经典排序方法 python
数据的排序是在解决实际问题时经常用到的步骤,也是数据结构的考点之一,下面介绍10种经典的排序方法。
首先,排序方法可以大体分为插入排序、选择排序、交换排序、归并排序和桶排序四大类,其中,插入排序又分为直接插入排序、二分插入排序和希尔排序,选择排序分为直接选择排序和堆排序,交换排序分为冒泡排序和快速排序,桶排序以基数排序和计数排序为代表。这些排序方法的时间复杂度和空间复杂度分别如下表所示。
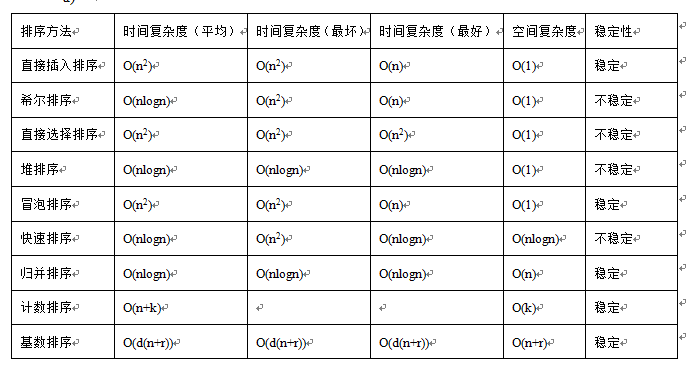
排序方法的稳定性是这样定义的:在待排序序列中如果存在a[i]和a[j],a[i]=a[j]&&i<j,如果排序后仍然符合a[i]=a[j]&&i<j,即它们的前后相对位置关系没有改变,该排序算法就是稳定的。
(1)直接插入排序
插入排序的基本思想是将数据插入合适的位置。如下所示序列[6,8,1,4,3,9,5,0],以升序排列为例。
a.6<8,符合升序
b. 8>1,不符合要求,改变1的位置。首先比较1和8,1更小,交换1和8的位置,序列成为[6,1,8,4,3,9,5,0],然后继续比较1和6,1更小,交换1和6的位置,序列成为[1,6,8,4,3,9,5,0],注意此时前三个值已经符合升序的要求。
c. 8>4,不符合要求,改变4的位置,按照上面的方法,依次与前面的值比较,分别与8和6交换位置,当比较到1时,1<4,不用交换位置。此时序列成为[1,4,6,8,3,9,5,0]
d.重复上满的操作,直到整个序列遍历完成。

因此,插入排序实际上是保证遍历过的序列是有序的,然后将下一个访问到的值,通过比较和交换位置,插入到这个有序序列中,当所有的值都被访问过后,整个序列就是有序的了。所以这种方法是稳定,空间复杂度为O(1),最好的时间复杂度为O(n),代码如下
def insert_sort(arr):
for i in range(len(arr)-1):
if arr[i+1]<arr[i]:#如果arr[i+1]较小,将其插入到前面升序序列中
for j in range(i+1,0,-1):
if arr[j]<arr[j-1]:#依次将大于arr[i+1]的值向后移动,直到找到不大于arr[i+1]的值
arr[j-1],arr[j]=arr[j],arr[j-1]
else:
break
return arr
(2) 二分插入排序
二分插入排序的思想与直接插入排序相同,只是在将数据插入有序序列时,采用了二分查找的思想,即先于中间位置的值进行比较,以缩短查找的时间。代码如下
def BinaryInsert_sort(arr):
for i in range(1,len(arr)):
if arr[i]<arr[i-1]:
left,right=0,i-1
while left<right:#最终right位置的值是有序序列中第一个不大于arr[i]的值
mid=left+(right-left)//2
if arr[i]<arr[mid]:#
right=mid
else:
left=mid+1
for j in range(i,right,-1):
arr[j],arr[j-1]=arr[j-1],arr[j]
return arr
(3) 希尔排序
希尔排序建立在直接插入排序的基础上,假设序列长度为n,先取一个小于n的整数d1,序列中所有距离为d1的数据为一组,如下图中,以2为i增量,1,4,5为一组,8,3,0为一组,1,9为1组,然后在组内进行直接插入排序,然后取整数d2,d2<d1,重复上面的步骤,直到增量减少为1。一般的初次取序列的一半为增量,以后每次减半。这样通过相隔增量的数,使得数移动时能跨过多个元素,加快速度。代码如下

def Hill_sort(arr):
d=len(arr)//2
while(d>=1):
for i in range(len(arr)//d):
for j in range(i,len(arr)-d,d):
if arr[j+d]<arr[j]:
for k in range(j+d,i,-d):
if arr[k]<arr[k-d]:
arr[k],arr[k-d]=arr[k-d],arr[k]
d=d//2
return arr
因为希尔排序跨距离访问元素,因此不稳定。空间复杂度为O(1),最好的时间复杂度为O(n)。
(4) 直接选择排序
选择排序的思想是每次从无序的序列中选择最大或最小的值,并与第一个位置的值交换。如序列l,如果是升序排列,第一次找出l的最小值与l[0]交换,第二次找出l[1:]最小的值,与l[2]交换,以此类推,代码如下。
def select_sort(arr):
for i in range(len(arr)-1):
minnum=arr[i]
m=i
for j in range(i+1,len(arr)):
