python并发学习总结
一、理解操作系统
操作系统(OS)统管了计算机的所有硬件,并负责为应用程序分配和回收硬件资源。
硬件资源总是有限的,而应用程序对资源的欲望都是贪婪的。
当多个应用程序发生硬件资源争夺时,OS负责出面调度,保证多任务的资源分配以保证系统稳定执行。
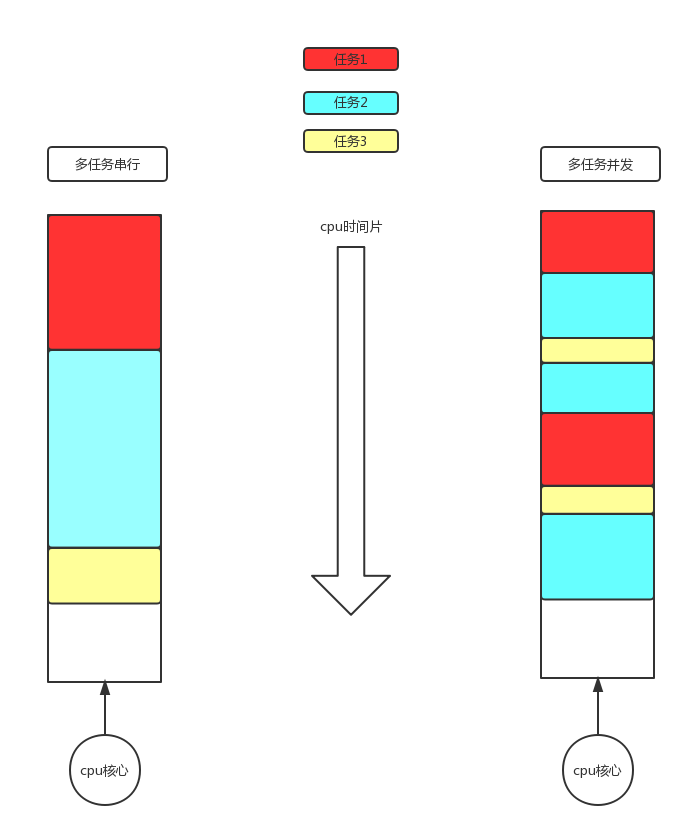
只有CPU可以执行代码,所以应用程序(任务)执行前,必须申请到CPU资源,同一时刻,一个CPU只能执行一个任务代码。
计算机的CPU数量(资源方)远远小于需要执行的任务数(需求方),操作系统将CPU的资源按照时间片划分,并根据任务类型分配,各任务轮流使用CPU。
CPU的执行/切换速度非常快,对于用户而言,多任务看上去就像同时执行一样,此称为并发。
如下是串行和并发的对比:
计算机的内存、硬盘、网卡、屏幕、键盘等硬件提供了数据交换的场所。
OS提供了IO接口以实现数据交换,数据交换的过程一般不需要CPU的参与。
IO接口有两种类型:
1、阻塞型IO
发生IO(数据交换)的时候,调用线程无法向下执行剩余代码,意图占用CPU但不执行任何代码,单线程阻塞型IO自身无法支持并发
2、非阻塞型IO
发生IO(数据交换)的时候,调用线程可以向下执行剩余代码,单线程非阻塞型IO自身可以支持并发
如下是阻塞型IO和非阻塞型IO的对比:

二、任务类型
根据一个任务执行期间占用CPU的比例来划分,有两种类型:
1、CPU密集型
绝大部分时间都是占用CPU并执行代码,比如科学计算任务
2、IO密集型
绝大部分时间都未占用CPU,而是在发生IO操作,比如网络服务
三、Socket模块
OS提供了阻塞IO和非阻塞IO两种类型的接口,应用程序可以自行选择。
Socket模块封装了两种接口,Socket模块提供的函数默认是阻塞IO类型。
用户可以选择手工切换至非阻塞IO类型,使用socketobj.setblocking(False)切换至非阻塞IO模式。
下面将通过一个简单的例子程序来记录对并发的学习思考及总结。
四、一个简单的C/S程序
客户端:循环接收用户的输入,并发送给服务器。从服务器接收反馈并打印至屏幕。
服务器:将接收到的用户输入,变成大写并返回给客户端。
客户端代码固定,主要思考服务器端的代码。
一般我们会这样写服务端代码:
# 服务器端
import socket
addr = ('127.0.0.1', 8080)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.listen(5)
print('监听中...')
