SQL基础之XML
1.XML数据类型
在SQL Server中xml数据类型可以用来保存xml文档,这个文档即可以是完整的xml文档和xml片段,这样开发者就可以像使用int数据类型一样来使用xml数据类型。不过xml数据类型是一种特殊的数据类型,它主要存在以下限制。
(1)除了string数据类型外,没有其他数据类型能够转换为xml数据类型。xml数量列不可用于group by语句中。
(2)xml列不得成为主键或外键的一部分,xml列不能指定为唯一的,可应用于xml列的内置标量函数只有isnull和coalesce。
(3)xml数据类型最多不能超过2gb,表中xml列不得超过32个,xml列不得加入到规则中。
2.XQuery
SQL Server为了更好的让开发者使用xml数据类型,于是便出现了xml查询语言XQuery,它可以查询结构化甚至是半结构化的xml数据。XQuery能够提供对xml数据的快速存储和查询,并且支持迭代以及对结果集进行排序等功能。下面是5个xml数据类型方法的sql语句。
use testDb
declare @myxml xml
set @myxml='<people>
<student id="201301">
<Name>王五</Name>
<Age>18</Age>
<Address>湖南</Address>
</student>
<student id="201302">
<Name>李一</Name>
<Age>20</Age>
<Address>湖北</Address>
</student>
</people>'
--query(QueryString)函数
select @myxml.query('/people/student/Name')
--结果: <Name>王五</Name><Name>李一</Name>
select @myxml.query('
for $ss in /people/student
where $ss/Age[text()]<22
return element Res
{
(attribute age{data($ss/Age[text()[1]])})
}')
--结果为: <Res age="18" /><Res age="20" />
/*
value(QueryString,SQLType),该方法对xml执行XQuery查询,返回SQL类型的标量值。
参数QueryString:字符串类型的XQuery表达式,它检索xml实例中的数据并且最多只返回一个值,否则将返回错误
参数SQLType:要返回的首选SQL类型,SQLType不能是XML数据类型、公共语言运行时用户定义类型、image、text、ntext或sql_variant数据类型。但SQLType可以是用户定义数据类型
*/
declare @result int
set @result=@myxml.value('(/people/student/@id)[1]','int')
select @result /*
exist(QueryString)方法, 它返回以下三种情况
1, 表示根据QueryString查询的结果集为非空,也就是说至少返回一个节点
0, 表示返回空结果集
null, 表示xml数据类型实例为null
*/
declare @ex xml
--如果不对@ex赋值,此时@ex为null,那么返回的结果将为null
--select @ex.exist('string') --返回NULL
set @ex=@myxml
--函数true()和false()分别返回布尔值true和false,注意只要是非空那么就将返回1select @ex.exist('true()') --返回1select @ex.exist('false()') --返回1select @ex.exist('/people') --返回1select @ex.exist('/people/haha') --返回0select @ex.exist('/people/student[@id[1]="201301"]') --返回1select @ex.exist('/people/student[@id[1]="201303"]') --返回0 --modify(XML_DML),使用此方法可以修改xml数据内容
--参数XML_DML表示XML数据操作语言,它是一条字符串,最终将根据这个字符串来操作xml数据
--xml数据类型的modify方法只能在update语句的set字句中使用,注意如果是针对null值调用modify方法将返回错误
set @myxml.modify('replace value of (/people/student/@id)[1] with "201303" ')
select @myxml
--此时第一个student节点的id将被改为201303 --语法: nodes(QueryString) as table(column), 如果要将xml数据类型拆分为关系数据,使用nodes方法将非常有效,它允许用户将标识映射到新行的节点
--参数QueryString: 如果查询表达式构造节点
--参数table(column): 结果行集的表名称和列名称
--获得所有student节点的数据,每一行显示一条student节点的数据
select T.c.query('.') as result from @myxml.nodes('/people/student') as T(c)
--将这些数据显示为一个表格
select T.c.value('(@id)[1]','int') as id,
