Java 8实战之读书笔记三:函数式数据处理
二、函数式数据处理
第4章 引入流
流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。
示例:
import static java.util.Comparator.comparing;
import static java.util.stream.Collectors.toList;
//为了利用多核架构并行执行这段代码换成.parallelStream()
List<String> lowCaloricDishesName = menu.stream()//.parallelStream()
.filter(d -> d.getCalories() < 400)
.sorted(comparing(Dish::getCalories))
.map(Dish::getName)
.collect(toList());把几个基础操作链接起来,来表达复杂的数据处理流水线(在filter后面接上sorted、 map和collect操作,如图所示),同时保持代码清晰可读
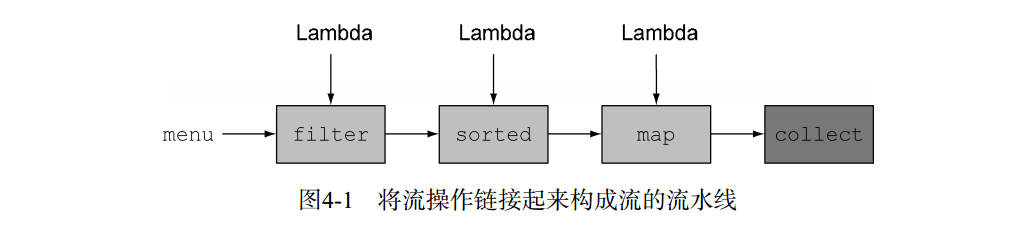
流的定义:从支持数据处理操作的源生成的元素序列,流操作具有流水线、内部迭代的特点。
关于内部迭代:
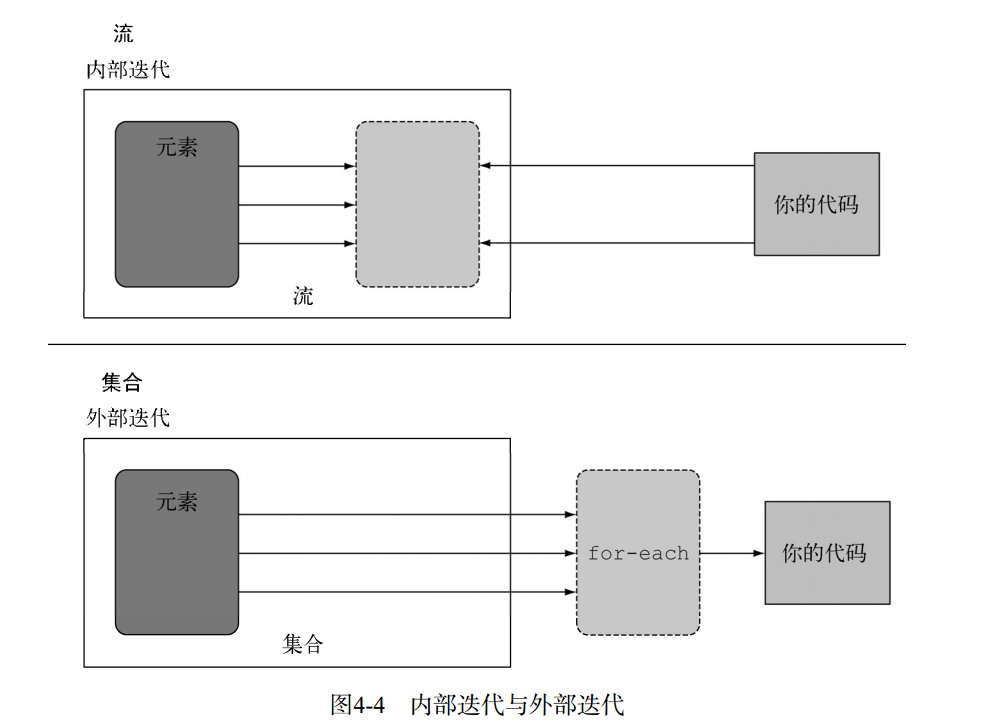
注意的是,和迭代器类似,流只能遍历一次。
流的操作分为中间操作、终端操作两种操作。
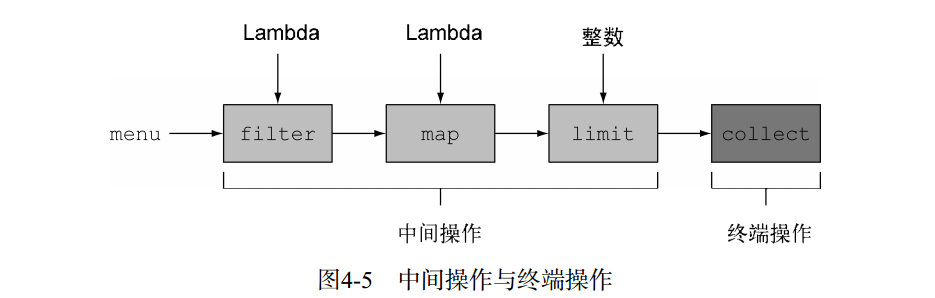
中间/终端操作具体的如下:
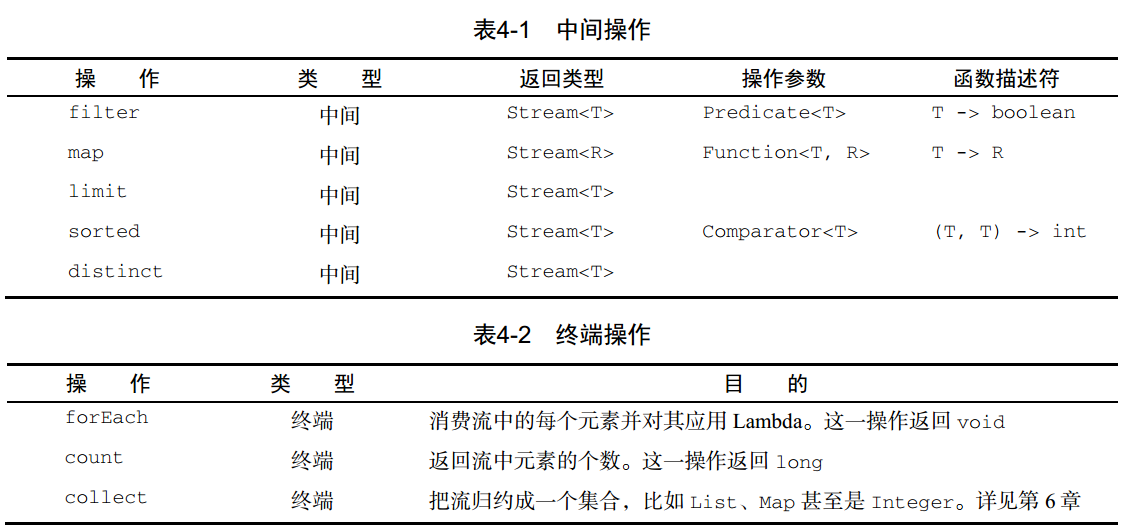
以下是你应从本章中学到的一些关键概念。
流是“从支持数据处理操作的源生成的一系列元素”。
流利用内部迭代:迭代通过filter、 map、 sorted等操作被抽象掉了。
流操作有两类:中间操作和终端操作。
filter和map等中间操作会返回一个流,并可以链接在一起。可以用它们来设置一条流水线,但并不会生成任何结果。
forEach和count等终端操作会返回一个非流的值,并处理流水线以返回结果。
流中的元素是按需计算的。
第5章 使用流
流的操作:
注意的是,强大的归约:reduce
示例:
List<Integer> numbers = Arrays.asList(4, 5, 3, 9);
int sum = numbers.stream().reduce(0, (a, b) -> a + b);
/**
reduce接受两个参数:
一个初始值,这里是0;
一个BinaryOperator<T>来将两个元素结合起来产生一个新值,这里我们用的是
lambda (a, b) -> a + b。
*/
