[大数据] hadoop全分布式安装
一、准备工作
在伪分布式的搭建基础上修改配置,搭建全分布式hadoop环境,伪分布式安装参照 hadoop伪分布式安装。
首先准备4台虚拟机,信息如下:
192.168.1.11 namenode1
192.168.1.12 datanode1
192.168.1.13 datanode2
129.168.1.14 datanode3
第一台namenode1用做NameNode节点,我们使用伪分布式安装好的环境(将其配置文件进行修改,并分发给其他3个节点)。
第二台datanode1用作第一台DataNode以及SecondaryNameNode。
第三台和第四台虚拟机,即datanode2和datanode3用作纯粹的Datanode节点。
在每台虚拟机上做如下基本操作:
1.配置各自的hostname(以namenode1为例)
vi /etc/hostname namenode1
2.配置主机映射
vi /etc/hosts 192.168.1.11 namenode1
192.168.1.12 datanode1
192.168.1.13 datanode2
192.168.1.14 datanode3
3.在namenode1上生成ssh公钥,并拷贝给其他节点
ssh-keygen -t rsa
ssh-copy-id -i /root/.ssh/id_rsa.pub root@namenode1
ssh-copy-id -i /root/.ssh/id_rsa.pub root@datanode1
ssh-copy-id -i /root/.ssh/id_rsa.pub root@datanode2
ssh-copy-id -i /root/.ssh/id_rsa.pub root@datanode3
4.保证每台虚拟机的JDK安装
[root@datanode1 ~]# jps
Jps
如果未安装JDK或未配置环境变量,请参照伪分布式安装中的步骤进行JDK的安装。
二、修改Hadoop配置文件
从伪分布式环境中,将hadoop包直接拷贝到namenode1的/opt目录下:
[root@namenode1 ~]# cd /opt/
[root@namenode1 opt]# ll
total
drwxr-xr-x root root Nov : hadoop-2.6.
这个hadoop包中的配置文件都是在伪分布安装时的配置。我们要对其进行一些修改:
1.备份伪分布式的配置文件:
[root@namenode1 etc]# cd /opt/hadoop-2.6./etc/
[root@namenode1 etc]# cp -r hadoop hadoop_pseudo/
2.修改core-site.xml
vi /opt/hadoop-2.6./etc/hadoop/core-site.xml <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://namenode1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/full</value>
</property>
</configuration>
3.修改hdfs-site.xml
vi /opt/hadoop-2.6./etc/hadoop/hdfs-site.xml <configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>datanode1:</value>
</property>
</configuration>
在这里,我们将SecondaryNameNode放在datanode1节点上,当然也可以用一台单独的虚拟机来运行。
4.修改slaves
vi /opt/hadoop-2.6./etc/hadoop/slaves datanode1
datanode2
datanode3
三、将修改好配置后的hadoop包分发给其余三个节点
scp -r /opt/hadoop-2.6. root@datanode1:/opt/
scp -r /opt/hadoop-2.6. root@datanode2:/opt/
scp -r /opt/hadoop-2.6. root@datanode3:/opt/
四、为所有节点的hadoop配置环境变量
当然也可以通过分发的形式:
scp /etc/profile root@datanode1:/etc/
scp /etc/profile root@datanode2:/etc/
scp /etc/profile root@datanode3:/etc/
在每台虚拟机上让环境变量生效:
. /etc/profile
五、初始化全分布式hadoop集群
在namenode1上运行:
[root@namenode1 opt]# hdfs namenode -format
// :: INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = namenode1/192.168.1.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.5
......
......
......
19/11/19 16:24:38 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at namenode1/192.168.1.11
************************************************************/
查看/var/hadoop下的文件:
[root@namenode1 name]# cd /var/hadoop/
[root@namenode1 hadoop]# ll
total
drwxr-xr-x root root Nov : full
# 此时存在格式化产生的namenode节点数据存放目录
cd /var/hadoop/full/dfs/name
而在其他三个节点上,此时还不存在此类目录,因为格式化的时候只会作用于NN,而要在启动集群的时候才会在DN上产生这类目录。
六、启动集群
start-dfs.sh
[root@namenode1 sbin]# start-dfs.sh
Starting namenodes on [namenode1]
namenode1: starting namenode, logging to /opt/hadoop-2.6./logs/hadoop-root-namenode-namenode1.out
datanode1: starting datanode, logging to /opt/hadoop-2.6./logs/hadoop-root-datanode-datanode1.out
datanode3: starting datanode, logging to /opt/hadoop-2.6./logs/hadoop-root-datanode-datanode3.out
datanode2: starting datanode, logging to /opt/hadoop-2.6./logs/hadoop-root-datanode-datanode2.out
Starting secondary namenodes [datanode1]
datanode1: starting secondarynamenode, logging to /opt/hadoop-2.6./logs/hadoop-root-secondarynamenode-datanode1.out
我们可以看到,nn启动在namenode1上,snn启动在datanode1上,其余dn启动在datanode1、datanode2、datanode3上。
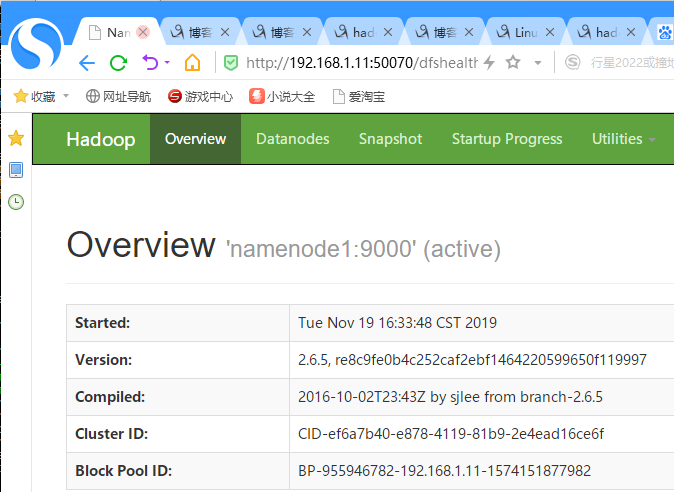
访问192.168.1.11:50070可以成功打开hadoop提供的web管理页面:
[大数据] hadoop全分布式安装的更多相关文章
- [大数据] hadoop伪分布式安装
注意:节点主机的hostname不要带"_"等字符,否则会报错. 一.安装jdk rpm -i jdk-7u80-linux-x64.rpm 配置java环境变量: vi + /e ...
