R-CNN学习总结
R-CNN是一个比较早期的用于目标检测方法,但却十分经典,在此结合论文对这一方法做一个总结。
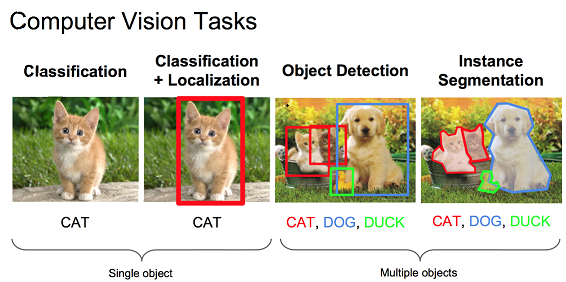
(写给小白:通过下图简单理解图像分类,图像定位,目标检测和实例分割)
R-CNN方法提出的背景:
1、近10年以来,以人工经验特征为主导的物体检测任务mAP(物体类别和位置的平均精度)提升缓慢;
2、随着ReLu激励函数、dropout正则化手段和大规模图像样本集ILSVRC的出现,在2012年ImageNet大规模视觉识别挑战赛中,Hinton及他的学生采用CNN特征获得了最高的图像识别精确度;
3、上述比赛后,引发了一股“是否可以采用CNN特征来提高当前一直停滞不前的物体检测准确率“的热潮。
R-CNN有两个创新点:
1、提出了一个高容量的卷积神经网络,自底向上地提取候选框特征,进行目标检测与识别;
2、使用大样本有监督预训练+小样本微调的方法解决了小样本难以训练或者过拟合的问题,同时也证明了卷积神经网络模型的可迁移性。
下面就看一下R-CNN的具体内容。
我们首先来看一下论文中R-CNN的流程图:
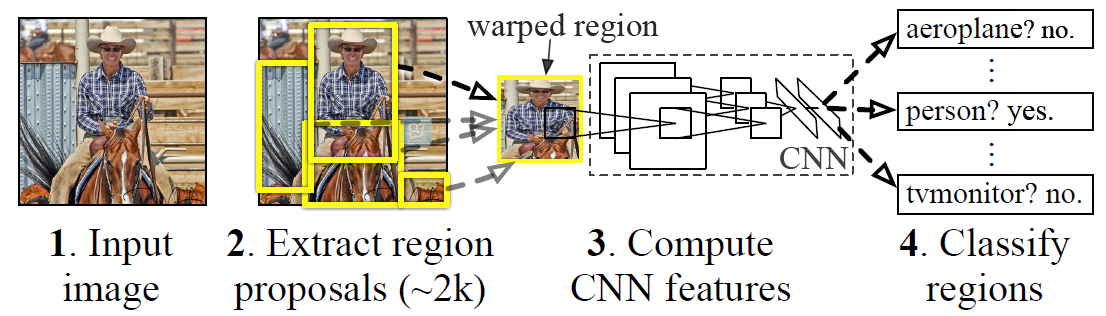
1、输入一张图像,通过selective search(具体见博客)的算法提出2000个左右的候选框,标出可能含有目标物体的区域;
2、将根据候选框得到的图像切片变形,使其满足CNNs的输出要求,此方法中采用了AlexNet网络,所以最终图像将变形为227×227;
3、对每个候选框进行减均值操作后,将其输入AlexNet网络中,获得4096维的特征向量,每张图像有2000个候选框,则最终每张图像会对应2000×4096维的特征矩阵;
4、将每个图像2000×4096的特征矩阵和20个SVM的权值矩阵4096×20相乘,此方法最终只预测20类物体和背景,每个SVM作为一个二分类器,所以需要20个SVM。最终会得到一个2000×20维矩阵,表示每个候选框属于某个类别的得分;
5、分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制(non maximum suppression, NMS)剔除重叠候选框,得到该列即该类中得分较高的一些候选框;
6、分别用20个回归器对上述20个类别中剩余的候选框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
如何将图像变形为227×227?作者在补充材料中给出了四种变形方式:
1、考虑context(图像中context指RoI周边像素)的各向同性变形,建议框像周围像素扩充到227×227,若遇到图像边界则用建议框像素均值填充,下图第二列;
2、不考虑context的各向同性变形,直接用建议框像素均值填充至227×227,下图第三列;
3、各向异性变形,简单粗暴对图像就行缩放至227×227,下图第四列;
4、变形前先进行边界像素填充(padding)处理,即向外扩展建议框边界,以上三种方法中分别采用padding=0下图第一行,padding=16下图第二行进行处理;
经过作者一系列实验表明采用padding=16的各向异性变形即下图第二行第三列效果最好,能使mAP提升3-5%。

为什么要进行非极大值抑制?非极大值抑制又如何操作?