if arr[j]<minnum:
minnum=arr[j]
m=j
arr[i],arr[m]=arr[m],arr[i]
return arr
直接选择排序是稳定的,空间复杂度为O(1),时间复杂度恒定为O(n2),因为原序列是否有序不会影响选择排序的步骤。
(5) 堆排序
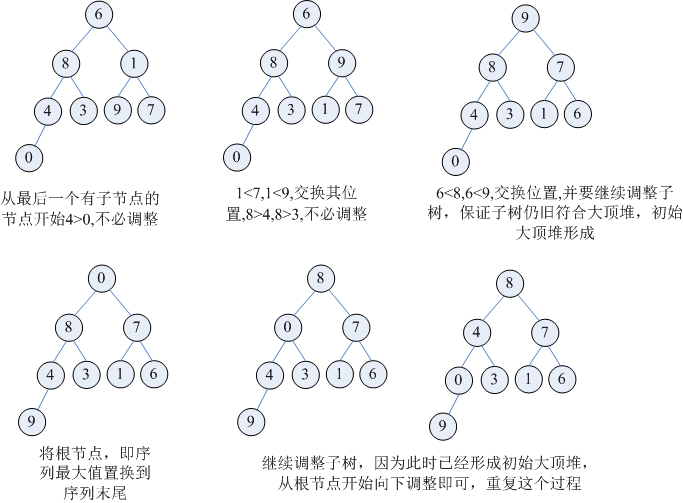
堆排序用到了大顶堆和小顶堆的概念。大顶堆是父节点最大的二叉树,即arr[i]>=arr[2*i+1]&&arr[i]>=arr[2*i-1];小顶堆是父节点的值最小的二叉树,即arr[i]<=arr[2*i+1]&&arr[i]<=arr[2*i-1]。 以升序排序为例,首先建立初始最大堆,以某个节点为入口,向下调整其子节点,使其符合大顶堆的特点。建立初始大顶堆的过程会重复调整一些节点,是因为父节点和子节点的交换,会影响以子节点为根节点的子树,如图中,[9,1,7]子树原符合要求,6和9交换后,[6,1,7]不符合要求,就要再次调整该子树。初始大顶堆建立之后,将根节点的值置换到序列末尾,然后重新调整前面的序列,这时只从根节点向下调整即可,因为初始大顶堆已经形成,如图中,即便交换了0和4的位置,父节点8也仍旧是最大的。
def heap_sort(arr):
def adjust(arr,node,maxid):
root=node
while True:
child=2*root+1
if child>maxid:
return
child=child+1 if arr[child+1]>arr[child] and child+1<maxid else child#child是两个孩子中值较大的一个
if arr[root]<arr[child]:
arr[root],arr[child]=arr[child],arr[root]
root=child
else:
return
first=len(arr)//2-1
for node in range(first,-1,-1):
adjust(arr,node,len(arr)-1)
for maxid in range(len(arr)-1,0,-1):
arr[0],arr[maxid]=arr[maxid],arr[0]
adjust(arr,0,maxid-1)
堆排序不稳定,空间复杂度为O(1),但时间复杂度恒定为O(nlogn)。
(6) 冒泡排序
交换排序即通过交换元素位置,使序列有序。冒泡排序是最简单的交换排序,每次将最大值/最小值依次交换到序列末尾。冒泡排序是稳定的,空间复杂度为O(1),时间复杂度最好为O(n)。
def bubble_sort(arr):
for i in range(len(arr)-1): # 这个循环负责设置冒泡排序进行的次数
for j in range(len(arr)-i-1): # j为列表下标
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr
(7) 快速排序
快速排序可以说是使用频率和考察频率最高的排序方法。快速排序的基本思想是以序列中的某个值为标准,大于该值的被放在右边,小于该值放在左边,然后再继续对该值左右两两边的序列重复此步骤,思想很简单,代码如下。
import random
def quick_sort(arr,start,end):
if end-start<=0: return
index=random.randrange(start,end+1)
print(index)
arr[end],arr[index]=arr[index],arr[end]
small=start-1
for i in range(start,end):
if arr[i]<arr[end]:
small+=1
if small!=i:#如果small与i不相同,说明有大于arr[end]的值出现,small记录的是分界线的位置
arr[i],arr[small]=arr[small],arr[i]
small+=1
arr[end],arr[small]=arr[small],arr[end]
print(arr)
quick_sort(arr,start,small-1)
quick_sort(arr,small+1,end)
对于python,有一种更加简单明了的实现方式
def qsort(arr):
if len(arr) <= 1: return arr
return qsort([lt for lt in arr[1:] if lt < arr[0]]) + arr[0:1]+ qsort([ge for ge in arr[1:] if ge >= arr[0]])