- 搭建大数据hadoop完全分布式环境遇到的坑
搭建大数据hadoop完全分布式环境,遇到很多问题,这里记录一部分,以备以后查看. 1.在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 【Hadoop学习之三】Hadoop全分布式安装
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 hadoop3.1.1 全分布式就是集群,注意配置主机名. ...
- 我搭建大数据Hadoop完全分布式环境遇到的坑---hadoop: command not found
搭建大数据hadoop环境,遇到很多问题,这里记录一部分,以备以后查看. [遇到问题].在安装配置完hadoop以后,需要格式化namenode,输入指令:hadoop namenode -forma ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- 大数据系列之分布式数据库HBase-0.9.8安装及增删改查实践
若查看HBase-1.2.4版本内容及demo代码详见 大数据系列之分布式数据库HBase-1.2.4+Zookeeper 安装及增删改查实践 1. 环境准备: 1.需要在Hadoop启动正常情况下安 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
随机推荐
- 第七次java实验报告
Java实验报告 班级 计科二班 学号20188437 姓名 何磊 完成时间 2019/10/25 评分等级 实验四 类的继承 实验内容 )总票数1000张:(2)10个窗口同时开始卖票:(3)卖票过 ...
- 小菜鸟之JAVA面试题库1
四次挥手 客户端发送释放连接报文,关闭客户端到服务端的数据传输 服务端收到后,发送确认报文给客户端 服务端发送释放连接报文,关闭服务端到客户端的数据传输 客户端发送一个确认报文给服务端 ------- ...
- 四则运算计算器的微信小程序_2 运算
js文件: function isOperator(value) { var operatorString = '+-*/()×÷'; return operatorString.indexO ...
- Github 添加公匙 出错 (我真傻 真的)
网上一搜一箩筐 之前配了很多次都没问题 重装系统后配了半天总是提示 github Key is invalid. You must supply a key in OpenSSH public key ...
- Luogu P5354 [Ynoi2017]由乃的OJ
题目 这题以前叫睡觉困难综合征. 首先我们需要知道起床困难综合征怎么做. 大概就是先用一个全\(0\)和全\(1\)的变量跑一遍处理出每一位\(1\)和\(0\)最后会变成什么. 然后高位贪心:如果当 ...
- Zabbix 系统概述与部署
Zabbix是一个非常强大的监控系统,是企业级的软件,来监控IT基础设施的可用性和性能.它是一个能够快速搭建起来的开源的监控系统,Zabbix能监视各种网络参数,保证服务器系统的安全运营,并提供灵活的 ...
- loj 2392「JOISC 2017 Day 1」烟花棒
loj 答案显然满足二分性,先二分一个速度\(v\) 然后显然所有没有点火的都会往中间点火的人方向走,并且如果两个人相遇不会马上点火,要等到火快熄灭的时候才点火,所以这两个人之后应该在一起行动.另外有 ...
- FormData传输文件
function uploadfile() { var inputThis = $(this); var thisOrderId = inputThis.parent().attr("dat ...
- Linux下如何查看CPU型号、个数、核数、逻辑CPU数、位数、发行版本、内核信息、内存、服务器生产厂家
[原文链接]:http://blog.csdn.net/mdx20072419/article/details/7767809 http://blog.chinaunix.net/uid-224252 ...
- Python基础编程:字符编码、数据类型、列表
目录: python简介 字符编码介绍 数据类型 一.Python简介 Python的创始人为Guido van Rossum.1989年圣诞节期间,在阿姆斯特丹,Guido为了打发圣诞节的无趣,决心 ...