在测试过程完成到第4步之后,获得2000×20维矩阵表示每个建议框是某个物体类别的得分情况,此时会遇到下图所示情况,同一个车辆目标会被多个建议框包围,这时需要非极大值抑制操作去除得分较低的候选框以减少重叠框。

非极大线性抑制的操作如下:
1、 对2000×20维矩阵中每列按从大到小进行排序;
2、从每列最大的得分候选框开始,分别与该列后面的得分候选框进行IoU计算,若IoU>阈值,则剔除得分较小的候选框,否则认为图像中存在多个同一类物体;
3、从每列次大的得分候选框开始,重复步骤2;
4、重复步骤3直到遍历完该列所有候选框;
5、遍历完2000×20维矩阵所有列,即所有物体种类都做一遍非极大值抑制;
6、最后剔除各个类别中剩余候选框得分少于该类别阈值的候选框。(论文中没有讲,但一般来说,得分较少的候选框我们一般不考虑)
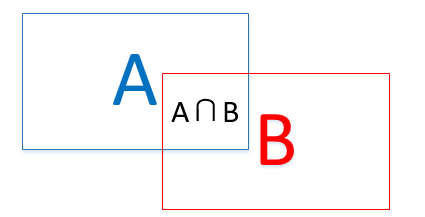
其中的IoU计算即(A∩B)/(A∪B) ,如下图所示:
为什么要采用回归器?回归器是什么有什么用?如何进行操作?
首先要明确目标检测不仅是要对目标进行识别,还要完成定位任务,所以最终获得的bounding-box也决定了目标检测的精度。
这里先解释一下什么叫定位精度:定位精度可以用算法得出的物体检测框与实际标注的物体边界框的IoU值来近似表示。
如下图所示,绿色框为实际标准的卡宴车辆框,即Ground Truth;黄色框为selective search算法得出的建议框,即Region Proposal。即使黄色框中物体被分类器识别为卡宴车辆,但是由于绿色框和黄色框IoU值并不大,所以最后的目标检测精度并不高。采用回归器是为了对建议框进行校正,使得校正后的Region Proposal与selective search更接近, 以提高最终的检测精度。论文中采用bounding-box回归使mAP提高了3~4%。

那么回归器该如何设计?
