Newsgroups数据集研究
1.数据集介绍
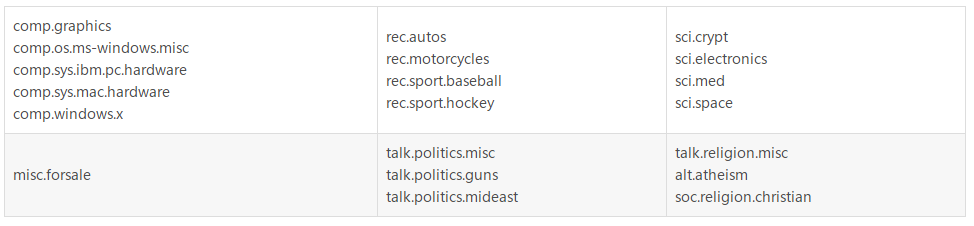
20newsgroups数据集是用于文本分类、文本挖据和信息检索研究的国际标准数据集之一。
数据集收集了大约20,000左右的新闻组文档,均匀分为20个不同主题的新闻组集合。
一些新闻组的主题特别相似(e.g. comp.sys.ibm.pc.hardware/ comp.sys.mac.hardware),还有一些却完全不相关 (e.g misc.forsale /soc.religion.christian)。
20newsgroups数据集有三个版本:
第一个版本19997是原始的并没有修改过的版本:20news-19997.tar.gz –原始20 Newsgroups数据集
第二个版本bydate是按时间顺序分为训练(60%)和测试(40%)两部分数据集,不包含重复文档和新闻组名(新闻组,路径,隶属于,日期):20news-bydate.tar.gz –按时间分类; 不包含重复文档和新闻组名(18846 个文档)
第三个版本18828不包含重复文档,只有来源和主题:20news-18828.tar.gz– 不包含重复文档,只有来源和主题 (18828 个文档)
在sklearn中,该模型有两种装载方式:
第一种是sklearn.datasets.fetch_20newsgroups,返回一个可以被文本特征提取器(如sklearn.feature_extraction.text.CountVectorizer)自定义参数提取特征的原始文本序列;
第二种是sklearn.datasets.fetch_20newsgroups_vectorized,返回一个已提取特征的文本序列,即不需要使用特征提取器。
2.数据集下载
使用ptyhon进行下载:
from sklearn.datasets import fetch_20newsgroups