T.c.value('(./Name)[1]','nvarchar(16)') as name,
T.c.value('(./Age)[1]','int') as age,
T.c.value('(./Address)[1]','nvarchar(16)') as address
from @myxml.nodes('/people/student') as T(c)
--nodes的结果如下图

3.FOR XML
通过使用for xml字句,我们可以检索系统中表的数据并自动生成xml格式。for xml在在SQL Server里一共有4种模式:RAW、AUTO、EXPLICIT、PATH,for xml子句可以用在顶级查询和子查询中,顶级for xml子句只能出现在select语句中,子查询中的for xml子句可以出现在insert、delete、update以及赋值语句中。
raw和auto是比较简单易理解的2种模式,raw模式将为select语句所返回的查询结果集中的每一行转换为带有通用标记符<row>或可能提供元素名称的xml元素。默认情况下行集中非null的列都将映射为<row>元素的一个属性。这样当使用select查询时,会对结果集进行xml的转换,它们将会被转为row元素的属性。下面是关于for xml的sql介绍,raw模式是这4种模式里最简单的一种。auto模式也是返回xml数据,它与raw的区别在于返回的xml数据中,不是以raw作为元素节点名,而是使用表名作为元素名。这个是最明显的区别,除此之外,auto模式的结果集还可以形成简单的层次关系。
select teacherId,teacherName from teacher where teacherSex='女' for xml raw
--结果:<row teacherId="4" teacherName="谢一"/>
-- <row teacherId="5" teacherName="罗二"/>
select teacherId,teacherName from teacher where teacherSex='女' for xml auto
--结果:<teacher teacherId="4" teacherName="谢一"/>
-- <teacher teacherId="5" teacherName="罗二"/> select student.id,student.name,teacher.teacherId,teacher.teacherName from student inner join teacher on student.teacherId=teacher.teacherId
--结果: 10 小李 1 王静
-- 11 小方 2 李四
select student.id,student.name,teacher.teacherId,teacher.teacherName
from student inner join teacher on student.teacherId=teacher.teacherId for xml raw
--结果: <row id="10" name="小李 " teacherId="1" teacherName="王静" />
-- <row id="11" name="小方 " teacherId="2" teacherName="李四" />
select student.id,student.name,teacher.teacherId,teacher.teacherName
from student inner join teacher on student.teacherId=teacher.teacherId for xml auto
/* 生成了嵌套关系
<student id="10" name="小李 ">
<teacher teacherId="1" teacherName="王静" />
</student>
<student id="11" name="小方 ">
<teacher teacherId="2" teacherName="李四" />
</student>
*/
explicit比较不好理解,我自己感觉学sql和学C#是两个完全不同的思维,sql学起来是一种有点难受的感觉,而C#就算钻得很深也学得很爽。首先在数据这个角度看,使用explicit模式和使用auto模式都是相同的数据,而且也可以得到相同的层级效果。接下来就是explicit和auto最明显的区别,也可以说是explicit的优点,使用explicit模式的时候我们可以以一种更加灵活的方式指定层级关系,并且可以自己指定元素的名称。当然explicit不像auto和raw那样就方便的加在语句后面,如果你这样做会报错:"FOR XML EXPLICIT 要求第一列包含代表 XML 标记 ID 的正整数"或"FOR XML EXPLICIT要求第二列包含NULL或代表XML父标记ID的非负整数"。这2个错误中,如果第一列不为整数类型那就会出现第一个错误,若第一列为整数那就会出现第二个错误。总之,报错的本质就是缺少2列数据,这2列数据正是错误中提示的“包含代表XML标记ID的正整数”和“包含NULL或代表XML父标记ID的非负整数”。XML标记ID指的是层级关系中,这段select所指定的层级。XML父标记则是你这个select层级的父级元素ID,这样根据标记ID和父标记ID来确定这段结果在xml中的位置。
select distinct 1 as Tag,
null as Parent,
student.id as [student!1!学生ID],