// Integer类现在有了一个静态的sum方法来对两个数求和
int sum = numbers.stream().reduce(0, Integer::sum);
// 无初始值
// reduce还有一个重载的变体,它不接受初始值,但是会返回一个Optional对象:
Optional<Integer> sum = numbers.stream().reduce((a, b) -> (a + b));
// 另外,还可以通过Integer.max或者.min来获取最大值和最小值
Optional<Integer> max = numbers.stream().reduce(Integer::max);个人觉得归约是集大成者,第二参数填入不同的表达式就对应着不同的直接方法,如.sum(),.max()等等。
数值范围:(IntStream调用.boxed()把IntStream转化成Stream<Integer>)
IntStream.rangeClosed(1, 100);
由值创建流
Stream<String> stream = Stream.of("Java 8 ", "Lambdas ", "In ", "Action");
stream.map(String::toUpperCase).forEach(System.out::println);
你可以使用empty得到一个空流,如下所示:
Stream<String> emptyStream = Stream.empty();
由数组创建流
int[] numbers = {2, 3, 5, 7, 11, 13};
int sum = Arrays.stream(numbers).sum();
由文件生成流
long uniqueWords = 0;
try(Stream<String> lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset())){
uniqueWords = lines.flatMap(line -> Arrays.stream(line.split(" ")))
.distinct()
.count();
} catch(IOException e){}
由函数生成流:创建无限流
迭代:Stream.iterate(0, n -> n + 2);
生成:Stream.generate(Math::random);
这一章很长,但是很有收获!现在你可以更高效地处理集合了。事实上,流让你可以简洁地表达复杂的数据处理查询。此外,流可以透明地并行化。以下是你应从本章中学到的关键概念。
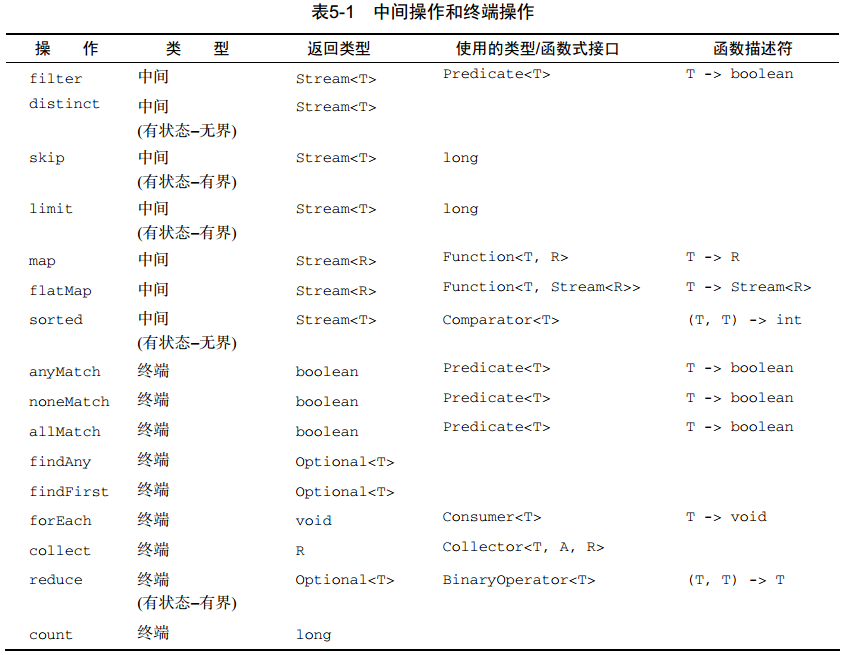
Streams API可以表达复杂的数据处理查询。常用的流操作总结在表5-1中。