corpus_path = './corpora_data'
data_train = fetch_20newsgroups(data_home=corpus_path, subset='train', categories=categories, shuffle=True, random_state=0, remove=remove)
data_test = fetch_20newsgroups(data_home=corpus_path, subset='test', categories=categories, shuffle=True, random_state=0, remove=remove)
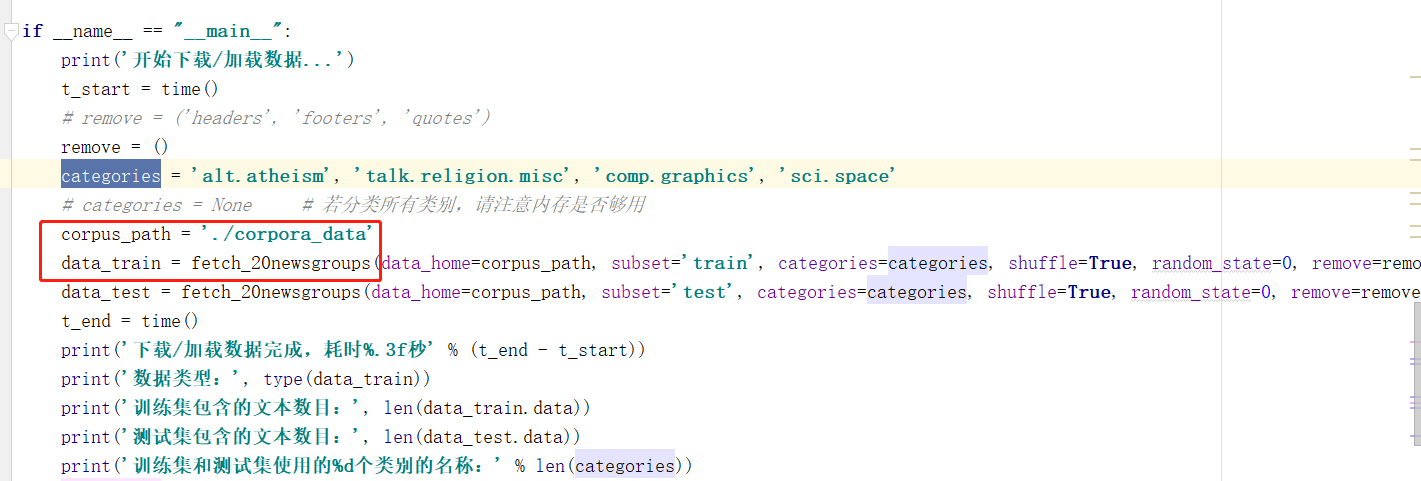
发现真的很卡。。。放弃
3.使用本地数据集
采取第二种方案:
1.下载文件
点击它给出的链接:20news-bydate.tar.gz –按时间分类; 不包含重复文档和新闻组名(18846 个文档)
2.路径修改
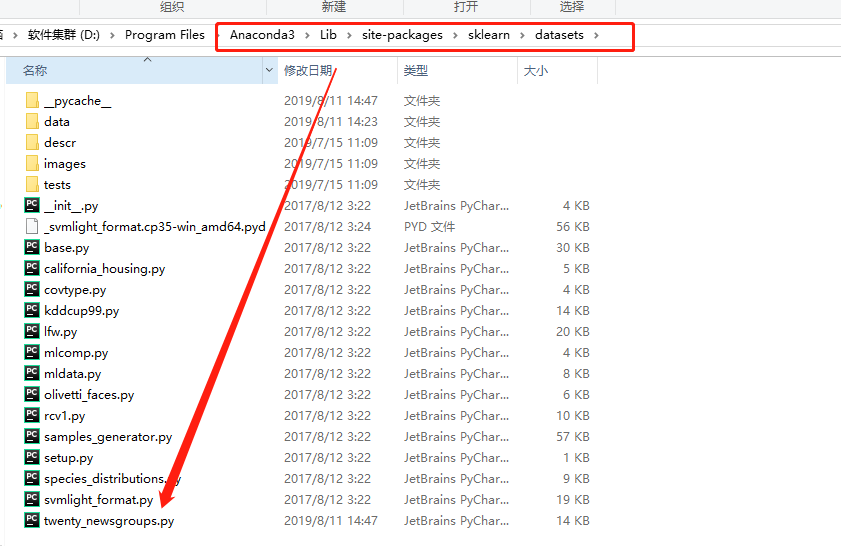
(1)下载后直接放在d:盘路径下
(2)
- 找到文件Anaconda3\Lib\site-packages\sklearn\datasets\twenty_newsgroups.py
- 修改把在下载的代码注销(红色),增加路径(蓝色)
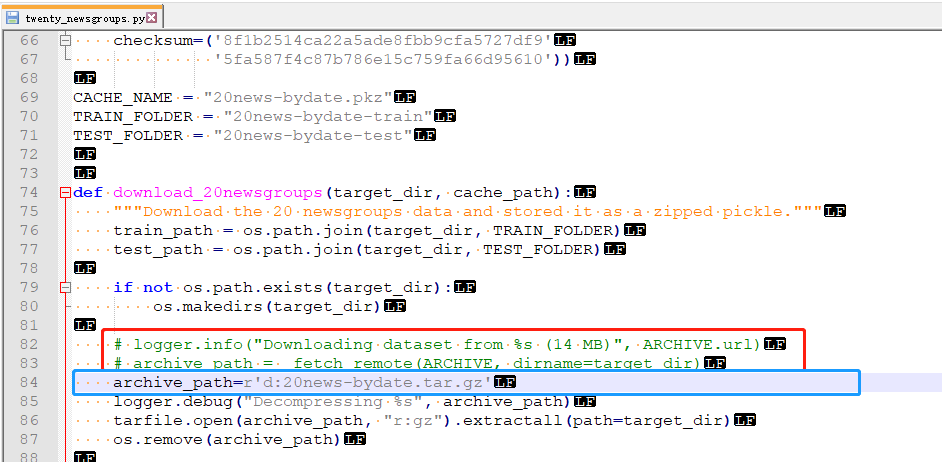
- 检查是否成功:如果在当前项目有如下路径则成功
Newsgroups数据集研究的更多相关文章
- Natural Language Generation/Abstractive Summarization
调研目的: 了解生成式文本摘要的常用技术和当前的发展趋势,明确当前项目有什么样的摘要需求,判断现有技术能否用于满足当前的需求,进一步明确毕业设计方向及其可行性 调研方向: 项目中需要用到摘要的地方以及 ...
