K-mean和k-mean++
(1)k-mean聚类
k-mean聚类比较容易理解就是一个计算距离,找中心点,计算距离,找中心点反复迭代的过程,
给定样本集D={x1,x2,...,xm},k均值算法针对聚类所得簇划分C={C1,C2,...,Ck}最小化平方误差
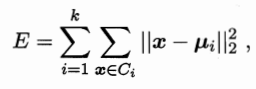
μi表示簇Ci的均值向量,在一定程度上刻画了簇内样本围绕均值向量的紧密程度,E值越小则簇内样本相似度越高。
下边是k均值算法的具体实现的算法

k均值算法的缺点是:(1)对于离群点和孤立点敏感;(2)k值选择; (3)初始聚类中心的选择; (4)只能发现球状簇。
k均值问题用于分布式的环境下:
分布式环境下肯定是在一块一块的计算的,如果在每个块中都加入选择的k个点,则在每个块中都进行简单的聚类。之后,,,,,
(2)k-mean++
k-mean算法有各种缺陷问题,比如上边的缺点(3)初始聚类中心的选择,选择不同的初始聚类中心点可能得到不同的结果,虽然可以多次选择不同的初始点,多次计算,但是这样无意中增加了更多的计算量,因此提出了k-mean++算法,k-mean++算法主要是针对初始时选择聚类中心的问题,
k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。wiki上对该算法的描述是如下:
- 从输入的数据点集合中随机选择一个点作为第一个聚类中心
- 对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
- 选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
- 重复2和3直到k个聚类中心被选出来
- 利用这k个初始的聚类中心来运行标准的k-means算法
从上面的算法描述上可以看到,算法的关键是第3步,如何将D(x)反映到点被选择的概率上,一种算法如下(详见此地):
- 先从我们的数据库随机挑个随机点当“种子点”
- 对于每个点,我们都计算其和最近的一个“种子点”的距离D(x)并保存在一个数组里,然后把这些距离加起来得到Sum(D(x))。
- 然后,再取一个随机值,用权重的方式来取计算下一个“种子点”。这个算法的实现是,先取一个能落在Sum(D(x))中的随机值Random,然后用Random -= D(x),直到其<=0,此时的点就是下一个“种子点”。
- 重复2和3直到k个聚类中心被选出来
- 利用这k个初始的聚类中心来运行标准的k-means算法
可以看到算法的第三步选取新中心的方法,这样就能保证距离D(x)较大的点,会被选出来作为聚类中心了。至于为什么原因很简单,如下图 所示:

假设A、B、C、D的D(x)如上图所示,当算法取值Sum(D(x))*random时,该值会以较大的概率落入D(x)较大的区间内,所以对应的点会以较大的概率被选中作为新的聚类中心。So it's work!
更过关于k-mean++的实现可以参见 http://blog.chinaunix.net/uid-24774106-id-3412491.html
duiyuk-mean算法的每个缺点的改进算法 http://blog.csdn.net/u010536377/article/details/50884416
K-mean和k-mean++的更多相关文章
- lintcode 中等题:k Sum ii k数和 II
题目: k数和 II 给定n个不同的正整数,整数k(1<= k <= n)以及一个目标数字. 在这n个数里面找出K个数,使得这K个数的和等于目标数字,你需要找出所有满足要求的方案. 样例 ...
- 今天遇到的面试题for(j=0,i=0;j<6,i<10;j++,i++) { k=i+j; } k 值最后是多少?
for(j=0,i=0;j<6,i<10;j++,i++) { k=i+j; } k 值最后是多少? <script type="text/javascript" ...
- 设子数组A[0:k]和A[k+1:N-1]已排好序(0≤K≤N-1)。试设计一个合并这2个子数组为排好序的数组A[0:N-1]的算法。
设子数组A[0:k]和A[k+1:N-1]已排好序(0≤K≤N-1).试设计一个合并这2个子数组为排好序的数组A[0:N-1]的算法.要求算法在最坏情况下所用的计算时间为O(N),只用到O(1)的辅助 ...
