,最小化负对数似然项等价于最小化图像与重构图像之间的绝对距离。其中,先验分布是一个0均值的高斯分布 。GAN的目标函数是
。GAN的目标函数是
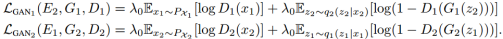
该目标函数是条件GAN目标函数。被用来确保生成的图像看起来像目标域的图像,超参数控制了GAN目标函数的影响。
只用一个VAE-like的目标函数来建模循环一致性约束,
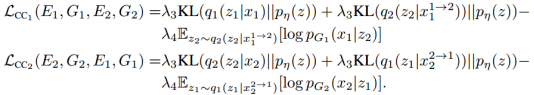
其中负对数似然目标函数确保了一个两次转换图像看起来像输入的图像,KL项惩罚潜在的编码由背离循环重建分支的先验分布。超参数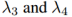 控制了两个不同目标项的权重。
控制了两个不同目标项的权重。
Unsupervised Image-to-Image Translation Networks的更多相关文章
- Unsupervised Image-to-Image Translation Networks --- Reading Writing
Unsupervised Image-to-Image Translation Networks --- Reading Writing 2017.03.03 Motivations: most ex ...
- On Explainability of Deep Neural Networks
On Explainability of Deep Neural Networks « Learning F# Functional Data Structures and Algorithms is ...
- 提高驾驶技术:用GAN去除(爱情)动作片中的马赛克和衣服
同步自我的知乎专栏:https://zhuanlan.zhihu.com/p/27199954 作为一名久经片场的老司机,早就想写一些探讨驾驶技术的文章.这篇就介绍利用生成式对抗网络(GAN)的两个基 ...
- Generative Adversarial Nets[CycleGAN]
本文来自<Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks>,时间线为2017 ...
- (转)Awsome Domain-Adaptation
Awsome Domain-Adaptation 2018-08-06 19:27:54 This blog is copied from: https://github.com/zhaoxin94/ ...
- (转)Autonomous_Vehicle_Paper_Reading_List
Autonomous_Vehicle_Paper_Reading_List 2018-07-19 10:40:08 Reference:https://github.com/ZRZheng/Auton ...
- Awesome TensorFlow
Awesome TensorFlow A curated list of awesome TensorFlow experiments, libraries, and projects. Inspi ...
- 生成对抗网络资源 Adversarial Nets Papers
来源:https://github.com/zhangqianhui/AdversarialNetsPapers AdversarialNetsPapers The classical Papers ...
- 《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》论文笔记
Code Address:https://github.com/junyanz/CycleGAN. Abstract 引出Image Translating的概念(greyscale to color ...
随机推荐
- UnknownPropertyException(Yii2)
在class里面的rule有属性,但是没声明
- vue.js(1)--创建vue实例的基本结构
vue实例基本结构与MVVM框架 (1)vue实例基本结构 <!DOCTYPE html> <html lang="en"> <head> &l ...
- ECharts 中的事件和行为
在 ECharts 的图表中用户的操作将会触发相应的事件.开发者可以监听这些事件,然后通过回调函数做相应的处理,比如跳转到一个地址,或者弹出对话框,或者做数据下钻等等. 如下是一个绑定点击操作的示例. ...
- 异步分布式队列Celery
异步分布式队列Celery 转载地址 Celery 是什么? 官网 Celery 是一个由 Python 编写的简单.灵活.可靠的用来处理大量信息的分布式系统,它同时提供操作和维护分布式系统所需的工具 ...
- 网页图片失效自动替换图片地址js代码
当你网页中的图片失效之后它会显示你预先设定好的默认图片,而不是显示为一个大大的红叉叉. js脚本如下: <script language="javascript"> v ...
- 一键部署lnmp脚本
先下载好nginx安装包,解包之后可以执行下面的脚本,一键部署 cd nginx-1.12.2 useradd -s /sbin/nologin nginx./configuremakemake in ...
- vue项目配置及项目初识
目录 Vue项目环境搭建 Vue项目创建 重构项目依赖 1.需要转移的文件 2.重构依赖 pycharm配置并启动vue项目 vue项目目录结构分析 vue组件(.vue文件) 全局脚本文件main. ...
- Scala传递参数遇到的坑
1.方法中的参数全为val型. 例: def insertMap(map:=>Map[String,Int]):Unit={ map+=("b"->2) //报错 ...
- linux 配置内网yum源
一.yum服务器端配置1.安装FTP软件#yum install vsftpd #service vsftpd start#chkconfig --add vsftpd#chkconfig vsftp ...
- [转] C++ 的关键字(保留字)完整介绍
转载至:https://www.runoob.com/w3cnote/cpp-keyword-intro.html 1. asm asm (指令字符串):允许在 C++ 程序中嵌入汇编代码. 2. a ...