后缀树 & 后缀数组
后缀树:
字符串匹配算法一般都分为两个步骤,一预处理,二匹配。
KMP和AC自动机都是对模式串进行预处理,后缀树和后缀数组则是对文本串进行预处理。
后缀树的性质:
- 存储所有 n(n-1)/2 个后缀需要 O(n) 的空间,n 为的文本(Text)的长度;
- 构建后缀树需要 O(dn) 的时间,d 为字符集的长度(alphabet);
- 对模式(Pattern)的查询需要 O(dm) 时间,m 为 Pattern 的长度;
介绍后缀树之前,我们首先要知道压缩字典树的概念。
我们在对关键字建立字典树的时候,有时某些节点只会有一个子树,没有别的支路。那么这个节点和他的子树就可以压缩成一个节点。
比如,下面是集合 {bear, bell, bid, bull, buy, sell, stock, stop} 所构建的 Trie 树。

他对应的压缩字典树就是这样的。

而后缀树就是一棵以所有的后缀为关键字建立的压缩字典树。
比如,对于文本 "banana\0",其中 "\0" 作为文本结束符号。下面是该文本所对应的所有后缀。
banana\0
anana\0
nana\0
ana\0
na\0
a\0
\0
将每个后缀作为一个关键词,构建一棵 Trie。

然后,将独立的节点合并,形成 Compressed Trie。

则上面这棵树就是文本 "banana\0" 所对应的后缀树。
像上面建立的其实是一棵显式后缀树,因为如果我们不在后缀后面加上\0.某些后缀比如a,na在其他后缀的前缀中出现过,他们会被表示在一条路径上,这样的后缀树被称为隐式后缀树。
在后缀后加入一个后缀中没有出现过的字符,如\0或是$可以保证后缀的唯一性,此时建立的就是一种显式后缀树。
后缀树 与 字典树 的不同在于,边(Edge)不再只代表单个字符,而是通过一对整数 [from, to] 来表示。其中 from 和 to 所指向的是 Text 中的位置,这样每个边可以表示任意的长度,而且仅需两个指针,耗费 O(1) 的空间。
后缀数组:
后缀树的建立相当的麻烦,后缀数组的提出就是为了代替后缀树,并且后缀数组节省了空间。因此题目中我们大多实现后缀数组。
其与后缀树的的关系有:
- 后缀数组可以通过对后缀树做深度优先遍历(DFT: Depth First Traversal)来进行构建,对所有的边(Edge)做字典序(Lexicographical Order)遍历。
- 通过使用后缀集合和最长公共前缀数组(LCP Array: Longest Common Prefix Array)来构建后缀树,可在 O(n) 时间内完成,例如使用 Ukkonen 算法。构造后缀数组同样也可以在 O(n) 时间内完成。
- 每个通过后缀树解决的问题,都可以通过组合使用后缀数组和额外的信息(例如:LCP Array)来解决。
后缀数组就是将文本串的所有后缀按照字典序进行排序,将后缀的起始字符的下标存入SA数组中。
比如字符串“ababa”, 他的后缀有ababa, baba, aba, ba, a
按照字典序排序为,a, aba, ababa, ba, baba他们的开始字符的下标分别为,5, 3, 1, 4, 2。因此SA[1~5]分别为5,3,1,4,2
同时我们可以用rank来记后缀在所有后缀里的排名
构建SA[i]数组中相邻元素的最长公共前缀(LCP,Longest Common Prefix),Height[i]表示SA[i]和SA[i-1]的LCP(i, j);H[i]=Height[Rank[i]表示Suffix[i]和字典排序在它前一名的后缀子串的LCP大小;
对于正整数i和j而言,最长公共前缀的定义如下: LCP(i, j) =lcp(Suffix(SA[i]), Suffix(SA[j])) = min(Height[k] | i + 1 <= k <= j)
也就是计算LCP(i, j)等同于查找Height数组中下标在i+1到j之间的元素最小值