你可以使用filter、 distinct、 skip和limit对流做筛选和切片。
你可以使用map和flatMap提取或转换流中的元素。
你 可 以 使 用 findFirst 和 findAny 方 法 查 找 流 中 的 元 素 。 你 可 以 用 allMatch 、noneMatch和anyMatch方法让流匹配给定的谓词。
这些方法都利用了短路:找到结果就立即停止计算;没有必要处理整个流。
你可以利用reduce方法将流中所有的元素迭代合并成一个结果,例如求和或查找最大元素。
filter和map等操作是无状态的,它们并不存储任何状态。 reduce等操作要存储状态才能计算出一个值。 sorted和distinct等操作也要存储状态,因为它们需要把流中的所有元素缓存起来才能返回一个新的流。这种操作称为有状态操作。
流有三种基本的原始类型特化: IntStream、 DoubleStream和LongStream。它们的操作也有相应的特化。
流不仅可以从集合创建,也可从值、数组、文件以及iterate与generate等特定方法创建。
无限流是没有固定大小的流。
第6章 用流收集数据


Collector接口
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
Function<A, R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}
/**
本列表适用以下定义。
T是流中要收集的项目的泛型。
A是累加器的类型,累加器是在收集过程中用于累积部分结果的对象。
R是收集操作得到的对象(通常但并不一定是集合)的类型。
*/以下是你应从本章中学到的关键概念。
collect是一个终端操作,它接受的参数是将流中元素累积到汇总结果的各种方式(称为收集器)。
预定义收集器包括将流元素归约和汇总到一个值,例如计算最小值、最大值或平均值。这些收集器总结在表6-1中。
预定义收集器可以用groupingBy对流中元素进行分组,或用partitioningBy进行分区。
收集器可以高效地复合起来,进行多级分组、分区和归约。
你可以实现Collector接口中定义的方法来开发你自己的收集器。
第7章 并行数据处理与性能
高效使用并行流
如果有疑问,测量。把顺序流转成并行流轻而易举,但却不一定是好事。我们在本节中已经指出,并行流并不总是比顺序流快。此外,并行流有时候会和你的直觉不一致,所以在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查其性能。
留意装箱。自动装箱和拆箱操作会大大降低性能。 Java 8中有原始类型流(IntStream、LongStream、 DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