快速排序并没有创建新的数组,但由于实现过程中利用了函数的递归调用,需要堆栈空间,所以空间复杂度为O(nlogn),时间复杂度最好为O(nlogn)。
(8) 归并排序
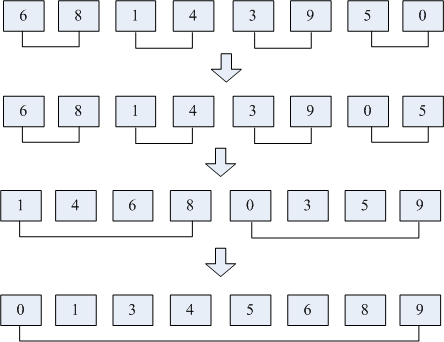
归并排序采用分而治之的思想,将序列分为多个小的序列,对小的序列排序之后,将小序列合并为大的序列,过程如下图所示。
代码如下
def merge_sort(arr,start,end):
def merging(l1,l2,lnew=[]):
i,j=0,0
while(i<len(l1) and j<len(l2)):
if l1[i]<l2[j]:
lnew.append(l1[i])
i+=1
else:
lnew.append(l2[j])
j+=1
if i<len(l1):
for num in l1[i:]:
lnew.append(num)
if j<len(l2):
for num in l2[j:]:
lnew.append(num)
return lnew
if end-start>1:#分
mid=start+(end-start)//2
merge_sort(arr,start,mid)
merge_sort(arr,mid,end)
arr[start:end]=merging(arr[start:mid],arr[mid:end],[])#治
return arr
归并排序需要新的数组存放合并后的序列,空间复杂度为O(n),时间复杂度恒定为O(nlogn),是稳定的。
(9) 计数排序
桶排序实际上是一类排序方法的总称。桶排序的思想是将所有数据按照一定的映射关系放到一定数量的桶中,将每个桶里的数据排序,再将所有的桶组合起来,所以不同的映射关系下可以产生不同的桶排序,并且桶排序是基于其他排序算法的,桶内数据的排序需要使用其他排序算法。计数排序和基数排序是桶排序的两种代表。
计数排序是采用的映射关系是最直接的f[i]=i,即一个桶里的数字都是相同的,因此没有桶内排序的步骤。具体过程为,1.找出待排序的数组中最大和最小的元素 2.统计数组中每个值为i的元素出现的次数,存入数组C的第i项,这时映射的过程 3.对所有的计数累加,C[i]的含义即是在数组中小于i的元素个数,即为排序后i应放的位置 4.反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个 元素就将C(i)减去1。代码如下
def count_sort(arr):
crr=[]
m=max(arr)+1
ll=len(arr)
ans=[]
for i in range(ll):#用于存放排序后的数组
ans.append(None)
for i in range(m):#桶
crr.append(0)
for num in arr:#映射的过程,计数
crr[num]+=1
for i in range(1,m):#计数累加
crr[i]=crr[i-1]+crr[i]
for num in arr:#反向填充数组
ans[crr[num]-1]=num
crr[num]-=1
return ans
(10) 基数排序
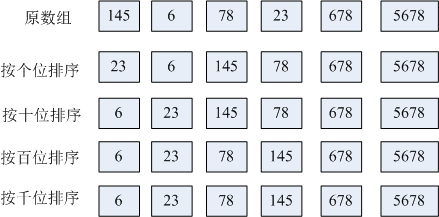
基数排序的映射方法是按照数据特定位上数字放入不同的桶中, 将序列中的数组按照个位放到不同的桶中,然后按照个位0~9的顺序依次取出,再按照十位放到不同的桶中,…….直到达到数据的最高位,最后一次将数据取出时,排序完成,例如:
实现代码
def radix_sort(arr):
def compare(basis,arr):#以数组basis为依据的插入排序
for i in range(1,len(basis)):
if basis[i]<basis[i-1]:
for j in range(i,0,-1):
if basis[j-1]>basis[j]:
basis[j],basis[j-1]=basis[j-1],basis[j]
arr[j],arr[j-1]=arr[j-1],arr[j]
else:
break
upnum=max(arr)
tmp=1
while(tmp<upnum):
basis=[num//tmp%10 for num in arr]
compare(basis,arr)
tmp*=10
return arr
注意基数排序在桶内排序时,一定要采用稳定的排序方法,这样才可以利用之前的排序结果,否则之前的排序是无意义的。
经典排序方法 python的更多相关文章
- Python中经典排序方法
数据的排序是在解决实际问题时经常用到的步骤,也是数据结构的考点之一,下面介绍10种经典的排序方法. 首先,排序方法可以大体分为插入排序.选择排序.交换排序.归并排序和桶排序四大类,其中,插入排序又分为 ...