暴力的构建后缀数组的方法复杂度是O(n^2logn),倍增算法(Doubling Algorithm)快速构造后缀数组,其利用了后缀子串之间的联系可将时间复杂度降至O(MlogN),M为模式串的长度,N为目标串的长度;另外基数排序算法的时间复杂度为O(N);Difference Cover mod 3(DC3)算法(Linear Work Suffix Array Construction)可在O(3N)时间内构建后缀数组;Ukkonen算法(On-line Construction of Suffix-Trees)可在O(N)的时间内构建一棵后缀树,然后再O(N)的时间内将后缀树转换为后缀数组,理论上最快的后缀数组构造法;
倍增法构造后缀数组,使用基数排序。基数排序在后缀数组中可以在O(n)的时间内对一个二元组(p,q)进行排序,其中p是第一关键字,q是第二关键字
我们把每个后缀分开来看。
开始时,每个后缀的第一个字母的大小是能确定的,也就是他本身的ASCLL值
具体点?把第ii个字母看做是(s[i],i)的二元组,对其进行基数排序
这样我们就得到了他们的在完成第一个字母的排序之后的相对位置关系
sa[i]:排名为i的后缀的位置
rak[i]:从第i个位置开始的后缀的排名,下文为了叙述方便,把从第i个位置开始的后缀简称为后缀i
tp[i]:基数排序的第二关键字,意义与sa一样
tax[i]:i号元素出现了多少次。辅助基数排序
s[i]:字符串
“倍增法”,每次将排序长度*2,最多需要log(n)次便可以完成排序
因此我们现在需要对每个后缀的前两个字母进行排序
此时第一个字母的相对关系我们已经知道了。
由于第i个后缀的第二个字母,实际是第i+1个后缀的第一个字母
因此每个后缀的第二个后缀的字母的相对位置关系我们也是知道的。
我们用tp这个数组把他记录出来,对rak,tp这个二元组进行基数排序
接下来我们需要对每个后缀的前四个后缀进行排序
此时我们已经知道了每个后缀前两个字母的排名,而第i个后缀的第3,4个字母恰好是第i+2个后缀的前两个字母。
他们的相对位置我们又知道啦。
这样不断排下去,最后就可以完成排序啦
举个栗子,banana先按第一个字母排序
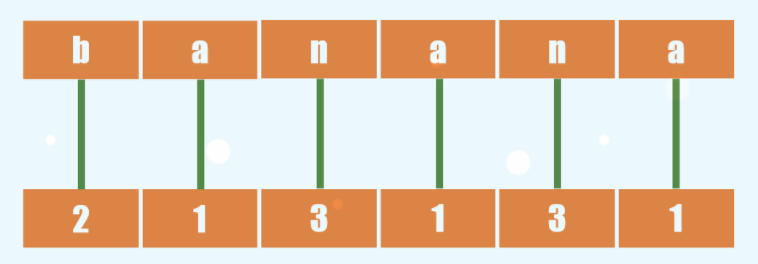
然后给前两个字母排序,也就是把相邻二元组合并。再根据字典序排

再排前四个

最长公共前缀(LCP)
对两个字符串u,v 定义函数lcp(u,v)=max{i|u=iv},对正整数i,j 定义LCP(i,j)=lcp(Suffix(SA[i]),Suffix(SA[j]),其中i,j 均为1 至n 的整数。
LCP(i,j)也就是后缀数组中第i 个和第j 个后缀的最长公共前缀的长度。
关于LCP 有两个显而易见的性质:
性质2.1 LCP(i,j)=LCP(j,i)
性质2.2 LCP(i,i)=len(Suffix(SA[i]))=n-SA[i]+1
这两个性质的用处在于,我们计算LCP(i,j)时只需要考虑i<j 的情况,因为i>j时可交换i,j,i=j时可以直接输出结果n-SA[i]+1。
并且LCP有一些定理【证明见OI2004国家集训队论文《后缀数组》许智磊,链接附在文后】
Lemma: 对任意1≤i<j<k≤n,LCP(i,k)=min{LCP(i,j),LCP(j,k)}
LCP Theorem: LCP(i,j)=min{LCP(k-1,k)|i+1≤k≤j}
LCP Corollary 对 i≤j<k,LCP(j,k)≥LCP(i,k)
定义数组height,height[i] = LCP(i-1, i),那么根据定理可得LCP(i,j)=min{height[k]|i+1≤k≤j}
那么求LCP的问题就可以变成经典的RMQ问题【如果height是固定的】,可以用线段树来维护。
【论文中提到的RMQ标准算法,O(n)时间预处理,O(1)完成查询,太菜,不会。】
设i<n,j<n,Suffix(i)和Suffix(j)满足lcp(Suffix(i),Suffix(j)>1,则成立以下两点:
Fact 1 Suffix(i)<Suffix(j) 等价于Suffix(i+1)<Suffix(j+1)。
Fact 2 一定有lcp(Suffix(i+1),Suffix(j+1))=lcp(Suffix(i),Suffix(j))-1。
那么如何高效的求height数组?