有些操作本身在并行流上的性能就比顺序流差。特别是limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如, findAny会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用limit可能会比单个有序流(比如数据源是一个List)更高效。
还要考虑流的操作流水线的总计算成本。设N是要处理的元素的总数, Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。 Q值较高就意味着使用并行流时性能好的可能性比较大。
对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
要考虑流背后的数据结构是否易于分解。例如, ArrayList的拆分效率比LinkedList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用range工厂方法创建的原始类型流也可以快速分解。最后,你将在7.3节中学到,你可以自己实现Spliterator来完全掌控分解过程。
流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
还要考虑终端操作中合并步骤的代价是大是小(例如Collector中的combiner方法) 。如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
Java 8实战之读书笔记三:函数式数据处理的更多相关文章
- 《Java 8实战》读书笔记系列——第三部分:高效Java 8编程(四):使用新的日期时间API
https://www.lilu.org.cn/https://www.lilu.org.cn/ 第十二章:新的日期时间API 在Java 8之前,我们常用的日期时间API是java.util.Dat ...
- Java 8实战之读书笔记一:内容简介
本书的主要内容如下: 如何使用Java 8新增的强大特性 如何编写能有效利用多核架构的程序 重构.测试和调试 怎样高效地应用函数式编程 目录: 第一部分 基础知识 第1 章 为什么要关心Jav ...
- Java 8实战之读书笔记二:基础知识
好记性不如烂笔头,整理一些个人觉得比较重要的东西. 一.基础知识 第1章 为什么要关心Java 8 Java 8提供了一个新的API(称为"流", Stream),它支持许多处理数 ...
- Java 8实战之读书笔记四:高效Java 8编程
三.高效Java 8编程 第8章 重构.测试和调试 Java 8的新特性也可以帮助提升代码的可读性: 使用Java 8,你可以减少冗长的代码,让代码更易于理解 通过方法引用和S ...