while True: # 链接循环
conn, client = server.accept()
print(f'一个客户端上线 -> {client}')
while True: # 消息循环
try:
request = conn.recv(1024)
if not request:
break
print(f"request: {request.decode('utf-8')}")
conn.send(request.upper())
except ConnectionResetError as why:
print(f'客户端丢失,原因是: {why}')
break
conn.close()
客户端代码保持不变:
# 客户端
import socket
addr = ('127.0.0.1', 8080)
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(addr)
print(f'服务器{addr}连接成功')
while True: # 消息循环
inp = input('>>>').strip()
if not inp: continue
try:
client.send(inp.encode('utf-8'))
response = client.recv(1024)
print(response.decode('utf-8'))
except ConnectionResetError as why:
print(f'服务端丢失,原因是: {why}')
break
client.close()
这种形式的编码我称为:单线程+阻塞IO+循环串行,有如下几个特点:
1、编码简单,模型简洁,可读性强
2、串行提供服务,用户使用服务器必须一个一个排队
单一线程的阻塞IO模型是无法支持并发的,如果要支持并发,有如下两类解决方案。
五、使用阻塞IO实现并发
单线程阻塞IO,本质上是无法实现并发的。因为一旦发生IO阻塞,线程就会阻塞,下方代码不会继续执行。如果要使用单线程阻塞IO来实现并发,需要增加线程数目或者进程数目,当某一个线程/进程发生阻塞的时候,由OS调度至另一个线程/进程执行。
方案一:阻塞IO+多进程
服务器端代码
import socket
from multiprocessing import Process
def task(conn):
"""通信循环处理函数"""
while True:
try:
request = conn.recv(1024)
if not request:
break
print(f"request: {request.decode('utf-8')}")
conn.send(request.upper())
except ConnectionResetError as why:
print(f'客户端丢失,原因是: {why}')
break
if __name__ == '__main__': # windows下需要把新建进程写到main中,不然会报错
addr = ('127.0.0.1', 8080)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.listen(5)
print('监听中...')
while True:
conn, client = server.accept()
print(f'一个客户端上线 -> {client}')
p = Process(target=task, args=(conn,)) # 开启子进程处理与用户的消息循环
p.start()
将服务器对用户的消息循环操作封装到进程中,单进程依然会发生阻塞。
进程之间的调度交由OS负责(重要)。
进程太重,创建和销毁进程都需要比较大的开销,此外,一台设备所能涵盖的进程数量非常有限(一般就几百左右)。
进程之间的切换开销也不小。
当进程数小于等于CPU核心数的时候,可以实现真正的并行,当进程数大于CPU核心的时候,依然以并发执行。
方案二:阻塞IO+多线程
服务器端代码
import socket
from threading import Thread
def task(conn):
"""通信循环处理函数"""
while True:
try:
request = conn.recv(1024)
if not request:
break
print(f"request: {request.decode('utf-8')}")
conn.send(request.upper())
except ConnectionResetError as why:
print(f'客户端丢失,原因是: {why}')
break
if __name__ == '__main__':
addr = ('127.0.0.1', 8080)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.listen(5)
print('监听中...')