student.name as [student!1!学生姓名],
null as [teacher!2!老师ID],
null as [teacher!2!老师姓名]
from student,teacher where student.teacherId=teacher.teacherId
union all
select 2 as Tag,
1 as parent,
student.id,
student.name,
teacher.teacherId,
teacher.teacherName
from student,teacher where student.teacherId=teacher.teacherId

这是没有加for xml的查询结果,下面是添加了for xml explicit的sql和结果。
select distinct 1 as Tag,
null as Parent,
student.id as [student!1!学生ID],
student.name as [student!1!学生姓名],
null as [teacher!2!老师ID],
null as [teacher!2!老师姓名]
from student,teacher where student.teacherId=teacher.teacherId
union all
select 2 as Tag,
1 as parent,
student.id,
student.name,
teacher.teacherId,
teacher.teacherName
from student,teacher where student.teacherId=teacher.teacherId
for xml explicit

上面这段xml是根据第一个查询结果集生成的,现在最关键的疑问就是如何根据这些数据生成xml?首先要深刻的记住生成xml时是按照结果集中的顺序一行一行开始生成的。由于第一行Parent为NULL也就是说第一行数据为顶级元素,因此执行完第一条结果集的时候此时xml中的内容为:
<student 学生ID="10" 学生姓名="小李 " />
接下来执行第二条结果集,此时仍然是顶级元素,于是又生成了一条xml节点,此时xml中的内容为:
<student 学生ID="10" 学生姓名="小李 " />
<student 学生ID="11" 学生姓名="小方 ">
接下来执行第三条结果集,现在Parent为1,Tag为2,说明这个结果集是Tag为1的子元素,于是便生成了teacher节点并且在上一个student父节点中,接下来又是一个子节点于是最终的效果就是添加了2个teacher节点并且这2个节点在第二个student父节点中:
<student 学生ID="10" 学生姓名="小李 " />
<student 学生ID="11" 学生姓名="小方 ">
<teacher 老师ID="1" 老师姓名="王静" />
<teacher 老师ID="2" 老师姓名="李四" />
</student>
但是,这个结果是错误的!因为是一个学生对应一个老师,而不是像显示xml结果中一个student包含2个teacher节点,导致这个现象产生的最主要因素就是我前面提到的顺序,xml的生成是根据结果集中的行数据一行一行生成的,为此我们需要在结果集上进行一个排序。要达到的效果应该是下面这样的:
有了这个正确顺序的结果集,那么正确的xml就是这样的:
<student 学生ID="10" 学生姓名="小李 ">
<teacher 老师ID="1" 老师姓名="王静" />
</student>
<student 学生ID="11" 学生姓名="小方 ">
<teacher 老师ID="2" 老师姓名="李四" />
</student>
笔者是一个喜欢尝鲜的人,很巧,课本和msdn上举的都是2个层级的例子,学习过程中在我学数据库建的表上也是写了2个select,于是我想尝试3个层级,sql如下。
select distinct 1 as Tag,
null as Parent,
student.id as [student!1!学生ID],
student.name as [student!1!学生姓名],
null as [teacher!2!老师ID],
null as [teacher!2!老师姓名],
null as [地址!3!老师地址]
from student,teacher where student.teacherId=teacher.teacherId
union all
select 2 as Tag,
1 as parent,
student.id,
student.name,
teacher.teacherId,
teacher.teacherName,
null
from student,teacher where student.teacherId=teacher.teacherId
union all
select 3 as Tag,
2 as parent,
null,
null,
null,
null,
teacher.teacherAddress
from student,teacher where student.teacherId=teacher.teacherId
order by [student!1!学生ID],[teacher!2!老师ID]
for xml explicit
这样写是有点问题的,因为order by那个地方是直接用的上面的order by字句,xml中的顺序应该会乱掉,但我没想到一执行就报错了。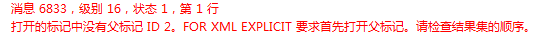