为了描述方便,设h[i]=height[Rank[i]],即height[i]=h[SA[i]]。
h 数组满足一个性质:对于i>1 且Rank[i]>1,一定有h[i]≥h[i-1]-1。
根据这个性质,可以令i从1 循环到n按照如下方法依次算出h[i]:
若 Rank[i]=1,则h[i]=0。字符比较次数为0。
若 i=1 或者h[i-1]≤1,则直接将Suffix(i)和Suffix(Rank[i]-1)从第一个字符开始依次比较直到有字符不相同,由此计算出h[i]。字符比较次数为h[i]+1,不超过h[i]-h[i-1]+2。
否则,说明i>1,Rank[i]>1,h[i-1]>1,根据性质3,Suffix(i)和Suffix(Rank[i]-1)至少有前h[i-1]-1 个字符是相同的,于是字符比较可以从h[i-1]开始,直到某个字符不相同,由此计算出h[i]。字符比较次数为h[i]-h[i-1]+2。
求出了h 数组,根据关系式height[i]=h[SA[i]]可以在O(n)时间内求出height数组,于是可以在O(n)时间内求出height 数组。
kuangbin的模板
/*
*suffix array
*倍增算法 O(n*logn)
*待排序数组长度为n,放在0~n-1中,在最后面补一个0
*build_sa( ,n+1, );//注意是n+1;
*getHeight(,n);
*例如:
*n = 8;
*num[] = { 1, 1, 2, 1, 1, 1, 1, 2, $ };注意num最后一位为0,其他大于0
*rank[] = { 4, 6, 8, 1, 2, 3, 5, 7, 0 };rank[0~n-1]为有效值,rank[n]必定为0无效值
*sa[] = { 8, 3, 4, 5, 0, 6, 1, 7, 2 };sa[1~n]为有效值,sa[0]必定为n是无效值
*height[]= { 0, 0, 3, 2, 3, 1, 2, 0, 1 };height[2~n]为有效值
*
*/ int sa[MAXN];//SA数组,表示将S的n个后缀从小到大排序后把排好序的
//的后缀的开头位置顺次放入SA中
int t1[MAXN],t2[MAXN],c[MAXN];//求SA数组需要的中间变量,不需要赋值
int rank[MAXN],height[MAXN];
//待排序的字符串放在s数组中,从s[0]到s[n-1],长度为n,且最大值小于m,
//除s[n-1]外的所有s[i]都大于0,r[n-1]=0
//函数结束以后结果放在sa数组中
void build_sa(int s[],int n,int m)
{
int i,j,p,*x=t1,*y=t2;
//第一轮基数排序,如果s的最大值很大,可改为快速排序
for(i=;i<m;i++)c[i]=;
for(i=;i<n;i++)c[x[i]=s[i]]++;
for(i=;i<m;i++)c[i]+=c[i-];
for(i=n-;i>=;i--)sa[--c[x[i]]]=i;
for(j=;j<=n;j<<=)
{
p=;
//直接利用sa数组排序第二关键字
for(i=n-j;i<n;i++)y[p++]=i;//后面的j个数第二关键字为空的最小
for(i=;i<n;i++)if(sa[i]>=j)y[p++]=sa[i]-j;
//这样数组y保存的就是按照第二关键字排序的结果
//基数排序第一关键字
for(i=;i<m;i++)c[i]=;
for(i=;i<n;i++)c[x[y[i]]]++;
for(i=;i<m;i++)c[i]+=c[i-];
for(i=n-;i>=;i--)sa[--c[x[y[i]]]]=y[i];