while True:
conn, client = server.accept()
print(f'一个客户端上线 -> {client}')
t = Thread(target=task, args=(conn,)) # 启动多线程处理与用户的消息循环
t.start()
将服务器对用户的操作封装到线程中,单线程中依然会发生IO阻塞。
线程之间的调度交由OS负责(重要)。
线程较轻,创建和销毁的开销都比较小,但是线程数量也不会太大,一台设备一般能容纳几百至上千的线程。
注意:因为CPython的GIL的存在,使用CPython编写的多线程代码,只能使用一个CPU核心,换句话说,使用官方的解释器执行Python多线程代码,无法并行(单进程中)。
线程之间的切换开销比较小。
实际上,多线程的最大问题并不是并发数太少,而是数据安全问题。
线程之间共享同一进程的数据,在频繁发生IO操作的过程中,难免需要修改共享数据,这就需要增加额外的处理,当线程数量大量增加时,如何妥善处理数据安全的问题就会变成主要困难。
阻塞IO模型的思考和总结
1、多线程和多进程都是基于阻塞IO模式提供的并发,两者编程模型比较简单,可读性也很高。
2、如果使用多线程/进程的方案来提供并发,当线程/进程数量不断增大时,系统稳定性将会下降。虽然可以使用线程/进程池来提供一定的优化,但超过一定数量之后,池子发挥的效果也会越来越小。所以,两者都无法支持超大规模的并发(如C10M及以上)。
3、线程/进程切换都交由OS调度,调度策略依据OS的算法,应用程序无法主动控制,无法针对任务的特性做一些必要的调度算法调整。
4、编码思维直接、易理解,学习曲线平缓。
5、多线程/进程的方案可以理解为单纯的增加资源,如果要想支持超大规模的并发,单纯的增加资源的行为并不合理(资源不可能无限或者总得考虑成本以及效率,而且数量越大,原有的缺点就会越凸显)。
6、另一种解决方案的核心思路是:改变IO模型。
六、使用非阻塞IO实现并发
单线程非阻塞IO模型,本身就直接支持并发,为啥?请回头看看阻塞IO和非阻塞IO的流程图片。
非阻塞IO接口的核心是:调用线程一旦向OS发起IO调用,OS就直接返回结果,因此,调用线程不会被阻塞而可以执行下方代码。不过也正因为不会阻塞,调用线程无法判断立即返回的结果是不是期望结果,所以调用线程需要增加额外的操作对返回结果进行判断,正因为这一点,就增加了编程难度(增加的难度可不是一点啊)。
对立即返回的结果进行判断的方案有两种:
- 轮询
线程定期/不定期主动发起查询和判断 - 回调函数+事件循环
线程在发起IO时注册回调函数,然后统一处理事件循环
注意:非阻塞IO实现并发有多种解决方案,编程模型的可读性都不高,有些方案的编程思维甚至晦涩、难以理解、且编码困难。
方案一:非阻塞IO+Try+轮询
服务器端代码
import socket
addr = ('127.0.0.1', 8080)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.setblocking(False)
server.listen(5)
print('监听中...')
# 需要执行接收的conn对象放入此列表
recv_list = []
# 需要发送数据的conn对象和数据放入此列表
send_list = []
# 执行链接循环
while True:
try:
conn, client = server.accept()
# 执行成功,说明返回值是conn,client
print(f'一个客户端上线 -> {client}')
# 将成功链接的conn放入列表,当accept发生错误的时候执行conn的消息接收操作
recv_list.append(conn)
except BlockingIOError:
# 执行accept不成功,意味着当前未有任何连接
# 在下一次执行accept之前,可以执行其他的任务(消息接收操作)
# 无法对处于遍历期间的接收列表执行remove操作,使用临时列表存储需要删除的conn对象
del_recv_list = []
# 对已经成功链接的conn列表执行接收操作
for conn in recv_list:
# 对每一个conn对象,执行recv获取request
try:
# recv也是非阻塞
request = conn.recv(1024)
# 执行成功,就要处理request
if not request:
# 当前conn链接已经失效
conn.close()
# 不再接收此conn链接的消息,将失效conn加入删除列表
del_recv_list.append(conn)
# 当前conn处理完毕,切换下一个
continue
# request有消息,处理,然后需要加入发送列表中
response = request.upper()
# 发送列表需要存放元组,发送conn和发送的数据
send_list.append((conn, response))
except BlockingIOError:
# 当前conn的数据还没有准备好,处理下一个conn
continue
except ConnectionResetError:
# 当前conn失效,不再接收此conn消息
conn.close()
del_recv_list.append(conn)
# 无法处理发送列表遍历期间的remove,使用临时列表
del_send_list = []
# 接收列表全部处理完毕,准备处理发送列表
for item in send_list:
conn = item[0]
response = item[1]
# 执行发送
try:
conn.send(response)
# 发送成功,就应该从发送列表中移除此项目
del_send_list.append(item)
except BlockingIOError:
# 发送缓冲区有可能已经满了,留待下次发送处理
continue
except ConnectionResetError:
# 链接失效
conn.close()
del_recv_list.append(conn)
del_send_list.append(item)
# 删除接收列表中已经失效的conn对象
for conn in del_recv_list:
recv_list.remove(conn)
# 删除发送列表中已经发送或者不需要发送的对象
for item in del_send_list:
send_list.remove(item)
服务器使用单线程实现了并发。
对于accept接收到的多个conn对象,加入列表,并通过遍历读取列表、发送列表来提供多用户访问。
单线程中的Socket模块提供的IO函数都被设置成:非阻塞IO类型。
增加了额外操作:对非阻塞调用立即返回的结果,使用了Try来判断是否为期望值。
因为不知道何时返回的结果是期望值,所以需要不停的发起调用,并通过Try来判断,即,轮询。
两次轮询期间,线程可以执行其他任务。但是模型中也只是不停的发起轮询,并没有利用好这些时间。
编码模型复杂,难理解。
优化:此模型中的主动轮询的工作由程序负责,其实可以交由OS代为操作。这样的话,应用程序就不需要编写轮询的部分,可以更聚焦于业务逻辑(upper()的部分),Python提供了Select模块以处理应用程序的轮询工作。
方案二:非阻塞IO+Select代理轮询
服务器端代码
import socket
import select
addr = ('127.0.0.1', 8080)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.setblocking(False)
server.listen(5)
print('监听中...')
# 最开始的server对象需要被监听,一旦可读,说明可以执行accept
read_list = [server,]
# 需要监听的写列表,一旦wl中可写对象处理完send,应该将它也从此列表中删除
write_list = []
# 用于临时存放某一个sock对象需要发送的数据
data_dic = {}
# 不停的发起select查询
while True:
# 发起select查询,尝试得到可以操作的socket对象
rl, wl, xl = select.select(read_list, write_list, [], 1)
# 操作可读列表
for sock in rl:
# 如果可读列表中的对象是server,意味着有链接,则server可执行accept
if sock is server:
# 执行accept一定不会报错,所以不需要try
conn, client = sock.accept()
# 一旦获得conn,就需要将此conn加入可读列表
read_list.append(conn)
else:
# 说明可读的对象是普通的conn对象,执行recv时要处理链接失效问题
try:
request = sock.recv(1024)
except (ConnectionResetError, ConnectionAbortedError):
# 此链接失效
sock.close()
read_list.remove(sock)
else:
# 还需要继续判断request的内容
if not request:
# 说明此conn链接失效
sock.close()
# 不再监控此conn
read_list.remove(sock)
continue
# 处理请求
response = request.upper()
# 加入发送列表
write_list.append(sock)
# 保存发送的数据
data_dic[sock] = response
# 操作可写列表
for sock in wl:
# 执行发送操作,send也会出错
try:
sock.send(data_dic[sock])
# 发送完毕后,需要移除发送列表
write_list.remove(sock)
# 需要移除发送数据
data_dic.pop(sock)
except (ConnectionResetError, ConnectionAbortedError):
# 此链接失效
sock.close()
read_list.remove(sock)
write_list.remove(sock)
服务器使用单线程实现了并发。
使用了Select模块之后,应用程序不再需要编写主动轮询的代码,而是将此部分工作交由Select模块的select函数代为处理。
应用程序只需要遍历select函数返回的可操作socket列表,并处理相关业务逻辑即可。
虽然应用程序将轮询工作甩给了select,自己不用编写代码。不过select函数的底层接口效率不高,使用epoll接口可以提升效率,此接口被封装在Selectors模块中。
此外,select函数是一个阻塞IO,在并发数很少的时候,线程大部分时间会阻塞在select函数上。所以select函数应该适用于随时随刻都有socket准备好、大规模并发的场景。
编码困难,模型难理解。
select函数接口说明
def select(rlist, wlist, xlist, timeout=None): # real signature unknown; restored from __doc__
"""
select(rlist, wlist, xlist[, timeout]) -> (rlist, wlist, xlist)
Wait until one or more file descriptors are ready for some kind of I/O.