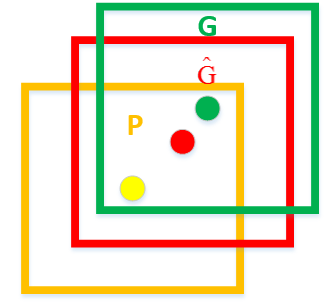
如上图,黄色框P表示候选框Region Proposal,绿色窗口G表示实际框Ground Truth,红色窗口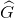 表示Region Proposal进行回归后的预测窗口,现在的目标是找到P到
表示Region Proposal进行回归后的预测窗口,现在的目标是找到P到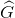 的线性变换(当Region Proposal与Ground Truth的IoU>0.6时可以认为是线性变换),使得与G越相近,这就相当于一个简单的可以用最小二乘法解决的线性回归问题,具体往下看。
的线性变换(当Region Proposal与Ground Truth的IoU>0.6时可以认为是线性变换),使得与G越相近,这就相当于一个简单的可以用最小二乘法解决的线性回归问题,具体往下看。
让我们先来定义P窗口的数学表达式: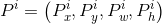 ,其中
,其中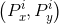 表示第一个i窗口的中心点坐标,
表示第一个i窗口的中心点坐标,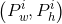 分别为第i个窗口的宽和高;G窗口的数学表达式为:
分别为第i个窗口的宽和高;G窗口的数学表达式为: ;窗口的数学表达式为:
;窗口的数学表达式为: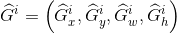 。以下省去上标i。
。以下省去上标i。
这里定义了四种变换函数,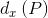 ,
,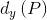 ,
,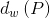 ,
,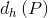 。和通过平移对x和y进行变化,和通过缩放对w和h进行变化,即下面四个式子所示:
。和通过平移对x和y进行变化,和通过缩放对w和h进行变化,即下面四个式子所示:
 (1)
(1)
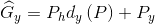 (2)
(2)
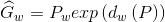 (3)
(3)
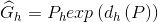 (4)
(4)
但是P,G对应的点是原图上的值,或者说对应的区域目标是未经过CNN处理过的。那么对应feature map上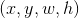 的变化量是多少呢?其中,回归目标
的变化量是多少呢?其中,回归目标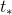 表示对应
表示对应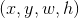 的变化量,由训练输入对
的变化量,由训练输入对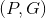 按下式计算得来:
按下式计算得来:
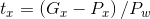 (6)
(6)
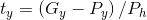 (7)
(7)
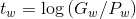 (8)
(8)
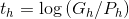 (9)
(9)
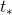 表示
表示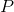 到
到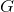 的偏移从原图映射到feature map上的映射关系,
的偏移从原图映射到feature map上的映射关系,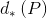 表示
表示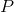 到
到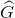 的偏移从原图映射到feature map上的映射关系。
的偏移从原图映射到feature map上的映射关系。
每一个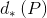 (*表示x,y,w,h)都是一个AlexNet CNN网络Pool5层特征
(*表示x,y,w,h)都是一个AlexNet CNN网络Pool5层特征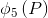 的线性函数,即
的线性函数,即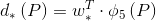 ,这里
,这里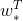 就是所需要学习的回归参数。损失函数即为:
就是所需要学习的回归参数。损失函数即为:
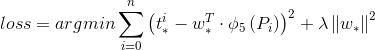 (5)
(5)
损失函数中加入正则项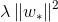 是为了避免回归参数