//根据sa和x数组计算新的x数组
swap(x,y);
p=;x[sa[]]=;
for(i=;i<n;i++)
x[sa[i]]=y[sa[i-]]==y[sa[i]] && y[sa[i-]+j]==y[sa[i]+j]?p-:p++;
if(p>=n)break;
m=p;//下次基数排序的最大值
}
}
void getHeight(int s[],int n)
{
int i,j,k=;
for(i=;i<=n;i++)rank[sa[i]]=i;
for(i=;i<n;i++)
{
if(k)k--;
j=sa[rank[i]-];
while(s[i+k]==s[j+k])k++;
height[rank[i]]=k;
}
}
参考链接:
后缀树 https://www.cnblogs.com/gaochundong/p/suffix_tree.html
后缀数组 https://www.cnblogs.com/gaochundong/p/suffix_array.html
https://www.douban.com/note/210945706/
https://www.cnblogs.com/jinkun113/p/4743694.html
OI2004国家集训队论文《后缀数组》许智磊https://github.com/Booooooooooo/OI-Public-Library/blob/master/%E5%9B%BD%E5%AE%B6%E9%9B%86%E8%AE%AD%E9%98%9F%E8%AE%BA%E6%96%871999-2017/2004/%E8%AE%B8%E6%99%BA%E7%A3%8A.pdf
OI2009国家集训队论文《后缀数组——处理字符串的有力工具》https://github.com/Booooooooooo/OI-Public-Library/blob/master/%E5%9B%BD%E5%AE%B6%E9%9B%86%E8%AE%AD%E9%98%9F%E8%AE%BA%E6%96%871999-2017/2009/%E7%BD%97%E7%A9%97%E9%AA%9E/%E5%90%8E%E7%BC%80%E6%95%B0%E7%BB%84%E2%80%94%E2%80%94%E5%A4%84%E7%90%86%E5%AD%97%E7%AC%A6%E4%B8%B2%E7%9A%84%E6%9C%89%E5%8A%9B%E5%B7%A5%E5%85%B7.pdf
后缀树 & 后缀数组的更多相关文章
- 字符串 --- KMP Eentend-Kmp 自动机 trie图 trie树 后缀树 后缀数组
涉及到字符串的问题,无外乎这样一些算法和数据结构:自动机 KMP算法 Extend-KMP 后缀树 后缀数组 trie树 trie图及其应用.当然这些都是比较高级的数据结构和算法,而这里面最常用和最熟 ...
- luoguP5108 仰望半月的夜空 [官方?]题解 后缀数组 / 后缀树 / 后缀自动机 + 线段树 / st表 + 二分
仰望半月的夜空 题解 可以的话,支持一下原作吧... 这道题数据很弱..... 因此各种乱搞估计都是能过的.... 算法一 暴力长度然后判断判断,复杂度\(O(n^3)\) 期望得分15分 算法二 通 ...
- UVA - 11107 Life Forms (广义后缀自动机+后缀树/后缀数组+尺取)
题意:给你n个字符串,求出在超过一半的字符串中出现的所有子串中最长的子串,按字典序输出. 这道题算是我的一个黑历史了吧,以前我的做法是对这n个字符串建广义后缀自动机,然后在自动机上dfs,交上去AC了 ...