The first three arguments are sequences of file descriptors to be waited for:
rlist -- wait until ready for reading
wlist -- wait until ready for writing
xlist -- wait for an ``exceptional condition''
If only one kind of condition is required, pass [] for the other lists.
A file descriptor is either a socket or file object, or a small integer
gotten from a fileno() method call on one of those.
The optional 4th argument specifies a timeout in seconds; it may be
a floating point number to specify fractions of seconds. If it is absent
or None, the call will never time out.
The return value is a tuple of three lists corresponding to the first three
arguments; each contains the subset of the corresponding file descriptors
that are ready.
*** IMPORTANT NOTICE ***
On Windows, only sockets are supported; on Unix, all file
descriptors can be used.
"""
pass
- 输入4个参数(3位置,1默认),返回3个值
- select函数是阻塞IO,函数的返回必须等到至少1个文件描述符准备就绪
- 位置参数
rlist/wlist/xlist分为是:需要监控的读列表/写列表/例外列表(第3参数暂不理解) - 在
windows下,列表中只能放socket对象,unix下,可以放任何文件描述符 - 第4参数如果是
None(默认),则会永久阻塞,否则按照给定的值(单位是秒)发生超时,可以使用小数如0.5秒 - 返回值是3个列表,里面涵盖的是可以操作的文件描述符对象
关于轮询效率的思考
轮询操作,效率不高。
轮询的工作视角是:发起者定期/不定期主动发起询问,如果数据没有准备好,就继续发起询问。如果数据准备好了,发起者就处理这些数据。
假设,调用者在第35次主动轮询的时候发现数据准备好了,那么意味着前34次主动轮询的操作是没有任何收益的。
调用者要想知道数据是否就绪,就要主动询问,而主动询问的效率又比较低。
这个矛盾的核心关键在于:如何得知数据准备就绪这件事呢?
使用回调函数+事件循环。
此种方案中,调用者不会主动发起轮询,而是被动的等待IO操作完成,并由OS向调用者发起准备就绪的事件通知。
方案三:非阻塞IO+Selectors+回调函数+事件循环
# 服务器端代码
import socket
from selectors import DefaultSelector, EVENT_READ
def recv_read(conn, mask):
# recv回调函数
try:
request = conn.recv(1024)
if not request:
# 意味着链接失效,不再监控此socket
conn.close()
selector.unregister(conn)
# 结束此回调的执行
return None
# 链接正常,处理数据
conn.send(request.upper())
except (ConnectionResetError, ConnectionAbortedError):
# 链接失效
conn.close()
selector.unregister(conn)
def accept_read(server, mask):
# accept回调函数
conn, client = server.accept()
print(f'一个客户端上线{client}')
# 监听conn对象的可读事件的发生,并注册回调函数
selector.register(conn, EVENT_READ, recv_read)
if __name__ == '__main__':
addr = ('127.0.0.1', 8080)
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(addr)
server.setblocking(False)
server.listen(5)
print('监听中...')