是为了避免回归参数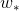 过大。
过大。
1、构造样本对。为了提高每类样本框回归的有效性,对每类样本都仅仅采集与Ground Truth相交IoU最大的Region Proposal,并且IoU>0.6的Region Proposal作为样本对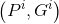 ,一共产生20对样本对(20个类别);
,一共产生20对样本对(20个类别);
2、每种类型的回归器单独训练,输入该类型样本对n个: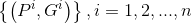 以及
以及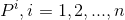 所对应的AlexNet CNN网络Pool5层特征
所对应的AlexNet CNN网络Pool5层特征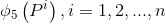 ;
;
3、利用(6)-(9)式和输入样本对计算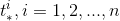 ;
;
4、利用和,根据损失函数(5)进行回归,得到使损失函数最小的参数。
训练过程:
1、有监督预训练
| 样本 | 来源 |
| 正样本 | ILSVRC2012 |
| 负样本 | ILSVRC2012 |
ILSVRC样本集上仅有图像类别标签,没有图像物体位置标注;
采用AlexNet CNN网络进行有监督预训练,学习率为0.01;
该网络输入为227×227的ILSVRC训练集图像,输出最后一层为4096维特征->1000类的映射,训练的是网络参数。
2、特定样本下的微调
| 样本 | 来源 |
|---|---|
| 正样本 | Ground Truth+与Ground Truth相交IoU>0.5的候选框(由于Ground Truth太少了) |
| 负样本 | 与Ground Truth相交IoU≤0.5的候选框 |
PASCAL VOC 2007样本集上既有图像中物体类别标签,也有图像中物体位置标签;
采用训练好的AlexNet CNN网络进行PASCAL VOC 2007样本集下的微调,学习率为0.001(0.01/10为了在学习新东西时不至于忘记之前的记忆);
mini-batch为32个正样本和96个负样本(由于正样本太少);
该网络输入为候选框(由selective search而来)变形后的227×227的图像,修改了原来的1000为类别输出,改为21维(20类+背景)输出,训练的是网络参数。
3、SVM训练
| 样本 | 来源 |
|---|---|
| 正样本 | Ground Truth |
| 负样本 | 与Ground Truth相交IoU<0.3的建议框 |
由于SVM是二分类器,需要为每个类别训练单独的SVM;
SVM训练时输入正负样本在AlexNet CNN网络计算下的4096维特征,输出为该类的得分,训练的是SVM权重向量;
由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本。
4、Bounding-box regression训练
| 样本 | 来源 |
|---|---|
| 正样本 | 与Ground Truth相交IoU最大的Region Proposal,并且IoU>0.6的Region Proposal |
输入数据为某类型样本对n个:以及所对应的AlexNet CNN网络Pool5层特征,输出回归后的建议框Bounding-box,训练的是,,,四种变换操作的权重向量。
解释分析:
1、什么叫有监督预训练?为什么要进行有监督预训练?
有监督预训练也称之为迁移学习,举例说明:若有大量标注信息的人脸年龄分类的正负样本图片,利用样本训练了CNN网络用于人脸年龄识别;现在要通过人脸进行性别识别,那么就可以去掉已经训练好的人脸年龄识别网络CNN的最后一层或几层,换成所需要的分类层,前面层的网络参数直接使用为初始化参数,修改层的网络参数随机初始化,再利用人脸性别分类的正负样本图片进行训练,得到人脸性别识别网络,这种方法就叫做有监督预训练。这种方式可以很好地解决小样本数据无法训练深层CNN网络的问题,我们都知道小样本数据训练很容易造成网络过拟合,但是在大样本训练后利用其参数初始化网络可以很好地训练小样本,这解决了小样本训练的难题。这篇文章最大的亮点就是采用了这种思想,ILSVRC样本集上用于图片分类的含标注类别的训练集有1millon之多,总共含有1000类;而PASCAL VOC 2007样本集上用于物体检测的含标注类别和位置信息的训练集只有10k,总共含有20类,直接用这部分数据训练容易造成过拟合,因此文中利用ILSVRC2012的训练集先进行有监督预训练。
2、ILSVRC 2012与PASCAL VOC 2007数据集有冗余吗?
即使图像分类与目标检测任务本质上是不同的,理论上应该不会出现数据集冗余问题,但是作者还是通过两种方式测试了PASCAL 2007测试集和ILSVRC 2012训练集、验证集的重合度:第一种方式是检查网络相册IDs,4952个PASCAL 2007测试集一共出现了31张重复图片,0.63%重复率;第二种方式是用GIST描述器匹配的方法,4952个PASCAL 2007测试集一共出现了38张重复图片(包含前面31张图片),0.77%重复率,这说明PASCAL 2007测试集和ILSVRC 2012训练集、验证集基本上不重合,没有数据冗余问题存在。
3、可以不进行特定样本下的微调吗?可以直接采用AlexNet CNN网络的特征进行SVM训练吗?