- 有两个序列A和B,A=(a1,a2,...,ak),B=(b1,b2,...,bk),A和B都按升序排列。对于1<=i,j<=k,求k个最小的(ai+bj)。要求算法尽量高效。
有两个序列A和B,A=(a1,a2,...,ak),B=(b1,b2,...,bk),A和B都按升序排列.对于1<=i,j<=k,求k个最小的(ai+bj).要求算法尽量高效. int * ...
- Python交互K线工具 K线核心功能+指标切换
Python交互K线工具 K线核心功能+指标切换 aiqtt团队量化研究,用vn.py回测和研究策略.基于vnpy开源代码,刚开始接触pyqt,开发界面还是很痛苦,找了很多案例参考,但并不能完全满足我 ...
- 给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
从第0行开始,输出第k行,传的参数为第几行,所以在方法中先将所传参数加1,然后将最后一行加入集合中返回. 代码如下: public static List<Integer> generat ...
- [leetcode]692. Top K Frequent Words K个最常见单词
Given a non-empty list of words, return the k most frequent elements. Your answer should be sorted b ...
- [leetcode]347. Top K Frequent Elements K个最常见元素
Given a non-empty array of integers, return the k most frequent elements. Example 1: Input: nums = [ ...
- imshow(K)和imshow(K,[]) 的区别
参考文献 imshow(K)直接显示K:imshow(K,[])显示K,并将K的最大值和最小值分别作为纯白(255)和纯黑(0),中间的K值映射为0到255之间的标准灰度值.
- spine 所有动画的第一帧必须把所有能K的都K上
spine 所有动画的第一帧必须把所有能K的都K上.否则在快速切换动画时会出问题.
随机推荐
- 【Unity】初始化物体的旋转角度
需求:钟表的指针默认位置在0点,在初始化时会根据当前的时间,旋转到一定角度.然后才是在当前旋转角度下每帧继续旋转. 问题:网上搜到的关于物体的旋转,基本都是给定一个速度的持续运动,而现在需要的是一个即 ...
- C语言 · 贪心算法
发现蓝桥杯上好多题目涉及到贪心,决定学一学. 贪心算法是指在对问题求解时,总是做出在当前看来是最好的选择.也就是说:不从整体最优上考虑,而是在某种意义上的局部最优解.其关键是贪心策略的选择,选择的贪心 ...
- web应用中文乱码问题的原因分析
为了让使用Java语言编写的程序能在各种语言的平台下运行,Java在其内部使用Unicode字符集来表示字符,这样就存在Unicode字符集和本地字符集进行转换的过程.当在Java中读取字符数据的时候 ...
- linux 共享内存shm_open实现进程间大数据交互
linux 共享内存shm_open实现进程间大数据交互 read.c #include <sys/types.h> #include <sys/stat.h> #includ ...
- Spring事件监听Demo
Spring事件监听实现了观察者模式.本Demo在junit4测试环境中实现 主要有三个类事件类.监听器类.事件发布类(入口) 事件类必须继承 ApplicationEvent,代码如下: impor ...
- kill -HUP pid 更改配置后不重新启动服务,动态更新配置文件
kill -HUP pid kill -HUP pid pid 是进程标识.如果想要更改配置而不需停止并重新启动服务,请使用该命令.在对配置文件作必要的更改后,发出该命令以动态更新服务配置. 根据约 ...
- iOS边练边学--(Quartz2D)图片添加水印
一.给图片添加水印的基本步骤 加载图片 手动创建位图上下文 绘制原生的图片 给原生的图片添加文字 生成一张图片给我们,从上下文中获取图片 关闭上下文 二.注意:位图上下文的获取方式跟layer上下文不 ...
- CentOS安装ssh服务
yum search ssh yum install openssh-server service sshd status [编辑]艺搜参考 http://www.cnblogs.com/eastso ...
- kettle中执行sql语句
一.直接执行sql,不添加任何参数 1.先找出执行sql语句的控件 2.打开控件,填写要执行的sql语句,主要下图中的红框中选项,后面会介绍各个选项的作用 二.执行sql,变量替换选项,变量指的是ke ...
- JS实现点击表头表格自动排序(含数字、字符串、日期)
这篇文章主要介绍了利用JS如何实现点击表头后表格自动排序,其中包含数字排序.字符串排序以及日期格式的排序,文中给出了完整的示例代码,并做了注释,相信大家都能看懂,感兴趣的朋友们一起来看看吧. < ...