- 后缀树(suffix tree)
参考: 从前缀树谈到后缀树 后缀树 Suffix Tree-后缀树 字典树(trie树).后缀树 一.前缀树 简述:又名单词查找树,tries树,一种多路树形结构,常用来操作字符串(但不限于字符串), ...
- [模板] 后缀自动机&&后缀树
后缀自动机 后缀自动机是一种确定性有限状态自动机, 它可以接收字符串\(s\)的所有后缀. 构造, 性质 翻译自毛子俄罗斯神仙的博客, 讲的很好 后缀自动机详解 - DZYO的博客 - CSDN博客 ...
- [算法]从Trie树(字典树)谈到后缀树
我是好文章的搬运工,原文来自博客园,博主July_,地址:http://www.cnblogs.com/v-July-v/archive/2011/10/22/2316412.html 从Trie树( ...
- POJ2774 --后缀树解法
POJ2774 Long Long Message --后缀树解法 原题链接 题意明确说明求两字符串的最长连续公共子串,可用字符串hash或者后缀数据结构来做 关于后缀树 后缀树的原理较为简单,但 \ ...
- 【BZOJ3413】匹配 离线+后缀树+树状数组
[BZOJ3413]匹配 Description Input 第一行包含一个整数n(≤100000). 第二行是长度为n的由0到9组成的字符串. 第三行是一个整数m. 接下来m≤5·10行,第i行是一 ...
- BZOJ 2754 SCOI 2012 喵星球上的点名 后缀数组 树状数组
2754: [SCOI2012]喵星球上的点名 Time Limit: 20 Sec Memory Limit: 128 MBSubmit: 2068 Solved: 907[Submit][St ...
随机推荐
- 【转】【Mysql】MySQL添加用户、删除用户与授权
MySql中添加用户,新建数据库,用户授权,删除用户,修改密码(注意每行后边都跟个;表示一个命令语句结束): 1.新建用户 1.1 登录MYSQL: @>mysql -u root -p @&g ...
- 【转】MFC CListCtrl 使用技巧
以下未经说明,listctrl默认view 风格为report 相关类及处理函数 MFC:CListCtrl类 SDK:以 “ListView_”开头的一些宏.如 ListView_InsertCol ...
- (转)MFC的ClistCtrl删除选中多行项目
MFC的ClistCtrl控件添加了多行数据后,若要删除选中的多行数据,可以使用ClistCtrl的成员函数,在网上找了很多例子,发现都有问题,因为在删除ClistCtrl行的时候,删除行下面的行会上 ...
- 【Java面试题】27 多线程笔试面试概念问答
第一题:线程的基本概念.线程的基本状态及状态之间的关系? 线程,有时称为轻量级进程,是CPU使用的基本单元:它由线程ID.程序计数器.寄存器集合和堆栈组成.它与属于同一进程的其他线程共享其代码段.数据 ...
- js得到当前文档的编码:document.characterSet
<!DOCTYPE HTML> <html > <head> <meta charset="utf-8"> <!--meta ...
- eclipse (ADT) svn插件 过滤上传的 文件 文件夹 一劳永逸
其实很简单哈,过滤的有三种类型,1.文件.2.文件夹.3.android的target 在ADT中 window->preferences-> 会打开如下界面 ignore就是忽视的意思 ...
- CSS实现圆角的方法
<style type="text/css"> body,p,div {margin:0;padding:0;} .Box {margin:10px auto;widt ...
- Navicat for Mysql 如何备份数据库
Navicat for Mysql 如何备份数据库 打开界面如下 打开自己的的数据库 点击需要备份的数据库名 未完!!! 文章来自:http://jingyan.baidu.com/article/f ...
- easyui_datagrid合并行单击某行选中所有
实现如下功能: 代码: <table id="dg" class="easyui-datagrid" title="Merge Cells fo ...
- C++第15周(春)项目3 - OOP版电子词典(二)
课程首页在:http://blog.csdn.net/sxhelijian/article/details/11890759,内有完整教学方案及资源链接 [项目3-OOP版电子词典](本程序须要的相关 ...