- 十大经典排序算法(Python,Java实现)
参照:https://www.cnblogs.com/wuxinyan/p/8615127.html https://www.cnblogs.com/onepixel/articles/7674659 ...
- 经典排序的python实现
具体原理我这里就不解释了,可以查看数据结构课本或者百度百科 这里只给出相应的代码(很简洁) 1 __author__ = "WSX" class sort: def __init_ ...
- 排序方法——python
1.冒泡排序法(Bubble Sort) 比较相邻的元素.如果第一个比第二个大,就交换它们两个: 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数: 针对所 ...
- python3 经典排序方法
1.插入排序: def nsert_sort(list): for i in range(len(list)): for j in range(i): if list[i] < list[j]: ...
- 基于python的七种经典排序算法
参考书目:<大话数据结构> 一.排序的基本概念和分类 所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作.排序算法,就是如何使得记录按照要求排列的方法. ...
- 经典排序算法总结与实现 ---python
原文:http://wuchong.me/blog/2014/02/09/algorithm-sort-summary/ 经典排序算法在面试中占有很大的比重,也是基础,为了未雨绸缪,在寒假里整理并用P ...
- 经典排序算法及python实现
今天我们来谈谈几种经典排序算法,然后用python来实现,最后通过数据来比较几个算法时间 选择排序 选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理是每一次从待排序的数据 ...
- 经典排序算法的总结及其Python实现
经典排序算法总结: 结论: 排序算法无绝对优劣之分. 不稳定的排序算法有:选择排序.希尔排序.快速排序.堆排序(口诀:“快速.选择.希尔.堆”).其他排序算法均为稳定的排序算法. 第一趟排序后就能确定 ...
随机推荐
- HDU:Gauss Fibonacci(矩阵快速幂+二分)
http://acm.hdu.edu.cn/showproblem.php?pid=1588 Problem Description Without expecting, Angel replied ...
- Parallel Decision Tree
Decision Tree such as C4.5 is easy to parallel. Following is an example. This is a non-parallel vers ...
- rest-framework框架的基本组件
快速实例 Quickstart 大致步骤 (1)创建表,数据迁移 (2)创建表序列化类BookSerializer class BookSerializer(serializers.Hyperlink ...
- 初识CGI
CGI Web 服务器只能生成静态内容,而用户请求动态内容时,Web服务器只能借助一些应用程序来实现.CGI时一套标准,它规定了Web服务器和应用程序之间的交互方式. 静态内容与动态内容 要想理解什么 ...
- FindBugs详解
欢迎和大家交流技术相关问题: 邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://g ...
- 如何使用STM32F4的BootLoader和APP程序
源:如何使用STM32F4的BootLoader和APP程序 STM32 BootLoader升级固件
- nw.js node-webkit系列(18)怎么对.js进行编译以防你的代码暴露出来
原文链接:http://blog.csdn.net/zeping891103/article/details/50819102 参考:https://segmentfault.com/a/119000 ...
- 20162326 qilifeng 2018-2019-2 《网络对抗技术》Exp0 Kali安装 Week1
<网络对抗技术>第1次作业 (一)作业任务 1.安装kali 2.设置共享文件夹 (二)操作过程 1.安装kali 因为之前安装过Oracle 的VM VirtualBox 所以直接 进入 ...
- Knockout 监控数组对象属性
代码: function Product(ProductID,ProductName,ProductNum,Result,Price) { this.ProductID = ko.observable ...
- office的project的激活码
8XWTK-7DBPM-B32R2-V86MX-BTP8PMVR3D-9XVBT-TBWY8-W3793-FR7C326K3G-RGBT2-7W74V-4JQ42-KHXQWD4HF2-HMRGR-R ...