- MLLib实践Naive Bayes
引言 本文基于Spark (1.5.0) ml库提供的pipeline完整地实践一次文本分类.pipeline将串联单词分割(tokenize).单词频数统计(TF),特征向量计算(TF-IDF),朴 ...
- 《mahout实战》
<mahout实战> 基本信息 原书名:Mahout in action 作者: (美)Sean Owen Robin Anil Ted Dunning Ellen Fr ...
- 2020厦门大学综述翻译:3D点云深度学习(Remote Sensiong期刊)
目录 摘要 1.引言: 2.点云深度学习的挑战 3.基于结构化网格的学习 3.1 基于体素 3.2 基于多视图 3.3 高维晶格 4.直接在点云上进行的深度学习 4.1 PointNet 4.2 局部 ...
- R语言重要数据集分析研究——需要整理分析阐明理念
1.R语言重要数据集分析研究需要整理分析阐明理念? 上一节讲了R语言作图,本节来讲讲当你拿到一个数据集的时候如何下手分析,数据分析的第一步,探索性数据分析. 统计量,即统计学里面关注的数据集的几个指标 ...
- R语言重要数据集分析研究——R语言数据集的字段含义
R语言数据集的字段含义 作者:马文敏 选择一种数据结构来储存数据 将数据输入或导入到这个数据结构中 数据集的概念 数据集通常是有数据结构的一个矩形数组,行表示规则,列表示变量. 不同的行业对数据集的行 ...
- R语言重要数据集分析研究—— 数据集本身的分析技巧
数据集本身的分析技巧 作者:王立敏 文章来源:网络 1.数据集 数据集,又称为资料集.数据集合或资料集合,是一种由数据所组成的集合. Data set(或dat ...
- R语言重要数据集分析研究——搞清数据的由来
搞清数据的由来 作者:李雪丽 资料来源:百度百科
- [转]最好用的 AI 开源数据集 Top 39:NLP、语音等 6 大类
原文链接 本文修正部分错误. 以下是精心收集的一些非常好的开放数据集,也是做 AI 研究不容错过的数据集. 标签解释 [经典]这些是在 AI 领域中非常著名.众所周知的数据集.很少有研究者或工程师没有 ...
随机推荐
- C# AE 通过要素类工作空间将shp路径string类型对象转换为IFeatureClass;
IWorkspaceFactory pWorkspaceFactory = new ShapefileWorkspaceFactoryClass();//打开shapefile工作空间openFile ...
- 应用安全 - PHP - CMS - EmpireCMS - 漏洞 - 汇总
2006 Empire CMS <= 3.7 (checklevel.php) Remote File Include Vulnerability Empire CMS Checklevel.P ...
- 浅谈Angularjs至Angular2后内置指令的变化
一.科普概要说明 我们常说的 Angular 1 是指 AngularJS: 从Angular 2 开始已经改名了.不再带有JS,只是单纯的 Angular: Angular 1.x 是基于JavaS ...
- spring boot 框架根據 sql 創建語句自動生成 MVC層類代碼
GITHUB: https://github.com/lin1270/spring_boot_sql2code 會自動生成model.mapper.service.controller. 代碼使用No ...
- [转帖]$PWD 和 $(pwd)
$PWD 和 $(pwd) https://blog.csdn.net/shaojwa/article/details/51894980 细节决定成败. 注意两个效果一样,但是注意大小写,PWD是 ...
- 格式化hdfs以及namnode没启动
先stop-all.sh 删除hdfs-site.xml中的这两个目录 然后删除core-site.xml 中的这个目录 然后格式化hdfs hdfs namenode -format 即可启动成功 ...
- acmsguru
acmsguru 101 - Domino 要求每两个相邻的多尼诺骨牌相对的数字相同,即做一个一笔画 #include<bits/stdc++.h> using namespace std ...
- Ruby学习中(条件判断, 循环, 异常处理)
一. 条件判断 详情参看:https://www.runoob.com/ruby/ruby-decision.html 1.详情实例(看看就中了) #---------------# # LOL场均人 ...
- win10 64支持承载网络
在intel官网找到对应型号的网卡驱动. 下载win7版本的,更新驱动.安装完毕之后还要在设备管理里面更新2019 7 30这个版本的驱动. 英特尔® PROSet/无线软件和面向 IT 管理员的驱动 ...
- Eslint报错整理与解决方法
1.‘Unexpected tab character’ 字面意思理解呢就是意想不到的制表符,当时出现的时候就是我习惯的使用Tab键去打空格,但是eslint默认不认可Tab,所以解决方法很简单: 在 ...