# 获取对象
selector = DefaultSelector()
# 第一个注册,监听server对象的可读事件的发生,并注册回调函数
selector.register(server, EVENT_READ, accept_read)
# 执行事件循环
while True:
# 循环调用select,select是阻塞调用,返回就绪事件
events = selector.select()
for key, mask in events:
# 获取此事件预先注册的回调函数
callback = key.data
# 对此事件中准备就绪的socket对象执行回调
callback(key.fileobj, mask)
服务器使用单线程实现了并发。
OS使用了Selectors自行选择最优的底层接口监听socket对象。
程序不再需要主动发起查询,而是注册回调函数。
增加事件循环,用于处理准备就绪的socket对象,调用预先注册的回调函数。
应用程序不用再关注如何判断非阻塞IO的返回值,而将精力聚焦于回调函数的编写。
方案四:非阻塞IO+协程+回调函数+事件循环(待后续补充)
pass
非阻塞IO的思考和总结(待后续补充)
- 如果将一个IO密集型任务的IO模型设置为非阻塞,则此任务类型将会从IO密集型逐渐转变为CPU密集型。
- 非阻塞IO的编程模型比较困难,可读性较差,模型理解困难
- 我认为,含有非阻塞IO+回调+事件循环的编程模型,就是异步编程。
pass
七、关于同步/异步,阻塞IO/非阻塞IO的区别和思考
- 阻塞IO和非阻塞IO指的是
OS提供的两种IO接口,区别在于调用时是否立即返回。 - 同步和异步指的是两个任务之间的执行模型
同步:两个任务关联性大,任务相互依赖,对任务执行的前后顺序有一定要求
异步:两个任务关联性小,任务可以相互独立,任务执行顺序没有要求 - 网上有很多关于同步阻塞、同步非阻塞、异步阻塞、异步非阻塞的各种理解,站在不同的角度,理解都不一样。我觉得应该把同步/异步划为一类,用于描述任务执行模型,而把阻塞/非阻塞IO划为一类,用于描述IO调用模型。
如下是我根据网上的各种解释,结合自己的思考给出的一个关于同步/异步简单的例子:
同步
第一天,晚饭时间到了,你饿了,你走到你老婆面前说:老婆,我饿了,快点做饭!你老婆回答:好的,我去做饭。
你跟着老婆走到厨房,你老婆花了30分钟的时间给你做饭。这期间,你就站在身边,啥也不干,就这样注视着她,你老婆问你:你站这干嘛?你说:我要等你做完饭再走。30分钟后,你吃到了晚饭。异步+轮询
第二天,晚饭时间到了,你饿了,你大喊:老婆,我饿了,快点做饭!你老婆回答:好的,我去做饭。
你老婆花了30分钟的时间给你做饭,但是你不再跟着你老婆走到厨房。这期间,你在客厅看电视,不过你实在饿得不行了,于是你每过5分钟,就跑到厨房询问:老婆,饭做好了没?你老婆回答:还要一会。30分钟后,你吃到了晚饭。异步+事件通知
第三天,晚饭时间到了,你饿了,你大喊:老婆,我饿了,快点做饭!你老婆回答:好的,我去做饭。
你老婆花了30分钟的时间给你做饭,你也不再跟着你老婆走到厨房。这期间,你在客厅看电视,你知道你老婆在做饭,你也不会去催她,专心看电视。30分钟后,你老婆喊你:饭做好了。最后你吃到了晚饭。
python并发学习总结的更多相关文章
- Python并发学习
#Python并发 多任务 多进程 多线程 线程同步 #多任务处理 多任务处理:使得计算机可以同时处理多个任务 听歌的同时QQ聊天.办公.下载文件 实现方式:多进程.多线程 #程序和进程 程序:是一个 ...
- Day1 Python基础学习
一.编程语言分类 1.简介 机器语言:站在计算机的角度,说计算机能听懂的语言,那就是直接用二进制编程,直接操作硬件 汇编语言:站在计算机的角度,简写的英文标识符取代二进制去编写程序,本质仍然是直接操作 ...