错误提示意思是说我没有打开父标记ID2,刚开始我真不明白这个打开是什么意思,仔细揣摩错误提示后发现本质原因了,下面是我不添加for xml的结果集,从中可以看到第一条数据tag为3,parent为2,此时xml文档中还没有生成ID为2的父节点,也就是说生成xml时必须已经存在父节点才可以继续生成,否则会报错。
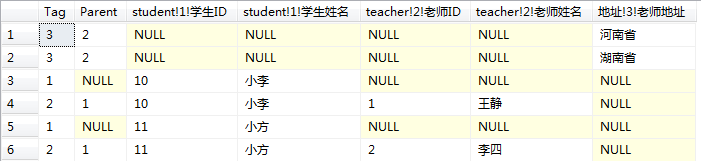
于是我开始进行顺序设置,但试了多种总是不可以。让我们再来观察这个结果集,如果要达到正确的效果那么tag为3的这2条数据应该是分别在2个tag为2的下面,可是tag为3的这一行只有地址这一列数据,无论怎么进行order by这2行数据都是挨着一起的,因此绝不可能达到正确的效果。
不过这让我对explicit的使用有一个更深刻的体会,说实话它并不是很好用,因为要得到正确的效果必须得有一个正确的顺序,而这个正确的顺序不仅仅体现在order by字句里。在进行select时,顶级元素需要查找出部分数据,其余数据设置为null,在进行二级select时,应该在顶级元素查找的基础上增加二级元素所需要的,接着第三级元素应该在第二级元素的基础上增加第三级所需要查找的元素。这么做的原因只有一个,就是进行order by时能够正确的排序,读到这里你是否已经想到如何设计才能让上面的结果集是一个正确的顺序呢?sql如下。
select distinct 1 as Tag,
null as Parent,
student.id as [student!1!学生ID],
student.name as [student!1!学生姓名],
null as [teacher!2!老师ID],
null as [teacher!2!老师姓名],
null as [地址!3!老师地址]
from student,teacher where student.teacherId=teacher.teacherId
union all
select 2 as Tag,
1 as parent,
student.id,
student.name,
teacher.teacherId,
teacher.teacherName,
null
from student,teacher where student.teacherId=teacher.teacherId
union all
select 3 as Tag,
2 as parent,
student.id,
student.name,
teacher.teacherId,
teacher.teacherName,
teacher.teacherAddress
from student,teacher where student.teacherId=teacher.teacherId
order by [student!1!学生ID],[teacher!2!老师ID]
for xml explicit

explicit虽然功能更加强大,但是使用起来需要写很长的sql并且还可能出错。为了解决这个问题四大模式中压轴的path模式就要出场了,在path中列名很重要,因为列名或列别名将被作为XPath表达式来处理,而这个表达式则指明了这一列在xml中位置。也就是说XPath表达式代替了explicit复杂的功能,只需要根据XPath中提供的类型、节点名称和层次结构即可生成具有层次结构的xml数据。使用path模式会自动为我们生成的xml在原有顶级元素之上再添加一个顶级元素<row>,如果不想要这个顶级元素可在path中写上空字符串即可。具体的实现就如文件夹路径一样,我们可使用“/”来进行层级的指定,在这一条字符串中的最后一个字符串中,如果仅仅只是字符串即未添加“@”那么将会生成节点,如果添加“@”那么则表示是属性,当然关于path模式笔者也还没有研究完内容还有很多。具体sql如下,还是实现上面的效果,但是使用的是极其简单方便的path模式。
select student.id as 'student/@学生ID',
student.name as 'student/@学生姓名',
teacher.teacherId as 'student/teacher/@老师ID',
teacher.teacherName as 'student/teacher/@老师姓名',
teacher.teacherAddress as 'student/teacher/地址/@老师地址'
from student,teacher where student.teacherId=teacher.teacherId
for xml path('')
SQL基础之XML的更多相关文章
- ASP.NET实现二维码 ASP.Net上传文件 SQL基础语法 C# 动态创建数据库三(MySQL) Net Core 实现谷歌翻译ApI 免费版 C#发布和调试WebService ajax调用WebService实现数据库操作 C# 实体类转json数据过滤掉字段为null的字段
ASP.NET实现二维码 using System;using System.Collections.Generic;using System.Drawing;using System.Linq;us ...
- (2.16)Mysql之SQL基础——函数
(2.16)Mysql之SQL基础——函数 关键词:mysql函数,mysql自定义函数,mysql聚合函数,mysql字符串函数,mysql数值函数 1.自定义函数 -- (1)一般形式 creat ...