- Java 8实战之读书笔记五:超越Java 8
四.超越Java 8 第13章 函数式的思考 下面是这一章中你应该掌握的关键概念. 从长远看,减少共享的可变数据结构能帮助你降低维护和调试程序的代价. 函数式编程支持无副作用的 ...
- 《R实战》读书笔记三
第二章 创建数据集 本章概要 1探索R数据结构 2使用数据编辑器 3数据导入 4数据集标注 本章所介绍内容概括例如以下. 两个方面的内容. 方面一:R数据结构 方面二:进入数据或者导入数据到数据结构 ...
- 《Java并发编程实战》读书笔记一 -- 简介
<Java并发编程实战>读书笔记一 -- 简介 并发的历史 并发的历史,也是人类利用有限的资源去提高生产效率的一个的例子. 设想现在有台计算机,这台计算机具有以下的资源: 单核CPU一个 ...
- 《Go并发编程实战》读书笔记-初识Go语言
<Go并发编程实战>读书笔记-初识Go语言 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在讲解怎样用Go语言之前,我们先介绍Go语言的特性,基础概念和标准命令. 一. ...
- 《Apache kafka实战》读书笔记-kafka集群监控工具
<Apache kafka实战>读书笔记-kafka集群监控工具 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如官网所述,Kafka使用基于yammer metric ...
随机推荐
- Spring Cloud Stream监听已存在的Queues/Exchanges
环境准备 rabbitmq已运行,端口5672,控制台web端口15672,用户名密码guest/guest 引入spring cloud stream依赖 compile('org.springfr ...
- R语言里面的循环变量
for (i in 1:10) { print("Hello world") } 以上这条命令执行完之后,变量i会被保存下来!并且,i的值将是10. 程序中有多处循环的时候要非常注 ...
- 【leetcode】1091. Shortest Path in Binary Matrix
题目如下: In an N by N square grid, each cell is either empty (0) or blocked (1). A clear path from top- ...
- vue对特殊特性的研究
key 预期:number | string key 的特殊属性主要用在 Vue 的虚拟 DOM 算法,在新旧 nodes 对比时辨识 VNodes.如果不使用 key,Vue 会使用一种最大限度减少 ...
- u盘被占用,无法弹出解决办法
方法1.把鼠标放到电脑屏幕最底部的中央,点击右键,点击 任务管理器 方法2.按:CTRL+ALT+ENTER(回车) 打开任务管理器,点击 进入性能后点击下方的:资源管理器 回到桌面,查看 ...
- windows系统如何查看物理cpu核数,内存型号等
首先,我们需要打开命令行模式,利用win+r键打开运行,输入cmd回车即会出现 然后在命令行界面输入wmic进入命令行系统管理执行脚本界面 然后我们通过cpu get *可以查看cpu的具 ...
- POJ 2391--Ombrophobic Bovines(最大流(拆点)+二分+最短路)
Ombrophobic Bovines Description FJ's cows really hate getting wet so much that the mere thought of g ...
- 【Java】Java URLDecoder异常Illegal hex characters in escape (%)
如果收到的HTTP请求参数(URL中的GET请求)中有一个字符串,是中文,比如“10%是黄段子”,服务器段使用URLDecoder.decode就会出现此异常.URL只能使用英文字母.阿拉伯数字和某些 ...
- 前端每日实战:124# 视频演示如何用纯 CSS 创作一只纸鹤
效果预览 按下右侧的"点击预览"按钮可以在当前页面预览,点击链接可以全屏预览. https://codepen.io/comehope/pen/xagoYb 可交互视频 此视频是可 ...
- legend3---1、meedu安装
legend3---1.meedu安装 一.总结 一句话总结: 视频的安装教程做主菜,辅以文档安装教程做配料,口感甚佳. 1.为什么不直接从github下载文件的发行版,而要选择composer方式安 ...