文中设计了没有进行微调的对比实验,分别就AlexNet CNN网络的pool5、fc6、fc7层进行特征提取,输入SVM进行训练,这相当于把AlexNet CNN网络当做万精油使用,类似HOG、SIFT等做特征提取一样,不针对特征任务。实验结果发现f6层提取的特征比f7层的mAP还高,pool5层提取的特征与f6、f7层相比mAP差不多; 在PASCAL VOC 2007数据集上采取了微调后fc6、fc7层特征较pool5层特征用于SVM训练提升mAP十分明显; 由此作者得出结论:不针对特定任务进行微调,而将CNN当成特征提取器,pool5层得到的特征是基础特征,类似于HOG、SIFT,类似于只学习到了人脸共性特征;从fc6和fc7等全连接层中所学习到的特征是针对特征任务特定样本的特征,类似于学习到了分类性别分类年龄的个性特征。
4、为什么微调时和训练SVM时所采用的正负样本阈值(0.5和0.3)不一致?
微调阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松:与Ground Truth相交IoU>0.5的建议框为正样本,否则为负样本;
SVM这种机制是由于其适用于小样本训练,故对样本IoU限制严格:Ground Truth为正样本,与Ground Truth相交IoU<0.3的建议框为负样本。
5、为什么不直接采用微调后的AlexNet CNN网络最后一层SoftMax进行21分类(20类+背景)?
因为微调时和训练SVM时所采用的正负样本阈值不同,微调阶段正样本定义并不强调精准的位置,而SVM正样本只有Ground Truth;并且微调阶段的负样本是随机抽样的,而SVM的负样本是经过hard negative mining方法筛选的;导致在采用SoftMax会使PSACAL VOC 2007测试集上mAP从54.2%降低到50.9%。
此方法的结果:
1、PASCAL VOC 2010测试集上实现了53.7%的mAP;
2、PASCAL VOC 2012测试集上实现了53.3%的mAP;
3、计算Region Proposals和features平均所花时间:13s/image on a GPU;53s/image on a CPU。
此方法还存在什么问题:
1、很明显,最大的缺点是对一张图片的处理速度慢,这是由于一张图片中由selective search算法得出的约2k个建议框都需要经过变形处理后由CNN前向网络计算一次特征,这其中涵盖了对一张图片中多个重复区域的重复计算,很累赘;
2、在计算2k个建议框的CNN特征时,在硬盘上保留了2k个建议框的Pool5特征,虽然这样做只需要一次CNN前向网络运算,但是耗费大量磁盘空间;
3、训练时间长,虽然文中没有明确指出具体训练时间,但由于采用RoI-centric sampling(从所有图片的所有建议框中均匀取样)进行训练,那么每次都需要计算不同图片中不同建议框CNN特征,无法共享同一张图的CNN特征,训练速度很慢;
4、整个测试过程很复杂,要先提取建议框,之后提取每个建议框CNN特征,再用SVM分类,做非极大值抑制,最后做bounding-box回归才能得到图片中物体的种类以及位置信息;同样训练过程也很复杂,ILSVRC 2012上预训练CNN,PASCAL VOC 2007上微调CNN,做20类SVM分类器的训练和20类bounding-box回归器的训练;这些不连续过程必然涉及到特征存储、浪费磁盘空间等问题。
参考博客:http://blog.csdn.net/wopawn/article/details/52133338
R-CNN学习总结的更多相关文章
- R基础学习
R基础学习 The Art of R Programming 1.seq 产生等差数列:seq(from,to,by) seq(from,to,length) for(i in 1:length(x) ...
- 卷积神经网络(CNN)学习笔记1:基础入门
卷积神经网络(CNN)学习笔记1:基础入门 Posted on 2016-03-01 | In Machine Learning | 9 Comments | 14935 Vie ...
- R语言学习 第四篇:函数和流程控制
变量用于临时存储数据,而函数用于操作数据,实现代码的重复使用.在R中,函数只是另一种数据类型的变量,可以被分配,操作,甚至把函数作为参数传递给其他函数.分支控制和循环控制,和通用编程语言的风格很相似, ...
- CNN学习笔记:批标准化
CNN学习笔记:批标准化 Batch Normalization Batch Normalization, 批标准化, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法. 在神经网络的训练过 ...