- 信安周报-第02周:SQL基础
信安之路 第02周 Code:https://github.com/lotapp/BaseCode/tree/master/safe 前言 本周需要自行研究学习的任务贴一下: 1.概念(推荐) 数据库 ...
- SQL基础篇(MICK)
SQL基础教程(Mick) 数据库和SQL C:\PostgreSQL\9.5\bin\psql.exe -U postgres -d shop 数据库的基本概念 数据库(DB):将大量数据保存起来, ...
- 《SQL基础教程》+ 《SQL进阶教程》 学习笔记
写在前面:本文主要注重 SQL 的理论.主流覆盖的功能范围及其基本语法/用法.至于详细的 SQL 语法/用法,因为每家 DBMS 都有些许不同,我会在以后专门介绍某款DBMS(例如 PostgreSQ ...
- 常见SQL语句和SQL基础知识
引自:http://blog.csdn.net/u012467492/article/details/46790205 SQL语句考察(一) 1.查询出每门课都大于80 分的学生姓名 name k ...
- [SQL] SQL 基础知识梳理(一)- 数据库与 SQL
SQL 基础知识梳理(一)- 数据库与 SQL [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902856.html 目录 What's 数据库 ...
- [SQL] SQL 基础知识梳理(二) - 查询基础
SQL 基础知识梳理(二) - 查询基础 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5904824.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(三) - 聚合和排序
SQL 基础知识梳理(三) - 聚合和排序 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5926689.html 序 这是<SQL 基础知识梳理 ...
随机推荐
- MySQL基础学习(一) 命令行命令
1. 命令行登录 mysql -uroot -p 按照提示输入密码 常用登录选项 -u 指定用户 -p 密码 -h 数据库所在主机 -P 端口 -D 指定数据库 2.命令行退出 exit quit \ ...
- 高性能MySQL笔记 第4章 Schema与数据类型优化
4.1 选择优化的数据类型 通用原则 更小的通常更好 前提是要确保没有低估需要存储的值范围:因为它占用更少的磁盘.内存.CPU缓存,并且处理时需要的CPU周期也更少. 简单就好 简 ...
- setTimeout()与setInterval()——走马灯效果
JavaScript中的setTimeout()与setInterval()都是指延时执行某一操作. 但setInterval()指每隔指定时间执行某操作,会循环不断地执行该操作:setTimeout ...
- 实现台式机redhat6.4无线网卡上网RTL8188CUS
台式机装了红帽6.4,无法无线wlan上网,特此用usb无线网卡设置 输入命令lsusb,可以看到USB无线网卡是 Realtek Semiconductor Corp. RTL8188CUS 8 ...
- BZOJ4152The Captain[DIjkstra]
4152: [AMPPZ2014]The Captain Time Limit: 20 Sec Memory Limit: 256 MBSubmit: 700 Solved: 266[Submit ...
- Concurrency::task(C++)
先看一个例子 #include <ppltasks.h> #include <iostream> using namespace Concurrency; using name ...
- Windows英文版GitHub客户端使用操作流程图文攻略教程现没中文版
Git是一个分布式的版本控制系统,最初由Linus Torvalds编写,用作Linux内核代码的管理.作为一个程序员,我们需要掌握其用法. 作为开源代码库以及版本控制系统,Github目前拥有140 ...
- 搞netty
开始搞netty了 查了下资料 在使用NIO 的时候,最好不要配置 SO_LINGER,假设设置了该參数,在 close的时候如缓冲区有数据待写出,会抛出 IOException. // 在netty ...
- java 24 - 8 GUI之创建四则运算计算器(未校验版)
这个是用NetBeans软件制作的,因为这个软件制作GUI任务比较方便 通过拖拽控件生成的窗体:(红色的名称是更改后的控件名称) 拉拽好布局后,要进行的步骤: A:更改想要进行操作的控件的名称(右键控 ...
- BZOJ 1304: [CQOI2009]叶子的染色
1304: [CQOI2009]叶子的染色 Time Limit: 10 Sec Memory Limit: 162 MBSubmit: 566 Solved: 358[Submit][Statu ...