- Day1 Python基础学习——概述、基本数据类型、流程控制
一.Python基础学习 一.编程语言分类 1.简介 机器语言:站在计算机的角度,说计算机能听懂的语言,那就是直接用二进制编程,直接操作硬件 汇编语言:站在计算机的角度,简写的英文标识符取代二进制去编 ...
- Python入门学习笔记4:他人的博客及他人的学习思路
看其他人的学习笔记,可以保证自己不走弯路.并且一举两得,即学知识又学方法! 廖雪峰:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958 ...
- Python进阶(4)_进程与线程 (python并发编程之多进程)
一.python并发编程之多进程 1.1 multiprocessing模块介绍 由于GIL的存在,python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大 ...
- python高级学习目录
1. Linux介绍.命令1.1. 操作系统(科普章节) 1.2. 操作系统的发展史(科普章节) 1.3. 文件和目录 1.4. Ubuntu 图形界面入门 1.5. Linux 命令的基本使用 1. ...
- 快速了解Python并发编程的工程实现(上)
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
- Python并发编程-多进程
Python并发编程-多进程 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.多进程相关概念 由于Python的GIL全局解释器锁存在,多线程未必是CPU密集型程序的好的选择. ...
- Python核心技术与实战——十八|Python并发编程之Asyncio
我们在上一章学习了Python并发编程的一种实现方法——多线程.今天,我们趁热打铁,看看Python并发编程的另一种实现方式——Asyncio.和前面协程的那章不太一样,这节课我们更加注重原理的理解. ...
随机推荐
- mongoTemplate更新一个Document里面的数组的一个记录。
假如有一个Document如下: { "_id" : "69bca85a-5a61-4b04-81fb-ff6a71c3802a", "_class& ...
- Gym 101201H Paint (离散化+DP)
题意:给定 n 个区间,让你选出一些,使得每个选出区间不交叉,并且覆盖区间最大. 析:最容易想到的先是离散化,然后最先想到的就是 O(n^2)的复杂度,dp[i] = max(dp[j] + a[i] ...
- Oracle物化视图的一般使用
普通视图和物化视图根本就不是一个东西,说区别都是硬拼到一起的,首先明白基本概念,普通视图是不存储任何数据的,他只有定义,在查询中是转换为对应的定义SQL去查询,而物化视图是将数据转换为一个表,实际存储 ...
- windows7 不能更新,提示:"WindowsUpdate_80240016" "WindowsUpdate_dt000",如何解决?
计算机(右键) ---- 管理 -------- 服务和应用程序 -----服务(找到名称为windows update的服务,并且在windwos update服务右键 选择重新启动 ) 再次安装更 ...
- HRBUST1212 乘积最大 2017-03-06 15:47 59人阅读 评论(0) 收藏
乘积最大 今年是国际数学联盟确定的"2000--世界数学年",又恰逢我国著名数学家华罗庚先生诞辰90周年.在华罗庚先生的家乡江苏金坛,组织了一场别开生面的数学智力竞赛的活动,你的一 ...
- cxrichedit导入WORD
cxrichedit导入WORD word := CreateOLEObject('Word.Application'); word.Documents.Open(l_path,false); w ...
- CURL命令测试网站打开速度
curl -o /dev/null -s -w %{time_namelookup}:%{time_connect}:%{time_starttransfer}:%{time_total} http: ...
- C# 连接sqlite数据库
web.config <connectionStrings> <add name="SQLiteDB" connectionString="Data S ...
- Ubuntu add-apt-repository: command not found
在Ubuntu下,时不时会有这个错误的. add-apt-repository: command not found 这个是缺少程序,安装一下就可以了.只是不知道安装的名字. 按以下命令走一趟就可以的 ...
- USB-Redirector-Technician 永久破解版(USB设备映射软件)
USB-Redirector-Technician 这个软件对于搞安卓刷机的人想必非常熟悉,淘宝破解版售价:38 一个的东西 除了远程刷机,用于映射一些小型设备是没问题的,只要网跟得上~ USB-Re ...