- CNN学习笔记:目标函数
CNN学习笔记:目标函数 分类任务中的目标函数 目标函数,亦称损失函数或代价函数,是整个网络模型的指挥棒,通过样本的预测结果与真实标记产生的误差来反向传播指导网络参数学习和表示学习. 假设某分类任务共 ...
- CNN学习笔记:卷积神经网络
CNN学习笔记:卷积神经网络 卷积神经网络 基本结构 卷积神经网络是一种层次模型,其输入是原始数据,如RGB图像.音频等.卷积神经网络通过卷积(convolution)操作.汇合(pooling)操作 ...
- CNN学习笔记:全连接层
CNN学习笔记:全连接层 全连接层 全连接层在整个网络卷积神经网络中起到“分类器”的作用.如果说卷积层.池化层和激活函数等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的特征表示映射到样 ...
- CNN学习笔记:池化层
CNN学习笔记:池化层 池化 池化(Pooling)是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样.有多种不同形式的非线性池化函数,而其中“最大池化(Max pooling)”是最为常见 ...
- CNN学习笔记:卷积运算
CNN学习笔记:卷积运算 边缘检测 卷积 卷积是一种有效提取图片特征的方法.一般用一个正方形卷积核,遍历图片上的每一个像素点.图片与卷积核重合区域内相对应的每一个像素值乘卷积核 .内相对应点的权重,然 ...
- CNN学习笔记:激活函数
CNN学习笔记:激活函数 激活函数 激活函数又称非线性映射,顾名思义,激活函数的引入是为了增加整个网络的表达能力(即非线性).若干线性操作层的堆叠仍然只能起到线性映射的作用,无法形成复杂的函数.常用的 ...
随机推荐
- ActionBar自己定义改动无效解决方法
假设程序支持API11下面的版本号,那么须要改动多个地方 values-v14 和values-v11以下的styles中也要写上 <style name="AppTheme" ...
- objc中类方法里的self指的是什么
所有转出“博客园”,请您注明出处:http://www.cnblogs.com/xiaobajiu/p/4121431.html objc中类方法里的self指的是什么 在objc中是可以在类方法中使 ...
- iOS之限制TextField的输入长度
网上有很多限制textField输入长度方法,但是我觉得都不是很完美,准确来说可以说是不符合实际开发的要求,因此在这里整理一下textField限制输入长度的方法.我所采用的并不是监听方法而是最不同的 ...
- JS基础——事件操作总结
通用事件绑定 function bindEvent(elem,type,fn) { elem.addEventListener(type,fn); } let a =document.getEle ...
- $.ajax 完整参数
jquery中的ajax方法参数 url: 要求为String类型的参数,(默认为当前页地址)发送请求的地址. type: 要求为String类型的参数,请求方式(post或get)默认为get.注意 ...
- [译文]程序员能力矩阵 Programmer Competency Matrix
注意:每个层次的知识都是渐增的,位于层次n,也蕴涵了你需了解所有低于层次n的知识. 计算机科学 Computer Science 2n (Level 0) n2 (Level 1) n (Leve ...
- less.js插件监听
<script>less.watch();</script> 在不手动刷新/重新加载页面会自动监听less的变化,页面做出相应的变化 . 写在这两行后面就好 了 <lin ...
- Hadoop系列-HDFS基础
基本原理 HDFS(Hadoop Distributed File System)是Hadoop的一个基础的分布式文件系统,这个分布式的概念主要体现在两个地方: 数据分块存储在多台主机 数据块采取冗余 ...
- vue 项目中px转rem转换问题(postcss-px2rem)
1.安装postcss-px2rem npm install postcss-px2rem --save npm install postcss-px2rem --save 2.配置px2rem 在配 ...
- [转]Web登录中的信心安全问题
1. 一个简单的HTML例子看看用户信息安全 标准的HTML语法中,支持在form表单中使用<input></input>标签来创建一个HTTP提交的属性,现代的WEB登录中, ...